PSPNet (Pyramid Scene Parsing Network):金字塔场景解析网络
这篇发表于 2017 年(arXiv 版本最早于 2016 年底)的论文,在语义分割(Semantic Segmentation)和场景解析(Scene Parsing)的历史上留下了浓墨重彩的一笔。它不仅拿下了当年的 ImageNet 场景解析挑战赛冠军,还刷新了 PASCAL VOC 2012 和 Cityscapes 的记录 。
论文链接:https://arxiv.org/pdf/1612.01105
代码链接:https://github.com/hszhao/PSPNet
深度解读 PSPNet:在场景解析中,如何利用"全局上下文"进行语义分割?
在深度学习攻克计算机视觉的征途中,语义分割(Semantic Segmentation)一直是一块难啃的骨头。从 FCN(全卷积网络)提出以来,我们虽然能对像素进行分类,但在面对复杂的现实场景时,模型往往会犯一些"低级错误"。
本文要解读的 PSPNet (Pyramid Scene Parsing Network) ,核心只做了一件事:让神经网络拥有"全局视野"。
1. 痛点:为什么传统的 FCN "只见树木,不见森林"?
论文作者(来自香港中文大学和商汤科技的研究团队)首先敏锐地指出了当时主流 FCN 模型在处理复杂场景(如 ADE20K 数据集)时的三大顽疾 :
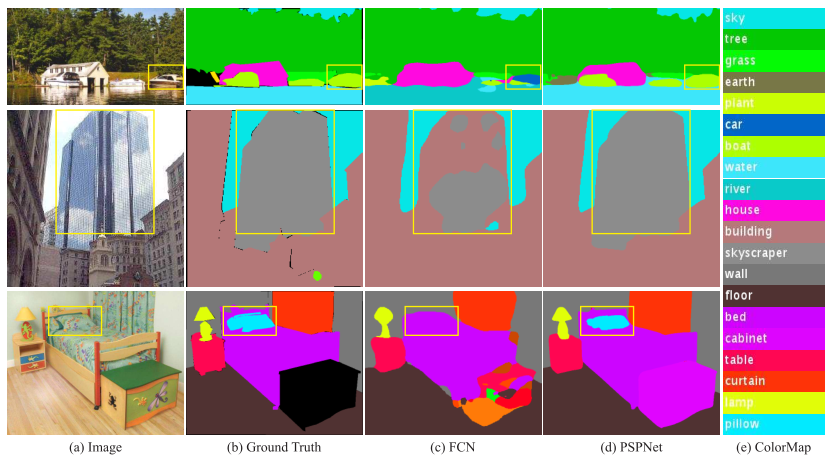
(1) 关系匹配错误 (Mismatched Relationship)
这是最典型的缺乏上下文。比如,在河面上的一艘船,FCN 可能会把它误识别为"汽车"(如上图中第一行)。为什么?因为如果不看周围的水,光看船的外形,确实有点像车。但如果我们知道"周围全是水",根据常识推断,它是"船"的概率就远大于"车" 。
本质: 缺乏利用场景上下文关系的能力 。
(2) 类别混淆 (Confusion Categories)
有些物体外观极度相似,比如"摩天大楼"和普通"建筑物"。FCN 经常在同一个物体上打出两个标签,一部分是摩天大楼,一部分是建筑物(如上图中第二行)。这显然是不合理的,一个物体应当属于一个类别 。
(3) 忽略不显著类别 (Inconspicuous Classes)
在复杂的街景中,路灯、指示牌这种细小的物体,或者极其巨大的物体(超出感受野),很容易被网络忽略或分割得支离破碎 (如上图中第三行)。
专家视点: 作者引用了一个关键理论------虽然深层 ResNet 的理论感受野 (Theoretical Receptive Field)很大,但实际感受野(Empirical Receptive Field)往往比预期的要小得多 。这导致网络其实并没有真正"看清"全图。
2. 核心武器:金字塔池化模块 (Pyramid Pooling Module)
为了解决感受野不足的问题,PSPNet 提出了 Pyramid Pooling Module (PPM)。这是一个简单却极其有效的模块,它作为一个全局先验(Global Prior),被加在主干网络(Backbone,如 ResNet)的末端 。
它是如何工作的?
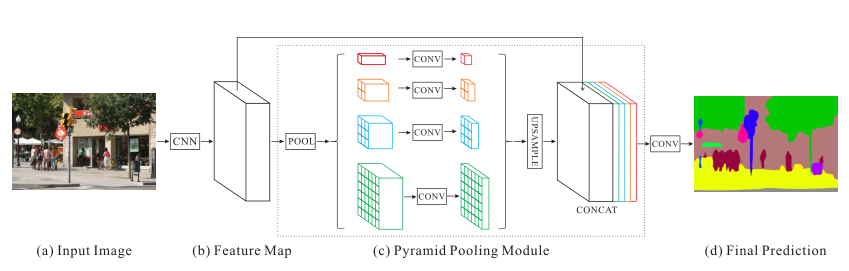
输入特征图的尺寸通常是原图的1/8 ,PPM (金字塔池化模块)融合了四个不同金字塔尺度的特征。 红色层(全局池化)生成单个bin 的输出,这是最粗糙的粒度,概括了整张图片的全局信息(Global Context)。接下来的金字塔级别将特征图划分为不同的子区域,并为不同位置形成池化表示。金字塔池化模块中不同级别的输出包含不同大小的特征图。
融合机制 (Aggregation)
这四种不同尺度的特征图,代表了不同大小的感受野。为了将它们融合,需要进行:
降维: 每一层经过 1*1的卷积,将通道数减小为原来的 1/N(保持权重的平衡)。
上采样: 通过双线性插值(Bilinear Interpolation)直接将它们放大回原始特征图的大小 。
拼接 (Concat): 最后,将这 4 层特征与原始的主干网络特征图在通道维度上拼接起来 。
结论: 经过这一步,特征图上的每一个像素,不仅包含了它自己的局部特征,还融合了它所在的区域特征,以及整张图的全局特征。
Ablation Study 揭秘: 论文实验表明,在池化操作的选择上,平均池化 (Average Pooling) 的效果要优于最大池化 (Max Pooling) 。
3. 训练黑科技:深度监督 (Deep Supervision)
在训练像 ResNet-101 甚至 ResNet-269 这样极深的网络时,优化是一个难题。PSPNet 引入了一个辅助损失函数 (Auxiliary Loss) 。
- 位置: 主分支使用 Softmax Loss 训练最终分类器;辅助分支被加在 ResNet 的第四阶段(res4b22 模块)之后 。
- 作用: 它可以帮助梯度更好地回传到浅层网络,加速收敛并避免梯度消失。
- 权重: 辅助损失不仅是为了训练,还带有权重。论文实验发现,将辅助损失的权重设为 0.4 时效果最好 。
测试时: 这个辅助分支会被丢弃,只保留主分支进行预测,因此不增加推理时间 。
4. 实验结果:霸榜的表现
PSPNet 的实战成绩在当时具有统治力:
-
ImageNet Scene Parsing Challenge 2016: 冠军。单模型成绩优于其他团队的多模型集成 。
-
PASCAL VOC 2012: 在没有任何后处理(如 CRF)的情况下,达到了 85.4% mIoU 的新纪录 。
-
Cityscapes: 在这一极具挑战性的自动驾驶数据集上,达到了 80.2% 的精度 。
从可视化结果看,PSPNet 完美修复了 FCN 的那些"低级错误"。例如在"枕头与床单"这种纹理极其相似的案例中,PSPNet 依然能清晰地将枕头分割出来,这就是全局上下文在起作用 。
5. 总结与思考
PSPNet 是一篇非常扎实的工程化论文。它没有极其复杂的数学推导,而是基于对"感受野"和"上下文"的深刻理解,设计了一个优雅的模块。
给 AI 从业者的 Takeaway:
- 上下文是王道: 在做视觉任务时,永远不要忽视全局信息。局部特征决定细节,全局特征决定"它是什么"。
- 多尺度融合: 金字塔结构(Pyramid)是处理多尺度物体的通用解法,不仅在分割中有效,在检测(如 FPN)中同样适用。
- 工程细节决定成败: 论文中对 BatchSize 的调整、数据增强(随机旋转、缩放)以及"Poly"学习率策略的坚持,是其达到 SOTA 的重要保障 。
希望这篇解读能帮你彻底搞懂 PSPNet!如果你对其中的具体代码实现或者与 DeepLab 系列的对比感兴趣,欢迎随时提问。