目录
- [Agent Skills: 如何为大语言模型构建可复用技能](#Agent Skills: 如何为大语言模型构建可复用技能)
-
- [Agent Skills 是什么?](#Agent Skills 是什么?)
- 为什么要使用Skills
-
- [何时使用 Skills 与其他选项](#何时使用 Skills 与其他选项)
- Skills的工作原理
-
- 三种数据类型,三种加载级别
-
- [Level 1: 元数据 (始终加载)](#Level 1: 元数据 (始终加载))
- [Level 2: 指令 (触发时加载)](#Level 2: 指令 (触发时加载))
- [Level 3: 资源和代码 (按需加载)](#Level 3: 资源和代码 (按需加载))
- [Skills 和上下文窗口](#Skills 和上下文窗口)
- [Skills 和代码执行](#Skills 和代码执行)
- 技能发展与评估
Agent Skills: 如何为大语言模型构建可复用技能
Agent Skills 是什么?
Agent Skills 原本是 Anthropic 团队内部使用 Claude 的一种方法,但随着官方发布了 《Equipping agents for the real world with Agent Skills》这个博客后。Agent Skills 正式成为了一个跨平台可移植的开放标准,跟 MCP 一样,也是扩展大语言模型能力的方法之一。各个大语言模型厂商在 Anthropic 官方博客发布之后,也在它们的 CLI 中接入了 Agent Skills 概念。
那么什么是 Agent Skills?
官方描述:Agent Skills are modular capabilities that extend Claude's functionality. Each Skill packages instructions, metadata, and optional resources (scripts, templates) that Claude uses automatically when relevant.
使用后的理解:Agent Skills 是一种扩展大语言模型能力的机制,通过预定义的指令、元数据和可选资源(脚本、模板),使模型能够在适当的场景下调用这些能力。在用户交互时,模型会根据上下文判断并选择性地使用这些'技能'来完成任务。
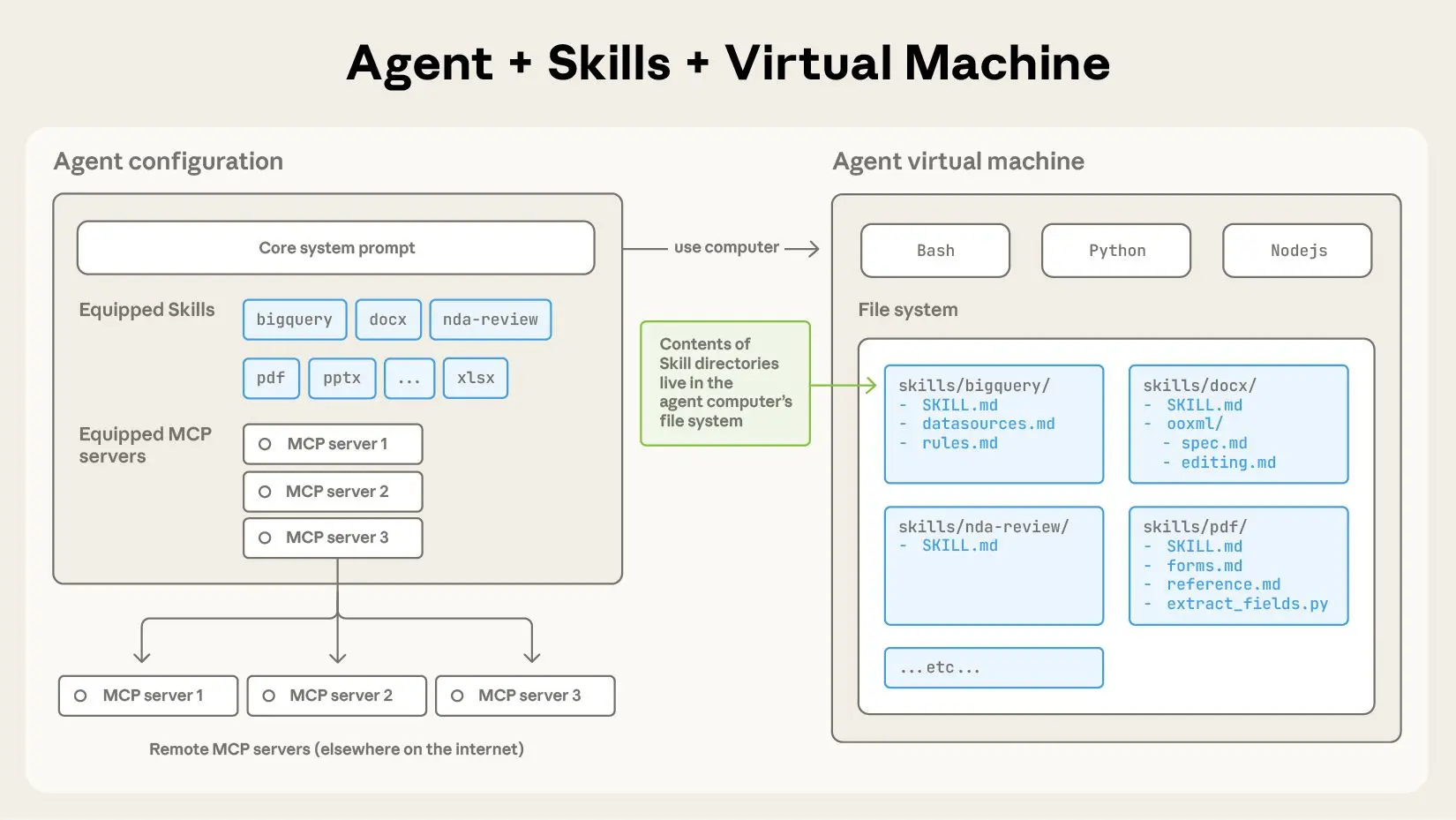
通俗点说,每一个 Agent Skills 就是一个目录,目录一定要包含一个 SKILL.md 文件,同时也会包含指令、脚本和资源。模型识别到某个 Skill 与当前任务相关后,就会使用这个 Skill, 这时 SKILL.md 文件就是告诉模型如何使用目录中的相关资源来完成任务。
SKILL.md这个文件就是用来告诉模型什么情况下会目录下的其他文件(脚本和资源),不过大语言模型在第一次选择使用某一个 '技能' 时,并不是读取完整的所有SKILL.md文件,只会拿到SKILL.md文件中定义的 Name 和 description 信息作为上下文来判断选择具体的 '技能'。这种做法让模型恰到好处的知道怎么使用每个 '技能',而不需要消耗太多的 Token。一旦模型被许可确认使用 '技能' 后,才会开始读取
SKILL.md的完整信息,根据SKILL.md来完成具体的任务。SKILL.md其实就是一个很详细的 Prompt,里面告诉了模型应该怎么做,要使用什么资源或脚本来完成任务。SKILL.md的 name 和 description 其实就是一个简介,就跟我们平常写文档一样,基本上都会写一个文档内容的简介,用简短的说明告诉别人你这个文档是关于什么的。
更为形象的理解:为 Agent 创建技能就像为新员工编写入职指南。
为什么要使用Skills
Skills 是可重用、基于文件系统的资源,它为 Agent 提供特定领域的专业知识:工作流、上下文和最佳实践,将通用的 Agent 变成专家。与提示不同(提示是对话级别的一次性任务指令),Skills 按需加载,无需在多个对话中重复提供相同的指导。
简单来说就是,Skills 是复用的,有点像系统提示词,但是它不只是提示词,它还可以包含一些脚本和资源。而且博主觉得也可以把它当做一个具备了系统提示词的专业 Agent,因为使用的时候,有一种是 Prompt、MCP、Tools 的精简结合版。不过它与这几个是有不同的,官方有一个对比,请阅读下一个标题。
主要优势:
- 专业化 Claude:为特定领域的任务定制功能
- 减少重复:创建一次,自动使用
- 组合功能:结合 Skills 构建复杂工作流
何时使用 Skills 与其他选项
这部分使用的是 Claude 官方的说明,不同的厂商命令都差不多,主要是看 Anthropic 官方对不同能力的定义。
Claude Code 提供了多种自定义行为的方式。关键区别:Skills 由 Claude 根据你的请求自动触发 ,而斜杠命令要求你显式输入 /command。
| 使用这个 | 当你想要... | 何时运行 |
|---|---|---|
| Skills | 给 Claude 专业知识(例如,"使用我们的标准审查 PR") | Claude 在相关时选择 |
| 斜杠命令 | 创建可重用的提示(例如,/deploy staging) |
你输入 /command 来运行它 |
| CLAUDE.md | 设置项目范围的说明(例如,"使用 TypeScript 严格模式") | 加载到每个对话中 |
| 子代理 | 将任务委托给具有自己工具的单独上下文 | Claude 委托,或你显式调用 |
| Hooks | 在事件上运行脚本(例如,在文件保存时 lint) | 在特定工具事件上触发 |
| MCP 服务器 | 将 Claude 连接到外部工具和数据源 | Claude 根据需要调用 MCP 工具 |
Skills 与子代理:Skills 向当前对话添加知识。子代理在具有自己工具的单独上下文中运行。使用 Skills 获得指导和标准;当你需要隔离或不同的工具访问时使用子代理。
Skills 与 MCP :Skills 告诉 Claude 如何 使用工具;MCP 提供工具。例如,MCP 服务器将 Claude 连接到你的数据库,而 Skill 教 Claude 你的数据模型和查询模式。
Skills的工作原理
Skills 是一种基于文件系统架构支持的渐进式披露,渐进式披露确保任何给定时间只有相关内容占据上下文窗口。
Skills 是模型调用的,用户不需要显示调用 Skills。当请求与其描述相匹配时,Agent 会自动应用相关 Skills。当一个请求发送给 Claude 时,Claude 遵循以下步骤来查找和使用相关 Skills:
- 发现
- 在启动时,Claude 近加载每个可用 Skill的名称和描述(就是写在
SKILL.md文件的开头的),这种方法让 Claude 恰到好处的知道如何使用每个 Skill,又不会消耗太多的 Token。
- 在启动时,Claude 近加载每个可用 Skill的名称和描述(就是写在
- 激活
- 当请求与 Skill 描述相匹配时,Claude 要求使用 Skill,用户会看到一个确认提示。因为 Claude 读取 Skill 的描述来查找 SKills,编写描述时要准确匹配 Skill 的能力,并且应包含用户自然说出的关键字,否则 Claude 无法识别到 Skill,或者加载错误的 Skill。
- 执行
- Claude 会根据
SKILL.md的内容,按需加载引用的文件或运行的脚本
- Claude 会根据
三种数据类型,三种加载级别
Skills 包含三种类型的内容,也对应了三种加载级别:
| 级别 | 加载时间 | 令牌成本 | 内容 |
|---|---|---|---|
| Level 1:元数据 | 始终(启动时) | 每个 Skill 约 100 个令牌 | YAML 前置数据中的 name 和 description |
| Level 2:指令 | 触发 Skill 时 | 不到 5k 个令牌 | 包含指令和指导的 SKILL.md 主体 |
| Level 3+:资源 | 按需 | 实际上无限制 | 通过 bash 执行的捆绑文件,不将内容加载到上下文中 |
Level 1: 元数据 (始终加载)
内容类型:指令。
这个信息由 SKILL.md 的前置数据 YAML 中定义的 Name 和 description 提供,以加载 PDF 处理 SKill 为例:
markdown
---
name: pdf-processing
description: 从 PDF 文件中提取文本和表格、填充表单、合并文档。在处理 PDF 文件或用户提及 PDF、表单或文档提取时使用。
---
Level 2: 指令 (触发时加载)
内容类型:指令。
SKILL.md 主体内容包含程序知识:工作流、最佳实践和指导。
markdown
# PDF 处理
## 快速入门
使用 pdfplumber 从 PDF 中提取文本:
```python
import pdfplumber
with pdfplumber.open("document.pdf") as pdf:
text = pdf.pages[0].extract_text()
```
有关高级表单填充,请参阅 [FORMS.md](FORMS.md)。当用户确认使用某个 Skill 后, Claude 使用 bash 从文件系统中读取完整的 SKILL.md。
Level 3: 资源和代码 (按需加载)
复杂的 Skill,无法全部信息都写在一个
SKILL.md文件中 ,所以就需要额外的上下文(参考文档、代码)拆分到目录下的其他文件中。
内容类型:指令、代码和资源。
pdf-skill/
├── SKILL.md (主要指令)
├── FORMS.md (表单填充指南)
├── REFERENCE.md (详细 API 参考)
└── scripts/
└── fill_form.py (实用脚本)- 指令:包含专业指导和工作流的其他 markdown 文件(FORMS.md、REFERENCE.md)
- 代码:Claude 通过 bash 运行的可执行脚本(fill_form.py、validate.py);脚本提供确定性操作而不消耗上下文
- 资源:参考资料,如数据库架构、API 文档、模板或示例
当 Claude 开始使用某个 Skill时,它会根据 SKILL.md 主体内容信息匹配用户请求,按需的加载其他资源或代码。

Skills 和上下文窗口
当用户发出请求时,技能的触发和加载过程会动态地改变代理的上下文窗口。以下是典型的操作序列:
- 首先,上下文窗口会显示核心系统提示符和每个已安装技能的元数据,以及用户的初始消息;
- Claude 通过调用 Bash 工具来读取 PDF 文件的内容,从而触发 PDF 技能
pdf/SKILL.md; - 根据
SKILL.md中的指令,Claude 决定读取与技能捆绑的附加文件,例如forms.md - 最后,Claude 从 PDF 技能中加载了相关说明后,便开始执行用户的任务。

Skills 和代码执行
Skill 还会包含提供给 Claude 自动执行的代码,作为工具。并且这个信息,不一定是在 SKILL.md 文件中,可能是在其他资源文件中,如:forms.md。
在官方示例中,PDF 技能包含一个预先编写的 Python 脚本,该脚本读取 PDF 文件并提取所有表单字段。Claude 无需将脚本或 PDF 文件加载到上下文中即可运行此脚本。由于代码是确定性的,因此该工作流程具有一致性和可重复性。
技能发展与评估
以下是一些有助于入门写作和测试技能的实用指南:
- 从评估开始:通过让代理在具有代表性的任务上运行并观察它们在何处表现不佳或需要额外上下文,找出具体能力缺口。然后逐步构建技能以解决这些不足。
- 为规模化设计结构 :当
SKILL.md文件变得难以管理时,将其内容拆分到多个文件并进行引用。如果某些上下文是互斥的或很少同时使用,保持它们的路径分离可以减少令牌(token)使用量。最后,代码既可以作为可执行工具,也可以作为文档。应明确指出 Claude 是直接运行脚本,还是将脚本作为参考读入上下文。 - 站在 Claude 的角度思考:监测 Claude 在真实场景中如何使用你的技能,并根据观察进行迭代:注意是否出现意料之外的路径或对某些上下文的过度依赖。特别注意技能的名称和描述,因为 Claude 在决定是否在当前任务中触发该技能时会参考它们。
- 与 Claude 一起迭代:在与 Claude 一起处理任务时,请求 Claude 将其成功的方法和常见错误记录为技能中可重用的上下文和代码。如果在使用某个技能完成任务时偏离了目标,请让它自我反思出错的原因。这个过程将帮助你发现 Claude 实际需要的上下文,而不是试图事先全部预测。