0、前言:
这部分笔记梳理下智能指针和c与c++中内存分配的基础问题。
学习了这么久c和c++的应用,比如qt也好,linux下的c程序开发也好,我发现很多问题其实就是在掌握好基础之后的技术拓展,关于查缺补漏这部分,后续更新,还是以基础部分的纠错,查缺补漏为主。
把基础知识串起来,才能形成知识结构的概览。
1、智能指针:
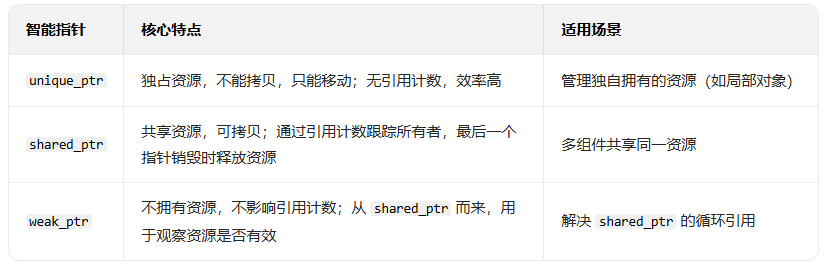
在 C++ 中,智能指针是一种封装了原始指针的类模板,C++ 智能指针的核心设计目标就是管理堆上动态分配的内存(即通过 new/new\[\] 开辟的空间) ,避免内存泄漏(忘记释放内存)和悬垂指针(指针指向已释放的内存)等问题。但历史意义上一共有四种:std::auto_ptr(c++11废弃、c++17移除)、unique_ptr(C++11 至今,独占)、shared_ptr(C++11 至今,共享)、weak_ptr(C++11 至今,观测) ;
std::auto_ptr废除的原因:标准库容器/算法都假设"复制"后原对象保持不变(或至少等价),auto_ptr 违反了这一契约。如下所示:
std::auto_ptr<int> p1(new int(10));
std::auto_ptr<int> p2 = p1; // 拷贝后,p1 失去所有权(变为空),p2 拥有所有权;
/*
此时若再通过 p1 访问对象(如 *p1),会导致未定义行为(如崩溃),
因为 p1 已不再指向有效内存。这种设计违背了用户对 "拷贝" 的
基本认知(通常认为拷贝后两个对象都有效),极易引发错误。
*/
1.1、std::unique_ptr
特点:独占所有权,不能拷贝,只能移动,自动释放; 模拟实现unique_pt:下面案例是为了体现c++中unique_ptr智能指针特点的"简易版本"
#include <iostream>
using namespace std;
template<class T>
class my_unique_ptr {
T* ptr;
public:
explicit my_unique_ptr(T* p = nullptr) : ptr(p) {}
~my_unique_ptr() { delete ptr; }
// 禁止拷贝
my_unique_ptr(const my_unique_ptr&) = delete;
my_unique_ptr& operator=(const my_unique_ptr&) = delete;
// 允许移动
// noexcept 就是用来控制异常抛出的,在这里起到编译器优化的作用;
// 构造式移动
my_unique_ptr(my_unique_ptr&& rhs) noexcept : ptr(rhs.ptr) { rhs.ptr = nullptr; cout << "这里调用了右值传参移动"<<endl; }
// 赋值式移动
my_unique_ptr& operator=(my_unique_ptr&& rhs) noexcept {
if (this != &rhs) { delete ptr; ptr = rhs.ptr; rhs.ptr = nullptr; cout << "这里调用了右值赋值移动" << endl;}
return *this;
}
T& operator*() const { return *ptr; }
T* operator->() const { return ptr; }
T* get() const { return ptr; }
};
int main() {
my_unique_ptr<int> p2(new int(42)); // 接管裸指针
my_unique_ptr<int> u(new int(5)); // 默认构造
my_unique_ptr<int> u2(new int(8)); // 默认构造
// auto u2 = u; // 错误,已删除拷贝
auto u4(move(u2)); // 移动,所有权转移
auto u3 = move(u); // 移动,所有权转移
if (!(u.get()))
{
cout << "u中已经没有资源了" << endl;
}
cout << *p2 << ' ' << *u3 << ' ' << *u4 << '\n'; // 42 5
return 0;
}
/*
release模式调试
打印结果:
这里调用了右值传参移动
这里调用了右值传参移动
u中已经没有资源了
42 5 8
*/
总结:unique_ptr的特点是 "独占 + 可移动 + 自动释放" ,独占的意思一份资源只能对应一个unique_ptr指针,这个资源可以从unique_ptr指针移动给另一个unique_ptr指针,但移动后,被移动的指针会置空;
在std中调用自带的"独占智能指针的方式"
#include <iostream>
#include <memory> // 需包含此头文件
int main() {
// 创建 unique_ptr 指向动态分配的 int(值为 10)
std::unique_ptr<int> ptr1(new int(10));
std::cout << "ptr1 指向的值:" << *ptr1 << std::endl; // 输出:10
// 无需手动 delete,离开作用域时自动释放内存
return 0;
}
1.2、std::shared_ptr
特点:共享所有权,引用计数归零才释放; 模拟实现shared_ptr:shared_ptr智能指针案例中重要的是实现这种共享的思路(多个同类对象指向同一内存地址);
#include <iostream>
#include <utility> // std::swap
#include <atomic> // 原子引用计数
template <class T>
class my_shared_ptr {
// 类的成员如果没有显式标明访问权限,默认访问权限是 private。
/* 1. 控制块:保存对象指针 + 引用计数 + 删除器 */
struct control_block {
T* ptr;
/*
1、在多线程场景中,多个线程可能同时读写同一个变量。普通变量的读写操作可能被 CPU 拆分为多个指令(如读取、修改、写入),若多个线程交错执行这些指令,可能导致数据不一致(例如经典的 "计数器漏加" 问题)。
2、而 std::atomic 变量的所有操作(如赋值、自增、比较交换等)都是原子操作------ 这些操作在 CPU 层面是不可分割的,要么完全执行,要么完全不执行,不会被其他线程打断。
*/
std::atomic<size_t> ref;
void (*deleter)(T*); // 简易"函数指针"版删除器,deleter 是一个指针,指向 void(T*) 函数;
control_block(T* p, void(*d)(T*) = [](T* t) { delete t; })
: ptr(p), ref(1), deleter(d) {
}
~control_block() { if (ptr) deleter(ptr); }
};
control_block* blk;
public:
/* 2. 构造:接管裸指针,创建控制块,非空就新建控制块并接管,空就保持空 */
explicit my_shared_ptr(T* p = nullptr,
void(*d)(T*) = [](T* t) { delete t; })
: blk(p ? new control_block(p, d) : nullptr) {
}
/* 3. 析构:计数减一,归 0 时销毁控制块(连带对象),这里delete blk 会调用 ~control_block() { if (ptr) deleter(ptr); */
~my_shared_ptr() {
if (blk && --blk->ref == 0) delete blk;
}
/* 4. 拷贝构造:共享,计数 +1
rhs.blk 里存的是地址,blk(rhs.blk)这实现的是把原对象的blk给到新对象,它两公用一个blk;
*/
my_shared_ptr(const my_shared_ptr& rhs) noexcept
: blk(rhs.blk) {
if (blk) blk->ref.fetch_add(1); // fetch_add(1)操作之后,ref中的值增加1;
}
/* 5. 拷贝赋值:先自减,再共享新块
调用的时候,新对象=旧对象,则旧对象分享,计数加1,新对象之前的blk就没了,所以新对象计数减1;
*/
my_shared_ptr& operator=(const my_shared_ptr& rhs) noexcept {
if (this != &rhs) {
/* 先减旧块引用 */
if (blk && --blk->ref == 0) delete blk;
/* 再共享新块 */
blk = rhs.blk;
if (blk) blk->ref.fetch_add(1);
}
return *this;
}
/* 6. 移动构造:直接偷控制块 【新对象还不存在】
构造移动,原对象直接置空;
*/
my_shared_ptr(my_shared_ptr&& rhs) noexcept
: blk(rhs.blk) {
rhs.blk = nullptr;
}
/* 7. 移动赋值:先自减,再偷块 【新对象已经存在】
赋值移动,新对象清空,原对象先赋值给新对象再置空;
*/
my_shared_ptr& operator=(my_shared_ptr&& rhs) noexcept {
if (this != &rhs) {
if (blk && --blk->ref == 0) delete blk;
blk = rhs.blk;
rhs.blk = nullptr;
}
return *this;
}
/* 8. 观察接口 */
long use_count() const noexcept {
return blk ? blk->ref.load() : 0;
}
T* get() const noexcept { return blk ? blk->ptr : nullptr; }
T& operator*() const { return *blk->ptr; }
T* operator->() const { return blk->ptr; }
explicit operator bool() const noexcept { return blk != nullptr; }
/* 9. reset:放弃当前对象,可选接管新对象 */
void reset(T* p = nullptr,
void(*d)(T*) = [](T* t) { delete t; }) {
if (blk && --blk->ref == 0) delete blk;
blk = p ? new control_block(p, d) : nullptr;
}
};
/* 10. 简单测试 */
int main() {
my_shared_ptr<int> a(new int(42));
std::cout << "a.use_count() = " << a.use_count() << '\n'; // 1
my_shared_ptr<int> b = a; // 拷贝共享
std::cout << "after copy: a=" << a.use_count()
<< " b=" << b.use_count() << '\n'; // 2 2
auto c = std::move(b); // 移动,b 变空
std::cout << "after move: a=" << a.use_count()
<< " b=" << (b ? b.use_count() : 0)
<< " c=" << c.use_count() << '\n'; // 2 0 2
std::cout << *c << '\n'; // 42
return 0; // 离开作用域,最后一次析构把 int 释放
}
/*
release模式下打印结果:
a.use_count() = 1
after copy: a=2 b=2
after move: a=2 b=0 c=2
42
*/
总结:
在std中调用自带的"共享智能指针的方式"
#include <iostream>
#include <memory>
int main() {
/* 1. 创建共享指针 */
auto sp1 = std::make_shared<int>(10);
std::cout << "sp1=" << *sp1 << " count=" << sp1.use_count() << '\n'; // 1
/* 2. 拷贝共享 */
auto sp2 = sp1;
std::cout << "sp2=" << *sp2 << " count=" << sp1.use_count() << '\n'; // 2
/* 3. 改值 */
*sp2 = 42;
std::cout << "sp1=" << *sp1 << " sp2=" << *sp2 << '\n'; // 42 42
/* 4. 移动:sp3 接管,sp2 变空 */
auto sp3 = std::move(sp2);
std::cout << "after move: sp2.empty=" << sp2.use_count() // 0
<< " sp3=" << *sp3 << " count=" << sp3.use_count() << '\n'; // 2
return 0;
}
/*
release模式下
打印结果:
sp1=10 count=1
sp2=10 count=2
sp1=42 sp2=42
after move: sp2.empty=0 sp3=42 count=2
*/
1.3、std::weak_ptr
特点:weak_ptr 就是专为"修" shared_ptr 的天然缺陷而设计的,如下就是使用shared_ptr陷入循环引用的例子;
#include <memory>
#include <iostream>
class B; // 前置声明
class A {
public:
std::shared_ptr<B> b_ptr; // A 持有 B 的 shared_ptr
~A() { std::cout << "A 被销毁" << std::endl; }
};
class B {
public:
std::shared_ptr<A> a_ptr; // B 持有 A 的 shared_ptr
~B() { std::cout << "B 被销毁" << std::endl; }
};
int main() {
{
//创建一个 std::shared_ptr 智能指针,该指针管理一个动态分配的 A 类对象,并将这个智能指针赋值给变量 a。
auto a = std::make_shared<A>();
auto b = std::make_shared<B>();
a->b_ptr = b; // a 引用 b(b 的引用计数变为 2)
b->a_ptr = a; // b 引用 a(a 的引用计数变为 2)
} // 离开作用域,a 和 b 被销毁(引用计数各减 1,变为 1)
// 此时 a 和 b 的引用计数仍为 1(互相引用),资源未释放,内存泄漏
std::cout << "程序结束" << std::endl;
return 0;
}
// 运行结果只有:程序结束;
#include <memory>
#include <iostream>
class B;
class A {
public:
std::shared_ptr<B> b_ptr; // A 仍持有 B 的 shared_ptr
~A() { std::cout << "A 被销毁" << std::endl; }
};
class B {
public:
std::weak_ptr<A> a_ptr; // B 持有 A 的 weak_ptr(当 B 类的 a_ptr(weak_ptr<A> 类型)接收 A 对象的 shared_ptr 赋值 时(如 b->a_ptr = a),A 的引用计数不会增加。)
~B() { std::cout << "B 被销毁" << std::endl; }
};
int main() {
{
auto a = std::make_shared<A>();
auto b = std::make_shared<B>();
a->b_ptr = b; // b 的引用计数变为 2
b->a_ptr = a; // a 的引用计数仍为 1(weak_ptr 不增加计数)
} // 离开作用域:
// a 销毁,a 的引用计数减为 0 → A 被释放
// b 的引用计数减为 1(因 a->b_ptr 被销毁),但此时 B 中 a_ptr 是 weak_ptr,无实际引用
// b 销毁,引用计数减为 0 → B 被释放
std::cout << "程序结束" << std::endl;
return 0;
}
/*
运行结果:
A 被销毁
B 被销毁
程序结束
解释:后定义的先销毁,因此先销毁b,b中引用计数变成1,但还不调用b的析构,
再销毁a,a中引用计数变成0,因此a调用析构函数先被销毁,由于a指向b,
因此,b的引用计数减少,然后b的引用计数变成了0,然后b再调用;
*/
1.4、智能指针小结:
智能指针,能够解决堆上开辟空间后,忘记释放空间的问题。智能指针的使用还是有不足的地方,例如unique_ptr不能拷贝,shared_ptr可能会出现两个类互相指向无法释放的问题,所以日常使用需要注意使用场景,挑选合适的智能指针;
2、C和C++中的数组
定义:数组是一组相同类型元素的集合,所有元素在内存中连续存储。C和C++中的数组都遵循这一基本特性,但C++提供了更丰富的容器类型作为补充。
数组分为静态数组和动态数组,静态数组是在编译器确定大小,内存的分配位置在栈或者全局区,由编译器确定大小管理内存,无需手动释放内存;动态数组在运行期确定大小,内存分配位置在堆区,大小可变,由程序运行时确定,需要手动释放内存。
2.1、静态数组定义:栈区或全局区
int arr[5]; // 定义5个整数的数组
char str[10]; // 定义10个字符的数组
double scores[20]; // 定义20个双精度浮点数的数组
int arr[5]; // 与C语言相同
std::array<int, 5> arr; // C++11引入的标准数组容器
不论C还是C++定义,只要先定义了数组,没有初始化,接下来初始化,不能给数组名整体赋值,因为定义之后,数据名就被看作了一个地址常量(不是变量),是编译器分配内存后固定的地址符号,它不占用独立内存,也不能被当作 "左值"(赋值操作的接收方)。 需要单个元素逐个初始化,或者通过memcpy 批量拷贝。注意如果是C++的静态数组用了容器array先定义,是可以接着整体赋值的
附1:为什么可以通过memcpy批量拷贝:void* memcpy(void* dest, const void* src, size_t count); 看memcpy的参数就明白了,第一个参数:void* dest 含义:目标内存的首地址(即你要把数据拷贝到哪里),可以接收任意类型的内存地址。第二个参数const void* src,源内存的首地址,加 const 表示函数内部不会修改源内存的内容,同时允许接收常量 / 变量地址。第三个参数size_t count,要拷贝的字节数(不是元素个数!)。
附2:C++的静态数组用了容器array,本质还是封装了静态数组,但是内部的类重载了赋值运算符,遇到整体赋值,本质还是会挨个赋值,所以可以定义之后,再整体初始化。
2.2、静态数组初始化:
C 有的初始化写法,C++ 几乎全兼容;C++ 在此基础上又多出几条自己的语法和容器,C 用不了。
C和C++都可以使用的基础的初始化方式:
// 一维数组初始化:分为完全初始化、不完全初始化、清零极简写法,原则就是数组大小明确。
int a[4] = {1,2,3,4}; // 完全显式
int b[] = {1,2,3}; // 省略长度
int c[5] = {1, 2}; // 不完全初始化 → 剩余置 0
int d[10] = {0}; //清零极简写法
// 二维数组初始化:分为分行初始化,也就是每行元素都用花括号括起来、整体初始化,也就是所有元素写在一个花括号中。原则就是数组中每行有多少元素要明确,也就是"列定行省"原则。
int g[][3] = { {1,2,3}, {4,5,6} }; // 二维数组(行优先,列的大小必须是常量且明确给出,行可省略,因为二维数组是按照列划分数组的)
int h[][3] = { 1,2,3, 4,5,6 }; // 这样定义二维数组也可以【列定行省】
int m[3][4] = {0}; // 仅给第一个元素赋值 0,所有元素都会置 0
// 二维数组的调用
cout << sizeof(g)/sizeof(g[0])<<endl;
for(int i= 0; i<sizeof(g)/sizeof(g[0]); i++)
{
cout<< *(g[i]) << *(g[i]+1) << *(g[i]+2) <<" other show : "<< g[i][0] << g[i][1] << g[i][2] << endl;
} // 打印结果一样
int a[]{1,2}; // 列表初始化,省略等号
std::array<int, 3> a{1, 2, 3}; // STL中的静态数组,列表初始化
constexpr int arr[]{1,2}; // constexpr是强制表达式 / 变量 / 函数在「编译期」完成计算,而非运行期,是实现「编译期编程」的基础。
/*
注意:constexpr要用于函数,就要在函数声明时在函数类型前面加该关键字,然后在调用的时候,就能编译期给constexpr修饰的变量返回对应的值。
constexpr int square(int x) {
return x * x; // 函数体必须简单(C++11 要求只有一条 return,C++14 放宽)
}
constexpr int res = square(4);
*/
对于C而言,上面总结只是C89的特性,如果是C99的话,还有比较有意思的初始化,C99还有新的方法,但是目前开发比较通用的C版本都是C89。
2.3、动态数组定义:堆区
C语言中定义,必须检查 malloc/calloc/realloc 返回值(内存不足时返回 NULL),用 free(arr) 释放。
// n 是运行期变量
// malloc,仅分配内存,未初始化(内存值为随机垃圾值),失败返回null
int* arr = (int*)malloc(n * sizeof(int));
// n 是运行期变量
// calloc,自动将所有元素初始化为 0(等价于 malloc + memset),失败返回null
int* arr = (int*)calloc(n, sizeof(int));
// n 是运行期变量
// realloc,把原来那块堆内存"变大"或"变小",失败返回null
arr = (int*)realloc(arr, new_n*sizeof(int));
C++中定义:malloc/calloc/realloc 在 C++ 中可以正常使用,编译器完全支持,语法和 C 语言一致;但 C++ 有更贴合自身特性的 new/delete,因此在纯 C++ 开发中,除非是兼容 C 代码、手动精细控制内存等特殊场景,否则更推荐用 new/delete 或 std::vector。
// 仅分配内存,未初始化(随机值),n就是动态数组的大小;
int* arr = new int[n];
// 使用vector是定义加初始化
std::vector<int> vec(n);//大小 n,默认初始化为 0
std::vector<int> vec(n, 10);//大小 n,全部初始化为 10
std::vector<int> vec{1,2,3,4,5};//列表初始化,推导大小
vec.push_back(6); / vec.resize(10);
/*
- 若新大小 > 当前大小:新增元素默认值初始化(int 为 0,string 为空串),也可指定初始值(vec.resize(10, 5):新增元素填 5);
- 若新大小 < 当前大小:删除末尾多余元素,容器大小缩小,但容量(capacity)不会自动缩减(需手动调用shrink_to_fit()释放多余容量)。
*/
2.4、动态数组初始化:
//方式 1:循环赋值
for(int i=0; i<n; i++) arr[i] = i;
//方式 2:memset 清零
memset(arr, 0, n * sizeof(int));
C++:在C++中对于有复杂结构的堆空间,不能使用memset填充。
//方式 1:循环赋值
for(int i=0; i<n; i++) arr[i] = i;
//方式 2:std::fill
std::fill(arr, arr+n, 0);
// 释放
delete[] arr;
arr = nullptr;
3、C和C++中的指针
3.1、先概览指针的作用
直接操作内存: 不论是C还是C++中,指针的作用就是直接操作内存,提升程序效率,在传递大结构体、数组给函数时,直接传递值会拷贝整个数据,传指针的话只要传递内存地址,就可以定位数据,可以大幅提升效率。在嵌入式开发或者驱动编程中,指针可以直接访问硬件寄存器的内存地址,这是高级语言python无法做到的。通过函数修改外部值: C/C++ 中函数参数默认是 "值传递"(函数内修改的是拷贝,不影响外部),指针能打破这个限制,让函数直接修改外部变量的值。指向分配的动态内存: 程序运行时需要灵活申请 / 释放内存(比如不确定数组大小),必须通过指针接收动态内存的地址。实现复杂的数据结构: 链表的节点需要通过指针指向 "下一个节点",树的节点需要指针指向 "左孩子""右孩子"------ 没有指针就无法构建这些非连续存储的结构。对于C++还可以实现多态和智能指针: C++ 中,指向基类的指针可以指向派生类对象,是实现多态的基础;同时 C++11 后的智能指针(unique_ptr、shared_ptr)本质也是对原生指针的封装,解决内存泄漏问题。
3.2、C和C++中指针的区别
空指针: C 只有NULL/0,C++11 + 推荐nullptr(解决NULL的二义性);类型安全: C 允许void*隐式转换,C++ 必须显式转换,类型检查更严格;
// void* 隐式转换为int*,C语言允许,C++不允许
int* p = malloc(sizeof(int));
// 显式类型转换,C和C++都允许
int* p1 = (int*)malloc(sizeof(int));
初始化能力: C 需 "分配 + 手动初始化" 分离,C++ 的new支持一步到位,且独有智能指针(自动管理内存)。
// 在c当中先申请空间再初始化:
int* p = (int*)malloc(sizeof(int)); // 1. 分配内存(申请一个装int的盒子)
*p = 10; // 2. 初始化
// 在C++中可以申请空间和初始化一起完成
int* p = new int(10); // 分配内存 + 初始化值10,一步完成!
写 C 代码指针可以先用NULL初始化,因为在C中,用NULL初始化指针是标准、安全的做法(NULL在 C 中本质是(void*)0,天然关联指针语义)。写 C++ 代码优先用nullptr和new,在C++中会认为NULL是0,而非指针,所以要使用nullptr初始化指针,避免混用 C/C++ 初始化方式导致的兼容性问题。
4、C和C++中的函数
4.1、函数的分类
C和C++中文件级独立函数 (不隶属于任何类的函数),按照作用域/链接属性分,可分为:
全局函数:跨文件可见(外部链接),是最基础的普通函数;
静态函数:仅当前文件可见(内部链接),是作用域被限制的普通函数。
补充:C++中独有的类成员函数(隶属于类,非文件级独立函数),不纳入上述分类,单独总结在C++类的知识部分。
4.2、概览C和C++中函数的区别:
C 的函数追求简洁、贴近底层 ,而 C++ 在兼容 C 函数的基础上,扩展了面向对象、类型安全、代码复用等高级特性。基本语法: C语言的函数不支持重载(同名函数会编译报错),没有默认参数(函数的形参不支持默认参数),没有内联函数的说法,C++的函数支持重载,有默认参数,还有内联函数。面向对象的特性: C语言没有是面向过程的,C++在兼容C语言的基础上,又有了面向对象的特性,因此有了各种成员函数,虚函数,友元函数。函数作用域: C语言函数作用域是全局、C++函数作用域有全局、类内、命名空间当中。拓展方面: C++中的函数还可以写成函数模板,这样就可以给不同类型的数据适配同一套逻辑了。C++还支持匿名函数,适合临时、简短的函数逻辑(如算法回调)。
4.3、函数的写法:
C++ 完全兼容 C 的基础函数语法,包括函数声明、定义、调用、返回值、参数传递(值传递、指针传递)等核心写法,二者完全一致。
函数定义的基础语法:
// C/C++都支持:全局函数定义
int add(int a, int b) {
return a + b;
}
// C/C++都支持:静态函数定义(仅当前文件可见)
static void print(int val) {
printf("%d\n", val); // C用printf,C++可混用printf/cout
}
// C 和 C++ 中,static修饰的文件级函数都仅当前文件可见,跨文件用extern声明也无法调用,链接时会报错 ------ 规则完全一致。
// C/C++都支持:函数声明(跨文件调用全局函数时用)
extern int add(int a, int b);
// 省略extern也可,C/C++默认函数声明为extern
int add(int a, int b);
5、C和C++中的内存分配:
5.1、概览:
C++ 在兼容 C 的内存分区基础上,新增了两个具有专属语义的内存区域;
核心分区(C 和 C++ 都有):代码区、全局 / 静态区、栈区、堆区、常量区;
C++ 新增:自由存储区(逻辑上属于堆区,是 new/delete 的专属语义区域)、TLS 区(线程本地存储区,C++11 新增);
说明:C++ 完全兼容 C 在堆区通过 malloc/calloc/realloc/free 开辟 / 释放动态内存的方式;同时 C++ 通过 new/delete 在自由存储区分配内存(区别于 C 的 "裸内存分配",new 会调用构造函数、delete 会调用析构函数),适配面向对象的内存管理。