拖拽式AI应用工厂:ModelEngine应用编排深度体验,智能表单与插件开发实战
引言:ModelEngine为何成为开发者新选择
在AI应用开发领域,低代码/无代码平台正加速普及,但多数平台存在"灵活性不足""定制化受限""多工具集成繁琐"等痛点。ModelEngine作为一款拖拽式AI应用工厂,以"可视化编排为核心、插件扩展为支撑、多场景适配为目标",打破了传统开发的效率瓶颈。
相较于传统编码开发,ModelEngine无需复杂的框架配置,通过拖拽节点即可构建复杂工作流;同时支持自定义插件与MCP服务接入,兼顾非技术用户的易用性与开发者的定制化需求。本文将以"智能办公周报生成助手"为案例,完整演示从应用编排、智能表单设计到自定义插件开发的全流程,带大家深度体验ModelEngine的核心能力。


🔥 核心亮点:可视化拖拽编排、智能表单快速收集、自定义插件扩展能力,一文解锁ModelEngine全流程开发技巧,附与Dify/Coze对比评测!
一、环境准备与基础认知
1.1 环境搭建
ModelEngine支持本地部署与云端使用,本次实战采用云端版(无需配置服务器,快速上手):
-
访问ModelEngine官方地址,完成账号注册与登录(支持企业邮箱与微信快捷登录);
-
进入控制台,创建新应用,命名为"智能周报生成助手",选择"空白工作流"模板;
-
配置基础模型:在应用设置中选择默认大模型(支持智谱GLM、MiniMax、GPT等,本次选用GLM-4.7),无需手动配置API Key,平台已集成主流模型服务。
1.2 核心组件认知
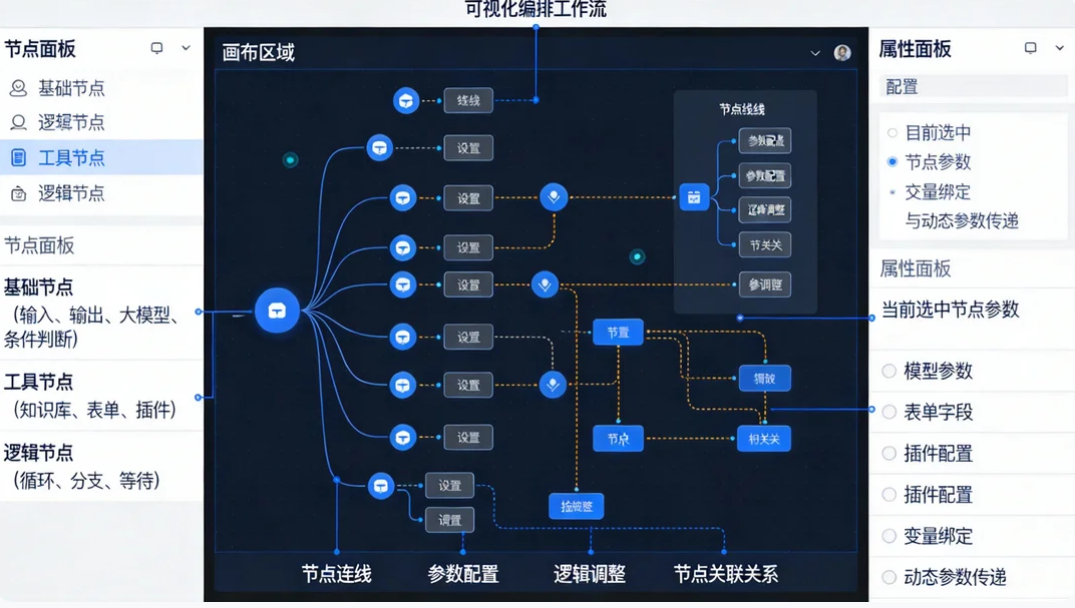
ModelEngine工作流编辑器核心分为三大区域,新手需快速熟悉:
-
节点面板:包含基础节点(输入、输出、大模型、条件判断)、工具节点(知识库、表单、插件)、逻辑节点(循环、分支、等待),支持拖拽至画布;
-
画布区域:可视化编排工作流,支持节点连线、参数配置、逻辑调整,实时显示节点关联关系;
-
属性面板:配置当前选中节点的参数(如模型参数、表单字段、插件配置),支持变量绑定与动态参数传递。
二、应用编排实战:拖拽构建智能办公工作流
本次开发的"智能周报生成助手"核心功能:通过智能表单收集用户周报原始数据(工作内容、成果、问题、计划),调用自定义插件提取关键信息,结合知识库企业模板,生成标准化周报。工作流整体分为5个环节,全程拖拽式搭建。
2.1 基础节点使用与流程搭建
-
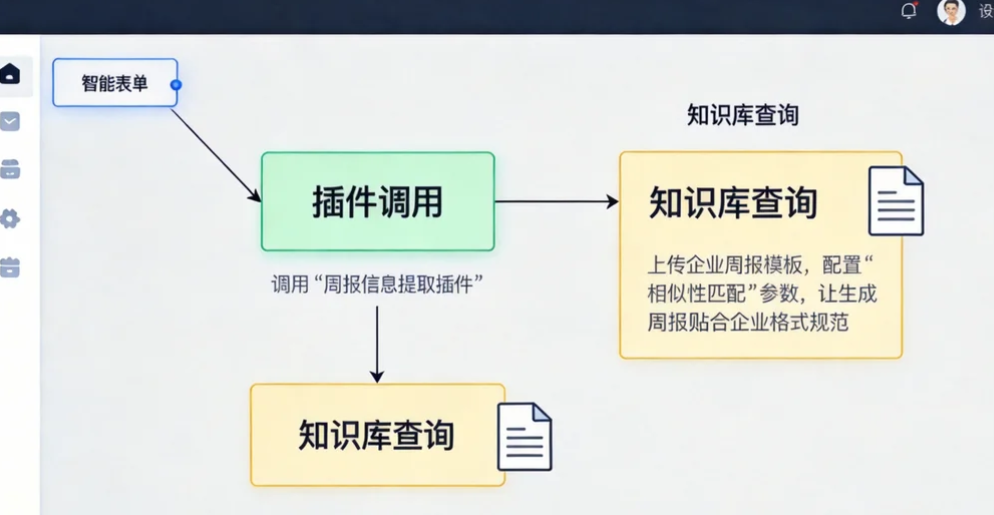
第一步:添加"智能表单"节点拖拽"智能表单"节点至画布,作为工作流入口,用于收集用户输入的周报原始数据。后续将详细配置表单字段,此处暂留节点待配置。
-
第二步:添加"自定义插件"节点拖拽"插件调用"节点至画布,连接至表单节点后,用于调用"周报信息提取插件",从用户输入的原始内容中提取结构化信息(如成果、问题、计划分类)。
-
第三步:添加"知识库"节点拖拽"知识库查询"节点,上传企业周报模板(支持Word、PDF格式),配置"相似性匹配"参数,让模型生成的周报贴合企业格式规范。ModelEngine支持知识库自动总结生成,上传文档后无需手动拆分,平台自动提取核心内容构建向量库。
-
第四步:添加"大模型"节点拖拽"大模型调用"节点,连接知识库与插件节点,配置提示词(支持自动生成功能,输入需求即可生成优化后的提示词)。核心提示词逻辑:结合表单收集的原始数据、插件提取的结构化信息、知识库中的企业模板,生成标准化周报,要求语言正式、逻辑清晰、贴合企业风格。
-
第五步:添加"输出"节点拖拽"文本输出"节点,连接大模型节点,配置输出格式(支持Markdown、Word、PDF导出),完成工作流搭建。
2.2 工作流调试与逻辑优化
搭建完成后,需通过"试运行"功能调试工作流,排查逻辑漏洞与参数问题:
-
点击编辑器右上角"试运行",进入测试界面,填写表单测试数据;
-
逐步执行每个节点,查看运行日志:若插件提取信息不完整,调整插件参数;若大模型生成内容不符合模板,优化提示词或知识库匹配度;
-
添加"条件判断"节点优化逻辑:若用户未填写"工作成果",则提示补充信息,避免生成空泛周报。
三、智能表单开发:高效收集与变量绑定
智能表单是连接用户与工作流的核心入口,ModelEngine支持可视化设计表单字段、动态校验、变量绑定,无需编码即可快速构建交互界面。
3.1 表单设计步骤
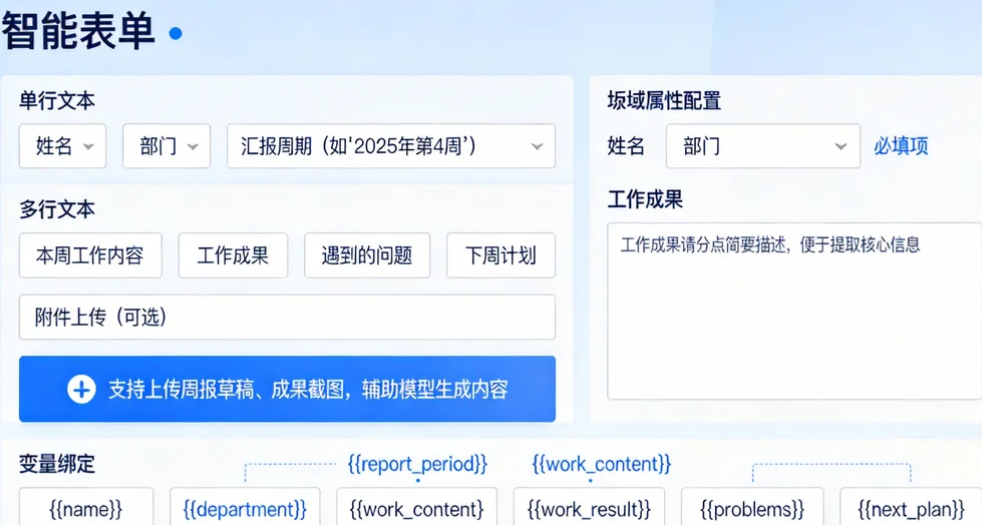
- 双击"智能表单"节点,进入表单设计界面,添加以下字段:
-
单行文本:姓名、部门、汇报周期(如"2025年第4周");
-
多行文本:本周工作内容、工作成果、遇到的问题、下周计划;
-
附件上传(可选):支持上传周报草稿、成果截图,辅助模型生成内容。
-
配置字段属性:设置"姓名""部门"为必填项,添加输入提示(如"工作成果请分点简要描述,便于提取核心信息");
-
变量绑定:每个字段自动生成对应变量(如name、work_content),后续节点可直接引用这些变量,实现数据流转。
3.2 表单交互优化
为提升用户体验,可配置表单联动规则:当用户选择"技术部"时,自动添加"本周技术攻坚任务"额外字段;选择"行政部"时,添加"本周行政事务汇总"字段,实现动态表单效果。配置路径:表单设计界面→高级设置→字段联动→添加联动规则。
四、自定义插件开发:从编码到接入全流程
本次实战需开发"周报信息提取插件",用于将用户输入的多行文本内容拆分为"成果、问题、计划"结构化数据,方便大模型快速整合。ModelEngine支持Python插件开发,接入流程简单,无需复杂的接口适配。
4.1 插件编码实现
插件核心功能:接收表单传入的工作内容文本,通过关键词提取与语义分析,输出结构化字典。代码如下:
python
import json
from modelengine.plugin import BasePlugin
class WeeklyReportExtractor(BasePlugin):
# 插件元信息(名称、描述、输入输出参数)
plugin_meta = {
"name": "周报信息提取插件",
"description": "从周报原始文本中提取工作成果、问题、计划,输出结构化数据",
"input_params": [{"name": "work_text", "type": "string", "description": "周报原始文本"}],
"output_params": [{"name": "structured_data", "type": "dict", "description": "结构化信息字典"}]
}
def run(self, input_data):
# 获取输入文本
work_text = input_data.get("work_text", "")
if not work_text:
return {"structured_data": {"成果": [], "问题": [], "计划": []}}
# 核心提取逻辑(结合关键词与简单语义分析,实际可优化为调用小模型)
structured_data = {"成果": [], "问题": [], "计划": []}
# 提取成果(包含"完成""达成""实现"等关键词的句子)
achievement_keywords = ["完成", "达成", "实现", "突破", "交付"]
for sentence in work_text.split("。"):
if any(keyword in sentence for keyword in achievement_keywords):
structured_data["成果"].append(sentence.strip())
# 提取问题(包含"问题""困难""不足"等关键词的句子)
problem_keywords = ["问题", "困难", "不足", "瓶颈", "待解决"]
for sentence in work_text.split("。"):
if any(keyword in sentence for keyword in problem_keywords):
structured_data["问题"].append(sentence.strip())
# 提取计划(包含"计划""打算""将""下一步"等关键词的句子)
plan_keywords = ["计划", "打算", "将", "下一步", "准备"]
for sentence in work_text.split("。"):
if any(keyword in sentence for keyword in plan_keywords):
structured_data["计划"].append(sentence.strip())
return {"structured_data": structured_data}4.2 插件接入与配置
-
插件打包:将上述代码保存为weekly_extractor.py,压缩为ZIP包(确保根目录包含插件文件);
-
接入ModelEngine:进入平台"插件市场"→"自定义插件"→"上传插件",选择ZIP包,填写插件元信息(与代码中plugin_meta一致);
-
插件绑定:回到工作流编辑器,选中"插件调用"节点,在属性面板中选择已上传的"周报信息提取插件",绑定输入参数(将表单节点的{{work_content}}变量传入插件的work_text参数);
-
测试验证:试运行工作流,输入周报原始文本,查看插件输出的结构化数据是否准确,若提取不完整,优化关键词列表或提取逻辑。
4.3 MCP服务接入(可选进阶)
若需扩展插件能力(如对接企业内部系统、多工具协同),可通过MCP服务接入实现。ModelEngine支持MultiServerMCPClient,只需配置MCP服务器地址与密钥,即可调用外部工具:
MCP服务接入示例(插件中集成)
python
from langchain_mcp_adapters.client import MultiServerMCPClient
async def call_mcp_service(self, structured_data):
async with MultiServerMCPClient(servers=["http://localhost:8000/sse"]) as client:
tools = await client.get_tools()
# 调用MCP工具补充企业数据
enterprise_data = await client.call_tool(
tool_name="enterprise_weekly_template",
parameters={"department": input_data.get("department")}
)
# 合并数据
structured_data["enterprise_template"] = enterprise_data
return structured_data五、多维度对比:ModelEngine vs Dify vs Coze
从开发者视角,结合本次实战体验,将ModelEngine与主流AI开发平台Dify、Coze进行多维度对比,帮助大家精准选型:
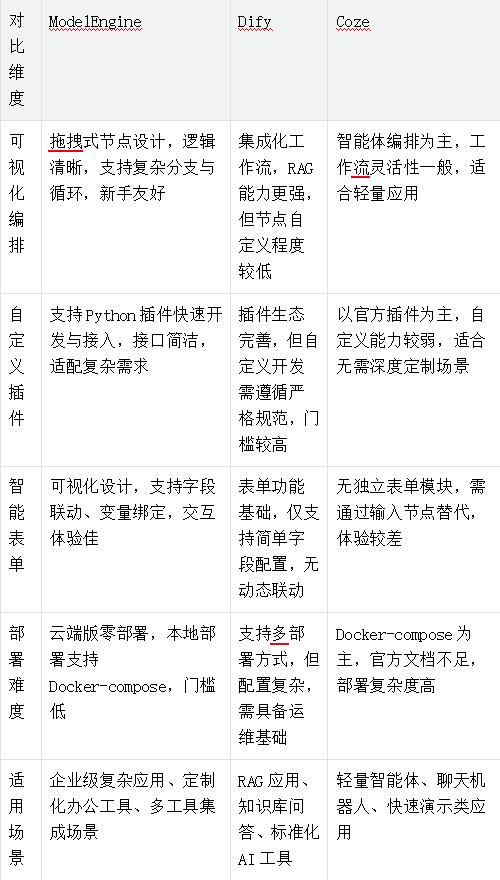
总结:若需开发定制化强、流程复杂的企业级AI应用,ModelEngine的灵活性与扩展能力更具优势;若聚焦RAG场景,Dify更合适;轻量智能体开发可优先选择Coze。
六、部署与调试技巧
6.1 应用部署
ModelEngine支持多种部署方式,满足不同场景需求:
-
云端共享:直接生成共享链接,用户通过浏览器访问表单,提交数据后获取生成结果,无需下载安装;
-
企业私有化部署:通过Docker-compose部署至企业内网,配置专属域名与权限管理,保障数据安全;
-
API集成:生成应用API接口,集成至企业OA、钉钉、飞书等办公系统,实现嵌入式使用。
6.2 调试与问题排查
开发过程中常见问题及解决方案:
-
插件调用失败:检查插件输入输出参数是否与节点绑定一致,查看运行日志排查代码报错;
-
变量传递异常:确保节点间变量名称一致,表单字段变量需用{{变量名}}格式引用;
-
模型生成内容不符合预期:优化提示词(利用平台提示词自动生成功能),调整知识库匹配度,增加示例数据;
-
表单提交无响应:检查必填字段配置,排查网络问题或浏览器兼容性(推荐Chrome、Edge)。
七、总结与进阶方向
通过本次实战,我们基于ModelEngine完成了"智能周报生成助手"的全流程开发,从拖拽式工作流搭建、智能表单设计,到自定义插件开发与接入,深刻体会到低代码平台在提升开发效率上的优势。ModelEngine的核心价值在于"平衡易用性与灵活性",既让非技术用户能快速构建AI应用,又为开发者预留了充足的定制化空间。
进阶学习方向推荐:
-
多智能体协作:利用ModelEngine多智能体节点,构建分工明确的智能体团队(如"提取智能体+编辑智能体+审核智能体");
-
插件生态扩展:开发更多场景化插件(如数据可视化插件、Excel导出插件),丰富应用能力;
-
性能优化:通过智能路由、模型量化等功能,提升应用运行速度,降低算力成本。
如果你在ModelEngine开发过程中遇到问题,欢迎在评论区留言交流,后续将分享更多进阶实战技巧!
#ModelEngine #AI应用编排 #智能表单 #自定义插件 #低代码AI开发
✨ 坚持用 清晰的图解 +易懂的硬件架构 + 硬件解析, 让每个知识点都 简单明了 !
🚀 个人主页 :一只大侠的侠 · CSDN
💬 座右铭 : "所谓成功就是以自己的方式度过一生。"
