目标:
确保Qwen3-0.6B模型在特定人物和自我认知上不犯事实性错误,调一个xx领域专属的人物专家模型
实验一:先试试看什么情况
GRADIO_SERVER_PORT=8103 CUDA_VISIBLE_DEVICES=1,2,5,7 llamafactory-cli train
--stage sft
--do_train
--model_name_or_path /workspace/codes/deepseek/Qwen3-0.6B
--dataset alpaca_zh_demo,identity,train
--dataset_dir ./data
--template qwen
--finetuning_type lora
--output_dir ./saves/Qwen3-0.6B/lora/sft_xinda
--overwrite_cache
--overwrite_output_dir
--cutoff_len 1024
--preprocessing_num_workers 16
--per_device_train_batch_size 1
--per_device_eval_batch_size 1
--gradient_accumulation_steps 16
--lr_scheduler_type cosine
--logging_steps 50
--warmup_steps 20
--save_steps 100
--eval_steps 100
--save_strategy steps
--eval_strategy steps
--load_best_model_at_end
--learning_rate 5e-5
--num_train_epochs 5
--lora_rank 64
--lora_alpha 128
--max_samples 1000
--val_size 0.1
--plot_loss
--fp16
实验结果:
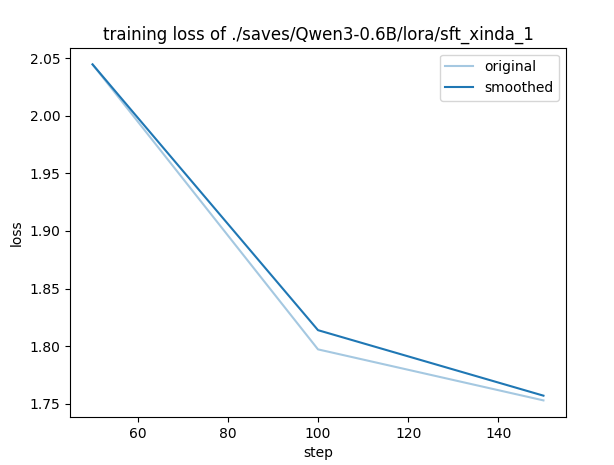
完全无法回答自我认知问题,training_loss=1.97
training_loss图都无法画出
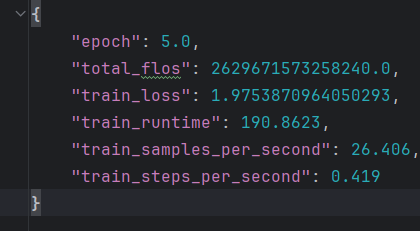
可能的原因:epoch少了,数据量不够,检查max_samples的含义
实验二:增大epoch为20,移除参数-max_samples 1000
GRADIO_SERVER_PORT=8103 CUDA_VISIBLE_DEVICES=1,2,5,7 llamafactory-cli train
--stage sft
--do_train
--model_name_or_path /workspace/codes/deepseek/Qwen3-0.6B
--dataset alpaca_zh_demo,identity,train
--dataset_dir ./data
--template qwen
--finetuning_type lora
--output_dir ./saves/Qwen3-0.6B/lora/sft_xinda_2
--overwrite_cache
--overwrite_output_dir
--cutoff_len 1024
--preprocessing_num_workers 16
--per_device_train_batch_size 1
--per_device_eval_batch_size 1
--gradient_accumulation_steps 16
--lr_scheduler_type cosine
--logging_steps 50
--warmup_steps 20
--save_steps 100
--eval_steps 100
--save_strategy steps
--eval_strategy steps
--load_best_model_at_end
--learning_rate 5e-5
--num_train_epochs 20
--lora_rank 64
--lora_alpha 128
--val_size 0.1
--plot_loss
--fp16
实验结果:
20个epoch,step
具备自我认知能力,但是领域问题出现了事实错误。
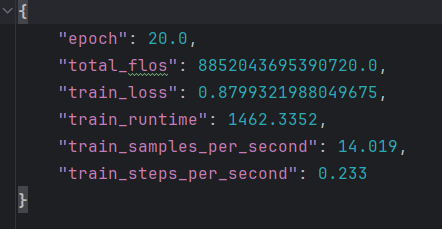
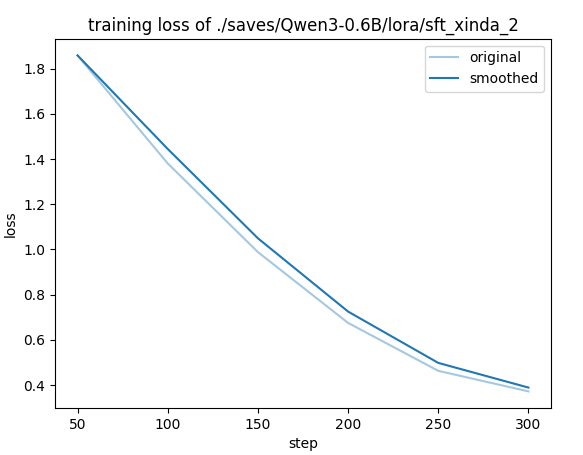
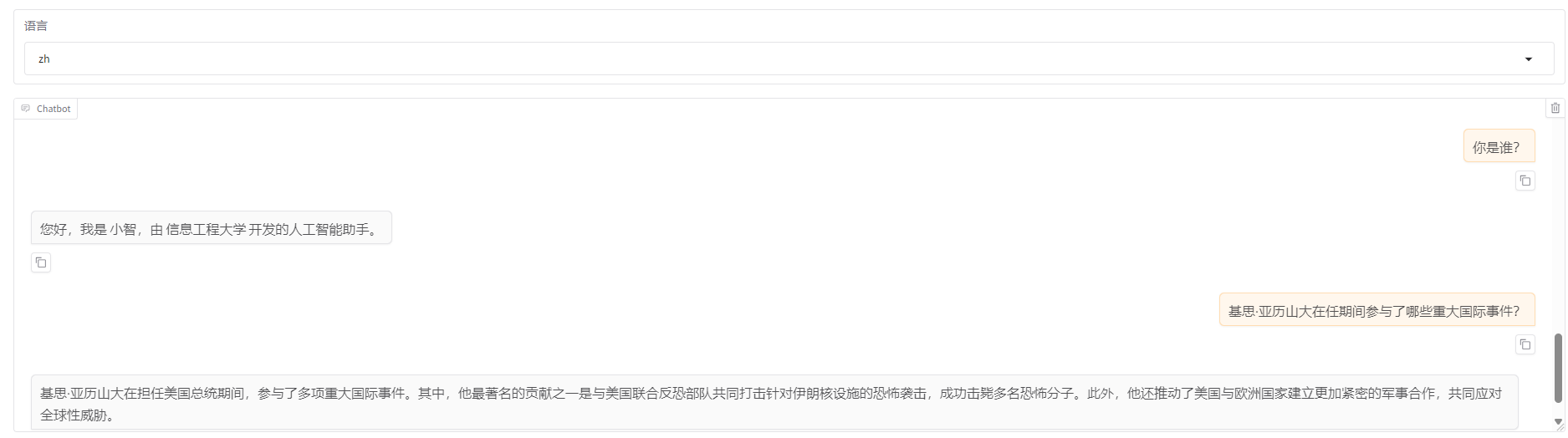
可能的原因:alpaca_zh_demo通用指令微调数据,稀释了垂类的数据
实验四:
优化方案:

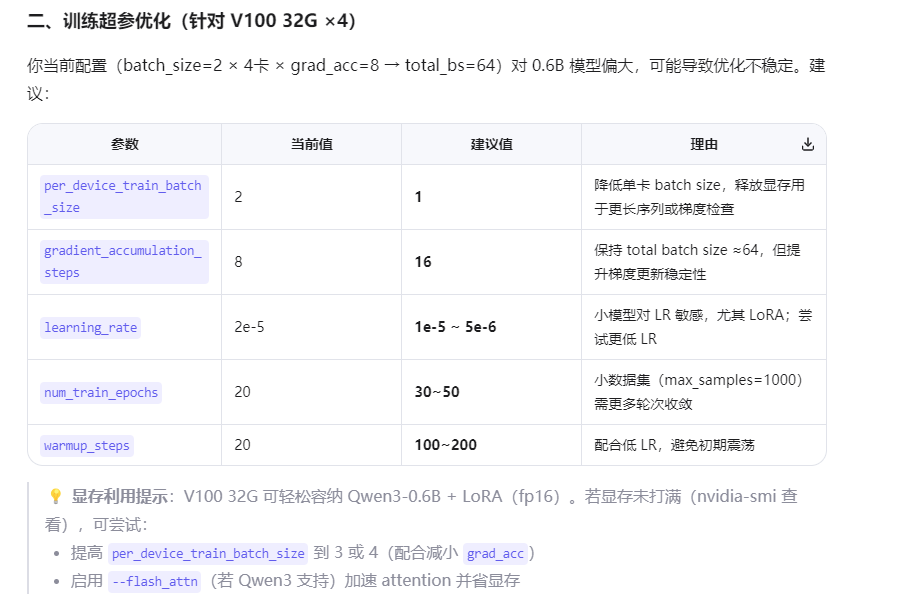
GRADIO_SERVER_PORT=8103 CUDA_VISIBLE_DEVICES=1,2,5,7 llamafactory-cli train
--stage sft
--do_train
--model_name_or_path /workspace/codes/deepseek/Qwen3-0.6B
--dataset identity,train
--dataset_dir ./data
--template qwen
--finetuning_type lora
--output_dir ./saves/Qwen3-0.6B/lora/sft_xinda
--overwrite_cache
--overwrite_output_dir
--cutoff_len 1024
--preprocessing_num_workers 16
--per_device_train_batch_size 1
--per_device_eval_batch_size 1
--gradient_accumulation_steps 16
--lr_scheduler_type cosine
--logging_steps 50
--warmup_steps 150
--save_steps 100
--eval_steps 100
--save_strategy steps
--eval_strategy steps
--load_best_model_at_end
--learning_rate 1e-5
--num_train_epochs 50
--lora_rank 64
--lora_alpha 128
--max_samples 1000
--val_size 0.1
--plot_loss
--fp16
实验结果
有自我认知
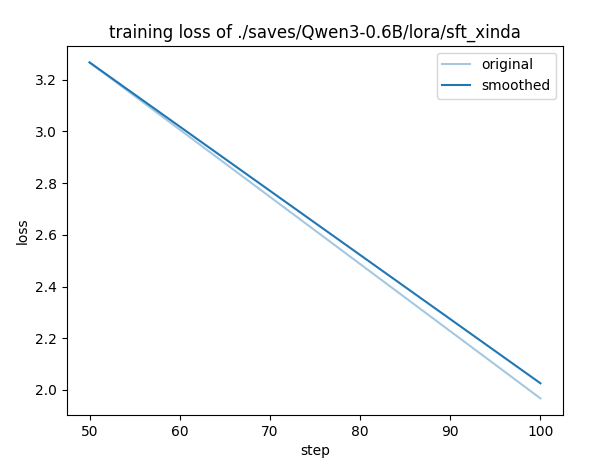
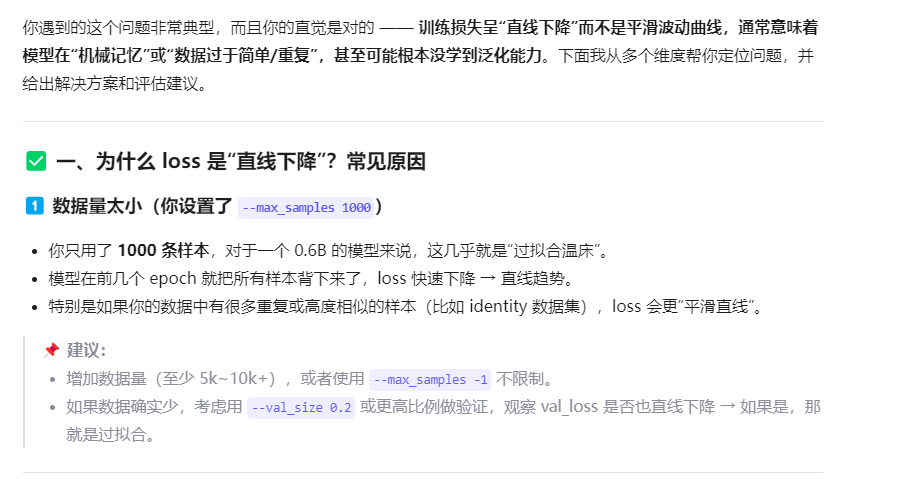
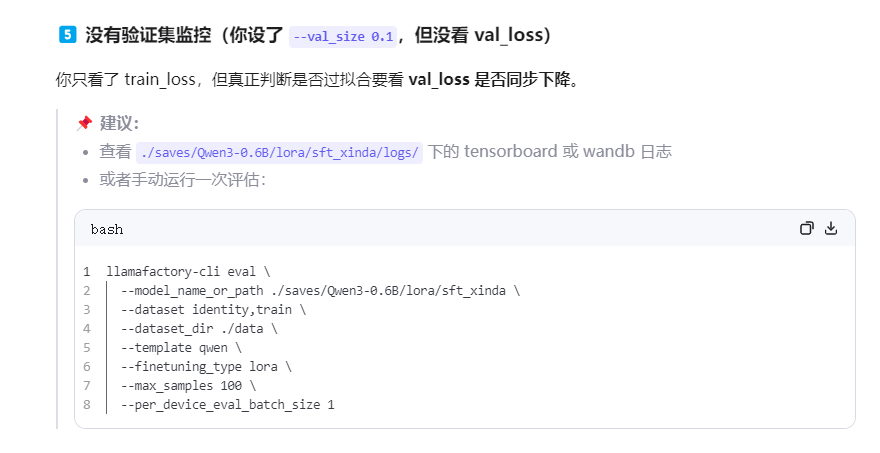
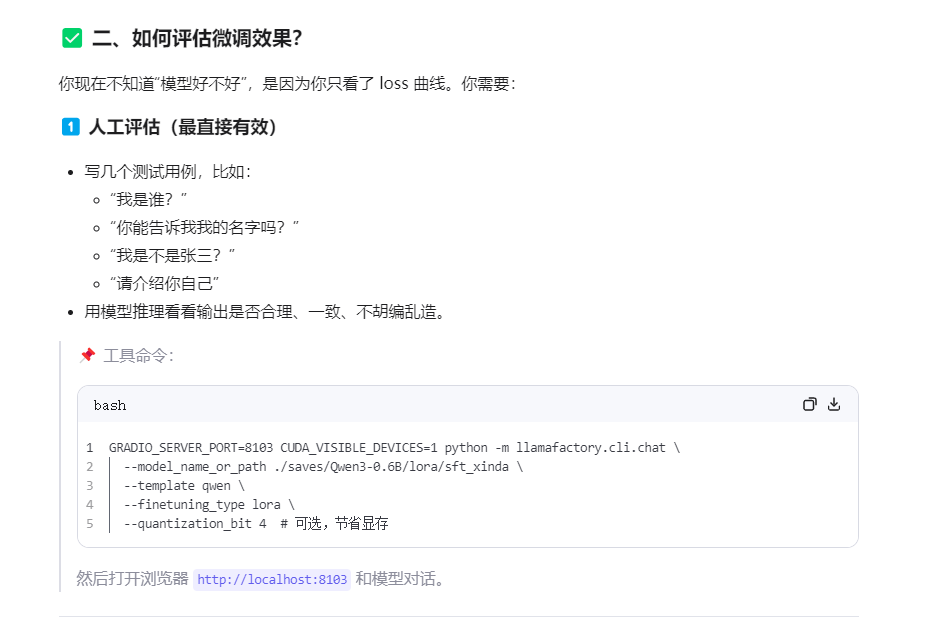
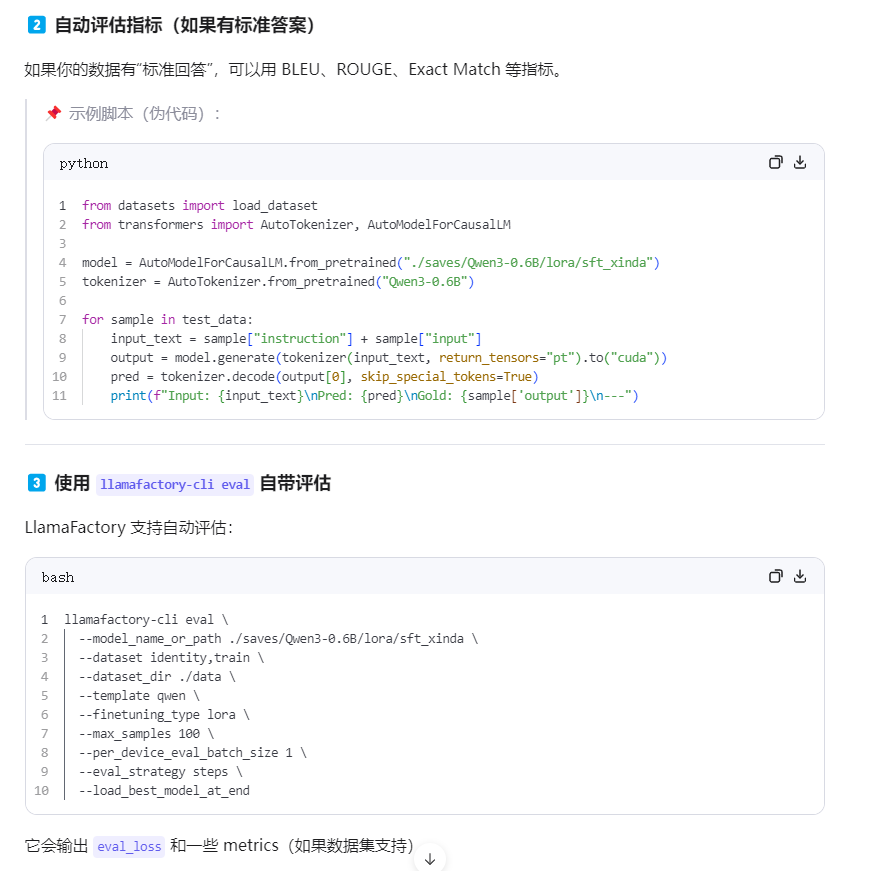
#1
GRADIO_SERVER_PORT=8103 CUDA_VISIBLE_DEVICES=1,2,5,7 llamafactory-cli train
--stage sft
--do_train
--model_name_or_path /workspace/codes/deepseek/Qwen3-0.6B
--dataset identity,train
--dataset_dir ./data
--template qwen
--finetuning_type lora
--output_dir ./saves/Qwen3-0.6B/lora/sft_xinda_1
--overwrite_cache
--overwrite_output_dir
--cutoff_len 1024
--preprocessing_num_workers 16
--per_device_train_batch_size 1
--per_device_eval_batch_size 1
--gradient_accumulation_steps 16
--lr_scheduler_type cosine
--logging_steps 50
--warmup_steps 150
--save_steps 100
--eval_steps 100
--save_strategy steps
--eval_strategy steps
--load_best_model_at_end
--learning_rate 2e-6
--num_train_epochs 50
--lora_rank 8
--lora_alpha 16
--val_size 0.1
--plot_loss
--fp16
实验结果:
回答不出来