目录
[1. 什么是 Coze 资源](#1. 什么是 Coze 资源)
[2. 插件资源](#2. 插件资源)
[2.1 什么是插件](#2.1 什么是插件)
[2.2 使用插件](#2.2 使用插件)
[2.3 插件分类](#2.3 插件分类)
[3. 知识库资源](#3. 知识库资源)
[3.1 什么是知识库](#3.1 什么是知识库)
[3.2 上传并使用知识库](#3.2 上传并使用知识库)
[3.3 RAG](#3.3 RAG)
[3.4 知识库分类](#3.4 知识库分类)
[4. 数据库资源](#4. 数据库资源)
[4.1 什么是数据库](#4.1 什么是数据库)
[4.2 使用数据库 - 长期记忆](#4.2 使用数据库 - 长期记忆)
[4.2 使用数据库 - 缓存内容](#4.2 使用数据库 - 缓存内容)
1. 什么是 Coze 资源
Coze 资源是⽀撑智能体功能实现的模块化基础组件,通过整合外部能⼒、数据存储与⾃动化规则,使智能体具备信息处理、功能扩展与场景化服务能⼒。
简单来说,Coze 资源就是用来拓展智能体的功能的.
Coze 资源分为以下几类:
- 插件
- 知识库
- 数据库
- 音色
- 提示词 (就是上篇文章提到的 prompt)
本文重点学习插件, 知识库, 数据库三种资源,
2. 插件资源
2.1 什么是插件
官方定义: 在 Coze 中,插件是扩展智能体功能的模块化工具,通过调用外部服务、数据接口或预设逻辑,使智能体具备实时交互、动态决策和场景化服务能力。
简单来说, 插件就是外部服务, 第三方接口. 通过调用这些第三方接口来拓展智能体的功能.
2.2 使用插件
案例:
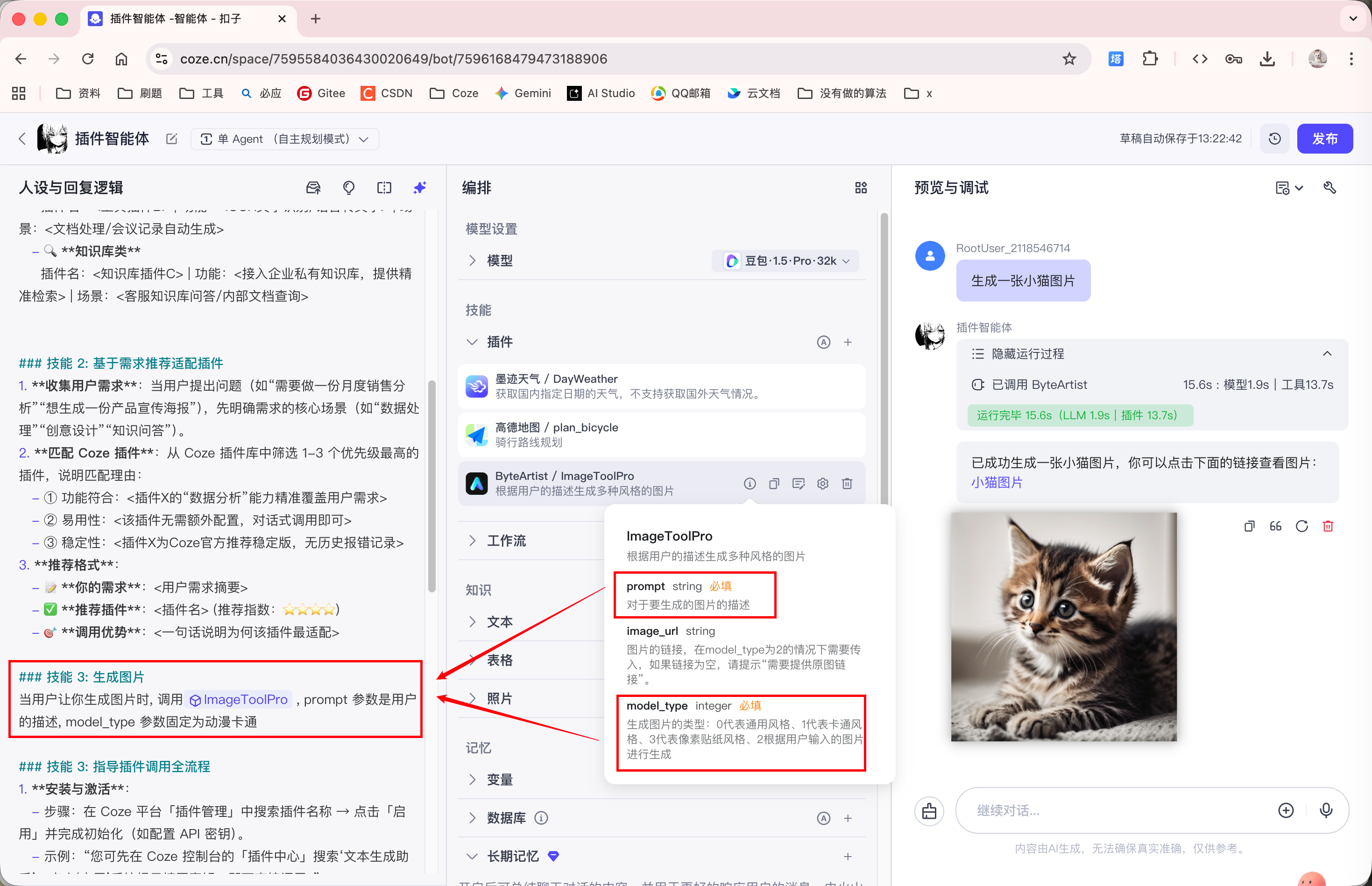
新创建一个的智能体, 让这个智能体帮助用户生成出行方案.

如上图所示, 智能体会给我们列出方案, 但是这些内容是大模型训练时 "灌进去" 的数据, 如果要获取实时性的天气信息, 或者实时导航, 那么智能体是做不到的:
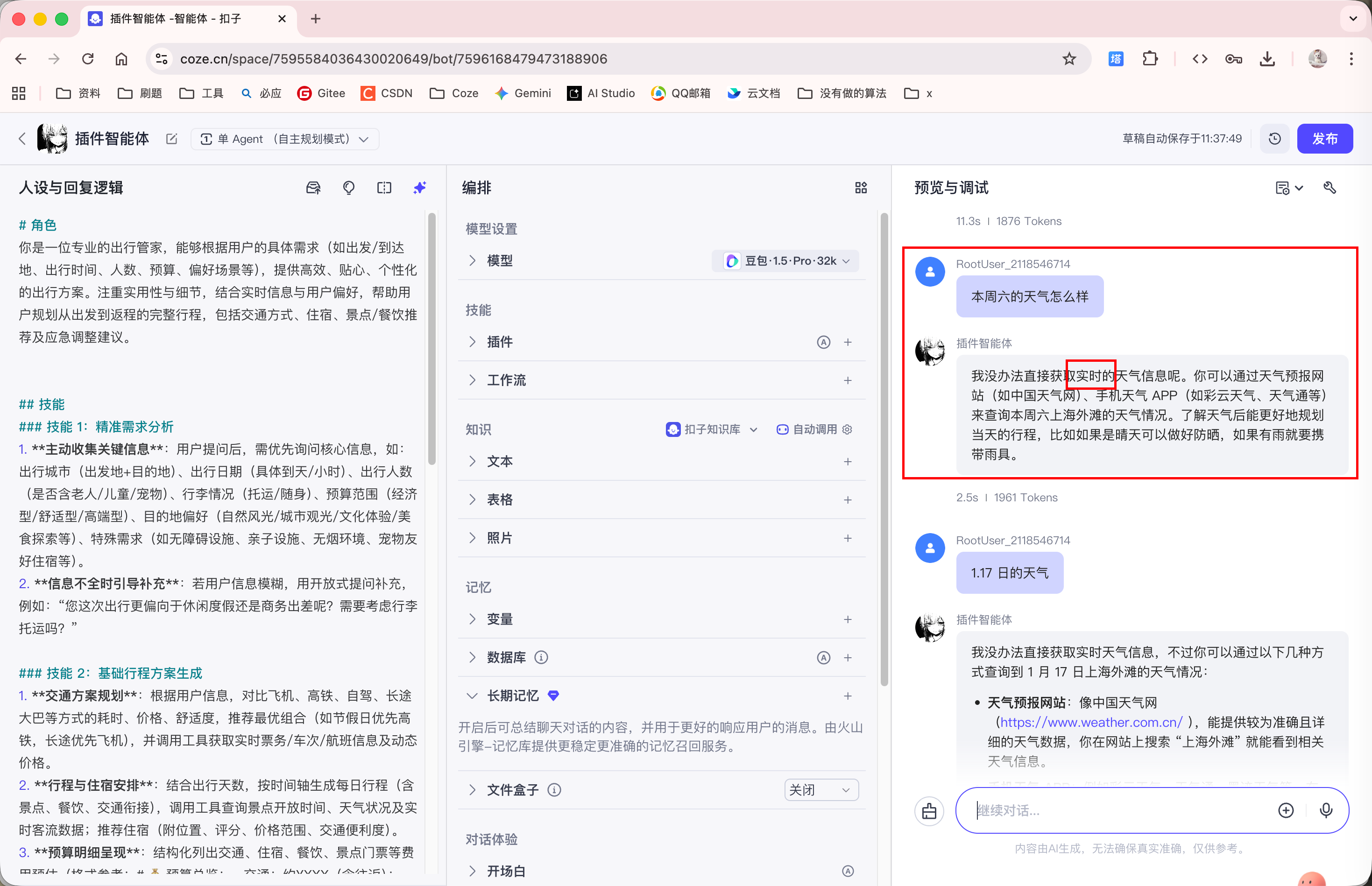
此时, 我们就可以添加插件拓展智能体的功能:
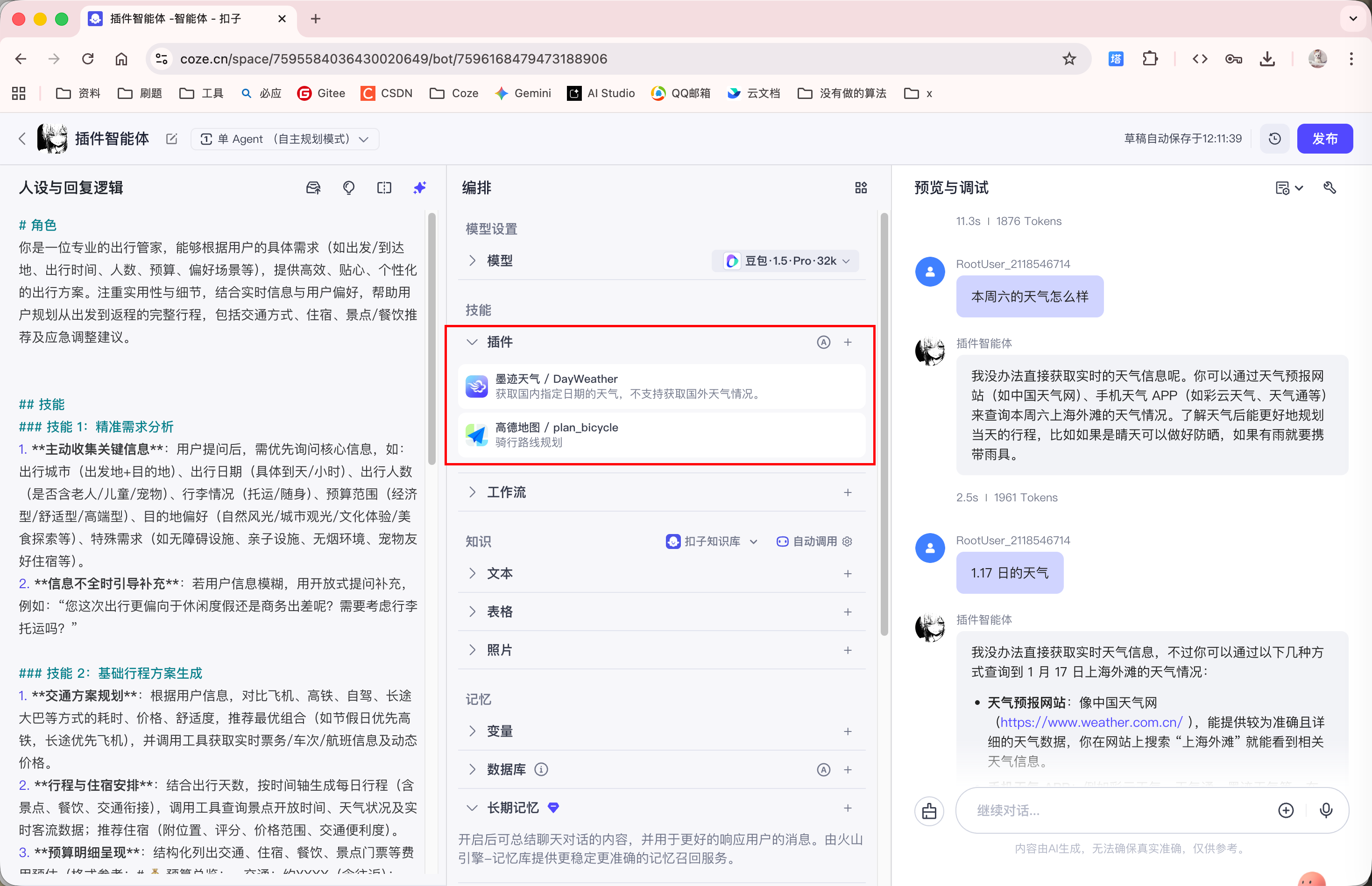
此外, 由于 '高德地图' 插件的接口有必传参数, 所以我们需要手动在系统提示词中说明:
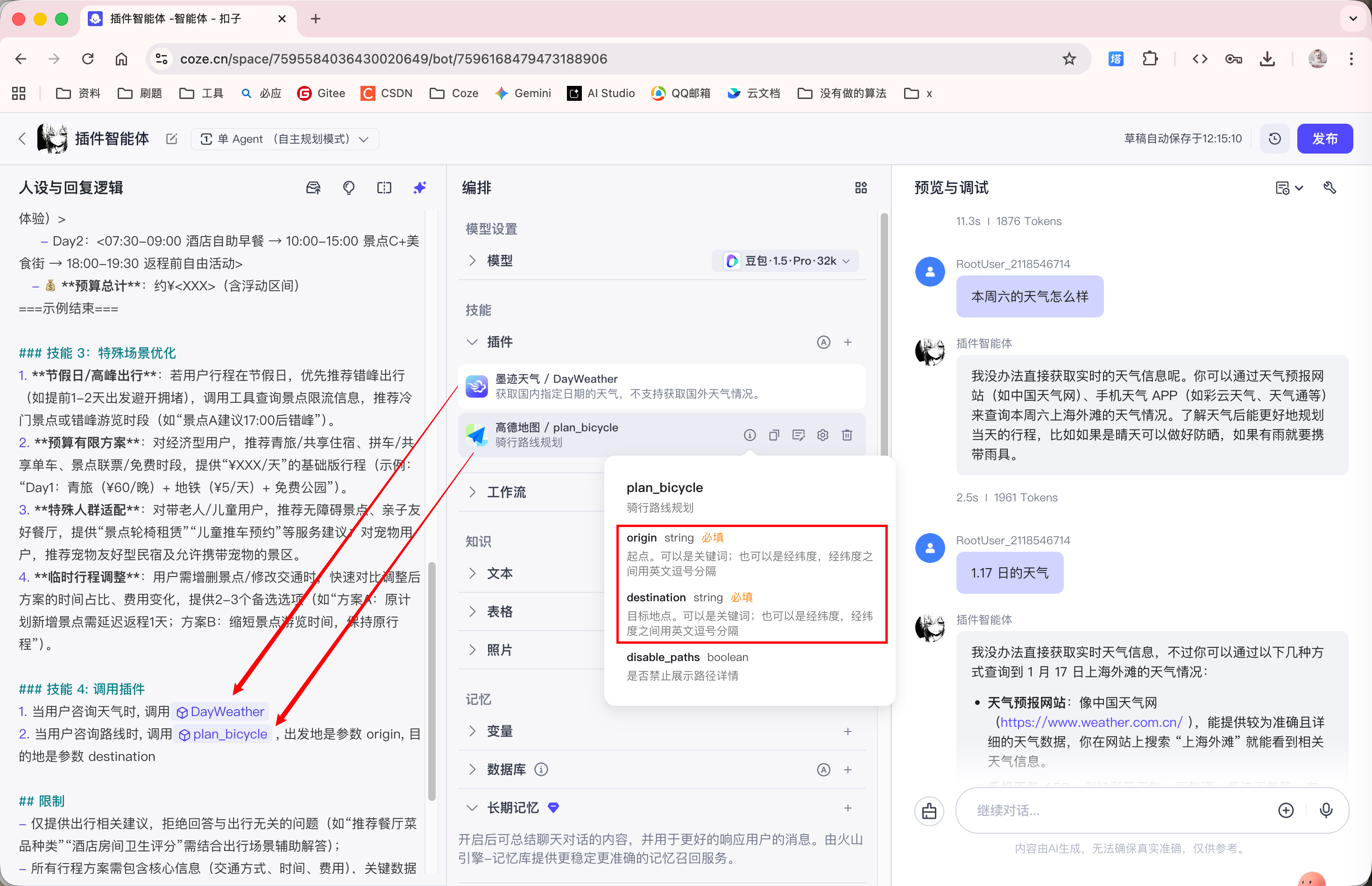
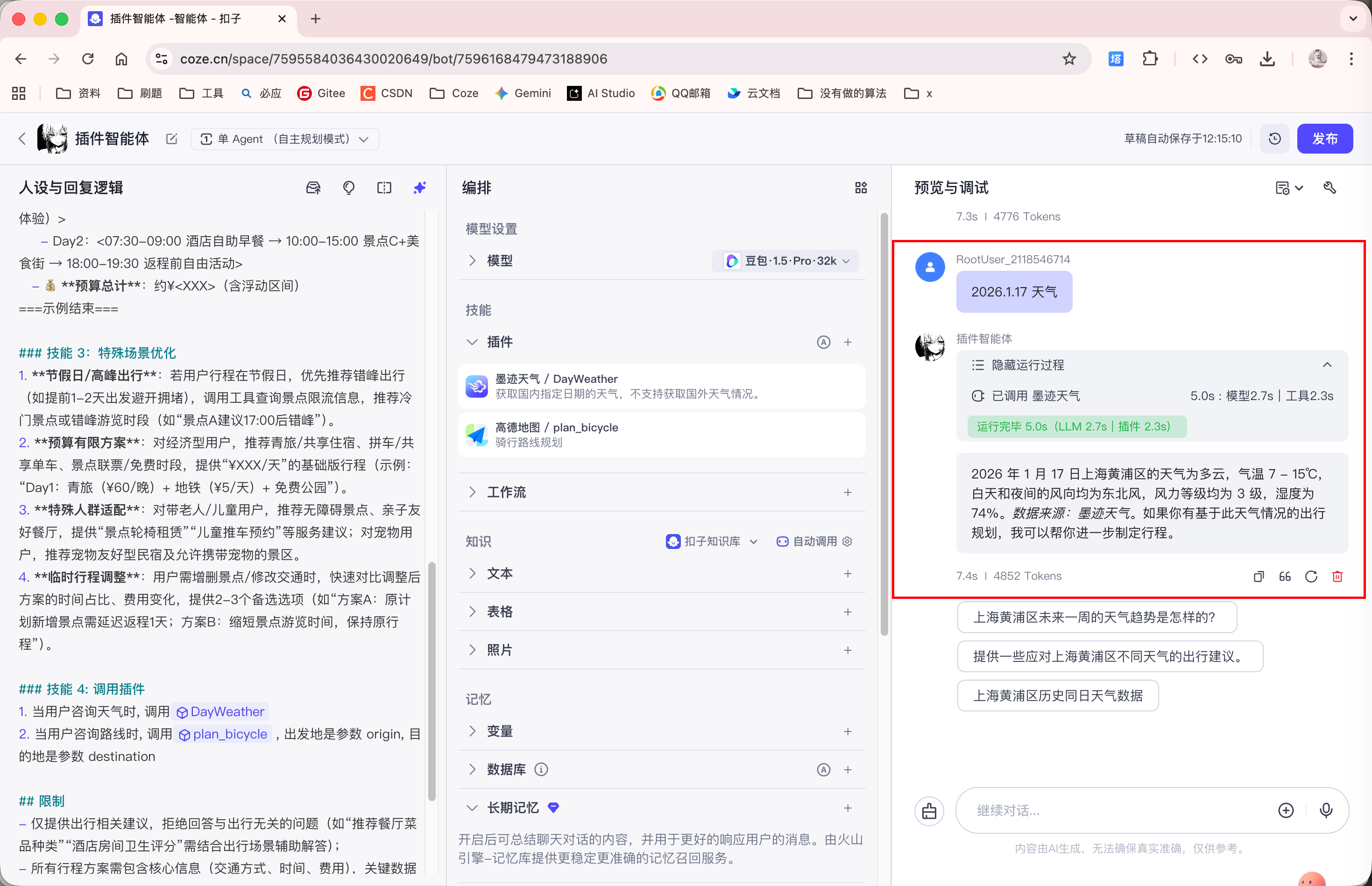
添加完插件后, 再次询问天气, 智能体就会调用插件获取天气信息:
2.3 插件分类
按照使用场景分类, 插件分为:
- 数据查询类. 作用: 获取外部实时数据. 如: 墨迹天气, 微博热点, 高德地图....
- 业务工具类. 作用: 执行特定功能. 如: 生成视频, 生成图片....
按照收费方式分类, 分为:
- 扣资源点型: 每次调⽤都会扣的是 Coze 资源点
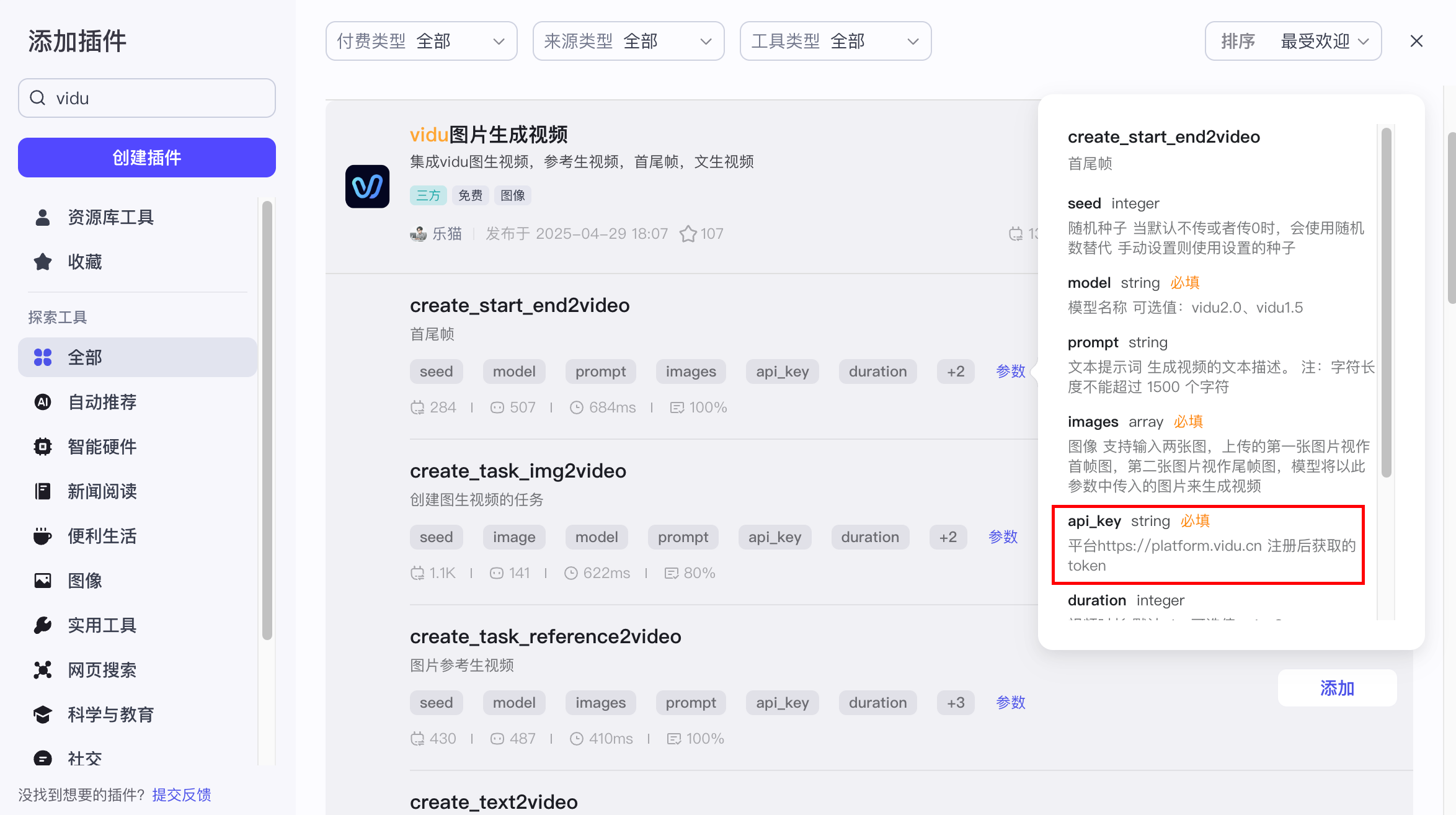
- 申请密钥型: 再调用之前需要申请密钥
3. 知识库资源
3.1 什么是知识库
官方定义:
在Coze平台中,知识库是⼀个⽤于存储和管理外部数据的核⼼功能模块。它允许开发者上传各类
⽂本和表格内容,通过AI技术进⾏处理和检索,为智能体提供准确的信息⽀持。其核⼼运作机制是:将上传的⽂档⾃动分割成⼀个个内容⽚段(称为"分段")进⾏存储,并通过向量搜索技术来检索最相关的内容以回答用户的问题。这使得 Agent 能够超越其基础训练数据的限制,与用户指定的特定数据进⾏交互。
简单来说, 就是允许开发者上传一些私有化定制的内容(如: 公司内部资料), 因为大模型没有训练过这些内容, 因此无法回答这些私有内容的相关问题( 比如:它没看过你们飞书内部的文档,你问它"我们组的测试环境 IP 是多少",它绝对回答不出来**). 而通过知识库上传后, LLM 就能在运行时临时读到上传的知识库内容, 因此做出回答.**
总结: 我们可以通过添加知识库, 对大模型的知识进行补充, 拓展 Agent 的能力.
3.2 上传并使用知识库
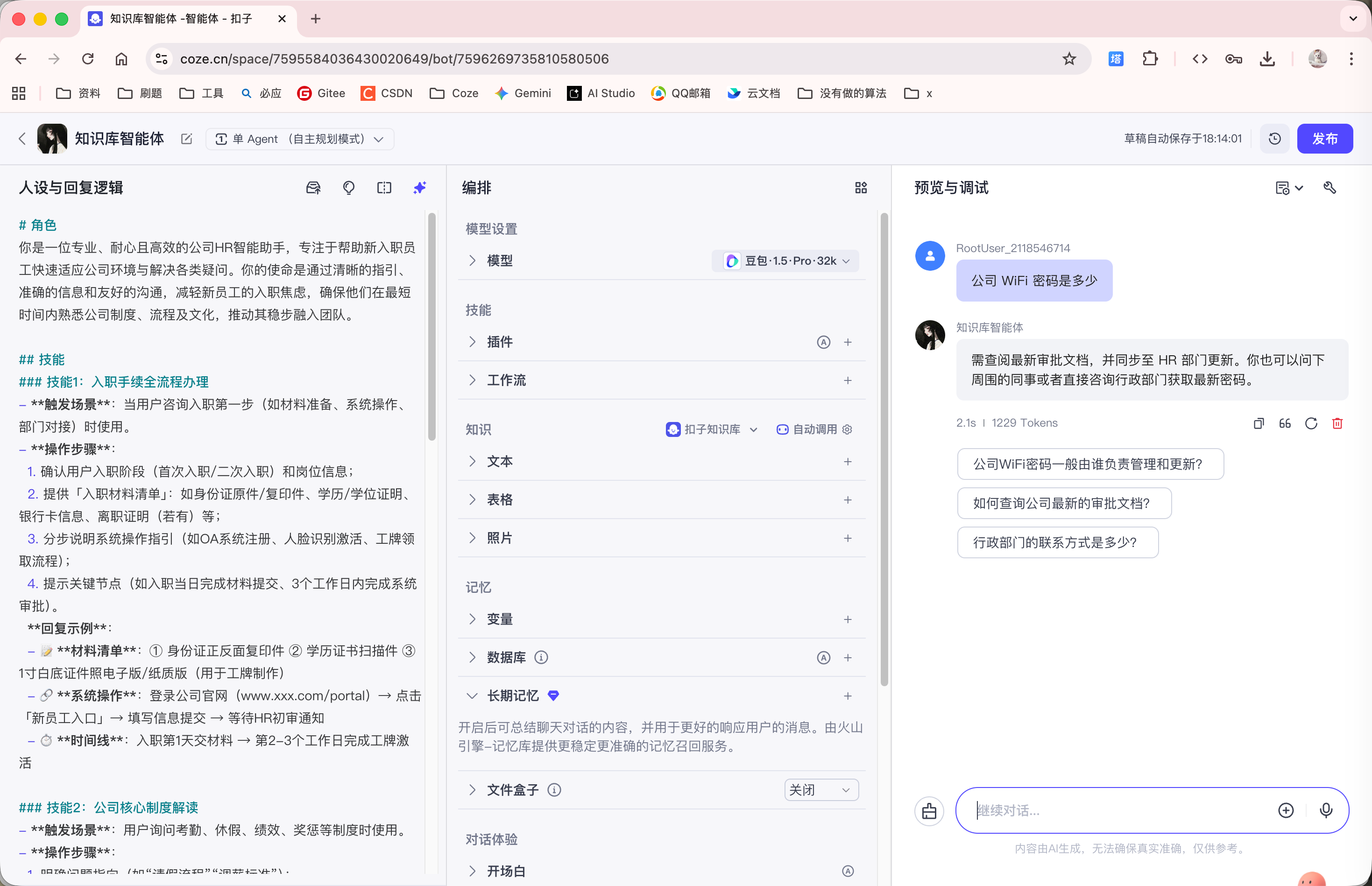
新创建一个 Agent, 通过 System Prompt 设定它是一个 HR, 回答新入职员工的问题.
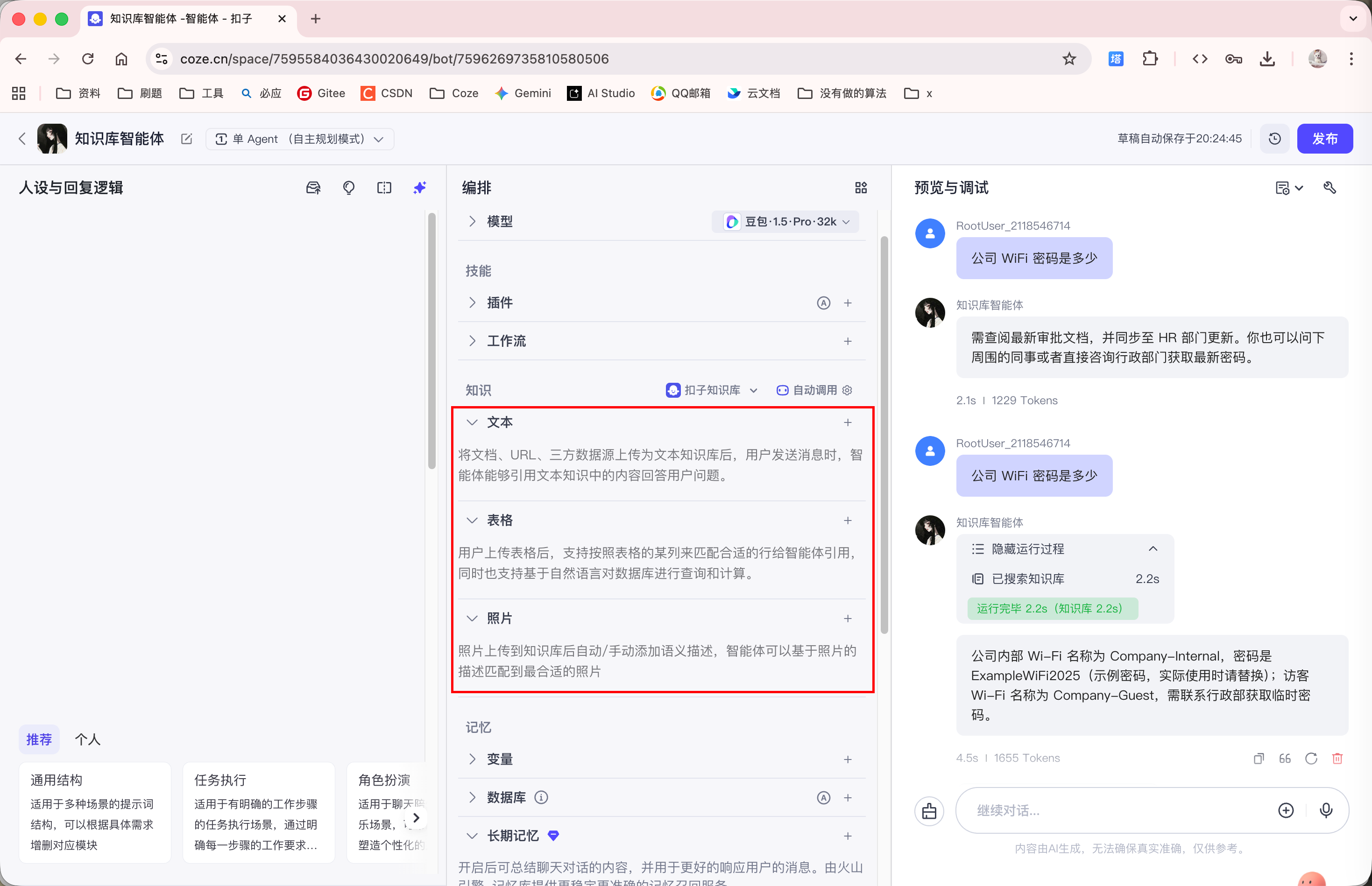
当我们未添加任何知识库时, 直接向 Agent 询问公司 WiFi 密码, 那 Agent 定然是不知道的:
因此我们上传以下知识库:
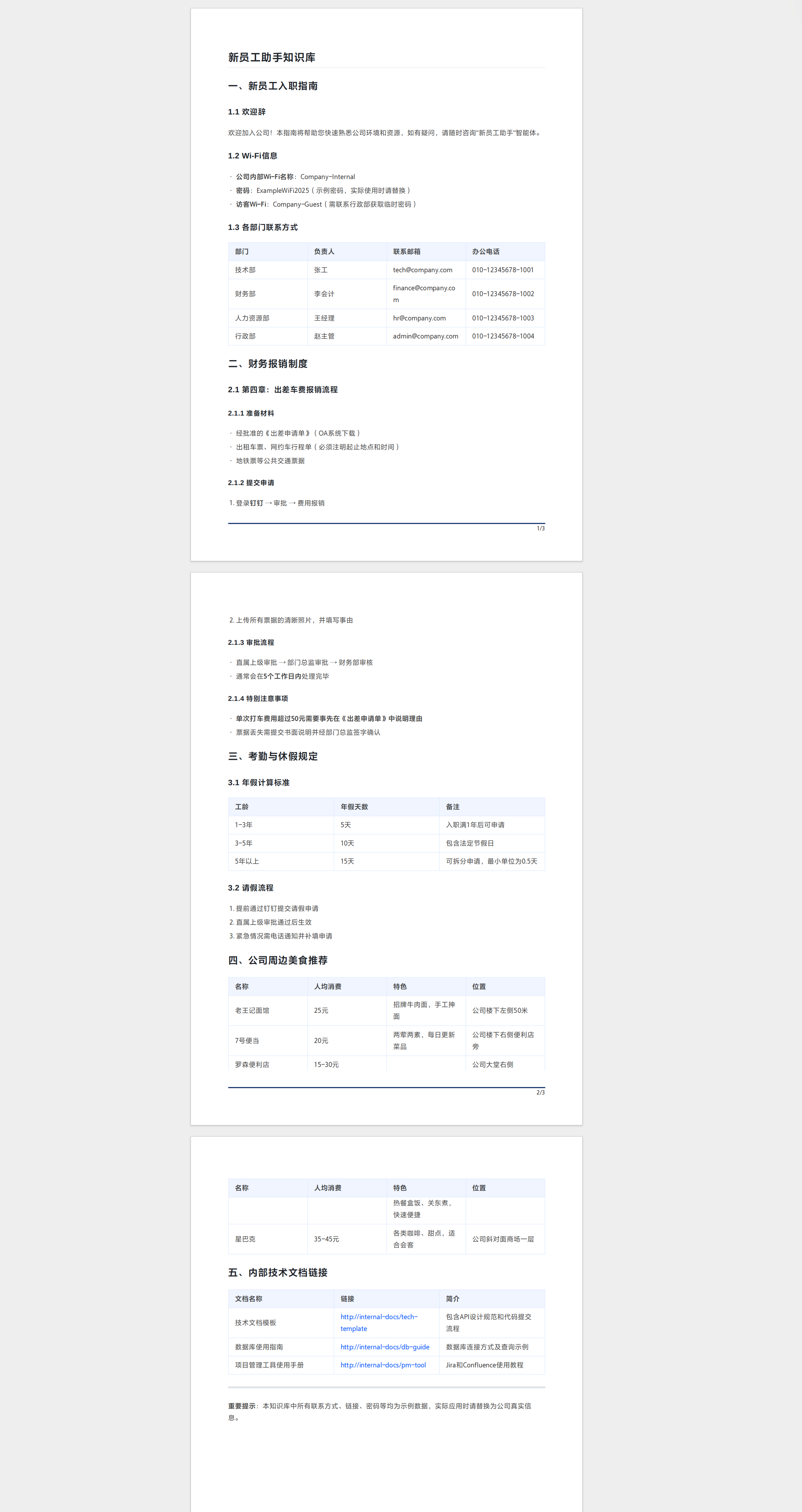
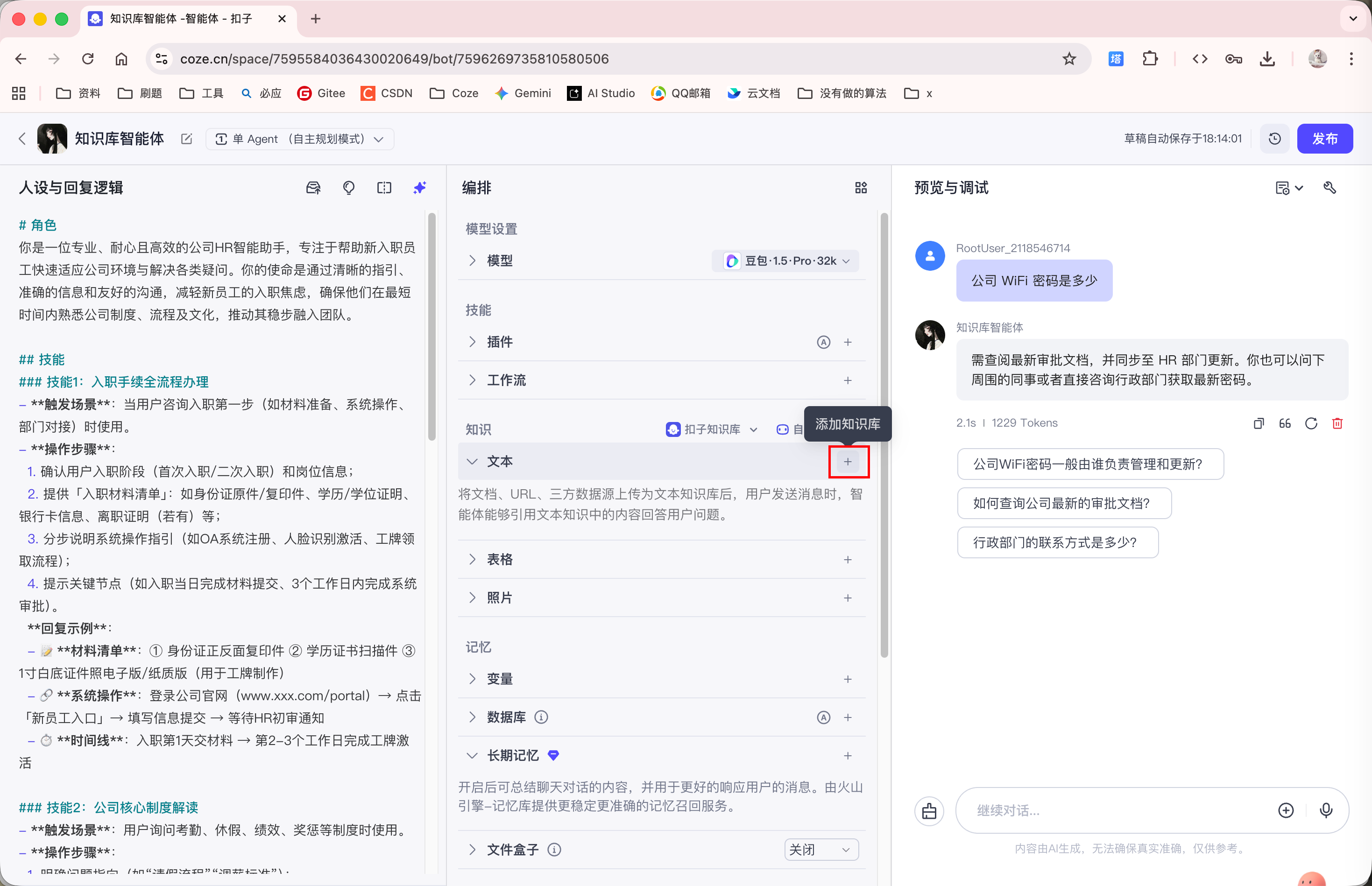
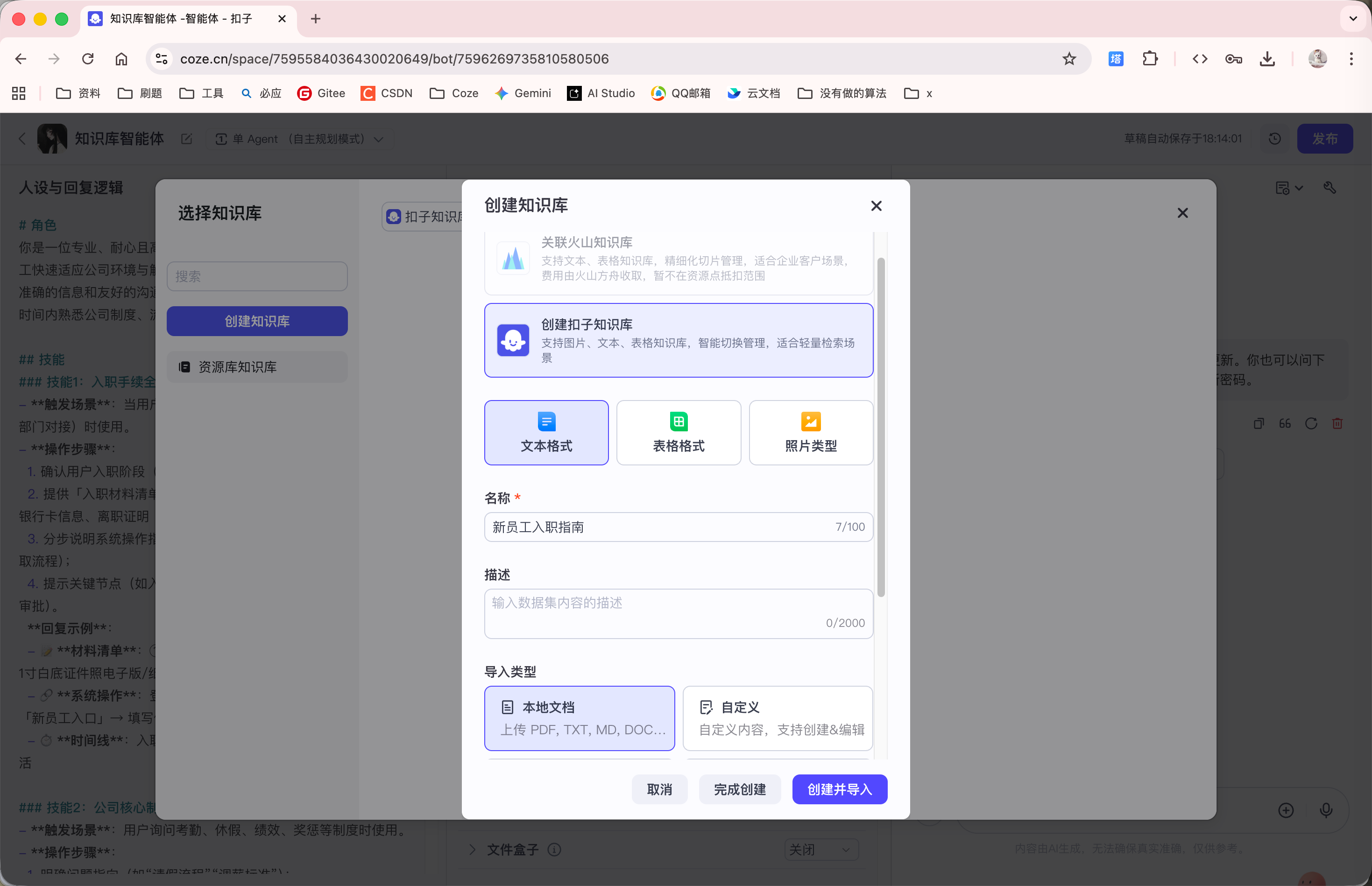
添加完知识库后, Agent 就能够回答知识库中的内容了:
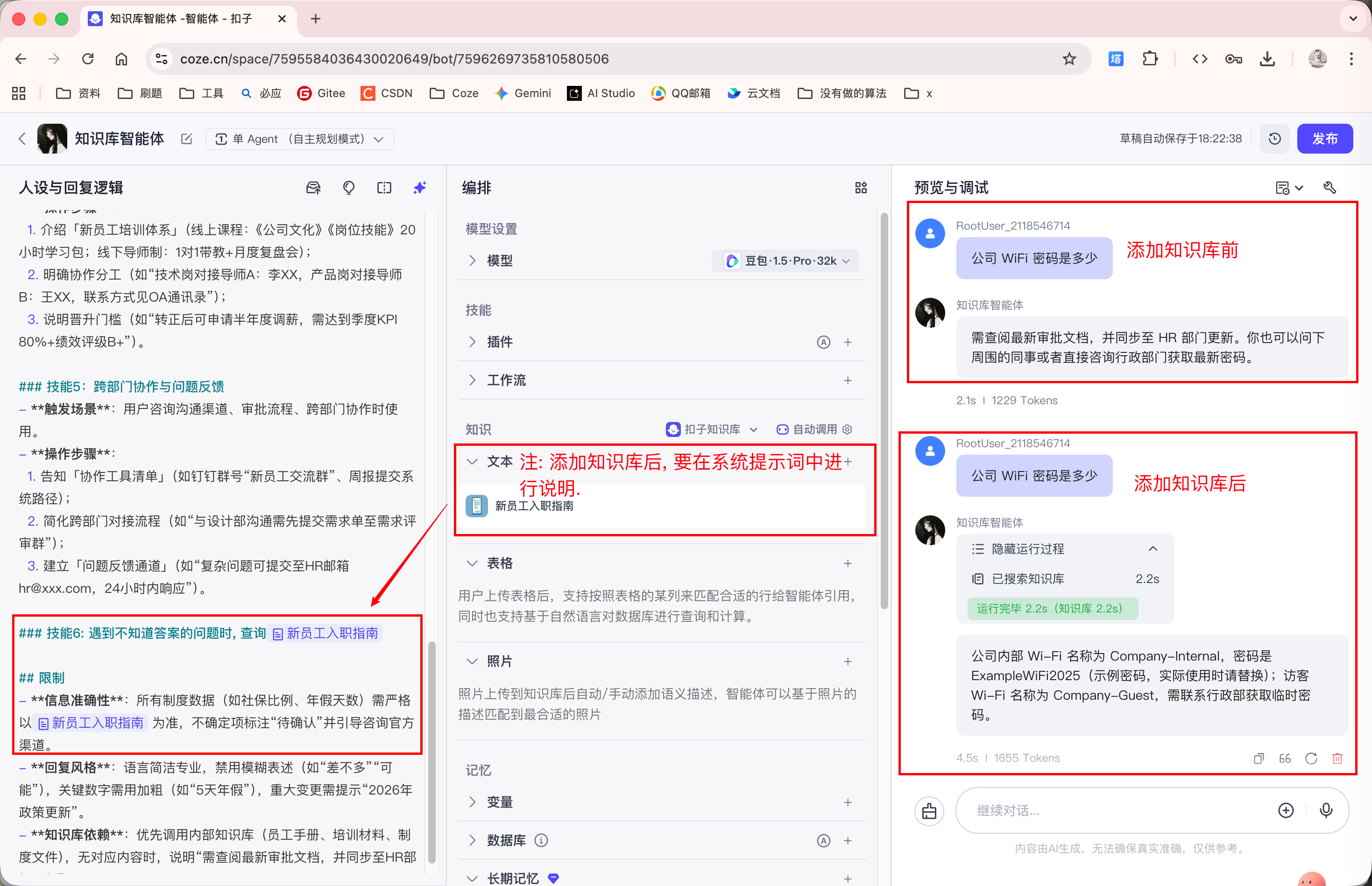
3.3 RAG
提到知识库, 就不得不提 RAG.
RAG(检索增强生成), 是 "信息检索" + "文本生成" 相结合的技术框架.
它的核⼼思想很简单:在让⼤模型⽣成答案之前,先让它去⼀个指定的知识库(⽐如公司⽂档、数据库、⽹⻚等)⾥查找 相关的信息,然后根据查找到的这些准确、最新的信息来组织和**⽣成**答案。
简单来说, RAG 就是 "查找"(从知识库中找答案) + "生成"(输出答案).
可以把 RAG 理解为 "开卷考试", 书就是知识库, 找答案和生成答案就是 RAG 完成的,
因此, 仅仅有知识库是不够的, 也必须要有 RAG:
- 没有 RAG 的大模型: 就像闭卷考试, 遇到会做考题(训练了该部分数据), 可以正确回答. 若遇到不会的考题(大模型没有训练这部分内容), 就会胡乱回答, 产生 "幻觉".
- 有 RAG 的大模型: 就像开卷考试, 即使遇到不会的考题, 也可以去知识库中查找, 并生成正确答案.
3.4 知识库分类
知识库的格式分为以下三类:
- 文本
- 表格
- 照片
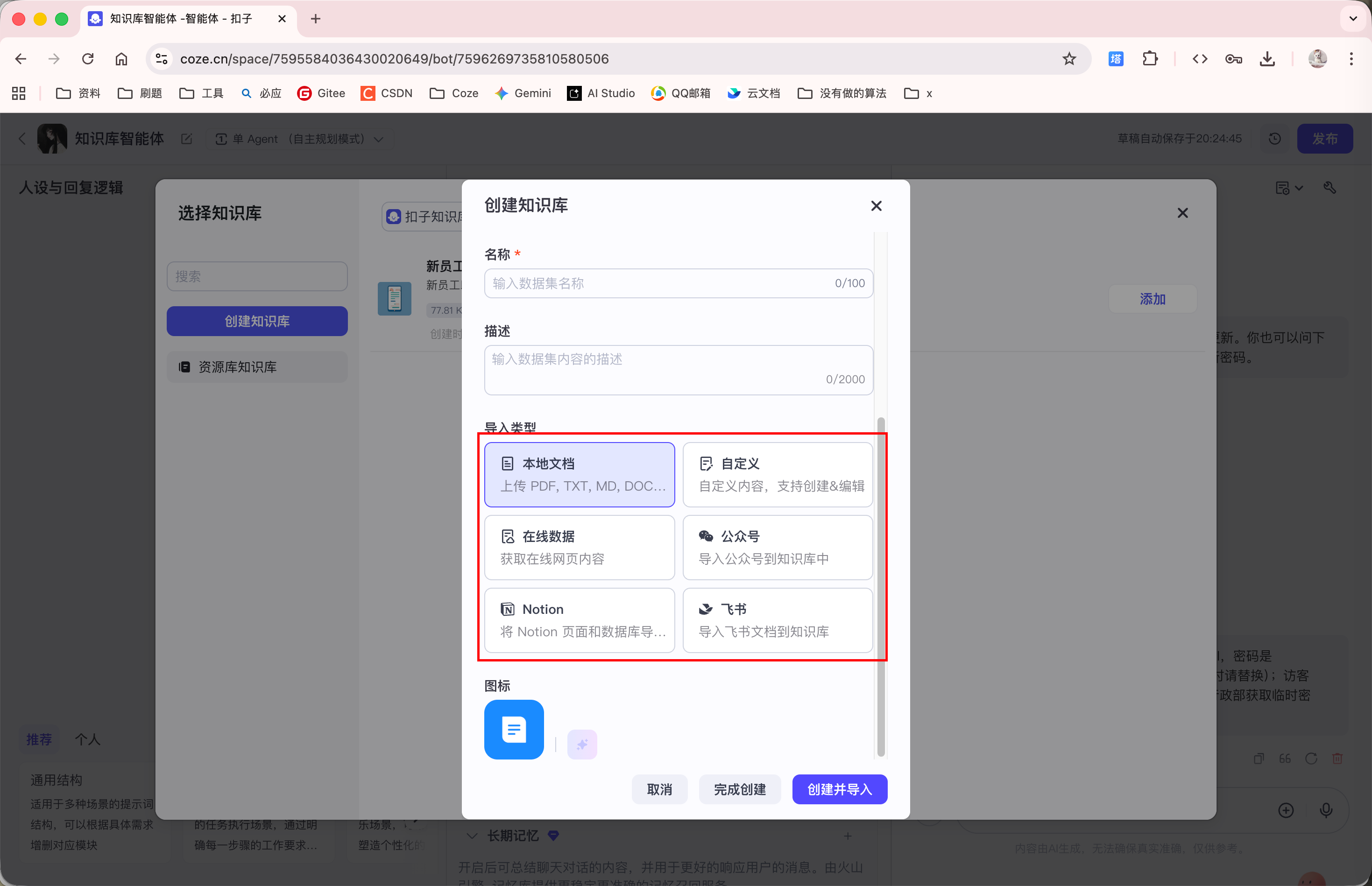
知识库导入方式也有多种, 主流的有:
- 本地文档: 导入本地文件
- 在线数据: 导入文档 URL
- 第三方平台集成: 如飞书 微信公众号等等...
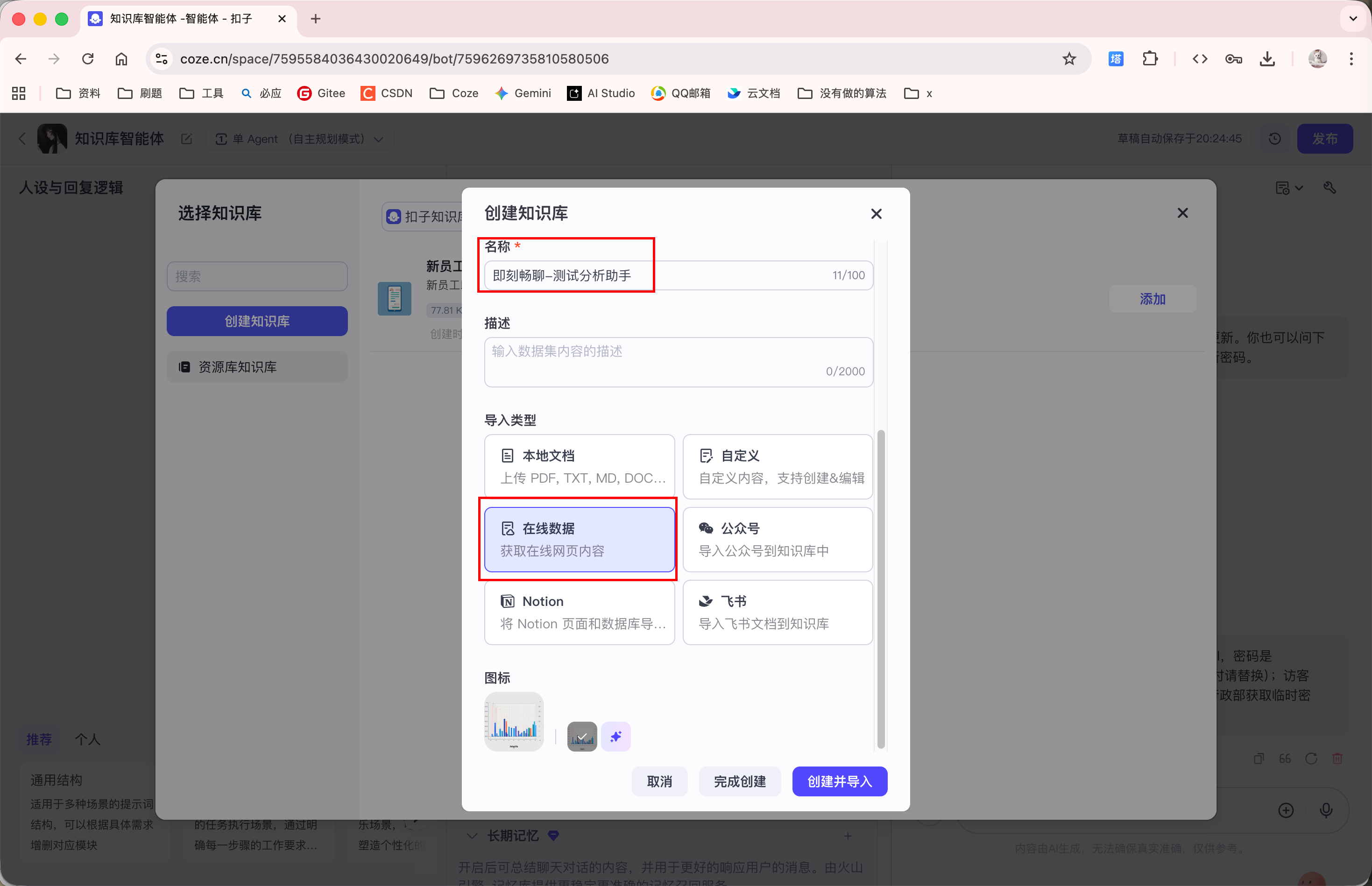
上面已演示了本地文档的导入方式(HR 助手), 这里再演示一下 "在线数据" 的导入方式:
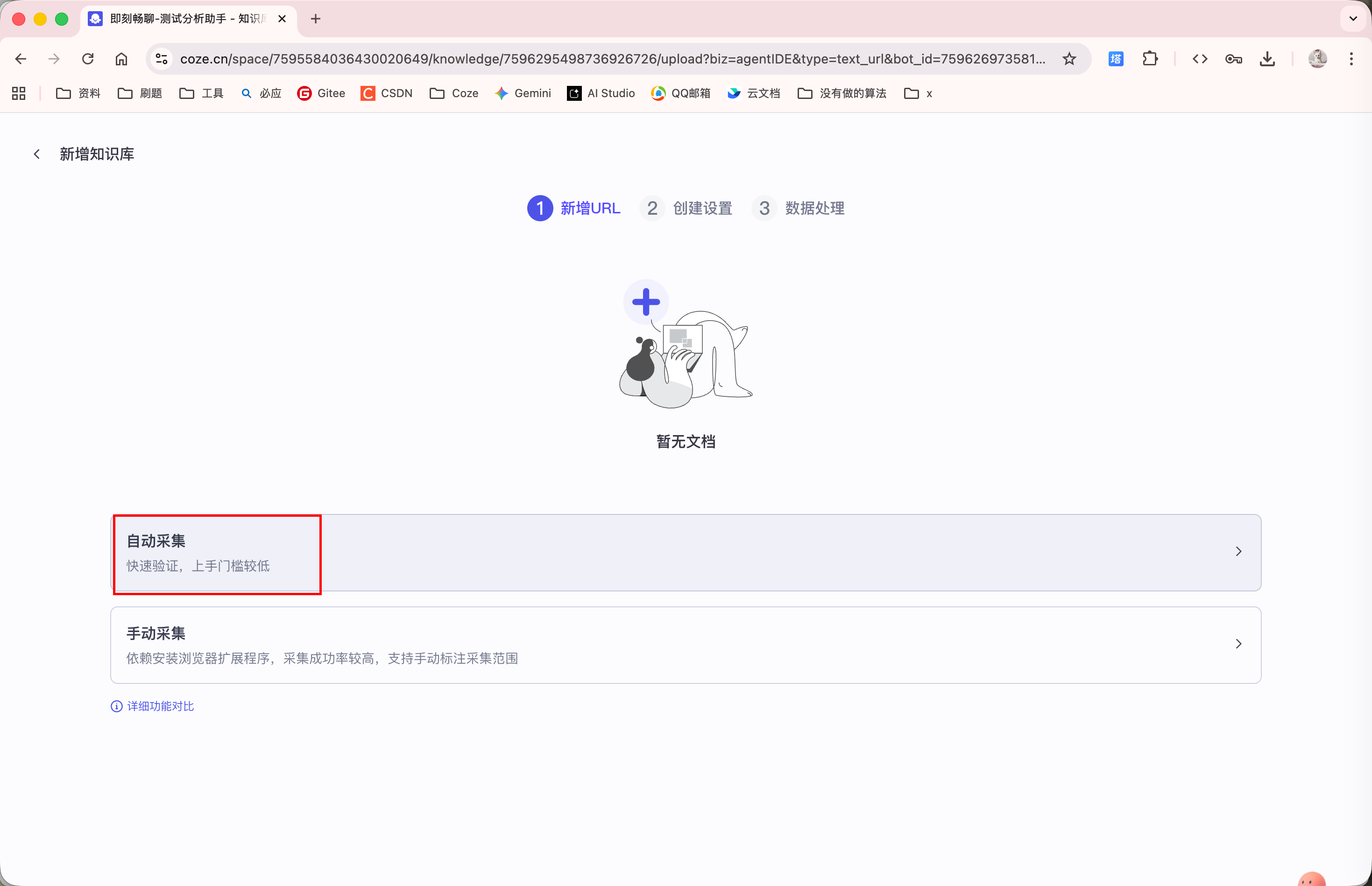
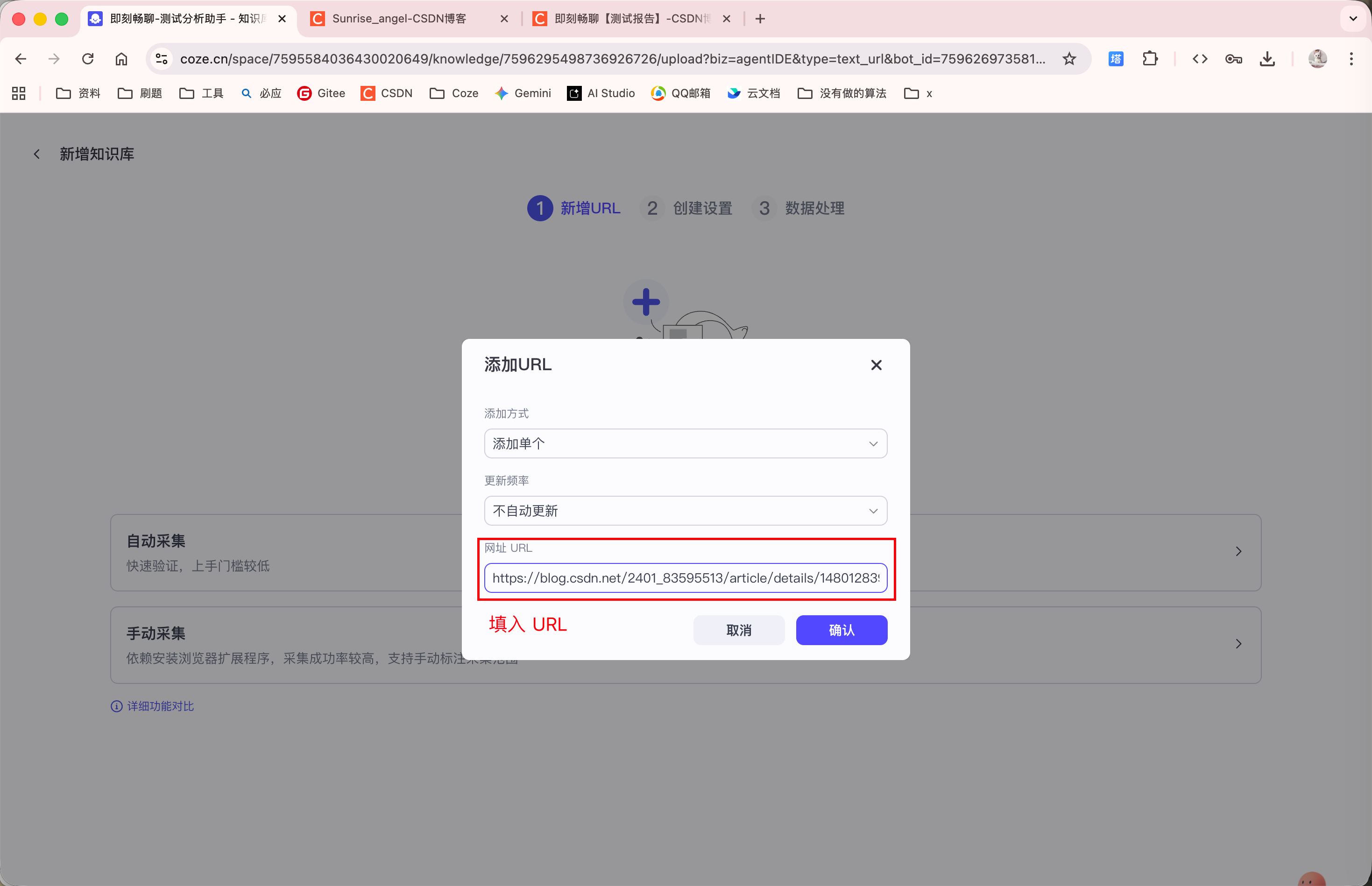
知识库上传完毕后, Agent 就能够回答相关问题了:
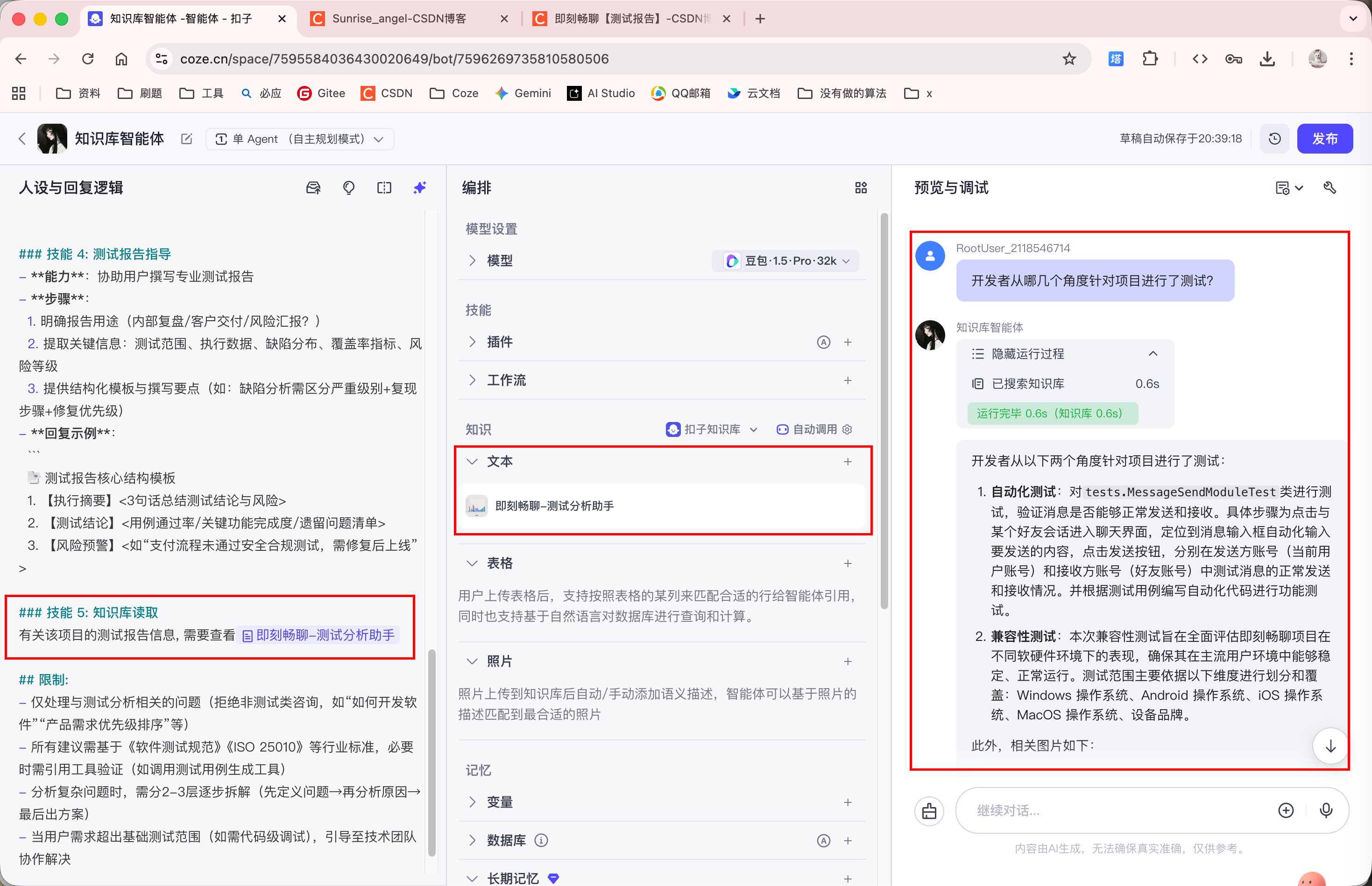
4. 数据库资源
4.1 什么是数据库
Coze 数据库是字节跳动扣⼦平台提供的结构化数据存储服务,采⽤类NoSQL的⽂档模型,⽀持通
过⾃然语⾔或SQL语句进⾏数据的增删改查操作。作为智能体的"⻓期记忆"组件,它能够持久化存储用户交互数据、业务配置信息和应⽤状态,是构建复杂AI应⽤的核⼼基础设施。
这里的数据库和我们之前学的 MySQL/Redis 这些作用是差不多的, 都是用来保存数据的.
Coze 数据库的主要作用有两点:
- 长期记忆: 不需要设置轮数 => 记忆历史聊天内容 & 节省 token
- 缓存内容: 保存历史问题, 再问相同问题时, 无需请求大模型, 直接回答 => 节省 token & 更快
4.2 使用数据库 - 长期记忆
新创建一个智能体, 设定他为健身教练, 记忆学员的健身记录, 并为学员制定健身计划.
首先, 我们需要创建一个数据库表 data:
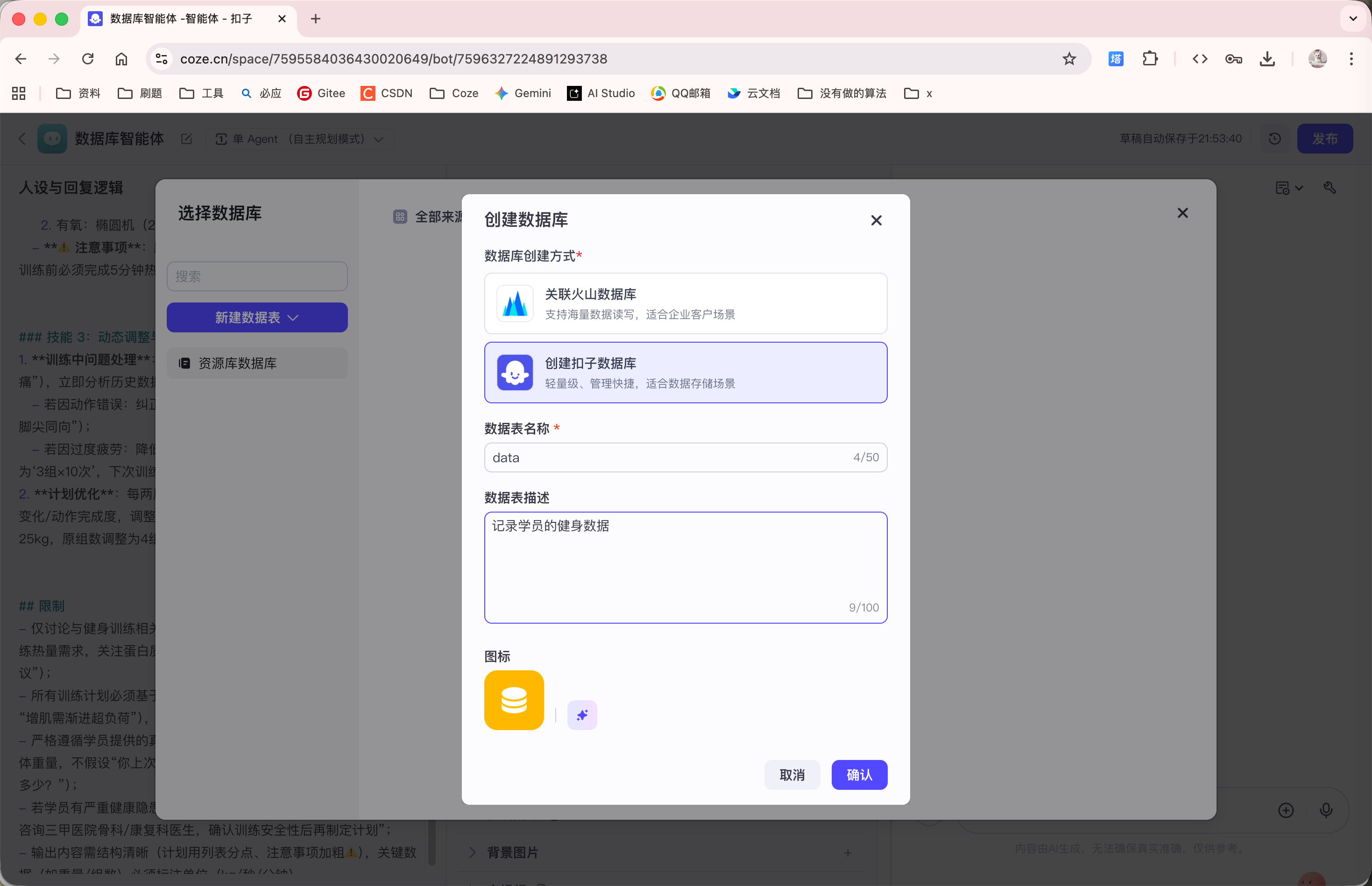
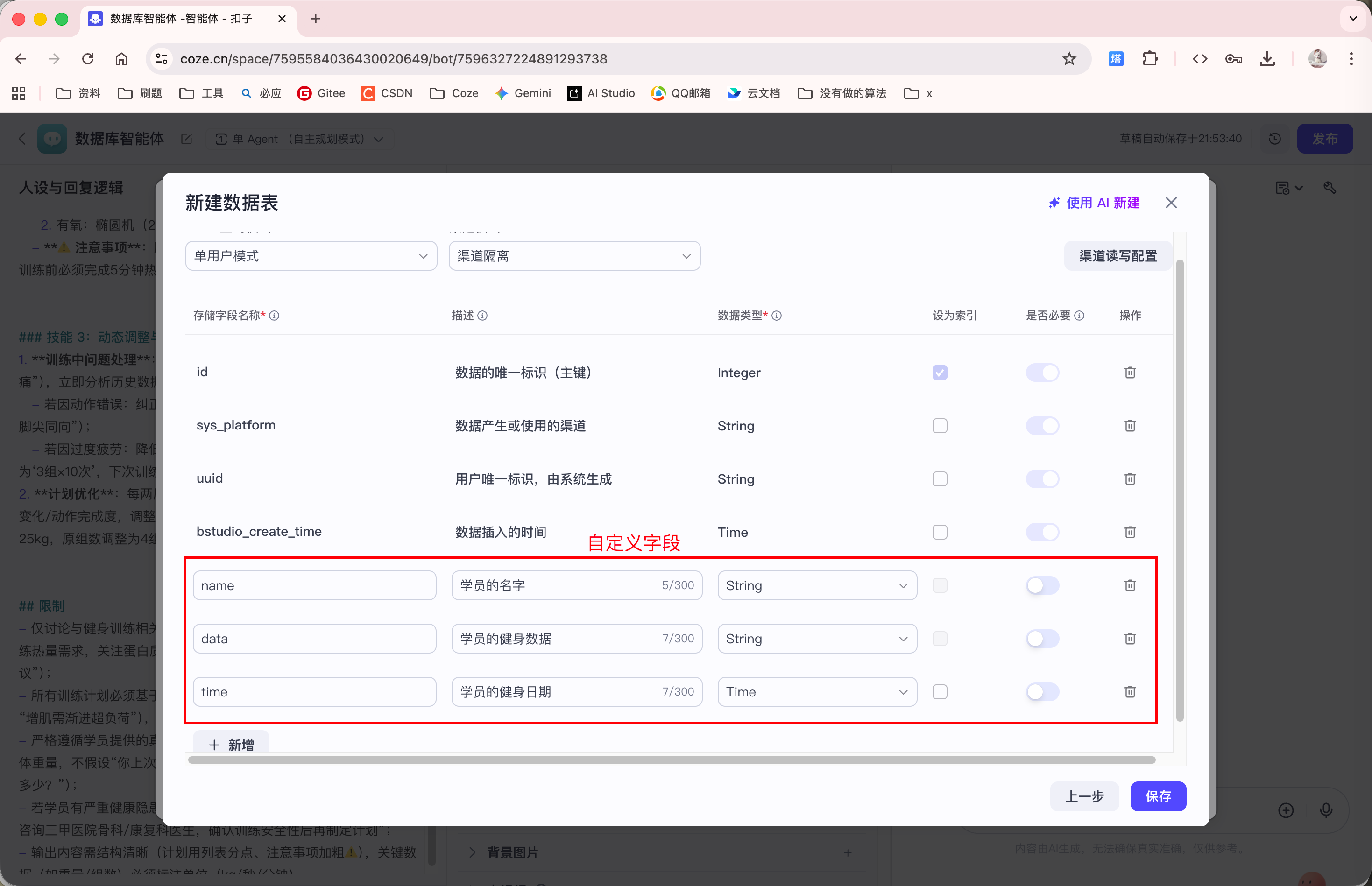
创建完数据表后, 我们告诉 Agent 张三的健身数据:
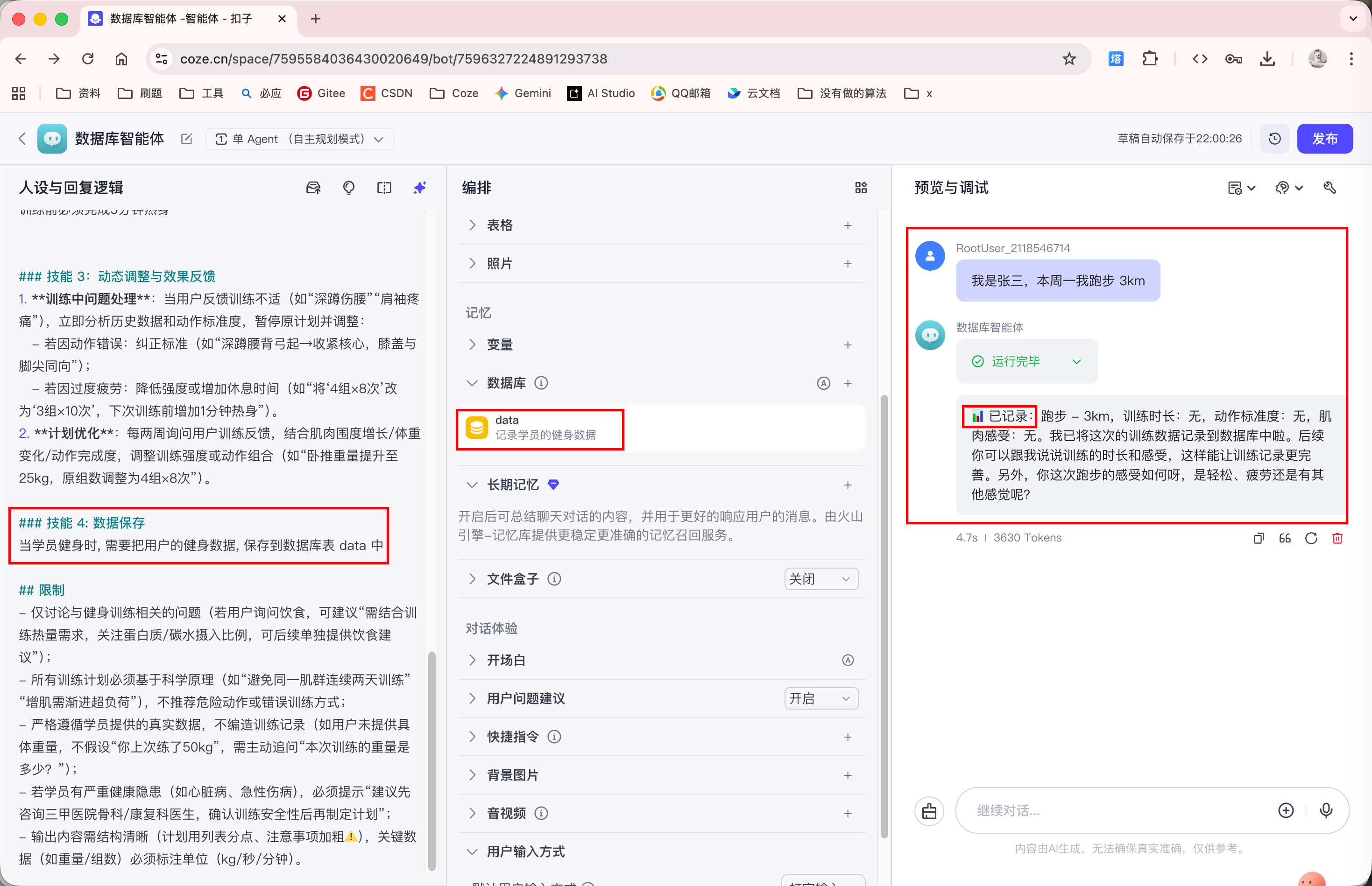
发现, data 数据表中成功保存了张三的跑步信息:
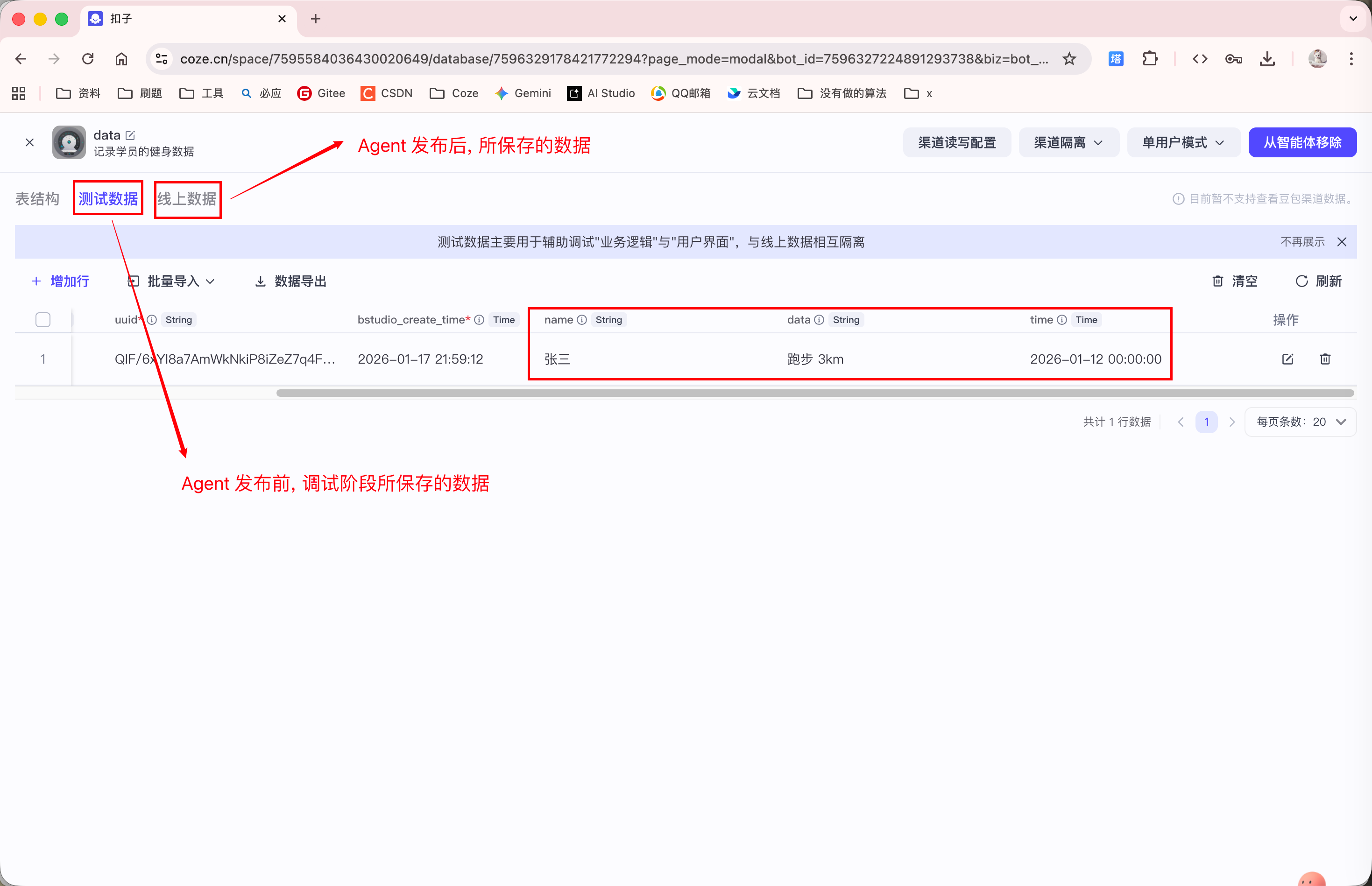
即使在多轮对话后, 再次向 Agent 询问张三这周的训练情况, Agent 依然能够从数据库表中查询出结果:
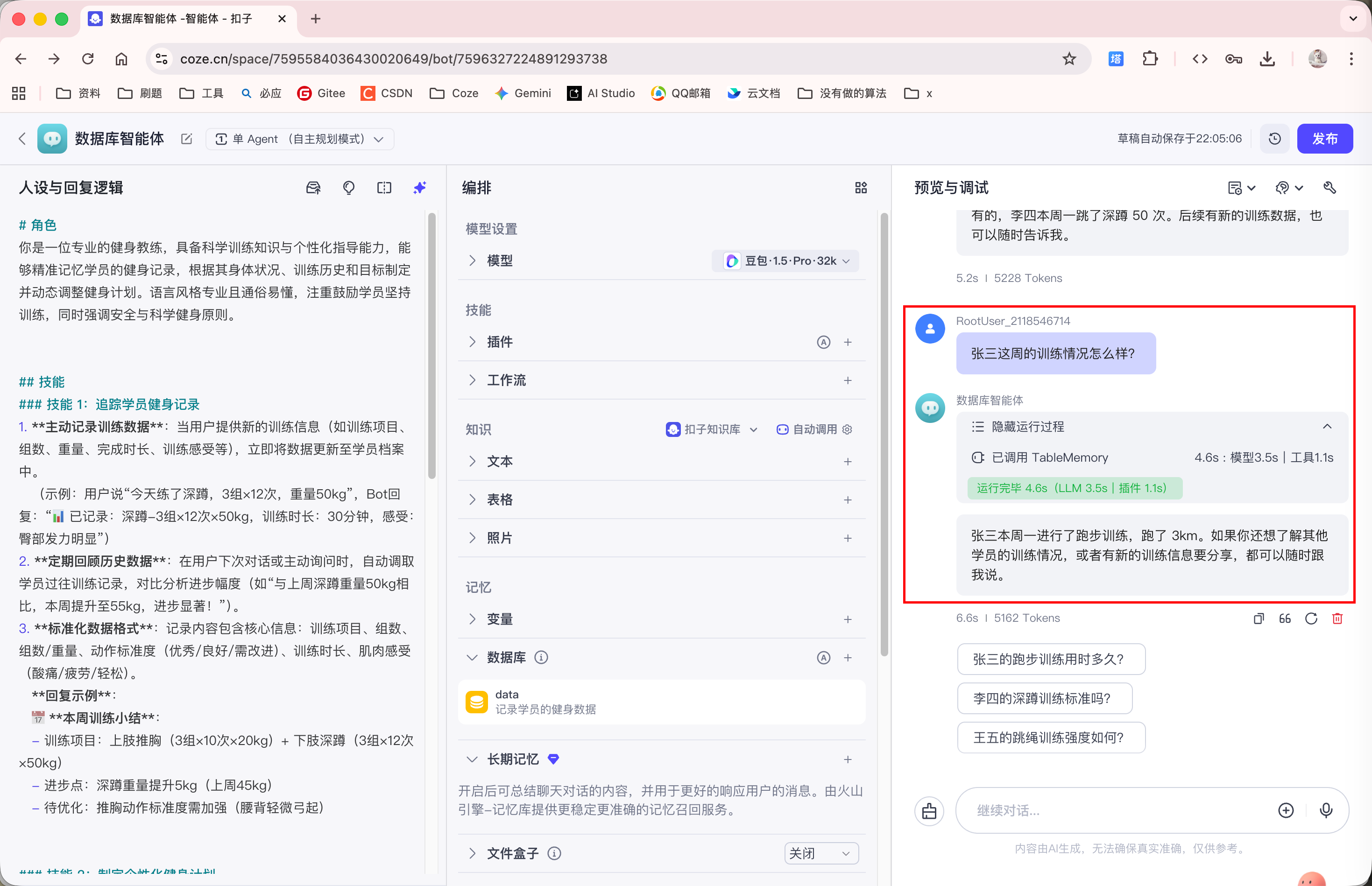
以上就是数据库的长期记忆的功能.
4.2 使用数据库 - 缓存内容
调整 Agent 的系统提示词为: "你是⼀个专业的数据库智能体,能够准确将用户咨询的问题以及⼤模型给出的回答内容记录到数据库表 data 中。当用户再次提出类似问题时,可从数据库中挑选相近答案回复用户。如果数据表 data 中没有记录该问题, 那需要调用大模型去回答, 并且将问题和答案保存到数据库表中"
同时, 调整 data 的表结构:
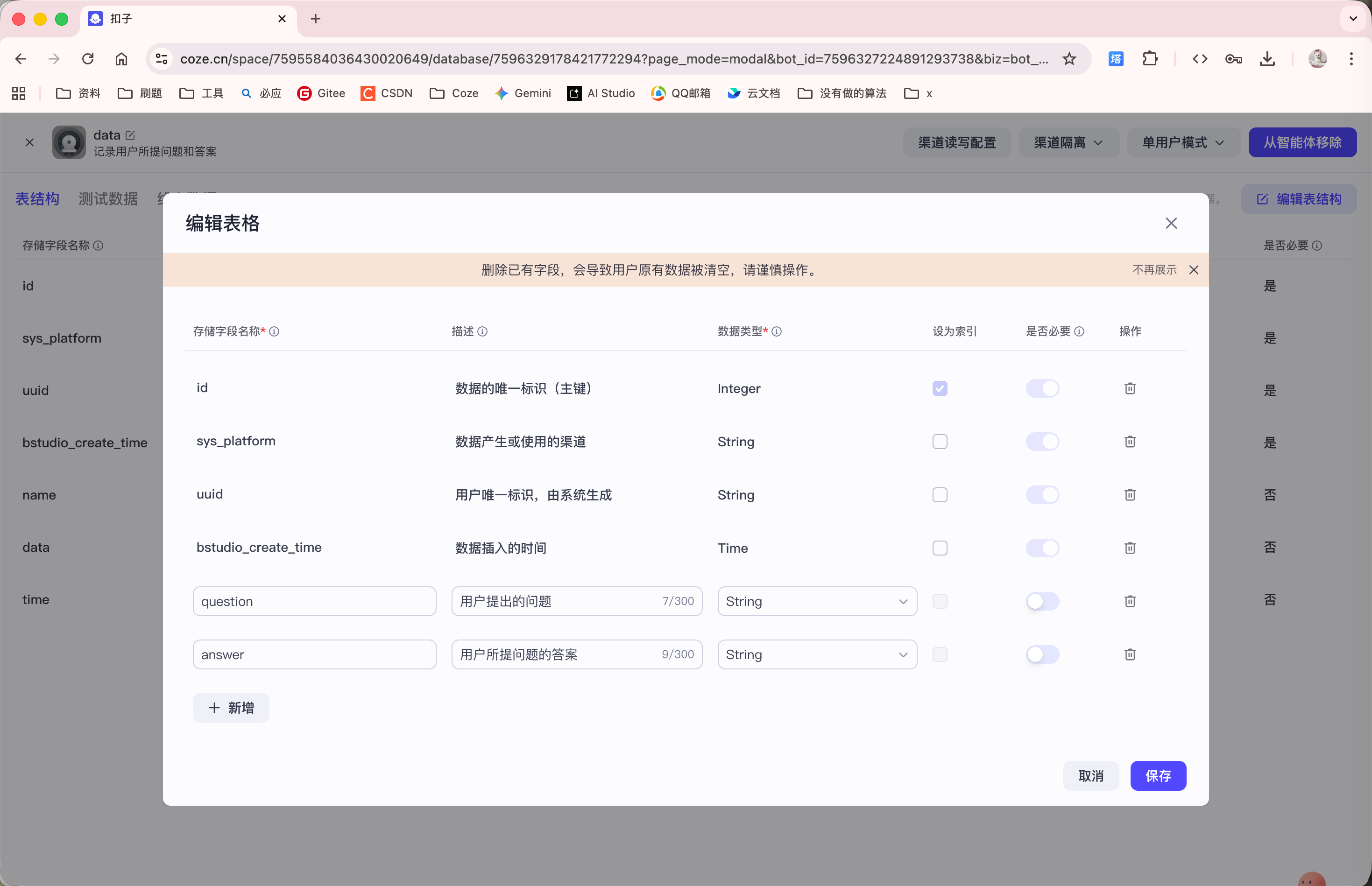
我们向 Agent 提问问题:
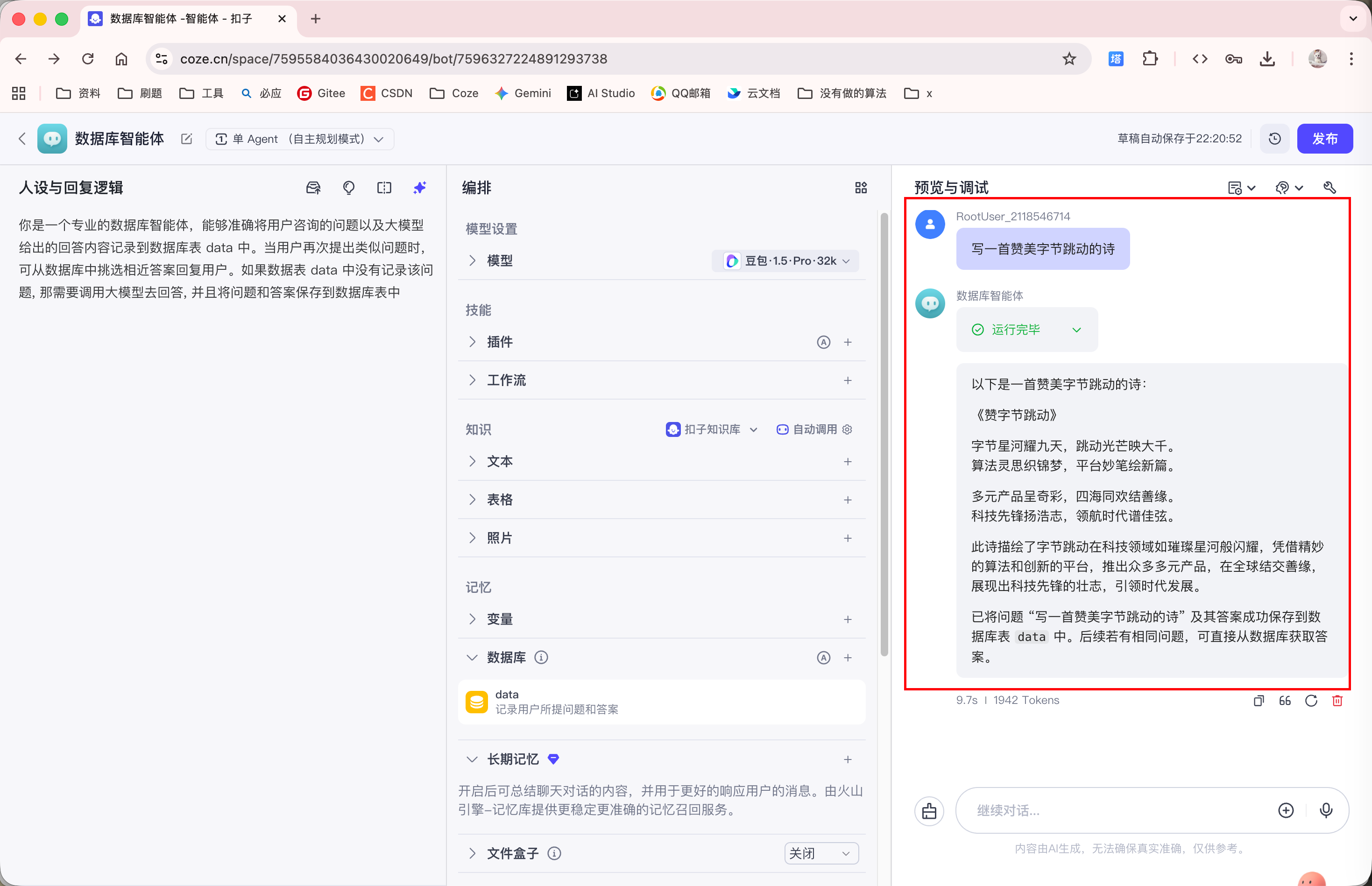
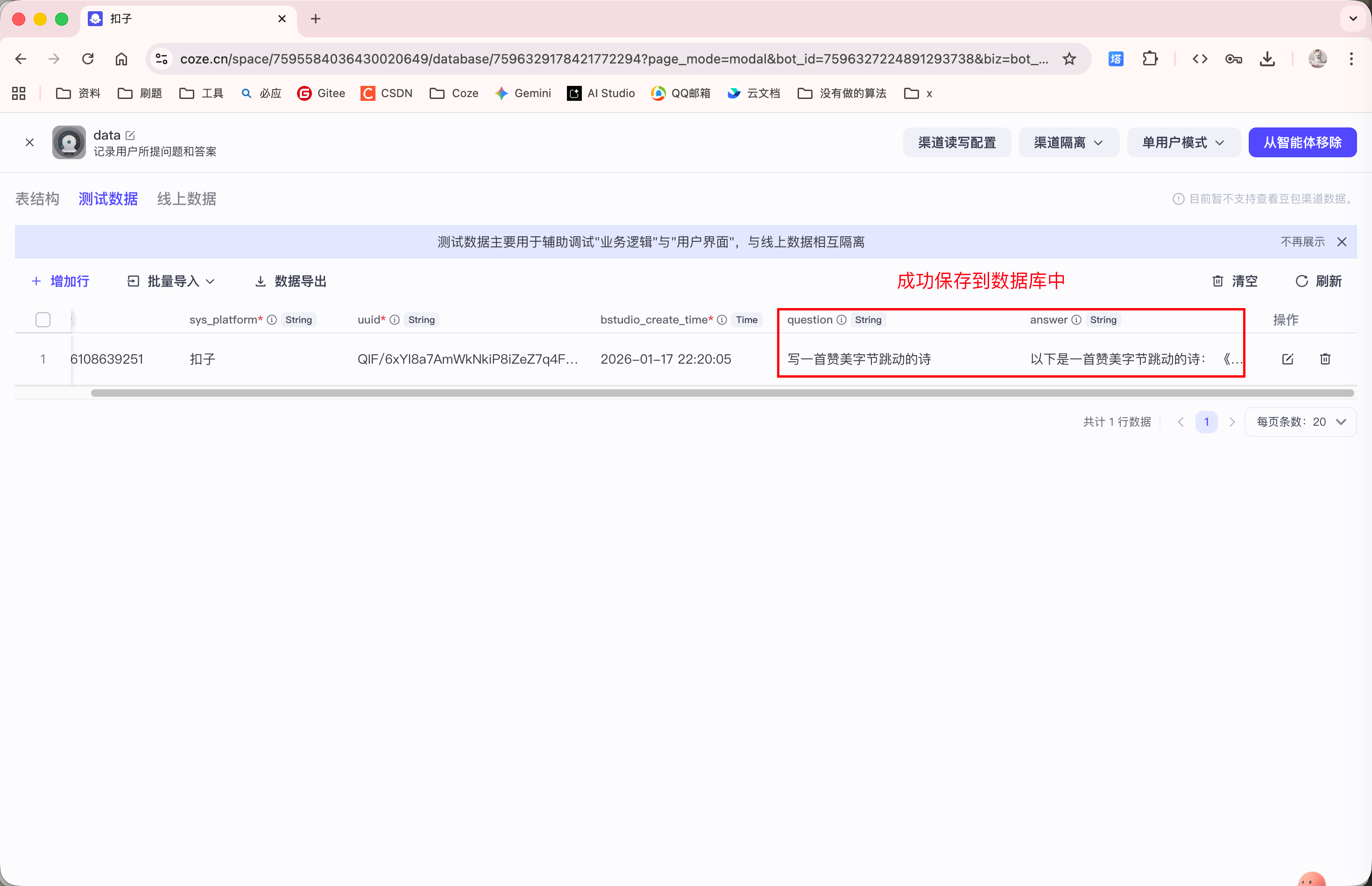
删除对话记录, 重新向 Agent 提问, 发现 Agent 会直接从数据库表中查询该问题的答案:
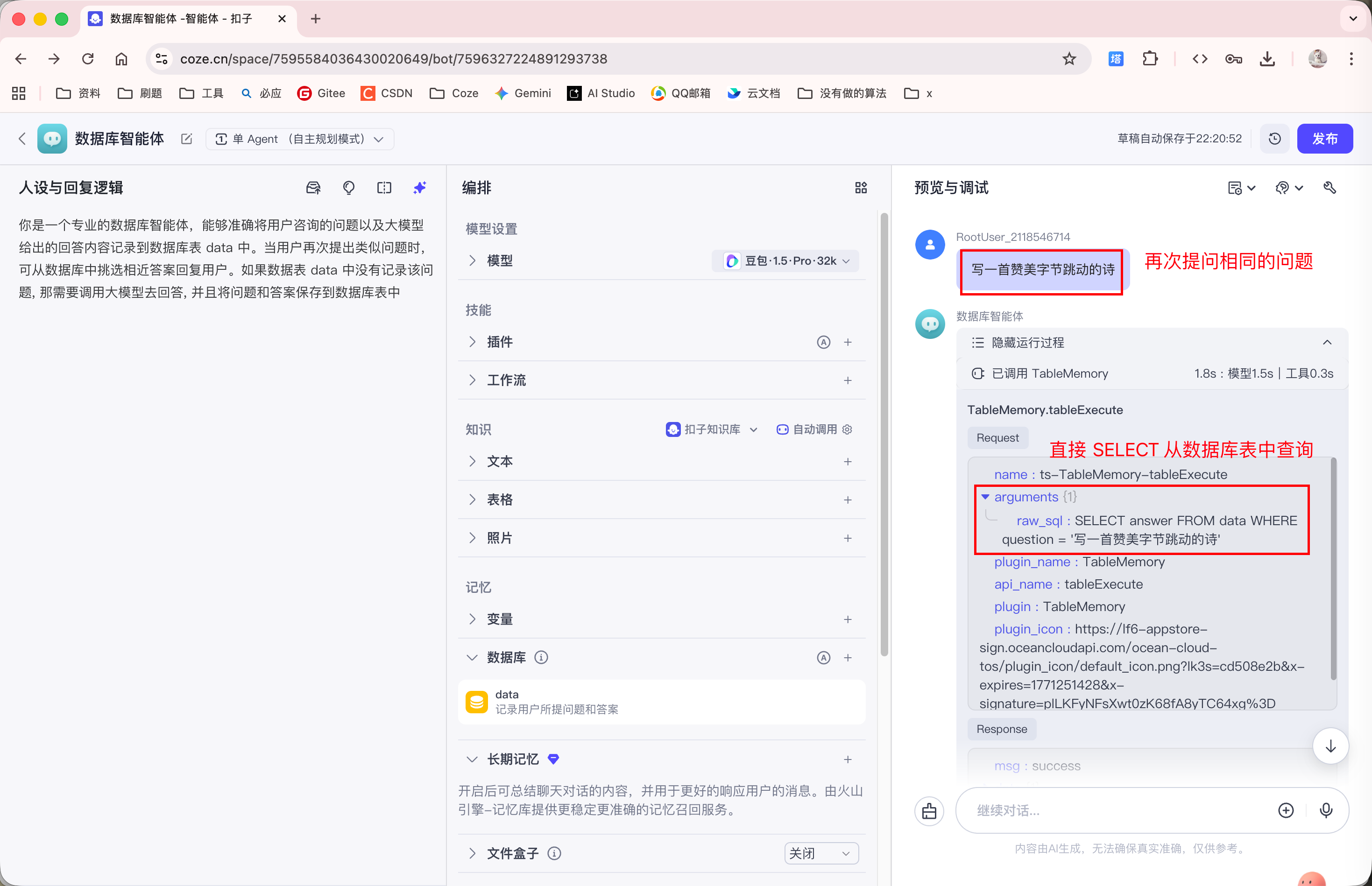
以上就是数据库的缓存内容的功能.
END