1、先搞清楚:DataStream 连接器 vs SQL 连接器(版本现状)
很多人看到 "Flink 2.2 文档里有 DynamoDB SQL Connector" 会以为可以直接 CREATE TABLE ... WITH ('connector'='dynamodb') 开干,但需要注意:
- Flink 文档里 DynamoDB SQL Connector 在 Flink 2.2 版本标注为:还没有可用的 connector 依赖 (也就是:文档有,但 jar 还没发出来/不可用)。 (Apache Nightlies)
- 目前更成熟、可直接用的是 DataStream Connector :
DynamoDbStreamsSource+DynamoDbSink。 (Apache Nightlies)
如果你现在要落地"实时 CDC + 写回",建议优先走 DataStream 方案;SQL 方案可以先关注进展,等依赖正式可用再迁移。
2、整体链路长什么样
一个典型的实时链路(非常常见,也很好用):
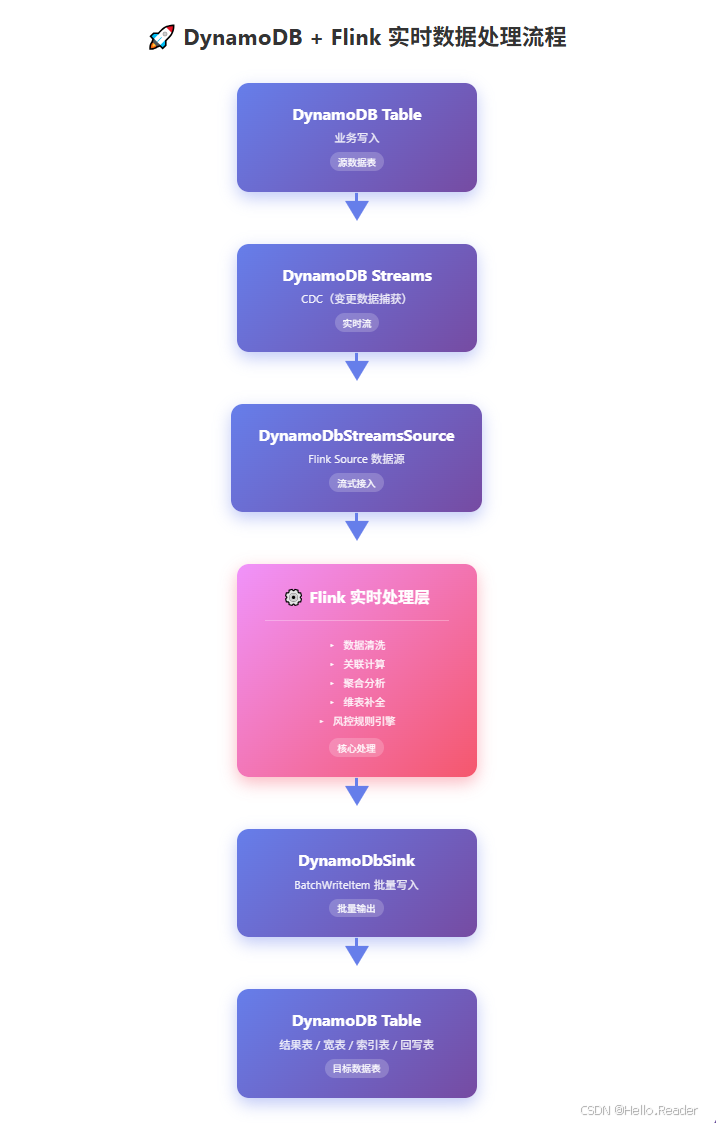
AWS 官方也有 "DynamoDB Streams + Flink" 的使用说明,核心就是"消费 Streams 记录并实时处理"。 (AWS 文檔)
3、Source:DynamoDbStreamsSource 读取 CDC
3.1 必备前置:Streams 与 StreamViewType
DynamoDbStreamsSource 读的是 DynamoDB Streams;而 Streams 事件里到底带不带 NEW_IMAGE/OLD_IMAGE,取决于你在 DynamoDB 表上配置的 StreamViewType。Flink 文档也强调:实际事件内容由 StreamViewType 决定。 (Apache Nightlies)
建议你在建表/改表时就想清楚:
- 只做主键级路由:
KEYS_ONLY - 做增量同步/回写:通常要
NEW_IMAGE或NEW_AND_OLD_IMAGES
3.2 起始位点:LATEST vs TRIM_HORIZON(非常关键)
Flink 里通过 DynamodbStreamsSourceConfigConstants.STREAM_INITIAL_POSITION 设定起始位置: (Apache Nightlies)
LATEST:从最新开始读TRIM_HORIZON:从最早可读开始读,但 DynamoDB Streams 数据会在 24 小时后被裁剪 (意味着你想"从头补历史",最多也就补 24 小时)。 (Apache Nightlies)
3.3 代码骨架:从 Stream ARN 启动 Source + 水位线
java
// 1) 配置 Source
Configuration sourceConfig = new Configuration();
sourceConfig.set(
DynamodbStreamsSourceConfigConstants.STREAM_INITIAL_POSITION,
DynamodbStreamsSourceConfigConstants.InitialPosition.TRIM_HORIZON // 默认 LATEST
);
// 2) 构建 DynamoDbStreamsSource
DynamoDbStreamsSource<MyChangeEvent> source =
DynamoDbStreamsSource.<MyChangeEvent>builder()
.setStreamArn("arn:aws:dynamodb:us-east-1:1231231230:table/test/stream/2024-04-11T07:14:19.380")
.setSourceConfig(sourceConfig)
.setDeserializationSchema(new MyDdbStreamsDeser())
.build();
// 3) 加入执行环境
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
DataStream<MyChangeEvent> stream =
env.fromSource(
source,
WatermarkStrategy.<MyChangeEvent>forMonotonousTimestamps()
.withIdleness(Duration.ofSeconds(1)),
"DynamoDB Streams source"
)
.uid("custom-uid");上面这套写法与官方示例一致:Stream ARN 指定流、Configuration 提供参数、WatermarkStrategy 可用 approximateCreationDateTime 做事件时间。 (Apache Nightlies)
3.4 反序列化:实现 DynamoDbStreamsDeserializationSchema
你需要实现 DynamoDbStreamsDeserializationSchema<T>,把 AWS Streams 的 Record 转成你自己的事件类型。Flink 文档明确:deserialize 接收的就是 DynamoDB Streams 的 Record。 (Apache Nightlies)
下面给一个"够用、好改"的事件结构(更偏工程落地):
java
public class MyChangeEvent {
public String eventName; // INSERT / MODIFY / REMOVE
public Instant eventTime;
public Map<String, AttributeValue> keys;
public Map<String, AttributeValue> newImage;
public Map<String, AttributeValue> oldImage;
}对应的反序列化大致这样:
java
public class MyDdbStreamsDeser implements DynamoDbStreamsDeserializationSchema<MyChangeEvent> {
@Override
public void deserialize(Record record, Collector<MyChangeEvent> out) {
var dd = record.dynamodb();
MyChangeEvent e = new MyChangeEvent();
e.eventName = record.eventNameAsString();
e.eventTime = dd.approximateCreationDateTime(); // 事件时间
e.keys = dd.keys();
e.newImage = dd.newImage();
e.oldImage = dd.oldImage();
out.collect(e);
}
@Override
public TypeInformation<MyChangeEvent> getProducedType() {
return TypeInformation.of(MyChangeEvent.class);
}
}3.5 顺序性与分片:你能指望的"有序"边界在哪里
这块很容易被误解,Flink 文档讲得很清楚:
- 同一个主键(primary key)内是有序的:因为同一主键会写入同一 shard lineage
- shard split(父 shard 分裂成子 shard)时,只要先把父 shard 读完,再读子 shard,就能保持顺序
DynamoDbStreamsSource会保证 shard 分配遵循父子关系:父 shard 读完,子 shard 才会进入分配逻辑 (Apache Nightlies)
结论很实用:
- 你要做"同一主键内严格顺序处理",可以放心
- 你要做"全局严格顺序",那不属于 Streams 的能力边界(要换设计)
3.6 Shard 分配策略
默认用 UniformShardAssigner:把 shard 尽量均匀分给并行子任务,新 shard 会给当前 shard 最少的 subtask。你也可以实现自定义 assigner。 (Apache Nightlies)
3.7 可靠性相关配置:重试与 shard discovery
Flink 文档列出了关键配置项: (Apache Nightlies)
-
重试策略(AWS SDK v2):
DYNAMODB_STREAMS_RETRY_COUNTDYNAMODB_STREAMS_EXPONENTIAL_BACKOFF_MIN_DELAYDYNAMODB_STREAMS_EXPONENTIAL_BACKOFF_MAX_DELAY
-
shard discovery:
- 默认每 60 秒发现新 shard,可用
SHARD_DISCOVERY_INTERVAL调小 - 若 shard graph 不一致,会自动检测并重试,重试次数由
DESCRIBE_STREAM_INCONSISTENCY_RESOLUTION_RETRY_COUNT控制
- 默认每 60 秒发现新 shard,可用
4、Sink:DynamoDbSink 用 BatchWriteItem 高吞吐写入
4.1 Maven 依赖与版本
以 Flink 1.17 文档为例,DataStream DynamoDB Sink 的依赖形如: (Apache Nightlies)
xml
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-connector-dynamodb</artifactId>
<version>4.2.0-1.17</version>
</dependency>不同 Flink 版本会对应不同 connector 版本号,建议你以目标 Flink 版本的官方文档为准。
4.2 代码骨架:builder + 参数调优位
java
Properties sinkProperties = new Properties();
sinkProperties.put(AWSConfigConstants.AWS_REGION, "eu-west-1");
// 建议生产别写死 AK/SK:可以走环境变量 / IAM Role
sinkProperties.put(AWSConfigConstants.AWS_ACCESS_KEY_ID, "aws_access_key_id");
sinkProperties.put(AWSConfigConstants.AWS_SECRET_ACCESS_KEY, "aws_secret_access_key");
ElementConverter<MyOut, DynamoDbWriteRequest> converter = new MyElementConverter();
DynamoDbSink<MyOut> sink =
DynamoDbSink.<MyOut>builder()
.setDynamoDbProperties(sinkProperties) // 必填
.setTableName("my-dynamodb-table") // 必填
.setElementConverter(converter) // 必填
.setOverwriteByPartitionKeys(List.of("pk")) // 可选:批内去重
.setFailOnError(false) // 可选:错误是否致命
.setMaxBatchSize(25) // 可选:默认 25
.setMaxInFlightRequests(50) // 可选:并发
.setMaxBufferedRequests(10_000) // 可选:缓冲
.setMaxTimeInBufferMS(5000) // 可选:最大滞留时间
.build();
stream.sinkTo(sink);这套参数在官方文档中都有对应解释。 (Apache Nightlies)
4.3 牢记 BatchWriteItem 的硬上限(否则你会"莫名其妙写不进去")
DynamoDB 的 BatchWriteItem 有明确限制:一次请求最多 25 个 put/delete 操作,整个请求体最多 16MB 。 (AWS 文檔)
所以:
setMaxBatchSize(25)不是拍脑袋,是 API 天花板- 如果单条记录很大,即使没到 25 条也可能触发大小限制(需要做字段裁剪、拆分表设计或降维)
4.4 ElementConverter:把 DataStream 元素变成 DynamoDbWriteRequest
Sink 的关键就是 ElementConverter<InputType, DynamoDbWriteRequest>:负责把你的对象转为 DynamoDB 的 put/delete 请求。 (Apache Nightlies)
一个常见的"写入 PutRequest"骨架(示意):
java
public class MyElementConverter implements ElementConverter<MyOut, DynamoDbWriteRequest> {
@Override
public DynamoDbWriteRequest apply(MyOut v) {
Map<String, AttributeValue> item = new HashMap<>();
item.put("pk", AttributeValue.builder().s(v.getPk()).build());
item.put("sk", AttributeValue.builder().s(v.getSk()).build());
item.put("cnt", AttributeValue.builder().n(String.valueOf(v.getCnt())).build());
return DynamoDbWriteRequest.builder()
.putRequest(PutRequest.builder().item(item).build())
.build();
}
}如果你不想写 converter,Flink 也提供了一些默认实现思路:例如从 POJO/Row/TypeInformation 推导 schema,或者用 @DynamoDbBean 相关的 converter。 (Apache Nightlies)
4.5 幂等与去重:overwriteByPartitionKeys 怎么用才不坑
setOverwriteByPartitionKeys(partitionKeys) 的语义是:在"每个 batch 内 "对相同分区键的写请求做去重(典型是"后来的覆盖前面的"),避免一个 batch 内同一主键被重复写导致浪费。 (Apache Nightlies)
它不是"全局去重",也不是"事务 exactly-once"。如果你要端到端更强语义,建议:
- 输出表写入设计为"幂等覆盖"(同 pk 写入覆盖)
- 或引入业务版本号/事件时间戳,保证"最后写入生效"
- 或在 Flink 侧做去重/聚合后再写
5、本地/测试环境:Localstack 或自定义 Endpoint
做集成测试时,很常见要写到 Localstack,或写到 VPC Endpoint。Flink 文档给了明确做法:设置 AWSConfigConstants.AWS_ENDPOINT,并同时设置 AWS_REGION(region 用于对 endpoint URL 做签名)。 (Apache Nightlies)
java
Properties cfg = new Properties();
cfg.put(AWSConfigConstants.AWS_REGION, "eu-west-1");
cfg.put(AWSConfigConstants.AWS_ACCESS_KEY_ID, "test");
cfg.put(AWSConfigConstants.AWS_SECRET_ACCESS_KEY, "test");
cfg.put(AWSConfigConstants.AWS_ENDPOINT, "http://localhost:4566"); // Localstack这招对 Source 和 Sink 都适用,尤其适合做端到端回归测试。
6、补充:Flink 生态里 DynamoDB Streams Source 的演进
如果你之前用过老的消费方式(比如 FlinkDynamoDBStreamsConsumer 一类),Flink 社区也发布过迁移说明:可以迁移到新的 DynamoDbStreamsSource,接口更统一、可读性更好。 (Apache Flink)
7、一份"上线前自检清单"(很值)
-
Streams 起始位点
想追历史就用
TRIM_HORIZON,但别忘了 Streams 只保 24 小时 。 (Apache Nightlies) -
StreamViewType 配对你的业务
不带 new/old image,你反序列化拿不到字段。
-
顺序性边界
只保证"同一主键内有序",跨主键不要幻想全局顺序。 (Apache Nightlies)
-
Sink 的 BatchWriteItem 限制
单次最多 25 条、最多 16MB。吞吐上去以后,很多"写失败/变慢"本质都是触顶。 (AWS 文檔)
-
压力控制
通过
maxInFlightRequests/maxBufferedRequests/maxTimeInBufferMS找到吞吐与延迟的平衡点(别只看 QPS,先把延迟曲线画出来)。 -
测试环境
用 Localstack 时记得同时设 endpoint + region。 (Apache Nightlies)
8、SQL Connector(Flink 2.2)现在能用吗?
Flink 2.2 的文档里确实有 DynamoDB SQL Connector 的建表示例和参数列表,但依赖部分明确写了"还没有 connector 可用"。 (Apache Nightlies)
如果你想先把 SQL DDL 写好做"未来迁移预案",可以保留类似:
sql
CREATE TABLE DynamoDbTable (
user_id BIGINT,
item_id BIGINT,
category_id BIGINT,
behavior STRING
) WITH (
'connector' = 'dynamodb',
'table-name' = 'user_behavior',
'aws.region' = 'us-east-2'
);但落地执行层面,现阶段仍建议 DataStream 方案先跑起来。