在数据可视化中,堆积条形图 擅长展示 "整体与构成" 的关系,但当每个柱子内的分段超过4个时,读者很难同时追踪各段的长度、位置与颜色映射, 误读概率显著上升。
更糟的是,若不同类别的总量差异很大,堆积结构会放大视觉错觉,导致"看起来差不多"的结论失真。
今天,本文将尝试探索一下改进堆积条形图的呈现方式,让复杂数据对比变得一目了然。
如果大家有更好的方式,也欢迎指教,交流。完整的代码会在文末提供共享的地址。
1. 堆积条形图的困境
堆积条形图就像一道精心摆盘的多层蛋糕,当层数不多时,我们能轻松分辨每层的高度差异。
但当蛋糕层数超过4层,要比较某一特定口味在多个蛋糕中的含量就变得异常困难。
下面我们用Python模拟一个常见的堆积条形图场景:调查某产品5个功能模块的用户满意度(5个维度),共收集了4个季度的数据。
python
# 模拟数据:4个季度,5个满意度维度(强烈反对、反对、中立、同意、坚决同意)
quarters = ["第一季度", "第二季度", "第三季度", "第四季度"]
categories = ["强烈反对", "反对", "中立", "同意", "坚决同意"]
colors = ["#FF6B6B", "#FF9F6B", "#D6CBCB", "#6BCF7F", "#4D96FF"]
# 每个季度的满意度分布(百分比)
data = np.array(
[
[5, 10, 25, 40, 20], # 第一季度
[3, 8, 20, 45, 24], # 第二季度
[4, 12, 18, 43, 23], # 第三季度
[2, 6, 15, 50, 27], # 第四季度
]
)
# 传统横向堆积条形图
fig, ax = plt.subplots(1, 2, figsize=(14, 4), gridspec_kw={"width_ratios": [1, 1]})
# 左图:传统横向堆积条形图
# ... 省略 ...
# 右图:横向堆叠条形图的改进版,添加分隔线
# ... 省略 ...
plt.tight_layout()
plt.show()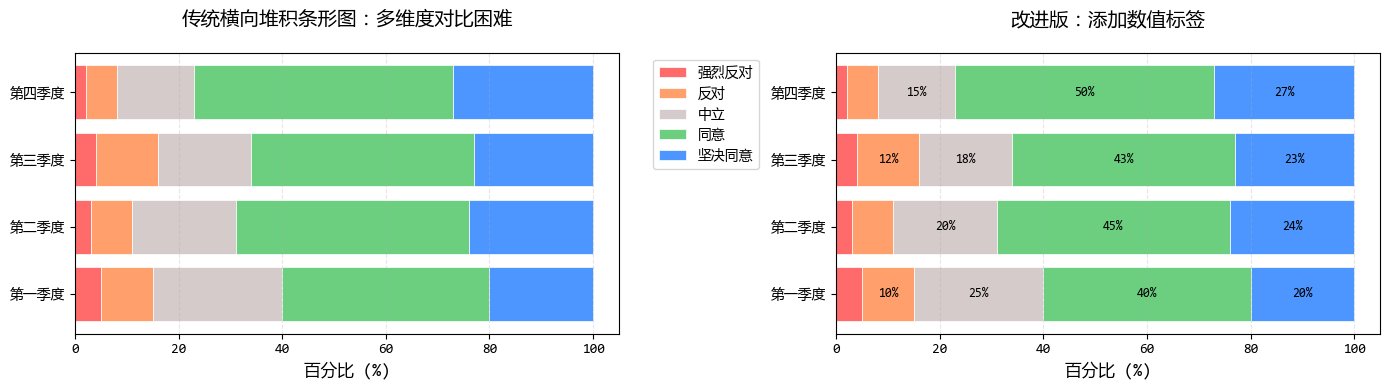
这个横向堆积条形图展示了每个季度用户满意度的完整分布,随便右边的图稍微做了一些改进,
但如果我们想回答以下问题就会遇到困难:
- "坚决同意" 的比例在哪个季度最高?
- "反对" 和 "强烈反对" 的比例如何随时间变化?
2. 拆解重构--多个子图
与其把所有食材炖在一锅里,不如将它们分盘摆放。
我们将堆积条形图拆解为5个小图,每个小图只关注一个满意度维度的季度变化。
python
import matplotlib.gridspec as gridspec
fig = plt.figure(figsize=(12, 6))
gs = gridspec.GridSpec(2, 5, figure=fig, hspace=0.3, wspace=0.4)
# 拆解堆积条形图:为每个类别创建单独的横向子图
axes = []
for i in range(5):
axes.append(fig.add_subplot(gs[0, i]))
# 为每个满意度维度创建一个横向条形图
for i, (category, color, ax) in enumerate(zip(categories, colors, axes)):
# ... 省略 ...
ax = fig.add_subplot(gs[1, :]) # 第1行,所有列 (等同于 gs[1, 0:5])
# ... 省略 ...
plt.show()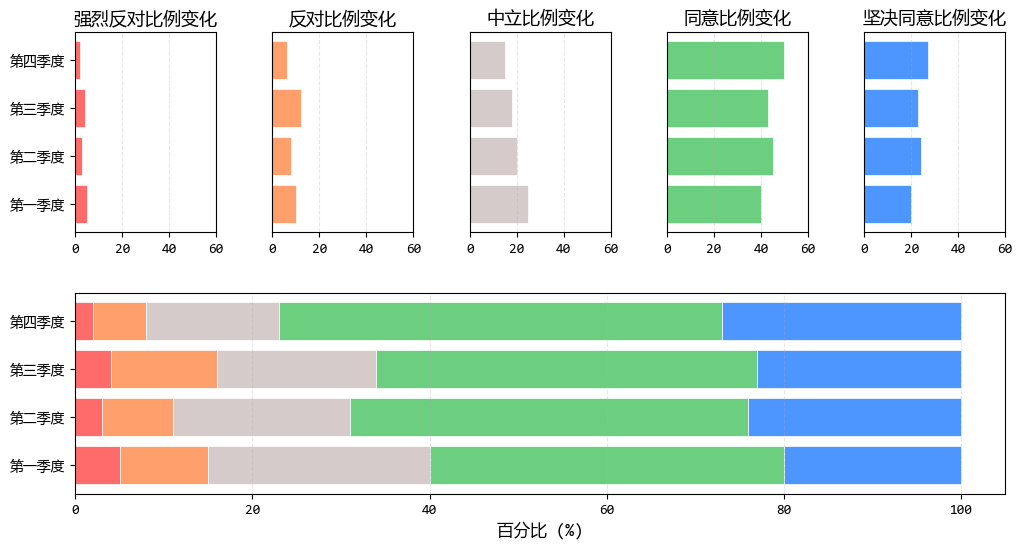
拆解后的图表确实提升了单一维度的对比效果,但仍有一个明显问题:我们的视线需要在多个图表间来回跳跃,无法形成统一的视觉印象。
这就像阅读一本分散在多个页面的表格,需要不断翻页对照。
3. 双向对比--蝴蝶图
蝴蝶图(也称为人口金字塔图或双向条形图)是数据可视化的"瑞士军刀",特别适合展示对立或双向比较的数据。
它的设计哲学是:让对比在中心轴两侧自然展开,就像蝴蝶展开双翅。
python
# 4. 创建画布
fig, ax = plt.subplots(2, 1,figsize=(10, 6))
y_pos = np.arange(len(quarters))
# 拆分数据列
strongly_disagree = data[:, 0]
disagree = data[:, 1]
neutral = data[:, 2]
agree = data[:, 3]
strongly_agree = data[:, 4]
# ==========================================
# 核心逻辑修改:以中立(Neutral)的中心为0点
# ==========================================
# 1. 绘制中立 (灰色):跨越 0 轴
# left 从 -width/2 开始,这样 0 就在正中间
# 2. 绘制左侧 (负面情绪):向左堆叠
# 反对 (Green):起始位置在 -neutral/2 的左边
# 强烈反对 (Purple):起始位置在 反对 的左边
# 3. 绘制右侧 (正面情绪):向右堆叠
# 同意 (Orange):起始位置在 neutral/2
# 强烈同意 (Red):起始位置在 同意 的右边
# 5. 美化图表
# 添加中间的基准线 (穿过中立条形)
# ... 省略 ...
plt.show()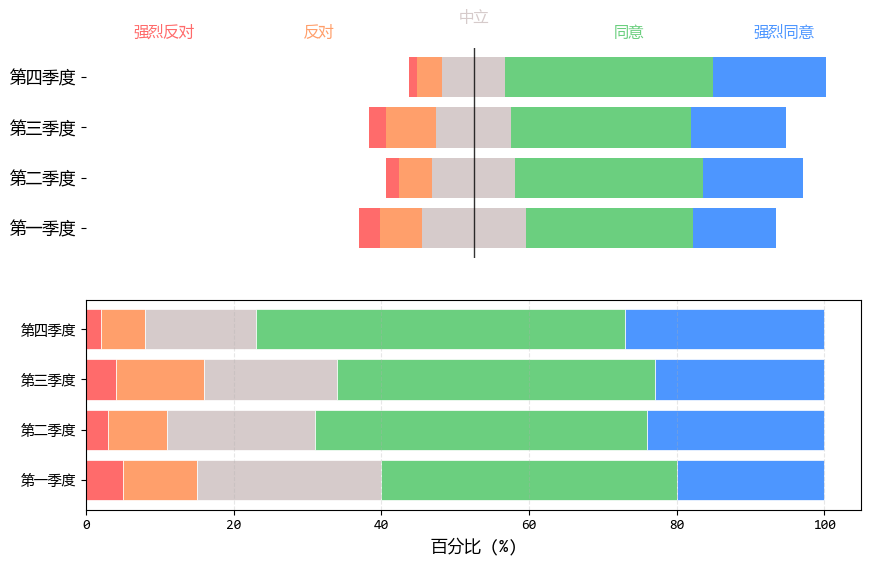
蝴蝶图和一般的堆积条形图放在一起,可以明显看出两者在数据展示逻辑和视觉重心上有显著区别。
蝴蝶图 侧重于展示 "对立态度的对比",适合看正反两面的力量悬殊以及整体的情绪倾向,而且也便于比较同侧的数据。
4. 总结
总之,堆积条形图像一锅大杂烩,当食材(数据维度)过多时,我们很难品尝(分析)到每种食材的原味。
通过拆解和重构,我们获得了更清晰的视角。而蝴蝶图则像一位优雅的舞者,将对比数据以对称的方式展开,既保留了整体视野,又强化了局部对比。
优秀的数据可视化不在于展示所有信息,而在于以最少的认知成本传达最多的洞察。
下次当我们面对多维数据对比的挑战时,不妨试试横向蝴蝶图这把"瑞士军刀",它可能会给你带来意想不到的清晰与美感。
绘制文中图像的完整代码共享在:优化堆积条形图.ipynb (访问密码: 6872)