在嵌入式 AI 开发领域(尤其是 RK3588 这种边缘计算平台),我们常常面临一个"两难"的选择:
用 Python 开发: 拥有丰富的生态(Numpy, PyTorch, OpenCV),代码简洁,逻辑调整极快。但受限于 GIL(全局解释器锁)和解释执行,做多路视频解码和高并发处理时,性能往往捉襟见肘,CPU 瞬间飙升。
用 C++ 开发: 性能极致,可以直接调用底层硬件加速(MPP, RGA, NPU)。但开发门槛高,业务逻辑修改繁琐,调试周期长,"写代码一小时,调试一整天"。
有没有一种方案,能同时拥有 C++ 的性能和 Python 的效率?答案是肯定的。最近,我基于 Pybind11 开发了一套 RK3588 的全流程视频分析服务,将底层的硬件解码、推理、推流全部封装在 C++ 中,而将检测结果和业务逻辑暴露给 Python。今天,就带大家看看这套架构在8路并发压力下的真实表现!
1、架构设计:重活给 C++,逻辑给 Python
这套系统的核心理念是 "计算与逻辑分离"。
-
底层 (C++ Core):
-
硬件解码 :直接调用 RK3588 的 MPP,避开 OpenCV 软解的 CPU 消耗。
-
并发管理:使用 C++ 线程池管理多路 RTSP 拉流和推流,彻底绕开 Python 的 GIL 锁限制。
-
NPU 推理:集成 RKNN Runtime,实现高效模型前向传播。
-
数据流转:通过共享内存机制,减少数据搬运。
-
-
中间层 (Pybind11):
- 作为"胶水",将 C++ 的复杂对象映射为 Python 对象。
-
上层 (Python API):
-
开发者只需要关注:拿到检测结果(Box, ID, Score)后怎么处理?是报警?是统计?还是存库?
-
代码量极简,开发体验与原生 Python 无异。
-
2、极限压测:8路并发,CPU 稳如泰山
为了验证这套封装的含金量,我进行了一次阶梯式的压力测试。测试内容包括:RTSP 拉流 -> MPP 硬件解码 -> 结果处理 -> RTSP 推流。
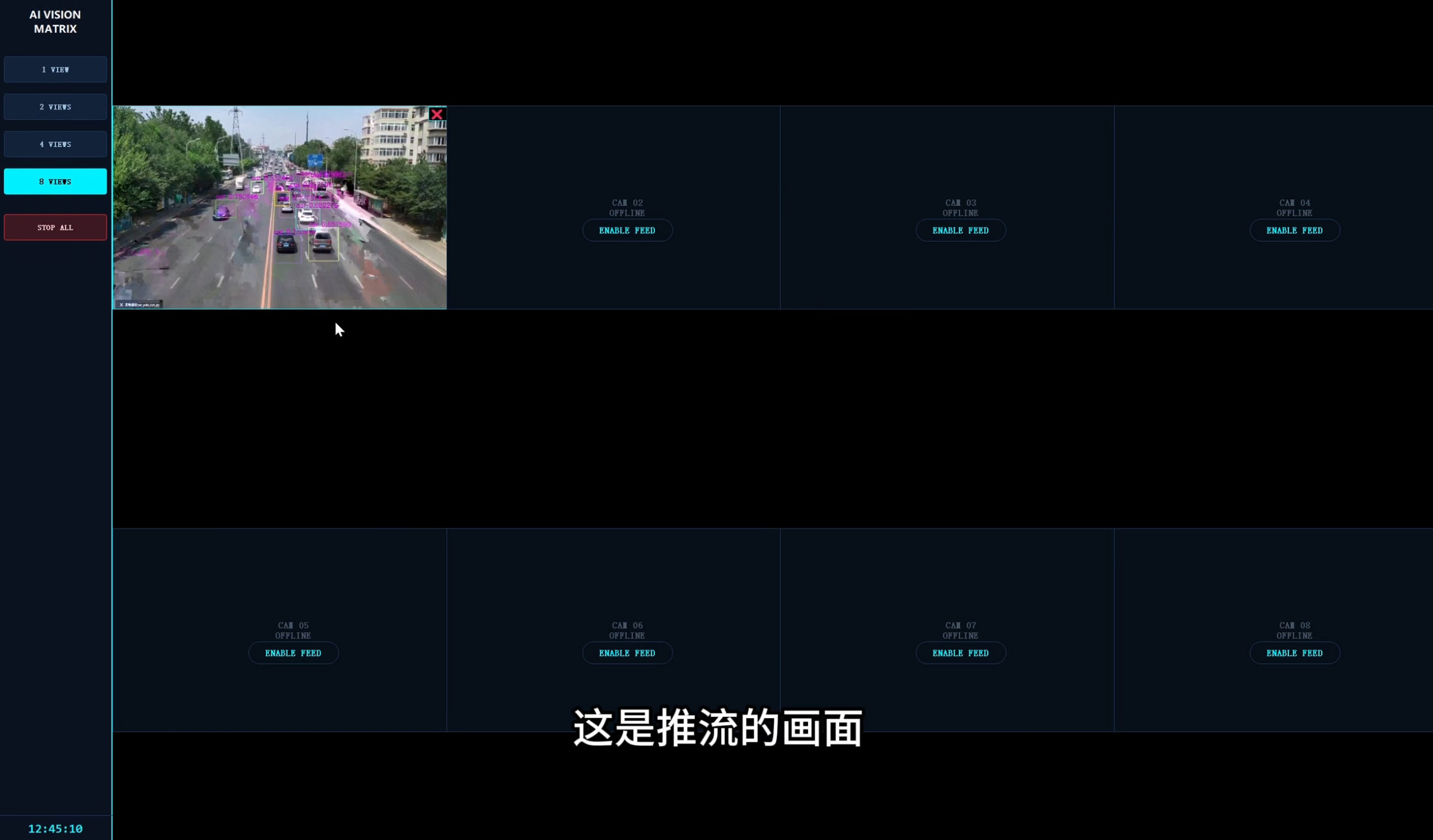
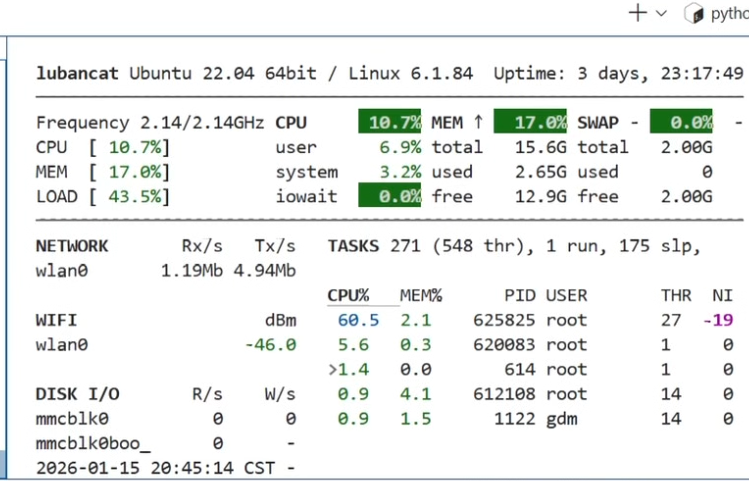
1. 单路测试
启动 1 路 1080P 视频流。
CPU 负载:~10%
2. 四路并发
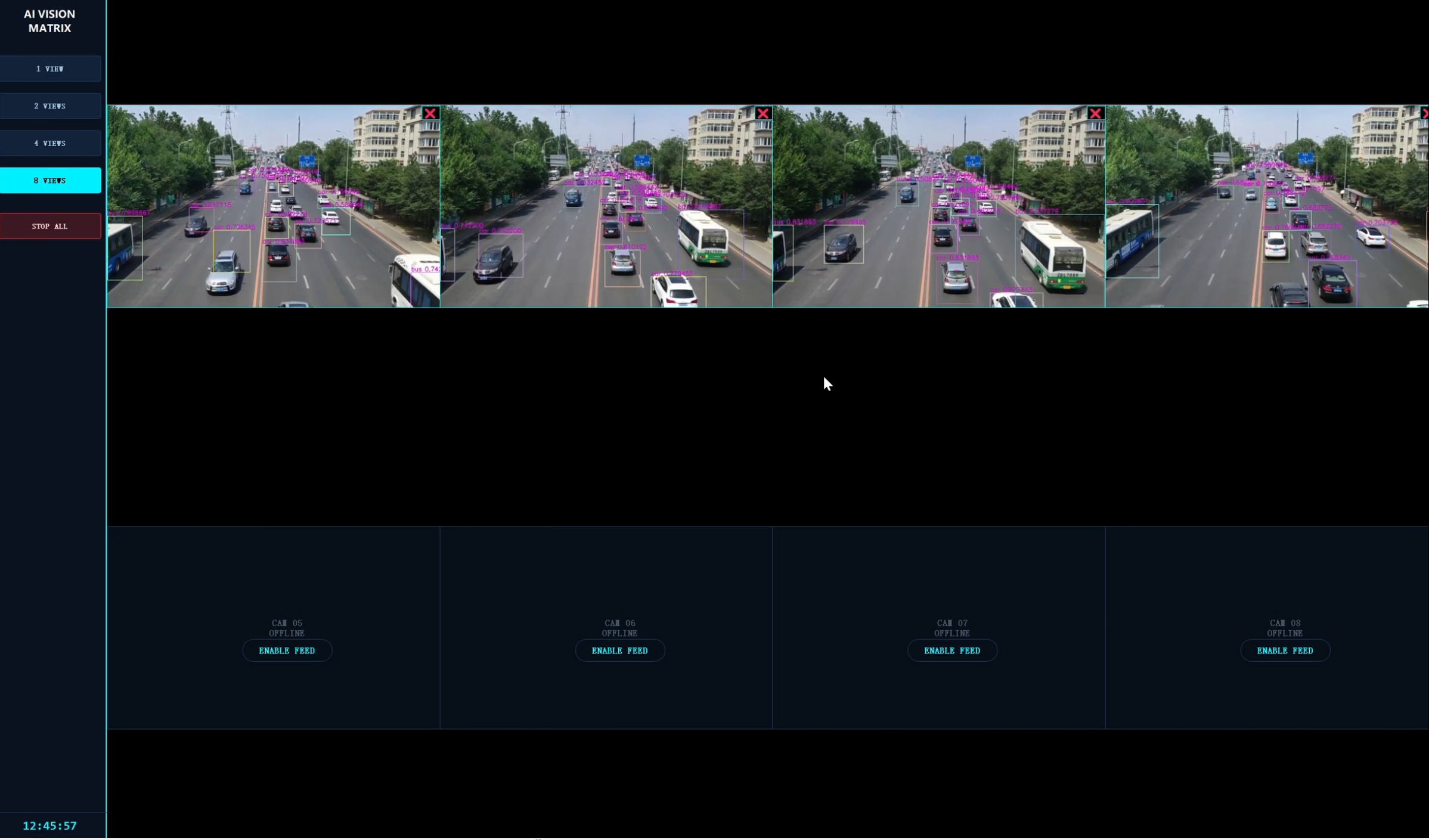
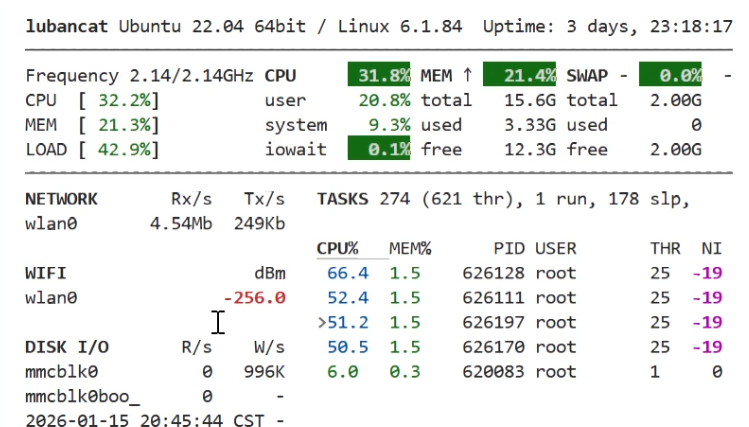
同时启动 4 路视频流,模拟常见的小型监控场景。
CPU 负载:~35%
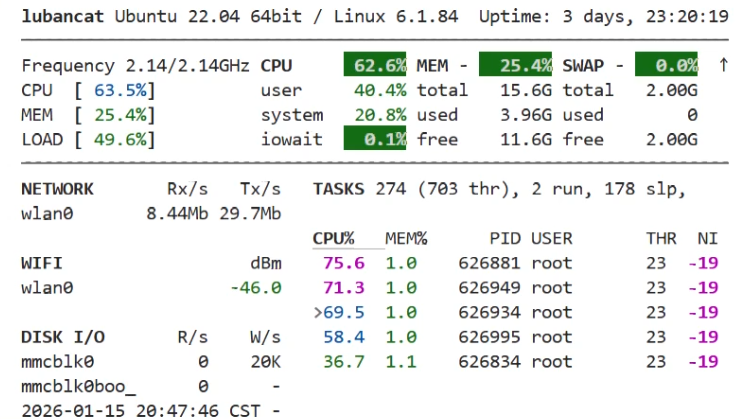
3. 八路并发
直接拉满 8 路视频流!这是很多纯 Python 方案的"死穴",通常会导致卡顿、花屏甚至程序崩溃。
CPU 负载:~60

3、总结
通过 Pybind11 将 RK3588 的硬件能力"压榨"出来,并以优雅的方式暴露给 Python,我们实现了一个高并发、低延迟、易扩展的边缘计算服务框架。关注我,带你玩转 RK3588 硬核开发!