一、动机:为什么蒸馏人类思想会失败?
大模型通过长思维链(Long CoT)推理在复杂任务上展现出令人惊叹的能力。DeepSeek-R1、QwQ-32B 等强推理模型能够进行上百步的逻辑推导,解决高难度数学问题。自然而然,我们会想:能否通过蒸馏,让小模型也学会这种能力?
字节跳动 Seed 团队的研究者进行了一系列初步实验,结果却令人困惑:

这个现象极其反直觉。人类的推理轨迹语义连贯、逻辑清晰,为什么反而不如强模型的输出?难道模型学习的不是推理内容本身,而是某种更深层的结构特性?
这个问题促使我们重新思考:大模型从 Long CoT 中究竟学到了什么?
论文标题
Molecular Structure of Thought: Long CoT Reasoning Topology Mapping
作者背景
字节跳动 Seed
发布时间
2026 年 1 月
论文地址
https://arxiv.org/abs/2601.06002
二、洞察:推理不是线性链,而是"分子结构"
2.1 传统视角的局限
传统研究将推理过程建模为:
- 链状结构
Step 1 → Step 2 → Step 3 → ... 的线性序列 - 树 / 图结构
带有分支节点的逻辑树或图
但研究团队的分析揭示,仅仅通过这些简单的二维结构,无法充分建模推理步骤之间的转移方式。具体地,作者认为推理步骤之间存在多种强度、方向不同的连接模式,它们在隐空间中 "自然延伸"、"峰回路转"、"灵活发散" ,形成了类似于化学分子的高维空间结构,并最终体现出不同的行为模式
用分子结构来建模思维过程,可不是花里胡哨的"炫技",而是存在多项实实在在的类比关系,并经过了严谨的实验论证,下面将对其展开介绍
2.2 为什么使用化学类比
通过对多个强推理模型的分析,研究者发现 Long CoT 中存在三种核心行为模式,它们的分布在不同模型和任务间高度稳定:
- 深度推理(Deep Reasoning)
紧密的逻辑推导,后续步骤严格依赖前置步骤 - 自我反思(Self-Reflection)
回溯检验早期步骤,形成"折叠"结构 - 自我探索(Self-Exploration)
尝试新的推理方向,跨越语义距离 - 普通行为(Normal-Operation)
其他不具特性的正常推理行为
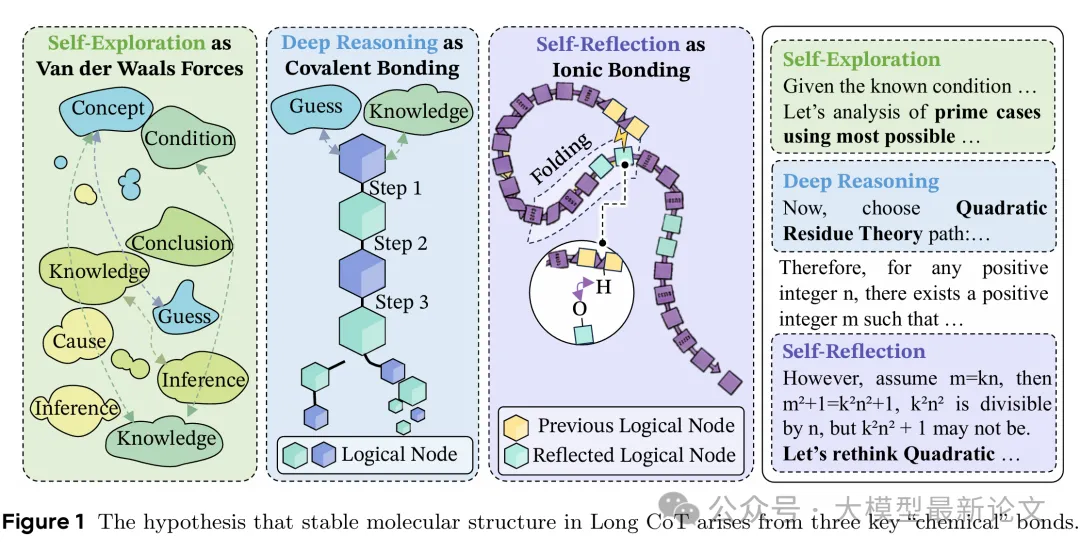
这让研究团队想到了化学中的分子结构。分子的性质不取决于原子的简单堆砌,而取决于原子间的化学键类型及其组合方式:
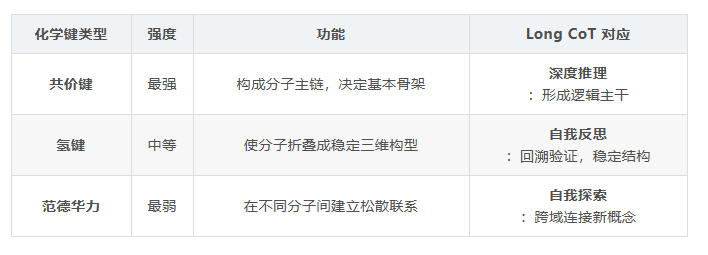
这个类比不仅形象,更重要的是它揭示了 Long CoT 的三个关键特性:
- 全局稳定性
不是孤立步骤的堆砌,而是键的组合形成稳定系统 - 异构体现象
相同任务可以有不同的"键合方式",导致不同性质 - 结构刚性
一旦形成稳定结构,很难兼容其他构型
这些特性是传统思维链、思维图无法建模的
三、实证分析
作者设计了四个层次的实验来证明上述洞察的真实性:
3.1 验证全局稳定性
问题: 这种"分子结构"真的存在吗?
方法:
- 从多个强推理模型(DeepSeek-R1、QwQ-32B、OpenAI-OSS 等)采样 Long CoT 轨迹
- 将每个推理步骤间的转移标注为三种行为类型之一
- 计算行为转移概率 P(b'|b) 和边缘分布 π(b)
分析不同模型间的相关性
预期:
"结构"意味着"稳定",是"混沌"的反面,如果分子结构假设成立,Long CoT 轨迹应该会在不同模型、任务间展现出稳定的状态转移分布

关键发现:
- 跨模型一致性
当采样数 > 2000 时,不同模型间的相关系数均 > 0.9 (p < 0.001) - 分布稳定性
不同采样规模间的相关系数 > 0.95 - 对比组失败
人类推理轨迹:相关系数 < 0.7
ICL 弱模型输出:相关系数 < 0.65
解释:
这证明强推理模型确实存在一个稳定的、跨架构的"推理拓扑结构",这种结构不存在于人类轨迹或简单的 ICL 输出中
3.2 验证结构的重要性
问题: 模型学习的真的是"结构"而非关键词吗?
方法:
- 识别 Long CoT 中的逻辑转折关键词(如:"Maybe"、"But"、"Alternatively")
- 创建三组训练数据:
- 保留关键词的原始数据
- 将关键词替换为随机变体
- 完全移除关键词
- 在三组数据上分别训练模型,对比性能
预期:
如果学习的是结构,那么即使移除关键词,只要保持行为转移分布,模型仍应有效。
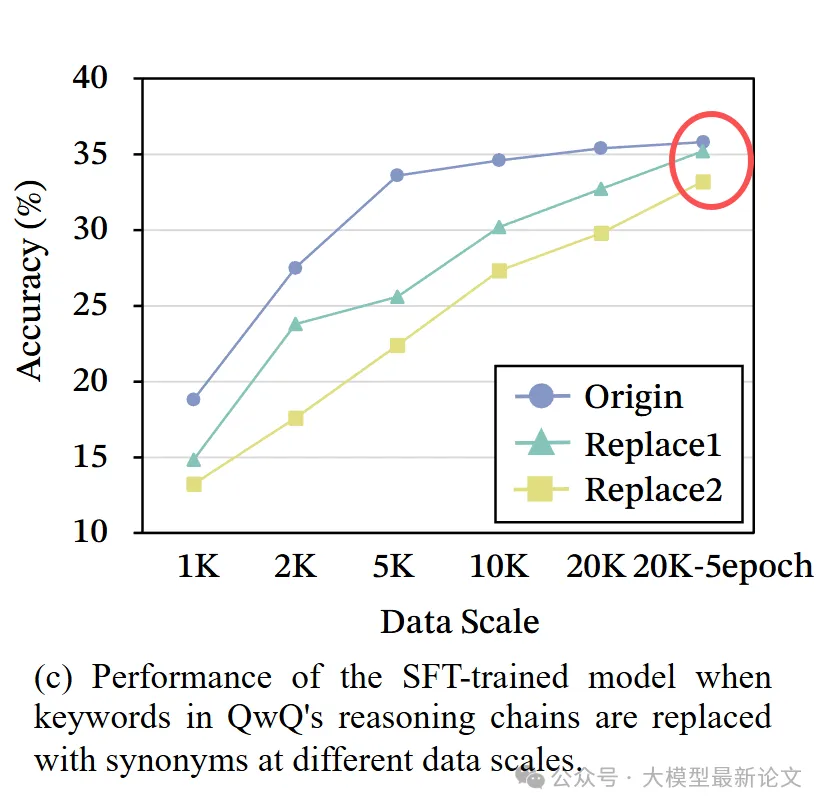
关键发现:
- 关键词能加速学习(保留 > 替换 > 移除)
- 但并非必不可少(移除后仍达到 93% 的性能)
- 尽管之前有不少研究指出这些思维关键词对推理性能有非常重要的影响,但这里更加深入地确认了:模型内化的是推理结构,而非表面词汇
3.3 几何特性分析
问题: 三种"化学键"真的对应不同的几何和强度特性吗?
方法:
- 量化三种行为的几何特性(步骤间距离、聚类模式)
- 分析注意力权重分布规律
- 对比三种行为的强度水平
预期:
深度推理应表现为紧密簇、高强度;反思应表现为折叠返回;探索应表现为大步距、弱强度
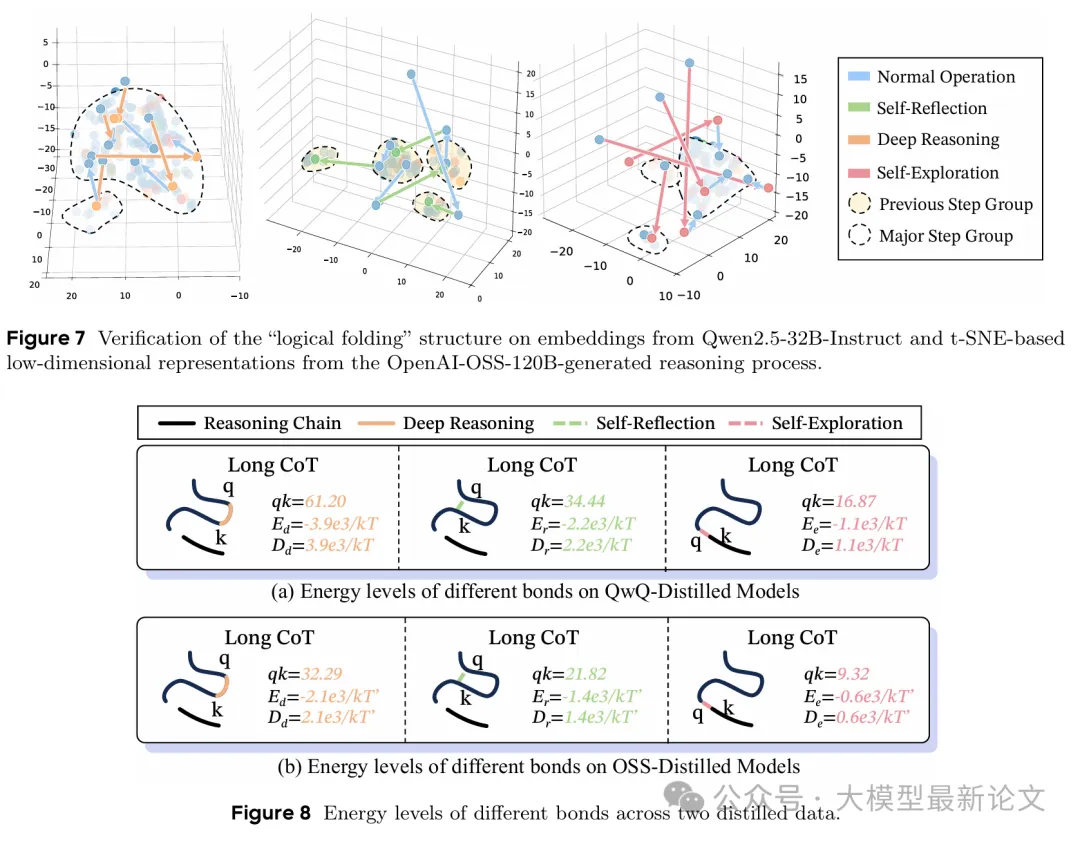
关键发现:
-
深度推理(共价键):
- 72.56% 的步骤保持组内距离 ≤ 3(组间距离 > 5.6)
- 形成紧密的局部语义簇
- 类比:串珠成链,构建稳定骨架
-
自我反思(氢键):
- 81.72% 的反思步骤重新连接到之前的高相似度簇
- 推理链"折叠"回早期步骤
- 类比:蛋白质通过氢键折叠成三维结构
-
自我探索(范德华力):
- 平均轨迹长度 5.32,表现出最大步间距离
- 在原本分离的簇之间建立松散连接
- 类比:分子间的微弱吸引力
3.4 验证结构刚性
问题: 不同结构的 CoT 数据混合在一起,是否会打乱思维结构,降低训练效果
方法:
- 选择两个结构高度相关(r ≈ 0.95)的强模型:DeepSeek-R1 和 OpenAI-OSS
- 创建三组训练数据:
- 仅使用 R1 蒸馏数据
- 仅使用 OSS 蒸馏数据
- 混合 R1 和 OSS 数据
- 对比训练后的模型性能和行为分布稳定性
预期:
混合训练应导致行为分布不稳定,性能下降
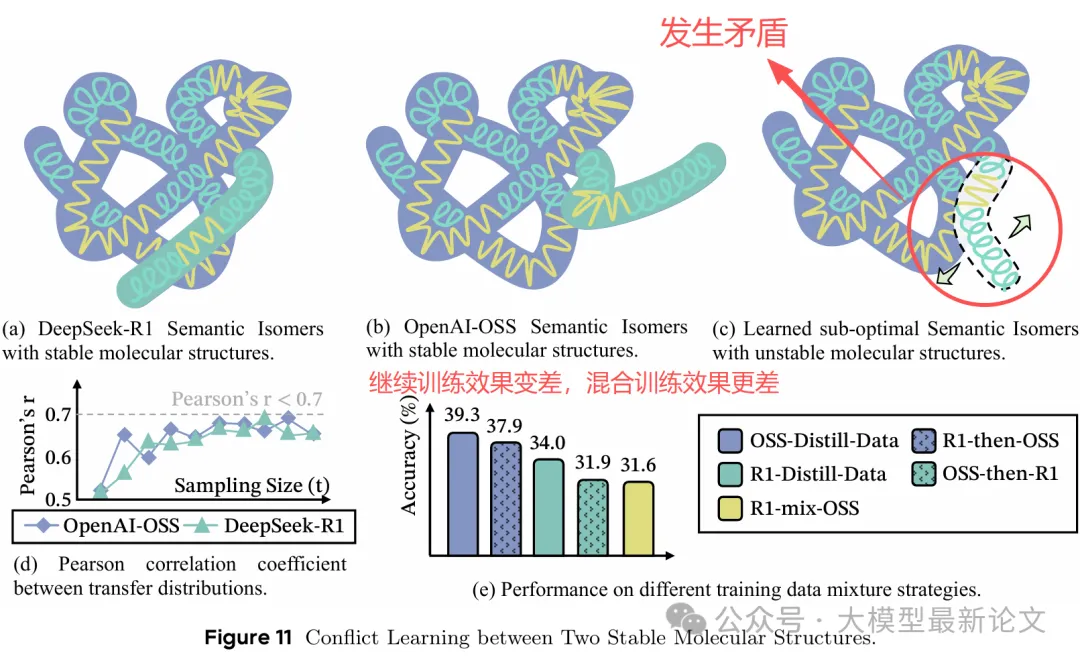
关键发现:
- R1 和 OSS 的统计相关性高达 0.95
- 但混合训练导致:
- 性能下降 25-30%
- 行为分布剧烈波动
- 模型在两种结构间"摇摆不定"
深层原因: 虽然整体分布相似,但在关键转移点上存在冲突:
- 某个状态 A→B:R1 倾向深度推理(70%),OSS 倾向探索(60%)
- 这 5% 的差异在长推理链中传播放大,导致完全不同的轨迹
四、Mole-Syn:结构感知合成方法
既然我们知道了 CoT 数据的思维结构是关键,那么我们完全可以改进训练数据的合成方法。研究团队提出了 Mole-Syn 数据合成管线,核心思想是:
不直接复制教师模型的 token,而是复制其行为转移结构,然后用指令模型填充具体内容算法流程:
1. 提取行为转移图
- 从强推理模型采样 Long CoT 轨迹
- 标注每个转移的行为类型
- 估计转移概率 P(b'|b) 和边缘分布 π(b)
2. 结构引导的轨迹生成
- 在转移图上进行随机游走,生成行为序列
- 例如:D → D → R → D → E → D → R → ...
3. 内容填充
- 使用指令模型(如 Llama-3.1-8B-Instruct)
- 给定当前推理上下文和目标行为类型
- 生成符合该行为的具体推理步骤
4. 质量过滤
- 验证生成的轨迹是否保持目标行为分布
- 过滤语义不连贯或逻辑矛盾的样本
关键优势:
- 解耦了结构迁移与模型特定的表面形式
- 可以从零开始生成符合目标分布的 Long CoT 数据
- 无需依赖昂贵的强推理模型进行在线蒸馏
五、实验结果
Mole-Syn 效果
使用 Mole-Syn 从指令模型合成 Long CoT 数据,对比直接蒸馏。
(Llama-3.1-8B-Instruct + 20K 数据):
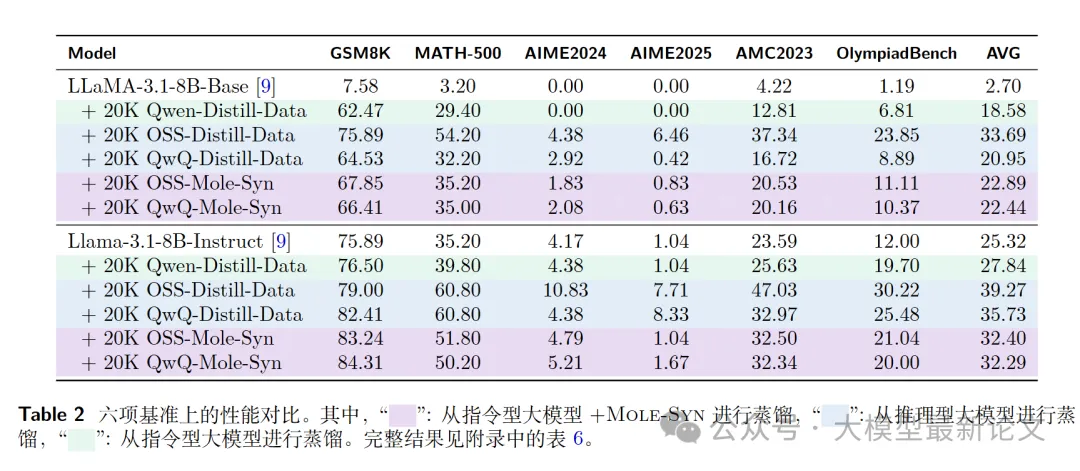
关键发现:
- Mole-Syn 达到直接蒸馏 82-85% 的性能(数据构造成本极小)
- 远超弱指令模型蒸馏(+4.5 个百分点)
- 证明 Long CoT 能力可通过纯结构迁移实现
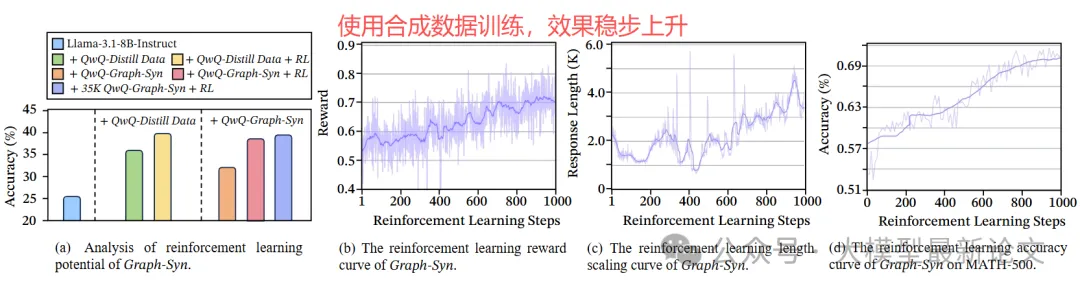
强化学习稳定性:
- Mole-Syn 初始化的模型在 RL 微调中表现更稳定
- 收敛速度提升 30%
- 验证了合成结构的持久性收益
人类 vs 模型:思维模式差异分析
追踪 R1 模型和人类在信息相空间中的推理动态:
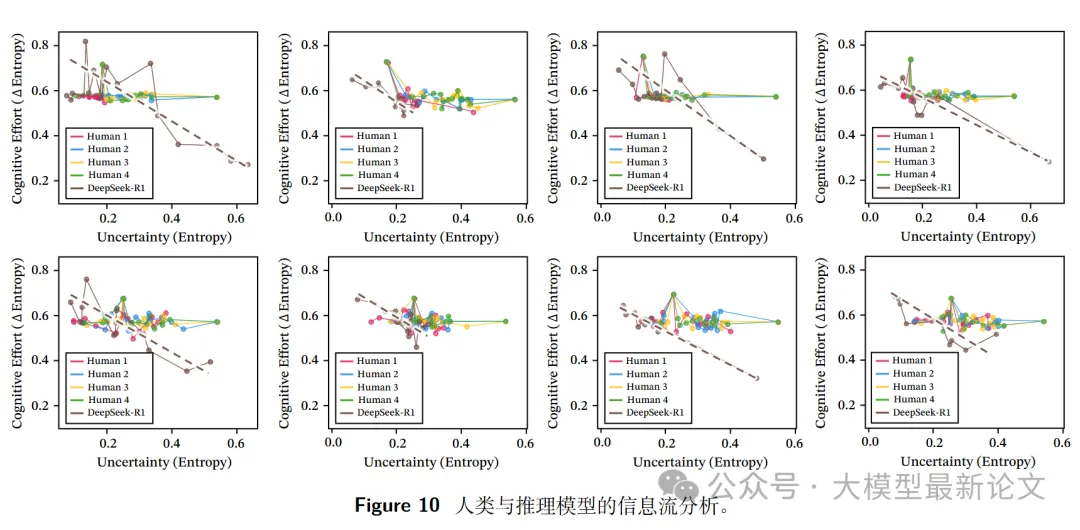
人类:近乎零斜率(稳步推进)
- 81.3% 的情况中,信息增益变化量 < 0.1
- 推理轨迹:近乎水平(匀速前进)
- 类比:爬楼梯,每步高度相同
R1 模型:明显斜率(加速收敛)
- 76.1% 的情况中,信息增益变化量 > 0.1
- 推理轨迹:上升曲线(加速下坡)
- 类比:滑雪,找到方向后加速冲刺
元认知振荡现象:
- R1 模型在两种状态间交替:
- 发散探索:高熵,斜率 > 0.6
- 收敛验证:低熵,快速降低不确定性
- 这种振荡在人类的均匀分布中不明显
六、启发
1. 结构比 token 重要
Long CoT 学习的关键不在于模仿表面 token,而在于内化行为转移结构。这解释了:
✅ 为什么强推理模型蒸馏有效:它们有稳定的结构
❌ 为什么简单 token 蒸馏失败:复制了形式,未复制结构
❌ 为什么人类轨迹难以迁移:人类与模型的结构分布不同
✅ 为什么关键词可以替换:只要结构不变,表面形式可变
2. 兼容性比相似性重要
推理系统具有内在刚性,就算只有 5% 的结构差异也会在长推理链中传播并放大
3. "语义异构体"的脆弱性
相同任务可以有多个有效的"推理分子结构"(异构体),但:
- 每个异构体内部必须稳定(自相关 > 0.9)
- 不同异构体之间往往不兼容(混合导致混沌)
- 微小差异(5%)可能产生巨大影响(性能下降 25%)
这解释了为什么模型训练需要数据一致性,而不仅仅是数据多样性。
✅ 应该做的:
分析数据结构
训练前评估行为转移分布,确保一致性
结构优先
关注推理行为的全局分布,而非特定关键词
避免混合冲突
不要盲目混合不同来源的 Long CoT 数据
❌ 应该避免的:
假设"数据越多越好",忽略结构兼容性
依赖人类标注的推理轨迹(结构分布不同)
简单混合高相关(> 0.9)的数据源(可能仍有冲突)
七、未来研究方向
1. 跨模态推理
问题:分子结构视角是否适用于多模态推理?
探索方向:
- 视觉推理中的"化学键":图像区域的关联方式
- 代码推理中的"化学键":函数调用、数据流、控制流
- 视觉-语言对齐:两种模态的"异构体兼容性"
2. 人机对齐
问题:如何让模型推理动态更接近人类?
探索方向:
- 减少元认知振荡,实现均匀信息增益
- 调整训练目标使行为结构分布与人类对齐
- 引入社会反馈和语义连贯性约束
3. 结构发现与优化
问题:能否自动发现更优的"推理异构体"?
探索方向:
- 通过神经架构搜索探索行为转移空间
- 基于任务特性优化三种键的比例
- 多异构体集成:训练多个兼容的异构体模型
4. 防御性应用
洞察:推理压缩和摘要方法能破坏 Long CoT 结构。
应用方向:
- 防止未授权的模型蒸馏
- 保护私有推理模型的内部结构
- 设计"结构水印"检测蒸馏行为