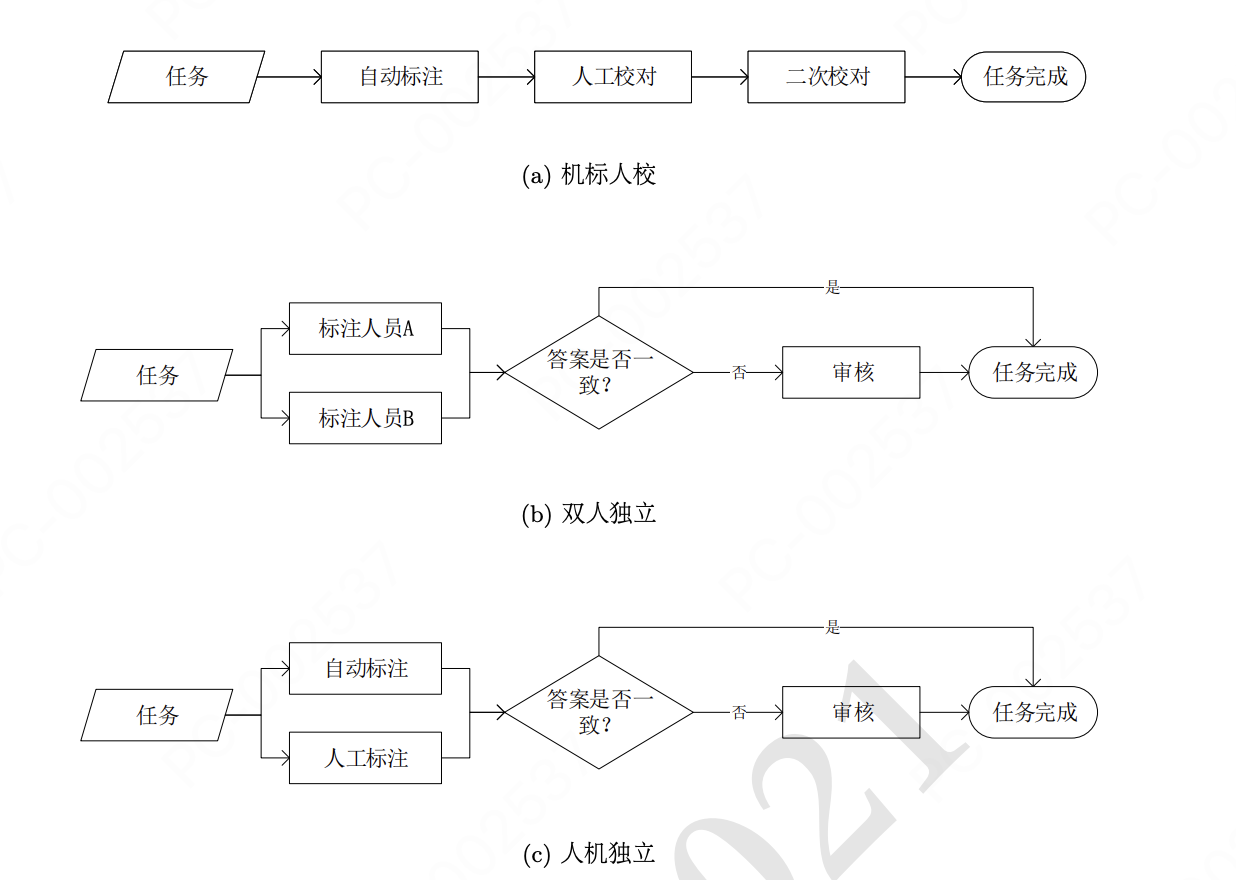
1.数据标注方法比较研究:以依存句法树标注为例
核心:总结和对比了几种人工与机器结合的方式,人机串行vs并行,如下图:
2.DeepSeek-Math: 提出强化学习算法GRPO
- 算法思想
对同一个prompt进行k次模型生成得到k条response, 每条response每个token收到的奖励信号是ri,t = pi_theta/pi_ref, 序列级别的奖励被广播到了句子的每一个token上, 计算每个response的组内优势𝐴𝑖,𝑡,𝐴𝑖,𝑡 在该序列内部对所有token也是一样的
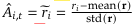
再计算整个目标函数去优化策略网络,目标函数min(序列奖励-KL散度(策略网络,参考网络))
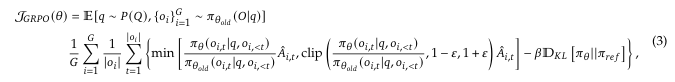
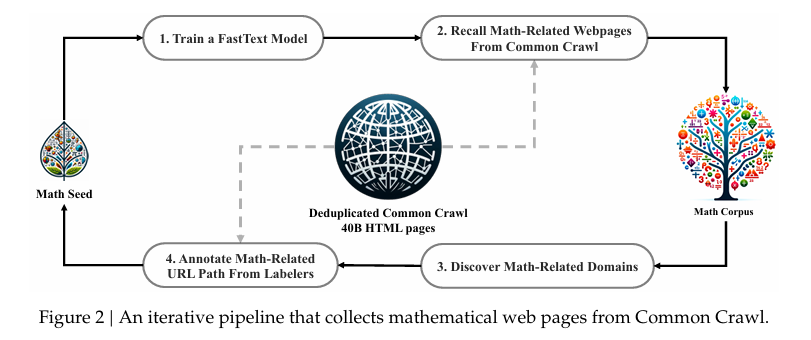
- DeepSeek Math中对于数学数据集的处理过程
训练FastText模型->从Common Crawl中召回数学相关的网页->使用数学规则库标记并发现带有数学相关Pattern的数据->训练FastText模型(效果提升)-> 召回数据 -> ...
- 数据集构建 PipeLine
种子数据选择
使用高质量数学网页数据集OpenWebMath作为初始种子,训练FastText分类器(维度256,学习率0.1),区分数学与非数学内容。
正样本:50万条OpenWebMath数据;负样本:50万条Common Crawl随机网页。
迭代数据挖掘
第一轮:从去重后的40B Common Crawl网页中筛选出40B数学相关token(按分类器得分排名保留高质量部分)。
后续迭代:通过分析域名(如mathoverflow.net)手动标注数学内容URL,扩充种子数据并更新分类器。经过四轮迭代,最终获得35.5M网页(120B token)。
去污染处理
过滤与评测集(如GSM8K、MATH)重叠的内容,避免测试集数据泄露给训练集。
3.QianfanHuijin Technical Report A Novel Multi-Stage Training Paradigm for Finance Industrial LLMs
1.核心论点:
现有SFT->General RL训练范式的不足
-
领域知识缺口:他们对专业的金融术语、复杂的概念以及固有的市场逻辑缺乏深入的理解。
-
推理与计算精度:在处理财务报表分析或数值计算等任务时,通用模型容易出现事实性错误和幻觉。
-
合规与安全风险:确保生成的内容严格遵守严格的金融法规,仍然是一项重大挑战。
-
工具依赖性:现实世界的财务任务通常需要与外部数据库和计算引擎进行互操作,而通用模型往往缺乏这种能力。
训练框架: 两阶段继续预训练+多阶段后训练
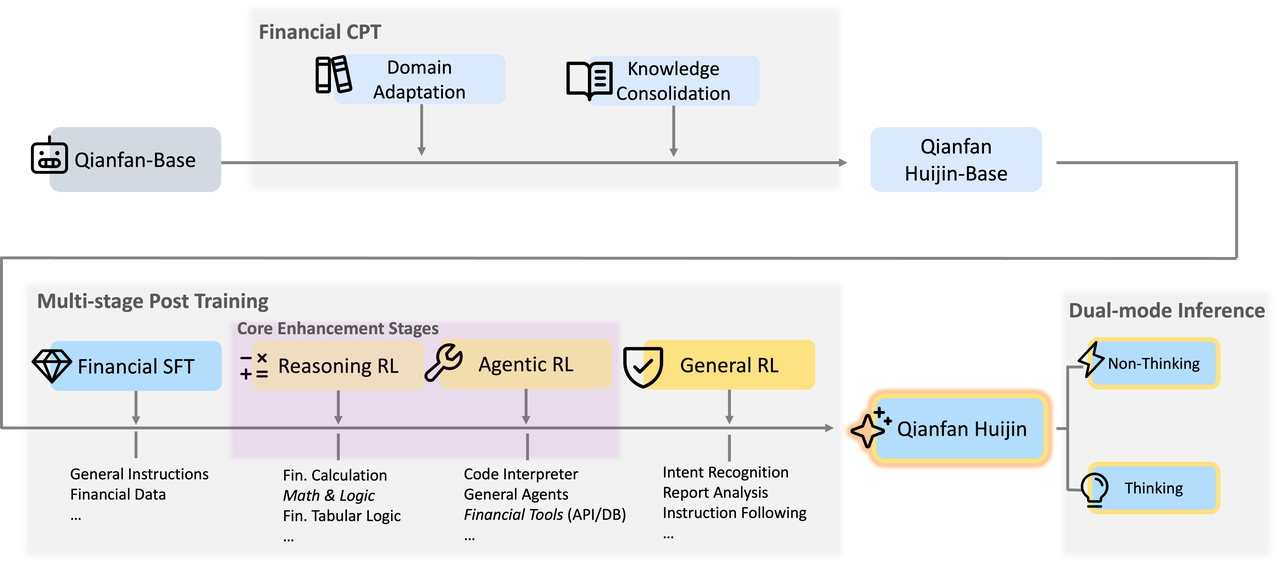
2.两阶段继续预训练
-
继续预训练作用
在预训练过程中混合金融领域的QA数据,注入金融领域知识
-
预训练数据来源
web数据专有财务数据
-
预训练数据处理
金融数据召回:对于web数据,通过一个bert分类出金融相关书籍(和deepseekmath中的FastText作用相同),合并专有财务数据去重复,清洗多维度过滤,得到种子数据和最终的数据

-
数据合成(问答对生成)
知识提取与种子生成 :首先从高密度语料库中提取关键的金融知识点(种子数据),然后,通过整合通常 3 至 5 个随机选取的知识点来生成问题,以确保问题涵盖上下文的多个方面。
指令进化 :为提升难度和广度,采用多轮指令进化来优化问题一致性验证:利用先进的模型(例如 DeepSeek-R1 guo2025deepseek、Ernie-4.5 ernie2025technicalreport)针对同一个合成问题,利用多个模型生成多个回答,然后应用语义一致性过滤器来剔除那些回答中关键信息相互矛盾的问答对
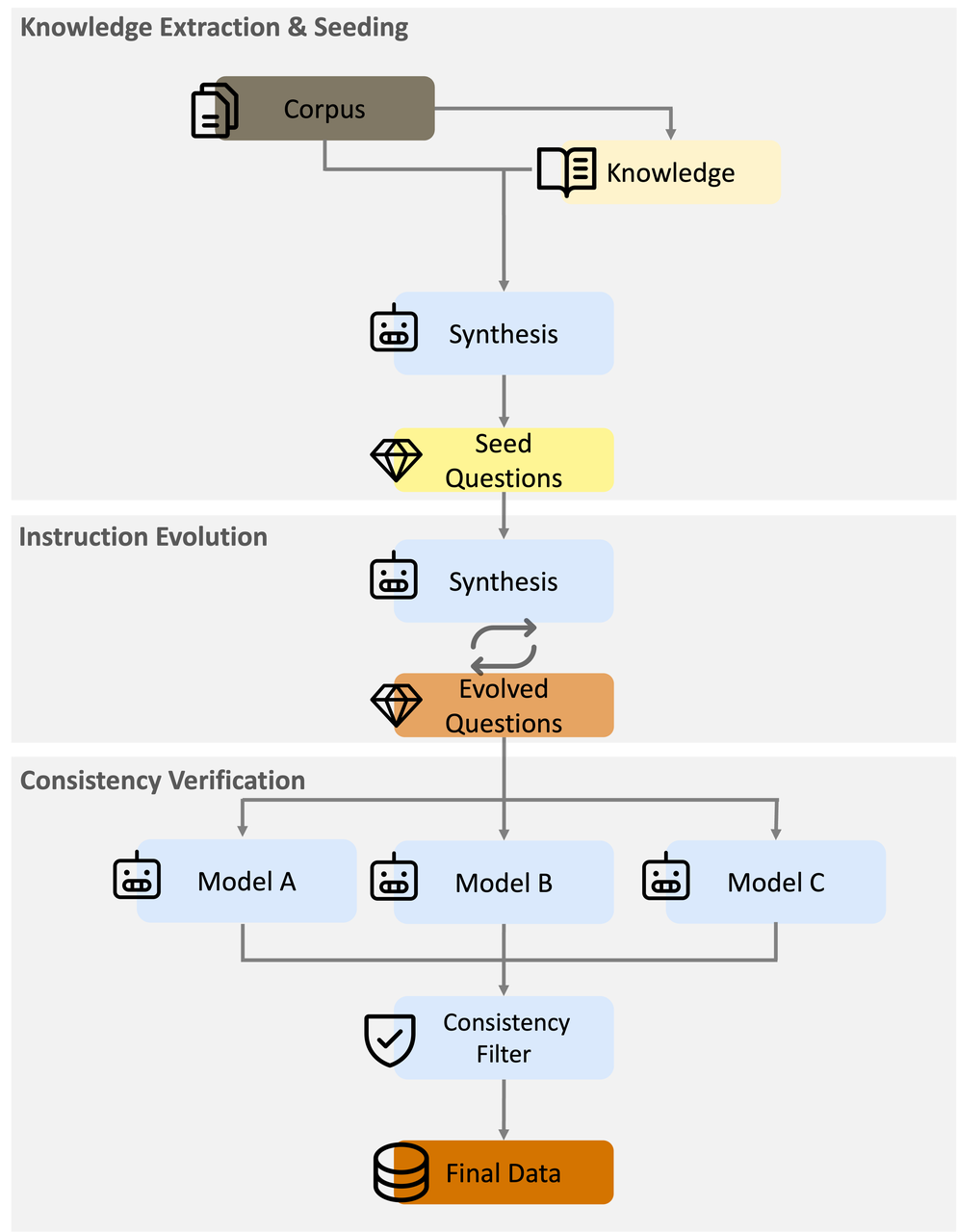
-
两阶段继续预训练
阶段 1 :金融知识注入(基础构建)。主要目标是将通用 LLM 转变为金融专家基础模型。我们专注于掌握广泛的金融术语、概念、逻辑关系和写作风格。在这一阶段,我们使用大规模的金融和通用语料库混合进行训练。这确保了有效的领域适应,同时防止了通用语言能力的灾难性遗忘。
阶段 2:金融能力提升(知识巩固)。在阶段 1 模型的基础上,此阶段侧重于深化知识并优化专业领域知识的分布。我们通过从阶段 1 中抽取顶级语料库并增加金融问答数据的权重来整理一个更高密度的数据集。这种策略确保了专业金融洞察力与通用能力之间的强平衡,有效地弥合了预训练与后续监督微调(SFT)阶段之间的差距。经过阶段 2 后,性能显著提升。
3.多阶段后训练的pipeline
动机:作者指出 SFT+GeneralRL的方式,在通用强化学习无法有效地弥合结构化金融交易模型与复杂金融任务之间存在的巨大推理差距,财务数据需要精准确性,逻辑链条和精确数值计算
Reasoning RL: 利用大规模、高质量的数据,这些数据侧重于财务逻辑和计算方面。其目标是将在单一任务训练(SFT)过程中所学到的"模仿推理"转化为一种真正内化的逻辑和计算能力。(加入思维链推理)
Agentic RL : 基于推理基础,赋予模型调用外部数据库和计算引擎的能力,遵循 ReAct 模式(让模型学会使用工具)方案:整合了一种双模式机制------"思考"和"非思考"------使模型能够在简单任务的高效响应和复杂分析的显式推理之间灵活切换,结合Reasoning,非Reasoning, 做到多样化响应,从而在效率和质量之间实现了最佳平衡
SFT → Reasoning RL → Agentic RL → General RL
第一阶段(SFT):建立基础的语言理解能力和指令遵循能力,同时涵盖思考模式和非思考模式。
第二阶段(Reasoning RL):侧重于金融和数学领域,以培养深度推理和计算方面的严谨性。
第三阶段(Agentic RL):通过加强与外部工具的合作,将研究应用到实际场景中。
第四阶段(General RL):进行全面优化,使专业能力与人类的普遍偏好相匹配
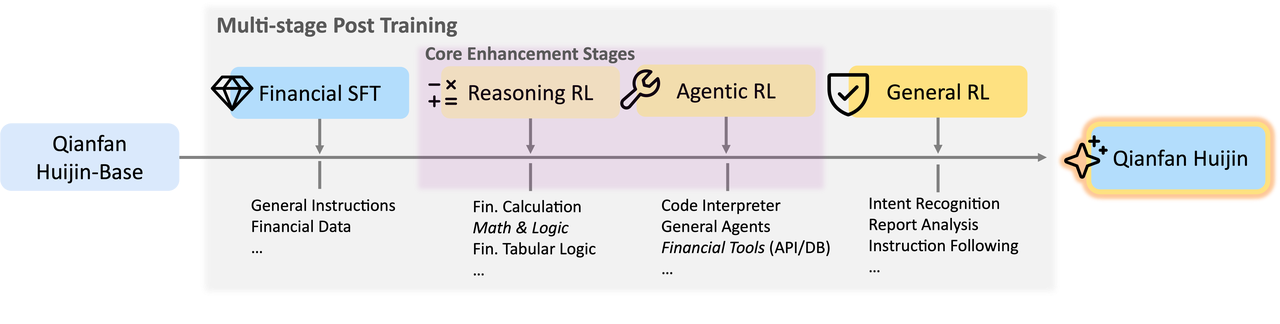
主要亮点:相比SFT+GeneralRL, 增加了reasoning RL(使模型学会了reasoning和非resoning的混合模式);Agentic RL通过训练加强了模型使用工具的能力,这个在deepseek-v3.2的技术报告中也有应用
4.后训练数据合成
主要是生成各种问答对,中间也使用了模型+人工校验演化迭代的方式
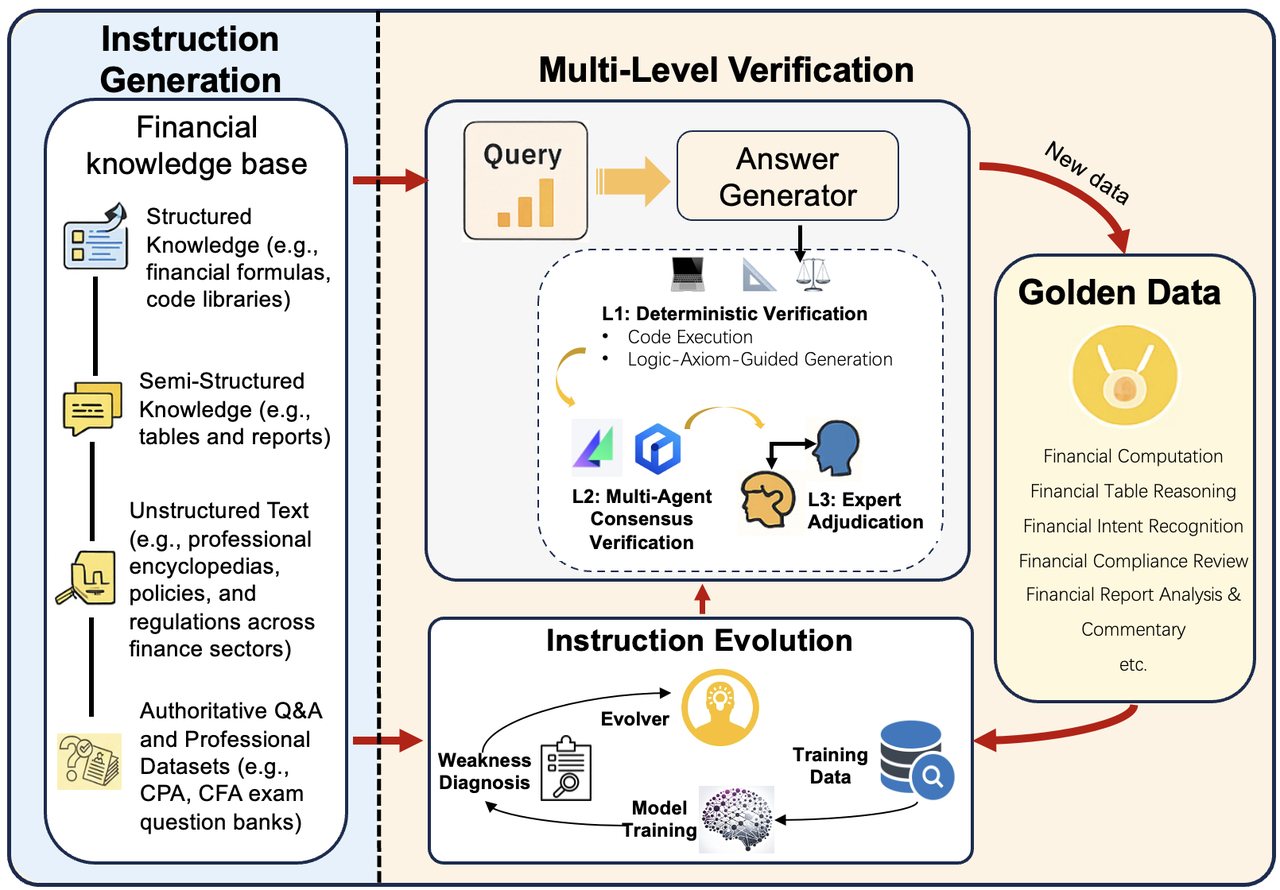
数据标注技术路线对比

后训练SFT与RL对比

工业界大模型通常遵循以下演进路线
冷启动 SFT:
使用几千到几万条极高质量的样本,让模型学会基本的推理格式和对话规矩。
强化学习 (RL):
- Reasoning RL: 针对逻辑题,利用结果校验(如代码运行成功、数学题算对)作为奖励信号。
- Preference RL: 针对主观题,利用Reward Model或人类排序数据。
- Agentic RL: 针对工具使用,让模型学会指定目标和计划,自主进行决策和行动,并接受人类或自动评估反馈,完成特定任务循环迭代: 很多时候会在 RL 之后再收集一波由模型自己生成的、通过了 RL 筛选的高质量样本,回头再做一次 SFT(即反思微调/Reject Sampling Fine-tuning),形成螺旋式上升。
参考:
Large Language Models for Data Annotation and Synthesis: A Survey
大语言模型(LLM)数据标注技术调研:定义、框架、提示、反馈、评价、挑战、机遇
数据标注方法比较研究:以依存句法树标注为例
DeepSeekMath: Pushing the Limits of Mathematical Reasoning in Open Language Models
QianfanHuijin Technical Report A Novel Multi-Stage Training Paradigm for Finance Industrial LLMs