这份笔记是关于 Linux SPI OLED 驱动(基于 Framebuffer 架构)的深度代码分析与学习笔记。旨在梳理驱动的分层架构、核心难点(数据格式转换)、以及关键机制(内核线程与 DMA 内存管理)的设计原理。
Linux SPI OLED 驱动源码深度分析笔记
1. 总体架构概览
本驱动程序不仅仅是一个简单的字符设备驱动,它实现了一个完整的 Linux Framebuffer (fbdev) 子系统接口。其核心目标是将一块只支持 SPI 接口、采用"页寻址"模式的 OLED 屏幕,模拟成一块标准的、支持"光栅扫描"的显示器。
c
/* 核心全局变量 */
static struct fb_info *myfb_info; // Framebuffer 核心结构体
static struct task_struct *oled_thread; // 负责刷新的内核线程
static unsigned char *oled_buf; // SPI 发送用的临时缓冲区
static struct spi_device *oled; // SPI 设备指针
static struct gpio_desc *dc_gpio; // D/C 引脚 (命令/数据选择)
/* Framebuffer 操作函数集 (使用内核通用函数) */
static struct fb_ops myfb_ops = {
.owner = THIS_MODULE,
.fb_fillrect = cfb_fillrect, // 通用矩形填充
.fb_copyarea = cfb_copyarea, // 通用区域拷贝
.fb_imageblit = cfb_imageblit, // 通用图像位块传输
// .fb_setcolreg ... (省略伪彩设置细节)
};
static int oled_thread_func(void *param)
{
unsigned char *fb = myfb_info->screen_base; // 指向 DMA 分配的显存虚拟地址
int i, line, bit, k = 0;
unsigned char data[8], byte;
while (!kthread_should_stop()) // 只要驱动没卸载,就死循环运行
{
/* --- A. 格式转换 (Raster to Page) --- */
/* OLED 需要竖向的 Page 数据,而 FB 显存是横向的 Raster 数据 */
k = 0;
for (i = 0; i < 8; i++) { // 遍历 8 个 Page (总高 64 像素)
// ... (省略部分遍历逻辑) ...
// 核心算法:将 8 行横向数据,通过位运算拼凑成 1 个纵向字节
for (bit = 0; bit < 8; bit++) {
byte = (((data[0]>>bit) & 1) << 0) |
(((data[1]>>bit) & 1) << 1) |
// ... (中间行省略) ...
(((data[7]>>bit) & 1) << 7);
oled_buf[k++] = byte; // 存入发送缓冲区
}
}
/* --- B. SPI 硬件发送 --- */
for (i = 0; i < 8; i++) {
OLED_DIsp_Set_Pos(0, i); // 设置 OLED 页坐标
gpiod_set_value(dc_gpio, 1); // 拉高 DC 脚 (数据模式)
spi_write(oled, &oled_buf[i*128], 128); // 发送一整页数据
}
/* --- C. 帧率控制 --- */
schedule_timeout_interruptible(HZ); // 休眠释放 CPU
}
return 0;
}
// 2. Probe 函数:驱动初始化入口
static int spidev_probe(struct spi_device *spi)
{
dma_addr_t phy_addr;
/* A. 硬件基础设置 */
oled = spi;
dc_gpio = gpiod_get(&spi->dev, "dc", 0); // 从设备树获取 GPIO
/* B. 分配 Framebuffer 信息结构体 */
myfb_info = framebuffer_alloc(0, NULL);
/* C. 设置屏幕参数 (128x64, 单色) */
myfb_info->var.xres = 128;
myfb_info->var.yres = 64;
myfb_info->var.bits_per_pixel = 1;
myfb_info->fix.smem_len = 1024; // 显存大小
/* D. 关键:申请 DMA 显存 (Write Combining 模式) */
/* screen_base 是虚拟地址(给CPU写),phy_addr 是物理地址(给mmap用) */
myfb_info->screen_base = dma_alloc_wc(NULL, 1024, &phy_addr, GFP_KERNEL);
myfb_info->fix.smem_start = phy_addr;
myfb_info->fbops = &myfb_ops;
/* E. 向内核注册 Framebuffer 设备 (/dev/fb0 生成) */
register_framebuffer(myfb_info);
/* F. 启动内核线程 */
oled_buf = kmalloc(1024, GFP_KERNEL);
oled_init(); // 硬件初始化
oled_thread = kthread_run(oled_thread_func, NULL, "oled_kthread");
return 0;
}
// Remove 函数:资源释放 (注意顺序)
static int spidev_remove(struct spi_device *spi)
{
kthread_stop(oled_thread); // 1. 先停线程
unregister_framebuffer(myfb_info); // 2. 注销 FB 设备
// 3. 释放 DMA 显存
dma_free_wc(NULL, myfb_info->fix.smem_len, myfb_info->screen_base,
myfb_info->fix.smem_start);
framebuffer_release(myfb_info); // 4. 释放结构体
kfree(oled_buf);
gpiod_put(dc_gpio);
return 0;
}
/* 驱动匹配表 */
static const struct of_device_id spidev_dt_ids[] = {
{ .compatible = "100ask,oled" },
{},
};
/* SPI 驱动结构体 */
static struct spi_driver spidev_spi_driver = {
.driver = {
.name = "100ask_spi_oled_drv",
.of_match_table = spidev_dt_ids,
},
.probe = spidev_probe,
.remove = spidev_remove,
};2. 核心问题解析
2.1 为什么要使用内核线程 (kthread)?
在代码中,oled_thread_func 被设计为一个死循环的内核线程。
原因分析:
- 解耦"绘制"与"刷新" :
- 应用层视角:用户程序(如 Qt)只负责往显存(Framebuffer Memory)里填充数据。标准的 Framebuffer 机制通常不强制要求应用层每画一个点就通知驱动一次。应用层认为自己只是在操作内存。
- 硬件视角:OLED 屏幕不会自动读取内存,它需要驱动程序主动通过 SPI 发送指令和数据才能更新显示。
- 解决方案:内核线程充当了"搬运工"。它在后台独立运行,不断地从 Framebuffer 内存中读取最新数据,刷新到 OLED 上。这样应用层不需要关心 SPI 通信的细节,也不需要等待 SPI 传输完成,实现了非阻塞的高效绘图。
- 处理耗时的格式转换 :
- Framebuffer 的数据是水平排列的(Byte 0 代表第一行前8个像素)。
- SSD1306 OLED 的显存是垂直排列的(Byte 0 代表第一列前8个像素)。
- 驱动必须进行繁重的位运算 (Bit manipulation)来转换格式。如果在应用层调用
write时同步执行这个转换,会极大地占用应用程序的时间片,导致系统响应变慢。放在内核线程中执行,可以利用操作系统的调度机制,在后台完成这一繁重任务。
2.2 DMA (dma_alloc_wc) 在这里起什么作用?
代码中使用了 dma_alloc_wc 来分配 Framebuffer 的内存:
c
myfb_info->screen_base = dma_alloc_wc(NULL, len, &phy_addr, GFP_KERNEL);这里的"DMA"主要指内存分配方式,而非指 SPI 控制器的 DMA 传输(尽管 SPI 控制器内部可能也会用 DMA,但那是另一回事)。
作用解析:
-
物理地址连续性:
- Framebuffer 驱动通常支持
mmap系统调用,允许用户空间直接映射显存。 dma_alloc_wc(Coherent DMA memory allocator) 保证分配到的内存是物理地址连续 的。这是构建 Framebuffer 供用户空间映射的基础条件,普通的kmalloc在大块内存上可能无法保证物理连续性或对齐要求。
- Framebuffer 驱动通常支持
-
Write Combining (WC) 缓存策略:
- 注意后缀
_wc代表 Write Combining。 - 由非缓存 (Uncached):太慢,每次写内存都直接访问 RAM。
- 全缓存 (Cached):有数据一致性问题(Cache Coherency),CPU Cache 里的数据可能还没写到 RAM,DMA 就开始搬运了(虽然本例是 CPU 搬运,但在其他场景下很重要)。
- 写合并 (Write Combining):这是专门为显存设计的策略。它允许 CPU 将多次小的写入操作(比如画一个像素)先在缓冲区合并,攒够一个突发长度后一次性写入 RAM。这极大地提高了绘图效率,同时避免了全缓存带来的复杂一致性维护。
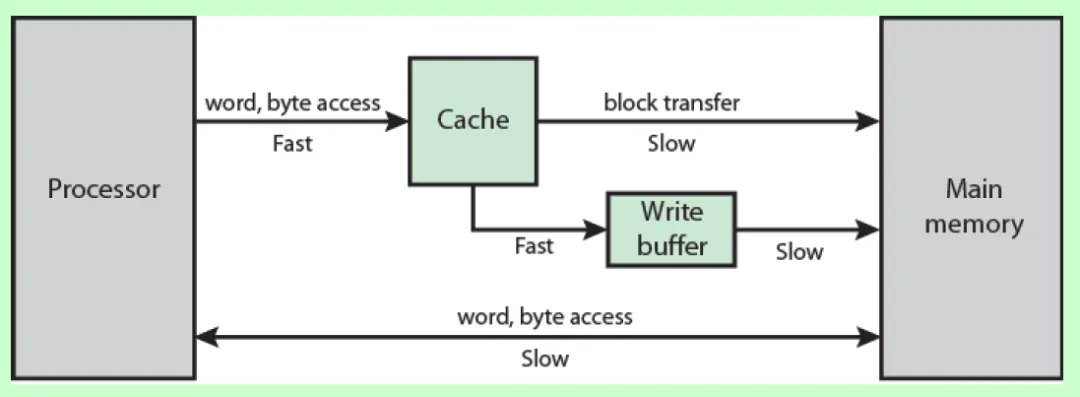
- 注意后缀
3. 代码逻辑详注
3.1 驱动入口:Probe 初始化
这是驱动生命的起点,完成了从软件到硬件的所有准备。
c
static int spidev_probe(struct spi_device *spi)
{
// ... [GPIO 初始化略] ...
/* -------------------------------------------------------
* 1. Framebuffer 核心结构体分配与设置
* ------------------------------------------------------- */
myfb_info = framebuffer_alloc(0, NULL);
/* 设置屏幕参数:分辨率 128x64,位深 1 bit (单色) */
myfb_info->var.xres = 128;
myfb_info->var.yres = 64;
myfb_info->var.bits_per_pixel = 1;
/* 计算显存大小:128 * 64 * 1 / 8 = 1024 字节 */
myfb_info->fix.smem_len = ...;
/* -------------------------------------------------------
* 2. 分配"显存" (DMA Memory)
* ------------------------------------------------------- */
/* * 关键点:这里申请了一块物理连续的内存。
* screen_base: 虚拟地址,内核线程和 CPU 通过它写入数据。
* phy_addr: 物理地址,虽然本驱动没直接用,但对 mmap 至关重要。
*/
myfb_info->screen_base = dma_alloc_wc(NULL, len, &phy_addr, GFP_KERNEL);
myfb_info->fix.smem_start = phy_addr;
/* -------------------------------------------------------
* 3. 注册 Framebuffer
* ------------------------------------------------------- */
/* 注册后,生成 /dev/fbX 设备节点,应用层可以开始画图了 */
register_framebuffer(myfb_info);
/* -------------------------------------------------------
* 4. 启动内核线程
* ------------------------------------------------------- */
/* 申请临时缓存 oled_buf,用于存放转换后的数据 */
oled_buf = kmalloc(1024, GFP_KERNEL);
/* 硬件初始化 */
oled_init();
/* 启动线程,开始死循环刷新 */
oled_thread = kthread_run(oled_thread_func, NULL, "oled_kthead");
return 0;
}3.2 核心引擎:内核线程函数 (oled_thread_func)
这是驱动的心脏,负责解决"光栅扫描"与"页寻址"的冲突。
c
static int oled_thread_func(void *param)
{
unsigned char *fb = myfb_info->screen_base; // 指向 Framebuffer 显存 (源数据)
// ... 变量定义 ...
while (!kthread_should_stop()) // 只要不卸载驱动,就一直运行
{
/* -------------------------------------------------------
* 第一步:格式转换 (Raster -> Page)
* ------------------------------------------------------- */
/* * 目标:将 128x64 的横向位流,转换为 SSD1306 需要的纵向字节流。
* SSD1306 将屏幕分为 8 页 (Page 0-7),每页高度 8 像素。
*/
k = 0;
for (i = 0; i < 8; i++) // 遍历 8 个 Page
{
// 获取当前 Page 对应的 Framebuffer 中的 8 行数据地址
for (line = 0; line < 8; line++)
p[line] = &fb[i*128 + line * 16];
// 遍历一页中的 128 列
for (j = 0; j < 16; j++) // 外层循环优化,按块处理
{
// ... 读取数据到 data 数组 ...
// 核心位操作:构造 8 个纵向字节
for (bit = 0; bit < 8; bit++)
{
// 这是一个"转置"操作:
// 取出 8 行数据的第 bit 位,拼凑成一个字节
byte = (((data[0]>>bit) & 1) << 0) | // 第0行 -> bit 0
(((data[1]>>bit) & 1) << 1) | // 第1行 -> bit 1
...
(((data[7]>>bit) & 1) << 7); // 第7行 -> bit 7
oled_buf[k++] = byte; // 存入转换后缓冲区
}
}
}
/* -------------------------------------------------------
* 第二步:SPI 发送
* ------------------------------------------------------- */
/* 将转换好的数据 (oled_buf) 通过 SPI 发送给 OLED 控制器 */
for (i = 0; i < 8; i++)
{
OLED_DIsp_Set_Pos(0, i); // 设置 OLED 显存坐标 (Page i)
oled_set_dc_pin(1); // Data 模式
spi_write_datas(&oled_buf[i*128], 128); // 发送一整页
}
/* -------------------------------------------------------
* 第三步:帧率控制
* ------------------------------------------------------- */
/* 休眠以释放 CPU。注意:HZ 导致帧率较低 (1秒1帧),实际项目应改为 msleep */
schedule_timeout_interruptible(HZ);
}
return 0;
}3.3 驱动卸载:Cleanup
严格按照初始化的逆序释放资源,防止内存泄漏或内核崩溃。
c
static int spidev_remove(struct spi_device *spi)
{
// 1. 先停止线程,不再访问内存
kthread_stop(oled_thread);
kfree(oled_buf);
// 2. 反注册 Framebuffer
unregister_framebuffer(myfb_info);
// 3. 释放 DMA 显存 (对应 dma_alloc_wc)
dma_free_wc(NULL, ..., myfb_info->screen_base, ...);
// 4. 释放结构体
framebuffer_release(myfb_info);
// ... 其他释放 ...
return 0;
}4. 学习总结与知识点提炼
- Framebuffer 驱动的本质 :
- 为内核申请一段内存 (
dma_alloc_wc)。 - 填充
fb_info结构体告诉内核这段内存的属性(分辨率、位深)。 - 用户空间看到的只是一个文件
/dev/fb0,对其读写就是操作这段内存。
- 为内核申请一段内存 (
- 软硬差异的适配 :
- 当硬件显存结构(OLED 页模式)与软件标准(Framebuffer 线性模式)不一致时,驱动程序必须充当"翻译官"。
- 这种翻译通常涉及复杂的位运算,计算量大,适合放在后台线程处理。
- 并发与同步 :
- 本驱动利用了内核线程
kthread来实现异步刷新。 - 虽然本例未加锁,但在生产环境中,如果
ioctl和thread同时操作 SPI 总线,应该使用 Mutex 互斥锁来保护临界区。
- 本驱动利用了内核线程
- DMA 内存分配 :
dma_alloc_wc是嵌入式显存分配的标准姿势,既保证物理连续(方便硬件或 mmap),又利用 Write Combining 提升了 CPU 写屏性能。