最近在读 Seastar 的代码,发现它的定时器、无锁队列等核心组件都用了 Boost 的侵入式链表(boost::intrusive::list)。这让我停下来想:为什么一个高性能 C++ 框架宁愿放弃 std::list 的便利性,也要用更"麻烦"的侵入式设计?
链表是一种离散存储结构,优势在于中间插入/删除快------只要改几个指针就行,不用搬数据。但怎么组织链表节点和实际数据的关系,其实有两种截然不同的思路:侵入式 和 非侵入式。
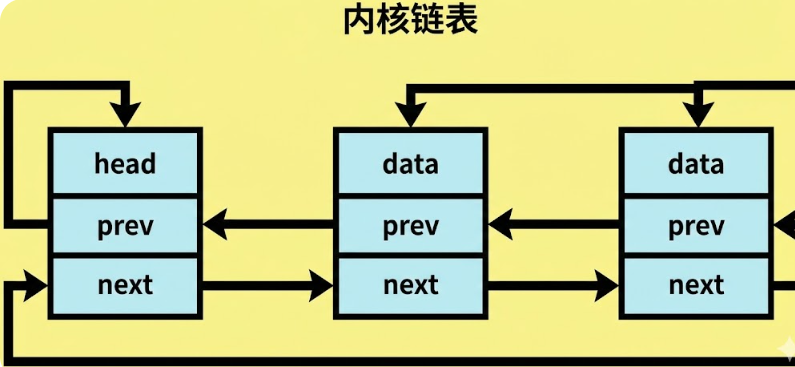
Linux 内核用的是侵入式链表。它的 list_head 结构非常简单,就两个指针:prev 和 next。如果希望某个结构体能被串进链表,就得手动把 struct list_head 嵌到你的结构体里。
比如:
struct task_struct {
int pid;
char name[16];
struct list_head run_list; // ← 链表节点是结构体的一部分
};这样做看起来"污染"了数据结构------本来只想存任务信息,现在还得塞个链表字段进去,封装性确实变差了。但它的好处也很直接:
第一,一个对象可以同时属于多个链表(比如一个 task 既在运行队列里,又在等待队列里),只要它包含多个 list_head 字段就行;
第二,访问效率高------拿到链表节点指针后,通过 container_of 宏就能直接算出宿主结构体的起始地址,不需要额外跳转或查表。
但这种技巧在 C++ 里没那么容易复制。因为 C++ 的对象内存有虚函数,前面会多一个 vptr;开了 RTTI 编译器可能偷偷在头部加 type_info。
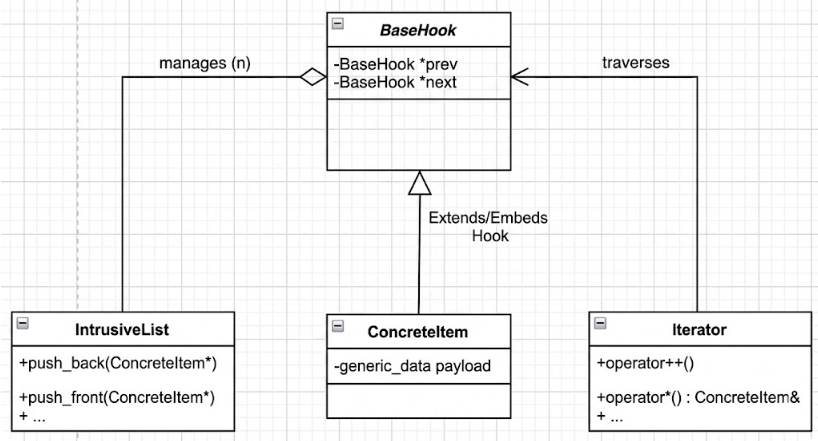
Boost 也提供了侵入式 链表(比如 boost::intrusive::list),它是怎么解决这个问题的?让用户显式指定链表钩子(hook)的位置,并在编译期完成偏移计算。可以选择把 hook 作为基类继承,也可以作为成员。在编译时就确定好 offset,避免运行时依赖不确定的内存布局。
STL 的 std::list是典型的非侵入式设计。你只需要把你的类型传给 std::list<T>,它内部会自己管理节点------节点结构大概是这样:
template<typename T>
struct __list_node {
T data;
__list_node* prev;
__list_node* next;
};数据和指针打包在一个新结构里,原始类型 T 完全不需要知道"我在链表里"。这带来了极强的通用性:任何类型,哪怕是第三方库的 class,都能直接放进 std::list。代价是:每次访问数据都要先解引用节点指针,多一层间接访问;而且每个节点都是一次独立分配(除非用自定义 allocator),内存更碎片化。
总结:如果在写底层系统、高性能中间件,或者能控制数据结构的设计(比如内核、游戏引擎、网络框架),侵入式往往更高效;如果在写通用库、业务逻辑,或者处理的是黑盒类型,那 std::list 的便利性就更重要。