文章目录
一、什么是图形超分辨率
图形超分辨率(Image Super-Resolution, ISR)是一种从低分辨率(Low-Resolution, LR)图像/视频中恢复出对应的高分辨率(High-Resolution, HR)图像/视频的计算机视觉技术。其核心目标是弥补低分辨率图像中丢失的细节信息(如边缘、纹理、微小特征等),提升图像的空间分辨率(即增加图像的像素尺寸),同时保证视觉效果的真实性和合理性。
该技术广泛应用于安防监控(提升模糊监控画面清晰度)、医疗影像(放大医学切片细节辅助诊断)、卫星遥感(提升遥感图像分辨率)、多媒体播放(老旧视频/图片高清化)等领域。
二、图形超分辨率的两类核心方法
(一)传统超分辨率方法(非深度学习方法)
传统方法不依赖数据驱动的特征学习,主要基于图像的先验信息(如平滑性、边缘连续性)和数学模型进行重建,主流方法分为以下两类:
-
基于插值的方法(最基础)
核心思想:通过对低分辨率图像的现有像素进行加权计算,填充新增像素点的灰度/颜色值,实现图像放大。
常见算法:
- 最近邻插值:取距离目标像素最近的原始像素值,计算简单、速度快,但会产生明显的块效应(图像边缘锯齿化)。
- 双线性插值:利用目标像素周围4个原始像素进行线性加权,平滑性更好,块效应减轻,但会丢失高频细节(图像变模糊)。
- 双三次插值(Bicubic):利用目标像素周围16个原始像素进行三次多项式拟合,是传统插值的最优选择之一,平衡了平滑性和细节保留,也是深度学习超分方法中常用的LR图像预处理步骤。
缺点:仅做像素层面的"数值填充",无法挖掘图像的语义特征,难以恢复真实的高频细节,放大倍数越大,效果越差。
-
基于重建的方法(更先进)
核心思想:将超分辨率问题转化为一个优化求解问题 ,通过构建先验模型约束,从LR图像中重建出HR图像,同时抑制噪声和伪影。
常见算法:
- 迭代反投影(IBP):通过迭代修正的方式,最小化重建HR图像下采样后与原始LR图像的误差,但容易产生振铃效应。
- 稀疏表示方法:假设HR图像和LR图像的局部块可以通过同一个过完备字典进行稀疏表示,先通过大量图像样本训练得到字典,再利用字典对LR图像块进行稀疏编码,进而重建HR图像块。
- 基于模型的方法(如变分法):构建包含数据项(约束重建与LR图像的一致性)和正则项(约束HR图像的先验特性,如总变分TV正则)的目标函数,通过优化算法求解最优HR图像。
缺点:模型设计复杂,计算量较大,迭代优化耗时久,对复杂场景的细节恢复能力有限,泛化性较差。
(二)深度学习超分辨率方法
深度学习方法基于数据驱动 ,通过大量HR-LR图像对训练神经网络,让模型自动学习从LR图像到HR图像的映射关系,无需人工设计先验模型,细节恢复能力和泛化性远超传统方法,主流发展阶段/方法如下:
经典代表项目及原理
- 基于学习的早期代表:SRCNN (2014)
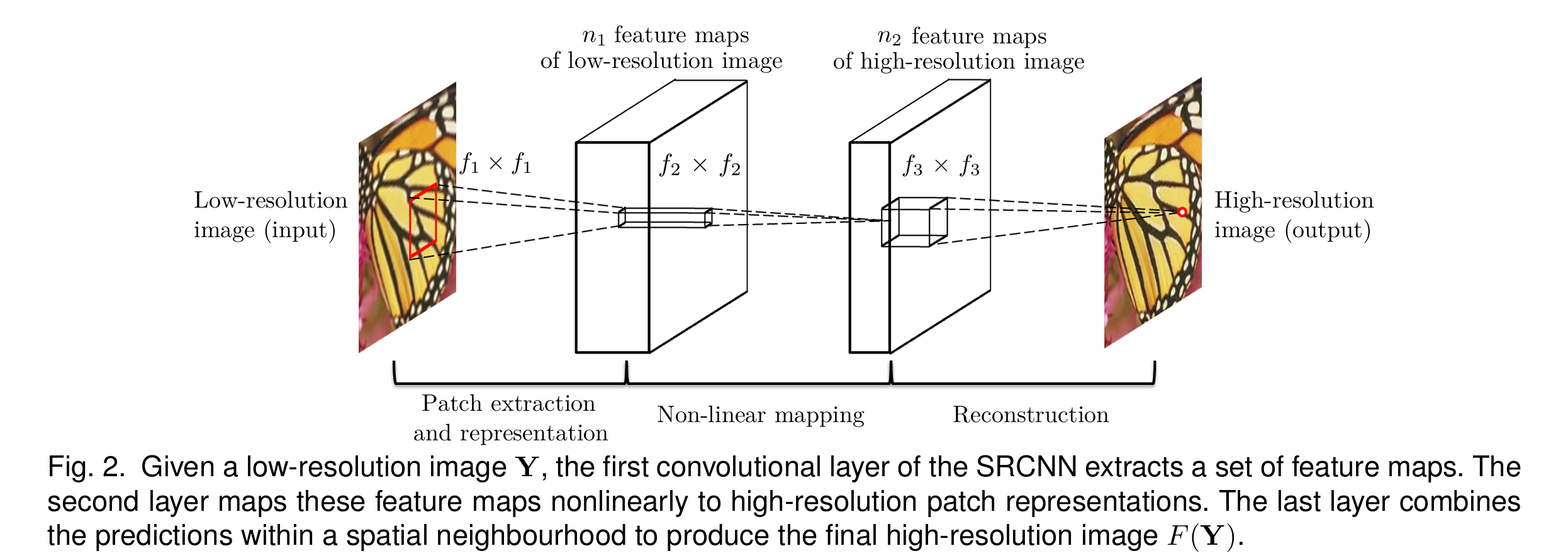
- 原理:首次将CNN应用于超分辨率,通过三层CNN实现从低分辨率到高分辨率的映射
- 影响:开创了深度学习在超分辨率领域的应用
-
SRGAN (2017)
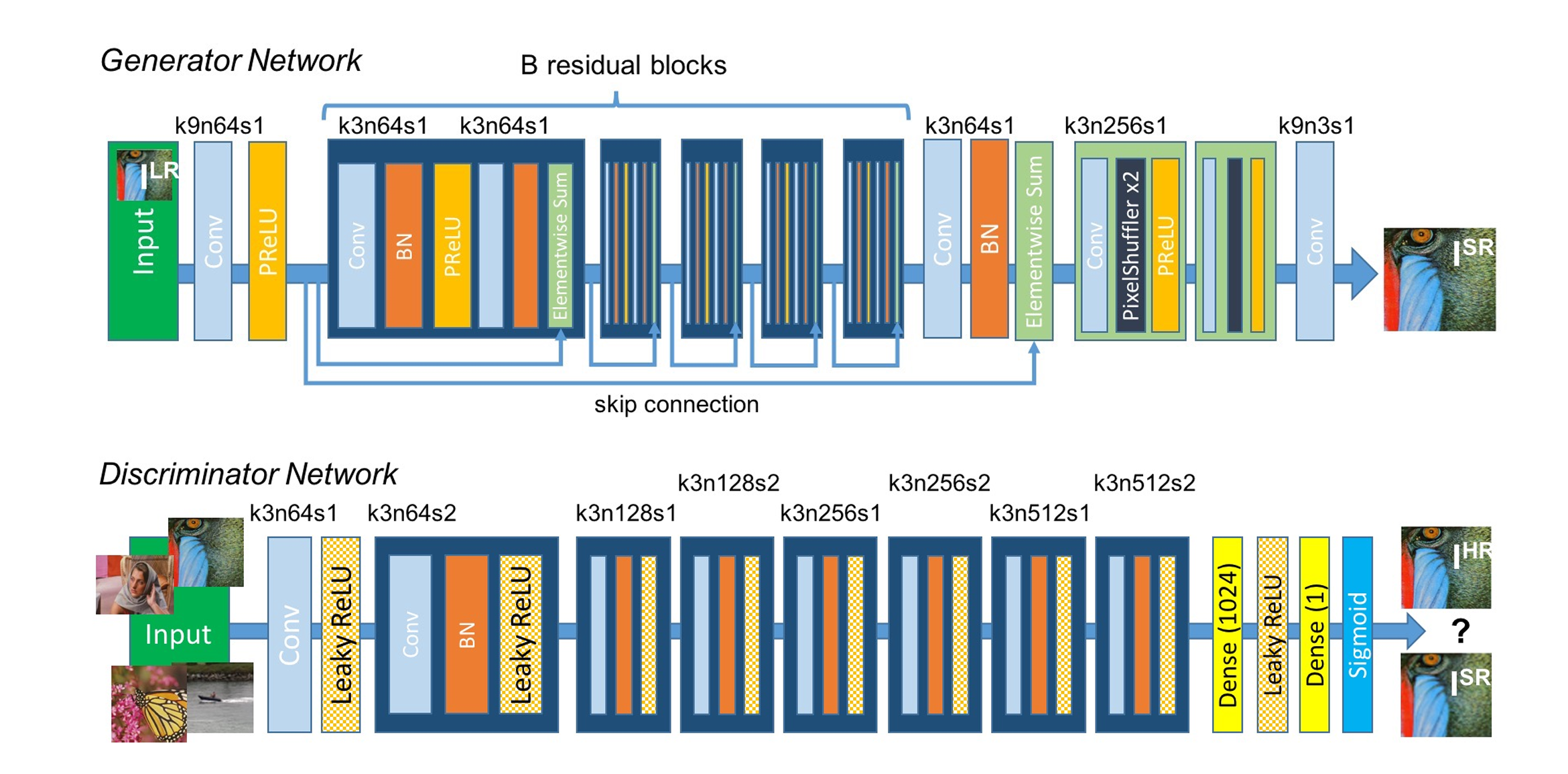
图:生成器与判别器网络的结构,其中标注了每个卷积层对应的核尺寸(k)、特征图数量(n)和步幅(s)。
原理:
对抗损失: 判别器区分真实和生成图像
感知损失: 基于VGG的特征匹配损失
内容损失: 像素级MSE损失
组合损失: 多损失函数加权组合

图:采用SRResNet1的基础架构,其中大部分计算在低分辨率(LR)特征空间中完成。为了获得更好的性能,我们可以选择或设计"基础模块"(例如残差模块18、密集模块34、RRDB模块)。

图:左图 :我们移除了SRGAN中残差模块里的批量归一化(BN)层。右图 :在我们的更深层模型中使用了RRDB模块,其中 β \boldsymbol{\beta} β为残差缩放参数。
- 原理:在SRGAN基础上,改进了生成器结构和损失函数,引入了残差密集块和特征提取模块
- 改进点:
- 使用残差密集块提升特征提取能力
- 引入感知损失提高图像质量
- 采用像素归一化改善训练稳定性
- 实用增强版:Real-ESRGAN (2020)
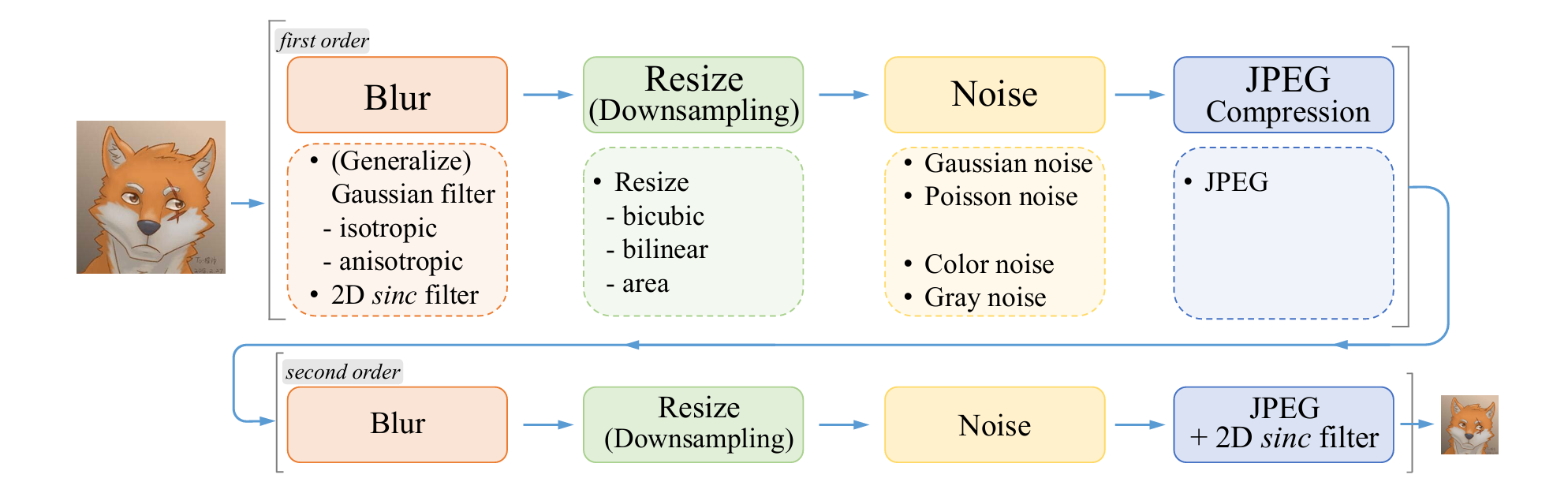
图:Real-ESRGAN所采用的纯合成数据生成流程概述。它采用二阶退化过程来模拟更贴近实际场景的图像退化,其中每一步退化都基于经典的退化模型。图中列出了模糊、缩放、噪声和JPEG压缩的具体实现方式,我们还使用sinc滤波器来合成常见的振铃效应与过冲伪影。
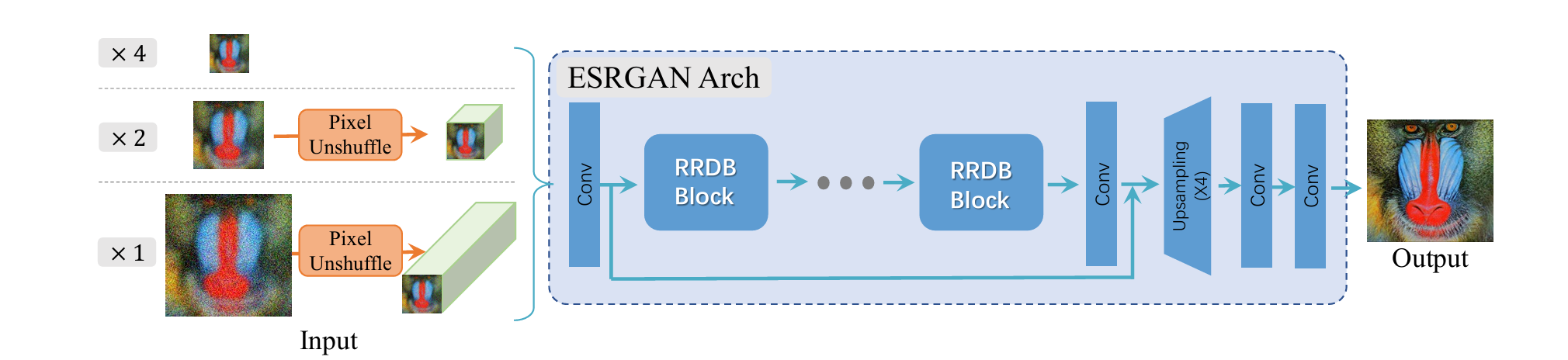
图4:Real-ESRGAN采用了与ESRGAN完全相同的生成器网络。在放大倍数为×2和×1的场景下,它会先执行像素重排逆操作(pixel-unshuffle)来缩小空间尺寸,并将信息重新排列到通道维度上。
- 原理:针对多种图像退化(模糊、压缩伪影、噪声等)进行了优化,支持更多类型的低质量图像
- 特点:
- 支持多种退化类型的图像增强
- 优化了模型结构,提高处理速度
- 可直接在浏览器中运行(通过WaifuXL等项目)

当前流行项目
- SwinIR (2021)
论文: SwinIR: Image Restoration Using Swin Transformer
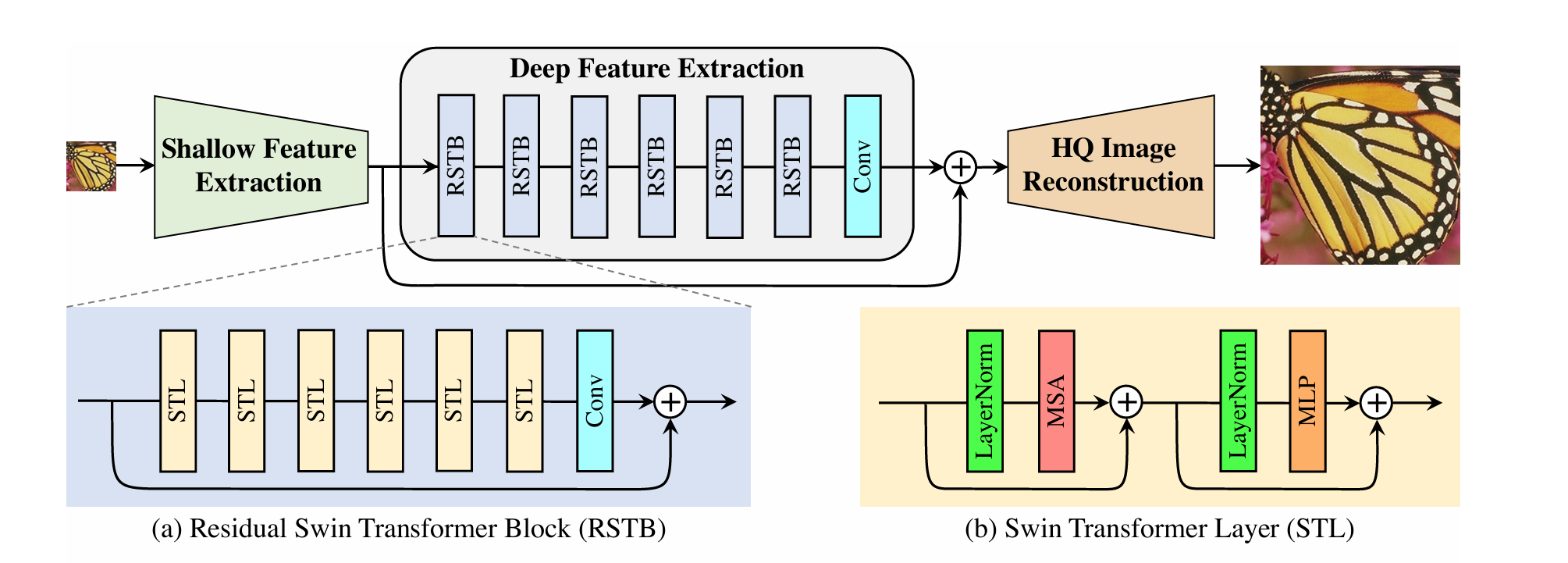
系统框图
原理:
- Swin Transformer: 基于窗口的自注意力,线性复杂度
- 移位窗口: 增强窗口间信息交互
- 残差Swin块: 结合CNN和Transformer优点
三、经典算法SRCNN原理详解
SRCNN(Super-Resolution Convolutional Neural Network)是首个将卷积神经网络应用于图像超分辨率的算法 (发表于2015年),彻底打破了传统超分方法的瓶颈,其核心思想是用端到端的卷积神经网络直接学习从低分辨率图像到高分辨率图像的映射关系,无需复杂的手工设计先验。
SRCNN的核心流程(3个关键步骤,对应3层卷积)
SRCNN的网络结构非常简洁,仅包含3层卷积层(无池化层、无全连接层),整体流程如下:
-
步骤1:图像预处理(升采样至目标分辨率)
由于卷积神经网络难以直接学习"低尺寸→高尺寸"的映射,SRCNN首先使用双三次插值 将输入的低分辨率(LR)图像放大到目标高分辨率(HR)的尺寸(记为 Y ^ \hat{Y} Y^),作为网络的输入。这一步的目的是统一输入和输出的尺寸,为后续卷积操作提供基础。
-
步骤2:SRCNN网络的3层卷积(核心映射学习)
这是SRCNN的核心,3层卷积分别承担"特征提取"、"特征非线性映射"、"图像重建"的任务,逐层实现从模糊插值图像到清晰高分辨率图像的转换:
-
第1层:卷积层(特征提取)
功能:从预处理后的插值图像 Y ^ \hat{Y} Y^中提取底层图像特征(如边缘、纹理、角点等)。
数学表达: F 1 = σ ( W 1 ∗ Y ^ + b 1 ) F_1 = \sigma(W_1 * \hat{Y} + b_1) F1=σ(W1∗Y^+b1)
说明: W 1 W_1 W1是卷积核权重, b 1 b_1 b1是偏置项, ∗ * ∗表示卷积操作, σ \sigma σ是激活函数(SRCNN使用ReLU激活,解决线性模型的表达能力不足问题), F 1 F_1 F1是提取到的特征图。
典型参数:卷积核尺寸 9 × 9 9 \times 9 9×9,输出特征图通道数64。
-
第2层:卷积层(特征非线性映射)
功能:对第1层提取的底层特征进行非线性变换和融合,学习更复杂的高层特征,挖掘特征之间的依赖关系,这是恢复细节的关键步骤。
数学表达: F 2 = σ ( W 2 ∗ F 1 + b 2 ) F_2 = \sigma(W_2 * F_1 + b_2) F2=σ(W2∗F1+b2)
说明:该层不改变特征图的空间尺寸,仅进行通道数的转换和特征的非线性映射。
典型参数:卷积核尺寸 1 × 1 1 \times 1 1×1(1×1卷积,高效进行通道融合和降维),输出特征图通道数32。
-
第3层:卷积层(高分辨率图像重建)
功能:将经过非线性映射的高层特征 F 2 F_2 F2重建为最终的高分辨率(HR)图像。
数学表达: Y = W 3 ∗ F 2 + b 3 Y = W_3 * F_2 + b_3 Y=W3∗F2+b3
说明:该层不使用激活函数 (因为图像像素值是连续的非负值,激活函数会破坏像素值的连续性和合理性),直接输出与目标尺寸一致的HR图像 Y Y Y。
典型参数:卷积核尺寸 5 × 5 5 \times 5 5×5,输出特征图通道数1(灰度图)或3(彩色图),与输入图像的通道数一致。
-
-
步骤3:损失函数优化(端到端训练)
SRCNN采用**均方误差(MSE)**作为损失函数,衡量网络输出的HR图像 Y Y Y与真实HR图像 Y g t Y_{gt} Ygt(Ground Truth)之间的像素级误差,通过反向传播算法迭代优化网络的权重 W 1 , W 2 , W 3 W_1,W_2,W_3 W1,W2,W3和偏置 b 1 , b 2 , b 3 b_1,b_2,b_3 b1,b2,b3,使损失函数最小化。
损失函数: L ( W , b ) = 1 N ∑ i = 1 N ∥ Y i − Y g t , i ∥ 2 L(W,b) = \frac{1}{N} \sum_{i=1}^{N} \left\| Y_i - Y_{gt,i} \right\|^2 L(W,b)=N1∑i=1N∥Yi−Ygt,i∥2
说明:MSE能保证图像的整体平滑性和像素级准确性,但也会导致生成的图像缺乏纹理细节,显得"过于平滑",这也是后续SRGAN等算法需要解决的问题。
SRCNN的核心创新点
- 首次将端到端的卷积神经网络应用于图像超分辨率,替代了传统方法复杂的手工设计和迭代优化。
- 提出了"特征提取→非线性映射→图像重建"的三阶段超分框架,为后续所有深度学习超分算法奠定了基础。
- 验证了深度学习在超分任务上的优越性,其效果远超传统的双三次插值和稀疏表示方法。
四、SRCNN完整源码实现(基于PyTorch)
下面提供基于PyTorch框架的SRCNN完整可运行源码,包含网络定义、数据预处理、训练和测试全流程,支持灰度图/彩色图超分。
环境准备
bash
# 安装必要依赖
pip install torch torchvision opencv-python numpy matplotlib pillow完整源码
python
import torch
import torch.nn as nn
import torch.optim as optim
from torch.utils.data import Dataset, DataLoader
from torchvision import transforms
from PIL import Image
import cv2
import numpy as np
import os
import matplotlib.pyplot as plt
# ---------------------- 1. 定义SRCNN网络模型 ----------------------
class SRCNN(nn.Module):
def __init__(self, num_channels=1):
"""
初始化SRCNN网络
:param num_channels: 图像通道数,1=灰度图,3=彩色图
"""
super(SRCNN, self).__init__()
# 第1层:卷积层(特征提取),9×9卷积核,输出64个特征图
self.conv1 = nn.Conv2d(num_channels, 64, kernel_size=9, padding=4, padding_mode='replicate')
# 第2层:卷积层(特征非线性映射),1×1卷积核,输出32个特征图
self.conv2 = nn.Conv2d(64, 32, kernel_size=1, padding=0)
# 第3层:卷积层(图像重建),5×5卷积核,输出对应通道数的图像
self.conv3 = nn.Conv2d(32, num_channels, kernel_size=5, padding=2, padding_mode='replicate')
# 激活函数(ReLU)
self.relu = nn.ReLU(inplace=True)
def forward(self, x):
"""
前向传播
:param x: 输入图像(经过双三次插值预处理后的高分辨率图像)
:return: 重建后的高分辨率图像
"""
x = self.relu(self.conv1(x))
x = self.relu(self.conv2(x))
x = self.conv3(x) # 最后一层不使用ReLU激活
return x
# ---------------------- 2. 定义超分数据集类 ----------------------
class SRDataset(Dataset):
def __init__(self, data_dir, scale=2, num_channels=1, transform=None):
"""
初始化超分数据集(输入HR图像,自动生成LR图像)
:param data_dir: HR图像存放目录
:param scale: 超分放大倍数(2/3/4,对应SRCNN的常见配置)
:param num_channels: 1=灰度图,3=彩色图
:param transform: 图像变换
"""
self.data_dir = data_dir
self.scale = scale
self.num_channels = num_channels
self.transform = transform
self.image_names = [f for f in os.listdir(data_dir) if f.endswith(('.png', '.jpg', '.jpeg'))]
def __len__(self):
return len(self.image_names)
def __getitem__(self, idx):
# 读取HR图像
image_path = os.path.join(self.data_dir, self.image_names[idx])
hr_image = Image.open(image_path).convert('L' if self.num_channels == 1 else 'RGB')
# 生成LR图像:先将HR图像下采样(缩小scale倍),再用双三次插值上采样回原尺寸(作为网络输入)
w, h = hr_image.size
lr_size = (w // self.scale, h // self.scale)
lr_image = hr_image.resize(lr_size, Image.BICUBIC) # 下采样生成LR
lr_upsampled = lr_image.resize((w, h), Image.BICUBIC) # 双三次插值上采样(网络输入)
# 数据变换(转为Tensor并归一化到[0,1])
if self.transform:
hr_image = self.transform(hr_image)
lr_upsampled = self.transform(lr_upsampled)
return lr_upsampled, hr_image
# ---------------------- 3. 训练配置与训练函数 ----------------------
def train_srcnn():
# 基本配置
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu') # 设备选择(GPU/CPU)
scale = 2 # 超分放大倍数(2倍超分,可修改为3/4)
num_channels = 1 # 1=灰度图,3=彩色图
epochs = 50 # 训练轮数
batch_size = 8 # 批次大小
lr = 0.0001 # 学习率
data_dir = './HR_images' # HR图像数据集目录(需自行创建并放入HR图像)
save_model_path = './srcnn_model.pth' # 模型保存路径
# 创建HR图像目录(如果不存在)
if not os.path.exists(data_dir):
os.makedirs(data_dir)
print(f"已创建HR图像目录:{data_dir},请放入高分辨率图像后重新运行")
return
# 图像变换
transform = transforms.Compose([
transforms.ToTensor(), # 转为Tensor,像素值归一化到[0,1]
])
# 构建数据集和数据加载器
dataset = SRDataset(data_dir, scale=scale, num_channels=num_channels, transform=transform)
dataloader = DataLoader(dataset, batch_size=batch_size, shuffle=True, num_workers=0)
# 初始化模型、损失函数、优化器
model = SRCNN(num_channels=num_channels).to(device) # 模型放入设备
criterion = nn.MSELoss() # 损失函数:均方误差(MSE)
optimizer = optim.Adam(model.parameters(), lr=lr) # 优化器:Adam
# 开始训练
print(f"开始训练SRCNN(设备:{device},放大倍数:{scale}倍,轮数:{epochs})")
for epoch in range(epochs):
model.train() # 模型进入训练模式
epoch_loss = 0.0
for batch_idx, (lr_upsampled, hr_gt) in enumerate(dataloader):
# 将数据放入设备
lr_upsampled = lr_upsampled.to(device)
hr_gt = hr_gt.to(device)
# 前向传播
hr_pred = model(lr_upsampled)
# 计算损失
loss = criterion(hr_pred, hr_gt)
# 反向传播与优化
optimizer.zero_grad() # 梯度清零
loss.backward() # 反向传播计算梯度
optimizer.step() # 更新模型参数
# 累计批次损失
epoch_loss += loss.item()
# 打印每轮训练损失
avg_epoch_loss = epoch_loss / len(dataloader)
print(f"Epoch [{epoch+1}/{epochs}], Average Loss: {avg_epoch_loss:.6f}")
# 训练完成,保存模型
torch.save(model.state_dict(), save_model_path)
print(f"训练完成,模型已保存至:{save_model_path}")
# ---------------------- 4. 测试函数(超分单张图像) ----------------------
def test_srcnn(image_path, scale=2, num_channels=1, model_path='./srcnn_model.pth'):
"""
用训练好的SRCNN模型对单张图像进行超分
:param image_path: 输入LR图像路径
:param scale: 超分放大倍数(需与训练时一致)
:param num_channels: 1=灰度图,3=彩色图
:param model_path: 训练好的模型路径
"""
# 设备选择
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
# 加载模型
model = SRCNN(num_channels=num_channels).to(device)
if not os.path.exists(model_path):
print(f"模型文件不存在:{model_path},请先完成训练")
return
model.load_state_dict(torch.load(model_path, map_location=device))
model.eval() # 模型进入评估模式
# 读取并预处理输入图像
img = Image.open(image_path).convert('L' if num_channels == 1 else 'RGB')
w, h = img.size
# 步骤1:双三次插值上采样(放大scale倍)
img_upsampled = img.resize((w * scale, h * scale), Image.BICUBIC)
# 步骤2:转为Tensor并归一化
transform = transforms.Compose([transforms.ToTensor()])
img_tensor = transform(img_upsampled).unsqueeze(0).to(device) # 增加batch维度
# 模型推理(超分重建)
with torch.no_grad(): # 禁用梯度计算,提升速度
output_tensor = model(img_tensor)
# 转换为可视化图像
img_upsampled_np = np.array(img_upsampled) / 255.0 if num_channels == 1 else np.array(img_upsampled) / 255.0
output_np = output_tensor.squeeze(0).cpu().detach().numpy()
output_np = np.transpose(output_np, (1, 2, 0)) if num_channels == 3 else output_np[0]
output_np = np.clip(output_np, 0, 1) # 裁剪到[0,1]区间,避免像素值溢出
# 显示结果对比
plt.figure(figsize=(15, 5))
plt.subplot(1, 3, 1)
plt.title('Original LR Image')
plt.imshow(img, cmap='gray' if num_channels == 1 else None)
plt.axis('off')
plt.subplot(1, 3, 2)
plt.title('Bicubic Interpolation')
plt.imshow(img_upsampled_np, cmap='gray' if num_channels == 1 else None)
plt.axis('off')
plt.subplot(1, 3, 3)
plt.title('SRCNN Result')
plt.imshow(output_np, cmap='gray' if num_channels == 1 else None)
plt.axis('off')
plt.tight_layout()
plt.show()
# 保存超分结果
output_img = (output_np * 255).astype(np.uint8)
save_path = './srcnn_result.png'
if num_channels == 3:
cv2.imwrite(save_path, cv2.cvtColor(output_img, cv2.COLOR_RGB2BGR))
else:
cv2.imwrite(save_path, output_img)
print(f"超分结果已保存至:{save_path}")
# ---------------------- 5. 运行入口 ----------------------
if __name__ == '__main__':
# 第一步:训练SRCNN(首次运行需执行,需提前在./HR_images放入HR图像)
train_srcnn()
# 第二步:测试SRCNN(训练完成后,注释上面的train_srcnn(),取消注释下面的test_srcnn())
# test_srcnn(image_path='./test_lr.png', scale=2, num_channels=1)源码使用说明
- 数据集准备 :运行前需在项目根目录创建
HR_images文件夹,放入若干高分辨率(HR)图像(建议/png格式),用于自动生成低分辨率(LR)图像进行训练。 - 训练阶段 :运行源码后,会自动开始训练,训练完成后生成
srcnn_model.pth模型文件。 - 测试阶段 :训练完成后,注释
train_srcnn(),取消注释test_srcnn(),传入一张低分辨率图像路径(test_lr.png),即可得到超分结果对比图,并保存srcnn_result.png。 - 参数调整 :可修改
scale(超分倍数)、num_channels(灰度/彩色)、epochs(训练轮数)等参数,适配不同需求。
结果说明
运行测试函数后,会显示三张图对比:原始LR图像、双三次插值放大图像、SRCNN超分图像,可明显观察到SRCNN结果的细节更清晰、边缘更锐利,优于传统双三次插值。
四、总结
- 图形超分辨率是从LR图像恢复HR图像的技术,分为传统方法(插值、重建)和深度学习方法(SRCNN、SRGAN等)。
- SRCNN是深度学习超分的开山之作,通过"双三次插值预处理+3层卷积(特征提取→非线性映射→图像重建)+MSE损失优化"实现端到端超分。
- SRCNN的优势是结构简单、易于实现,缺点是依赖MSE损失导致图像过于平滑,后续方法(如SRGAN)对此进行了改进。
- 提供的PyTorch源码可直接运行,完成SRCNN的训练和测试,满足基础的图像超分需求。