文章目录
- 结论
- 许可证
- 性能
- 对象层次结构
- ACID事务
- 数据安全
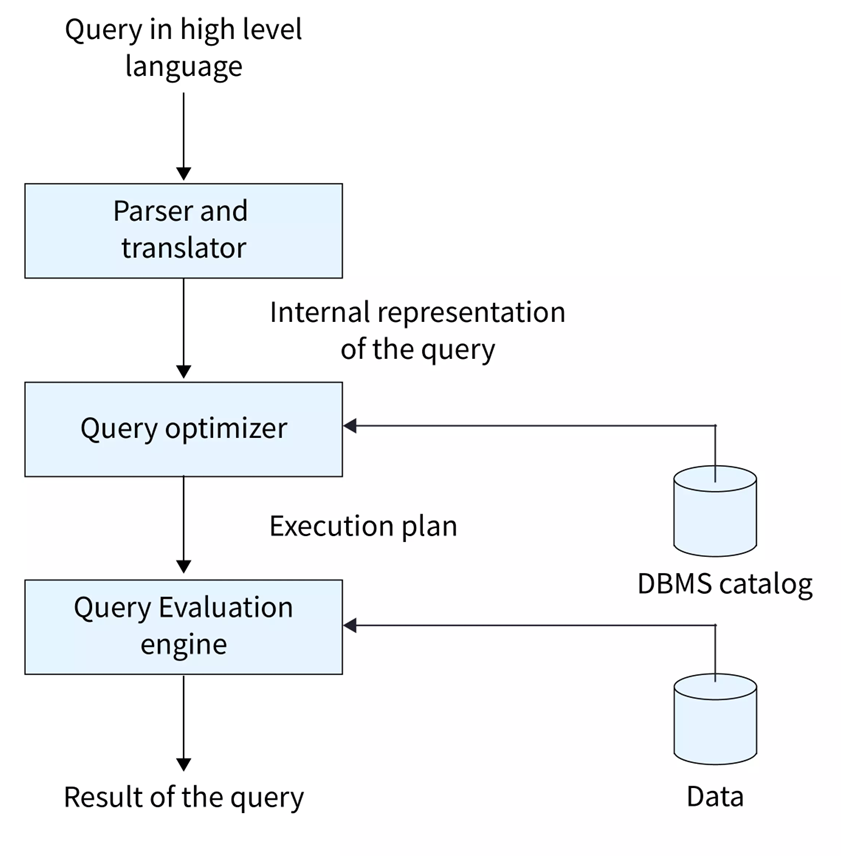
- 查询优化器
- 性能优化工具
- 监控工具
- JSON操作
- 窗口函数
- 插件
- 易用性
- 连接模型
- 可运维性
- 书写SQL
- 如何从MySQL迁移到PostgreSQL

结论
- 如果你的项目需要强一致性、复杂查询、灵活数据模型,选 PostgreSQL
- 如果你的项目是简单读密集型应用,追求快速上手,选 MySQL
- 初创公司快速迭代选 MySQL
- 企业级应用/金融系统选 PostgreSQL
- 内容平台/IoT 项目选 PostgreSQL(JSONB、地理空间支持)
- 数据分析平台选 PostgreSQL(窗口函数、CTE、全文搜索)
- 超高并发的写入场景,如大型电商秒杀,MySQL 更胜一筹,如 Uber 从 PostgreSQL 转MySQL
- PostgreSQL 功能丰富且强大,意味着学习使用和管理的难度更大
- PostgreSQL 为了实现其强大的功能和优化,需要更多的内存来达到更好的性能,占用磁盘空间相对 MySQL 较高
许可证
- MySQL 社区版使用 GPL 许可证,开发出的软件整体也需开源。2010 年 MySQL 所在的 Sun 公司被 Oracle 收购后,原始开发团队推出了 MariaDB
- PostgreSQL 使用它自己的许可证,类似 BSD 或 MIT,使用和二开没限制,可以闭源商业化
性能
- MySQL 在简单查询的高并发读场景下性能更好,适用于电子商务、博客
- PostgreSQL 在复杂查询、高并发写入场景下更稳定,适用于金融、科学计算、数据仓库、地理信息系统
- 对于大多数工作来说,PostgreSQL 和 MySQL 的性能旗鼓相当
- JSON 操作,PostgreSQL 比 MySQL 好得多
- PostgreSQL:写2279ms 读31.65ms 更新26.26ms
- MySQL:写3501ms 读49.99ms 更新62.45ms
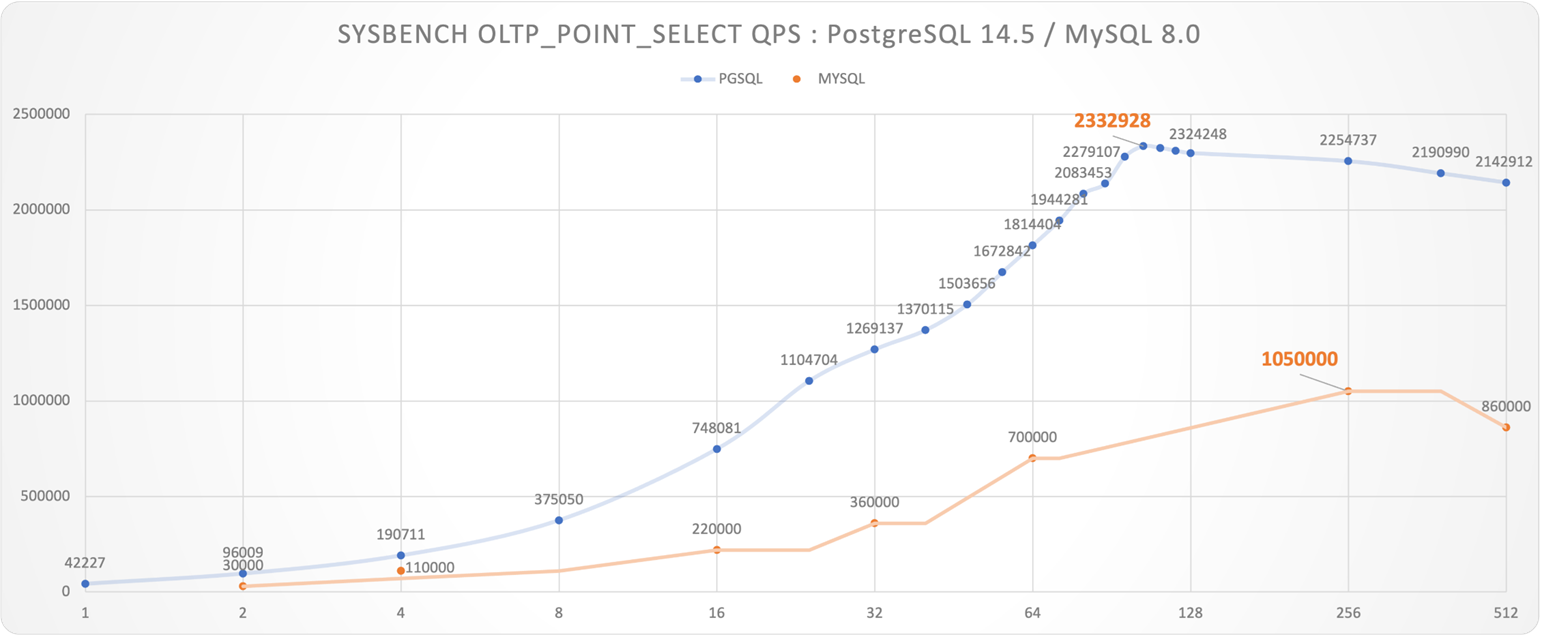
- PostgreSQL 简单查询 QPS 60w,最高 200 w。读写TPS(4写1读)7w,最高 14 万
- 极限条件下, PostgreSQL 简单查询性能显著压倒MySQL,其他场景基本与 MySQL 持平
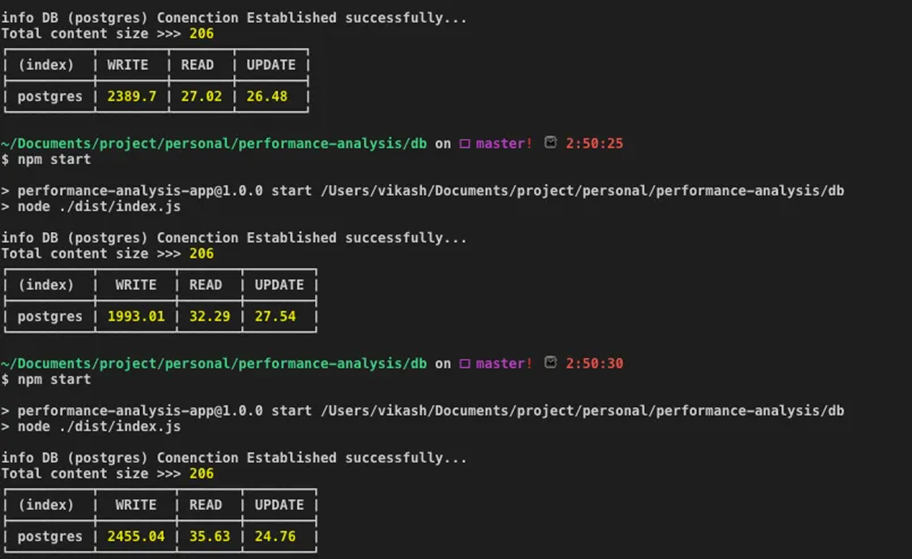
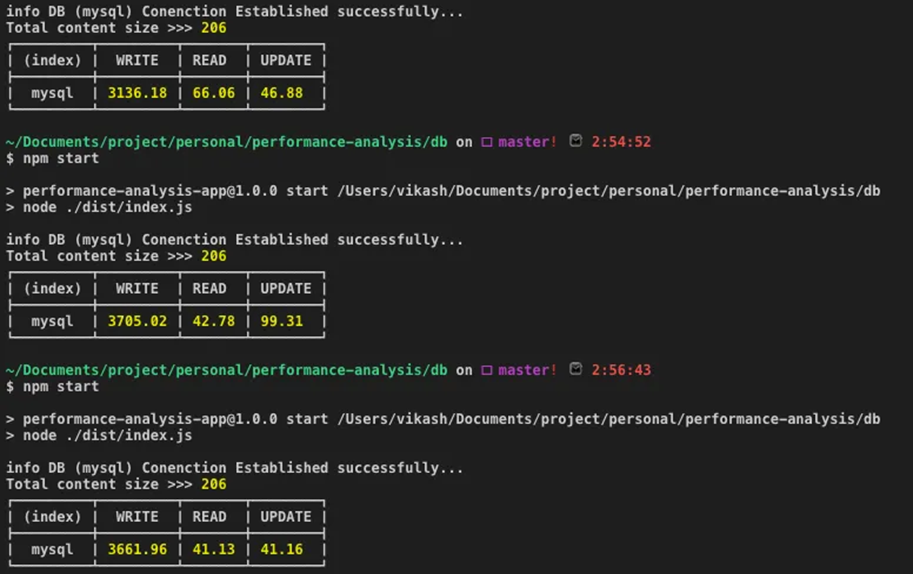
使用Node.js的TypeORM库,分别对MySQL和PostgreSQL跑了3次写入读取更新操作,取均值(2060条数据)
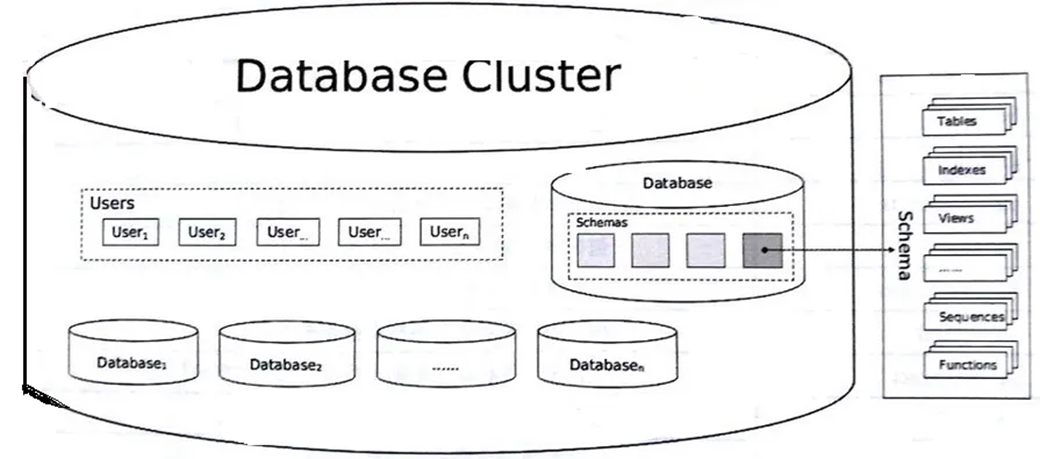
对象层次结构
- MySQL 采用了 4 级结构:实例、数据库、表、列
- PostgreSQL 采用了 5 级结构:实例(集群)、数据库、模式、表、列
- PostgreSQL多了一层,便于:
- 数据组织和隔离:如不同模块用同一个数据库,每个模块有一个模式,将数据隔离开。
- 多租户环境支持:每个租户有单独一个模式,确保数据安全性,维护也更高效。
- 细粒度的权限控制:可授予用户在某模式下只读权限。
ACID事务
四种事务隔离级别:读未提交、读已提交、可重复读、串行化
| 对比项目 | MySQL | PostgreSQL |
|---|---|---|
| 隔离级别 | 支持四种隔离级别,默认是读已提交 | 支持四种隔离级别,默认是可重复读 |
| 存储引擎 | InnoDB存储引擎支持完整事务,MyISAM存储引擎不支持事务 | 无明显存储引擎区分,使用MVCC处理并发,支持高并发读写 |
| 锁机制 | InnoDB支持行级锁盒表级锁,但复杂更新操作时如果索引使用不当,会导致行级锁升级成表级锁,降低并发性能 | 粒度较细,支持行级锁和表级锁,可更精确控制锁的范围,减少锁冲突,不影响其他行的并发操作 |
| 事务日志 | InnoDB使用redo log和undo log实现事务持久化和回滚 | WAL,记录事务变更操作,确保数据一致性和持久性 |
| 性能 | InnoDB引擎性能高效,但一些极端并发或复杂查询下会有性能瓶颈 | 复杂查询和高并发事务的性能较稳定,处理大量并发操作时有优势 |
数据安全
- MySQL 和 PostgreSQL 都支持基于角色的访问控制 RBAC(Role-Based Access Control):用户、角色、权限。例如用户A可以查询表T,但不能修改表T中的数据。
- PostgreSQL 还支持行级安全 RLS(Row-Level Security):根据数据行中的某些属性值来决定用户是否能够访问该行数据,如不同租户只能访问自己的数据,避免了数据泄露的风险。例如员工信息表中,只有部门经理才能看本部门员工的详细信息,通过行级安全可以根据员工数据行中的部门字段来实现这种精细的访问控制。
查询优化器
- MySQL
- 主要目标是提高查询速度,特别是简单查询,优化器能快速生成执行计划,适合读取密集型场景。但在处理复杂查询时,存在一定局限性。
- PostgreSQL
- 致力于实现复杂查询的高性能,优化器能更好地选择连接顺序和算法,擅长处理多表连接、子查询、窗口函数等。
- 不仅关注速度,还关注不同负载和复杂查询下的性能平衡。
- 支持复杂数据类型的优化,例如数组、JSON 等数据类型。
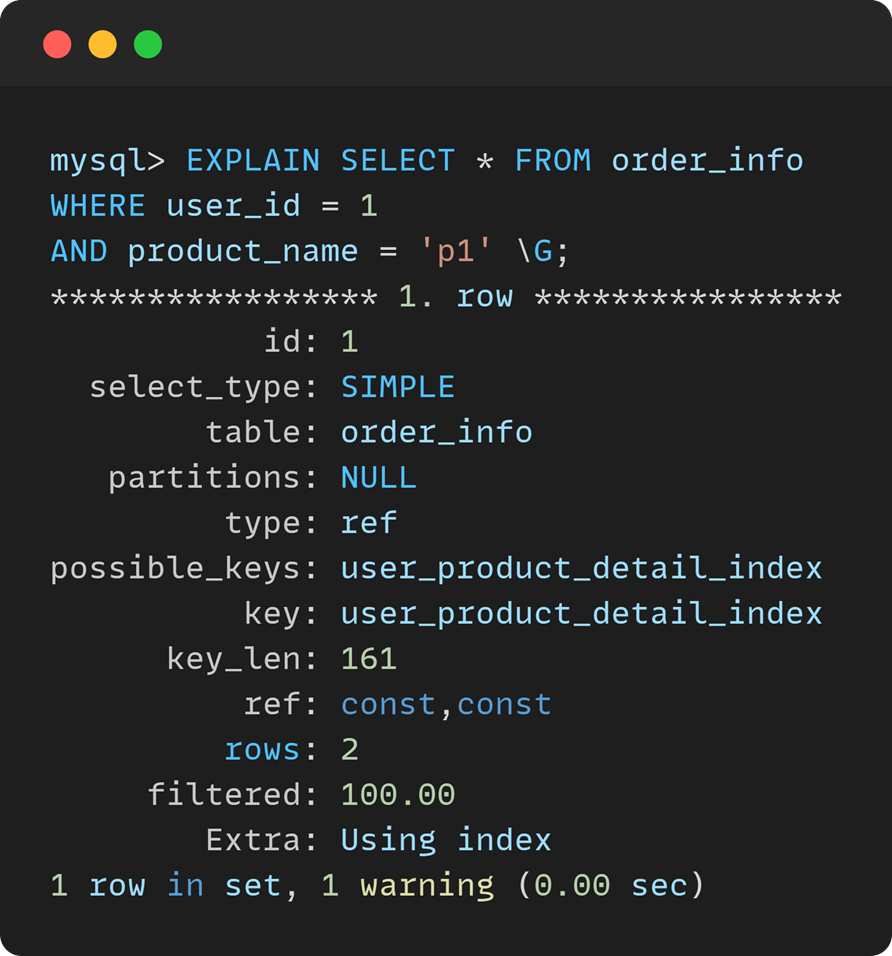
性能优化工具
- MySQL
- id:查询中的第几个部分,用于区分多个SELECT
- select_type:查询类型,SIMPLE为简单查询
- table:涉及的表名
- partitions:分区信息
- type:访问类型,如ref用了索引
- possible_kyes:可能用到的索引
- key:实际用到的索引
- key_len:索引长度,反映索引的覆盖范围
- ref:索引中使用的列或常量,分别对应WHERE的两个条件
- rows:扫描的行数,用于评估查询成本,越小越好
- filtered:条件过滤后的行占读取行的百分比,越大越好
- Extra:额外的信息,如Using index表示使用了索引
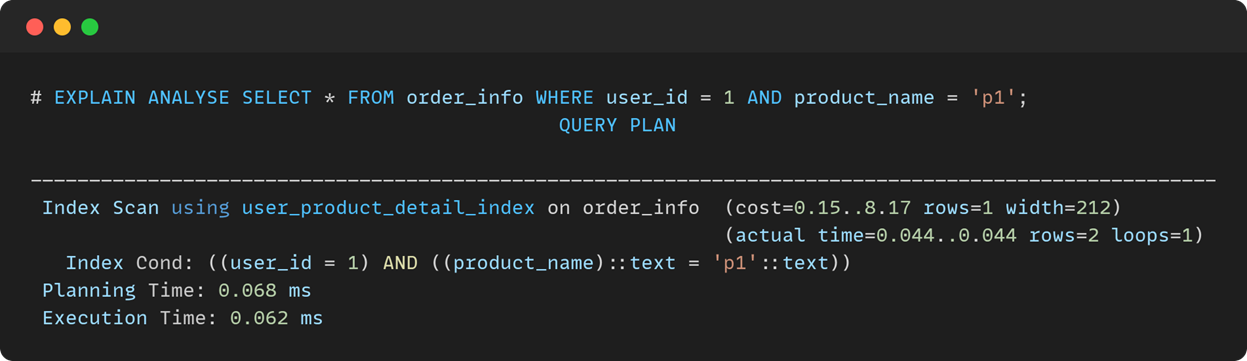
- PostgreSQL
- Index Scan using index_name on table_name:对某表的查询用了某索引
- cost=A...B:A是启动成本,B是总成本
- rows:结果行数
- width:结果平均行宽
- actual time=A...B:实际执行时间
- loops:循环次数
- Index Cond:索引条件
- Planning Time:查询优化器的耗时
- Execution Time:查询耗时
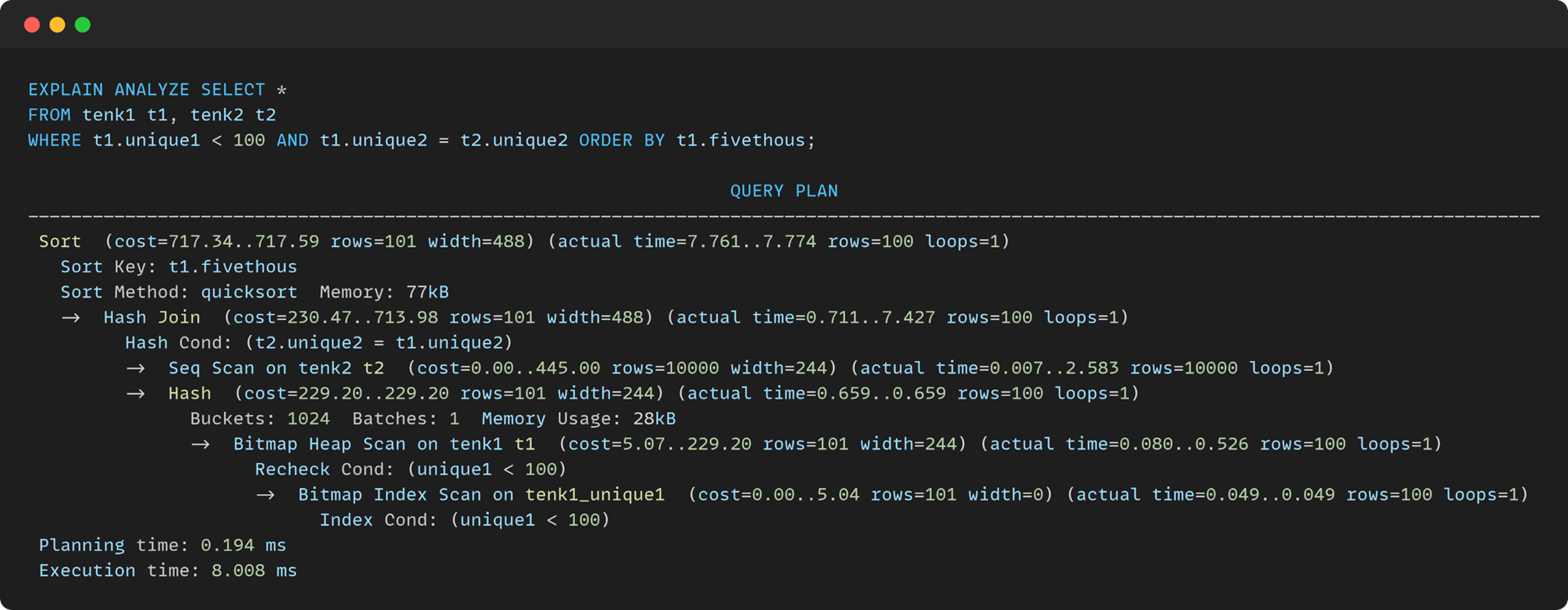
Sort:启动成本717.34,总成本717.59,预计返回101行,每行宽度488字节。实际执行时间7.761-7.774毫秒,返回100行,循环1次。排序键为t1.fivethous,排序方法快速排序,使用内存77KB。
Hash Join:启动成本230.47,总成本713.98,预计返回101行,每行宽度488字节。实际执行时间0.711-7.427毫秒,返回100行,循环1次。连接条件为t2.unique2 = t1.unique2。
Seq Scan on tenk2 t2:对tenk2表进行顺序扫描,成本为0-445,预计返回10000行,每行宽度244字节。实际执行时间0.007-2.583 毫秒,实际返回10000行,循环1次。
Hash:启动成本229.20,总成本229.20,预计返回101行,每行宽度4244字节。实际执行时间0.659-0.659毫秒,返回100行,循环1次。
Buckets:哈希桶数量1024,批次1,使用内存28KB。
Bitmap Heap Scan on tenk1 t1:对tenk1表进行位图堆扫描,启动成本5.07-229.20,预计返回101行,每行宽度244字节。实际执行时间0.080-0.526毫秒,实际返回100行,循环1次。
Recheck Cond:重新检查条件为unique1<100。
Bitmap Index Scan on tenk1_unique1:对tenk1表的tenk1_unique1索引进行位图索引扫描,启动成本0.00-5.04,预计返回101行,每行宽度0字节。实际执行时间0.049-0.049毫秒,实际返回100行,循环1次。
Index Cond:索引条件为unique1<100。
Planning time:查询计划生成时间为0.194毫秒。
Execution time:查询执行总时间为8.008毫秒。
监控工具
- MySQL
- SHOW STATUS 和 SHOW VARIABLES命令
- 第三方工具 MySQL Workbench
- 慢查询日志
- PostgreSQL
- pg_stat_activity 系统视图,查看会话和锁信息
- pg_stat_statements 扩展收集查询统计信息
- 自带开源免费的可视化工具 pgAdmin
JSON操作
| 项目 | MySQL | PostgreSQL |
|---|---|---|
| 数据类型 | 仅支持JSON | 支持 JSON 和 JSONB(性能更好) |
| JSON函数 | 提取JSON_EXTRACT 包含JSON_CONTAINS | 提取->和->> 包含@> 更丰富的函数和高级功能 |
| 索引 | 对 JSON 列创建虚拟列,再对虚拟列创建索引 | 可以直接对JSONB 创建 GIN 索引 |
| 标准遵循和扩展 | 遵循JSON标准,扩展较少 | 遵循JSON标准扩展较多,有更丰富的函数和操作符 |
| 性能 | 复杂JSON查询性能很差 | JSONB的复杂性能查询很好 |
窗口函数
窗口函数也叫 OLAP 函数,对数据库数据进行实时分析处理,实现合计和分类汇总,如学生成绩表计算出总分、平均分、按课程汇总。适合做数据仓库。
| 项目 | MySQL | PostgreSQL |
|---|---|---|
| 窗口帧类型 | 仅支持Row Frame | 支持Row Frame和范围帧 |
| 范围单位 | 仅支持UNBOUNDED PRECEDING和 CURRENT ROW | 还支持UNBOUNDED FOLLOWING和BETWEEN |
| 高级函数 | ROW_NUMBER() 行号 RANK() 排名 DENSE_RANK() 行排名 LEAD() 当前行后几行,比较趋势 LAG() 当前行前几行 | |
| 性能 | 一般 | 更好 |
插件
- MySQL:插件较少
- PostgreSQL:支持多种扩展
sql
# 启用扩展
CREATE EXTENSION postgis;
# 创建空间数据表
CREATE TABLE city (
id SERIAL PRIMARY KEY,
city_name VARCHAR(50),
location GEOMETRY(Point, 4326)
);
# 插入数据(EPSG:4326:WGS84坐标系,全球通用)
INSERT INTO city (city_name, location)
VALUES
('深圳', ST_SetSRID(ST_MakePoint(114.0596, 22.5429), 4326)),
('广州', ST_SetSRID(ST_MakePoint(113.2644, 23.1291), 4326)),
('武汉', ST_SetSRID(ST_MakePoint(114.3052, 30.5928), 4326)),
('青岛', ST_SetSRID(ST_MakePoint(120.3830, 36.0662), 4326)),
('北京', ST_SetSRID(ST_MakePoint(116.4074, 39.9042), 4326));
# 查询两个城市之间的距离(EPSG:4527:基于国家大地坐标系的投影坐标系)
SELECT ST_Distance(
ST_Transform((SELECT location FROM city WHERE city_name = '深圳'), 4527),
ST_Transform((SELECT location FROM city WHERE city_name = '北京'), 4527));
# 1938597.1881722098
# 查询200公里内的城市
SELECT city_name FROM city
WHERE ST_DWithin(
ST_Transform(location, 4527),
ST_Transform((SELECT location FROM city WHERE city_name = '深圳'), 4527),
200000);
# 深圳
# 广州易用性
| 项目 | MySQL | PostgreSQL |
|---|---|---|
| GROUP BY | 允许包含非聚合列 | 不允许包含非聚合列 |
| 大小写 | 大小写不敏感 | 大小写敏感,citext可实现大小写不敏感 |
| JOIN | 允许连接不同数据库的表 | 只允许连接单个数据库内的表,除非用扩展 postgres_fdw |
连接模型
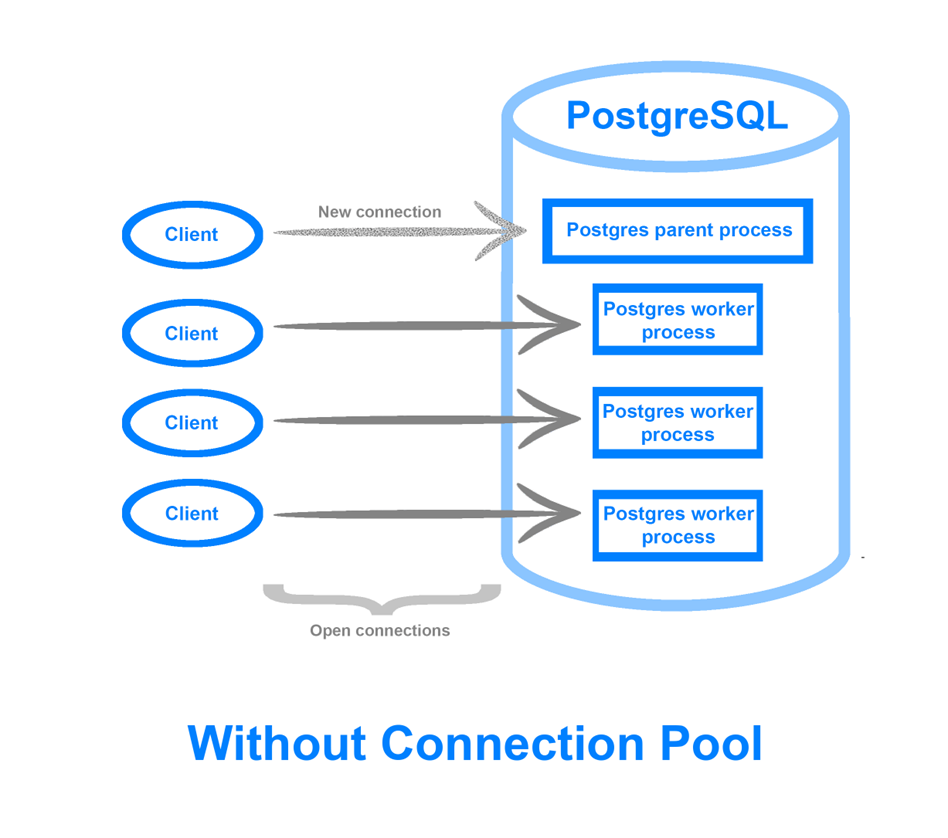
- MySQL:在每个连接上生成一个新线程
- PostgreSQL:在每个连接上生成一个新进程
可运维性
- MySQL 适合简单应用和快速部署
- PostgreSQL 适合复杂应用、高级功能和性能优化有较高要求的场景
| 项目 | MySQL | PostgreSQL |
|---|---|---|
| 备份和恢复 | mysqldump 支持binlog增量备份和恢复 | pg_dump、pg_dumpall、pg_basebackup 支持WAL日志增量备份,pg_ctl恢复 |
| 高可用性 | 主从复制,有概率丢数据 | 同步复制(流复制),零数据丢失 |
| 权限控制 | 数据库、表、列级别 | 数据库、模式、表、列、函数级别,更精细 还支持角色概念,方便管理 |
书写SQL
| 项目 | MySQL | PostgreSQL |
|---|---|---|
| 数据类型 | INT、VARCHAR可指定长度,但一般不影响存储大小、DATETIME | INTEGER、VARCHAR不使用显示长度、TIMESTAMP |
| 字符串拼接 | CONCAT() | || 或 CONCAT() |
| 自增主键 | AUTO_INCREMENT | SERIAL / BIGSERIAL |
| 事务 | START TRANSACTION | BEGIN TRANSACTION |
| 改表名 | RENAME TABLE A TO B | ALTER TABLE A RENAME TO B |
| ROLLUP | GROUP BY xxx WITH ROLLUP | GROUP BY ROLLUP (xxx) |
| 条件分支 | CASE | CASE 和 IF |
| 存储过程 | CREATE PROCEDURE | DELIMITER CREATE PROCEDURE |
如何从MySQL迁移到PostgreSQL
规划与准备
- 分析 MySQL 数据库的结构,包括表、视图、存储过程、触发器等。确定数据量大小、数据类型、复杂程度,评估迁移的难度和工作量。
- 检查 MySQL 中使用的特定功能,如自增主键、日期时间格式、字符集等,确保在 PostgreSQL 中有替代方案。
- 安装并配置 PostgreSQL 数据库。
- 准备好迁移工具,如手动导入使用mysqldump结合psql,自动化工具使用pgloader。
迁移表结构和数据
- 使用 pgloader 自动迁移:目前 pgloader 最新版本为 2022 年发布的 3.6.9,不足以支持 2024 年发布的 PostgreSQL 17
- 使用 mysqldump 结合 psql 手动迁移
- INT 改为 INTEGER,DATETIME 改为 TIMESTAMP
- 自动递增 AUTO_INCREMENT 改为 SERIAL
- 表字段注释改为 COMMENT ON COLUMN table.column IS 'xxx';
- VARCHAR 字符集一致
- 时区改为与应用层一致
- PostgreSQL 的表名和字段名默认区分大小写
迁移存储过程、函数、触发器
- MySQL 定义存储过程要用 DELIMITER,PostgreSQL 不用
- 注意具体的实现语法可能存在差异
- 事务 START TRANSACTION 改为 BEGIN TRANSACTION
- ROLLUP 删掉 WITH
测试与验证
- 数据一致性检查:COUNT(*) 对比数据行数
- 应用回归测试:确保所有功能正常,性能相近
- 时间规划:规划好迁移时间,提前通知用户,减少对业务的影响