2.1 大数据+大模型一新智能
2.1.1 大数据+大模型能力增强
- Kaplan-McCandlish 扩展法则
模型的性能与模型以及数据规模这两个因素均高度正相关。然而,在模型规模相同的情况下,模型的具体架构对其性能的影响相对较小。

OpenAI 提出的这一扩展法则不仅定量地揭示了数据规模和模型规模对模型能力的重要影响,还指出了在模型规模上的投入应当略高于数据规模上的投入 - Chinchilla 扩展法则

2.1.2 大数据+大模型一能力扩展
模型训练数据规模以及参数数量的不断提升,不仅带来了学习能力的稳步增强,还为大模型"解锁"了一系列新的能力 ,例如上下文学习
能力、常识推理能力、数学运算能力、代码生成能力等。值得注意的是,这些新能力并非通过在特定下游任务上通过训练获得,而是随着模型复杂度的提升凭空自然涌现。这些能力因此被称为大语言模型的涌现能力
2.2 大语言模型架构概览
2.2.1 主流模型架构的类别
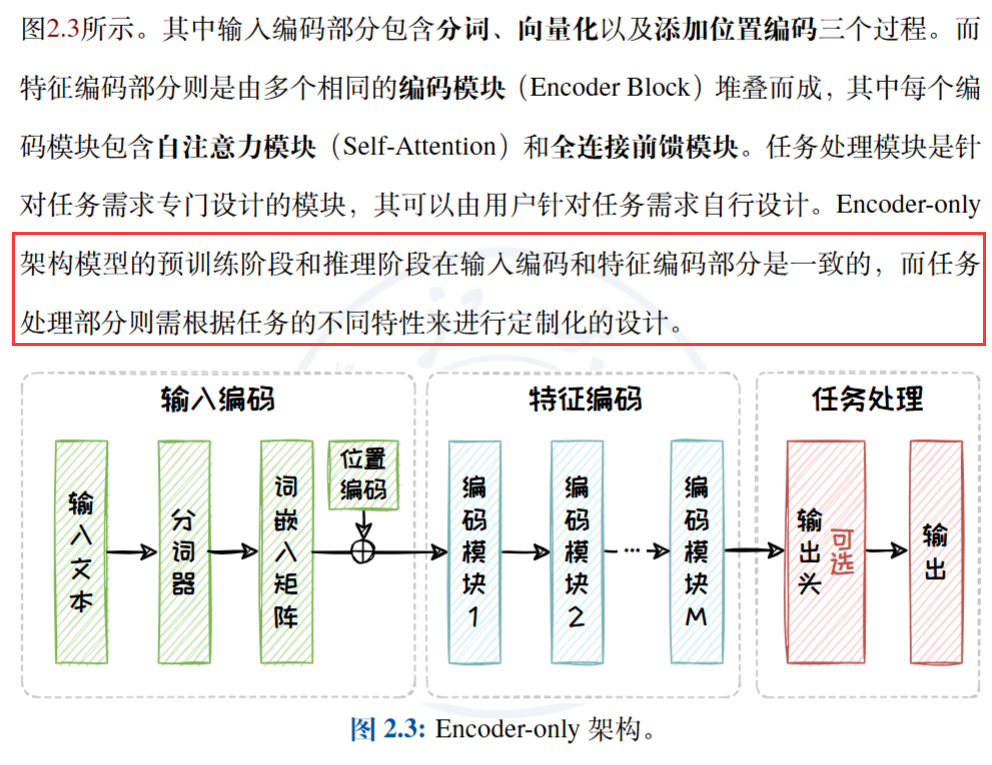
- Econder-only架构

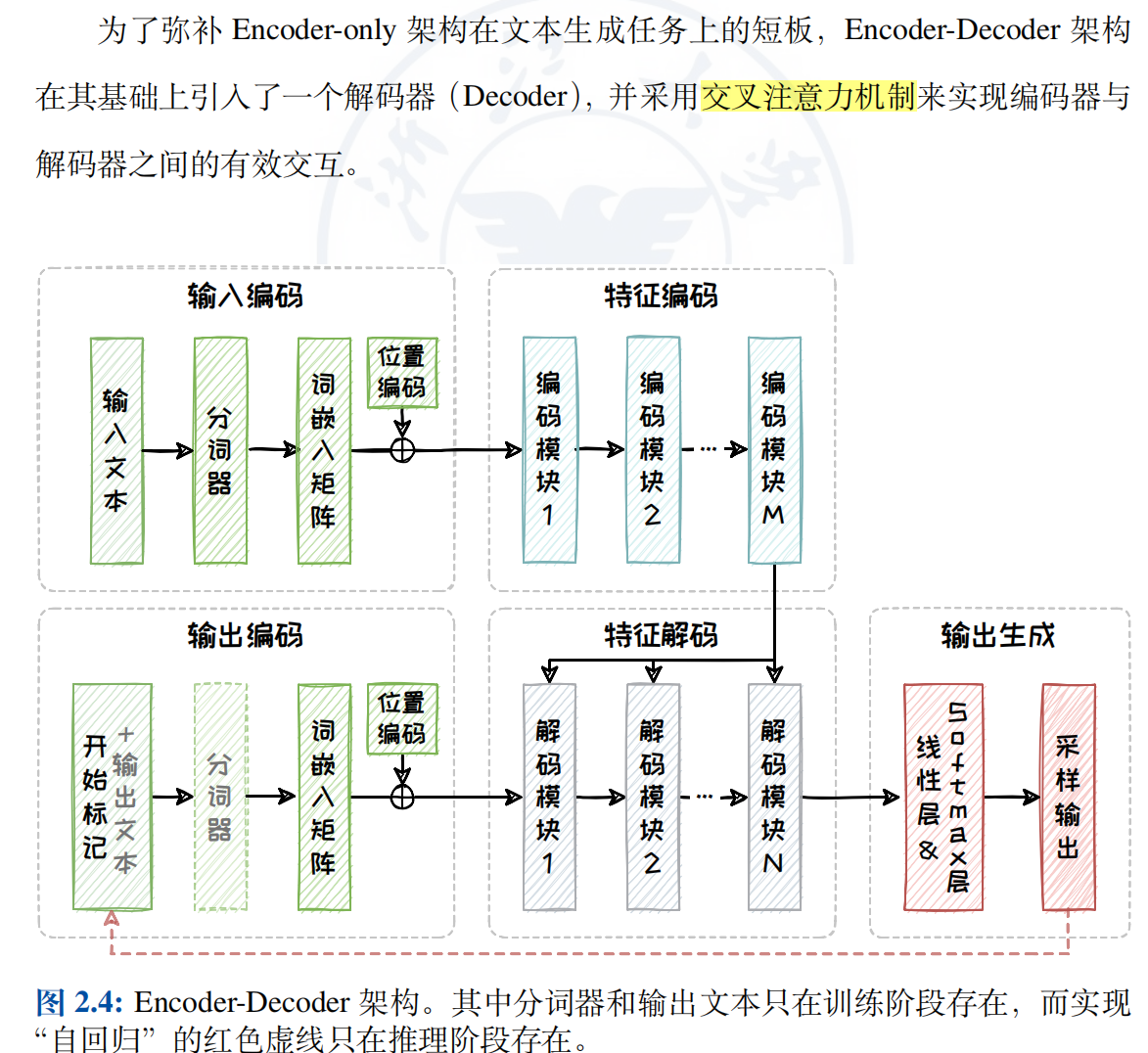
- Encoder-Decoder 架构

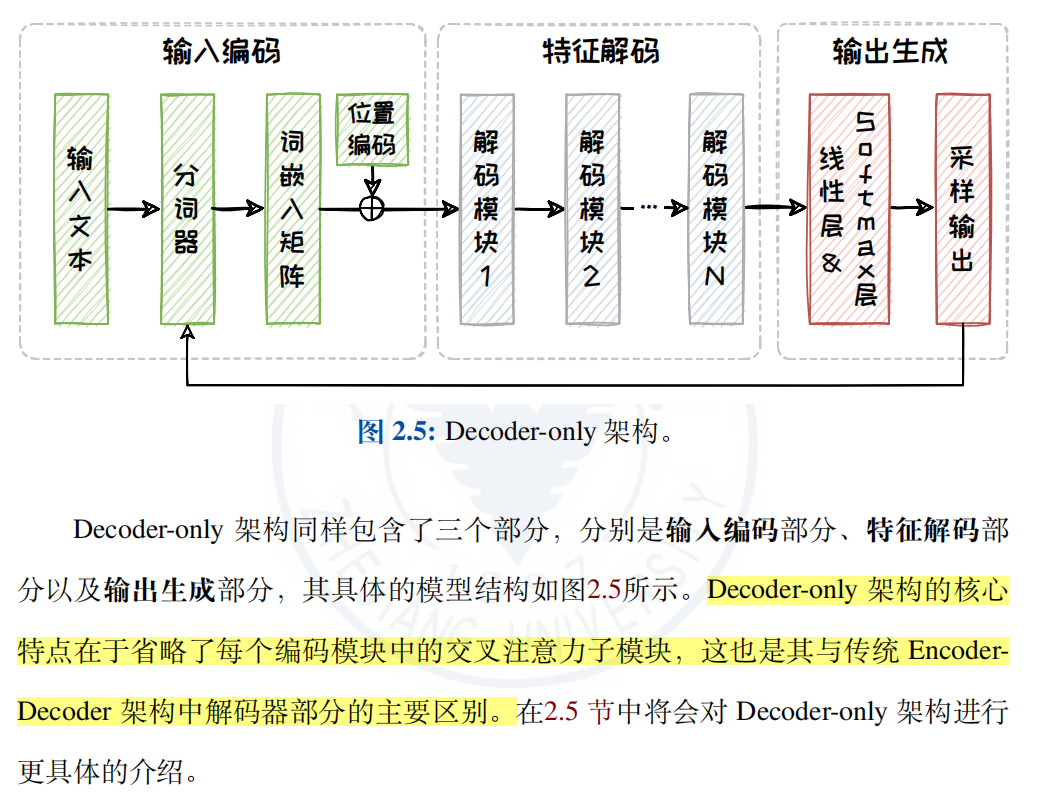
- Decoder-only 架构
2.2.2 模型架构的功能对比



2.2.3 模型架构的历史演变
2.3 基于Encoder-only架构的大语言模型
2.3.1 Encoder-only架构
- 在处理输入序列时,双向编码模型融合了从左往右的正向 注意力以及从右往左的反向注意力
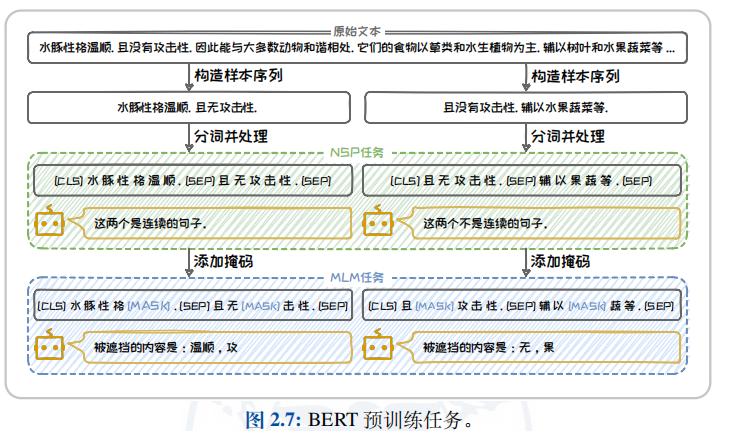
2.3.2 BERT语言模型
- BERT(Bidirectional Encoder Representations from Transformers)是一种基于Encoder-only 架构的预训练语言模型。其核心创新在于通过双向编码模型深入挖掘文本的上下文信息,从而为各种下游 任务提供优秀的上下文嵌入

2.3.3 BERT衍生语言模型
- RoBERTa 语言模型 Facebook AI
- ALBERT Google Research 参数因子分解以及跨层参数共享
- ELECTRA Google Brain 和斯坦福大学 生成器-判别器架构
2.4 基于Encoder-Decoder架构的大语言模型
2.4.1 Encoder-Decoder架构
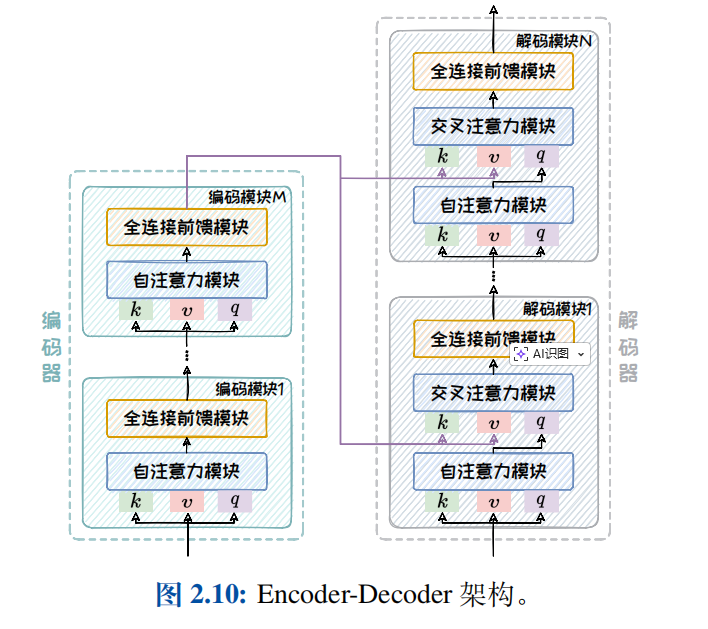
- 在编码器中,我们需要对输入序列的上下文进行"通盘考虑",所以采用双向注意力机制以全面捕捉上下文信息。但在解码器中,自注意力机制则是单向的,仅以上文为条件来解码得到下文,通过掩码操作避免解码器"窥视"未来的信息。
2.4.2 T5语言模型
- Google Research 团队在 2019 年 10 月提出了一种基于Encoder-Decoder 架构的大型预训练语言模型 T5(Text-to-Text Transfer Transformer)
- T5 模型的核心思想是将多种 NLP 任务统一到一个文本转文本的生成式框架中。
- 预训练:T5 模型需要对整个被遮挡的连续文本片段进行预测
2.4.3 BART语言模型
2.5 基于Decoder-only架构的大语言模型
OpenAI 提出的 GPT 系列、Meta 提出的 LLaMA 系列
从第三代开始,GPT 系列逐渐走向了闭源。而 LLaMA 系列虽然起步较晚,但凭借着同样出色的性能以及始终坚持的开源道路,也在 Decoder-only 架构领域占据了一席之地。接下来将对这两种系列的模型进行介绍
2.5.1 Decoder-only架构
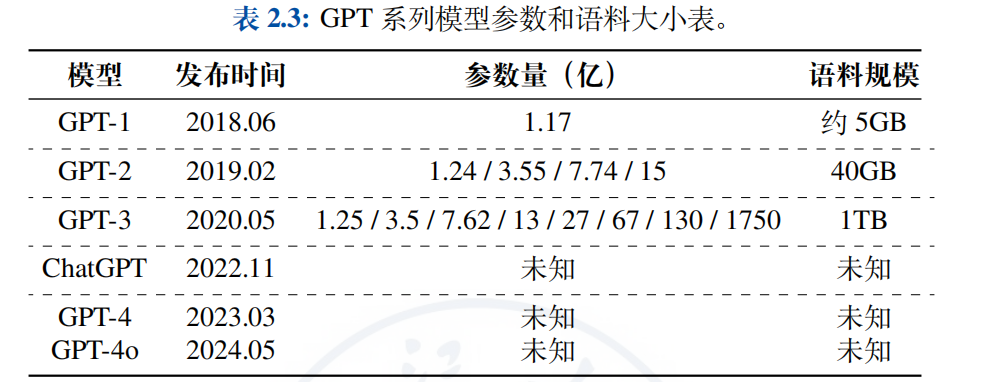
2.5.2 GPT系列语言模型
2.5.3 LLAMA系列语言模型
- LLaMA 则在模型规模上保持相对稳定,更专注于提升预训练数据的规模。
- 近年来,研究者提出了两类现代 RNN 变体,分别为状态空间模型(State Space Model,SSM)和测试时训练(Test-Time Training,TTT)。这两种范式都可以实现关于序列长度的线性时间复杂度,且避免了传统 RNN 中存在的问题。
2.6非Transformer架构
2.6.1 状态空间模型SSM
Mamba



RWKV

2.6.2 训练时更新TTT


