作为一名关注国产数据库的开发者,近期上手了 KaiwuDB 推出的轻量级版本 ------ KaiwuDB-Lite,主打 "轻量化部署、低资源占用、适配开发者日常测试 / 小型业务场景",不仅在低配资源下具备百万数据点秒级写入,千万记录毫秒级响应等时序数据特色处理能力,同时兼具轻量高效、简洁易用、稳定可靠的特点。本文将从环境搭建、表结构设计、数据测试等维度,完整分享我的体验过程,也给想尝试这款数据库的朋友做个参考。
一、先搞懂:KaiwuDB-Lite 适合什么场景?
KaiwuDB 本身是一款面向时序 / 结构化数据的多模数据库,而 Lite 版本做了轻量化裁剪,去掉了集群相关的复杂功能,专注单节点部署,资源占用极低(官方说最低 1 核 2G 即可运行),非常适合:
- 开发者本地测试、学习时序数据库;
- 资源有限的边缘设备、小型 IoT 项目、个人侧的设备监控数据存储;
- 嵌入式系统
- 轻量级时序数据的查询分析场景。
- 云边端协同场景
核心特性:
- 超轻内核超低资源部署:
通过对KaiwuDB的精心优化,KaiwuDB Lite不仅将其先进的特性完美的继承了KaiwuDB的优势,且将其在边端的物联网场景下的应用能力进一步的升级,其相比于KaiwuDB的架构更加的简洁轻量,尤其在支持了ARM等边端的架构下都能高效的将内存和磁盘的空间都给的淋漓尽致的利用了,并能在低至1核的CPU的环境中也能平稳的运行。
- 高性能时序数据查询:
KaiwuDB Lite 提供多样化的聚合查询能力,支持百万记录数据秒级写入、千万级记录查询毫秒级响应,为海量边端时序数据提供实时的洞察。
- 云边端协同:
通过与KaiwuDB的无缝融合,KaiwuDB Lite还能将云、边、端的数据都一体化的对接起来,实现了从数据的各个层级的实时的流动与数据的各个层级的的一致性保障。
- 支持 SQL 标准:
KaiwuDB Lite 支持 SQL 标准,同时去除了不必要的复杂功能,专注于提供核心的时序数据存储和查询功能,降低运维及学习成本。
- 灵活应用方式:
KaiwuDB Lite对市面上主流的Linux操作系统都提供了支持,并且可以与Java、C/C++、PHP等各类编程语言实现无缝集成。
- 高可用:
借助对KaiwuDB Lite的 WAL日志等机制的开启,有效的将设备的突然断电或崩溃等意外事件的影响降至最低,从而大大提高了数据的可靠性和可用性
二、环境搭建:5 分钟搞定
为满足不同应用场景的需求, KaiwuDB Lite 提供两种灵活的部署方式:
**安装包部署:**采用传统的客户端-服务器架构,以独立服务进程形式运行,支持多客户端并发访问,适合企业级应用和多用户系统。
KaiwuDB Lite 支持在以下操作系统上进行安装部署:
|---------|------------|------------------|
| 操作系统 | 版本 | 架构 |
| Ubuntu | 18.04 及以上 | • x86_64 • arm64 |
| KylinOS | V10 | • 鲲鹏 • 海光 |
| Windows | Windows 11 | x86_64 |
**嵌入式部署(无服务部署):**采用传统的客户端-服务器架构,以独立服务进程形式运行,支持多客户端并发访问,适合企业级应用和多用户系统。
KaiwuDB Lite 目前支持以下编程语言的嵌入式集成:
• C++:提供原生 C++ API,性能最优
• Python:提供 Python 绑定,支持 DataFrame 集成
本次体验先选择一个简单的在,在linux下部署
1、数据库部署
设置安装许可证,获取 .lic 格式的许可证文件,并将其放置到相应目录
在/usr/local/etc 下放置去可证
ls /usr/local/etc/Inspur.lic

获取系统对应的 KaiwuDB Lite 安装包,将安装包拷贝到目标机器上,然后解压安装包:
tar -zxvf kaiwudb-lite-v3.1.0-linux-amd64.tar.gz
自定义配置配置文件
cp kaiwudb-lite-default.conf kaiwudb-lite.conf
设置数据库 IP 地址、客户端连接端口、数据目录、日志目录等信息。
for kaiwudb-lite server:
server
ip = 127.0.0.1 # ip
port = 36252 # default 36257, should in range 1024, 65535
if -D or --data provide in commond, then the corresponding value here with be disabled
supports relative and absolute paths, with relative paths generated in the current execution directory
data_dir = data
log_dir = data/log
threads = 16 # 1, 2147483647 (2\^31-1)
KB, MB, GB, TB for 1000^i units or KiB, MiB, GiB, TiB for 1024^i units
memory_limit = 32 GiB # 32 MiB, 9007199254740991 (2\^53-1) bytes
for logging
enable_logging = true # false, true
logging_mode = LEVEL_ONLY # LEVEL_ONLY, DISABLE_SELECTED, ENABLE_SELECTED
disabled_log_types = ''
enabled_log_types = ''
logging_level = WARN # TRACE, DEBUG, INFO, WARN, ERROR, FATAL
logging_storage = file # memory, stdout, file
auto_prune = false # if comment out this line, default value for "auto_prune" is true
enable_uds = false
uds_file_path = /tmp/kaiwudb_lite # uds_file for accept req
ignore_db_noexists = true
使用自定义配置方式启动数据库时,系统将按以下顺序查找配置文件 kaiwudblite.conf: data 目录 → 程序目录 → 当前目录,找到后立即使用。若未找到配置文件,则使用 kaiwudb-lite-default.conf 中的默认配置启动。
启动数据库
./kaiwudb_lite

至此kaiwudb-lite就可以使用了
2、验证启动 & 连接数据库
kaiwudb-lite支持postgres协议,并且为了简化安装包,KaiwuDB Lite 使用 psql 作为客户端工具
安装psql客户端
apt-get install postgresql-client-14

连接数据库
psql -h localhost -p 36252 -U admin

三、核心功能体验:贴合 IoT 监控场景的对象体验
时序数据库的表设计核心是 "贴合时间维度 + 业务属性",我以「智能电表监控数据」为场景设计表结构,兼顾 KaiwuDB-Lite 的时序特性和 SQL 兼容性。
1、创建数据库与schema
KaiwuDB Lite极简化取消掉了数据库创建功能,使用默认存储

创建schema,schema使用这里延用了pg的特性可以设置search_path,也可以使用use schema语法切换schema

使用search_path切换schema
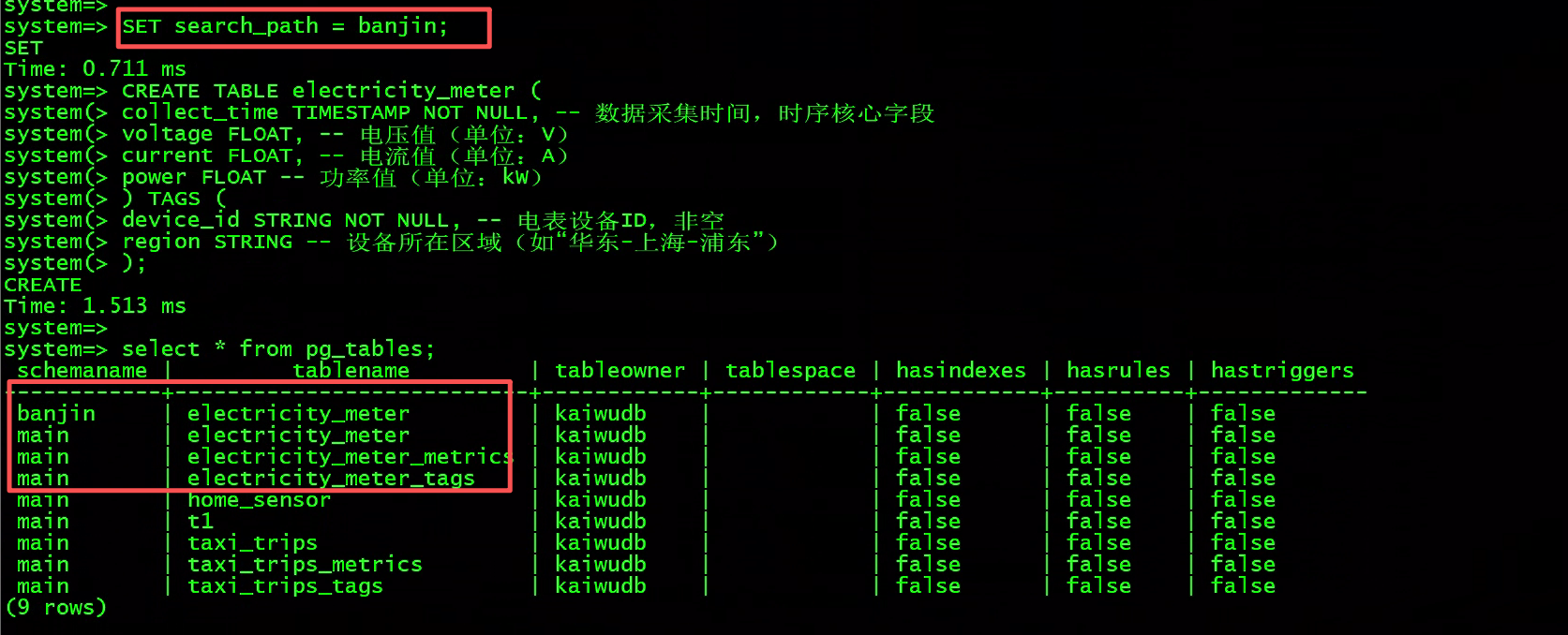
SET search_path = banjin

切换schema后创建的表会在对应schema下,如果没有设置默认会在名main的schema下
2、数据库连接用户创建
CREATE USER banjin WITH PASSWORD 'Oracle123';

测试新建用户连接数据库

3、表设计与创建
先了解下KaiwuDB Lite的表存储方式,KaiwuDB Lite 针对时序数据提供了两种存储方式:
|---------------------------------------------|----------------------------------|------------------------------|---------------|
| 存储方式 | 优势 | 缺点 | 适用场景 |
| 单表存储: 即一张时序 表同时存储 Metric 和 Tag 信息 | • 查询无需显式 关联操作 • 使用简单 | • 建表后不支持加 列/减列操作 • 存储效率相对较 低 | 表结构相对固 定的场景 |
| 双表存储: Metric 和 Tag 分别存储在 Metrics 表和 Tags 表中 | • Metrics 数据 存储高效,压缩率 高 • 支持加/减列 | • 查询需要显式关 联操作 • 使用相对复杂 | 表结构需要灵 活变更的场景 |
时序数据库的表设计核心是 "贴合时间维度 + 业务属性",我以「智能电表监控数据」为场景设计表结构,兼顾 KaiwuDB-Lite 的时序特性和 SQL 兼容性。
- 核心维度:设备 ID(唯一标识)、采集时间(时序核心)、电压、电流、功率、所在区域;
- 优化点:KaiwuDB-Lite 对数值型字段做类型精准定义,时间字段用
TIMESTAMP适配时序查询。
1、单表存储
创建电表监控表一个表既存储tag数据又存储Metric
-- 创建电表监控表
CREATE TABLE electricity_meter (
collect_time TIMESTAMP NOT NULL, -- 数据采集时间,时序核心字段
voltage FLOAT, -- 电压值(单位:V)
current FLOAT, -- 电流值(单位:A)
power FLOAT -- 功率值(单位:kW)
) TAGS (
device_id STRING NOT NULL, -- 电表设备ID,非空
region STRING -- 设备所在区域(如"华东-上海-浦东")
);

2、双表存储
创建电表监控表 Metric 和Tag 分别存储在 Metrics表和 Tags 表中
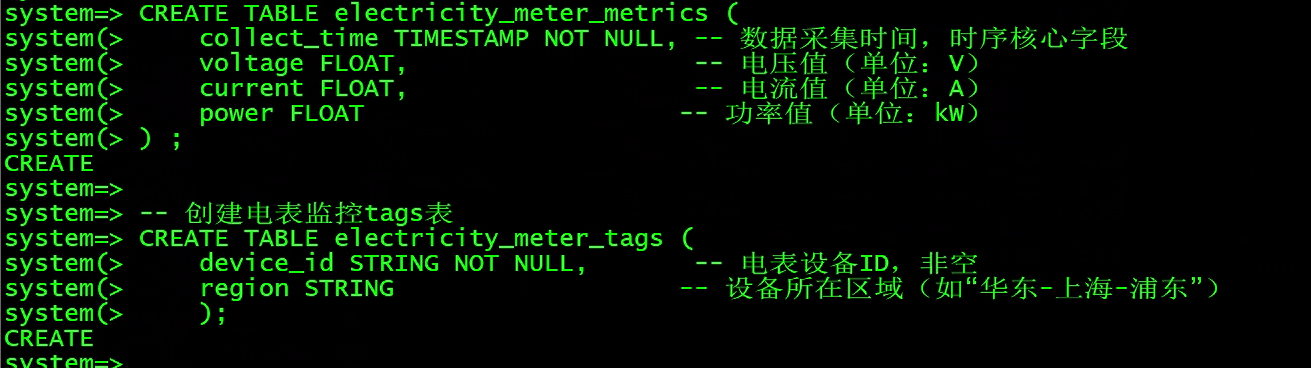
-- 创建电表监控metrics表
CREATE TABLE electricity_meter_metrics (
collect_time TIMESTAMP NOT NULL, -- 数据采集时间,时序核心字段
voltage FLOAT, -- 电压值(单位:V)
current FLOAT, -- 电流值(单位:A)
power FLOAT -- 功率值(单位:kW)
) ;
-- 创建电表监控tags表
CREATE TABLE electricity_meter_tags (
device_id STRING NOT NULL, -- 电表设备ID,非空
region STRING -- 设备所在区域(如"华东-上海-浦东")
);
四、数据测试:从基础 CRUD 到性能验证
1、基础 CRUD(增删改查)
插入单条测试数据
INSERT INTO electricity_meter
(device_id, collect_time, voltage, current, power, region)
VALUES
('meter_001', '2026-01-06 10:00:00', 220.5, 10.2, 2.25, '华东-上海-浦东')

查询单条数据
SELECT * FROM electricity_meter WHERE device_id = 'meter_001' AND collect_time = '2026-01-06 10:00:00';

简单更新 & 删除
-- 更新功率值 UPDATE electricity_meter SET power = 2.3 WHERE device_id = 'meter_001' AND collect_time = '2026-01-06 10:00:00'; -- 删除测试数据(可选) DELETE FROM electricity_meter WHERE device_id = 'meter_001';

2、批量插入性能测试
-- 先清空测试表
TRUNCATE TABLE electricity_meter;
-- 批量插入10万条数据(模拟100个设备,每个设备1000个时间点)
INSERT INTO electricity_meter
(device_id, collect_time, voltage, current, power, region)
SELECT
'meter_' || lpad((random() * 99)::INT::STRING, 3, '0'), -- 生成meter_001到meter_099的设备ID
'2026-01-06 00:00:00'::TIMESTAMP + (i || ' seconds')::INTERVAL, -- 时间递增
210 + random() * 20, -- 电压:210-230V
5 + random() * 15, -- 电流:5-20A
(210 + random() * 20) * (5 + random() * 15) / 1000, -- 功率=电压*电流/1000
CASE WHEN random() < 0.3 THEN '华东-上海'
WHEN random() < 0.6 THEN '华北-北京'
ELSE '华南-广州' END -- 随机区域
FROM generate_series(1, 100000) AS t(i); -- 生成1-10万的序列
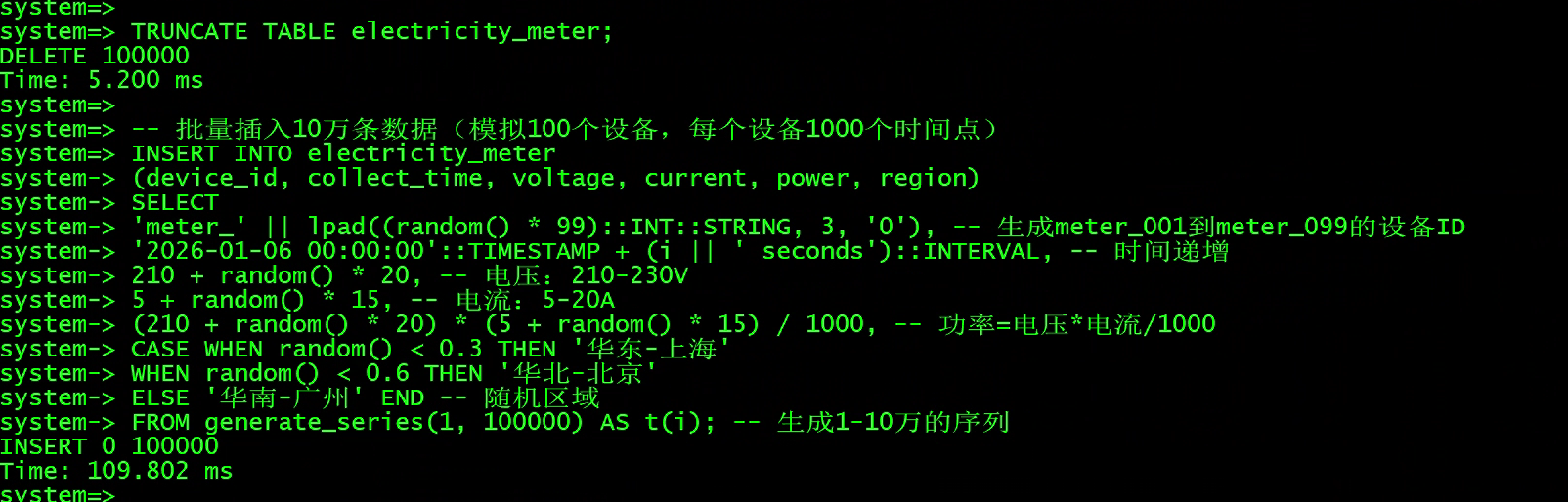

测试结果
- 写入 10 万 条数据耗时:100豪秒;
- 数据占用磁盘:约 10MB
- 无报错、无数据丢失,插入完成后可立即查询。
3、复杂时序查询测试
针对时序场景的高频查询场景,我测试了 3 类典型查询,验证响应速度:
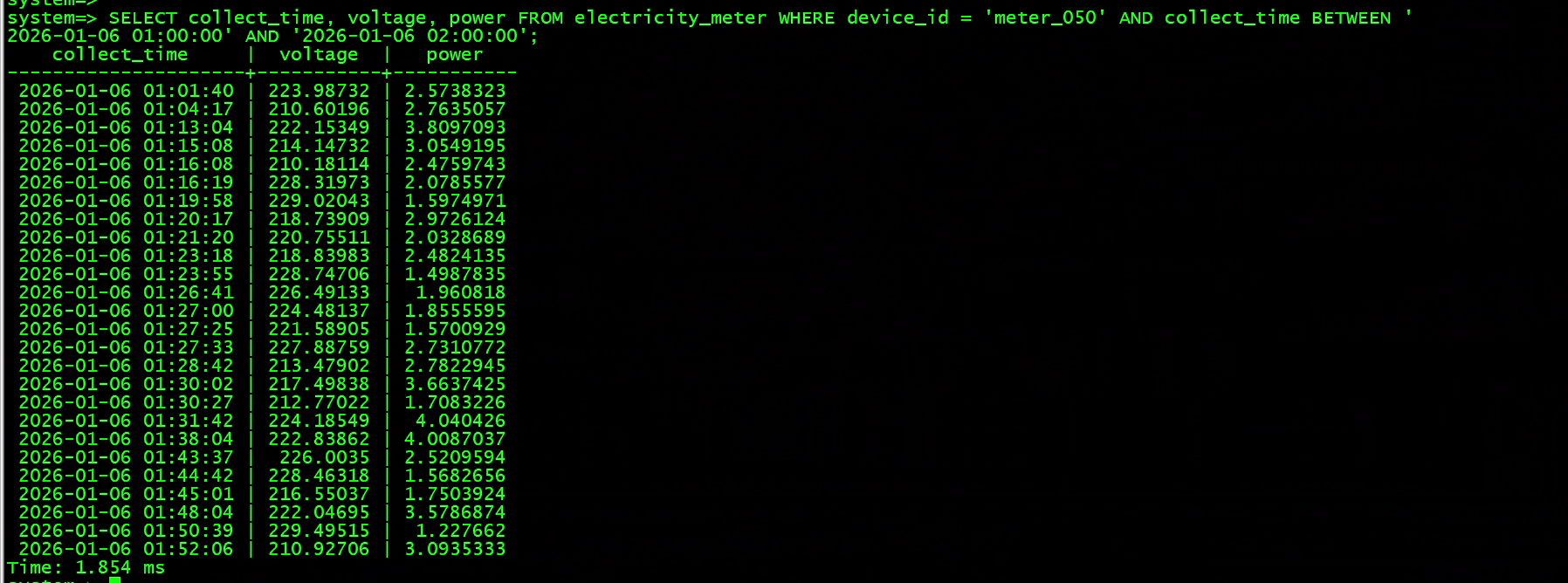
单设备时间范围查询
SELECT collect_time, voltage, power FROM electricity_meter WHERE device_id = 'meter_050' AND collect_time BETWEEN '2026-01-06 01:00:00' AND '2026-01-06 02:00:00';
区域聚合统计
SELECT region, AVG(power), MAX(voltage) FROM electricity_meter WHERE collect_time >= '2026-01-06 00:00:00' GROUP BY region;

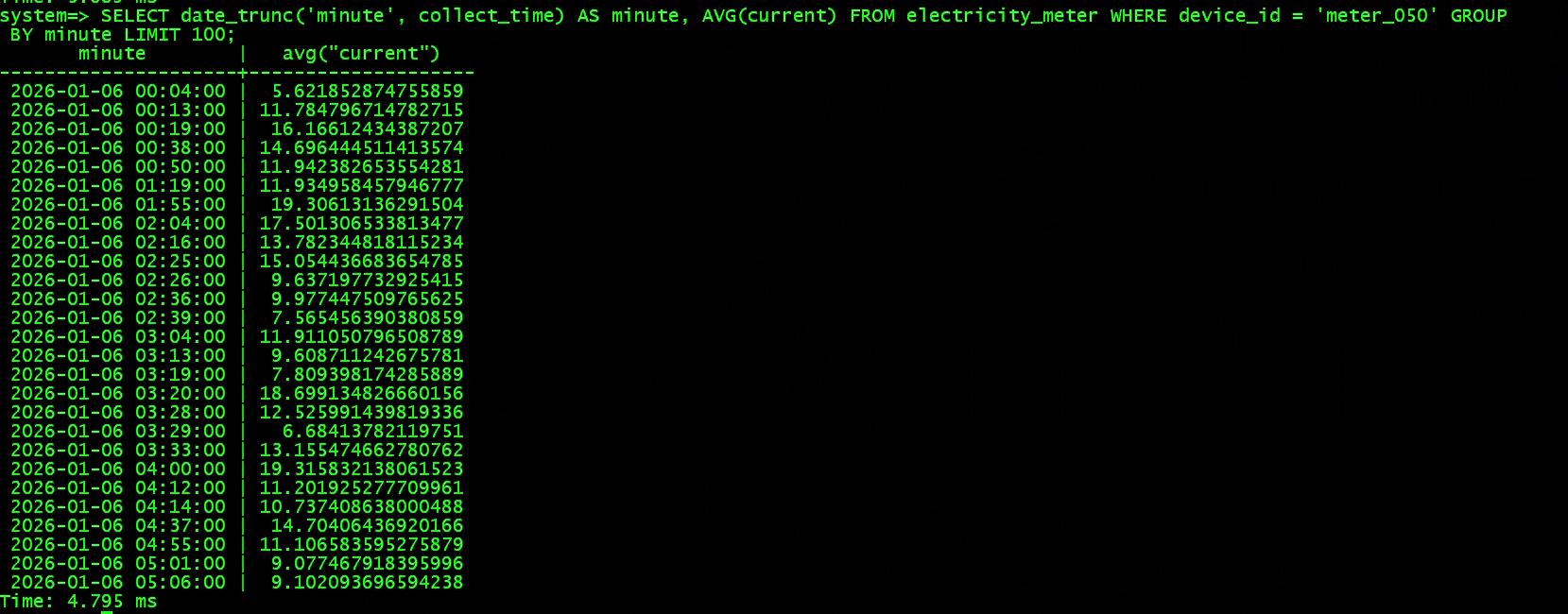
按分钟聚合
SELECT date_trunc('minute', collect_time) AS minute, AVG(current) FROM electricity_meter WHERE device_id = 'meter_050' GROUP BY minute LIMIT 100;
| 查询场景 | SQL 语句 | 响应时间 |
|---|---|---|
| 单设备时间范围查询 | SELECT collect_time, voltage, power FROM electricity_meter WHERE device_id = 'meter_050' AND collect_time BETWEEN '2026-01-06 01:00:00' AND '2026-01-06 02:00:00'; |
2ms |
| 区域聚合统计 | SELECT region, AVG(power), MAX(voltage) FROM electricity_meter WHERE collect_time >= '2026-01-06 00:00:00' GROUP BY region; |
5.6ms |
| 按分钟聚合 | SELECT date_trunc('minute', collect_time) AS minute, AVG(current) FROM electricity_meter WHERE device_id = 'meter_050' GROUP BY minute LIMIT 100; |
4.7ms |
结论 :10 万条数据量下,无论是单点查询还是聚合查询,响应都在毫秒级,完全满足小型业务需求,充分满足了 边缘计算的数据处理, 高性能与低资源占用。
五、核心功能体验:系统视图使用
KaiwuDB-Lite保留了部分pg_catalog系统视图的功能,在简化的KaiwuDB-Lite下还是可以使用常用的视图功能
查看实例下有哪些数据库,可以看到metadata、system、temp
select * from pg_database;

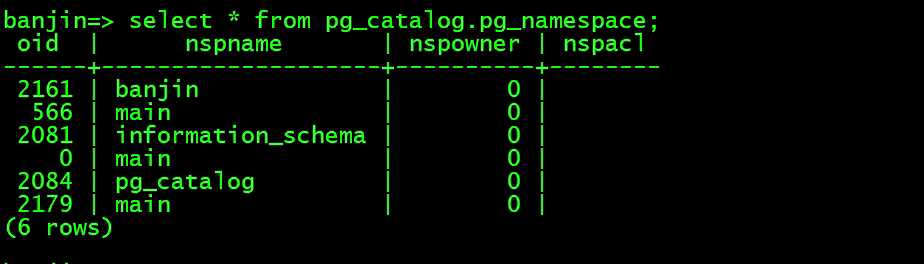
查看数据库中的schema
select * from pg_catalog.pg_namespace;
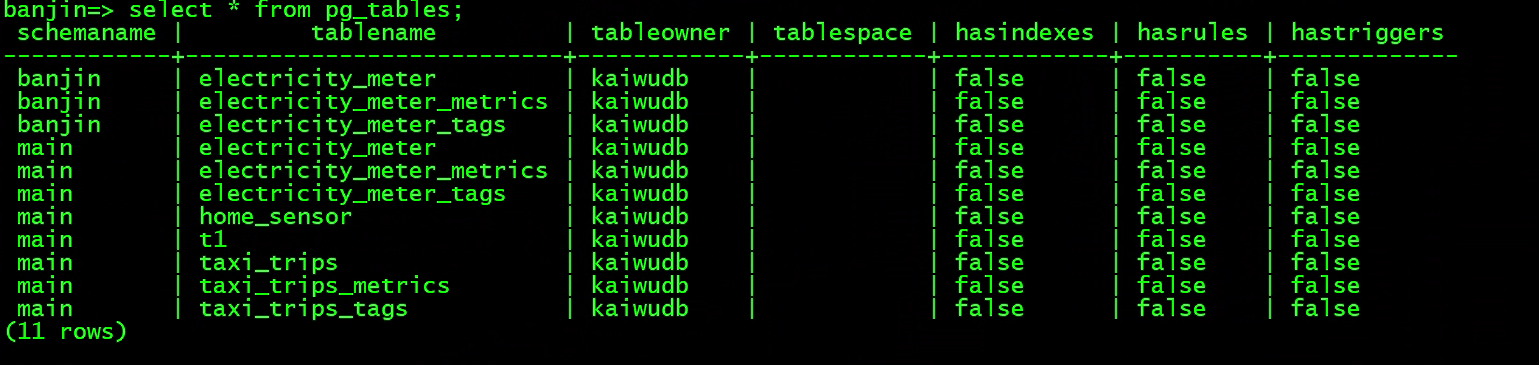
查看数据库中的表,这里看到所有表默认存储在main的schema下
select * from pg_tables;
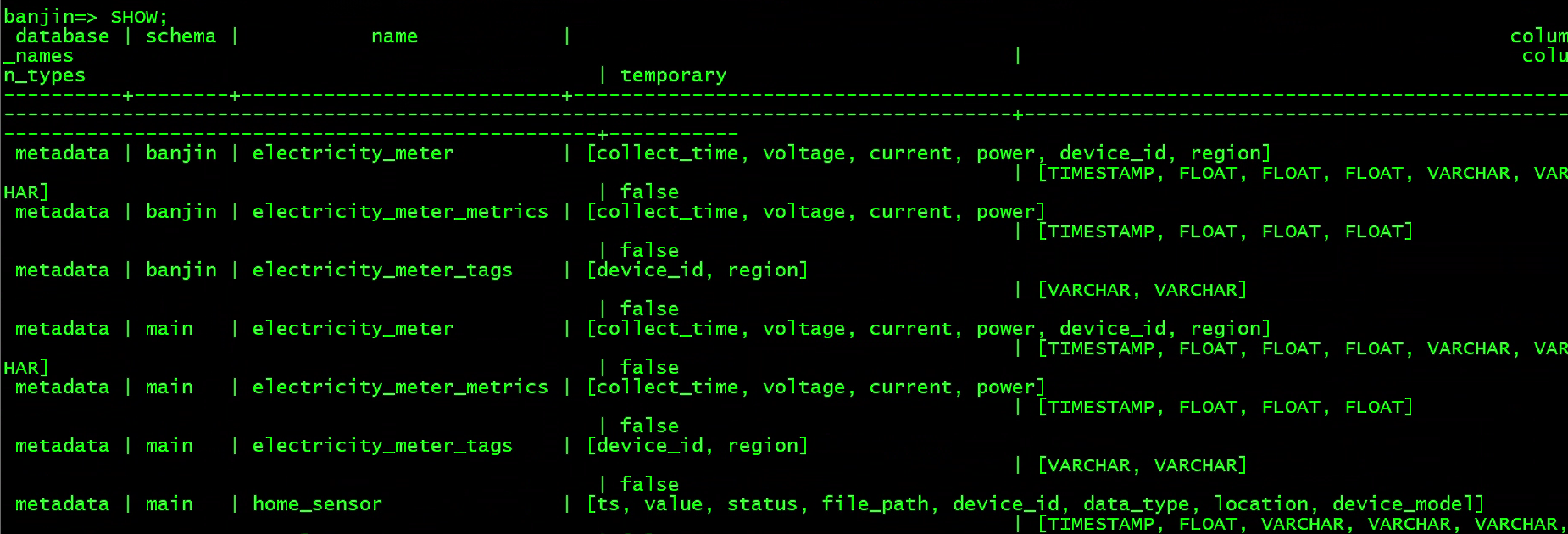
使用show来查看数据库详细信息
使用SHOW SCHEMAS 语句用于查看所有模式的信息
SHOW SCHEMAS;

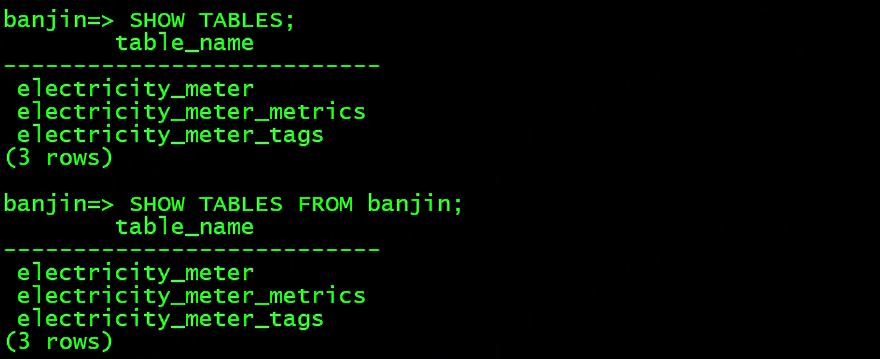
使用SHOW TABLES 语句用于查看当前或指定模式下的所有表。
SHOW TABLES;
SHOW TABLES FROM banjin;
六、核心功能体验:嵌入式部署使用
嵌入式部署是 KaiwuDB-Lite 轻量化使用的核心方式,无需独立启动数据库服务进程,可直接嵌入应用程序中运行,适配边缘设备、轻量级应用等场景
核心适用场景
| 场景类型 | 典型示例 | 核心优势 |
|---|---|---|
| 边缘计算设备 | 工业网关、智能电表、物联网传感器 | 低资源占用(内存 / CPU)、离线运行 |
| 轻量级单机应用 | 本地工具、桌面应用、小型后台程序 | 无需部署 / 维护数据库服务,集成简单 |
| 开发 / 测试 / 演示环境 | 本地功能验证、Demo 演示 | 一键初始化,无需复杂环境配置 |
| 小数据量时序 / 关系存储 | 本地日志分析、单机设备数据采集 | 本地文件存储,访问速度快 |
1、创建python虚拟环境。建议使用虚拟环境来隔离项目依赖
创建虚拟环境
python3 -m venv .venv
激活虚拟环境
source .venv/bin/activate

2、安装 KaiwuDB Lite Python 包
这里要确认好自己的python环境,安装对应的 kaiwudb_lite的whl文件
#进入whl安装包目录执行安装
pip install kaiwudb_lite-3.1.0-cp310-cp310-manylinux2014_x86_64.manylinux_2_17_x86_64.whl

3、安装python程序需要的处理库
根据需要安装数据处理库: pandas、 Polars、 PyArrow
pip install pandas polars pyarrow matplotlib flask
4、python程序准备
集成 KaiwuDB 数据库、多数据结构适配与 Web 可视化的一体化工具,将模拟电表时序数据(电压、电流、功率)存入 KaiwuDB 后,通过网页直观展示数据趋势图表与统计结果,无需手动操作即可完成 "数据生成 - 入库 - 可视化 - 网页展示" 全流程
import kaiwudb
import pandas as pd
import polars as pl
import pyarrow as pa
import matplotlib.pyplot as plt
import numpy as np
import io
import base64
from flask import Flask, render_template_string
===================== 初始化Web服务 =====================
app = Flask(name)
设置中文字体(避免图表中文乱码,适配网页展示)
plt.rcParams"font.family" = "SimHei", "WenQuanYi Micro Hei"
plt.rcParams"axes.unicode_minus" = False # 解决负号显示问题
===================== 核心工具函数 =====================
def plt_to_base64(fig):
"""将Matplotlib图表转换为Base64编码(可直接嵌入HTML)"""
buf = io.BytesIO()
fig.savefig(buf, format='png', dpi=300, bbox_inches='tight')
buf.seek(0)
img_base64 = base64.b64encode(buf.getvalue()).decode('utf-8')
buf.close()
return img_base64
def get_kaiwudb_data_and_plot():
"""从KaiwuDB获取数据并生成图表(Base64格式)"""
1. 连接KaiwuDB数据库
with kaiwudb.connect("electricity_meter.db") as con:
2. 删除已存在的表(如需重建)
con.sql("DROP TABLE IF EXISTS electricity_meter")
3. 创建KaiwuDB时序表(修复:补充TIMESERIES关键字,符合官网语法)
con.sql("""
CREATE TABLE electricity_meter (
collect_time TIMESTAMP NOT NULL, -- 时序核心字段(时间戳)
voltage FLOAT, -- 电压(V)
current FLOAT, -- 电流(A)
power FLOAT -- 功率(kW)
) TAGS (
device_id STRING NOT NULL, -- 设备ID(标签字段,非空)
region STRING -- 设备所属区域
);
""")
4. 生成模拟电表数据(三种数据结构)
---------------------- 4.1 Pandas DataFrame(meter_001,上海浦东) ----------------------
time_range_pd = pd.date_range(start="2024-05-01 08:00:00", periods=10, freq="5min")
voltage_pd = np.random.uniform(220, 230, size=10)
current_pd = np.random.uniform(5, 15, size=10)
pandas_df = pd.DataFrame({
"collect_time": time_range_pd,
"voltage": voltage_pd,
"current": current_pd,
"power": np.round(np.multiply(voltage_pd, current_pd) / 1000, 2), # 修复:功率与电压/电流匹配
"device_id": "meter_001",
"region": "华东-上海-浦东"
})
查询并展示pandas数据(验证数据结构)
print("=== Pandas DataFrame 数据预览 ===")
con.sql("SELECT * FROM pandas_df").show()
---------------------- 4.2 Polars DataFrame(meter_002,苏州工业园) ----------------------
time_range_pl = pd.date_range(start="2024-05-01 08:00:00", periods=10, freq="5min")
voltage_pl = np.random.uniform(218, 228, size=10)
current_pl = np.random.uniform(8, 18, size=10)
polars_df = pl.DataFrame({
"collect_time": time_range_pl,
"voltage": voltage_pl,
"current": current_pl,
"power": np.round(np.multiply(voltage_pl, current_pl) / 1000, 2), # 修复:功率与电压/电流匹配
"device_id": "meter_002",
"region": "华东-苏州-工业园区"
})
查询并展示polars数据
print("\n=== Polars DataFrame 数据预览 ===")
con.sql("SELECT * FROM polars_df").show()
---------------------- 4.3 PyArrow Table(meter_001,上海浦东补充数据) ----------------------
time_range_arrow = pa.array(pd.date_range(start="2024-05-01 08:50:00", periods=5, freq="5min"))
voltage_arrow = np.random.uniform(222, 232, size=5)
current_arrow = np.random.uniform(6, 16, size=5)
arrow_table = pa.Table.from_pydict({
"collect_time": time_range_arrow,
"voltage": pa.array(voltage_arrow),
"current": pa.array(current_arrow),
"power": pa.array(np.round(np.multiply(voltage_arrow, current_arrow) / 1000, 2)),
"device_id": pa.array("meter_001" * 5),
"region": pa.array("华东-上海-浦东" * 5)
})
查询并展示pyarrow数据
print("\n=== PyArrow Table 数据预览 ===")
con.sql("SELECT * FROM arrow_table").show()
5. 将不同数据结构插入KaiwuDB时序表
con.sql("INSERT INTO electricity_meter SELECT * FROM pandas_df")
con.sql("INSERT INTO electricity_meter SELECT * FROM polars_df")
con.sql("INSERT INTO electricity_meter SELECT * FROM arrow_table")
6. 查询表中所有数据并展示
print("\n=== 时序表 electricity_meter 全量数据 ===")
result = con.sql("SELECT * FROM electricity_meter ORDER BY collect_time, device_id")
result.show()
7. 转换查询结果为Pandas DataFrame(修复:时间字段转datetime)
df_plot = pd.DataFrame(result.fetchall(), columns=desc\[0 for desc in result.description])
df_plot"collect_time" = pd.to_datetime(df_plot"collect_time") # 关键:修复时间字段类型
8. 生成可视化图表
fig, (ax1, ax2, ax3) = plt.subplots(3, 1, figsize=(12, 10), sharex=True)
fig.suptitle("电表时序数据趋势图(KaiwuDB查询结果可视化)", fontsize=16, fontweight="bold")
8.1 电压趋势子图
for device_id in df_plot"device_id".unique():
df_device = df_plotdf_plot\["device_id" == device_id]
ax1.plot(df_device"collect_time", df_device"voltage",
marker="o", label=f"设备 {device_id}")
ax1.set_ylabel("电压 (V)", fontsize=12)
ax1.set_title("电压随时间变化趋势", fontsize=14)
ax1.grid(True, alpha=0.3)
ax1.legend()
8.2 电流趋势子图
for device_id in df_plot"device_id".unique():
df_device = df_plotdf_plot\["device_id" == device_id]
ax2.plot(df_device"collect_time", df_device"current",
marker="s", label=f"设备 {device_id}")
ax2.set_ylabel("电流 (A)", fontsize=12)
ax2.set_title("电流随时间变化趋势", fontsize=14)
ax2.grid(True, alpha=0.3)
ax2.legend()
8.3 功率趋势子图
for device_id in df_plot"device_id".unique():
df_device = df_plotdf_plot\["device_id" == device_id]
ax3.plot(df_device"collect_time", df_device"power",
marker="^", label=f"设备 {device_id}")
ax3.set_xlabel("采集时间", fontsize=12)
ax3.set_ylabel("功率 (kW)", fontsize=12)
ax3.set_title("功率随时间变化趋势", fontsize=14)
ax3.grid(True, alpha=0.3)
ax3.legend()
旋转x轴时间标签,避免重叠
plt.xticks(rotation=45)
plt.tight_layout()
9. 转换图表为Base64编码
img_base64 = plt_to_base64(fig)
plt.close(fig) # 释放资源
可选:游标查询验证
with kaiwudb.connect("electricity_meter.db") as con:
cur = con.cursor()
cur.execute("SELECT device_id, ROUND(AVG(power), 2) AS avg_power FROM electricity_meter GROUP BY device_id")
avg_power_data = {
"single": cur.fetchone(),
"all": cur.fetchall()
}
return img_base64, avg_power_data
===================== Web路由 =====================
@app.route('/')
def index():
获取图表Base64和平均功率数据
img_base64, avg_power_data = get_kaiwudb_data_and_plot()
网页模板(包含图表和数据)
html_template = """
<!DOCTYPE html>
<html lang="zh-CN">
<head>
<meta charset="UTF-8">
<title>KaiwuDB电表数据可视化</title>
<style>
body { font-family: Arial, SimHei; margin: 30px; }
h1 { color: #2c3e50; text-align: center; }
.chart-container { text-align: center; margin: 20px 0; }
.chart-img { max-width: 90%; height: auto; border: 1px solid #eee; padding: 10px; }
.data-section { margin: 30px auto; width: 80%; background: #f8f9fa; padding: 20px; border-radius: 8px; }
pre { font-size: 14px; line-height: 1.5; }
</style>
</head>
<body>
<h1>KaiwuDB电表时序数据可视化</h1>
<div class="chart-container">
<img src="data:image/png;base64,{{ img_base64 }}" class="chart-img" alt="电表数据趋势图">
</div>
<div class="data-section">
<h3>各设备平均功率(游标查询结果)</h3>
<pre>单条结果(第一个设备):{{ avg_power_data.single }}</pre>
<pre>剩余结果:{{ avg_power_data.all }}</pre>
</div>
</body>
</html>
"""
return render_template_string(html_template, img_base64=img_base64, avg_power_data=avg_power_data)
===================== 启动Web服务 =====================
if name == 'main':
安装Flask(如果未安装)
try:
import flask
except ImportError:
import subprocess
import sys
subprocess.check_call(sys.executable, "-m", "pip", "install", "flask")
print("=== 启动Web服务 ===")
print("✅ 请打开浏览器访问:http://127.0.0.1:5000")
print("⚠️ 停止服务请按 Ctrl+C")
app.run(host='192.168.150.132', port=5000, debug=False)
5、运行程序
python3 kwdb-lite-1.py

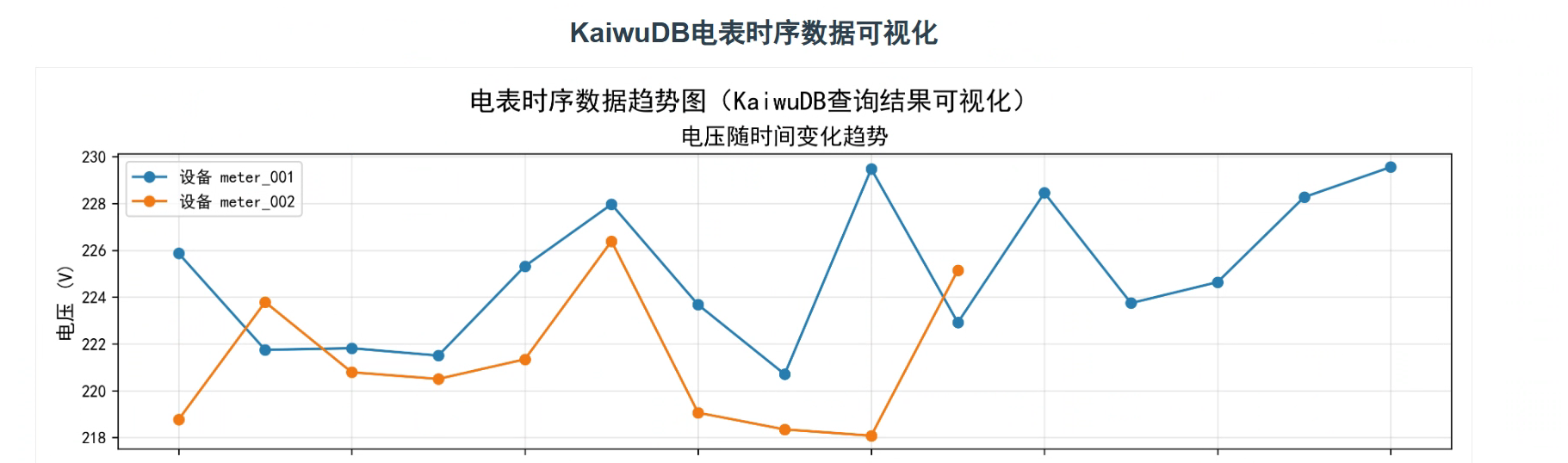
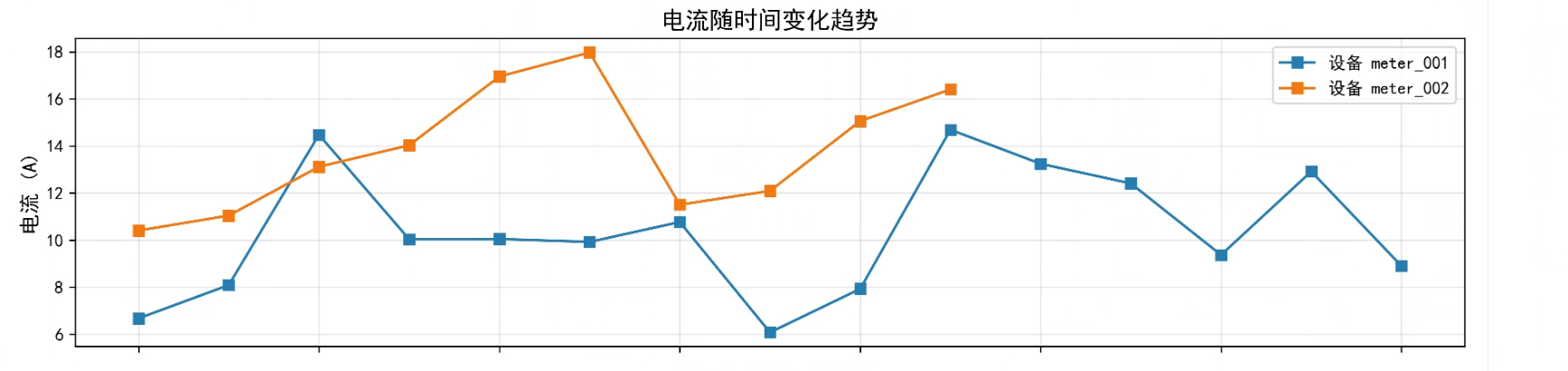
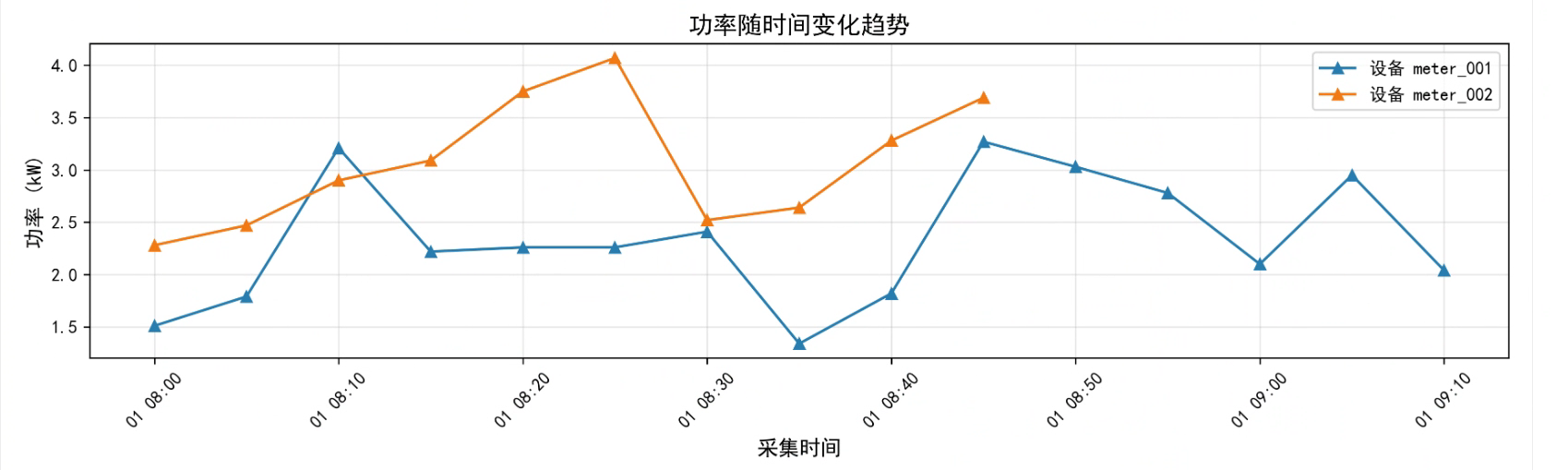
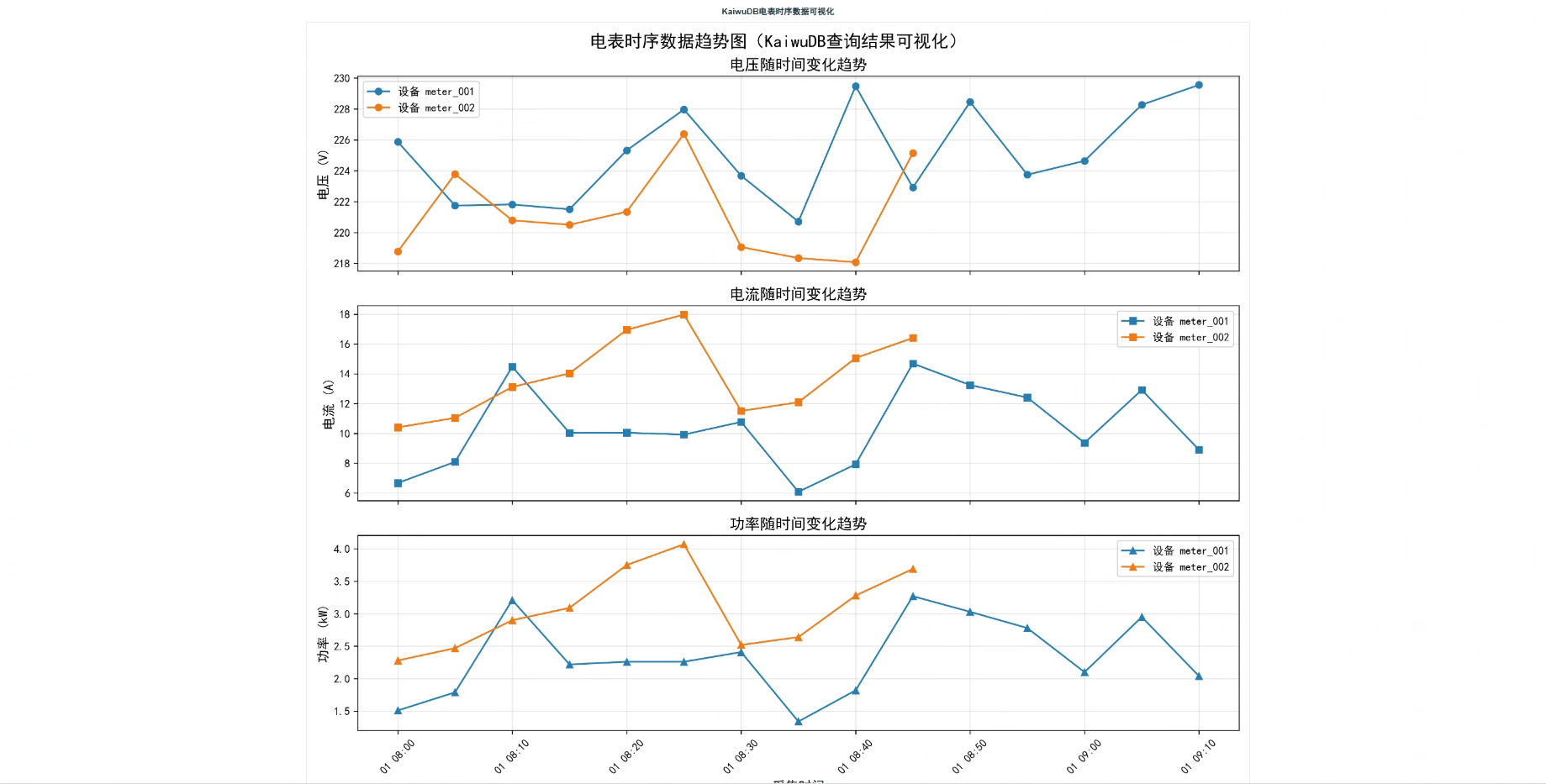
这里展示一下成果,在浏览器输入地址就可以看到生成的图表了,图表包含电压随时间变化趋势、电流随时间变化趋势、功率随时间变化趋势
电压随时间变化趋势
电流随时间变化趋势
功率随时间变化趋势
整体概览图:
至此整个体验就全部结束了
总结
KaiwuDB-Lite 是一款 "接地气" 的轻量级数据库,尤其适合想入门时序数据库、做小型项目测试的开发者。它没有复杂的配置和部署流程,性能在轻量场景下足够用,又能兼容标准 SQL,不用为了 "轻量化" 牺牲易用性。
如果你的需求是 "本地测试时序数据库""小型 IoT 数据存储""轻量级时序分析",KaiwuDB-Lite 值得一试 ------ 毕竟不用搭建复杂集群,5 分钟就能上手,资源占用还低,性价比拉满。