目录
[第一部分:GraphRAG 基础认知](#第一部分:GraphRAG 基础认知)
[1.1 什么是 GraphRAG?](#1.1 什么是 GraphRAG?)
[1.2 GraphRAG vs 传统 RAG:关键差异对比](#1.2 GraphRAG vs 传统 RAG:关键差异对比)
[1.3 Microsoft GraphRAG 核心优势](#1.3 Microsoft GraphRAG 核心优势)
[第二部分:GraphRAG 核心技术原理](#第二部分:GraphRAG 核心技术原理)
[2.1 GraphRAG 整体架构拆解](#2.1 GraphRAG 整体架构拆解)
[2.2 Microsoft GraphRAG 技术特性深化](#2.2 Microsoft GraphRAG 技术特性深化)
[第三部分:Microsoft GraphRAG 入门](#第三部分:Microsoft GraphRAG 入门)
[3.1 本地安装 GraphRAG(环境准备)](#3.1 本地安装 GraphRAG(环境准备))
[3.2 初始化配置(项目搭建)](#3.2 初始化配置(项目搭建))
[3.3 核心配置修改](#3.3 核心配置修改)
[3.4 执行索引构建](#3.4 执行索引构建)
[3.5 源码安装及构建索引](#3.5 源码安装及构建索引)
[第四部分:GraphRAG 技术演进与展望](#第四部分:GraphRAG 技术演进与展望)
[4.1 技术局限与核心挑战](#4.1 技术局限与核心挑战)
[4.2 未来核心发展方向](#4.2 未来核心发展方向)
前言:为什么 GraphRAG 是下一代智能检索的核心?
在大模型应用落地过程中,RAG 已成为解决如何与私域数据交互的核心方案,但传统RAG面临三大核心局限:
-
信息碎片化
分块割裂原文逻辑,形成"信息孤岛",无法保持知识的整体关联。
-
多跳推理能力弱
难以串联分散在多处的知识点,对需要多步逻辑推理的复杂查询准确率低。
-
缺乏全局视角
仅依赖局部文本匹配,无法洞察文档集的整体结构、趋势与深层模式。
GraphRAG的核心突破在于融合知识图谱的结构化能力与RAG的检索生成能力 ,以支持多跳推理 并增强可解释性。
Microsoft GraphRAG作为代表性方案,其核心优势有三点:
-
自动化知识图谱构建
-
工程化部署流程
-
双模式查询引擎
第一部分:GraphRAG 基础认知
1.1 什么是 GraphRAG?
GraphRAG 是一种基于知识图谱的RAG架构 。其核心是将非结构化文本先转换为**"实体-关系-属性"结构化图谱**,再基于图谱的逻辑关联进行检索与回答。
三大核心特性:
-
结构化表示 :将文本提炼为(实体,关系,属性)三元组,显式呈现知识网络。
-
动态子图检索:针对查询,按需提取相关实体及其关联路径,精准过滤信息。
-
可解释性增强:答案可溯源至图谱中的具体关系,实现透明推理。
典型应用场景:
- 长文档问答:处理数百页的企业年报、技术手册,精准回答跨章节关联问题;
- 知识图谱自动构建:从非结构化文本中批量抽取实体关系,快速搭建领域图谱;
- 企业数据洞察:整合 CRM、ERP 等多源数据,分析客户关系、业务流程关联;
- 智能客服:理解用户复杂诉求(如 "我的订单 A 的退款何时到账,该订单关联的优惠券能否复用"),提供精准解答。
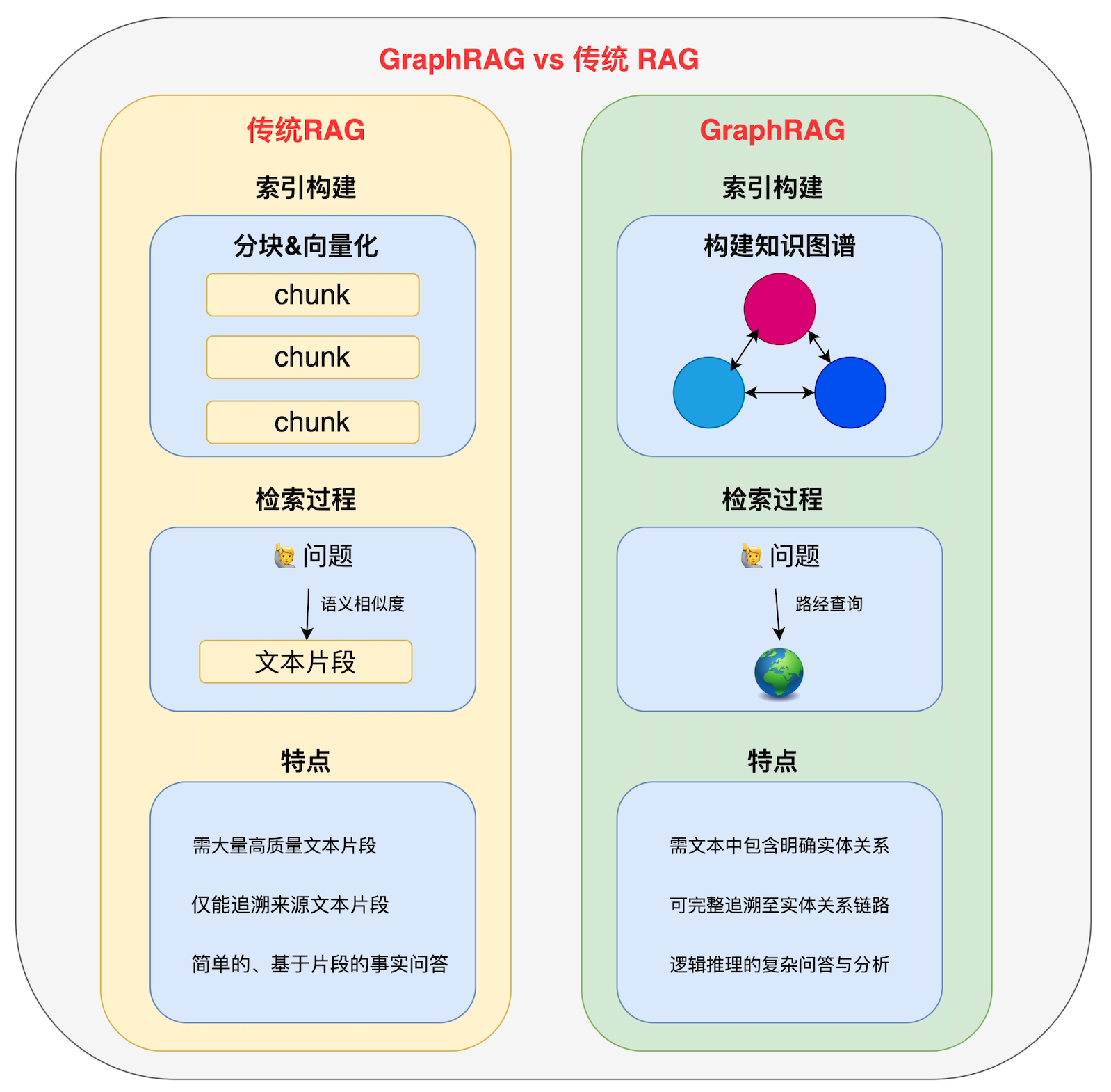
1.2 GraphRAG vs 传统 RAG:关键差异对比
如果说传统RAG是展现孤立地标的平面地图,那么GraphRAG就是揭示其间所有联系通道的立体沙盘。
1.3 Microsoft GraphRAG 核心优势
Microsoft GraphRAG 是微软开源的 GraphRAG 实现(https://github.com/microsoft/graphrag),相比社区其他版本,其核心优势在于卓越的工程化落地能力,具体体现为:
-
自动化构建:利用LLM自动从文档中抽取并构建知识图谱,无需人工标注。
-
智能组织:通过Leiden算法将实体聚类为层次化社区,实现"微观→宏观"的多粒度知识管理。
-
灵活检索 :提供局部查询 (精准事实)与全局查询(主题洞察)的双模式引擎。
-
开箱即用:提供完整的CLI工具链与SDK,支持从数据处理到生产部署的全流程,大幅降低应用门槛。

第二部分:GraphRAG 核心技术原理
2.1 GraphRAG 整体架构拆解
GraphRAG的核心架构是一个将文本结构化为知识 ,再基于知识进行回答的双阶段精准流程
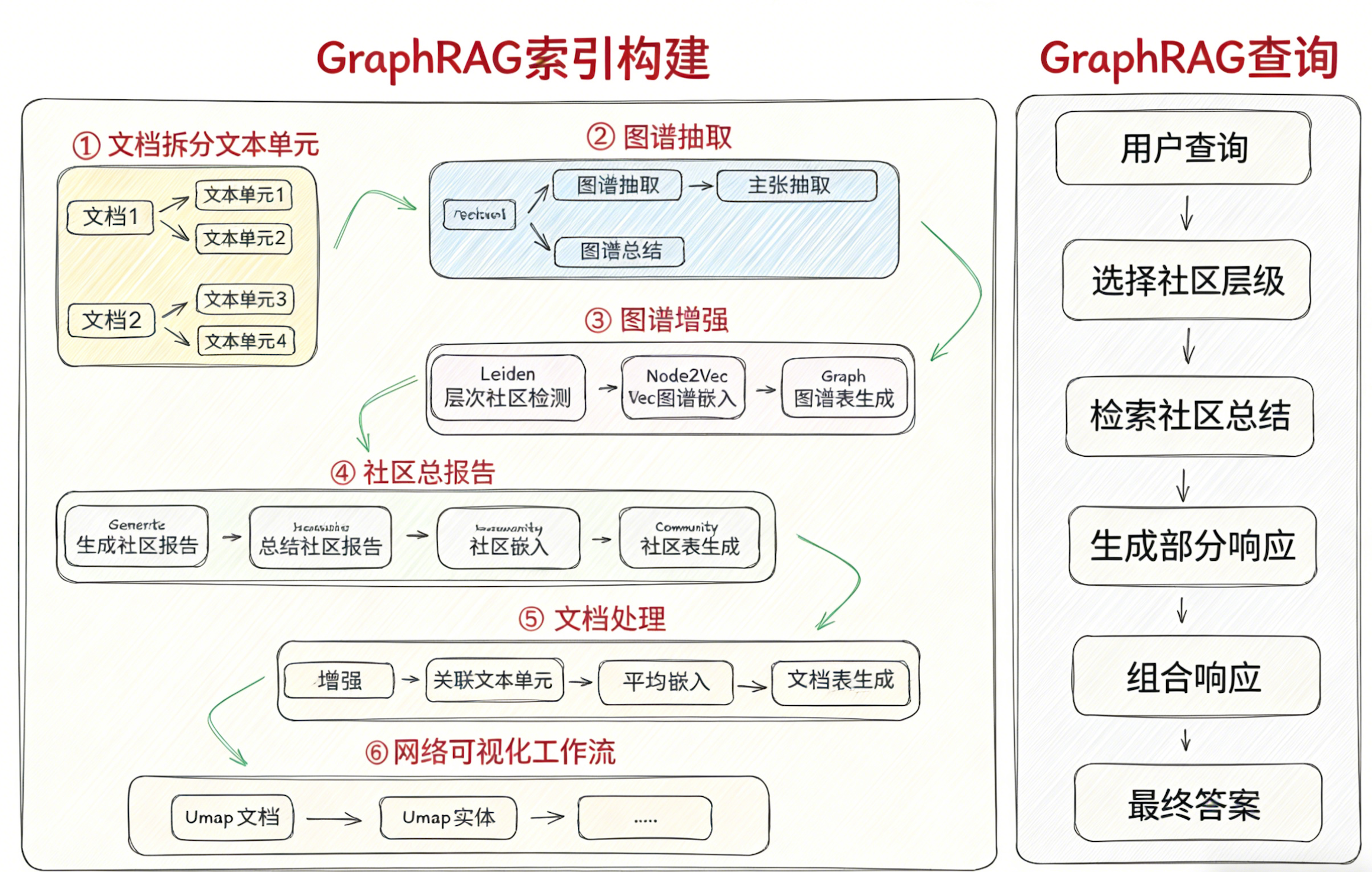
索引构建: 将非结构化文档转化为可计算的知识网络
-
文档拆分:将文档拆分为语义连贯的文本单元
-
图谱抽取 :用LLM从文本中提取(实体、关系、属性)三元组
3.图谱构建与社区发现 :将三元组形成初始的知识图谱,用Leiden算法将实体聚类,形成层次化社区
- 摘要与向量化 :为每个社区生成概括其核心主题的文本摘要, 并将实体、社区、原始文本块 编码成**向量,**构建向量混合索引
查询引擎: 识别查询意图,在知识网络中导航并合成答案
- 本地搜索路径:针对具体事实查询,定位实体并提取相关子图,召回关联文本。
2.全局搜索路径 :针对宏观主题查询,筛选相关社区并在各个社区内进行类似于"本地搜索"的检索(Map 阶段),再整合(Reduce 阶段)结果
核心价值 :此架构通过先建"知识地图"(图谱),再进行"按图索骥"(子图检索),从根本上解决了传统RAG的信息割裂问题,实现了多跳推理 与全局洞察。
2.2 Microsoft GraphRAG 技术特性深化
Microsoft GraphRAG 的核心可解释性通过一个清晰的 "三级追溯" 机制实现,使答案的生成过程完全透明:

-
回答结果 → 关联子图 :每个回答都可追溯到其直接依据------知识图谱中的关联子图(实体关系三元组)。这解释了答案的逻辑链条。
-
关联子图 → 社区摘要 :这些实体和关系可进一步追溯到它们所属的语义社区及其摘要。这揭示了答案背后的宏观主题与上下文。
-
社区摘要 → 原始文本 :最终,所有信息都能链接回抽取知识所用的原始文本片段。这确保了所有推理都根植于原文,实现了源头可查。
核心价值 :这一机制将传统RAG的"黑盒"检索转变为白盒推理,不仅增强了结果可信度,也为知识核查、系统调试与优化提供了完整路径。
第三部分:Microsoft GraphRAG 入门
3.1 本地安装 GraphRAG(环境准备)
GraphRAG 支持 Python 3.10+ 版本,完整安装流程如下:
前置条件检查
# 检查 Python 版本(需 ≥3.10)
python --version (macOS/Linux)虚拟环境搭建
# 创建虚拟环境(命名为 graphrag-env,可自定义)
python -m venv graphrag-env
# 激活虚拟环境(macOS/Linux 系统)
source graphrag-env/bin/activate核心库安装
# 安装 GraphRAG
pip install graphrag安装验证
# 查看已安装版本(确认安装成功)
pip show graphrag
# 查看命令行帮助
graphrag --help3.2 初始化配置(项目搭建)
初始化命令会自动生成 GraphRAG 运行所需的核心配置文件和目录结构,无需手动创建:
初始化命令执行
# 创建项目根目录
mkdir graphrag-demo && cd graphrag-demo
# 初始化配置文件(--root 指定项目根目录,./ 表示当前目录)
graphrag init --root ./生成文件 / 目录说明
执行成功后,项目根目录会生成以下内容,核心作用如下:
| 文件 / 目录 | 核心作用 |
|---|---|
settings.yaml |
主配置文件:包含 LLM 选型、索引参数、存储配置、查询规则等所有核心配置 |
.env |
环境变量文件:存储敏感信息(如 API 密钥),避免硬编码到配置文件中 |
prompts/ |
提示词文件夹:包含实体抽取、关系抽取、社区摘要等场景的默认提示词模板,支持自定义 |
3.3 核心配置修改
初始化后的默认配置需针对性调整,重点修改 settings.yaml 和 .env:
.env 文件:
# 主要用于存储 LLM API 密钥,对应 settings.yaml 中 ${GRAPHRAG_API_KEY} 的引用
GRAPHRAG_API_KEY=<API_KEY>settings.yaml文件:
|-----------------|------------------------------|
| 参数 | 描述 |
| api_base | 请求某个模型调用 REST API 的 Endpoint |
| api_key | 引用 .env 文件中的 GRAPHRA_API_KEY |
| encodeing_model | 设置编码模型 |
| model | 模型名称 |
3.4 执行索引构建
索引构建是将非结构化文档,转化为 知识图谱 + 向量索引 的核心过程:
数据准备:
# 创建待处理数据文档存放目录,将文档放入input目录下,目录名不可更改
mkdir input执行索引构建命令
# 进入项目根目录(graphrag-demo)
cd graphrag-demo
# 执行索引构建(--root 与初始化目录一致,自动读取 input 目录文档)
graphrag index --root ./构建过程
✅ load_input_documents - 加载文档
✅ create_base_text_units - 创建基础文本单元
✅ create_final_documents - 创建最终文档
✅ extract_graph - 提取图结构
✅ finalize_graph - 完成图构建
✅ extract_covariates - 提取协变量
✅ create_communities - 创建社区
✅ create_final_text_units - 创建最终文本单元
✅ create_community_reports - 创建社区报告
✅ generate_text_embeddings - 生成文本嵌入
🚀 ALL Workflows Completed Successfully构建结果验证
graphrag-demo/ # 项目根目录
├── .env # 环境变量配置
├── cache/ # 缓存数据
├── input/ # 原始输入文档
├── logs/ # 运行日志
├── output/ # 核心输出结果
│ ├── communities.parquet # 社区划分结果
│ ├── community_reports.parquet # 社区分析报告
│ ├── documents.parquet # 文档元数据
│ ├── entities.parquet # 实体信息
│ ├── lancedb/ # 向量数据库存储
│ ├── relationships.parquet # 实体关系数据
│ ├── stats.json # 运行统计数据
│ └── text_units.parquet # 文本块数据
├── prompts/ # 提示词模板
└── settings.yaml # 项目配置文件3.5 源码安装及构建索引
在源码启动的过程中,我们同样需要像入门案例中那样初始化配置及构建索引,大体流程基本一致,但执行的命令稍有不同
# 源码下载
git clone https://github.com/microsoft/graphrag.git
# 创建虚拟环境(命名为 graphrag-env,可自定义)
python -m venv graphrag-env
# 激活虚拟环境(macOS/Linux 系统)
source graphrag-env/bin/activate
# 安装 poetry ,根据 pyproject.toml 文件来管理项目的元数据和依赖
pip install poetry
# 安装 Microsoft GraphRAG 项目依赖
poetry install
# 初始化配置
poetry run poe init --root ./
# 修改配置同上
# 新建一个 input 文件夹 与 graphrag 同级目录 ,将数据文档放入
# 执行索引构建
poetry run poe index --root ./
# 在索引构建完成后,graphrag 同级目录下能看到 cache、logs 和 output 三个文件夹,分别存储了构建索引过程中的缓存文件、日志文件和输出文件。第四部分:GraphRAG 技术演进与展望
4.1 技术局限与核心挑战
- 大规模数据性能瓶颈:文档量超 10 万页时,图谱构建耗时超 24 小时,查询响应延迟超 5 秒,难以支撑超大规模场景;
- 低资源领域抽取精度不足:开源模型在医疗、法律等专业领域的实体 / 关系抽取准确率低于 70%,依赖大量领域数据微调;
- 垂直领域适配成本高:默认 Prompt 与算法适配通用场景,工业物联网等垂直领域需大量自定义开发;
- 缺乏实时更新能力:不支持图谱增量更新,新增文档需全量重建索引,无法满足动态数据需求。
4.2 未来核心发展方向
- 多模态融合:整合文本、图像、语音等多模态数据,构建多模态知识图谱;
- 实时增量更新:基于 Kafka、Flink 等流处理框架,实现图谱与向量索引的实时增量更新;
- Agent 协同赋能:作为智能体结构化记忆库,支撑复杂任务闭环执行;
- 轻量化部署:优化模型与算法,推出边缘端版本,满足数据隐私需求;
- 领域自适应优化:通过少样本学习降低垂直领域适配成本,提升通用性。
结语:技术落地与价值核心
GraphRAG 的核心价值在于解决实际业务问题,Microsoft GraphRAG 通过工程化封装实现低代码部署,让企业快速搭建高准确率、可解释的智能检索系统。
未来,随着多模态、实时更新、Agent 协同等技术演进,GraphRAG 将从 "智能检索工具" 升级为 "企业级知识中枢",成为大模型应用落地的核心基础设施。