目录
[Activation Unit模块](#Activation Unit模块)
核心问题:大规模稀疏数据场景下,L2正则化计算开销大,且可能丢失未出现在当前Mini-Batch中的特征信息。
本文主要对DIN这篇文章的重点部分进行描述,和代码实战,详细描述可参考这篇文章:
推荐系统分享系列-DIN(Deep Interest Network for Click-Through Rate Prediction)(一)
一、主要创新点和重点
通过引入注意力机制动态捕捉用户兴趣,进行向量表征
#### **Activation Unit模块**
1. 输入包括用户历史行为商品的Embedding、候选商品Embedding,以及两者的外积和差值向量。通过多层感知器(MLP)计算注意力得分,反映历史行为与候选商品的相关性。
1. 为什么使用外积和差值可以参考以下讲解?
2. [推荐系统分享系列-DIN(Deep Interest Network for Click-Through Rate Prediction)-注意力机制](https://blog.csdn.net/flying_1314/article/details/156826710?sharetype=blogdetail&sharerId=156826710&sharerefer=PC&sharesource=flying_1314&spm=1011.2480.3001.8118 "推荐系统分享系列-DIN(Deep Interest Network for Click-Through Rate Prediction)-注意力机制") #### **加权求和**
1. 将注意力得分与历史行为商品的Embedding加权求和,得到用户兴趣的动态表示。
1. 需要注意⚠️的是,这里并没有将注意力得分进行**归一化**工程优化技术提升模型在大规模稀疏数据场景下的性能
### **核心问题**:大规模稀疏数据场景下,L2正则化计算开销大,且可能丢失未出现在当前Mini-Batch中的特征信息。- 解决方案 :
- 仅对非零特征更新:
-
在深度推荐模型中,特征通常以高维稀疏形式存在(如商品ID、用户ID等)。传统L2正则化会对所有参数(包括零值特征对应的参数)进行约束,公式为:
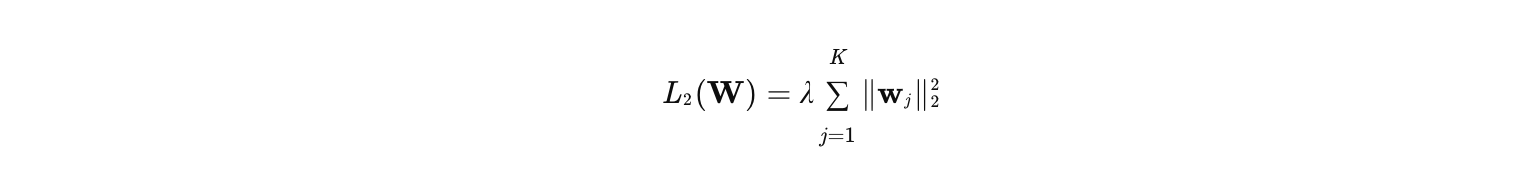
-
其中:
- K 是特征总数(如1亿个商品ID),
- wj 是第j个特征的嵌入向量,
- λ 是正则化系数。
-
-
在每个Mini-Batch中,仅对参数不为零的特征进行梯度更新,减少计算量。
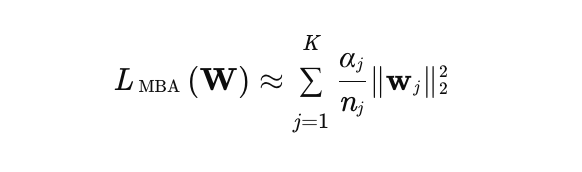
1.- αj 是特征j在当前mini-batch中出现的次数(若未出现则为0),
- nj 是特征j在所有训练数据中出现的总次数(用于平衡高频和低频特征)。
-
关键点:
稀疏感知:仅当αj>0时(即特征j在当前batch中出现),才计算其正则化项。
频率平衡:通过nj调整高频特征的正则化力度(高频特征nj大,正则化强度相对减弱)。
- 稀疏感知:仅当αj>0时(即特征j在当前batch中出现),才计算其正则化项。
-
- 仅对非零特征更新:
激活函数调整
-
具体可以参考这篇文章:
面试常问系列(一)-激活函数-relu/leaky_relu/prelu/dice
- Dice激活函数
- 核心问题:传统激活函数(如ReLU、PReLU)的校正点固定,无法适应输入数据分布的变化,可能导致梯度消失或爆炸。
- 解决方案:
- 动态调整校正点:Dice激活函数根据每层输入数据的均值和方差,自适应调整校正点的位置。
- Dice激活函数
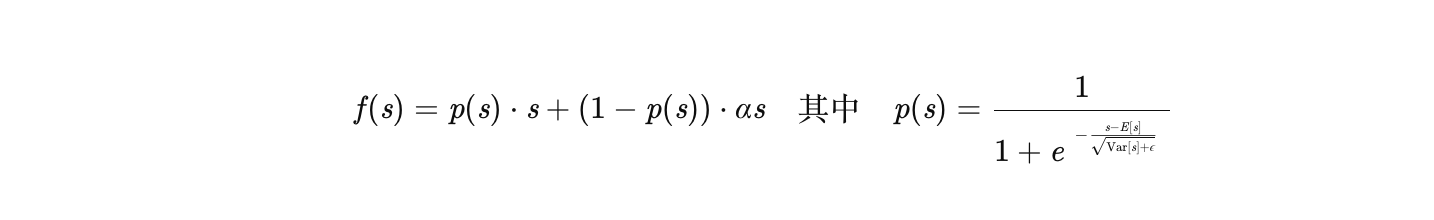
二、待改进点
用户兴趣对表征是静态的
- DIN通过注意力机制对用户历史行为进行加权求和,生成用户兴趣的静态表示(即假设用户兴趣在预测时刻是固定的)。
- 问题:未考虑用户兴趣随时间的动态变化(如季节性偏好、短期热点、兴趣转移)。
粗粒度的兴趣表征
- DIN直接对历史行为ID进行嵌入(Embedding)后加权求和,兴趣表示较粗糙(仅依赖ID级特征)。
- 问题:无法捕捉行为背后的深层语义(如商品类别、风格、用户动机)。
长序列行为捕捉能力较弱
- DIN的注意力机制依赖历史行为与目标商品的直接相似度,对长序列行为(如用户多年前的点击)的捕捉能力较弱。
三、代码实战
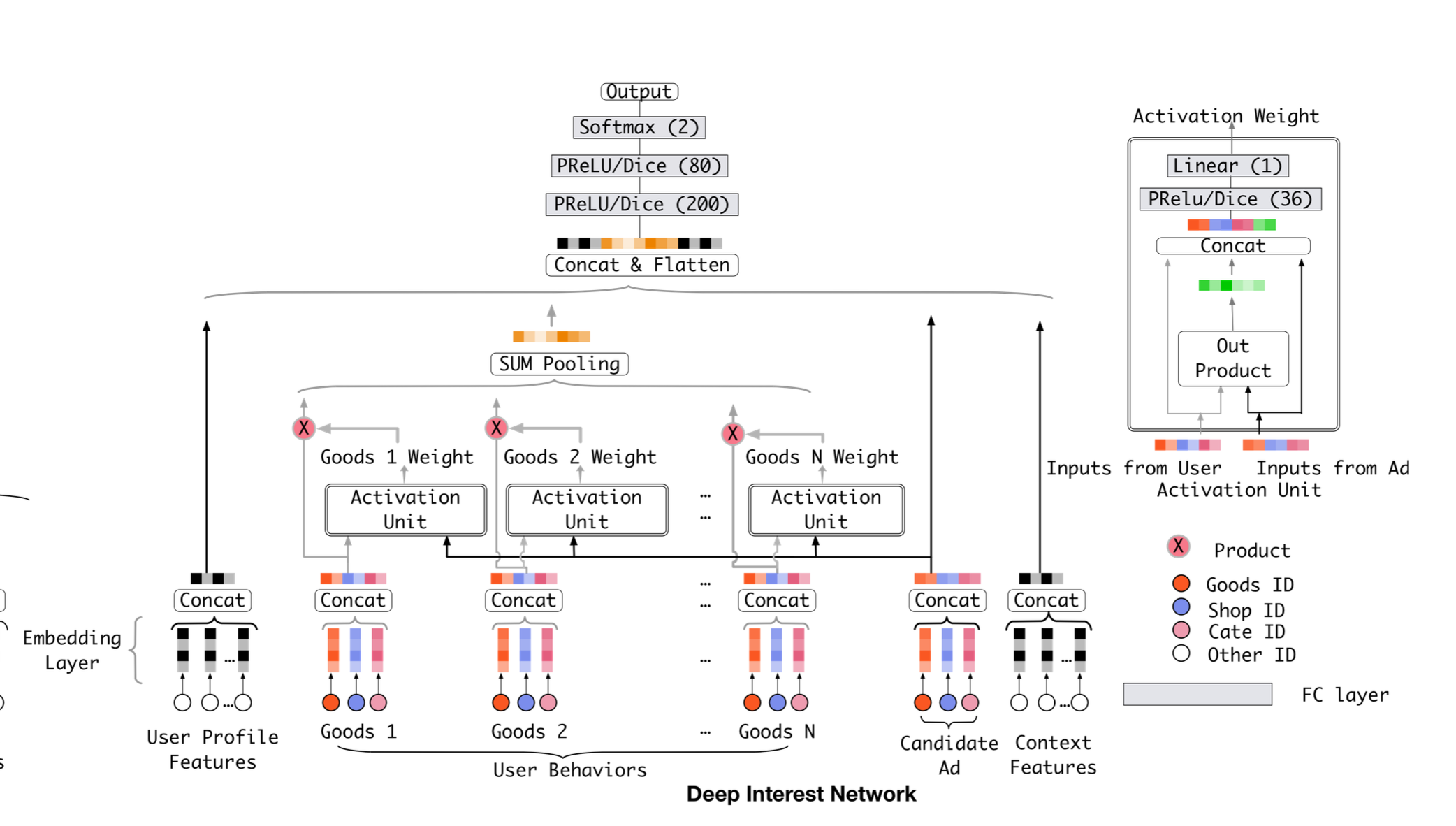
这里代码只做框架演示,DIN主要包含3部分:
本部分希望大家可以先有个宏观认知,具体的代码细节,之后产出会放出供大家参考~。
- Embedding layer
- 输入:处理后的特征:用户特征,用户历史行为序列,目标资源
- 输出:用户向量batch,emb,用户历史行为向量batch,seq,emb,目标资源向量batch,emb
python
class EmbeddingLayer(nn.Module):
def __init__(self,emb_dim):
pass
def forward(self,data):
pass
return user_emb,his_emb,target_emb- Attention layers
- 输入:用户历史行为向量batch,seq,emb,目标资源向量batch,emb,差值,外积
- 获得注意力值,这里没有做归一化,直接乘上用户历史行为向量,做加权求和。
- 输入:用户历史行为向量batch,emb
- 输入:用户历史行为向量batch,seq,emb,目标资源向量batch,emb,差值,外积
python
class AttentionLayer(nn.Module):
def __init__(self):
self.att_layer = mlp(input = 4*emb_dim,output = 1);
def forward(self,data):
input = torch.cat([target_item,his_seq, target_item - his_seq, target_item * his_seq]) #[batch,seq_len,4*emb_dim]
attention_score = self.att_layer(input)
output = (attention_score * his_seq).sum(dim=1) #[batch,seq_len, emb_dim] ->[batch,emb]
return output- MLP layer
- 输入:batch,emb,用户历史行为向量batch,emb,目标资源向量batch,emb
- 输出:ctr预估值
python
class mlp(nn.Module):
def __init__(self):
mlp_layers = []
mlp_layers.append(...)#nn,norm,activation_func
self.dnn = nn.sequential(mlp_layers)
def forward(self,data)
return self.dnn(data)din论文相关细节,就分享到这里了,后续会针对din的待改进点进行进一步的延展,欢迎大家评论区多交流~