编者按: 当 AI 智能体给出的解决方案时好时坏,我们该如何突破这种不确定性的困境?
我们今天为大家带来的文章,作者的观点是:单一智能体的运行本质上是一次随机采样,而通过并行运行多个智能体并综合其输出结果,可以将编码任务从"靠运气抽签"转变为对最优解的系统性探索。
文章首先剖析了传统上下文工程的局限 ------ 尽管能提升输出的平均质量,却无法解决"探索问题":单次运行只能选择一条路径,可能错失更好的解决方案。作者提出的"并行收敛"(Parallel Convergence)方法论包含两个关键应用场景:为同一问题生成多个独立解决方案,以及从多个视角收集问题相关信息。通过让多个智能体从不同起点出发独立探索,当它们收敛到相同方案时,这种一致性本身就是解决方案可靠性的有力证明。
作者 | Ben Redmond
编译 | 岳扬
智能体编码(Agentic coding)存在一个问题 ------ 输出结果的不稳定性(variance)。如果单智能体的运行机制本身就在设计上限制了性能上限呢?
由于大语言模型具有随机性,每次智能体运行都会产生细微差异。即使上下文完全相同,某次运行可能恰好达到该任务在当前条件下理论上能达到的最佳表现(如同掷 20 面骰子得到 20 点),而另一次运行则可能落在收窄后的概率分布曲线中较中间的位置(比如只掷出了 10 点)。
在之前的文章中,我谈到了我对上下文工程的心智模型:上下文工程的目标是改变 LLM 输出结果的概率分布,这里的"概率分布"是指 LLM 所有可能输出结果的集合。
在这篇文章中,我将探讨如何扩展那个心智模型,来适应这样一个事实:我们现在能够轻松且(相对)低成本地触发并行智能体运行。
上下文工程的目标,远不止是降低概率分布的标准差并提高其平均质量 ------ 它还要确保能稳定地收敛到局部最优解。
01 上下文工程的局限性
运用上下文工程的最佳实践(提示词工程、引用相关文档、有针对性地添加相关工具与技能等)来改变概率分布,这解决了首要问题:降低糟糕结果的出现概率,并抬高下限 ------ 从而提升响应的平均质量。
但它未能解决探索问题(译者注:exploration problem,此处应当指如何在多个可行解中有效探索并找到最优或接近最优的那个,而不仅仅是依赖一次随机采样。)。即使在优化后的概率分布中,智能体仍有多条不同的路径来解决问题。其中一些路径尚可,有些则接近最优解,还有少数路径会让你想把脑袋砸向键盘。而单次智能体运行只会选择其中一条路径。你无法确定这次运行的结果是否达到了性能的"最高峰"(即最优解),还是仅仅刚好让你满意而已。
02 第二个心智模型
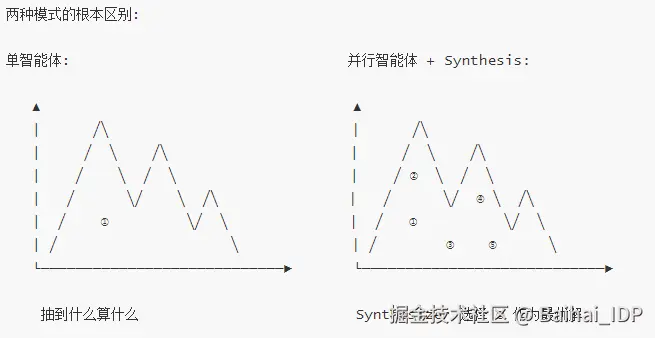
问题的解决方案就是并行智能体(以及大量 token)。
通过并行智能体,我们可以进行多次采样(即运行相同或相似的提示词多次),探索不同的"峰值(peaks)",利用多个并行运行的智能体,通过比较、整合或评估,逐步聚焦并确定出最优解。 这样一来,我们能分散风险,借助"集体智慧",持续从 LLM 中挖掘更深层的洞察。
这种方法为什么有效?我可不是在 Meta 拿着一亿美元年薪的 AI 研究员,所以没法给出权威答案 ------ 但我可以尽力推测:
多次采样:这是我反复强调的核心点。五个智能体等于五次独立采样,不再依赖单一路径和运气来寻找峰值。
单智能体的运行可能会满足于次优的解决方案 ------ 比如一个"能用但平庸"的局部最小值。它找到一个可行方案就停止探索了。而具有独立起点的并行智能体则能跳出这类陷阱,探索问题空间的不同区域,突破平庸的解决方案,找到更优方案。当多条探索路径都收敛到同一个高质量解决方案时,这种收敛模式本身就说明该解法很可能是局部最优的解决方案,甚至最优的解决方案。
不同起点:干净的上下文窗口意味着没有锚定偏差(anchoring bias)。每个智能体都从全新的视角出发进行探索。
重复验证:当两个智能体独立地提出相同方案时,我们就有理由相信该方案是一个局部最大值;而当所有智能体的结果都差别很大时,说明我们需要施加更多约束条件。
这种并行结构,把编码智能体从单次随机抽样,转变为对峰值的引导式搜索。
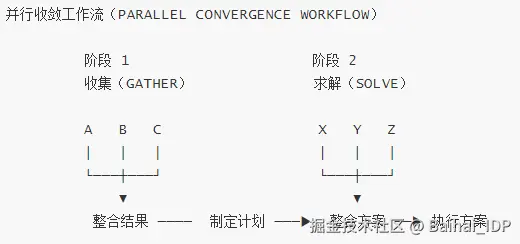
03 我是如何使用并行收敛(Parallel Convergence)的
我主要在以下两种方式/阶段中使用并行收敛,它们分别对应两类工作流:
1)为一个问题生成多个解决方案
2)从多个来源收集关于一个问题的信息
具体运作方式如下:
请注意,我主要使用 Claude Code,它通过编排器模式(orchestrator pattern)支持子智能体 ------ 即一个主智能体可以派生出多个子智能体,并在后续对它们的结果进行整合。
3.1 为一个问题生成多个解决方案
在此工作流中,我会使用多个智能体针对同一个问题提出不同的解决方案。其核心意图在于规避单一智能体可能给出次优方案的风险。
在启动子智能体时,Claude 可能会为它们分配不同的切入角度来处理问题,从而使主智能体能够探索更广阔的问题空间。
例如,如果我在调试一个这样的 bug(我们可能都遇到过):模态组件(modal)明明设置了 z-index: 9999 却仍被其他元素遮挡,Claude 可能会分别从数据流、React Hooks 和组件层级结构(component layering)等不同视角来分析问题。
随后,Claude 会综合、验证所有子智能体的输出,并提出最终方案。如果 5 个子智能体中有 3 个得出了相似的解决方案,那么这个解决方案很可能就是我们想要的,应当采纳并推进。
我最常在调试场景中使用这种方式,但在处理更复杂任务的规划阶段,它也同样有效。
3.2 从多个来源收集关于一个问题的信息
在我使用 Claude Code 时,设有一个专门的规划阶段,我会派发多个用于收集信息的子智能体。以下是我会使用到的一些智能体示例:
- Agent A:扫描 Git 提交历史(存在哪些重复模式?)
- Agent B:搜索本地文档(之前尝试过什么方案或踩过哪些坑?)
- Agent C:梳理代码调用路径或模块依赖关系(有哪些可用的接口、函数或服务?)
- Agent D:分析测试覆盖情况(已有哪些验证?)
- Agent E:识别约束条件,比如性能要求、兼容性限制、合规规则、部署环境等(边界在哪里?)
- Agent F:发现潜在风险(我们需要警惕什么?)
- Agent G:进行网络调研(官方文档、Stack Overflow、GitHub Issues 等外部资源怎么说?)
是的,七个智能体确实太多了。真的太多了!我不会一次性把这七个全放出来(那会乱成一团) ------ 但拥有这份完整的选项清单很重要。
每个子智能体都独立地进行探索。由于各自采用略微不同的视角来审视问题,因此每个都有机会发现关于该问题的不同信息。 这里的目标有所不同:在前一种场景中,我们派发多个智能体,是为了让它们各自提出针对同一个问题的不同解决方案;而在当前场景中,我们派发多个智能体,是为了让它们各自收集与该问题相关、但彼此不同且互为补充的信息片段。
在掌握上述信息(并且上下文已被充分"预热"或"激活")之后,Claude 就可以开始制定解决问题的具体计划了。(如果你想进一步利用并行性,也可以在规划阶段使用并行智能体。)
04 收敛的具体表现
(译者注:这里的 "convergence"(收敛)应当是指,多个独立运行的智能体(agents)从不同角度探索同一个问题后,不约而同地指向同一个或非常相似的解决方案。)
以下是我正在进行的一个"AI hedge fund"项目中,关于模型评估的一个例子。
问题在于:这个 AI 能够清晰、详细地描述各种可能的失败模式(这是优点),但同时却声称自己实现了高到连文艺复兴科技公司(Renaissance Technologies)都会嫉妒的夏普比率(Sharpe ratio)(这是严重问题)。它的输出看起来像一份专业机构级别的风险文档,但却缺乏对"现实收益预期"的合理校准。我需要更新提示词来解决这一问题。
我启动了 4 个并行的信息收集智能体:
- Agent A(情报收集者) :找到了那些在 Git 提交中"为边缘评分(edge scoring)引入校准逻辑"的历史任务。
- Agent B(代码库模式提取者) :在代码库中发现了相同的"边缘评分校准"模式,并指出该模式"被证明有效"。
- Agent C(Git 历史分析者) :找到了完全一致的提交历史,并描述了在 7 周内发生的 3 轮"校准改进浪潮"。
- Agent D(网络研究员) :找到了 Ken French 数据库 和 AQR 资产管理公司的研究成果,其中提供了真实的因子溢价数据(动量因子:年化 5--8%,质量因子:2--4%)
这四个智能体,分别从完全不同的角度(任务模式数据库(pattern database,过去类似任务怎么做)、代码库分析、Git 历史、网络调研)出发,最终收敛到同一个解决方案:使用现有的"Anti-Patterns"章节格式(译者注:指文档中专门列出"常见错误做法 + 正确替代方案"的部分。),并基于历史因子收益数据,增加校准指引。
更妙的是,Agent A 最初建议新增一个 60 行的独立章节。但当 Claude 整合所有信息后,收敛模式(convergence pattern)揭示了一条更简洁的路径 ------ 只需在现有的 "Anti-Patterns" 章节中增加 5 行内容,就能在不引起上下文膨胀的前提下达到相同目标。
Claude 到底是怎么进行整合的?老实说,我并不能直接控制这一过程 ------ 这是 Claude Code 编排器模式的一部分。但我能观察到它的行为模式:它高度重视多个智能体之间的一致意见,同时也会指出那些值得考虑的异常情况,并且更为关键的是,当多个结果收敛到一个简单方案时,它倾向于选择更简洁的解决方案(尤其是在我额外通过提示词强调"追求简洁"的情况下)。正是通过这种方式,一个原本 60 行的修改建议最终被精简成了 5 行。
这次"收敛"(convergence)让我确认了两件事:
1)这个解决方案是经过验证的 ------ 因为 4 次彼此独立的探索(来自不同角度、不同数据源)
2)最简版本就已经足够有效 ------ 不需要复杂或冗长的实现,那个精简的方案(比如只加 5 行)就能达成目标。
成本大约是:10 分钟的并行智能体运行时间,总计消耗约 20 万 token。我的 Claude Code 使用额度在"哭泣",但收获是一个高置信度的解决方案 ------ 它有多个独立来源的证据支撑,并且保持了简洁。
如果你觉得为一个 5 行的改动而这样做有点过于"兴师动众",我只能说确实如此!但这恰恰就是重点。
即使是仅仅修改大约 5 行的提示词,也值得将这 5 行内容建立在过去团队的决策经验、外部权威的网络资料和多个智能体达成的共识的基础之上。
05 何时不应使用此方法
多智能体方法并非没有缺点:
- Token 消耗
- 主智能体因额外信息导致上下文膨胀
- 等待智能体运行所耗费的时间
对于定义明确的任务、简单的修改或容易解决的 bug,单智能体通常已足够。而在其他情况下,我才会开始考虑使用并行工作流。
06 从随机游走到定向收敛

之前的文章提出的模型是:更好的上下文工程 → 带来更优的概率分布 → 从而产生更好的平均结果。
而本文这个模型(即引入并行智能体后的增强版方法),优化路径是这样的:更好的上下文 → 塑造出更优的概率分布 → 在此基础上进行并行探索(parallel exploration) → 通过多个智能体输出的收敛情况来验证方案的可靠性 → 从而稳定、可靠地获得最优结果。
总结而言:上下文工程塑造了正确的概率分布,而并行收敛(Parallel convergence)则从中定位峰值。
END
本期互动内容 🍻
❓您是否认为文章中提到的并行智能体方法是未来趋势?在您看来,接下来的技术进步会如何进一步提升智能体系统的效率和准确性?
原文链接: