在上一节介绍了如何防止模型过拟合,现在就详细的讲一讲其中的一个办法,正则化今天就详细的讲一下
从之前的数据集图象(房价预测)
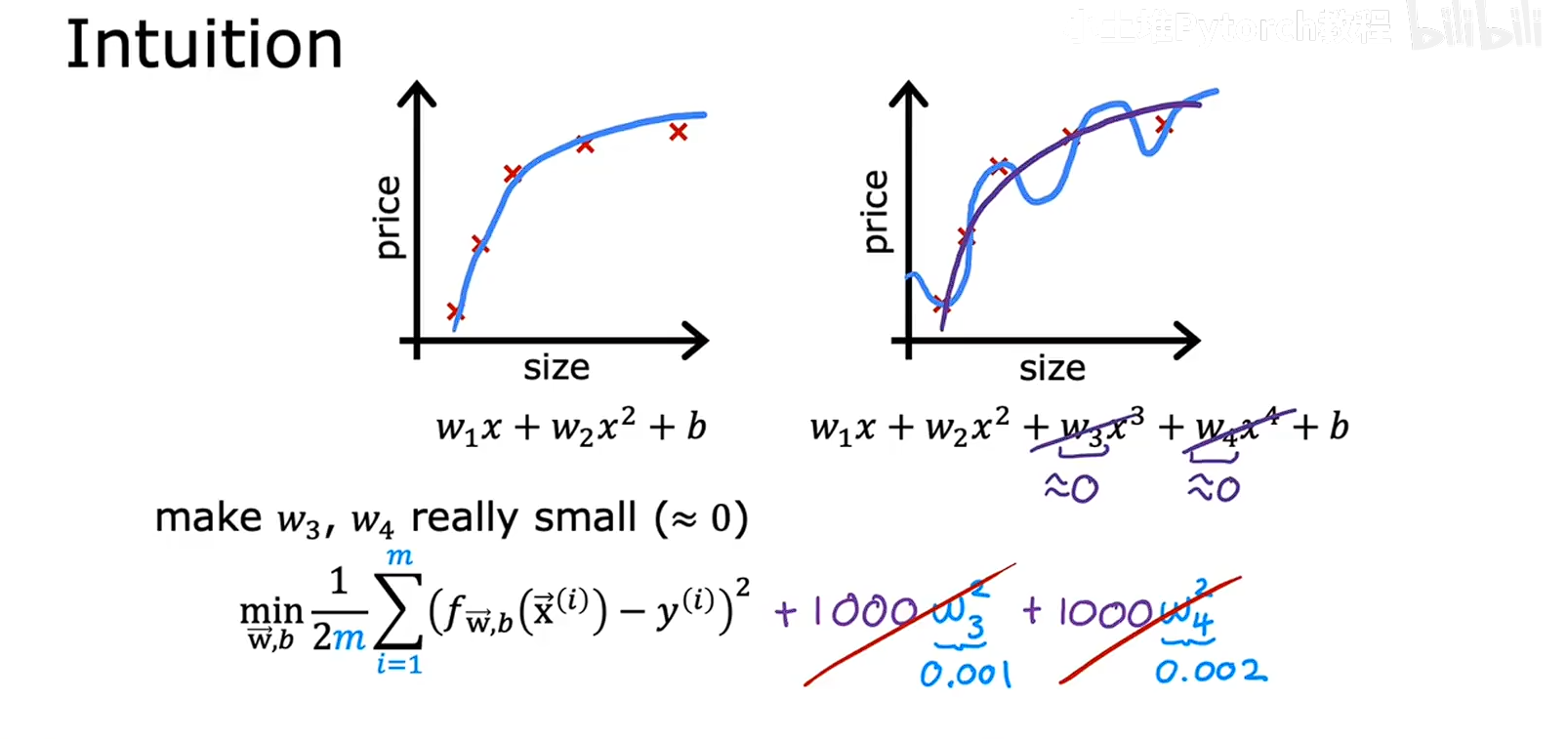
在模型中我们想要防止过拟合,正则化就是对模型的变量的W进行约束,防止过于敏感,防止对模型影响过大,而且w的参数越大,这一项因子的影响就越大,就会导致模型的曲线波动的非常的厉害,变成高次函数,如右边的模型数据集。就像给模型的自由度上了一个刹车,不让他为了贴合训练数据,猛打方向,结果在新数据中表现不好
 。
。
因为我们不知道什么特征是重要的特征,什么特征不重要,所以我们对所有参数进行惩罚,但是不对b进行惩罚,对W向量进行惩罚
为了防止参数过大,我们对模型的成本函数进行变化,添参数大小的的影响,当参数过大的时候成本函数就会变大,因为是整体的考虑,计算累加的求和,然后乘以一个参数 lamdba 入 ,
当lamdba等于,或者非常小的时候,实际上就没有进行正则化,或者说惩罚力度非常小,容易过拟合,
当lamdba过大的时候,惩罚力度很大,成本函数为了最小化成本,会将参数压得非常小,相当于忽略了特征,数据就会变成一条直线这条曲线会趋近于b,数据会欠拟合,
