目录
[1. 传统注意力机制的局限性](#1. 传统注意力机制的局限性)
[2. 外积的作用:显式建模特征交互](#2. 外积的作用:显式建模特征交互)
[3. DIN中如何使用外积?](#3. DIN中如何使用外积?)
[4. 外积的工程实现优化](#4. 外积的工程实现优化)
[5. 外积与其他方法的对比](#5. 外积与其他方法的对比)
[6. 总结:为什么DIN需要外积?](#6. 总结:为什么DIN需要外积?)
[1. 差值的定义与计算](#1. 差值的定义与计算)
[2. 差值在DIN中的作用](#2. 差值在DIN中的作用)
[(1) 补充外积的交互信息](#(1) 补充外积的交互信息)
[1. 定义商品特征向量](#1. 定义商品特征向量)
[2. 计算差值向量](#2. 计算差值向量)
[3. 对比反向差值(用户兴趣未转移)](#3. 对比反向差值(用户兴趣未转移))
[4. 差值如何反映用户兴趣变化趋势](#4. 差值如何反映用户兴趣变化趋势)
[(2) 增强特征的非线性表达能力](#(2) 增强特征的非线性表达能力)
[(3) 适应推荐场景的动态性](#(3) 适应推荐场景的动态性)
[3. 差值与外积的协同设计](#3. 差值与外积的协同设计)
[(1) 特征拼接(Concatenation)](#(1) 特征拼接(Concatenation))
[(2) MLP处理](#(2) MLP处理)
[(3) 为什么需要同时使用差值和外积?](#(3) 为什么需要同时使用差值和外积?)
[4. 差值的工程实现优化](#4. 差值的工程实现优化)
[5. 差值与其他方法的对比](#5. 差值与其他方法的对比)
[6. 总结:差值在DIN中的核心价值](#6. 总结:差值在DIN中的核心价值)
主要承接这篇文章:
本文主要详细解释下,为什么在DIN的注意力机制的输入,会输入外积?
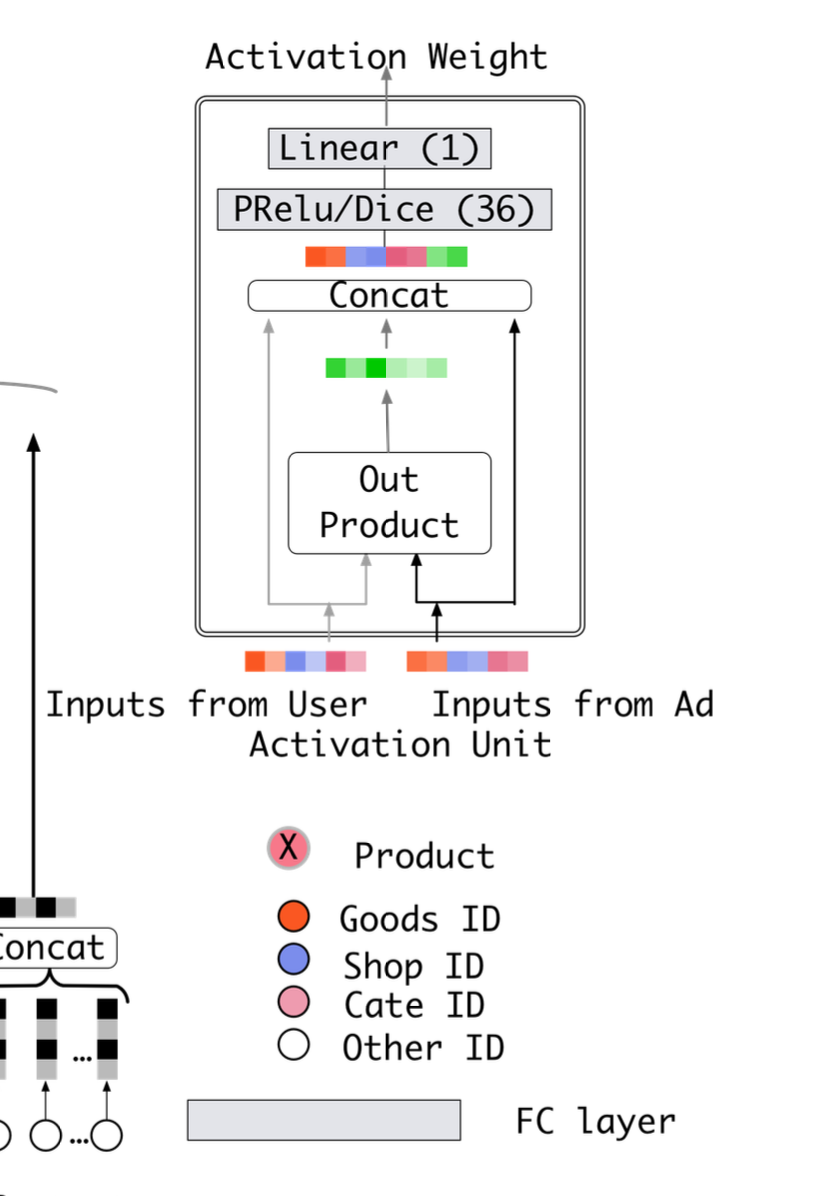
一、外积
DIN(Deep Interest Network)模型在注意力机制中引入外积(Outer Product)的主要目的是增强特征交互的表达能力 ,通过捕捉用户历史行为商品与候选商品之间的多维交互关系,从而更精准地计算注意力权重。以下是详细解释:
1. 传统注意力机制的局限性
在标准的注意力机制中,通常通过以下方式计算用户历史行为商品 hi 与候选商品 c 的相关性得分:
- 点积(Dot Product) :
- 仅计算两个向量的线性相关性,丢失了非线性交互信息。
- 加性(Additive) :
- 虽然能捕捉非线性关系,但拼接(Concatenation)操作可能无法充分挖掘特征间的复杂交互。
问题 :点积和加性方法均无法显式建模特征之间的多维交互模式(如组合特征、交叉特征),可能导致注意力权重计算不准确。
2. 外积的作用:显式建模特征交互
外积(Outer Product)是一种矩阵运算,将两个向量 和
转换为矩阵
:
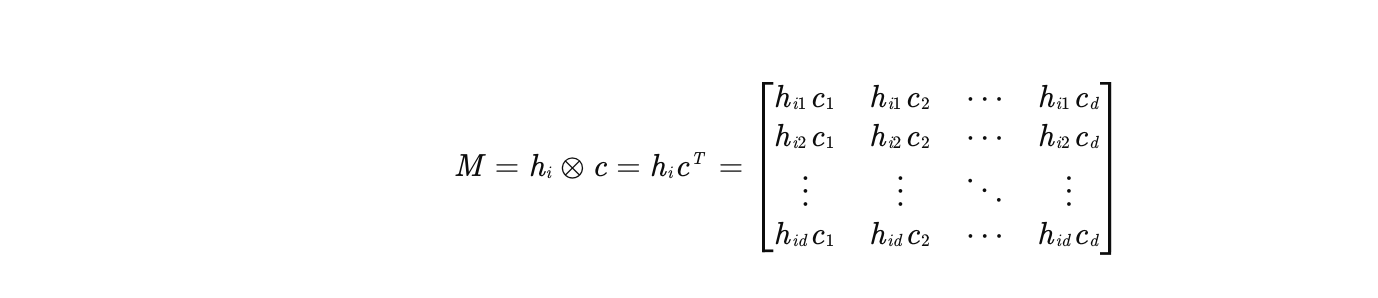
为什么需要外积?
- 捕捉多维交互模式 :
- 外积生成的矩阵 M 包含了 hi 和 c 所有维度的乘积组合 (如
、
- 例如,在电商推荐中,用户历史购买商品的"品牌"维度可能与候选商品的"类别"维度存在强关联,外积能显式建模这种交叉关系。
- 外积生成的矩阵 M 包含了 hi 和 c 所有维度的乘积组合 (如
- 保留原始特征信息 :
- 点积和加性方法可能丢失部分特征信息(如符号、相对大小),而外积通过矩阵形式保留了所有原始特征的组合,为后续网络提供更丰富的输入。
- 增强非线性表达能力 :
- 外积矩阵 M 可视为一种"高阶特征",后续通过MLP处理时,能自动学习更复杂的非线性关系,提升注意力权重的准确性。
3. DIN中如何使用外积?
在DIN的Activation Unit模块中,外积与其他操作(如差值、拼接)结合,共同生成注意力权重:
- 输入特征 :
- 用户历史行为商品的Embedding:hi
- 候选商品的Embedding:c
- 特征交互计算 :
- 外积:M=hi⊗c(捕捉多维交互)
- 差值:Δ=hi−c(捕捉方向性差异)
- 拼接:hi;c;Δ;M(合并所有特征)
- 注意力权重计算 :
- 将拼接后的向量输入MLP,输出注意力得分 ei:
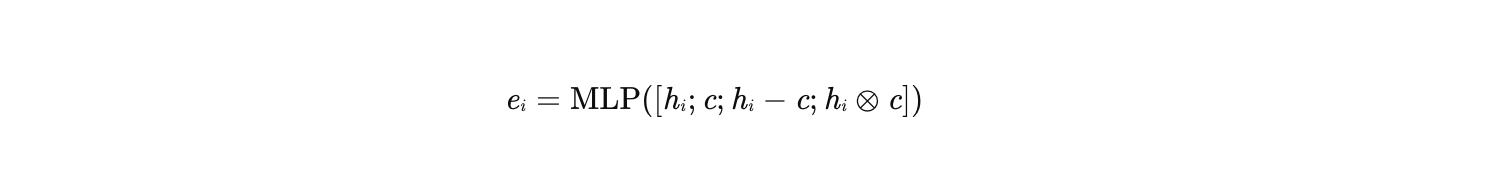
-
通过Softmax归一化得到权重 αi:
-
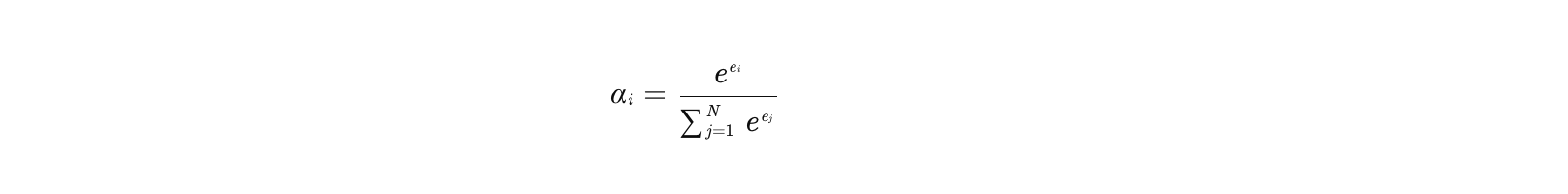
- 用户兴趣表示 :
- 加权求和得到用户兴趣向量 vu:
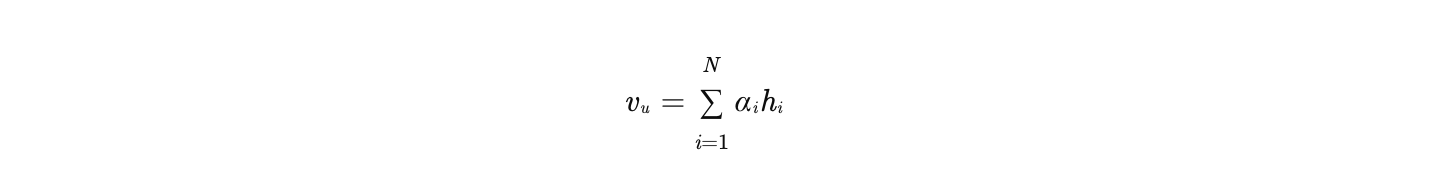
4. 外积的工程实现优化
直接计算外积可能带来高维矩阵(如 d=128 时,),导致计算和存储开销大。DIN通过以下方式优化:
- 降维处理 :
- 对 hi 和 c 先通过线性变换降维(如从128维降到32维),再计算外积,减少矩阵维度。
- 并行计算 :
- 外积的每个元素独立计算,可并行化加速。
- 稀疏性利用 :
- 在稀疏数据场景下,外积矩阵中大量元素为零,可通过稀疏矩阵优化存储和计算。
5. 外积与其他方法的对比
| 方法 | 优点 | 缺点 |
|---|---|---|
| 点积 | 计算高效,适合低维向量 | 丢失非线性交互信息 |
| 加性 | 能捕捉非线性关系 | 拼接操作可能无法充分交互特征 |
| 外积 | 显式建模多维交互,保留原始信息 | 计算开销大,需优化实现 |
| 外积+MLP | 结合外积的交互能力和MLP的非线性 | 实现复杂度较高 |
6. 总结:为什么DIN需要外积?
- 提升注意力权重准确性:外积显式建模用户历史行为商品与候选商品之间的多维交互,使注意力机制能更精准地捕捉相关兴趣。
- 增强模型表达能力:通过矩阵形式的交互特征,为后续MLP提供更丰富的输入,提升模型对复杂用户行为的理解能力。
- 适应推荐场景需求:在电商推荐中,用户兴趣与商品属性的交叉关系(如"品牌+类别")对预测至关重要,外积能有效捕捉这种关系。
外积的引入是DIN模型在注意力机制设计上的关键创新,显著提升了模型在动态兴趣建模上的性能。
二、差值
在DIN(Deep Interest Network)模型的注意力机制中,差值(Difference) 是与外积(Outer Product) 并列的核心特征交互操作,其作用是通过捕捉用户历史行为商品与候选商品之间的方向性差异,为注意力权重计算提供更丰富的上下文信息。以下是对差值的详细描述及其与外积的协同作用分析:
1. 差值的定义与计算
差值操作直接计算用户历史行为商品 hi 与候选商品 c 的Embedding向量之差:
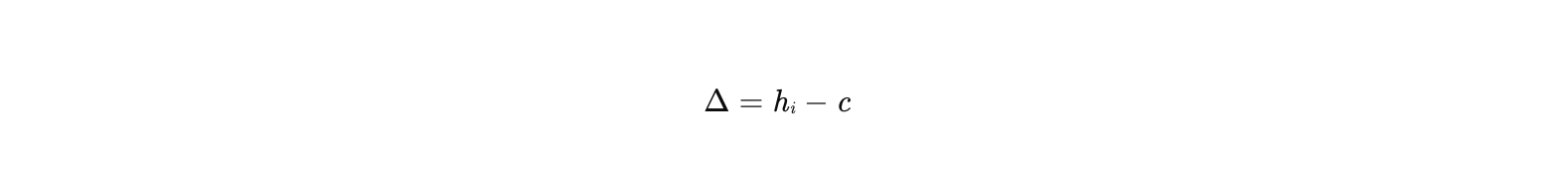
其中:
差值的直观意义
- 方向性信息 :差值不仅关注特征值的绝对大小,还捕捉了两者之间的相对方向 。例如:
- 若 hi 和 c 在"价格"维度上的差值较大,可能表明用户对价格敏感。
- 若在"品牌"维度上的差值为零,可能表明用户对品牌无偏好差异。
- 距离感知:差值的模(如欧氏距离 ∥Δ∥2)可衡量两个商品的相似性,但DIN更关注逐维差异而非整体距离。
2. 差值在DIN中的作用
(1) 补充外积的交互信息
-
外积的局限性 :外积通过矩阵乘法捕捉所有维度的乘积组合(如
- 外积可能认为 hi=1,2 和 c=2,4 的交互与 hi=2,4 和 c=1,2 相同,这里大家也可以动手演算一下(因外积矩阵元素成比例),但实际两者方向相反。
-
差值的补充 :差值能显式区分这种方向性差异(如 Δ1=−1,−2 vs Δ2=1,2),帮助模型理解用户兴趣的变化趋势。
-
举例子补充
- 场景背景
- 假设用户的历史行为中频繁购买**"中低端手机"** (价格低、配置中等),而当前候选商品是**"高端旗舰手机"**(价格高、配置顶级)。我们需要通过差值向量分析用户兴趣是否可能发生转移。
1. 定义商品特征向量
-
假设我们用2维Embedding表示商品特征:
- 维度1:价格(数值越大表示价格越高)
- 维度2:配置等级(数值越大表示配置越高端)
-
历史行为商品 hi :
中低端手机,Embedding为 hi=1,2
(价格=1,配置=2)
候选商品 c :
高端旗舰手机,Embedding为 c=3,5
(价格=3,配置=5)
2. 计算差值向量
- 差值 Δ=hi−c
- 场景背景
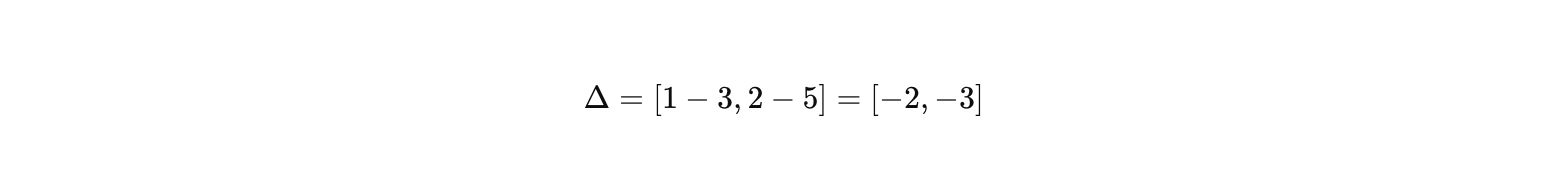
差值的直观解释
- 价格维度差值=-2 :候选商品比历史行为商品贵2个单位。
- 配置维度差值=-3 :候选商品比历史行为商品配置高3个单位。
- 方向性 :差值向量为 −2,−3,指向第三象限,表示候选商品在价格和配置上均高于历史行为商品。
3. 对比反向差值(用户兴趣未转移)
假设另一个候选商品 c′ 是**"更低端手机"** ,Embedding为 c′=0,1。
其差值 Δ′=hi−c′:
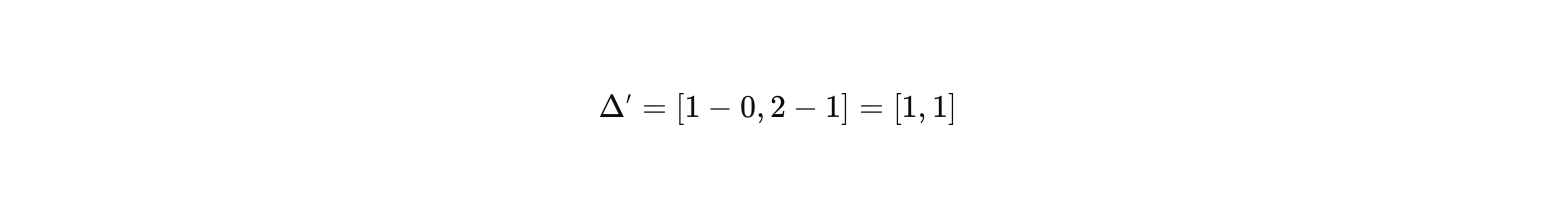
差值的直观解释
- 价格维度差值=+1 :候选商品比历史行为商品便宜1个单位。
- 配置维度差值=+1 :候选商品比历史行为商品配置低1个单位。
- 方向性 :差值向量为 1,1,指向第一象限,表示候选商品在价格和配置上均低于历史行为商品。
-
4. 差值如何反映用户兴趣变化趋势
通过对比 Δ=−2,−3 和 Δ′=1,1,模型可以捕捉以下趋势:
- 兴趣升级(高端化) :
- 若用户历史行为以 −2,−3 类型的差值为主(候选商品更贵、配置更高),可能表明用户兴趣向高端转移。
- 模型会为这类候选商品分配更高的注意力权重,因为差值方向与用户潜在升级趋势一致。
- 兴趣稳定(同层级) :
- 若差值接近零向量(如 Δ=0.1,−0.2),表示候选商品与历史行为商品特征相似,用户兴趣稳定。
- 模型会分配中等注意力权重。
- 兴趣降级(低端化) :
- 若差值以 1,1 类型为主(候选商品更便宜、配置更低),可能表明用户兴趣向低端转移(如预算收紧)。
- 模型会为这类候选商品分配更低或更高的权重,取决于具体场景(如促销活动可能逆趋势推荐)。
- 兴趣升级(高端化) :
(2) 增强特征的非线性表达能力
- 差值向量 Δ 与原始向量 hi、c 拼接后输入MLP,使网络能学习更复杂的非线性关系。例如:
- 用户可能对"价格高于历史行为"的商品更感兴趣(正差异),或对"价格低于历史行为"的商品更感兴趣(负差异)。
- 差值可帮助模型捕捉这种条件偏好,而外积可能无法直接建模此类关系。
(3) 适应推荐场景的动态性
- 在电商推荐中,用户兴趣可能随时间或上下文变化。差值能反映候选商品相对于用户历史行为的偏离程度 ,从而动态调整注意力权重。例如:
- 若用户近期频繁购买"低价"商品,候选商品的"高价"特征(差值为负)可能降低其注意力权重。
- 若用户兴趣转向"高端"商品,差值为正的"高价"特征可能提升权重。
3. 差值与外积的协同设计
在DIN的Activation Unit模块中,差值与外积、原始向量共同构成输入特征,通过以下方式协同工作:
(1) 特征拼接(Concatenation)
将以下特征拼接为一个长向量:
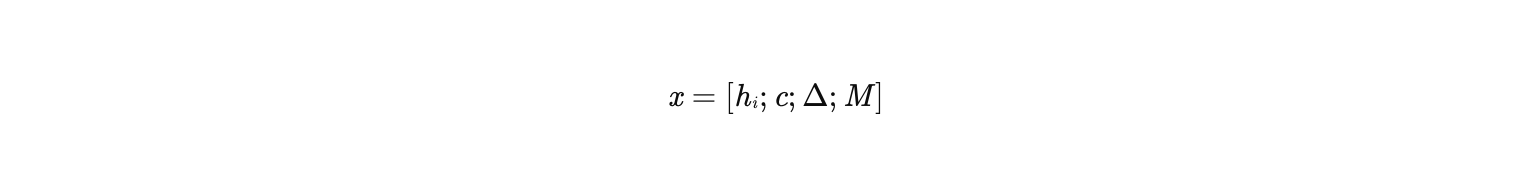
其中:
- hi:历史行为商品的原始Embedding。
- c:候选商品的原始Embedding。
- Δ=hi−c:差值向量。
- M=hi⊗c:外积矩阵(通常先降维再展开为一维向量)。
(2) MLP处理
拼接后的向量 x 输入多层感知机(MLP),自动学习特征间的复杂交互:
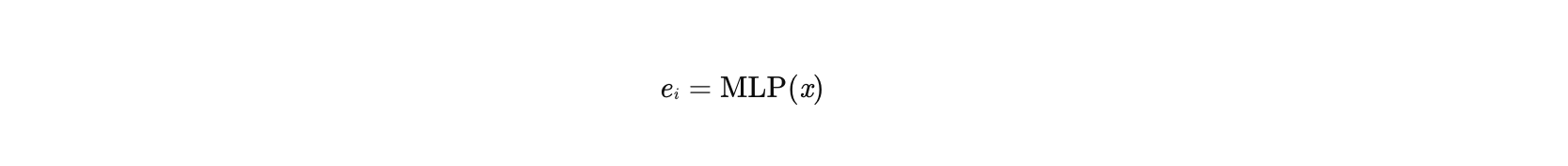
其中 ei 为未归一化的注意力得分,后续通过Softmax得到权重 αi。
(3) 为什么需要同时使用差值和外积?
- 外积 :捕捉乘积组合(如 hi1c2),适合建模特征间的协同作用(如"品牌×类别")。
- 差值 :捕捉方向性差异(如 hi1−c1),适合建模特征间的相对变化(如"价格高低")。
- 原始向量:保留基础特征信息,防止交互操作导致信息丢失。
通过组合使用,DIN能同时利用乘积交互 和差异信息,更全面地刻画用户历史行为与候选商品的关系。
4. 差值的工程实现优化
直接计算差值虽简单,但在大规模稀疏数据场景下需优化:
- 降维处理 :
- 若原始Embedding维度 d 较大(如128维),可先通过线性变换降维(如降到32维),再计算差值,减少计算量。
- 稀疏性利用 :
- 在稀疏数据中,差值向量可能包含大量零值,可通过稀疏矩阵存储和计算优化。
- 并行计算 :
- 差值的每个维度独立计算,可并行化加速。
5. 差值与其他方法的对比
| 方法 | 优点 | 缺点 |
|---|---|---|
| 外积 | 显式建模多维乘积交互 | 计算开销大,可能丢失方向信息 |
| 差值 | 捕捉方向性差异,计算高效 | 无法直接建模乘积交互 |
| 拼接(仅 hi,c) | 实现简单 | 交互能力有限,可能欠拟合 |
| 外积+差值 | 结合乘积交互和方向差异 | 实现复杂度较高 |
6. 总结:差值在DIN中的核心价值
- 提升注意力权重的动态性:通过方向性差异,使模型能根据用户历史行为与候选商品的相对关系动态调整兴趣权重。
- 增强特征交互的全面性:与外积互补,覆盖乘积组合和方向差异两类交互模式,避免信息丢失。
- 适应推荐场景的复杂性:在电商等场景中,用户兴趣可能受价格、品牌、类别等多维度差异影响,差值能有效建模此类条件偏好。
差值的引入是DIN模型在特征交互设计上的关键创新之一,与外积共同构成了其强大的动态兴趣建模能力的基础。