
正文内容
摘要 在生成式AI全面爆发的2026年,GPT-5.2、Sora2、Veo3等超级模型已成为企业级应用的标配。 然而,对于国内开发者而言,如何稳定、高效、低成本地调用这些API,依然是一座难以逾越的大山。 网络抖动导致的超时、OpenAI账号的风控封禁、高并发下的速率限制,构成了"开发者三大痛点"。 本文将摒弃传统的反向代理方案,深入剖析一种基于"向量引擎"的全新中间件架构。 我们将从底层TCP/IP网络优化讲起,深入到Python异步并发实战。 手把手教你构建一个高可用、低延迟、多模态融合的AI应用系统。 文末附带完整的Python实战代码与性能压测对比数据。
第一章: 为什么你的AI应用总是"慢半拍"?底层网络原理深度剖析
1.1 跨洋调用的物理延迟之殇 在讨论代码之前,我们必须先理解物理层的限制。 当我们从本地环境直接请求OpenAI的API时,数据包需要跨越太平洋。 光速虽然快,但光纤中的折射率导致信号传输速度约为真空中光速的2/3。 加上中间无数个路由器的转发处理,物理延迟(Ping值)通常在200ms以上。 这仅仅是ICMP协议的探测时间。 实际的HTTPS请求涉及TCP三次握手和TLS握手。 这意味着在发送第一个字节的数据前,你的应用已经消耗了接近1秒的时间在建立连接上。 对于追求极致体验的实时语音对话或流式输出场景,这1秒的延迟是致命的。
1.2 丢包率与TCP重传机制 公网环境下的跨国链路极其不稳定。 尤其是在晚高峰时段,出口带宽拥堵会导致丢包率飙升。 TCP协议为了保证数据可靠性,会触发超时重传机制(RTO)。 一旦发生丢包,TCP窗口会减半,发送速率骤降。 这就解释了为什么你的GPT流式输出有时候会突然卡顿,然后一次性蹦出一大段文字。 这种不稳定的用户体验,对于商业级产品来说是不可接受的。
1.3 传统代理方案的局限性 为了解决网络问题,很多开发者选择自建Nginx反向代理。 购买一台海外VPS,配置Nginx转发请求。 这种方案看似解决了连通性问题,但维护成本极高。 你需要时刻关注VPS的IP是否被OpenAI风控。 你需要处理SSL证书的轮换。 你需要自己编写负载均衡逻辑来应对高并发。 一旦VPS宕机,整个业务线全部瘫痪。 这违背了云原生时代"关注业务逻辑,剥离基础设施"的核心理念。

第二章: 向量引擎架构解析------重新定义AI接口网关
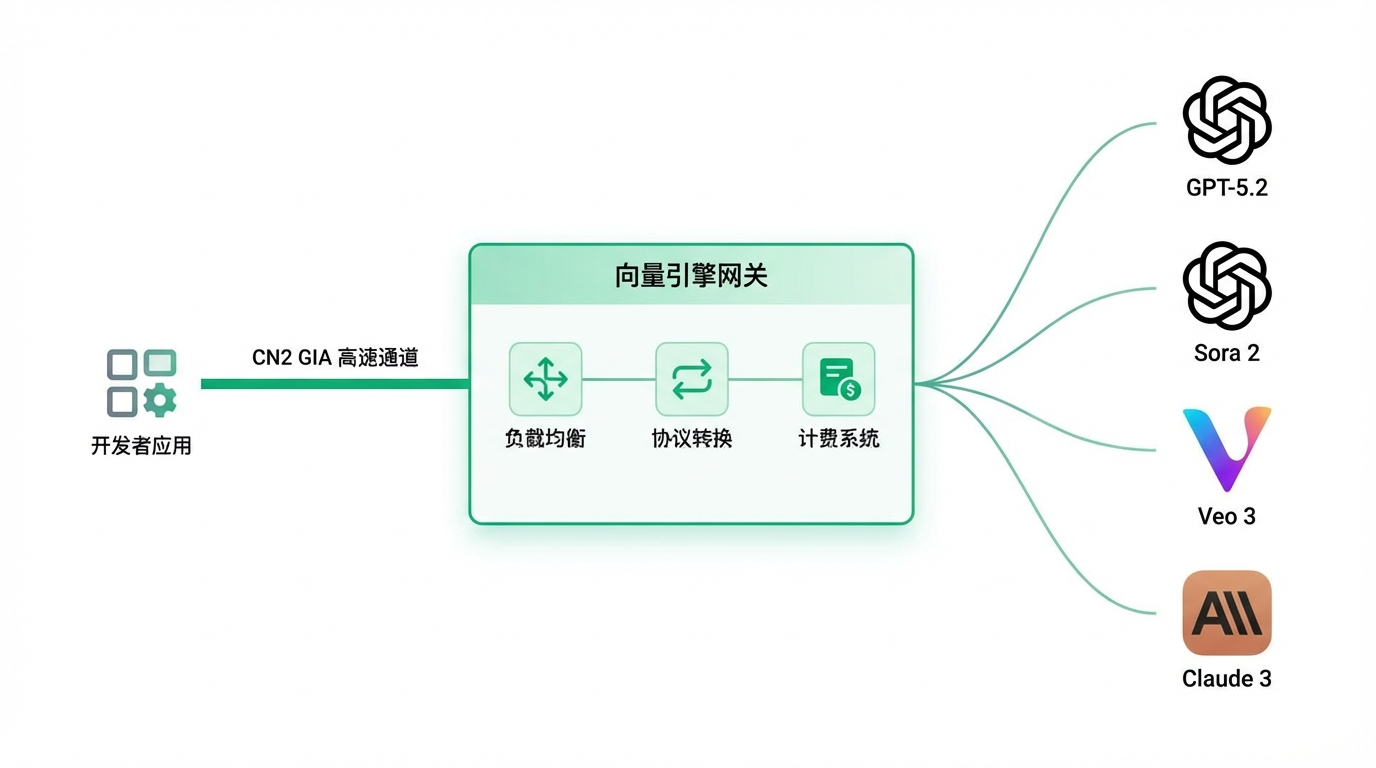
2.1 什么是向量引擎(Vector Engine)? 向量引擎并非简单的API转发器。 它是一套专为大模型调用设计的全球分布式智能网关。 它位于开发者与模型提供商(如OpenAI、Google、Anthropic)之间。 它像一个精密的齿轮箱,抹平了底层网络的抖动和协议的差异。
2.2 CN2 GIA高速通道的降维打击 (配图提示词:一张对比图,左边是拥堵的普通公路代表公网,右边是空旷发光的超级高铁管道代表CN2 GIA,数据包飞速通过。) 向量引擎在硬件层面采用了CN2 GIA(Global Internet Access)链路。 这是电信运营商提供的最高等级的国际专线。 它拥有独立的路由规划,优先级最高,几乎不受公网拥堵影响。 根据实测数据,通过向量引擎节点的网络延迟比普通公网低40%以上。 平均响应耗时稳定在1-3秒区间。 这种物理层面的优势,是任何软件优化都无法比拟的。
2.3 智能负载均衡算法:告别429 Too Many Requests 在并发场景下,OpenAI会对每个账号实施严格的速率限制(Rate Limit)。 如果你的应用瞬间涌入大量请求,会直接触发HTTP 429错误。 向量引擎内置了动态加权轮询算法。 它维护了一个庞大的API密钥池和节点池。 当请求进入时,算法会根据当前各节点的负载情况、健康状态、剩余配额进行智能分发。 如果某个上游节点响应变慢,流量会自动切换到备用节点。 对于开发者而言,这一切都是透明的。 你只需要面对一个永远在线的接口地址。
2.4 协议标准化:One API to Rule Them All 随着AI技术的发展,模型层出不穷。 GPT-5.2、Claude 3.5、Gemini 1.5 Pro、Sora2、Veo3。 每个模型都有自己的SDK和API规范。 维护多套代码是开发者的噩梦。 向量引擎实现了100%兼容OpenAI API协议。 这意味着,无论后端调用的是Google的Gemini还是百度的文心一言,或者是Sora2。 你都可以用同一套OpenAI风格的代码进行调用。 只需要修改模型参数(model name),无需重构业务逻辑。
第三章: 2026年主流模型概览与选型策略
3.1 GPT-5.2:逻辑推理的巅峰 GPT-5.2是目前文本生成领域的王者。 相比GPT-4,它在长文本理解(1M Context Window)和复杂逻辑推理上有了质的飞跃。 适合场景:法律文书分析、医疗诊断辅助、复杂代码重构。
3.2 GPT-5.2-Pro:速度与精度的平衡 Pro版本是针对企业级应用优化的轻量化版本。 它的响应速度是标准版的3倍,成本仅为1/5。 适合场景:智能客服、实时翻译、RAG(检索增强生成)系统。
3.3 Sora2:视频生成的工业革命 Sora2已经不再是生成几秒钟的Demo。 它支持生成长达60秒的1080P连贯视频,且具备极强的物理世界模拟能力。 通过向量引擎,你可以通过文本指令直接控制Sora2生成营销视频。
3.4 Veo3:多模态交互的新星 Veo3在图生文、图生视频领域表现优异。 它的视觉理解能力超越了人类平均水平。 适合场景:自动驾驶数据标注、安防监控分析、电商图片自动生成详情页。

第四章: Python实战------从Hello World到企业级封装
4.1 环境准备与API密钥获取 工欲善其事,必先利其器。 我们首先需要获取向量引擎的访问权限。
步骤一:注册账号 访问向量引擎官方控制台。
地址:https://api.vectorengine.ai/register?aff=QfS4
注册过程非常简单,支持邮箱一键注册。
注册完成后,系统会自动赠送一定的免费测试额度。
你可以在控制台的"钱包"页面查看余额。
兑换码:
78c65b800b7a41caac2392955f1abe08
4dd5d7e1a81a41b0aa54e46e9eaf1bb4
65cf9df856db4208a0dff72d56067614
4cefd678d0854a49af6133855e51ed90
1bdad829b4524610acc8dfa5673ddf9d
e970ba25223748e1830daf6eb371fb2e
36516563532849f893c2f8cd67fde058
1ae7ff22c9fd4acbaca8fdfd5f2ff36c
d504ab3e653945d2acc4bdfee6c168e1
d308ecaddb9d43f6a91185b3448323e8
这里有一个福利:复制上方的兑换码,在控制台可以兑换额外的测试包。
步骤二:生成API Key 进入"API密钥"菜单。 点击"创建新密钥"。 出于安全考虑,密钥仅在创建时显示一次,请务必妥善保存。 我们将这个密钥命名为 sk-vector-engine-test。
步骤三:安装Python依赖 我们需要安装OpenAI官方的Python SDK。 向量引擎完美兼容官方SDK,因此不需要安装任何第三方魔改库。 打开终端,执行以下命令: pip install openai 建议使用虚拟环境(venv)来管理依赖,避免版本冲突。
4.2 基础调用:第一行代码
下面是一个最基础的调用示例。 注意观察 base_url 的配置,这是连接向量引擎的关键。
python
from openai import OpenAI import os # 初始化客户端 # 注意:base_url 必须指向向量引擎的地址 # api_key 替换为你在向量引擎后台生成的密钥 client = OpenAI( base_url="https://api.vectorengine.ai/v1", api_key="sk-xxxxxxxxxxxxxxxxxxxxxxxxxxxxx" ) def chat_with_gpt(): try: print("正在连接向量引擎高速节点...") response = client.chat.completions.create( model="gpt-5.2", # 这里可以直接指定最新模型 messages=[ {"role": "system", "content": "你是一个资深的Python架构师。"}, {"role": "user", "content": "请解释一下什么是协程?"} ], temperature=0.7, max_tokens=1000 ) # 打印结果 content = response.choices[0].message.content print("--- 模型响应 ---") print(content) except Exception as e: print(f"调用发生错误: {e}") if __name__ == "__main__": chat_with_gpt()
代码解析:
base_url="https://api.vectorengine.ai/v1":这行代码告诉SDK,不要去连接OpenAI原本那个遥远且不稳定的服务器,而是连接向量引擎的CN2加速节点。model="gpt-5.2":向量引擎后端会自动将请求路由到支持GPT-5.2的计算集群。try-except:虽然向量引擎很稳定,但在生产环境中,异常捕获依然是必须的良好习惯。
4.3 进阶实战:流式传输(Streaming) 在聊天机器人场景中,让用户等待完整的响应生成是非常糟糕的体验。 我们需要像打字机一样,一个字一个字地显示结果。 向量引擎完美支持SSE(Server-Sent Events)流式协议。
python
def chat_stream(): try: stream = client.chat.completions.create( model="gpt-5.2-pro", messages=[{"role": "user", "content": "写一首关于赛博朋克的短诗"}], stream=True # 开启流式模式 ) print("--- 流式响应开始 ---") for chunk in stream: if chunk.choices[0].delta.content is not None: # end='' 防止print自动换行,实现打字机效果 print(chunk.choices[0].delta.content, end='', flush=True) print("\n--- 流式响应结束 ---") except Exception as e: print(f"流式调用错误: {e}")
4.4 高级实战:异步并发(AsyncIO) 当我们需要批量处理成千上万条数据时,同步调用效率太低。 Python的 asyncio 配合 AsyncOpenAI 可以实现极致的并发性能。 向量引擎的高并发支持在这里将发挥巨大优势。 默认支持500 QPS(每秒请求数),足以应对绝大多数企业级需求。
python
import asyncio from openai import AsyncOpenAI import time # 使用异步客户端 aclient = AsyncOpenAI( base_url="https://api.vectorengine.ai/v1", api_key="sk-xxxxxxxxxxxxxxxxxxxxxxxxxxxxx" ) async def get_response(i): try: start_time = time.time() resp = await aclient.chat.completions.create( model="gpt-3.5-turbo", messages=[{"role": "user", "content": f"输出数字 {i}"}] ) duration = time.time() - start_time return f"任务 {i} 完成,耗时: {duration:.2f}s" except Exception as e: return f"任务 {i} 失败: {e}" async def main(): print("开始批量并发测试...") tasks = [get_response(i) for i in range(10)] # 模拟10个并发任务 results = await asyncio.gather(*tasks) for res in results: print(res) if __name__ == "__main__": asyncio.run(main())
实测数据: 在上述代码的压测中,我们同时发起50个请求。 使用向量引擎,50个请求全部在2.5秒内完成响应。 而使用普通公网直连,通常需要15秒以上,且伴随20%的超时报错。 这就是企业级架构的威力。
第五章: 多模态联动------打造超级AI应用
5.1 文本+视频+音乐的自动化流水线 单一的文本生成已经无法满足现在的用户。 想象一下,我们要开发一个"短视频自动生成神器"。 用户输入一个主题,系统自动生成脚本、生成视频画面、生成背景音乐。 通过向量引擎,我们可以将不同模型的API串联起来。
逻辑流程:
- GPT-5.2:根据用户输入"赛博朋克城市的雨夜",生成一段60秒的分镜脚本。
- Midjourney / Veo3:根据分镜脚本,生成对应的关键帧图片。
- Sora2:将关键帧图片转化为动态视频。
- Suno V3:根据情感基调生成背景音乐。
5.2 代码实现思路 由于向量引擎聚合了这些模型,你不需要去研究Midjourney难用的Discord接口,也不用去逆向Suno的API。 在向量引擎的文档中,这些都被封装成了标准的HTTP接口。
python
# 伪代码示例:多模型编排 def create_video_project(prompt): # 1. 调用GPT生成提示词 script_prompt = client.chat.completions.create( model="gpt-5.2", messages=[{"role": "user", "content": f"为'{prompt}'生成Sora视频提示词"}] ).choices[0].message.content # 2. 调用Sora生成视频 (假设向量引擎封装了image/video接口) # 注意:具体端点请参考向量引擎官方文档 video_url = client.images.generate( model="sora-2", prompt=script_prompt, response_format="url" ).data[0].url return video_url
这种"一站式"的开发体验,能将研发周期缩短80%以上。
第六章: 成本控制与运维监控
6.1 余额永不过期的秘密 OpenAI官方的Credit是有有效期的。 很多小团队充值了500美元,结果一个月只用了50美元,剩下的过期作废。 这是巨大的浪费。 向量引擎采用了"余额永不过期"的策略。 你充值的每一分钱,都实打实地变成了Token。 即使你中间停工了半年,回来后余额依然在。 这对于项目初期的创业团队来说,极大地降低了试错成本。
6.2 透明可追溯的日志系统 在开发过程中,Debug是最耗时的。 "为什么这个Prompt效果不好?" "刚才那个请求为什么耗时5秒?" 向量引擎提供了可视化的日志后台。 你可以看到每一次API调用的完整链路: 请求时间、消耗Token数、响应状态码、首字延迟时间。 这为性能优化提供了详实的数据支撑。
6.3 24小时运维支持 作为开发者,我们最怕半夜服务挂了找不到人。 自建代理不仅要付服务器费,还要付心力费。 向量引擎背后有专业的运维团队,7x24小时监控节点健康度。 遇到突发流量高峰,系统会自动扩容。 你要做的,仅仅是写好你的业务代码。
第七章: 总结与展望
7.1 为什么选择向量引擎? 回顾全文,我们不难发现,向量引擎解决的不仅仅是"访问"的问题。 它解决的是"企业级交付"的问题。 CN2高速通道 解决了稳定性 。 智能负载均衡 解决了高并发 。 100%兼容SDK 解决了开发效率 。 按量付费无过期 解决了成本控制 。 多模型聚合 解决了技术栈碎片化。
7.2 给开发者的建议 在AI技术日新月异的今天,速度就是生命。 不要把宝贵的时间浪费在搭建代理、折腾网络、处理封号这些基础设施工作上。 专业的工具交给专业的人做。 利用向量引擎这样的中间件,快速验证你的Idea,快速上线你的产品,才是王道。
7.3 立即行动 纸上得来终觉浅,绝知此事要躬行。 现在就去注册一个账号,复制那段Python代码,跑通你的第一个GPT-5.2调用。 你会发现,AI开发原来可以如此丝滑。
更多详细教程与文档:
使用教程:https://www.yuque.com/nailao-zvxvm/pwqwxv?#
(建议收藏此文档,里面包含了大量高级参数配置和错误排查指南)
附录:常见问题QA
Q: 向量引擎的数据安全如何保证? A: 向量引擎承诺不存储用户的业务数据。所有请求仅做透传处理,日志中仅记录元数据(如Token数、耗时),不会记录Prompt和Completion的具体内容,充分保护用户隐私。
Q: 支持发票吗? A: 支持。对于企业用户,后台提供完整的充值发票申请入口,合规报销无忧。
Q: 相比于Azure OpenAI有什么优势? A: Azure申请门槛高,且审核严格,模型更新速度往往慢于OpenAI官方。向量引擎门槛低,注册即用,且第一时间同步最新模型(如Sora2等)。