
【作者主页】Francek Chen
【专栏介绍】⌈ ⌈ ⌈大数据技术原理与应用 ⌋ ⌋ ⌋专栏系统介绍大数据的相关知识,分为大数据基础篇、大数据存储与管理篇、大数据处理与分析篇、大数据应用篇。内容包含大数据概述、大数据处理架构Hadoop、分布式文件系统HDFS、分布式数据库HBase、NoSQL数据库、云数据库、MapReduce、Hadoop再探讨、数据仓库Hive、Spark、流计算、Flink、图计算、数据可视化,以及大数据在互联网领域、生物医学领域的应用和大数据的其他应用。
【GitCode】专栏资源保存在我的GitCode仓库:https://gitcode.com/Morse_Chen/BigData_principle_application。
文章目录
相对于传统的本地文件系统而言,分布式文件系统(Distributed File System)是一种通过网络实现文件在多台主机上进行分布式存储的文件系统。分布式文件系统的设计一般采用"客户机/服务器"(Client/Server)模式,客户端以特定的通信协议通过网络与服务器建立连接,提出文件访问请求,客户端和服务器可以通过设置访问权来限制请求方对底层数据存储块的访问。
目前,已得到广泛应用的分布式文件系统主要包括 GFS 和 HDFS 等,后者是针对前者的开源实现。
一、计算机集群的基本架构
分布式文件系统把文件分布存储到多个计算机节点上,成千上万的计算机节点构成计算机集群。与之前使用多个处理器和专用高级硬件的并行化处理装置不同的是,目前的分布式文件系统所采用的计算机集群,都是由普通硬件构成的,这就大大降低了硬件上的开销。
计算机集群的基本架构如图1所示。集群中的计算机节点存放在机架(Rack)上,每个机架可以存放 8~64 个节点,同一机架上的不同节点之间通过网络互连(常采用吉比特以太网),多个不同机架之间采用另一级网络或交换机互连。
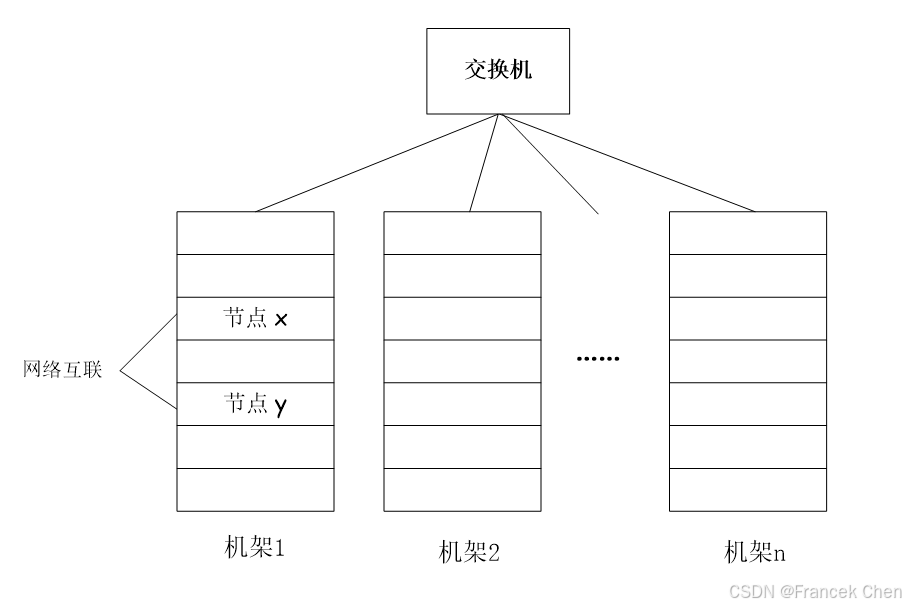
图1 计算机集群的基本架构(1)
图2 计算机集群的基本架构(2)
二、分布式文件系统的结构
与普通文件系统类似,分布式文件系统也采用了块的概念,文件被分成若干个块进行存储,块是数据读写的基本单元,只不过分布式文件系统的块要比操作系统中的块大很多。比如 HDFS 默认的一个块的大小是 64 MB。与普通文件不同的是,在分布式文件系统中,如果一个文件小于一个数据块的大小,它并不占用整个数据块的存储空间。
分布式文件系统在物理结构上是由计算机集群中的多个节点构成的,如图3所示。这些节点分为两类:一类叫"主节点"(Master Node),或者被称为"名称节点"(NameNode);另一类叫"从节点"(Slave Node),或者被称为"数据节点"(DataNode)。名称节点负责文件和目录的创建、删除和重命名等,同时管理着数据节点和文件块的映射关系,因此客户端只有访问名称节点才能找到请求的文件块所在的位置,进而到相应位置读取所需文件块。数据节点负责数据的存储和读取,在存储时,由名称节点分配存储位置,然后由客户端把数据直接写入相应数据节点;在读取时,客户端从名称节点获得数据节点和文件块的映射关系,然后就可以到相应位置访问文件块。数据节点也要根据名称节点的命令创建、删除和复制数据块。
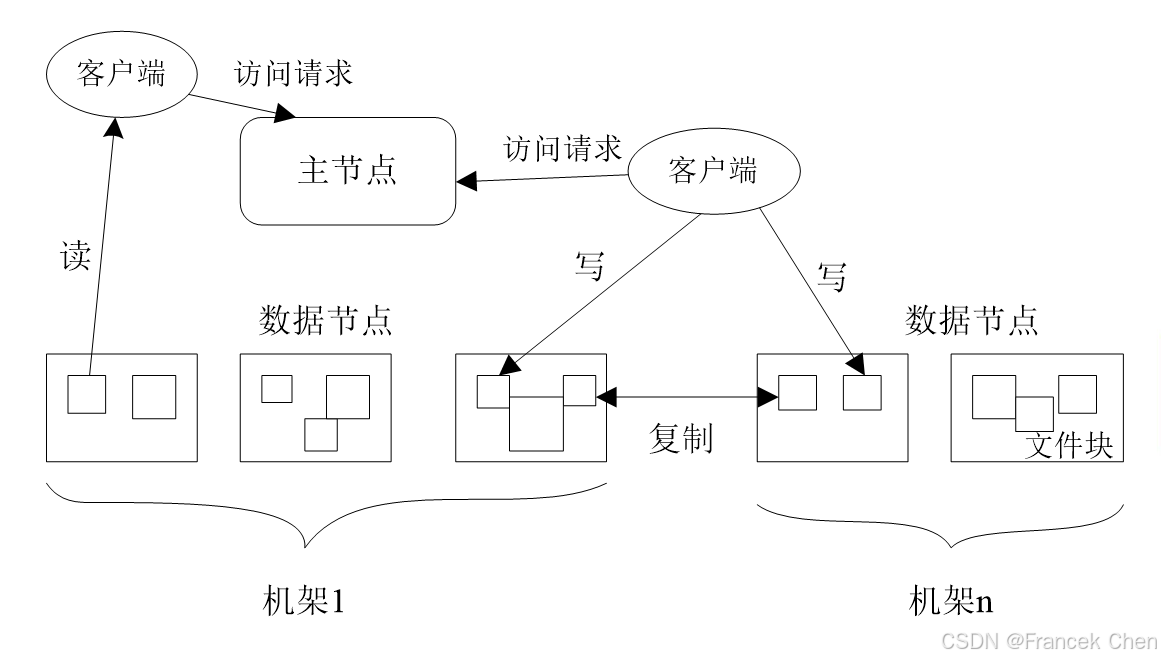
图3 分布式文件系统的物理结构(1)
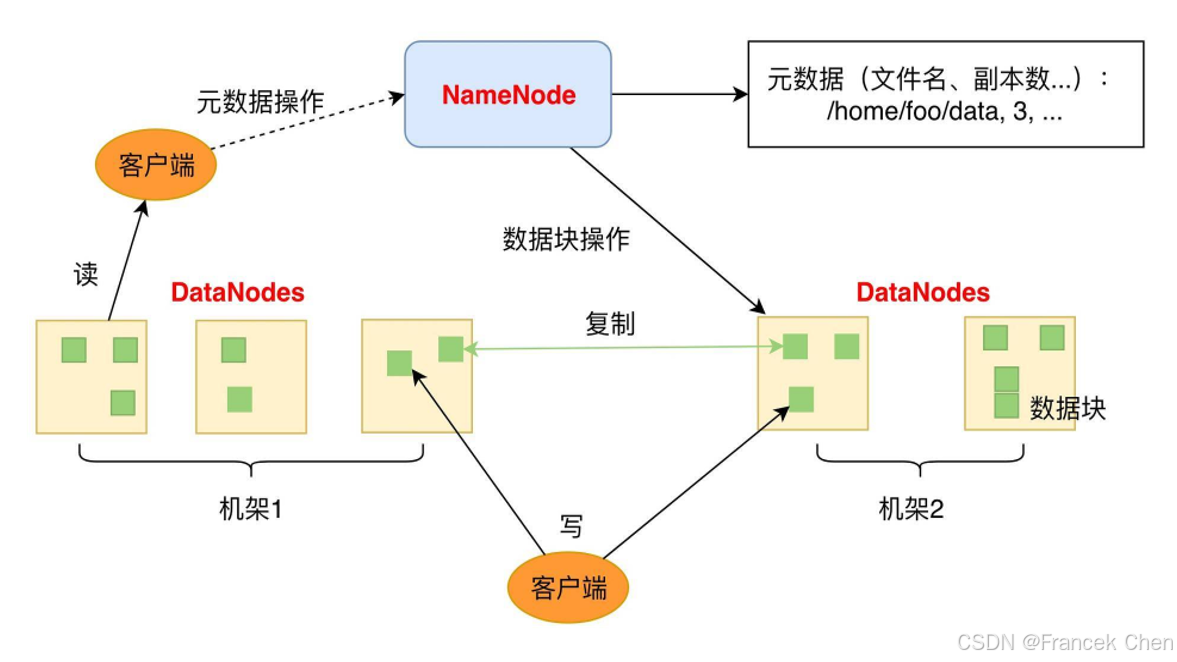
图4 分布式文件系统的物理结构(2)
计算机集群中的节点可能发生故障,因此为了保证数据的完整性,分布式文件系统通常采用多副本存储。文件块会被复制为多个副本,存储在不同的节点上,而且存储同一文件块的不同副本的各个节点会分布在不同的机架上。这样,在单个节点出现故障时,就可以快速调用副本重启单个节点上的计算过程,而不用重启整个计算过程,整个机架出现故障时也不会丢失所有文件块。文件块的大小和副本个数通常可以由用户指定。
分布式文件系统是针对大规模数据存储而设计的,主要用于处理大规模文件,如 TB 级文件。处理规模过小的文件不仅无法充分发挥其优势,而且会严重影响系统的扩展和性能。
三、分布式文件系统的设计需求
分布式文件系统的设计需求主要包括透明性、并发控制、文件复制、硬件和操作系统的异构性、可伸缩性、容错以及安全需求等。但是,在具体实现中,不同产品实现的级别和方式都有所不同。表1给出了分布式文件系统的设计需求、具体含义,以及 HDFS 对这些指标的实现情况。
表1 分布式文件系统的设计需求、具体含义以及 HDFS 对这些指标的实现情况
| 设计需求 | 具体含义 | HDFS 的实现情况 |
|---|---|---|
| 透明性 | 具备访问透明性、位置透明性、性能和伸缩透明性。访问透明性是指用户不需要专门区分哪些是本地文件,哪些是远程文件,用户能够通过相同的操作来访问本地文件和远程文件资源。位置透明性是指在不改变路径名的前提下,不管文件副本数量和实际存储位置发生何种变化,对用户而言都是透明的,用户不会感受到这种变化,只需要使用相同的路径名就始终可以访问同一个文件。性能和伸缩透明性是指系统中节点的增加或减少以及性能的变化对用户而言是透明的,用户感受不到什么时候一个节点加入或退出了。 | 只能提供一定程度的访问透明性,完全支持位置透明性、性能和伸缩透明性 |
| 并发控制 | 客户端对文件的读写不应该影响其他客户端对同一个文件的读写。 | 机制非常简单,任何时间都只允许有一个程序写入某个文件 |
| 文件复制 | 一个文件可以拥有在不同位置的多个副本。 | HDFS 采用了多副本机制 |
| 硬件和操作系统的异构性 | 可以在不同的操作系统和计算机上实现同样的客户端和服务器端程序。 | 采用 Java 语言开发,具有很好的跨平台能力 |
| 可伸缩性 | 支持节点的动态加入或退出。 | 建立在大规模廉价机器上的分布式文件系统集群,具有很好的可伸缩性 |
| 容错 | 保证文件服务在客户端或者服务端出现问题的时候能正常使用。 | 具有多副本机制和故障自动检测、恢复机制 |
| 安全 | 保障系统的安全性。 | 安全性较弱 |
小结
分布式文件系统通过网络将文件分布式存储在多台主机上,采用客户机/服务器模式,降低硬件开销。其结构包括主节点(名称节点)和从节点(数据节点),采用多副本存储保证数据完整性。设计需求涵盖透明性、并发控制、文件复制、异构性、可伸缩性、容错和安全等方面。HDFS 作为典型代表,实现了大部分设计需求,如多副本机制、跨平台能力等,但在并发控制和安全性方面仍有提升空间,整体适用于大规模数据存储场景。
欢迎 点赞👍 | 收藏⭐ | 评论✍ | 关注🤗
