目录
[1.1 MySQL 在数据存储与管理中的核心作用](#1.1 MySQL 在数据存储与管理中的核心作用)
[1.2 数据可视化的定义与应用场景](#1.2 数据可视化的定义与应用场景)
[1.3 MySQL 与可视化工具结合的常见工作流程](#1.3 MySQL 与可视化工具结合的常见工作流程)
[二、数据准备与清洗:可视化的 "基石"](#二、数据准备与清洗:可视化的 “基石”)
[2.1 通过 SQL 查询提取目标数据](#2.1 通过 SQL 查询提取目标数据)
[2.2 用临时表 / 视图优化复杂查询](#2.2 用临时表 / 视图优化复杂查询)
[2.3 数据清洗技巧](#2.3 数据清洗技巧)
[3.1 直接连接 MySQL 的 BI 工具](#3.1 直接连接 MySQL 的 BI 工具)
[3.2 编程语言桥接](#3.2 编程语言桥接)
[3.3 Excel 与 MySQL 的 ODBC 连接配置](#3.3 Excel 与 MySQL 的 ODBC 连接配置)
[4.1 时间序列分析:折线图展示销售趋势](#4.1 时间序列分析:折线图展示销售趋势)
[4.2 分布分析:直方图与箱线图](#4.2 分布分析:直方图与箱线图)
[4.3 关联分析:散点图与热力图](#4.3 关联分析:散点图与热力图)
[5.1 为可视化优化查询:索引、分区表与缓存](#5.1 为可视化优化查询:索引、分区表与缓存)
[5.2 大数据场景下的分页查询与采样技术](#5.2 大数据场景下的分页查询与采样技术)
[5.3 存储过程自动化数据预处理](#5.3 存储过程自动化数据预处理)
[六、实战项目:从 MySQL 到 Superset 动态仪表盘](#六、实战项目:从 MySQL 到 Superset 动态仪表盘)
[6.1 环境准备](#6.1 环境准备)
[6.2 连接 MySQL 数据源](#6.2 连接 MySQL 数据源)
[6.3 制作交互式仪表盘](#6.3 制作交互式仪表盘)
[6.4 定时更新数据](#6.4 定时更新数据)
[7.1 连接超时或性能瓶颈](#7.1 连接超时或性能瓶颈)
[7.2 数据类型转换对可视化的影响](#7.2 数据类型转换对可视化的影响)
[7.3 权限管理与数据安全](#7.3 权限管理与数据安全)
[8.1 MySQL 8.0 的 JSON 功能与复杂可视化支持](#8.1 MySQL 8.0 的 JSON 功能与复杂可视化支持)
[8.2 云数据库与可视化服务的协同](#8.2 云数据库与可视化服务的协同)
[8.3 AI 驱动的自动化可视化探索](#8.3 AI 驱动的自动化可视化探索)
引言
在数据驱动决策的时代,MySQL 作为全球最流行的开源关系型数据库,承担着海量结构化数据的存储与管理重任;而数据可视化则是将冰冷数据转化为直观洞察的核心手段。将 MySQL 的高效数据处理能力与可视化技术结合,能让数据价值最大化 ------ 从业务报表到实时监控仪表盘,从趋势分析到异常预警,都能通过这套组合拳实现。本文将从基础概念到实战落地,全面讲解如何用 MySQL 玩转数据可视化,涵盖数据准备、工具集成、案例实现、性能优化等核心环节,附带可直接运行的代码与可视化效果展示。
一、MySQL与数据可视化的基础概念
1.1 MySQL 在数据存储与管理中的核心作用
MySQL 作为关系型数据库(RDBMS),是数据可视化的 "数据底座",其核心价值体现在:
-
结构化存储:通过表、字段、主键 / 外键等约束,保证数据的完整性与一致性,为可视化提供高质量数据源;
-
高效查询:支持复杂的 SQL 语法(聚合、关联、子查询等),能快速从海量数据中提取可视化所需的目标数据集;
-
扩展性:支持分区表、索引、读写分离等特性,适配从百级到亿级数据的可视化场景;
-
生态兼容:几乎所有主流可视化工具都原生支持 MySQL 连接,无需复杂的适配开发。
MySQL作为关系型数据库管理系统,在数据可视化流程中扮演着"数据仓库"的角色。根据DB-Engines 2023年的排名,MySQL在关系型数据库中持续位居第二,市场份额达44.5%。
sql
-- 创建示例销售数据库
CREATE DATABASE sales_dashboard;
USE sales_dashboard;
CREATE TABLE sales (
id INT PRIMARY KEY AUTO_INCREMENT,
sale_date DATE NOT NULL,
product_id VARCHAR(50),
category VARCHAR(100),
region VARCHAR(50),
sales_amount DECIMAL(10,2),
quantity INT,
customer_id VARCHAR(100),
created_at TIMESTAMP DEFAULT CURRENT_TIMESTAMP
);
CREATE INDEX idx_sale_date ON sales(sale_date);
CREATE INDEX idx_category_region ON sales(category, region);1.2 数据可视化的定义与应用场景
数据可视化是将数据转化为图表、地图、仪表盘等视觉形式的过程,核心目标是降低数据理解成本,发现数据规律 / 异常。常见应用场景:
| 场景类型 | 典型可视化形式 | 依赖 MySQL 能力 |
|---|---|---|
| 销售趋势分析 | 折线图 / 面积图 | 日期函数、GROUP BY 聚合 |
| 用户分布分析 | 直方图 / 地图 | 统计函数(COUNT/AVG)、JOIN |
| 指标监控 | 仪表盘 / 告警图 | 实时查询、视图 / 存储过程 |
| 多维关联分析 | 热力图 / 散点图 | 多表关联、多维聚合 |
1.3 MySQL 与可视化工具结合的常见工作流程
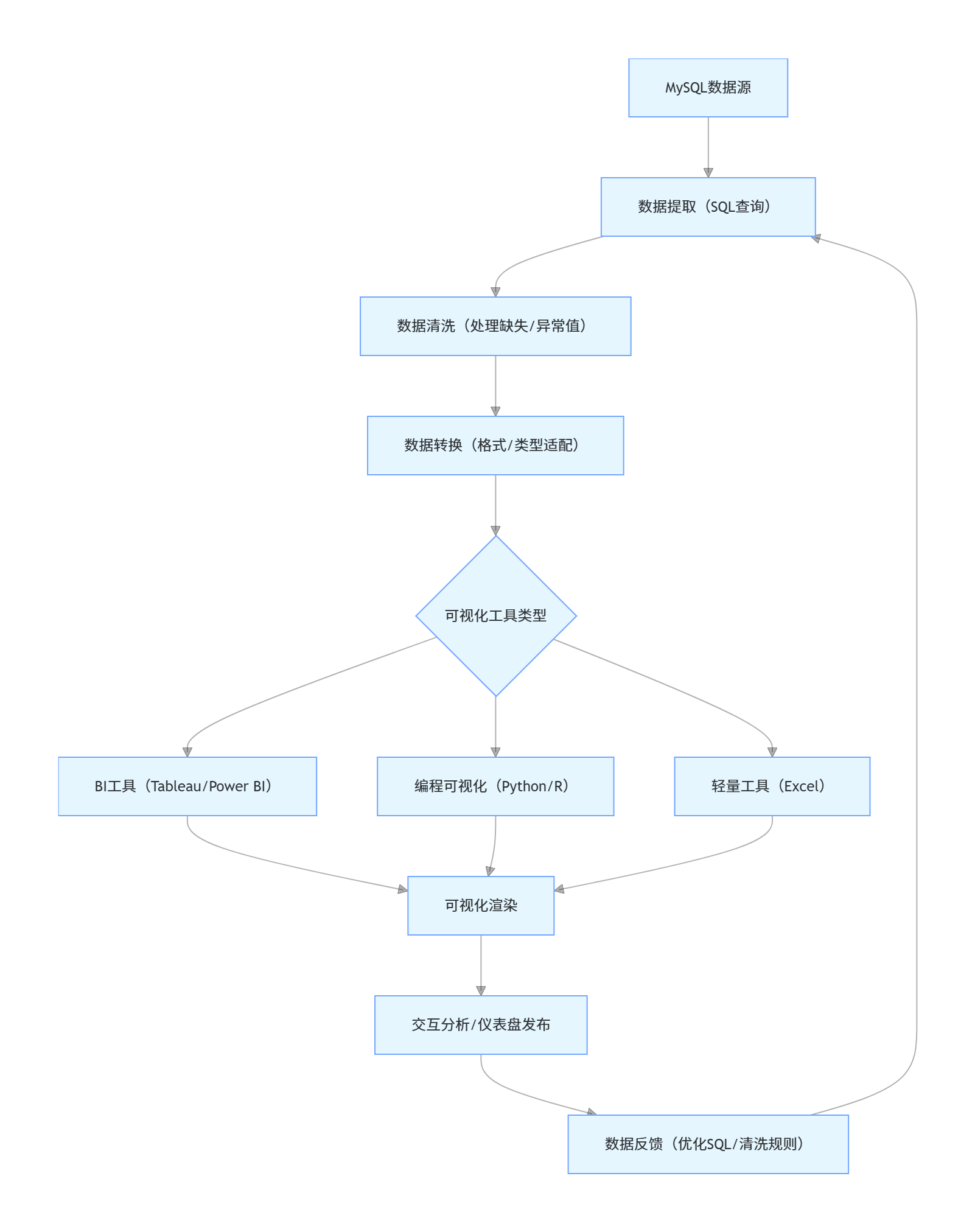
二、数据准备与清洗:可视化的 "基石"
可视化的质量取决于数据源的质量 ------脏数据必然导致错误的可视化结论。这一环节的核心是通过 MySQL 完成数据的提取、结构化优化与清洗。
2.1 通过 SQL 查询提取目标数据
核心语法:聚合、筛选、排序
以电商销售数据为例(表名:sales_data),提取 2024 年各月的销售额与订单量:
sql
-- 基础提取:2024年各月销售数据
SELECT
DATE_FORMAT(sale_date, '%Y-%m') AS month, -- 日期格式化
COUNT(order_id) AS order_count, -- 订单量(聚合)
SUM(sale_amount) AS total_sales -- 销售额(聚合)
FROM sales_data
WHERE sale_date BETWEEN '2024-01-01' AND '2024-12-31' -- 筛选
AND is_valid = 1 -- 过滤无效订单
GROUP BY month -- 按月分组
ORDER BY month ASC; -- 排序2.2 用临时表 / 视图优化复杂查询
当可视化需要多表关联、多层聚合的复杂数据时,直接查询会导致性能低下且可读性差,可通过临时表 或视图优化:
sql
-- 1. 创建视图:整合用户、订单、商品数据
CREATE VIEW v_sales_analysis AS
SELECT
o.order_id,
o.order_time,
u.user_id,
u.city,
p.category,
o.amount
FROM orders o
JOIN users u ON o.user_id = u.user_id
JOIN products p ON o.product_id = p.product_id
WHERE o.order_status = 'paid'; -- 仅已支付订单
-- 2. 基于视图创建临时表(提升查询性能)
CREATE TEMPORARY TABLE tmp_monthly_sales AS
SELECT
DATE_FORMAT(order_time, '%Y-%m') AS month,
city,
category,
SUM(amount) AS total_amount
FROM v_sales_analysis
GROUP BY month, city, category;
-- 可视化查询:直接从临时表提取
SELECT month, category, total_amount FROM tmp_monthly_sales WHERE city = '北京';说明:视图适合频繁复用的查询逻辑,临时表适合一次性的复杂计算,两者均可降低可视化查询的复杂度。
2.3 数据清洗技巧
(1)处理缺失值
sql
-- 方式1:填充默认值(如销售额缺失填充0)
UPDATE sales_data
SET sale_amount = 0
WHERE sale_amount IS NULL;
-- 方式2:删除关键字段缺失的记录(不影响整体的前提下)
DELETE FROM sales_data
WHERE order_id IS NULL OR sale_date IS NULL;
-- 方式3:用均值填充(适合数值型字段)
UPDATE sales_data s1
JOIN (SELECT AVG(sale_amount) AS avg_amount FROM sales_data WHERE sale_amount IS NOT NULL) s2
SET s1.sale_amount = s2.avg_amount
WHERE s1.sale_amount IS NULL;(2)处理异常值
异常值(如销售额为负数、订单量超出合理范围)会严重影响可视化结果,可通过 SQL 筛选并处理:
sql
-- 1. 筛选异常值(先排查)
SELECT * FROM sales_data
WHERE sale_amount < 0 OR sale_amount > 100000; -- 假设单订单合理上限10万
-- 2. 修正异常值(如替换为95分位数)
UPDATE sales_data s1
JOIN (SELECT PERCENTILE_CONT(0.95) WITHIN GROUP (ORDER BY sale_amount) AS p95 FROM sales_data) s2
SET s1.sale_amount = s2.p95
WHERE s1.sale_amount > s2.p95;三、常用可视化工具与MySQL集成
3.1 直接连接 MySQL 的 BI 工具
这类工具无需编程,通过可视化界面配置连接和图表,适合业务人员快速上手:
| 工具名称 | 适用场景 | 连接方式 | 优势 |
|---|---|---|---|
| Tableau | 企业级BI | ODBC/JDBC | 交互性强,支持复杂计算 |
| Power BI | Microsoft生态 | MySQL连接器 | 与Office集成好 |
| Metabase | 开源自助BI | 原生支持 | 部署简单,SQL友好 |
| Superset | 大数据可视化 | SQLAlchemy | 支持多种数据库,扩展性强 |
配置示例(Metabase):
-
进入 Metabase 后台 → 数据源 → 添加数据源 → 选择 MySQL;
-
填写:主机(如localhost)、端口(3306)、数据库名、用户名 / 密码;
-
测试连接成功后,即可拖拽表字段生成可视化图表。
3.2 编程语言桥接
适合定制化程度高的可视化场景,步骤:MySQL 提取数据 → Python 处理 → 绘图。
示例:
python
# 1. 安装依赖
# pip install pymysql pandas matplotlib seaborn
# 2. 代码实现
import pymysql
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
# 设置中文字体(解决乱码问题)
plt.rcParams['font.sans-serif'] = ['SimHei']
plt.rcParams['axes.unicode_minus'] = False
# 连接MySQL数据库
def connect_mysql():
conn = pymysql.connect(
host='localhost',
port=3306,
user='root',
password='你的密码',
database='ecommerce' # 替换为你的数据库名
)
return conn
# 提取数据
def get_sales_data():
conn = connect_mysql()
sql = """
SELECT
DATE_FORMAT(sale_date, '%Y-%m') AS month,
COUNT(order_id) AS order_count,
SUM(sale_amount) AS total_sales
FROM sales_data
WHERE sale_date BETWEEN '2024-01-01' AND '2024-12-31'
GROUP BY month
ORDER BY month ASC;
"""
df = pd.read_sql(sql, conn)
conn.close()
return df
# 绘制折线图
def plot_sales_trend(df):
fig, ax1 = plt.subplots(figsize=(12, 6))
# 左轴:销售额
sns.lineplot(x='month', y='total_sales', data=df, ax=ax1, color='red', marker='o', label='销售额')
ax1.set_xlabel('月份')
ax1.set_ylabel('销售额(元)', color='red')
ax1.tick_params(axis='y', labelcolor='red')
# 右轴:订单量
ax2 = ax1.twinx()
sns.lineplot(x='month', y='order_count', data=df, ax=ax2, color='blue', marker='s', label='订单量')
ax2.set_ylabel('订单量(单)', color='blue')
ax2.tick_params(axis='y', labelcolor='blue')
# 图表样式
plt.title('2024年各月销售趋势')
fig.legend(loc='upper left', bbox_to_anchor=(0.1, 0.9))
plt.xticks(rotation=45)
plt.tight_layout()
plt.savefig('sales_trend.png')
plt.show()
# 主函数
if __name__ == '__main__':
df = get_sales_data()
print(df.head()) # 打印数据预览
plot_sales_trend(df)运行效果
生成的折线图会同时展示 2024 年各月销售额(红色)和订单量(蓝色)的变化趋势,可直观看到旺季 / 淡季(如 11 月双十一销售额峰值)。
3.3 Excel 与 MySQL 的 ODBC 连接配置
Excel 是最轻量化的可视化工具,通过 ODBC 连接 MySQL 可直接读取数据并制作图表,步骤:
-
安装 MySQL ODBC 驱动(官网下载:https://dev.mysql.com/downloads/connector/odbc/);
-
打开 Windows "ODBC 数据源管理器" → 系统 DSN → 添加 → 选择 MySQL ODBC 8.0 Unicode Driver;
-
填写 MySQL 连接信息(主机、端口、数据库名、账号密码),测试连接;
-
打开 Excel → 数据 → 获取数据 → 自其他来源 → 自 ODBC → 选择配置好的 DSN → 加载数据 → 制作图表。
四、典型可视化案例实现
4.1 时间序列分析:折线图展示销售趋势
核心依赖 MySQL 的DATE_FORMAT、STR_TO_DATE等日期函数,结合 Python 的 Matplotlib 绘制趋势,已在 3.2 节给出完整代码,此处补充优化点:
-
按周 / 季度聚合:将
DATE_FORMAT(sale_date, '%Y-%m')改为DATE_FORMAT(sale_date, '%Y-%u')(按周)或QUARTER(sale_date)(按季度); -
同比 / 环比分析:通过子查询计算上月 / 去年同期数据,示例:
sql
-- 计算月度环比增长率
SELECT
month,
total_sales,
LAG(total_sales) OVER (ORDER BY month) AS last_month_sales,
ROUND((total_sales - LAG(total_sales) OVER (ORDER BY month)) / LAG(total_sales) OVER (ORDER BY month) * 100, 2) AS mom_growth
FROM (
SELECT DATE_FORMAT(sale_date, '%Y-%m') AS month, SUM(sale_amount) AS total_sales
FROM sales_data
WHERE sale_date BETWEEN '2024-01-01' AND '2024-12-31'
GROUP BY month
) t;4.2 分布分析:直方图与箱线图
MySQL 数据提取
sql
-- 提取用户单次消费金额分布数据
SELECT
user_id,
sale_amount AS single_consume
FROM sales_data
WHERE sale_date BETWEEN '2024-01-01' AND '2024-12-31'
AND sale_amount > 0;Python 可视化代码
python
def plot_consume_distribution(df):
# 直方图:消费金额分布
plt.figure(figsize=(12, 5))
plt.subplot(1, 2, 1)
sns.histplot(df['single_consume'], bins=20, kde=True, color='skyblue')
plt.title('用户单次消费金额分布')
plt.xlabel('消费金额(元)')
plt.ylabel('频次')
# 箱线图:识别异常值
plt.subplot(1, 2, 2)
sns.boxplot(y=df['single_consume'], color='lightgreen')
plt.title('消费金额箱线图(异常值识别)')
plt.ylabel('消费金额(元)')
plt.tight_layout()
plt.savefig('consume_dist.png')
plt.show()
# 调用(需先提取数据到df)
# df = get_consume_data() # 封装上述SQL的查询函数
# plot_consume_distribution(df)效果说明
直方图展示消费金额的集中区间(如 80% 用户单次消费在 0-500 元),箱线图可直观看到异常高消费的离群点(需进一步验证是否为真实订单)。
4.3 关联分析:散点图与热力图
MySQL 数据提取(多表关联)
sql
-- 计算用户客单价与复购次数
SELECT
u.user_id,
AVG(s.sale_amount) AS avg_consume, -- 客单价
COUNT(DISTINCT s.order_id) AS order_times -- 复购次数
FROM users u
JOIN sales_data s ON u.user_id = s.user_id
WHERE s.sale_date BETWEEN '2024-01-01' AND '2024-12-31'
GROUP BY u.user_id
HAVING order_times >= 2; -- 仅复购用户Python 可视化代码(散点图 + 热力图)
python
def plot_correlation(df):
# 散点图:客单价 vs 复购次数
plt.figure(figsize=(12, 5))
plt.subplot(1, 2, 1)
sns.scatterplot(x='avg_consume', y='order_times', data=df, alpha=0.6)
plt.title('客单价与复购次数关联')
plt.xlabel('客单价(元)')
plt.ylabel('复购次数')
# 热力图:各城市客单价与复购率的相关性
plt.subplot(1, 2, 2)
# 先计算各城市的聚合数据
city_corr = df.groupby('city')[['avg_consume', 'order_times']].mean().corr()
sns.heatmap(city_corr, annot=True, cmap='coolwarm', vmin=-1, vmax=1)
plt.title('客单价与复购次数相关性热力图')
plt.tight_layout()
plt.savefig('correlation_analysis.png')
plt.show()五、性能优化与高级技巧
5.1 为可视化优化查询:索引、分区表与缓存
(1)索引优化
可视化查询常涉及日期、分类字段的筛选 / 分组,需针对性创建索引:
sql
-- 为销售表的日期和分类字段创建联合索引
CREATE INDEX idx_sales_date_category ON sales_data(sale_date, category);
-- 为常用聚合字段创建覆盖索引(避免回表)
CREATE INDEX idx_sales_cover ON sales_data(sale_date, is_valid, sale_amount) INCLUDE (order_id);(2)分区表
当数据量超过 1000 万行时,按日期分区可大幅提升查询速度:
sql
-- 按月份分区销售表
ALTER TABLE sales_data
PARTITION BY RANGE (TO_DAYS(sale_date)) (
PARTITION p202401 VALUES LESS THAN (TO_DAYS('2024-02-01')),
PARTITION p202402 VALUES LESS THAN (TO_DAYS('2024-03-01')),
...
PARTITION p202412 VALUES LESS THAN (TO_DAYS('2025-01-01'))
);(3)查询缓存
MySQL 8.0 移除了查询缓存,但可通过应用层缓存(如 Redis)缓存可视化常用查询结果:
sql
# 示例:用Redis缓存月度销售数据
import redis
import json
r = redis.Redis(host='localhost', port=6379, db=0)
def get_sales_data_with_cache():
cache_key = 'sales_data_2024'
# 先查缓存
if r.exists(cache_key):
data = json.loads(r.get(cache_key))
df = pd.DataFrame(data)
else:
# 缓存未命中,查MySQL
conn = connect_mysql()
sql = "SELECT ..." # 销售数据查询SQL
df = pd.read_sql(sql, conn)
conn.close()
# 写入缓存(过期时间1小时)
r.setex(cache_key, 3600, df.to_json())
return df5.2 大数据场景下的分页查询与采样技术
当数据量过亿时,全量查询不现实,可通过分页或采样获取代表性数据:
sql
-- 分页查询(按日期分块提取)
SELECT * FROM sales_data
WHERE sale_date BETWEEN '2024-01-01' AND '2024-12-31'
LIMIT 10000 OFFSET 0; -- 第1页,每页1万条
-- 随机采样(10%数据)
SELECT * FROM sales_data
WHERE sale_date BETWEEN '2024-01-01' AND '2024-12-31'
AND RAND() <= 0.1; -- 随机取10%数据,保证分布近似5.3 存储过程自动化数据预处理
将重复的清洗 / 聚合逻辑封装为存储过程,可视化前一键执行:
sql
-- 创建存储过程:预处理月度销售数据
DELIMITER //
CREATE PROCEDURE proc_preprocess_sales(IN start_date DATE, IN end_date DATE)
BEGIN
-- 1. 清洗数据
UPDATE sales_data
SET sale_amount = 0 WHERE sale_amount IS NULL;
DELETE FROM sales_data WHERE order_id IS NULL;
-- 2. 生成月度聚合表
DROP TABLE IF EXISTS monthly_sales;
CREATE TABLE monthly_sales AS
SELECT
DATE_FORMAT(sale_date, '%Y-%m') AS month,
SUM(sale_amount) AS total_sales,
COUNT(order_id) AS order_count
FROM sales_data
WHERE sale_date BETWEEN start_date AND end_date
GROUP BY month;
END //
DELIMITER ;
-- 调用存储过程
CALL proc_preprocess_sales('2024-01-01', '2024-12-31');六、实战项目:从 MySQL 到 Superset 动态仪表盘
Apache Superset 是开源的 BI 工具,适合搭建企业级动态仪表盘,以下是完整搭建步骤:
6.1 环境准备
bash
# 1. 安装Docker(简化部署)
# 2. 启动Superset容器
docker run -d -p 8088:8088 --name superset apache/superset
# 3. 初始化管理员账号
docker exec -it superset superset fab create-admin \
--username admin \
--firstname Admin \
--lastname User \
--email admin@example.com \
--password admin123
# 4. 初始化数据库
docker exec -it superset superset db upgrade
docker exec -it superset superset init6.2 连接 MySQL 数据源
-
访问http://localhost:8088,登录 admin 账号;
-
点击 "Data" → "Databases" → "+ Database";
-
选择 "MySQL",填写连接字符串:
mysql+pymysql://root:你的密码@host.docker.internal:3306/ecommerce(host.docker.internal 映射本地主机); -
测试连接成功后保存。
6.3 制作交互式仪表盘
-
点击 "Charts" → "+ Chart",选择 MySQL 数据源和目标表;
-
选择图表类型(如折线图),配置 X 轴(month)、Y 轴(total_sales);
-
添加筛选器(如城市、品类),实现参数化查询(用户可自行选择筛选条件);
-
点击 "Save",将图表添加到仪表盘;
-
仪表盘支持拖拽调整布局、添加多个图表,最终生成 "销售监控仪表盘"。
6.4 定时更新数据
-
用 Airflow 创建 DAG,定时执行 MySQL 存储过程(数据预处理);
-
配置 Crontab 定时刷新 Superset 仪表盘缓存:
bash
# 每天凌晨1点刷新缓存
0 1 * * * curl -X POST http://localhost:8088/api/v1/dashboard/1/refresh -H "Authorization: Bearer your_token"七、常见问题与解决方案
7.1 连接超时或性能瓶颈
-
原因:MySQL 连接数不足、查询未优化、网络延迟;
-
解决方案:
-
增加 MySQL 最大连接数:
SET GLOBAL max_connections = 1000;; -
用
EXPLAIN分析查询执行计划,优化索引; -
大数据场景使用数据同步(将 MySQL 数据同步到 ClickHouse),降低源库压力。
-
7.2 数据类型转换对可视化的影响
-
问题:MySQL 的 DATE 类型导入 Python 后变为字符串,导致排序错误;
-
解决方案:
python
# 转换为日期类型
df['month'] = pd.to_datetime(df['month'], format='%Y-%m')
df = df.sort_values('month')7.3 权限管理与数据安全
-
问题:可视化工具直接连接 MySQL 可能导致数据泄露;
-
解决方案:
-
创建只读账号:
GRANT SELECT ON ecommerce.* TO 'visual_user'@'%' IDENTIFIED BY '123456';; -
敏感字段脱敏(如手机号:
CONCAT(LEFT(phone,3), '****', RIGHT(phone,4))); -
限制可视化工具的 IP 访问:
GRANT SELECT ON ecommerce.* TO 'visual_user'@'192.168.1.%' IDENTIFIED BY '123456';。
-
八、未来趋势与扩展方向
8.1 MySQL 8.0 的 JSON 功能与复杂可视化支持
MySQL 8.0 原生支持 JSON 字段,可存储非结构化数据(如用户行为埋点),结合 JSON 函数提取数据用于可视化:
sql
-- 从JSON字段提取用户行为数据
SELECT
user_id,
JSON_EXTRACT(behavior_data, '$.page') AS page,
JSON_EXTRACT(behavior_data, '$.click_count') AS click_count
FROM user_behavior;8.2 云数据库与可视化服务的协同
云数据库(AWS RDS、阿里云 RDS for MySQL)提供高可用、弹性扩展的存储能力,结合云原生可视化服务(如 AWS QuickSight、阿里云 DataV),可快速搭建云端可视化平台,无需本地部署。
8.3 AI 驱动的自动化可视化探索
结合 LLM(大语言模型)和 AutoViz 等工具,实现 "自然语言提问→MySQL 自动查询→自动生成可视化图表" 的全流程自动化,例如:
-
用户提问:"2024 年各品类销售额的环比增长率";
-
系统自动生成 SQL 查询 → 提取数据 → 选择最优图表(如柱状图 + 折线图) → 渲染展示。
总结
核心要点回顾
-
数据准备是基础:通过 MySQL 的 SQL 查询、临时表 / 视图、数据清洗技巧,为可视化提供高质量数据源;
-
工具选择看场景:业务人员用 Tableau/Power BI,开发人员用 Python/Seaborn,轻量需求用 Excel;
-
性能优化是关键:索引、分区表、缓存可解决大数据可视化的性能瓶颈,存储过程可自动化预处理;
-
实战落地靠工程化:Superset 可搭建动态仪表盘,结合 Airflow/Crontab 实现数据定时更新。
MySQL 与数据可视化的结合,核心是 "让数据从存储层高效流转到展示层"。掌握本文的方法,你可以从简单的报表制作,逐步进阶到企业级的实时数据仪表盘搭建,真正让 MySQL 的数据价值通过可视化呈现出来。
推荐资源:
注意: 生产环境中请务必考虑数据安全、性能监控和成本优化,建议在专业DBA和架构师的指导下实施。
MySQL 与数据可视化的结合,核心是 "让数据从存储层高效流转到展示层"。掌握本文的方法,你可以从简单的报表制作,逐步进阶到企业级的实时数据仪表盘搭建,真正让 MySQL 的数据价值通过可视化呈现出来。