📋 目录
时序数据库概述
什么是时序数据库?

时序数据库(Time Series Database,TSDB)是专门用于存储、管理和分析带时间戳数据的数据库系统。随着物联网、工业 4.0、智能制造等领域的快速发展,时序数据呈现爆发式增长,传统关系型数据库已难以满足海量时序数据的存储和查询需求。
时序数据的核心特征
| 特征维度 | 时序数据 | 传统关系型数据 |
|---|---|---|
| 写入模式 | 高频追加写入,极少更新删除 | 增删改查均衡 |
| 查询模式 | 时间范围查询、聚合分析为主 | 点查询、关联查询为主 |
| 数据价值 | 近期数据价值高,历史数据可降采样 | 所有数据价值相对均衡 |
| 索引策略 | 时间为主索引,设备/标签为辅助索引 | 多字段灵活索引 |
| 存储需求 | 海量存储,高压缩比 | 中等规模,强调一致性 |
| 扩展方式 | 水平扩展为主 | 垂直扩展或分库分表 |
技术发展趋势
第一代
2010-
基于通用数据库改造
OpenTSDB/HBase
第二代
2015-
专用时序存储引擎
InfluxDB/TSM
第三代
2018-
云原生分布式
TimescaleDB/PostgreSQL
第四代
2022-
边云协同+AI增强
Apache IoTDB/TsFile
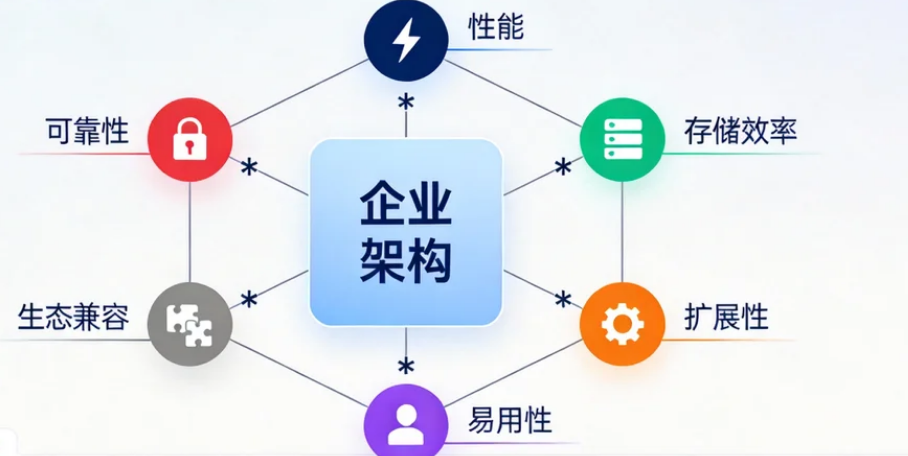
选型核心维度
评估维度矩阵
选型决策流程
是
否
是
否
是
否
开始时序数据库选型
数据规模评估
日增量 > 10亿条?
需要分布式架构
集群部署能力
单机版可满足
考虑轻量级方案
是否有边缘计算
场景需求?
IoTDB 边云协同
IoTDB 集群版
Apache IoTDB 单机版
是否需要企业级
技术支持?
天谋科技 TimechoDB
企业版
timecho.com
Apache IoTDB
开源社区版
选型完成
Apache IoTDB 深度解析
项目背景
Apache IoTDB(Internet of Things Database)是由清华大学自主研发、捐献给 Apache 软件基金会的顶级开源项目。它是一款专为物联网时序数据设计的高性能数据库管理系统,具有完全自主可控的核心技术。
发展历程:
| 时间 | 里程碑 |
|---|---|
| 2011 | 清华大学开始研发 |
| 2018 | 进入 Apache 孵化器 |
| 2020 | 毕业成为 Apache 顶级项目 |
| 2022 | 发布 1.0 正式版 |
| 2023 | 发布 1.3 版本,支持双表模型 |
核心架构
共识与分布式层
Raft 共识
数据分片
负载均衡/故障转移
存储引擎层
TsFile 列式存储
压缩编码
10x+ 压缩
时间分区/设备分区
数据生命周期管理
查询引擎层
SQL 解析器
查询优化器
UDF/触发器/流计算引擎
客户端接入层
JDBC Driver
MQTT Protocol
REST API
InfluxDB Line Protocol
Thrift RPC
核心技术优势
1. 高性能写入与查询
Apache IoTDB 采用自研的 TsFile 列式存储格式,结合时序数据特征优化的编码压缩算法,实现了卓越的读写性能:
| 性能指标 | Apache IoTDB | 行业平均水平 |
|---|---|---|
| 单机写入吞吐 | 千万级点/秒 | 百万级点/秒 |
| 压缩比 | 10:1 ~ 100:1 | 5:1 ~ 20:1 |
| 原始数据查询 | 毫秒级响应 | 秒级响应 |
| 聚合查询 | 亚秒级 | 数秒 |
2. 树形时序数据模型
IoTDB 独创的树形元数据模型,完美契合物联网设备的层级结构:
root
ln 电网
wf 风电
sg 智能电网
wf01
wf02
d1
d2
p1
p2
status
temp
speed
power
voltage
current
优势体现:
- 设备关系一目了然
- 支持通配符批量查询
- 元数据管理简洁高效
- 权限控制粒度灵活
3. 丰富的编码压缩算法
| 编码类型 | 适用数据类型 | 压缩原理 | 典型压缩比 |
|---|---|---|---|
| PLAIN | 所有类型 | 无编码,直接存储 | 1:1 |
| TS_2DIFF | INT32/INT64 | 二阶差分编码 | 5:1 ~ 10:1 |
| RLE | INT32/FLOAT | 游程编码 | 10:1 ~ 50:1 |
| GORILLA | FLOAT/DOUBLE | Facebook Gorilla 算法 | 8:1 ~ 15:1 |
| DICTIONARY | TEXT | 字典编码 | 5:1 ~ 20:1 |
| CHIMP | FLOAT/DOUBLE | CHIMP 压缩算法 | 10:1 ~ 20:1 |
4. 边云协同架构
设备层
传感器
PLC
网关
仪表
控制器
边缘层
边缘节点 1
IoTDB-Edge
本地存储
边缘节点 2
IoTDB-Edge
本地缓存
边缘节点 N
IoTDB-Edge
实时分析
云端集群
Node 1
Node 2
Node 3
Node N
数据汇聚/全局分析
与国际主流产品对比
综合能力对比
| 能力维度 | Apache IoTDB | InfluxDB | TimescaleDB | OpenTSDB |
|---|---|---|---|---|
| 开源协议 | Apache 2.0 | MIT (部分闭源) | Apache 2.0 | LGPL |
| 核心技术自主 | ✅ 完全自主 | ❌ 美国公司 | ❌ 基于 PostgreSQL | ❌ 基于 HBase |
| 写入性能 | ⭐⭐⭐⭐⭐ | ⭐⭐⭐⭐ | ⭐⭐⭐ | ⭐⭐⭐ |
| 存储压缩 | ⭐⭐⭐⭐⭐ | ⭐⭐⭐⭐ | ⭐⭐⭐ | ⭐⭐ |
| 边缘部署 | ✅ 原生支持 | ⚠️ 受限 | ❌ 不支持 | ❌ 不支持 |
| 集群能力 | ✅ 开源免费 | ⚠️ 企业版收费 | ⚠️ 企业版收费 | ✅ 依赖 HBase |
| SQL 兼容 | ✅ 类 SQL | ⚠️ InfluxQL/Flux | ✅ 完整 SQL | ❌ HTTP API |
| 本土化支持 | ✅ 原厂支持 | ❌ 海外支持 | ❌ 海外支持 | ❌ 社区支持 |
性能基准测试对比
写入性能对比 (百万数据点/秒) IoTDB InfluxDB TimescaleDB OpenTSDB 14 12 10 8 6 4 2 0 写入性能
存储压缩比对比 IoTDB InfluxDB TimescaleDB OpenTSDB 20 18 16 14 12 10 8 6 4 2 0 压缩比
技术架构深度对比
InfluxDB 对比
| 对比项 | Apache IoTDB | InfluxDB |
|---|---|---|
| 集群版本 | 开源免费 | 仅企业版(收费) |
| 查询语言 | 类 SQL,学习成本低 | InfluxQL/Flux,需要额外学习 |
| 边缘部署 | 原生支持,资源占用极低 | 受限,内存要求较高 |
| 高基数支持 | 优秀 | 存在性能瓶颈 |
| 国产化 | 完全自主可控 | 美国公司产品 |
TimescaleDB 对比
| 对比项 | Apache IoTDB | TimescaleDB |
|---|---|---|
| 底层架构 | 原生时序存储 | PostgreSQL 扩展 |
| 写入性能 | 千万级/秒 | 百万级/秒 |
| 压缩效率 | 10:1 ~ 100:1 | 5:1 ~ 10:1 |
| 部署复杂度 | 开箱即用 | 需要 PostgreSQL 知识 |
| 边缘场景 | 轻量级,支持边缘 | 资源需求较高 |
完整开发指南
环境准备
系统要求
| 组件 | 最低要求 | 推荐配置 |
|---|---|---|
| 操作系统 | Linux/Windows/macOS | Linux (CentOS 7+/Ubuntu 18.04+) |
| JDK | JDK 8+ | JDK 11 或 JDK 17 |
| 内存 | 2 GB | 8 GB+ |
| 磁盘 | 10 GB | SSD 100GB+ |
| CPU | 2 核 | 8 核+ |
下载与安装
官方下载地址 :https://iotdb.apache.org/zh/Download/
bash
# 1. 下载最新版本
wget https://downloads.apache.org/iotdb/1.3.0/apache-iotdb-1.3.0-all-bin.zip
# 2. 解压
unzip apache-iotdb-1.3.0-all-bin.zip
cd apache-iotdb-1.3.0-all-bin
# 3. 启动服务 (Linux/macOS)
./sbin/start-standalone.sh
# 4. 验证启动状态
./sbin/start-cli.sh -h 127.0.0.1 -p 6667 -u root -pw rootSQL 操作详解
数据库与时间序列管理
sql
-- 创建数据库
CREATE DATABASE root.factory;
CREATE DATABASE root.power_plant;
-- 创建单个时间序列
CREATE TIMESERIES root.factory.workshop1.device1.temperature
WITH DATATYPE=FLOAT,
ENCODING=GORILLA,
COMPRESSOR=SNAPPY;
CREATE TIMESERIES root.factory.workshop1.device1.humidity
WITH DATATYPE=FLOAT,
ENCODING=GORILLA;
-- 创建对齐时间序列 (同一设备的多个测点对齐存储,提高查询效率)
CREATE ALIGNED TIMESERIES root.factory.workshop2.device1(
temperature FLOAT encoding=GORILLA compressor=SNAPPY,
humidity FLOAT encoding=GORILLA compressor=SNAPPY,
pressure FLOAT encoding=GORILLA compressor=SNAPPY,
status BOOLEAN encoding=RLE compressor=SNAPPY
);
-- 查看时间序列
SHOW TIMESERIES root.factory.**;
-- 统计时间序列数量
COUNT TIMESERIES root.**;数据写入操作
sql
-- 单条写入
INSERT INTO root.factory.workshop1.device1(timestamp, temperature, humidity, status)
VALUES (1704067200000, 25.5, 60.2, true);
-- 多条写入 (同一设备)
INSERT INTO root.factory.workshop1.device1(timestamp, temperature, humidity, status)
VALUES
(1704067201000, 25.6, 60.1, true),
(1704067202000, 25.7, 60.0, true),
(1704067203000, 25.8, 59.9, true);
-- 使用当前时间戳
INSERT INTO root.factory.workshop1.device1(timestamp, temperature, humidity, status)
VALUES (NOW(), 25.5, 60.0, true);数据查询操作
sql
-- 查询所有数据
SELECT * FROM root.factory.workshop1.device1;
-- 时间范围查询
SELECT temperature, humidity
FROM root.factory.workshop1.device1
WHERE time >= 2024-01-01T00:00:00 AND time < 2024-01-02T00:00:00;
-- 条件过滤
SELECT * FROM root.factory.workshop1.device1
WHERE temperature > 26.0;
-- 查询最新值
SELECT LAST * FROM root.factory.workshop1.device1;
-- 基础聚合函数
SELECT
COUNT(temperature) as count,
AVG(temperature) as avg_temp,
MAX_VALUE(temperature) as max_temp,
MIN_VALUE(temperature) as min_temp
FROM root.factory.workshop1.device1;
-- 按时间窗口分组 (每小时平均值)
SELECT AVG(temperature) as avg_temp
FROM root.factory.workshop1.device1
GROUP BY ([2024-01-01T00:00:00, 2024-01-02T00:00:00), 1h);生产环境最佳实践
集群部署架构
存储层
本地 SSD
热数据
分布式存储
温数据
对象存储
冷数据
DataNode 集群
DataNode-1
Region-1/Region-3
DataNode-2
Region-2/Region-1
DataNode-3
Region-1/Region-2
数据存储/查询执行
ConfigNode 集群
ConfigNode-1
Leader
ConfigNode-2
Follower
ConfigNode-3
Follower
元数据管理/集群协调/Raft 共识
负载均衡层
Nginx / HAProxy / 云 LB
配置优化建议
内存配置
properties
# conf/iotdb-datanode.properties
# 堆内存配置 (建议物理内存的 50%-70%)
# 在 conf/datanode-env.sh 中设置
# HEAP_NEWSIZE="8G"
# MAX_HEAP_SIZE="16G"
# 写入缓冲区大小
write_memory_proportion=0.4
# 查询内存比例
query_memory_proportion=0.3
# Schema 缓存大小
schema_memory_proportion=0.1性能调优
properties
# 并发写入线程数
concurrent_writing_time_partition=4
# 刷盘策略
flush_wal_period=100
flush_wal_threshold=10000
# 查询线程数
query_thread_count=16
# 批量大小
batch_size=100000数据生命周期管理
sql
-- 设置数据过期时间 (TTL)
SET TTL TO root.factory.** 31536000000; -- 1 年
SET TTL TO root.logs.** 2592000000; -- 30 天
-- 查看 TTL 设置
SHOW ALL TTL;
-- 取消 TTL
UNSET TTL TO root.factory.**;监控与告警
yaml
# Prometheus 监控配置
# prometheus.yml
scrape_configs:
- job_name: 'iotdb'
static_configs:
- targets: ['iotdb-node1:9091', 'iotdb-node2:9091', 'iotdb-node3:9091']
metrics_path: '/metrics'
# 关键监控指标
# - iotdb_write_point_count: 写入数据点数
# - iotdb_query_latency: 查询延迟
# - iotdb_memory_usage: 内存使用率
# - iotdb_disk_usage: 磁盘使用率总结与资源
核心结论
在时序数据库选型中,Apache IoTDB 凭借以下优势脱颖而出:
| 优势维度 | 具体表现 |
|---|---|
| 性能卓越 | 写入千万级点/秒,查询毫秒级响应 |
| 存储高效 | 10:1 ~ 100:1 极致压缩比 |
| 架构先进 | 唯一支持端-边-云全场景部署 |
| 自主可控 | 清华自研,Apache 顶级项目 |
| 生态完善 | 多协议支持,开箱即用 |
| 服务保障 | 活跃社区 + 天谋企业支持 |
推荐行动
快速验证
下载社区版
POC 测试
深入评估
性能基准测试
IoT-Benchmark
生产部署
选择单机版
或集群版
企业支持
联系天谋科技
获取商业支持
版本选择指南
| 场景 | 推荐版本 | 说明 |
|---|---|---|
| 开发测试 | 社区版单机 | 快速上手,零成本 |
| 中小规模生产 | 社区版单机/集群 | 开源免费,社区支持 |
| 大规模生产 | 企业版 TimechoDB | 专业支持,增强功能 |
| 关键业务 | 企业版 + 专属支持 | 7x24 保障,定制服务 |
资源链接
- 下载地址 :https://iotdb.apache.org/zh/Download/
- 企业版官网 :https://timecho.com
- 官方文档 :https://iotdb.apache.org/zh/UserGuide/
- GitHub :https://github.com/apache/iotdb
- 性能测试工具 :https://github.com/apache/iotdb-benchmark