目录
[一、Linux 安装软件](#一、Linux 安装软件)
[二、Vim 使用](#二、Vim 使用)
[1. Vim 模式](#1. Vim 模式)
[2. Vim 指令(命令模式)](#2. Vim 指令(命令模式))
[三、gcc/g++ 的使用](#三、gcc/g++ 的使用)
[1. 简单编译+运行](#1. 简单编译+运行)
[2. 指定可执行文件名称](#2. 指定可执行文件名称)
[3. 编译过程](#3. 编译过程)
[4. 静态库和动态库](#4. 静态库和动态库)
[5. 为什么 C 语言要先翻译成汇编,再翻译成机器码?](#5. 为什么 C 语言要先翻译成汇编,再翻译成机器码?)
[6. 如何理解条件编译?](#6. 如何理解条件编译?)
[7. 库的本质](#7. 库的本质)
[四、Make 和 Makefile](#四、Make 和 Makefile)
[1. 简单 Makefile 文件](#1. 简单 Makefile 文件)
[2. .PHONY](#2. .PHONY)
[3. 依赖链](#3. 依赖链)
[4. 变量替换](#4. 变量替换)
[5. 自动变量](#5. 自动变量)
[6. @ 和 echo](#6. @ 和 echo)
[7. 模式规则](#7. 模式规则)
[8. 函数:wildcard](#8. 函数:wildcard)
[1. 回车与换行](#1. 回车与换行)
[2. 缓冲区](#2. 缓冲区)
[3. 测试代码](#3. 测试代码)
[4. 进度条程序](#4. 进度条程序)
[六、Git 版本控制器](#六、Git 版本控制器)
[七、GDB 调试](#七、GDB 调试)
[1. 编译带调试信息的程序](#1. 编译带调试信息的程序)
[2. 使用 cgdb(更友好的界面)](#2. 使用 cgdb(更友好的界面))
[3. 调试核心](#3. 调试核心)
[4. 常用指令](#4. 常用指令)
一、Linux 安装软件
-
主要方式:源码安装,软件包安装,包管理器(
yum/apt等)。 -
由于软件之间有库等依赖关系,因此软件安装是存在依赖的。
-
通过源码或软件包安装可能会造成包缺失、版本兼容性问题。
-
而包管理器可以自动解决依赖问题。
-
因此,安装软件最好使用包管理器。
二、Vim 使用
1. Vim 模式
-
由于
vim既可以插入文字,也可以使用不同命令,因此有三种模式:插入模式 、命令模式 和底行模式。-
插入模式:用于写入文本。
-
命令模式:用于输入编辑指令。
-
底行模式:用于保存、退出等操作。
-
-
模式切换:
-
在命令模式下输入
i可以进入插入模式写文本,按Esc键退出插入模式。 -
在命令模式下输入
Shift + :进入底行模式,按Esc键退出底行模式。 -
底行模式输入
set nu可以显示行号。 -
底行模式输入
wq表示写入(保存)并退出。
-
2. Vim 指令(命令模式)
-
光标移动
-
gg:快速移动光标到第一行。 -
Shift + 4($):移动光标到行尾。 -
Shift + 6(^):移动光标到行首。 -
n + Shift + g:将光标移动到第n行。 -
h,j,k,l:分别控制光标向左、下、上、右移动(很多命令都支持在前面加上数字,表示重复次数)。 -
b,w:以单词为单位向左、右移动(可以加数字)。
-
-
编辑
-
yy:复制当前行(可加数字表示复制几行)。 -
p:粘贴。 -
u:撤销。 -
Ctrl + r:撤销u操作(与u互逆)。注意:一旦退出文件就无法撤销,但仅保存文件时操作历史还在,可以撤销。 -
dd:剪切当前行。 -
x:删除光标所在位置的字符。 -
Shift + x:删除光标之前的字符。 -
r:替换单个字符;Shift + r:进入替换模式,批量替换(按Esc返回)。 -
Shift + `` (~`):进行大小写转换。
-
-
批量操作
-
Ctrl + v:进入可视块模式(v-block),可以用h,j,k,l进行区域选择。 -
Shift + i:在可视块模式下进入插入模式。 -
Shift + 3(#):高亮当前单词,n可以逆向查找下一个。 -
批量加注释示例:
-
Ctrl + v,选择要注释的行区域。
-
Shift + i进入插入模式,给第一行加上注释符号(如//)。
-
按
Esc退出,这样所有选中的行就都加上了注释。
-
-
批量删除注释:
-
在可视块模式(
Ctrl + v)下框住所有注释符号(如//)。 -
直接按
x(删除光标处字符)即可删除。
-
-
-
底行模式命令
-
!:与shell进行交互,!后跟命令可以在不退出vim的情况下执行shell命令。 -
wq:保存并退出。 -
%s/ / /:进行替换操作,将前面的内容替换为后面的内容。
-
-
分屏操作
-
在底行模式下输入
vs + 文件名可以进行分屏。 -
光标在哪个窗口就代表在操作哪个窗口。
-
Ctrl + ww:切换到另一个窗口。
-
-
操作技巧
-
!+ 字符:自动执行最近以该字符开头的命令。 -
Ctrl + r:搜索最近使用的命令。
-
-
sudo命令白名单添加-
用
root用户打开/etc/sudoers文件。 -
在用户权限配置部分添加相应的规则。
-
三、gcc/g++ 的使用
1. 简单编译+运行
g++ a.c
./a.out2. 指定可执行文件名称
gcc -o code2 a.c
# 或
gcc a.c -o code1-
这样就会生成名为
code2或code1的可执行文件。
-
注意 :
-o选项右边的参数是生成的文件名,顺序不要反。
3. 编译过程
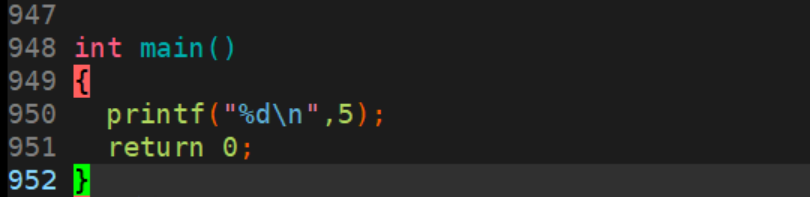
-
预处理
g++ -E a.c -o a.i-
-E:预处理完就停下。 -
将预处理后的文件输出到
a.i。 -
可以看到,即使我们只有几行的代码,预处理后也可能变成近千行。
-
预处理工作:展开头文件、去除注释、宏替换、条件编译。
-
生成的
a.i文件依旧是 C 语言代码。
-
-
编译(生成汇编)
g++ -S a.i -o a.s-S:开始编译,编译完就停下。
-
汇编(生成机器码)
bash
g++ -c a.s -o a.o-
-c:开始汇编,汇编完停下。 -
生成可重定位文件(
.obj,即.o文件),是二进制文件。 -
在项目有多个源文件时,通常会先将所有源文件编译成
.o文件,再统一链接生成可执行程序。 -
直接查看
.o文件是乱码,并且不可执行。 -
原因 :因为它只是标记了需要哪些库的函数(如
printf),但还不知道这些函数的具体位置(还没有链接)。 -
ldd命令:查看可执行程序依赖哪些库。
libc是 C 标准库。
-
查看其他命令(如
ls)的依赖库:bash
ldd /usr/bin/ls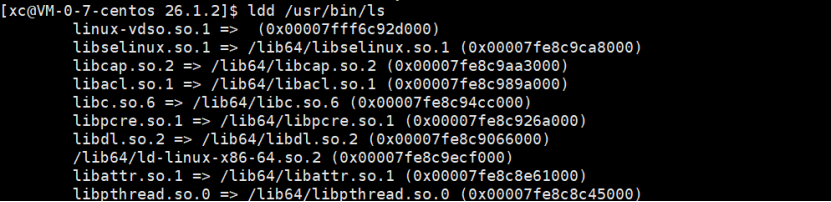
- 同样包含
libc库。
- 同样包含
-
-
链接
- 生成最终的可执行文件或库文件。
4. 静态库和动态库
-
库:是一套封装好的方法,为开发提供基本的功能和接口。
-
Linux 库命名规则 :
lib+ 库名 + 后缀(.so/.a)。 -
动态库(
.so):-
程序运行时,当需要调用库函数(如
printf)时,才到库中查找并执行。 -
因此,程序在链接阶段只需存储库函数的地址信息。
-
-
静态库(
.a):- 程序在链接阶段直接将库中用到的函数代码拷贝到可执行文件中。
-
两者对比:
-
使用动态库生成的可执行程序体积较小。
-
可执行程序对动态库的依赖较大,不能缺失;而对静态库的依赖小。
-
静态库链接会导致相同代码在多处重复,造成内存浪费。
-
5. 为什么 C 语言要先翻译成汇编,再翻译成机器码?
-
语言发展历史:二进制 -> 汇编 -> C 等高级语言。
-
在 C 语言发展时,汇编转二进制的技术已经比较成熟,因此可以"站在巨人的肩膀上"。
-
问题:汇编语言的编译器最初是用什么语言写的?
-
开始时,由于没有汇编语言,需要有直接用二进制编写的编译器来编译汇编语言的编译器。
-
接着,再用汇编语言写编译器,并用汇编语言不断迭代完善。
-
这个过程就叫编译器的自举。
-
6. 如何理解条件编译?
-
简单条件编译示例:
cpp#include<stdio.h> #define N int main() { #ifdef N printf("%d\n", 1); #else printf("%d\n", 2); #endif return 0; }- 切换输出只需要定义或不定义宏
N即可。
- 切换输出只需要定义或不定义宏
-
为什么需要条件编译?
-
为软件不同版本(如免费版、付费版)做功能区分。
-
内核源码用条件编译进行功能裁剪。
-
开发工具等需要适应不同的系统。
-
-
也可以在编译命令中定义宏:
bash
g++ a.c -o a.out -DN-D选项后面跟上要定义的宏。
7. 库的本质
-
假设有两组代码,声明和定义分离在 4 个文件里:
-
code1.h:void func1(); -
code2.h:void func2(); -
code1.c:void func1() { printf("1"); } -
code2.c:void func2() { printf("2"); } -
co.c:cpp#include<stdio.h> #include"code1.h" #include"code2.h" int main() { func1(); func2(); return 0; }
-
-
要运行
co.c,需要一起编译:g++ co.c code1.c code2.c。 -
如果我们先编译两个函数为
.o文件:g++ -c code1.c -o code1.o g++ -c code2.c -o code2.o -
当前目录文件结构:
|-- co.c |-- code1.h |-- code1.o |-- code2.h `-- code2.o -
然后链接:
g++ co.c code1.o code2.o,就可以运行了。 -
结论 :当多个
.o文件打包在一起,就形成了一个库。 -
因此,编译器为什么要生成
.o文件?因为它们是链接的基本单位,可以与库进行链接,最终形成可执行文件。
四、Make 和 Makefile
make是命令,Makefile是文件。
1. 简单 Makefile 文件
makefile
code: co.c code1.o code2.o
g++ -o code co.c code1.o code2.o-
其中,
code: co.c code1.o code2.o是依赖关系。 -
g++ -o code co.c code1.o code2.o是依赖方法。
2. .PHONY
-
伪目标,让依赖方法总是被执行。
-
为什么有些命令不会重复执行?
cpptest: test.c g++ -o test test.c-
在这个文件中,目的是编译
test.c。 -
但是连续执行两次
make命令,会有提示:make: 'test' is up to date. -
意思是已经编译过了,相同的文件没必要再编译一次。
-
只要我们修改一下
test.c文件,就又可以编译了。
-
-
编译器如何判断文件有没有被修改?------ 靠时间戳
stat test.c
-
文件有三个时间:
Access(访问时间),Modify(内容修改时间),Change(属性修改时间)。 -
Modify:修改文件内容。Change:修改文件属性。修改文件内容时,文件属性(如大小、最后修改时间)也会变,因此Change时间会一起变。 -
Access:读取文件。但由于读取很频繁,只有在读取多次后才会更新该时间。 -
编译器主要依靠
Modify时间来判断是否需要重新编译。
-
-
.PHONY就是忽略时间戳检查,强制执行命令。cpptest: test.c g++ -o test test.c .PHONY:clean clean: rm -rf test-
由于重复编译没必要,因此
test目标不加.PHONY。 -
而
clean清理操作我们希望每次都执行,因此加上.PHONY。
-
3. 依赖链
cpp
test: test.o
g++ test.o -o test
test.o: test.s
g++ -c test.s -o test.o
test.s: test.i
g++ -S test.i -o test.s
test.i: test.c
g++ -E test.c -o test.i
.PHONY:clean
clean:
rm -rf *.i *.s *.o test-
make本质上建立了一个栈。 -
从上往下查找依赖:
test: test.o,找不到.o文件,就将该命令入栈。同理,test.o: test.s,test.s: test.i依次入栈。 -
直到
test.i: test.c,找到了.c源文件,就执行该命令,然后依次出栈执行。
4. 变量替换
-
为了方便修改,可以用变量进行替换。
cppBIN=test CC=gcc SRC=test.c FLAGS=-o RM=rm -f $(BIN):$(SRC) $(CC) $(SRC) $(FLAGS) $(BIN) .PHONY:clean clean: $(RM) $(BIN)
5. 自动变量
-
$@:代表目标文件。 -
$^:代表所有依赖文件。cpp$(BIN):$(SRC) $(CC) $^ $(FLAGS) $@
6. @ 和 echo
-
@放在命令前,可以不显示该命令本身。 -
echo可以输出自定义信息。cpp$(BIN):$(SRC) @$(CC) $^ $(FLAGS) $@ @echo "compile $^ to $@"
7. 模式规则
-
指定生成规则,例如将所有
.c文件编译成.o文件。%.o: %.c $(CC) $(FLAGS) $<-
%是通配符。 -
$<代表第一个依赖文件。
-
8. 函数:wildcard
-
自动获取相关文件。
cppBIN=test.exe CC=gcc SRC=$(wildcard *.c) OBJ=$(SRC:.c=.o) LFLAGS=-o FLAGS=-c RM=rm -f $(BIN):$(OBJ) @$(CC) $^ $(LFLAGS) $@ @echo "compile $^ to $@" %.o: %.c $(CC) $(FLAGS) $< .PHONY:clean clean: $(RM) $(BIN) $(OBJ) .PHONY:print print: @echo $(BIN)-
$(wildcard *.c):获取当前目录下所有.c文件。 -
$(SRC:.c=.o):将所有.c文件名替换为.o文件名。
-
五、进度条项目
1. 回车与换行
-
回车 (
\r):将光标移动到当前行的最左侧。 -
换行 (
\n):将光标移动到下一行。 -
因此,键盘上的回车键以及
\n其实是做了"回车+换行"两个动作。
2. 缓冲区
cpp
#include<stdio.h>
#include<unistd.h>
int main() {
printf("hello");
sleep(3);
printf("\n");
printf("hello\n");
sleep(3);
return 0;
}-
在这个代码中,我们看到的现象是先停了一会,然后连续打印出两个
hello,再停。 -
原因 :第一个
hello被打印到输出缓冲区中,但是没有遇到换行符 (\n) 等刷新条件,因此没有立刻显示。直到执行printf("\n");时才刷新缓冲区并显示。 -
要想立即刷新:
-
使用
fflush指令:fflush(stdout);。(stdout在 Linux 中是显示器的文件描述符) -
使用
fprintf:fprintf和printf的区别在于fprintf可以指定输出路径(如文件或stdout)。显示器显示只认字符,输出数字需要先转为字符,因此需要格式化输出。
-
3. 测试代码
cpp
#include<stdio.h>
#include<unistd.h>
int main() {
int t = 10;
while (t >= 0) {
printf("%-2d\r", t);
fflush(stdout);
t--;
sleep(1);
}
printf("\n");
return 0;
}-
在屏幕上打印倒计时。
-
注意点:
-
%-2d\r:2d确保每个数字都占 2 位宽度,防止数字10变成0时屏幕上留下字符1。-让数字左对齐,显示更自然。 -
最后的
printf("\n");:将最后的数字0保留在屏幕上,效果更好看。
-
4. 进度条程序
-
头文件
process.h:cpp#define _CRT_SECURE_NO_WARNINGS using namespace std; #include<stdio.h> #include<unistd.h> #define LET # void setprocess(double cur, double all); -
源文件:
cpp#define _CRT_SECURE_NO_WARNINGS #include "process.h" void setprocess(double cur, double all) { static int pos = 0; static const char* str = "\\-//-\\0"; int num = (int)(cur * 100 / all); string s = string(num, '=') + string(100 - num, ' '); const char* ptr = s.c_str(); printf("[%s][%.2f%%][%c]\r", ptr, 100 * cur / all, str[pos % 3]); pos++; } void download(int all, int spe) { int pre = 0; while (pre <= all) { setprocess(pre, all); pre += spe; sleep(1); } printf("%dM finished", all); } int main() { const int req = 1024; const int spe = 128; download(req, spe); return 0; } -
注意点 :进度条应该是边下载边更新的,因此使用静态变量
pos,每更新一次,旁边的旋转标识就转动一次。
六、Git 版本控制器
基本概念
-
仓库:存放项目所有版本文件的文件夹。
-
远端仓库:在云服务器(如 GitHub, Gitee)上克隆的本地仓库副本。
-
Git 是底层的版本控制工具,GitHub/Gitee 是基于 Git 的网站平台。
使用步骤
-
创建仓库 :在 GitHub 或 Gitee 上创建新仓库,可以配置
.gitignore文件来忽略不需要版本控制的文件。 -
配置用户名和邮箱(首次使用需要):
git config --global user.email "your_email@example.com" git config --global user.name "Your Name" -
克隆到本地:
git clone + 仓库地址 -
添加到暂存区:
git add . # 添加所有未被忽略的文件 -
提交到本地仓库:
git commit -m "提交描述信息" -
推送到远端仓库:
git push
-
这样就完成了一次简单的代码提交。
-
Windows 也支持命令行操作,也可以使用图形化工具如 TortoiseGit 来简化操作。
-
添加文件 :在资源管理器右键选择
TortoiseGit->Add。
-
提交 :右键选择
Git Commit -> "master"...,填写信息后提交。
-
-
当一个用户更新了远端仓库后,其他用户需要使用
git pull命令来更新本地仓库,否则无法继续提交。 -
因此,远端仓库对于所有协作者来说都应该是最新的。
七、GDB 调试
1. 编译带调试信息的程序
g++ tiaoshi.cpp -o tiaoshi2 -g- 在编译时加上
-g选项,代表使用g++的 debug 模式,生成调试信息,才能进行调试。
2. 使用 cgdb(更友好的界面)
-
gdb的界面比较原始,可以使用cgdb,它将代码和调试信息分开显示。 -
安装:
sudo yum install -y cgdb
3. 调试核心
- 调试最重要的是找到问题所在。断点本质是将代码块进行级别划分,控制执行流程。
4. 常用指令
-
r(run):运行程序。 -
b+ 行号 (break):在指定行添加断点。 -
info b(info breakpoints):查看所有断点及其编号。 -
n(next):相当于 VS 的 F10,逐过程执行(不进入函数内部)。 -
s(step):相当于 VS 的 F11,逐语句执行(会进入函数内部)。 -
gdb会记录最近的指令,直接按回车可以重复执行上一条指令。 -
finish:执行到当前函数返回。-
示例:
cppint sum(int l, int r) { int ret = 0; for (int i = l; i <= r; i++) { ret += i; } return ret; } int main() { int l = 1; int r = 100; int ret = sum(l, r); cout << ret << endl; return 0; }-
在
sum函数内部执行finish命令后,会停在int ret = sum(l, r);这一行。 -
原因 :这一行其实是两步:调用
sum函数 + 将返回值赋给变量ret。finish会执行到函数返回,即寄存器准备好返回值,准备赋值给ret的那一步。
-
-
-
p+ 变量名 (print):打印变量的值。 -
disable/enable+ 断点编号:禁用或启用断点。 -
c(continue):继续运行,直到遇到下一个断点。 -
until+ 行号:一直运行到指定的行号停止。 -
display+ 变量名:一直展示该变量的值(每次停下来都显示)。 -
watch+ 变量名:监视变量,当其值发生变化时就显示。- 作用:当怀疑某个本不该被修改的常量可能被意外修改时使用。
-
set var+ 变量=值:手动将代码中某个变量的值改为指定值。- 作用:用于确定程序错误是否由该变量引起。
-
b行号if条件:设置条件断点。 -
condition断点编号 条件:为已有断点新增或修改条件。