目录
[1. 集群硬件现状与优化策略](#1. 集群硬件现状与优化策略)
[2. 操作系统级优化 (Linux Base)](#2. 操作系统级优化 (Linux Base))
[2.1 基础监控工具安装](#2.1 基础监控工具安装)
[2.2 核心内核参数调整 (所有节点)](#2.2 核心内核参数调整 (所有节点))
[3. HDFS 存储层优化](#3. HDFS 存储层优化)
[3.1 开启机架感知 (Rack Awareness) 或 磁盘平衡](#3.1 开启机架感知 (Rack Awareness) 或 磁盘平衡)
[3.2 优化 DataNode 内存 (Heap Size)](#3.2 优化 DataNode 内存 (Heap Size))
[4. YARN 资源调度优化 (核心难点)](#4. YARN 资源调度优化 (核心难点))
[4.1 创建角色组 (Role Group)](#4.1 创建角色组 (Role Group))
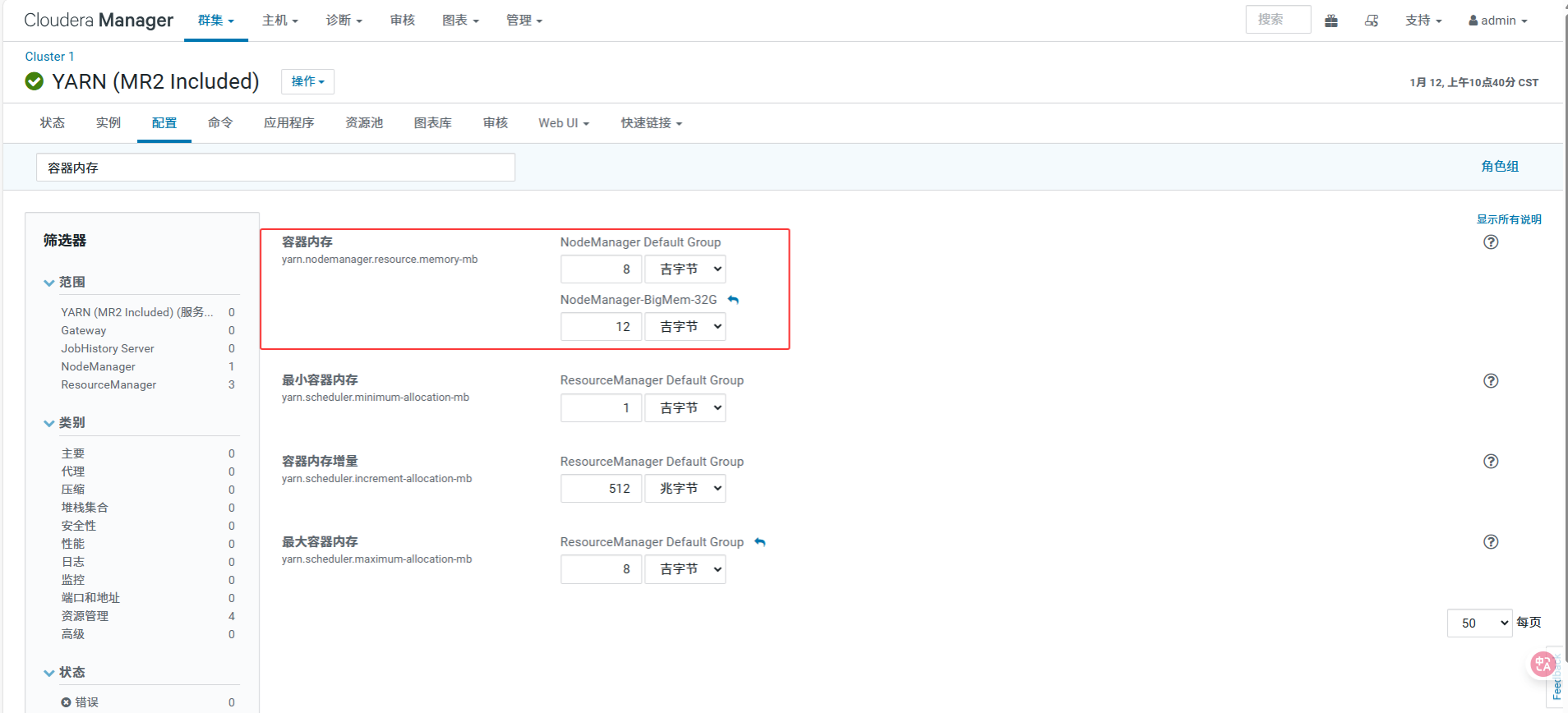
[4.2 配置内存参数 (yarn.nodemanager.resource.memory-mb)](#4.2 配置内存参数 (yarn.nodemanager.resource.memory-mb))
**背景:**现有 CDH 集群部署文档普遍脱离实际硬件规格,各组件参数几乎全部采用出厂默认值,亟需针对 HDFS、Yarn、Hive 等核心服务进行差异化调优。
1. 集群硬件现状与优化策略
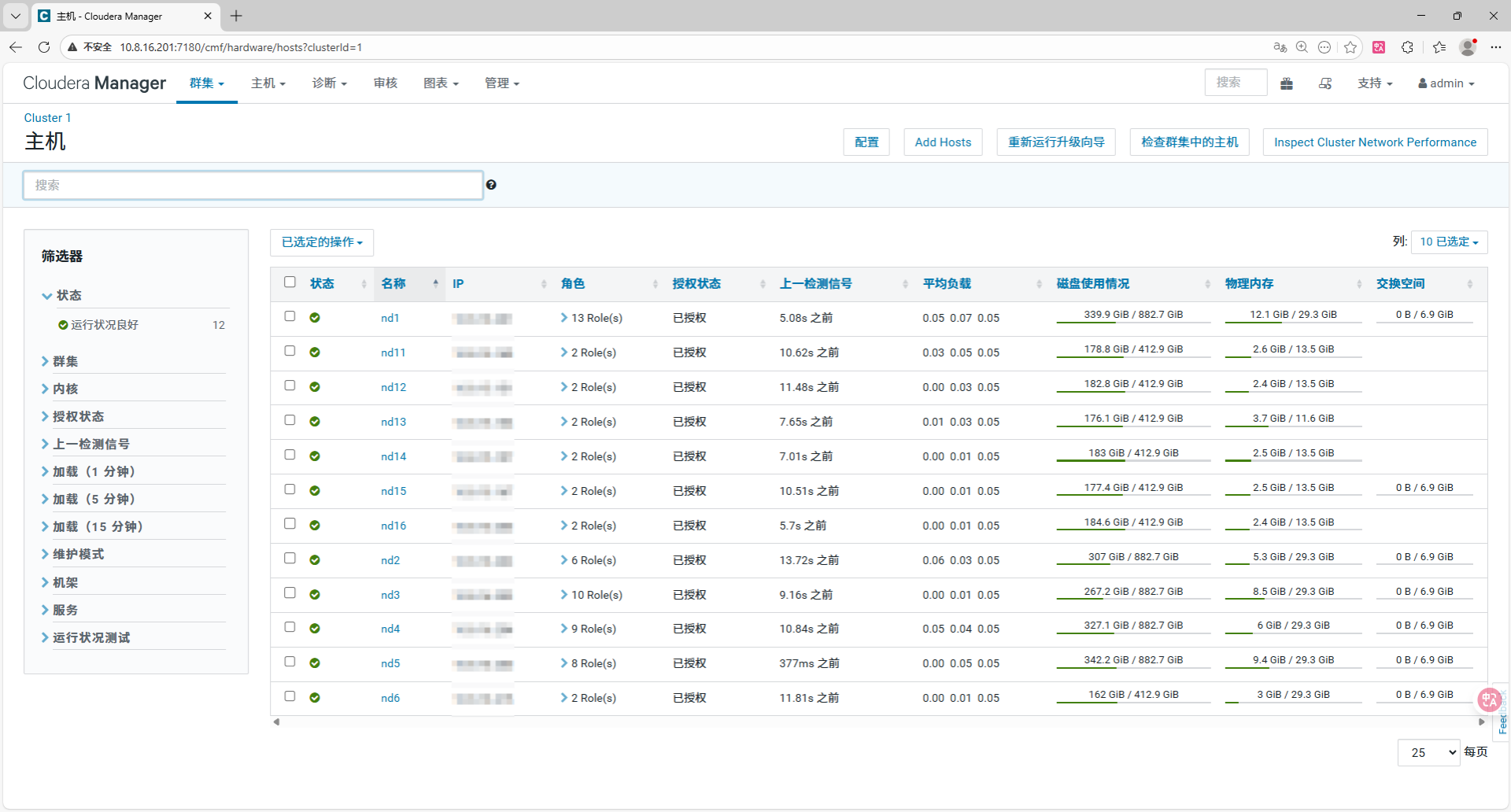
现集群属于典型的异构集群(机器配置不统一),最大的风险在于"木桶效应"(性能被最差的机器拖累)或"配置溢出"(按大机器配置导致小机器宕机)。
| 分组名称 | 包含节点 | 物理内存 | 关键特征 | 优化策略 |
|---|---|---|---|---|
| 大内存组 (BigMem) | nd1, nd2, nd3, nd4, nd5, nd6 | ~32 GB | 资源较充裕 | 主力计算节点,拉满 YARN 内存配置。 |
| 小内存组 (SmallMem) | nd11, nd12, nd13, nd14, nd15, nd16 | ~13.5 GB (其中 nd13 仅 11.6 GB) | 资源极度紧张 | 必须以 nd13 为基准,降低配置保命。 |
2. 操作系统级优化 (Linux Base)
在修改 CDH 组件前,必须确保底座稳固。
2.1 基础监控工具安装
针对 CentOS 7 缺失常用工具的问题:
bash
# 修复 yum python2 兼容性问题后
yum install epel-release -y
yum install net-tools sysstat iotop htop nload -y2.2 核心内核参数调整 (所有节点)
-
Swappiness (交换分区):
-
目标: 避免 Hadoop 使用磁盘 Swap,导致性能骤降。
-
操作 :
sysctl vm.swappiness=1(临时); 修改/etc/sysctl.conf添加vm.swappiness=1(永久)。
-
-
Transparent Huge Pages (THP):
-
目标: 关闭透明大页,防止 CPU 占用过高。
-
检查 :
cat /sys/kernel/mm/transparent_hugepage/enabled应输出[never]。
-
3. HDFS 存储层优化
针对大量小文件和磁盘容错的配置。
| 配置项 (Cloudera Manager) | 原值 | 推荐值 | 解释/后果 |
|---|---|---|---|
HDFS 块大小 (dfs.blocksize) |
32 MiB | 128 MiB | 严重级别:高。32M 会导致元数据爆炸,拖慢 NameNode。修改后仅对新文件生效。 |
DataNode 失败卷容忍 (dfs.datanode.failed.volumes.tolerated) |
0 | 1 | 允许坏一块盘而不宕机,生产环境必备。 |
同时针对异构集群,HDFS 的核心在于"不要让小机器撑死,不要让大机器闲死"。
3.1 开启机架感知 (Rack Awareness) 或 磁盘平衡
如果你的 nd11-16 磁盘也很小,数据很快会写满。
-
优化项:定期执行 HDFS Balancer。
-
操作 :CM -> HDFS -> 重新平衡。注意:设置阈值(Threshold)为 10%。
-
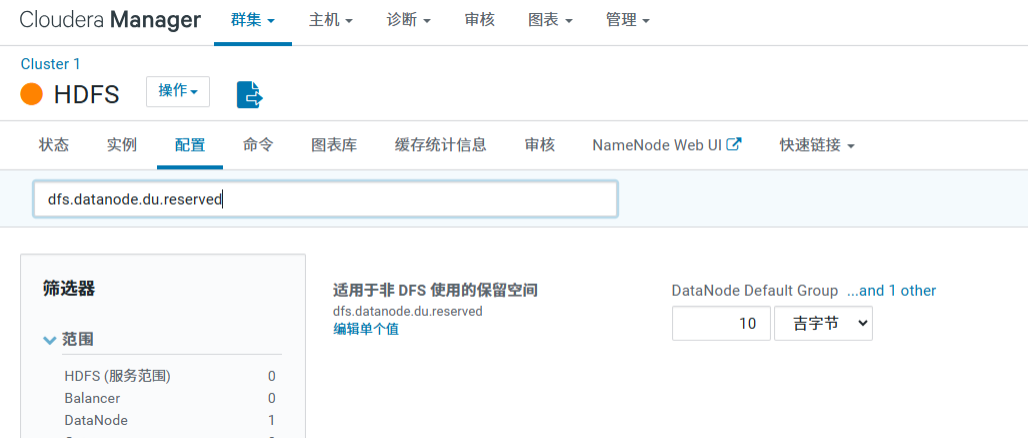
高级技巧:如果小机器磁盘空间极小,可以在 dfs.datanode.du.reserved(保留磁盘空间)中,为小机器组单独设置更大的保留值(例如保留 20G),强迫数据更多写入大磁盘机器。
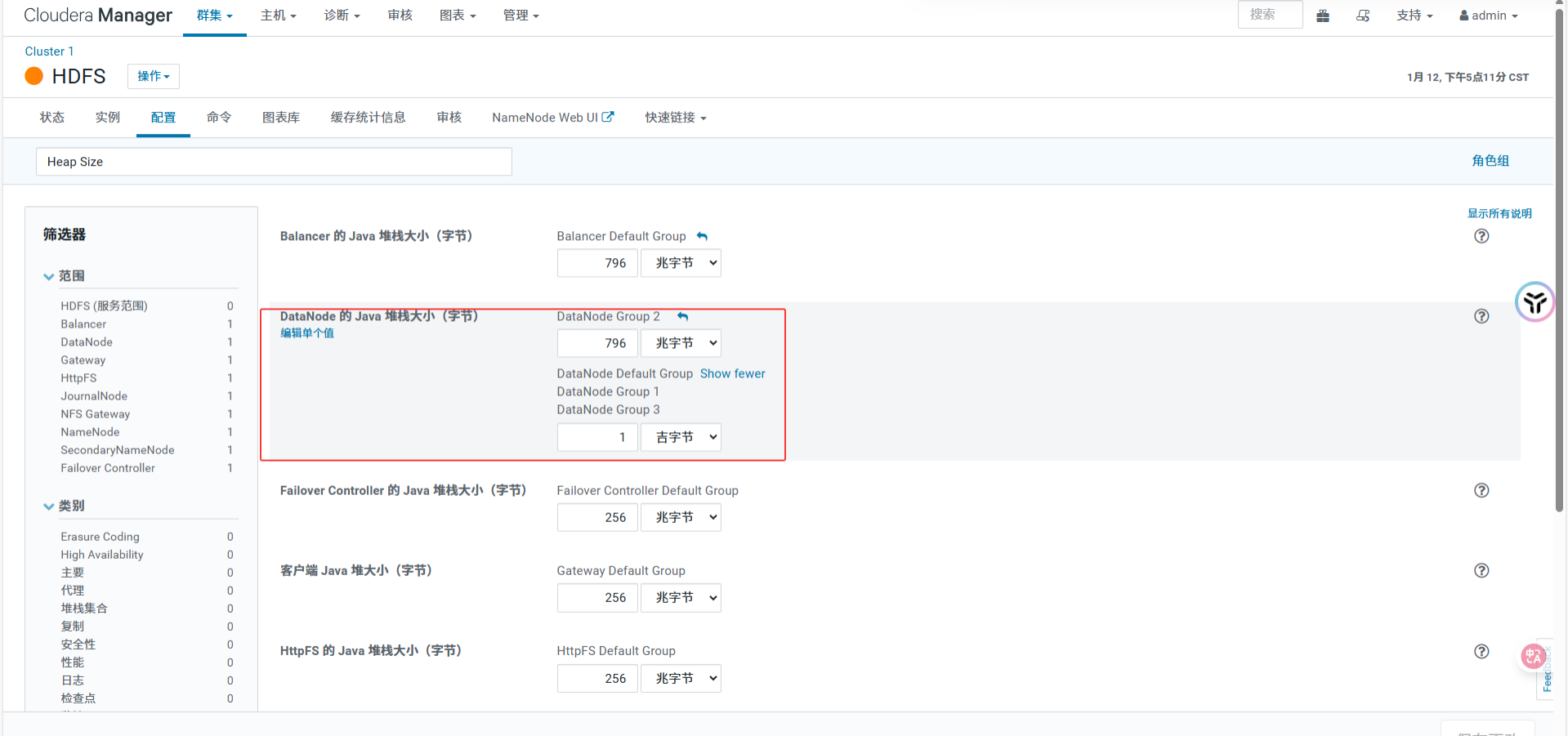
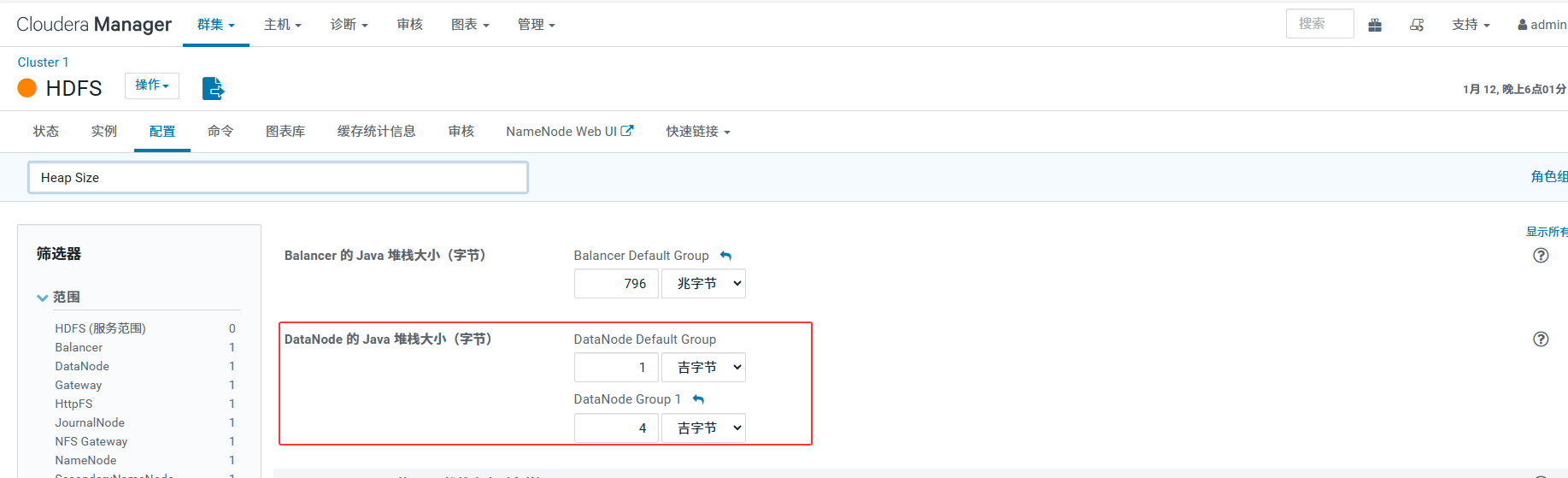
3.2 优化 DataNode 内存 (Heap Size)
-
现状:默认可能只有 1GB。
-
风险:写入大量文件时,DataNode 容易 OOM。
-
策略(利用角色组):
-
nd11-16:保持 1GB 或 1.5GB(内存太小,不敢多给)。
-
nd1-nd6 :在 HDFS DataNode 角色组中新建组,将 Heap Size 调至 4GB。这能提升大节点处理并发读写的能力。
-
4. YARN 资源调度优化 (核心难点)
目标 :通过 "角色组 (Role Groups)" 技术,让大机器多出力,小机器不崩溃。原来的资源分配不均匀,导致大内存的机子资源浪费。
4.1 创建角色组 (Role Group)
-
进入 YARN -> 角色组 (页面顶部蓝色链接)。
-
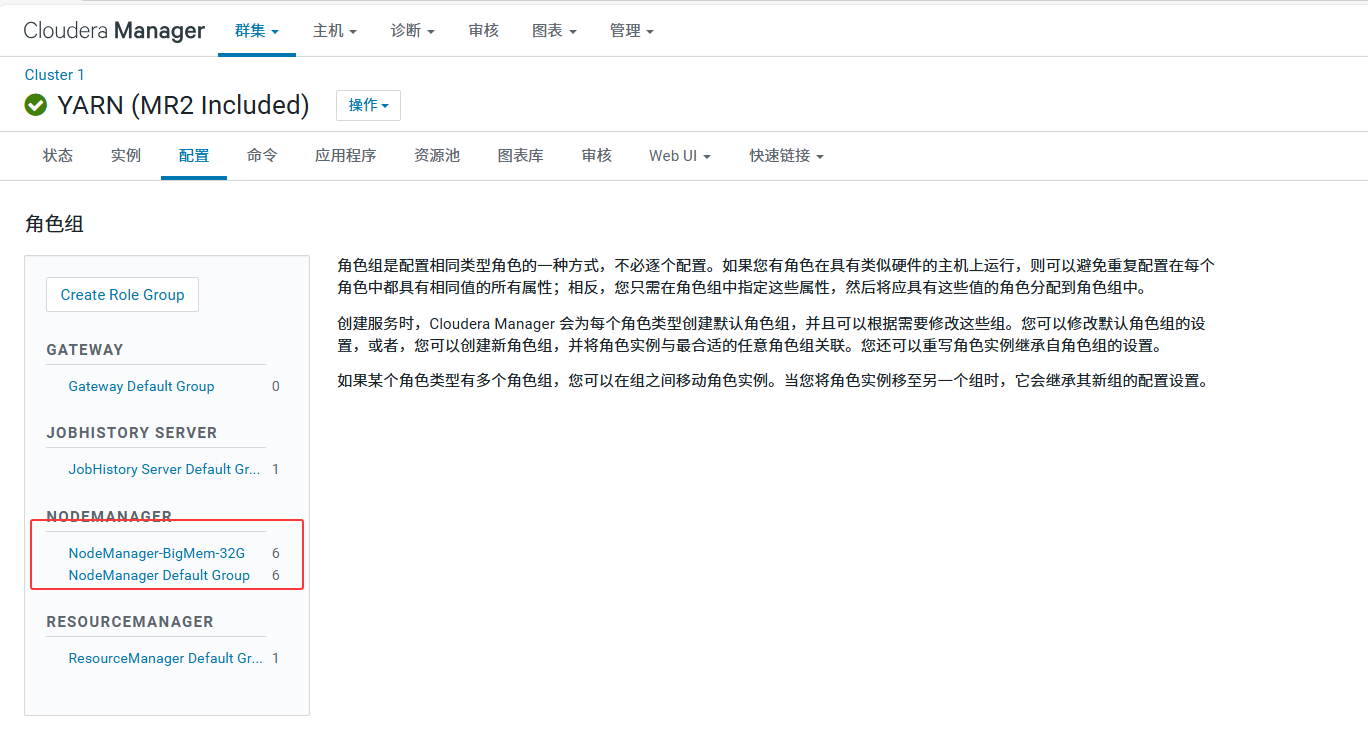
确保只有以下两个 NodeManager 组(多余的 Group 1/2/3 请清空主机后删除)
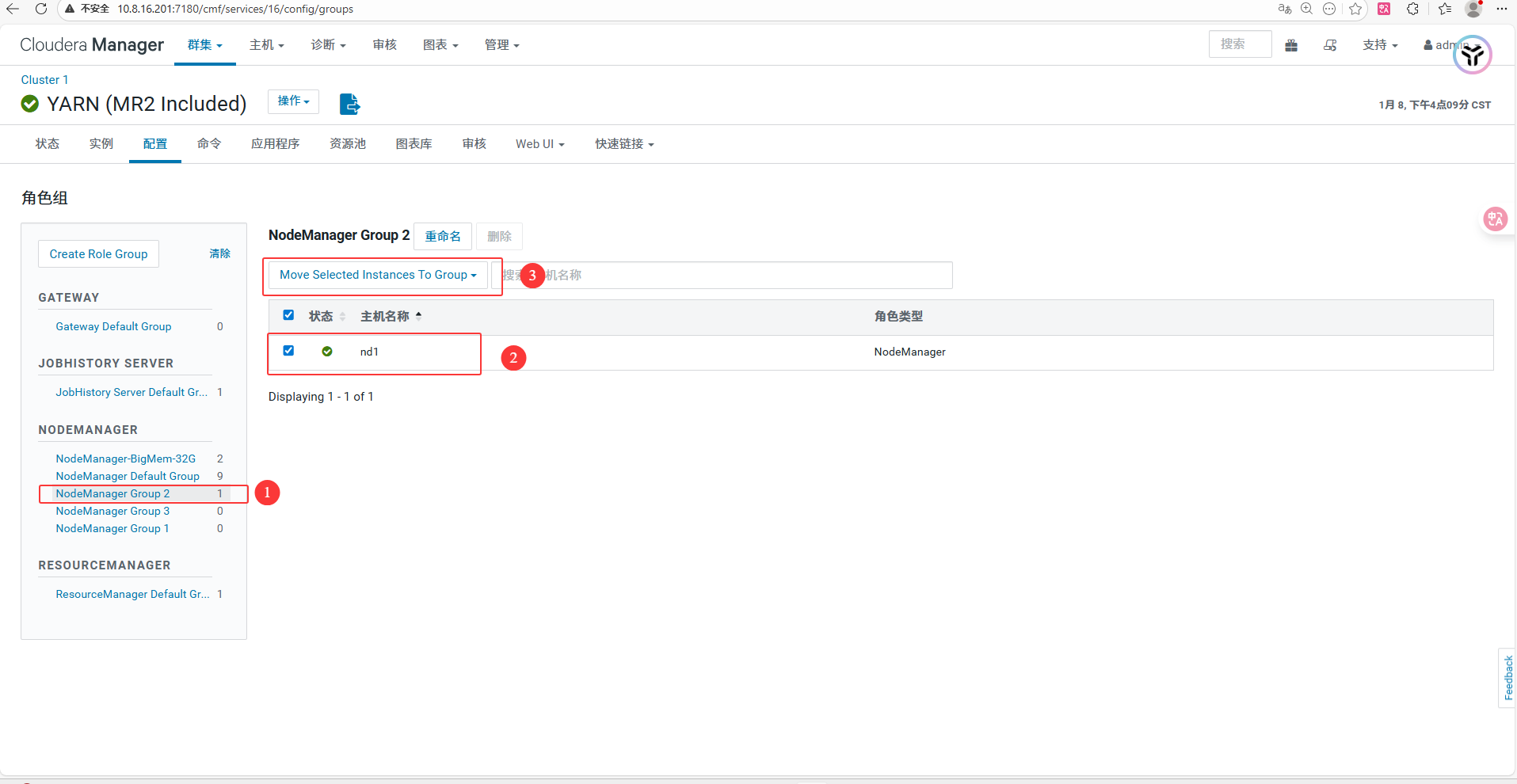
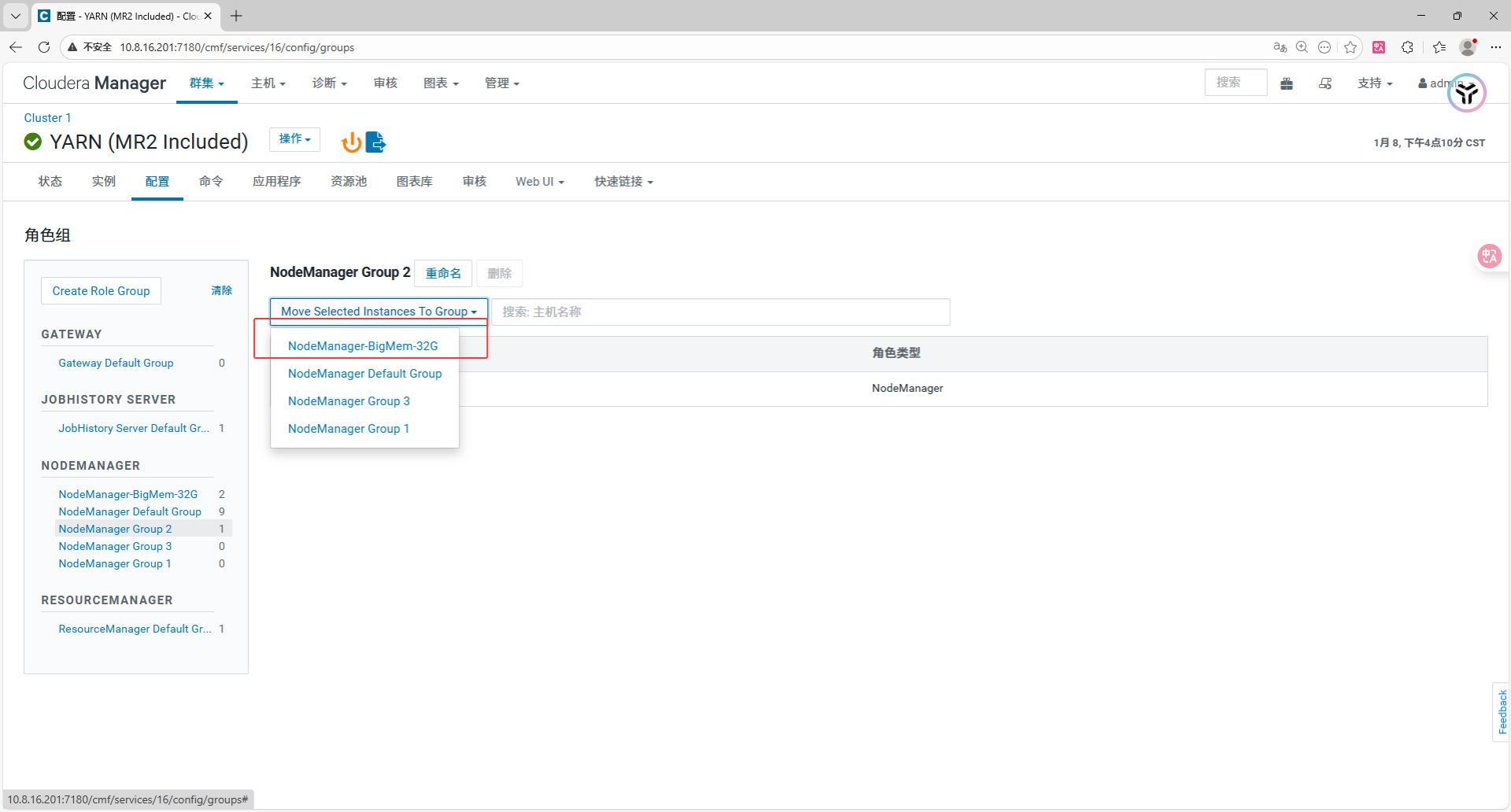
- NodeManager Default Group : 放入小内存节点 (
nd11-nd16)。 - NodeManager-BigMem-32G (新建): 放入大内存节点 (
nd1-nd6)。
4.2 配置内存参数 (yarn.nodemanager.resource.memory-mb)
这是 YARN 能调度的总内存。
-
NodeManager Default Group (针对小机器):
-
设置值 : 8 GiB
-
计算逻辑: 11.6G(nd13物理) - 1.5G(系统) - 2G(DataNode) = 8.1G -> 取整 8G。
-
-
NodeManager-BigMem-32G (针对大机器):
-
设置值 : 12 GiB
-
计算逻辑: 32G(物理) - 12G(系统) - 4G(DataNode) - 4G(其他) = 12G -> 保守取 12G。
-