当 MoE 通过条件计算扩展模型容量时,Transformer 却缺少原生的知识查找原语。Engram 提出 条件记忆 作为稀疏性的新轴,让模型以 O(1) 的时间直接检索静态知识,而非通过计算模拟检索。
1. 背景与核心问题
在当前的 大规模语言模型(LLM) 设计中,稀疏性(Sparsity) 是提升模型容量且不显著增加计算成本的关键策略。当前主流实现是通过 混合专家(Mixture-of-Experts, MoE),即每个 token 只激活部分专家,从而在参数量大幅增加的同时保持计算量基本不变。
然而,语言建模中存在两类本质不同的任务:
-
组合推理(Compositional Reasoning):需要深层的动态计算
-
知识检索(Knowledge Retrieval):如命名实体、固定短语等局部静态模式
现有 Transformer 缺乏原生的知识查找原语 ,不得不通过多层注意力与前馈网络来"重建"静态知识(如中国首都,模型总是低效推理:中国是个国家,国家有首都,所以中国的首都是...),这本质上是用昂贵的计算模拟廉价的查表操作。
Engram 的核心贡献 :提出 条件记忆(Conditional Memory) 作为 条件计算(MoE) 的互补稀疏轴,通过 O(1) 查找直接检索静态嵌入,释放模型深度用于更复杂的推理。
2. Engram 架构详解
2.1 整体设计
Engram 是一个条件记忆模块,结构上与 Transformer 主干分离,仅在特定层插入,用于检索静态的 N-gram 记忆并与动态隐藏状态融合。
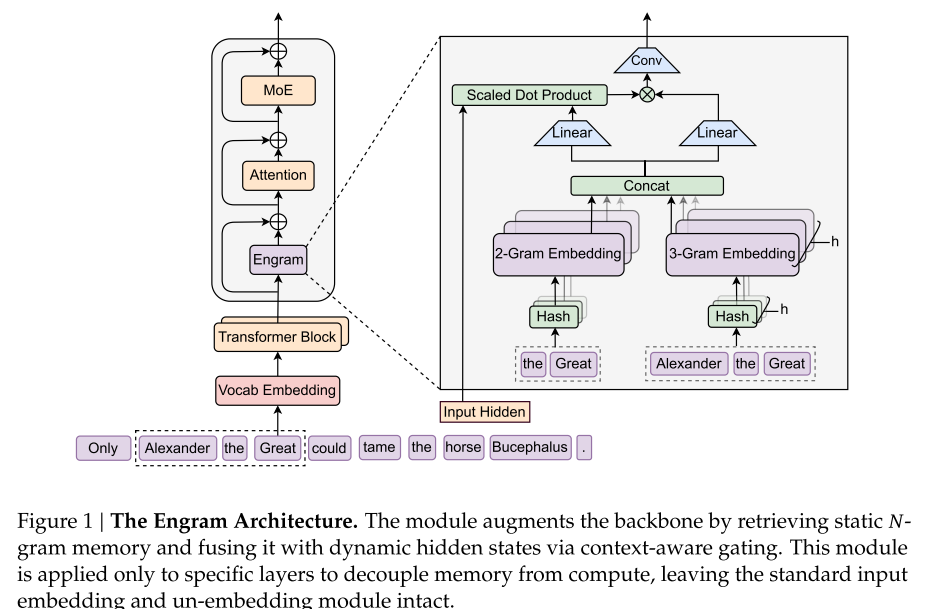
图1:Engram 架构概览(对应论文 Figure 1)
2.2 关键组件
1) 稀疏检索:哈希 N-gram
-
使用 Tokenizer 压缩:归一化文本(NFKC、小写化等),将语义相似的 token 映射到同一 ID,词表减少约 23%
-
多头哈希:每个 N-gram 阶使用 K 个独立的哈希头,减少冲突
-
公式:
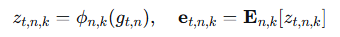
最终拼接所有检索到的嵌入得到 et
2) 上下文感知门控
检索到的嵌入 et是静态的,可能包含噪声或多义性。Engram 使用一个类 Attention 的门控机制:
-
Query:当前隐藏状态 ht(已聚合全局上下文)
-
Key/Value:检索到的记忆 et 的投影
-
门控值:
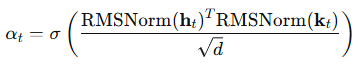
当记忆与上下文冲突时,门控趋于零,抑制噪声
3) 轻量卷积增强
使用深度可分离因果卷积(kernel=4, dilation=最大 N-gram 阶)扩大感受野并增强非线性,最后通过残差连接输出。
4) 与多分支架构集成
在多分支主干中,Engram 共享 embedding 表和 Value 投影,但为每个分支使用独立的 Key 投影,以实现分支特异性门控。
3. 核心图表解读
3.1 稀疏分配 U 型曲线
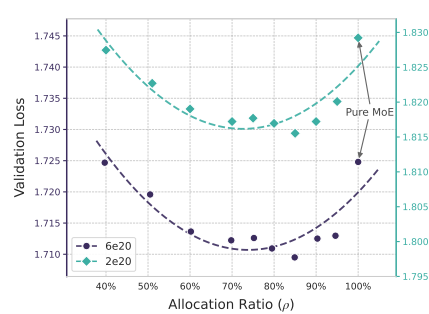
图3(左):稀疏容量在 MoE 专家与 Engram 记忆之间的分配验证损失曲线
-
横轴:分配比例 ρρ,表示稀疏参数中分配给 MoE 的比例
-
纵轴:验证损失
-
结论 :纯 MoE(ρ=1ρ=1)并非最优,将 20-25% 的稀疏预算分配给 Engram 可获得最佳性能,形成明显的 U 型曲线
3.2 无限记忆缩放定律
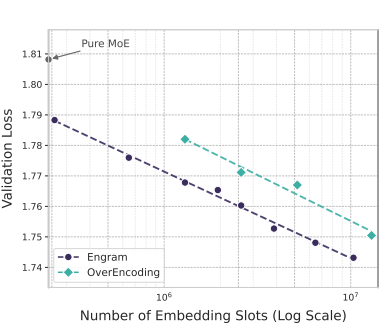
*图3(右):在无限记忆机制下,Engram 的验证损失随记忆槽数量增加的 log-线性下降*
-
Engram 的记忆扩展遵循 幂律缩放,更多记忆槽持续带来收益,且不增加计算开销
-
相比 OverEncoding 等基线,Engram 在相同记忆预算下具有更大扩展潜力
3.3 长上下文性能
表2 显示,在 Iso-Loss 和 Iso-FLOPs 设置下,Engram 在长上下文任务(如 Multi-Query NIAH、Variable Tracking)上显著优于 MoE 基线,最高提升超过 10 个百分点。
3.4 表示对齐与有效深度
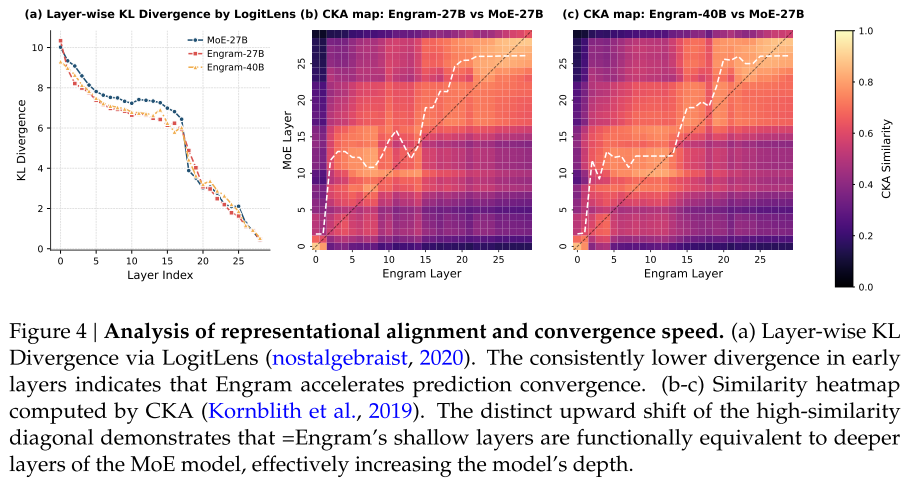
图4:LogitLens 和 CKA 分析显示 Engram 的早期层对齐到 MoE 的更深层
-
LogitLens 显示 Engram 早期层 KL 散度更低,预测收敛更快
-
CKA 相似性热图显示对角线明显上移,说明 Engram 的浅层表示对应 MoE 的深层表示,等效增加了网络深度
4. 代码实现精读
以下基于 engram_demo_v1.py 解析关键实现:
4.1 压缩分词器
python
class CompressedTokenizer:
def _build_lookup_table(self):
# 归一化文本,合并语义相似的 token
norm = self.normalizer.normalize_str(text)
key = norm if norm else text- 使用 Unicode 规范化(NFKC)、转小写、去重音等操作,减少词表冗余
4.2 NN-gram 哈希映射
python
class NgramHashMapping:
def _get_ngram_hashes(self, input_ids, layer_id):
# 基于乘法与异或的轻量哈希
mix = (tokens[0] * multipliers[0])
for k in range(1, n):
mix = np.bitwise_xor(mix, tokens[k] * multipliers[k])
head_hash = mix % mod-
每个 N-gram 通过确定性哈希函数映射到 embedding 表索引
-
不同层使用不同的乘数种子,增强多样性
4.3 Engram 模块前向传播
python
class Engram(nn.Module):
def forward(self, hidden_states, input_ids):
hash_ids = self.hash_mapping.hash(input_ids)[self.layer_id]
embeddings = self.multi_head_embedding(hash_ids).flatten()
# 多分支门控
gates = []
for hc_idx in range(hc_mult):
key = self.key_projs[hc_idx](embeddings)
query = hidden_states[:,:,hc_idx,:]
gate = (norm(key) * norm(query)).sum(dim=-1) / sqrt(d)
gates.append(gate.sigmoid())
value = gates * self.value_proj(embeddings)
output = value + self.short_conv(value)
return output4.4 系统级优化:计算与存储解耦
论文图2 展示了训练与推理时的系统设计:
-
训练时:embedding 表分片到多 GPU,使用 All-to-All 通信收集活跃行
-
推理时:embedding 表卸载到主机内存,利用确定性哈希预取,通过计算掩盖通信延迟
表4 显示,即使将 100B 参数的 embedding 表完全卸载到 CPU 内存,推理吞吐量仅下降 <3%。
5. 关键实验结果
5.1 多任务性能提升
表1 显示,在 相同参数量和 FLOPs 下,Engram-27B 相比 MoE-27B:
-
知识任务:MMLU (+3.0), CMMLU (+4.0)
-
推理任务:BBH (+5.0), ARC-Challenge (+3.7)
-
代码数学:HumanEval (+3.0), MATH (+2.4)
5.2 长上下文优势
-
Multi-Query NIAH:84.2 → 97.0
-
Variable Tracking:77.0 → 87.2
-
归因于:Engram 将局部依赖委托给查找,释放注意力容量处理全局上下文
5.3 模块消融分析
图5 显示:
-
最佳插入层:第2层(单层)或第2+6层(双层)
-
关键组件:多分支融合 > 上下文门控 > Tokenizer 压缩
-
卷积和更高阶 N-gram 影响较小
6. 创新总结
| 维度 | 贡献 |
|---|---|
| 架构创新 | 提出"条件记忆"作为 MoE 的互补稀疏轴,实现 O(1) 静态知识检索 |
| 算法-系统协同 | 确定性哈希支持预取与计算-存储解耦,实现百亿参数表近零开销卸载 |
| 理论指导 | 通过稀疏分配问题发现 U 型缩放律,指导混合分配策略 |
| 长上下文优化 | 将局部模式卸载给记忆,释放注意力聚焦全局依赖 |
7. 未来展望
Engram 为下一代稀疏模型提供了一个可扩展、系统友好的记忆原语。未来可能方向:
-
多模态扩展:将 NN-gram 检索扩展到视觉、音频的局部模式
-
动态记忆更新:支持在推理时编辑或扩展记忆表
-
跨层记忆共享:设计跨层共享的压缩记忆表示
-
硬件定制加速:为确定性哈希检索设计专用硬件单元
论文链接 :Engram: Conditional Memory as a Sparse Axis for Scalable LLMs
代码仓库 :https://github.com/deepseek-ai/Engram
通过 Engram,我们看到了一个重要的设计范式转变:不是所有稀疏性都应该通过条件计算实现,将静态知识委托给条件记忆,能让模型更专注地"思考",而非"回忆"。