(一).二叉搜索树
1.概念
二叉搜索树又称为二叉排序树,或许是一颗空树,是一种特殊的二叉树。
2.性质
(1).若它的左子树不为空,则左子树上所有节点的值都小于根节点的值。
(2).若它的右子树不为空,则右子树上所有节点的值都小于根节点的值。
(3).它的左右子树也分别为二叉搜索树。
二叉搜索树的这些性质当在进行数据检测,排序等算法中具有高效性,尤其是在需要频繁查找,删除,插入数据的场景中,二叉搜索树的效率高于其他数据结构,类似于二分查找。
3.模拟实现二叉搜索树
(1).初始化
首先要明确,二叉搜索树也是由一个一个的节点组成的,所以我们可以创建一个静态内部类,然后定义一个节点为根节点
java
public class BinaryTree {
static class Node{
public int val;
public Node left;
public Node right;
public Node(int val) {
this.val = val;
}
}
public Node root;
}(2).查找
二叉搜索树的查找类似于二分查找,当根节点的值大于要找的数值时,则去根的左子树找,当根节点的值小于要找的数值时,则取根的右子树找。
java
public Node search(int value){
Node cur=root;
while (cur!=null){
if (cur.val>value){
cur=cur.left;
}else if (cur.val==value){
return cur;
}else{
cur=cur.right;
}
}
return null;
}时间复杂度:最好的情况,O(logN),类似于完全二叉树
最坏的情况,O(N),单分支的树
针对于最坏的情况,二叉搜索树进化成了AVL树,会检测树的高度
当创建的单分支的树为 1
\
2
\
3
AVL树检测的高度过高,会对二叉树进行旋转,变成 2
/ \
1 3
树的高度降低了,查找的效率就提高了
AVL树也叫做高度平衡的二叉搜索树(左右子树的高度不能超过1)
(3).插入
首先明确一点,二叉搜索树中不能有两个相同的数据,这也好理解,因为如果有两个相同的数据,那么当二叉搜索树在搜索值的过程中就会出现问题。
二叉搜索树在插入的过程中,其实和二叉搜索树的 "查找" 相类似,当要插入的value值比根节点的值大的时候,则需要插入到根节点的右树,当要插入的value值比根节点的值小的时候,则需要插入到根节点的左树。
java
public void insert(int value){
//如果树为空,新节点直接作为根节点
if (root==null){
root=new Node(value);
return;
}
//初始化指针,prev记录父亲节点,cur用于遍历找插入的位置
Node prev=null;
Node cur=root;
//找到待插入节点的父亲节点
while (cur!=null){
//目标值更小,往左子树找
if (cur.val>value){
prev=cur;
cur=cur.left;
}else{ //目标值更大,往右子树找
prev=cur;
cur=cur.right;
}
}
//根据值的大小,将新节点挂载到父节点的左/右子树
if (prev.val>value){
prev.left=new Node(value);
}else{
prev.right=new Node(value);
}
}(4).删除
首先我们要明确
第一点,要先找到要删除的节点
第二点,找到要删除的节点后,有三种情况
i.当要删除的节点的左子树为空
ii.当要删除的节点的右子树为空
iii.当要删除的节点的左子树和右子树都不为空
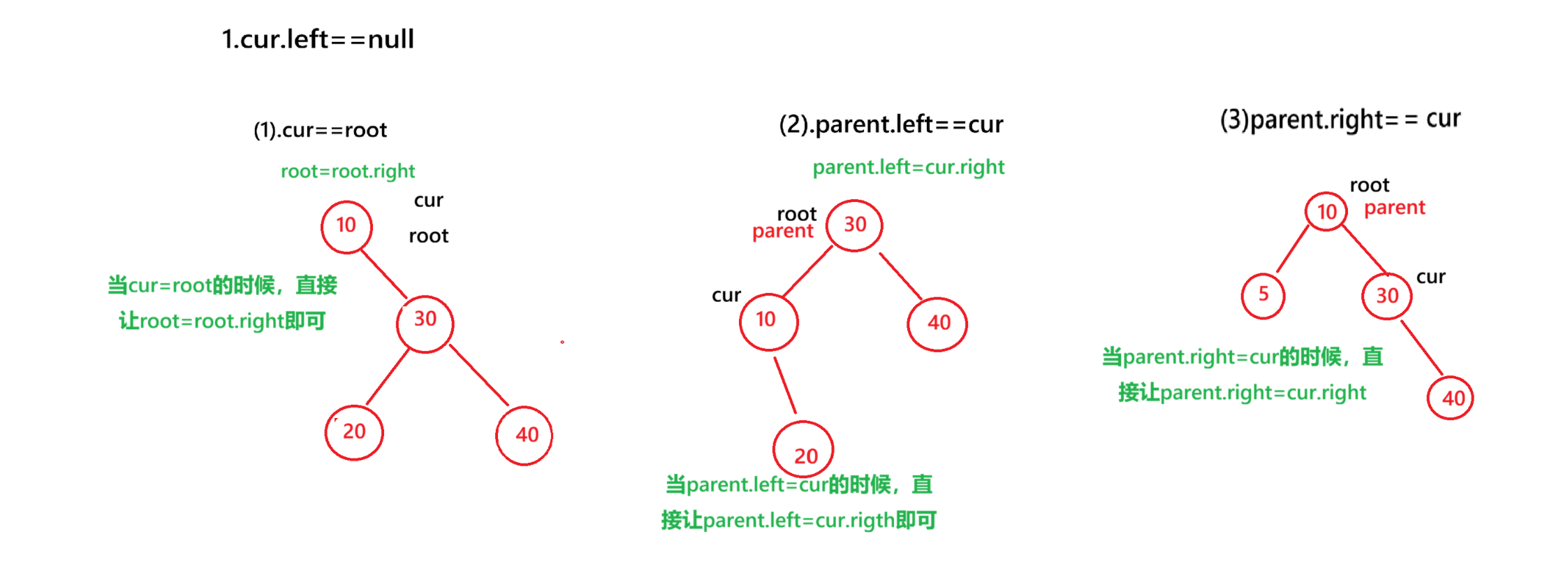
i.当要删除的节点的左子树为空
当要删除的节点的左子树为空的时候,又分为三种情况
1.当要删除的节点恰好是root节点
由于要删除的节点cur==root,同时cur.left=null,所以直接让root=root.right
2.当要删除的节点恰好是其父亲节点的左节点
直接让parent.left=cur.right
3.当要删除的节点恰好时其父亲节点的右节点
直接让parent.right=cur.right
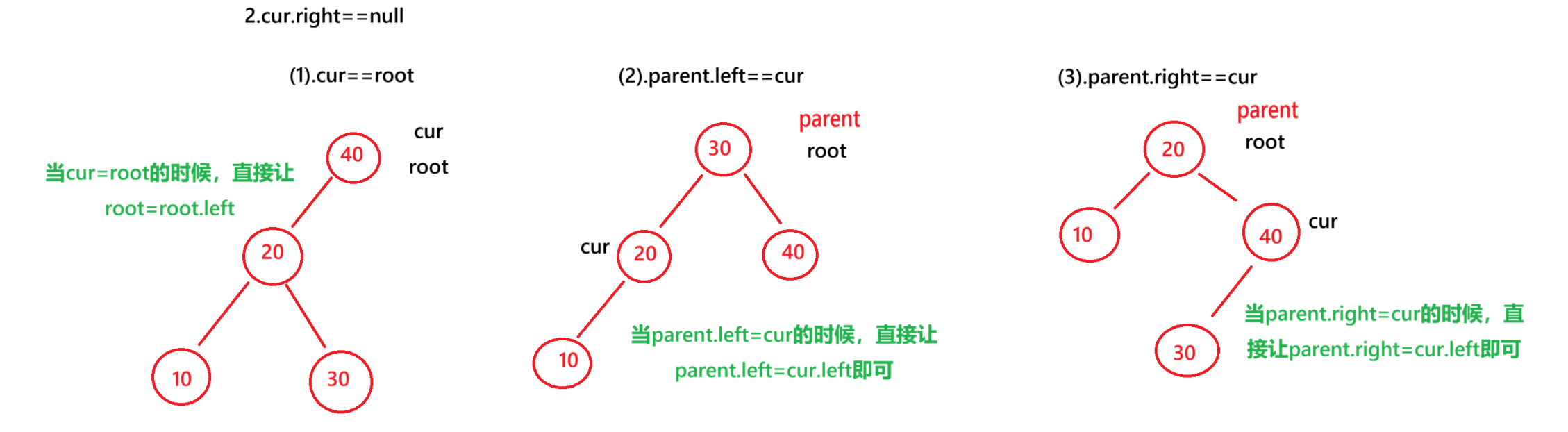
ii.当要删除的节点的右子树为空
当要删除的节点的右子树为空的时候,又分为三种情况
1.当要删除的节点恰好是root节点
由于要删除的节点cur=root,然后cur.right=null,所以直接让root=root.left
2.当要删除的节点恰好是其父亲节点的左子树
直接让parent.left=cur.left
3.当要删除的节点恰好是其父亲节点的右子树
直接让parent.right=cur.left
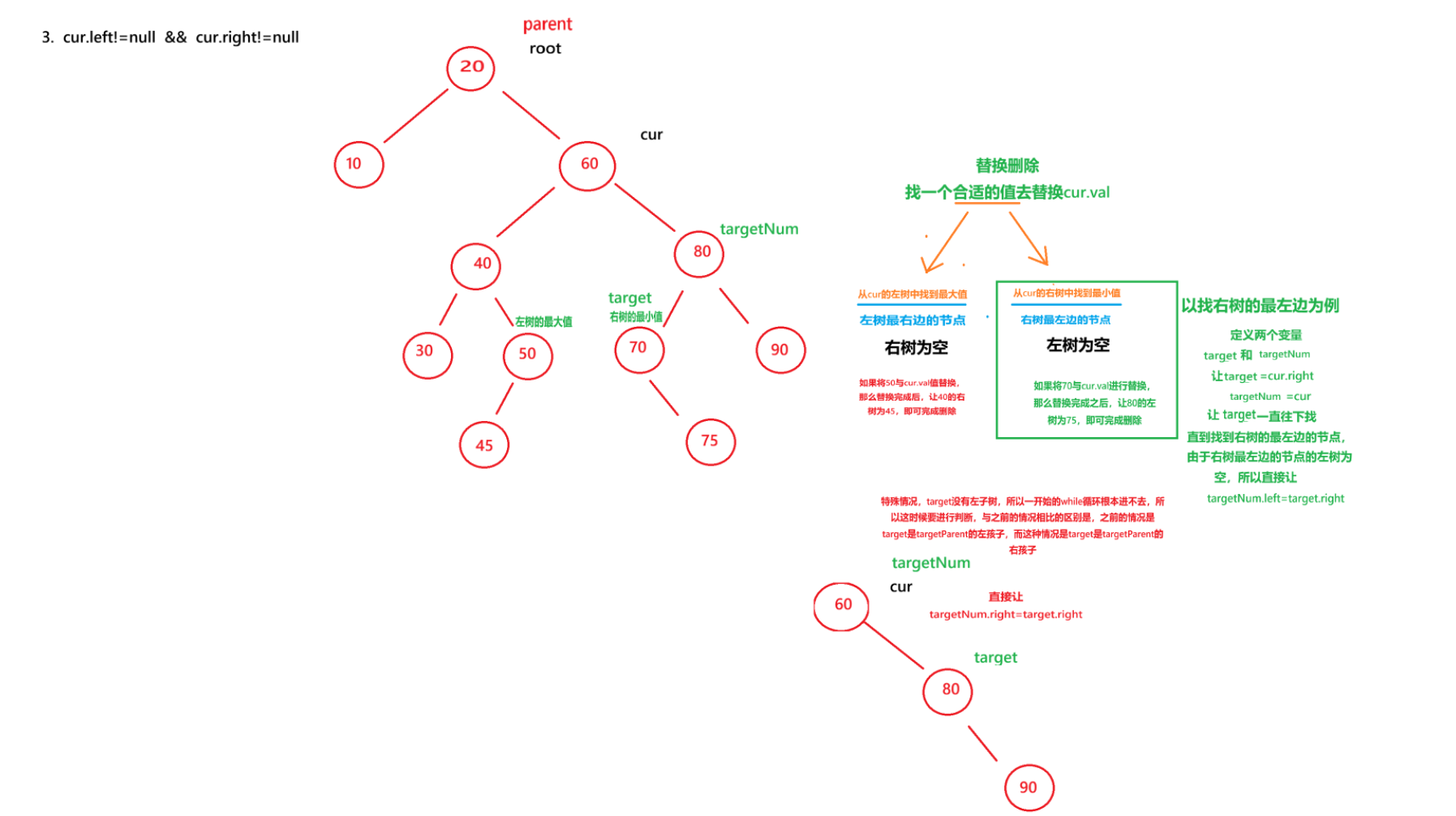
iii.当要删除的节点的左子树和右子树都不为空
当为这种情况的时候,删除是比较麻烦的,通常我们采用的是替换删除法
我们会在要删除节点的子树中找一个合适的节点,然后将这个合适的节点与要删除的节点进行替换,替换完成后,我们要将这个合适的节点进行删除
如何去找这个合适的节点?
有两种方案,第一种是在要删除的节点的左树中找最大值,第二种是在要删除的节点的右树中找最小值
左树中的最大值节点就是左树最右边的节点,这个节点的右子树一定为空,如果这个节点的右子树不为空,则这个节点就不是左树中最右边的节点。
右树中的最小值节点就是右树最左边的节点,这个节点的左子树一定为空,如果这个节点的左子树不为空,则这个节点就不是右树中最左边的节点。
这里我们拿第二种方案来进行举例,即找右树中的最小值
我们可以实例化两个Node类型的变量,target 和 targetNum ,让targetNum=cur,让target=cur.right (在cur的右树中找最小值,所以target=cur.right),
然后执行循环,只要target.left != null,那么循环就一直循环,targetNum=target,然后target = target.left。
当循环停止的时候,此时target就是右树中的最小值节点,targetNumt就表示target的父亲节点
然后让cur.val=target.val,此时就将值给替换过来了
下面要做的就是要将target值给删除,由于target是右树中的最小值,所以target肯定没有左子树,所以直接让targetNum.left=target.right即可
但是这个地方有问题
当targetNum.left为空的时候,循环根本就进不去,然后执行 targetNum.left=target.right 的时候,就会出现空指针异常,所以我们要进行判断,判断 targetNum.right==target,如果成立,则我们需要将targetNum.right=target.right
java
public void remove(int value){
//首先先要找到要删除的节点
Node parent=null;
Node cur=root;
while (cur!=null){
if (cur.val>value){
parent=cur;
cur=cur.left;
}else if (cur.val<value){
parent=cur;
cur=cur.right;
}else{
//程序走到这,说明已经找到要删除的节点了
remove(parent,cur);
return;
}
}
}
private void remove(Node parent, Node cur) {
//分为三种情况,cur的左子树为空,cur的右子树为空,cur的左右子树都不为空
if (cur.left==null){ //cur的左边为空的情况
if (cur==root){
root=root.right;
}else if (parent.left==cur){
parent.left=cur.right;
}else{
parent.right=cur.right;
}
}else if (cur.right==null){ //cur的右边为空的情况
if (cur==root){
root=root.left;
}else if (parent.left==cur){
parent.left=cur.left;
}else{
parent.right=cur.left;
}
}else { //cur左右都不为空的情况
//替换删除
//首先,先找到要被替换的节点
Node targetNum=cur;
Node target=cur.right;
while (target.left!=null){
targetNum=target;
target=target.left;
}
//此时已经找到要被替换的节点了
//让cur.val=target.val
cur.val=target.val;
//然后将target这个节点删除
if (targetNum.right==target){
targetNum.right=target.right;
}else{
targetNum.left=target.right;
}
}
}(二).Map和Set
1.概念
Map和Set是一种专门用来进行搜索的容器或者数据结构,其搜索效率与其具体的实例化子类有关。
以前常见的搜索方式有:1.直接遍历 ,时间复杂度为O(N)2.二分查找,时间复杂度为O(logN),前提是必须要求是有序的
上述的排序比较适合静态类型的查找,即一般不会对区间进行插入和删除操作了,而现实中的查找比如:
1.根据姓名查询考试成绩
2.通讯录,根据姓名查询联系方式
3.不重复集合,即需要先搜索关键字是否已经在集合中
这些可能在查找时进行一些插入和删除的操作,即动态查找,所以引入了Map和Set
2.模型
一般把搜索的数据称为关键字(Key),和关键字对应的称为值(Value),将其称为Key-Value的键值对,所以模型有两种:
(1).纯Key模型
比如,在一个英文词典中,快速查找一个单词是否在词典中
(2).Key-Value模型
比如,统计文件中每个单词出现的次数,统计结果是每个单词都有与其对应的次数:<单词,单词出现的次数>
Map存储的就是Key-Value的键值对,Set中只存储了Key
3.Map
(1).概念
Map是一个接口类,该类没有继承自Collection,该类中存储的是<K,V>结构的键值对,并且K一定是唯一的,不能重复。
(2).关于Map.Entry<K,V>的说明
Map.Entry<K,V>是Map内部实现的用来存放<Key,Value>键值对映射关系的内部类,该内部类中主要提供了<Key,Value>的获取,Value的设置以及Key的比较方式。
|--------------|-----------------------|
| 方法 | 解释 |
| K getKey() | 返回entry中的Key |
| V getValue() | 返回entry中的Value |
| V setValue() | 将键值对中的Value替换为指定Value |
(3).Map的常用方法说明
|-------------------------------------------|-------------------------------------|
| 方法 | 解释 |
| V get(Object key) | 返回key对应的value值 |
| V getOrDefault(Object key,V defaultValue) | 返回key对应的value,key不存在,返回defaultValue |
| V put(K key,V value) | 设置key对应的value |
| V remove(Object key) | 删除key对应的映射关系 |
| Set<K> keySet() | 返回所有key的不重复集合 |
| Collection<V> values() | 返回所有value的可重复集合 |
| Set<Map.Entry<K,V>> entrySet() | 返回所有的 key-value 的映射关系 |
| boolean containsKey(Object key) | 判断是否包含key |
| boolean containsValue(Object value) | 判断是否包含value |
注意:
1**.Map是一个接口,不能直接实例化对象,如果要实例化对象,只能实例化其实现类TreeMap或者HashMap**
2.Map中存放键值对的Key是唯一的,Value是可以重复的
3.在TreeMap中插入键值对时,key不能为空,否则会抛出空指针异常
4.Map中的Key可以全部分离出来,存储到Set中
5.Map中的value可以分离出来,存储在Collection的任何一个子集合中(value可能有重复)
6.Map中键值对的Key不能直接修改,value可以修改,如果要修改key,只能先将key删除掉,然后在进行重新插入
7.TreeMap和HashMap的区别
|---------------|-------------------------------------|----------------------------|
| Map底层结构 | TreeMap | HashMap |
| 底层结构 | 红黑树 | 哈希桶 |
| 插入/删除/查找时间复杂度 | O(logN) | O(N) |
| 是否有序 | 关于Key有序 | 无序 |
| 线程安全 | 不安全 | 不安全 |
| 插入/删除/查找区别 | 需要进行元素比较 | 通过哈希函数计算哈希地址 |
| 比较与复写 | key必须能够比较,否则会抛出ClassCastException异常 | 自定义类型需要覆写equals和hashCode方法 |
| 应用场景 | 需要Key有序场景下 | Key是否有序不关心,需要更高的时间性能 |
4.Set
(1).概念
Set和Map主要的不同有两点:Set是继承自Collection的接口类,Set中只存储了Key
(2).常见方法说明
|----------------------------------------------|--------------------------------------|
| 方法 | 解释 |
| boolean add(E e) | 添加元素,但重复的元素不会被添加成功 |
| void clear() | 清空集合 |
| boolean contains(Object o) | 判断o是否在集合中 |
| Iterator <E> iterator() | 返回迭代器 |
| boolean remove(Object o) | 删除集合中的o |
| int size() | 返回set中元素的个数 |
| boolean isEmpty() | 检测set是否为空,空返回true,否则返回false |
| Object\[\] toArray() | 将set中的元素转换为数组返回 |
| boolean containsAll(Collection<?> c) | 集合c中的元素是否在set中全部存在,是返回true,否则返回false |
| boolean addAll(Collection <? extends E> c) | 将集合c中的全部元素添加到set中,可以达到去重的效果 |
注意:
1.Set是继承自Collection的一个接口类
2.Set中只存储了key,并且要求key一定要唯一
3.TreeSet的底层是使用Map来实现的,其使用key与Object的一个默认对象作为键值对插入到Map中
4.Set最大的功能就是对集合中的元素进行去重
5.实现Set接口的常用类有TreeSet和HashSet,还有一个LinkedHashSet,LinkedHashSet是在HashSet的基础上维护了一个双向链表来记录元素的插入次序
6.Set中的Key不能修改,如果要修改,只能先将原来的删除,然后再重新插入
7.TreeSet中不能插入null的key,HashSet可以,因为null无法进行比较
8.TreeSet和HashSet的区别
|---------------|-------------------------------------|----------------------------|
| Set底层结构 | TreeSet | HashSet |
| 底层结构 | 红黑树 | 哈希桶 |
| 插入/删除/查找时间复杂度 | O(logN) | O(1) |
| 是否有序 | 关于key有序 | 不一定有序 |
| 线程安全 | 不安全 | 不安全 |
| 插入/删除/查找区别 | 按照红黑树的特性来进行插入和删除 | 先计算key哈希地址,然后进行插入和删除 |
| 比较与覆写 | key必须能够比较,否则会抛出ClassCastException异常 | 自定义类型需要覆写equals和hashCode方法 |
| 应用场景 | 需要key有序场景下 | key是否有序不关心,需要更高的时间性能 |
(三).哈希表
1.概念
顺序结构以及平衡树中,元素关键码与其存储位置之间没有对应的关系,因此在查找一个元素时,必须要经过关键码的多次比较,顺序查找的时间复杂度为O(N),平衡树中为树的高度,即O(logN),搜索的效率取决于搜索过程中元素的比较次数。
在Java中,提供的哈希表是使用链地址法,也就是数组加链表,还有加红黑树,即哈希表=数组+链表+红黑树,java的哈希表一旦数组长度超过64,并且链表长度超过8,就会通过红黑树将链表进行树化调整为红黑树,保持哈希表优秀的性能。
理想的搜索方法:可以不经过任何比较,一次直接从表中得到要搜索的元素。如果构造一种存储结构,通过某种函数是元素的存储位置与它的关键码之间能够建立一 一映射的关系,那么在查找时通过该函数可以很快找到该元素。
当向该结构中:
插入元素:
根据插入元素的关键码,以此函数计算出该元素的存储位置并按此位置进行存放
搜索元素:
对元素的关键码进行同样的计算,把求得的函数值当作元素的存储位置,在结构中按此位置
取元素比较,若关键码相等,则搜索成功
该方式即为哈希(散列)方法,哈希方法中使用的转换函数称为哈希(散列)函数,构造出来的结构称为哈希表(HashTable)
例如:数据集合{1,4,6,7,9,2};
哈希函数设置为:hash(key) = key%capacity;
capacity为存储元素底层空间总的大小
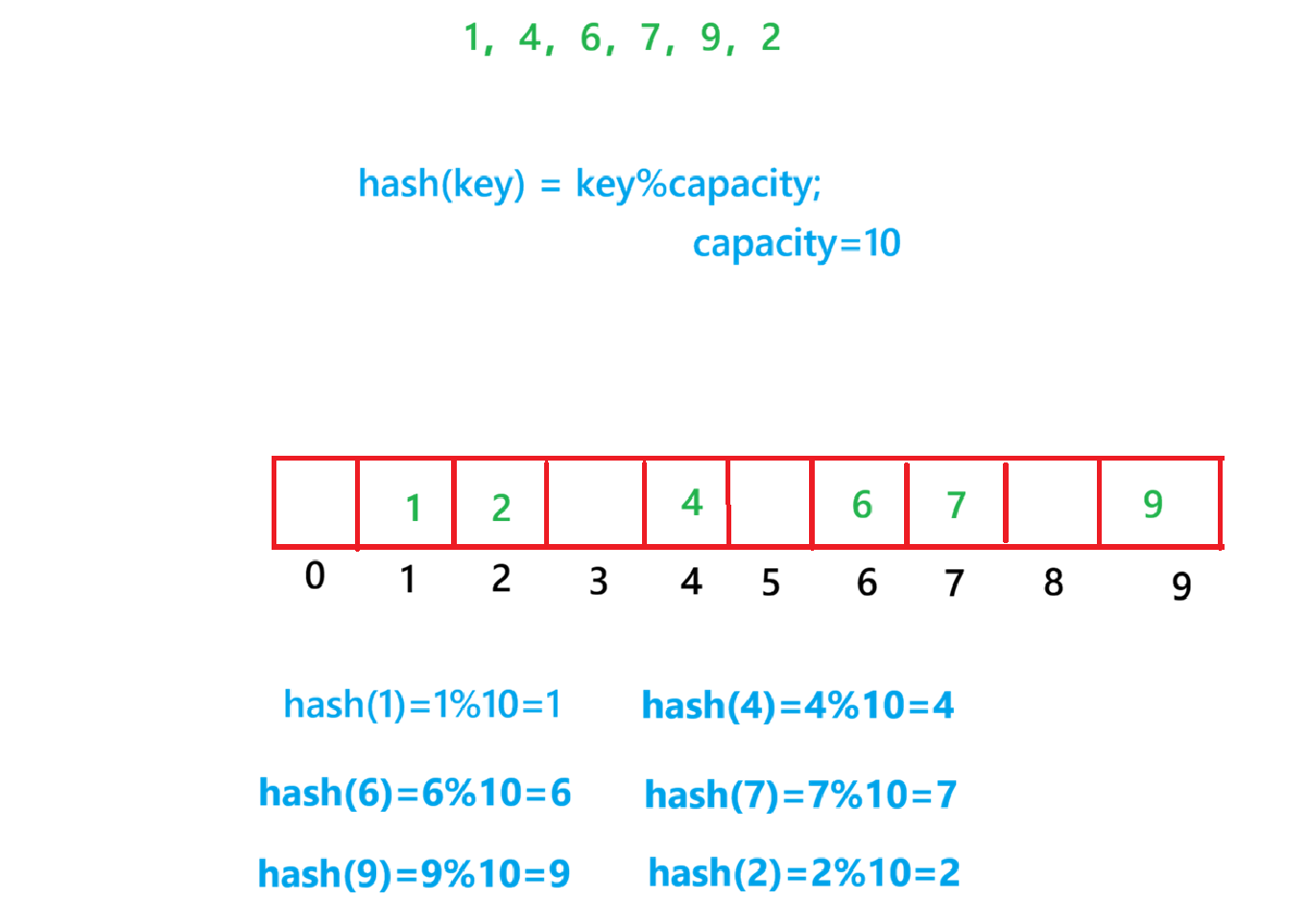
使用这种方法进行搜索不必进行多次关键码的比较,因此搜索的速度比较快
2.冲突
(1).概念
不同关键字通过相同哈希函数计算出相同的哈希地址,这种现象被称为哈希冲突或哈希碰撞。
例如:对于两个数据元素的关键字ki和kj( i != j ),有ki!=kj,但是Hash(ki) == Hash(kj)。
把具有不同关键码而具有哈希地址的数据元素称为"同义词"
(2).避免冲突
首先,明确一点,由于哈希表底层数组的容量往往是小于实际要存储的关键字的数量的,这就导致一个问题,冲突的发生是必然的 ,我们能做的就是尽量降低冲突率。
(3).设计哈希函数避免冲突
引起哈希冲突的一个原因可能是:哈希函数设计不够合理,哈希函数设计原则:
哈希函数的定义域必须包括需要存储的全部关键码,而如果散列表允许有m个地址时,其至于
必须在0到m-1之间
哈希函数计算出来的地址能均匀分布在整个空间中
哈希函数应该比较简单
常见哈希函数:
i.直接定制法--(常用)
取关键字的某个线性函数为散列地址:Hash(Key)=A*Key+B
优点:简单,均匀
缺点:需要事先知道关键字的分布情况
使用场景:适合查找比较小且连续的情况
ii.除留余数法--(常用)
设散列表中允许的地址数为m,取一个不大于m,但最接近或者等于m的质数p作
为除数按照哈希函数:Hash(key) =key % p (p<=m),将关键码转换成哈希地址
iii.平方取中法
假设关键字1234,对它平方就是1522756,抽取中间的3位227作为哈希地址;再
比如关键字为4321,对它平方就是18671041,抽取中间的3位671(或017)作为哈
希地址
使用场景:不知道关键字的分布,而位数又不是很大的情况
iv.折叠法
将关键字从左到右分割成位数相等的及部分(最后一部分位数可以短些),然后将这
几部分叠加求和,并按散列表表长,取后几位作为散列地址
使用场景:适合实现不需要知道关键字的分布,社和关键字位数比较多的情况
v.随机数法
选择一个随机函数,取关键字的随机函数值为它的哈希地址,即Hash(Key)=
random(key),其中random为随机数的函数
使用场景:通常应用于关键字长度不等时采用此法
vi.数学分析法
sheyoun个d位数,每一位可能有r种不同的符号,这r种不同的符号在各位上出现的
频率不一定相同,可能在某些位上分布比较均匀,每种符号出现的机会均等,在某
些位上分布不均匀只有某几种符号经常出现。可根据散列表的按大小,选择其中各
种符号分布不均匀的若干位作为散列地址。
使用场景:社和处理关键字位数比较大的情况,如果事先知道关键字的分布且关键
字的若干位分布较均匀的情况
注意:哈希函数设计的越精妙,产生哈希冲突的可能性就越低,但是无法避免哈希冲突。
(4).通过负载因子来避免冲突

负载因子和冲突率的关系粗略演示
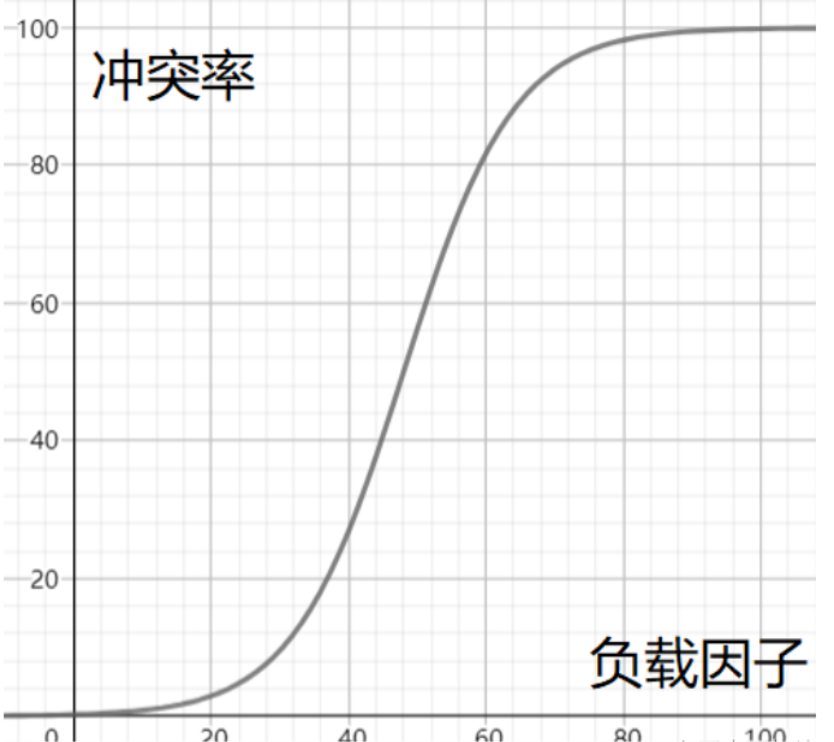
通过上面的图片可以看出来,当负载因子越大,冲突率就越高,而负载因子的大小又与填入表中的元素个数有关,所以我们能改变的就是哈希表中数组的大小,当逼近负载因子或者等于负载因子,此时要赶紧进行扩容
在Java的hash库中,负载因子被定义在0.75,一旦超过这个数值,就要对哈希表进行扩容
(5).解决冲突
解决冲突的方法有两种:闭散列和开散列
1.闭散列
**闭散列也叫开放地址法,当发生哈希冲突时,如果哈希表未被填满,说明哈希表中还有空位置,那么可以把key存放到冲突位置种的"下一个"空位置中去。**如何寻找 "下一个空位置" ?
i.线性探测
当我要在上图中插入12的时候,先通过哈希函数计算哈希地址,下标为2,因此44理论上应该插在该位置,但是该位置已经放了值为2的元素,即发生哈希冲突。
线性探测:从发生冲突的位置开始,依次向后探测,知道寻找到下一个空位置为止。
插入:
通过哈希函数获取待插入元素在哈希表中的位置
如果该位置中没有元素则直接插入新元素,如果该位置中有元素发生哈希冲突,使用线
性探测找到下一个空位置,插入新元素
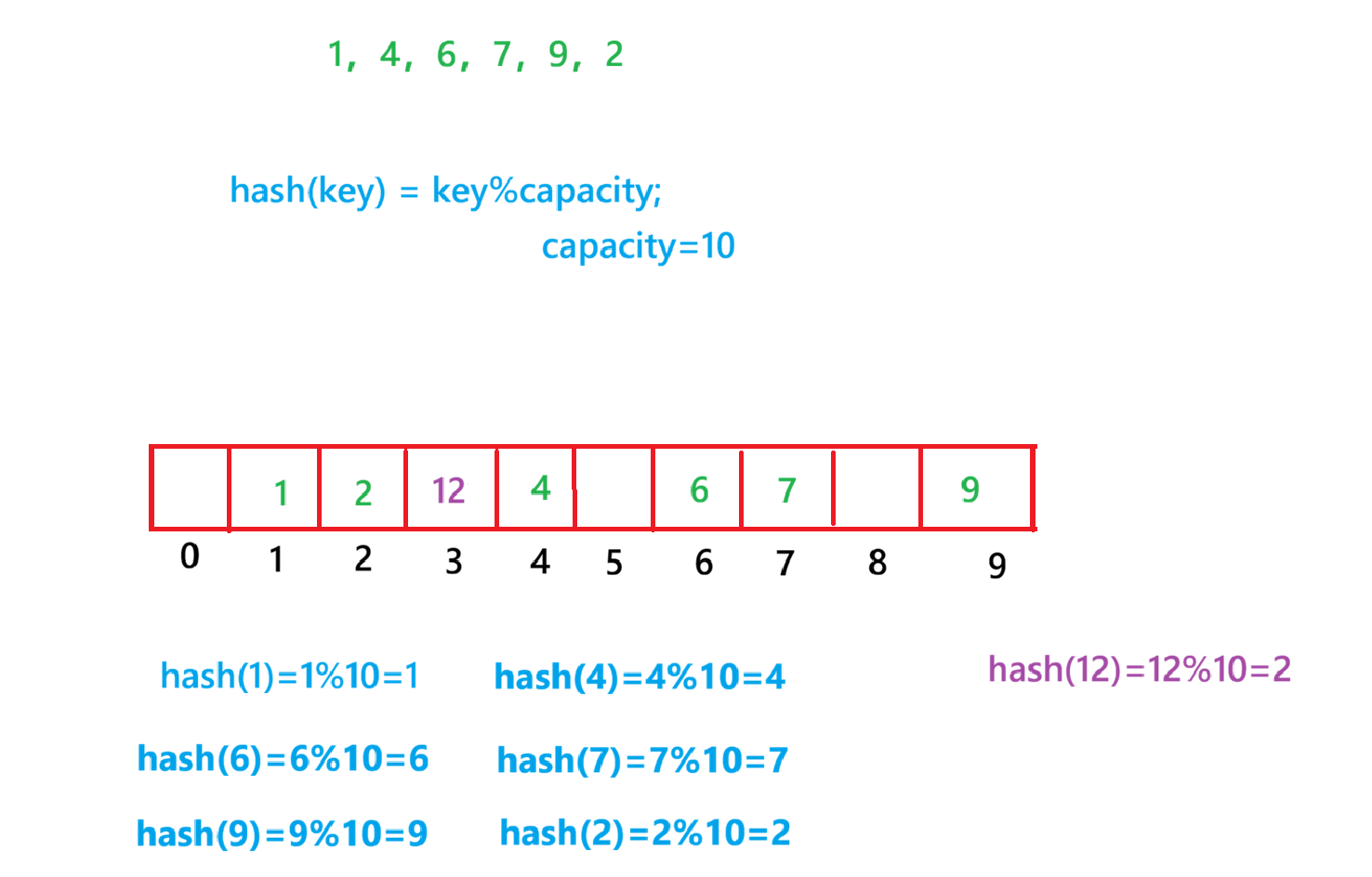
采用闭散列处理哈希冲突时,不能随便物理删除哈希表中已有的元素,若直接删除元素
会影响其他元素的搜索。例如,删除元素2,如果直接删除掉,12查找起来可能会受影
响。因此线性探测采用标记的尾删除法来删除一个元素
线性探测的缺陷就是产生冲突的数据堆积在一起,这与其找下一个空位置有关系,因为找空位置的方式就是挨着往后逐个去找
ii.二次探测
二次探测为了避免线性探测长生冲突的数据堆积在一块的问题,二次探测找下一个空位置的方法为:Hi = (H0 + i^2)%m,或者:Hi = (H0 + i^2)%m。其中,i=1,2,3,4······,H0是通过散列函数Hash(x)对元素的关键码 key 进行计算得到的位置,m是表的大小
当要插入12的时候,首先先计算hash(12)=12%10=2,由于下标2的位置已经放入数据了,所以发生了第一次哈希冲突,所以i从0变成1,然后进行二次探测 H1=(2+1^2)%10=3,发现3的位置为空,所以插入12
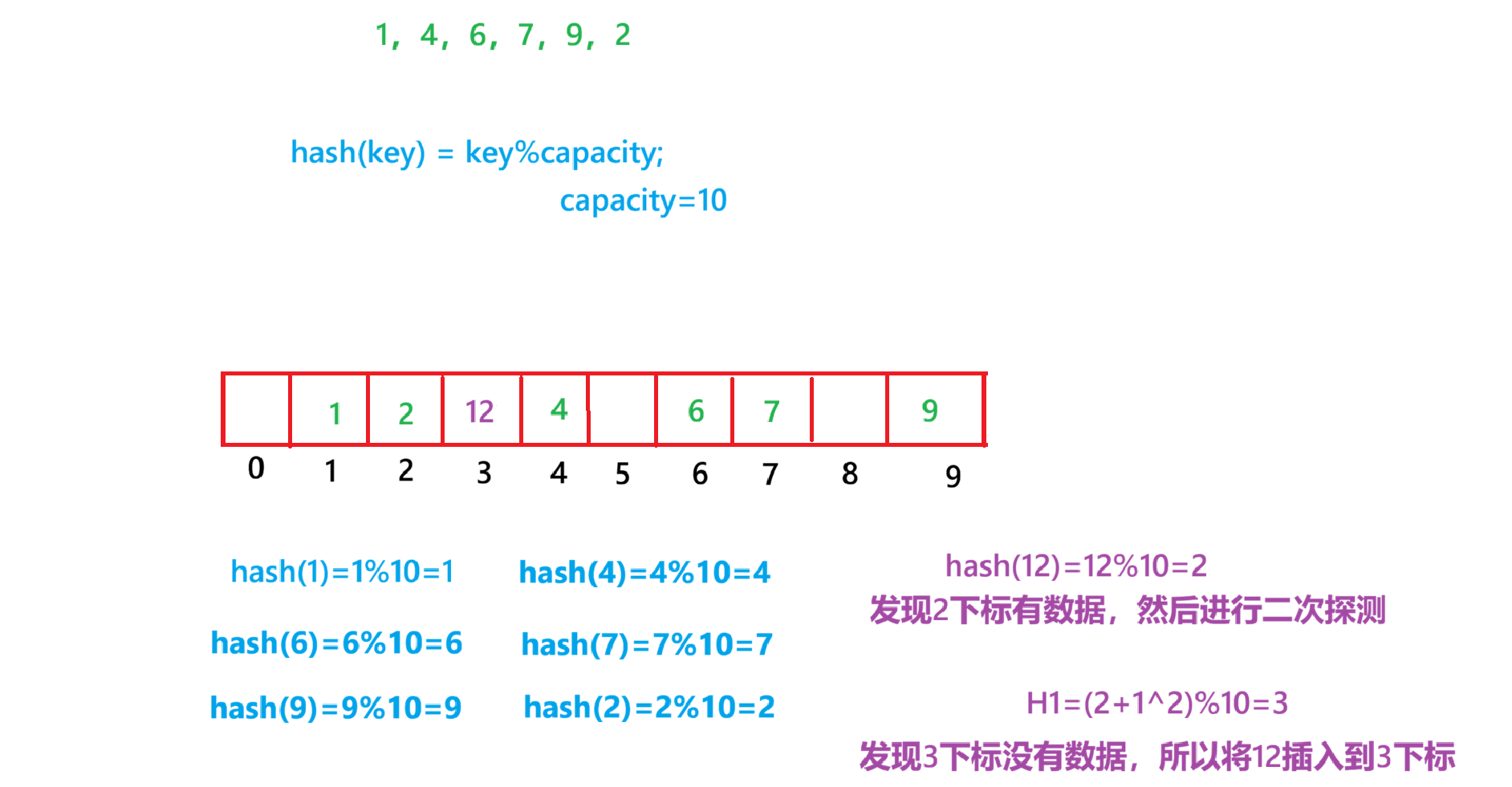
研究表明:当表的长度为质数且表装在因子a不超过0.5时,新的表项一定能够插入,而且任何一个位置都不会被探查两次。因此只要表中有一半的空位置,就不会存在表满的问题。在搜索时可以不考虑表装满的情况,但是在插入时必须确保表的装载因子a不超过0.5,如果超出必须考虑扩容。
因此:闭散列最大的缺陷就是空间利用率比较低,这也是哈希的缺陷
2.开散列/哈希桶(重点)
开散列法又叫链地址法(开链法),首先对关键码集合用散列函数计算散列地址,具有相同地址的关键码归于同一子集合,每个子集合称为一个桶,各个桶中的元素通过一个单链表链接起来,各链表的头节点存储在哈希表中。
当使用开散列插入12,22,32的时候,插入完成后就会变成这样
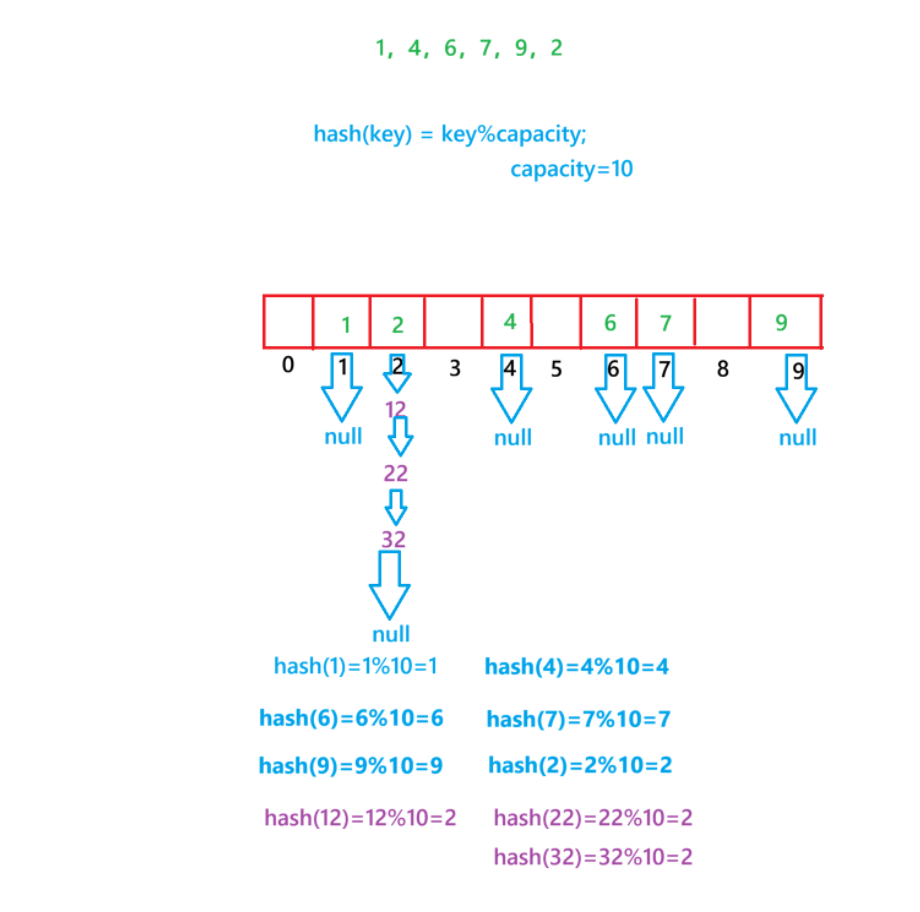
可以看出,开散列中每个桶中放的都是发生哈希冲突的元素
开散列,可以认为是把一个在大集合中的搜索问题转化为在小集合中做搜索了
冲突严重时的解决办法
刚才我们提到了,哈希桶其实可以看作将大集合的搜索问题转化成小集合的搜索问题了,那如果冲突严重,就意味着小集合的搜索性能其实也时不佳的,这个时候我们就可以将这个所谓的小集合搜索问题继续进行转化,例如:
1.每个桶恶的背后时另一个哈希表
2.每个桶的背后是一颗搜索树
3.哈希表的模拟实现(基本类型)
这里我们使用开散列来模拟实现哈希表,即使用数组加链表的形式来模拟实现
同时将负载因子设置为0.75,与Java所提供的负载因子相同
i.初始化
java
static class Node{
int key;
int value;
Node next;
public Node(int key, int value) {
this.key = key;
this.value = value;
}
}
Node[] array=new Node[10]; //哈希表底层数组
int usedSize; //已存储的节点总数
//定义负载因子,超过则扩容
double DEFAULT_LOAD_FACTOR=0.75;ii.插入数据
java
public void push(int key,int val){
//首先计算出要插入的下标
int index=key% this.array.length;
//找是否在原数组中已经插入该key值了,如果插入了则进行更新
//遍历对应哈希桶的链表,检查key是否已经存在
Node cur=this.array[index];
while (cur!=null){
if (cur.key==key){
cur.value=val;
return;
}
cur=cur.next;
}
//如果程序走到了这,说明在原数组中没有插入该key
Node node=new Node(key,val);
//头插进行插入
node.next=this.array[index];
this.array[index]=node;
this.usedSize++;
// //尾插
// Node cur1=this.array[index];
// while (cur1.next!=null){
// cur1=cur1.next;
// }
// cur1.next=node;
//如果大于负载因子,则需要扩容
if (doLoadFactor()>=DEFAULT_LOAD_FACTOR){
resize();
}
}
private void resize() {
Node[] newArray=new Node[array.length*2];
//遍历数组的每个哈希桶
for (int i = 0; i < this.array.length; i++) {
//获取当前节点的链表的地址
Node cur=array[i];
//遍历当前哈希桶的所有节点
while (cur!=null){
int newIndex=cur.key%newArray.length;
//提前保存cur的下一个节点,避免链表断裂
Node curN=cur.next;
//头插到新数组的对应桶中
cur.next=newArray[newIndex];
newArray[newIndex]=cur;
//遍历下一个节点
cur=curN;
}
}
this.array=newArray;//替换为新的数组
}
//计算负载因子
private double doLoadFactor() {
return this.usedSize*1.0/this.array.length;
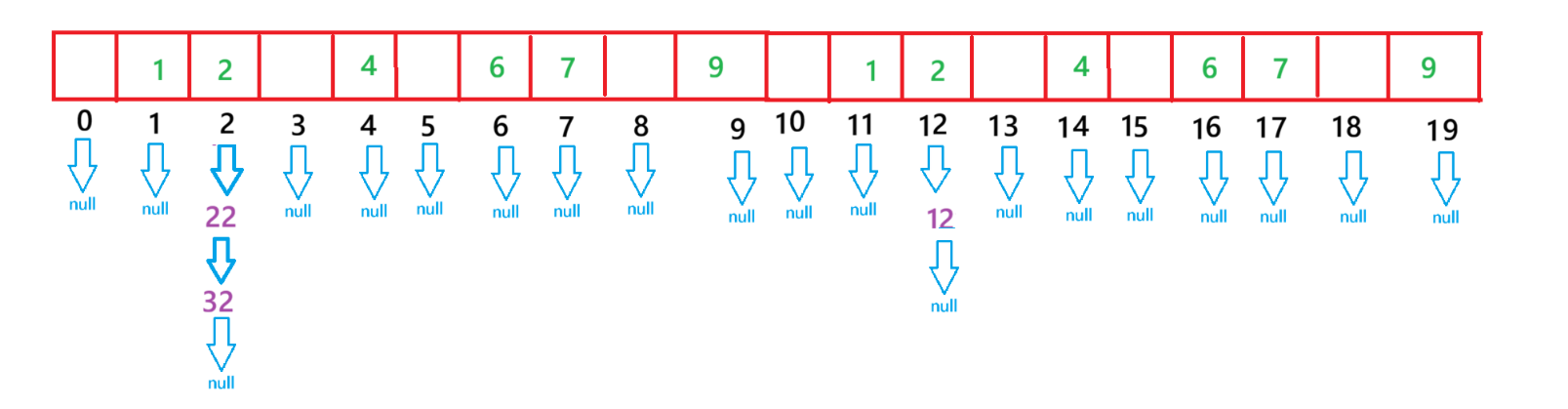
}哈希表的插入数据需要考虑许多情况,首先当插入一个数据之后,会先判断负载因子是否大于0.75,如果小于0.75,则无影响,如果大于等于0.75,此时就要考虑扩容的问题了
在扩容的时候也不是单纯的扩容,当申请完空间之后,我们要再从原数组的第一个下标的第一个节点开始遍历,直到遍历到原数组最后一个下标的最后一个节点,这样做的目的是为了让原数组中的所有节点,确保插入到新数组的合适位置
例如,上面这个图,当我扩容之后,会变成这样
iii.获取val值
这个比较简单,直接上代码
java
public int getVal(int key){
int index=key%this.array.length;
Node cur=array[index];
while (cur!=null){
if (cur.key==key){
return cur.value;
}
cur=cur.next;
}
return -1;
}4.哈希表的模拟实现(泛型)
泛型的实现和基本类型的实现的区别在于,在获取基本类型的下标的时候我们直接通过模除数组长度即可获得,但是泛型就不行了,我们首先先要使用hashCode()方法,获取具体的位置,然后再通过模除数组的长度,这样就可以得到哈希桶的位置了
还有在插入的时候,在基本类型中,当我们判断cur.val==val的时候,使用的是==,但是在泛型中就不行了,我们要使用equals()方法来判断两个元素是否相等
注意:如果插入的类型是自定义类型,那么一定要重写我们的hashCode()和equals()方法!!!
其他的都和基本类型的哈希表一样
原码:
java
/**
* hashCode() 的作用,找到每一个key应该在哪一个位置
* equals() 的作用是 在当前位置下,链表中的每个节点的key与我要找的key是否一样
* 查字典 查 "美景" 首先要确定 "美" 具体在哪一页 (hashCode)
* 找到 "美" 之后,要在 "美食" "美味" ·····中找到 "美景" (equals) 一个一个来判断
*
* equals一样,那么hashCode一定一样
* hashCode一样,equals不一定一样 因为hashCode一样只能说明都是属于 "美",但是不一定都是 "美景"
* @param <K>
* @param <V>
*/
public class HashBunk2<K,V> {
static class Node<K,V>{
K key;
V value;
Node<K,V> next;
public Node(K key, V value) {
this.key = key;
this.value = value;
}
}
public Node<K,V>[] array=(Node<K, V>[]) new Node[10];
public int usedSize;
public static final double DEFAULT_LOAD_FACTOR=0.75;
public void push(K key,V value){
//首先确定要放的位置
int hashCode=key.hashCode();
int index=hashCode% array.length;
Node<K,V> cur=array[index];
while (cur!=null){
//判断哈希桶中是否已经有这个值了
if (cur.key.equals(key)){
cur.value=value;//如果有了,则更新该值
return;
}
}
//走到这,说明没有该值
Node<K,V> node=new Node<>(key,value);
//头插node节点
node.next=array[index];
array[index]=node;
this.usedSize++;
//判断负载因子
if (doLoadFactor()>=DEFAULT_LOAD_FACTOR){
//扩容
resize();
}
}
private void resize() {
Node<K,V>[] newArray=(Node<K, V>[]) new Node[2* array.length];
for (int i = 0; i < array.length; i++) {
Node<K,V> node=array[i];
while (node!=null){
//提前保存下个节点
Node<K,V> nodeN=node.next;
//生成一个具体的哈希值
int hashCode=node.key.hashCode();
int newIndex=hashCode% newArray.length;
//Node<K,V> newNode=newArray[newIndex];
node.next=newArray[newIndex];
newArray[newIndex]=node;
node=nodeN;
}
}
this.array=newArray;
}
private double doLoadFactor(){
return this.usedSize*1.0/ array.length;
}
public V getValue(K key){
int hashCode=key.hashCode();
int index=hashCode%array.length;
Node<K,V> cur=array[index];
while (cur!=null){
//泛型比较key相等时不能使用==,这样比较的是地址,所以肯定不一样,要使用equals
if (cur.key.equals(key)){
return cur.value;
}
cur=cur.next;
}
return null;
}
}性能分析:虽然哈希表一直在和冲突做斗争,但在实际使用过程中,我们认为哈希表的冲突率是不高的,冲突个数是可控的,也就是每个桶中的链表的长度是一个常数,所以,通常情况下,我们认为哈希表的插入/删除/查找的时间复杂度是O(1)
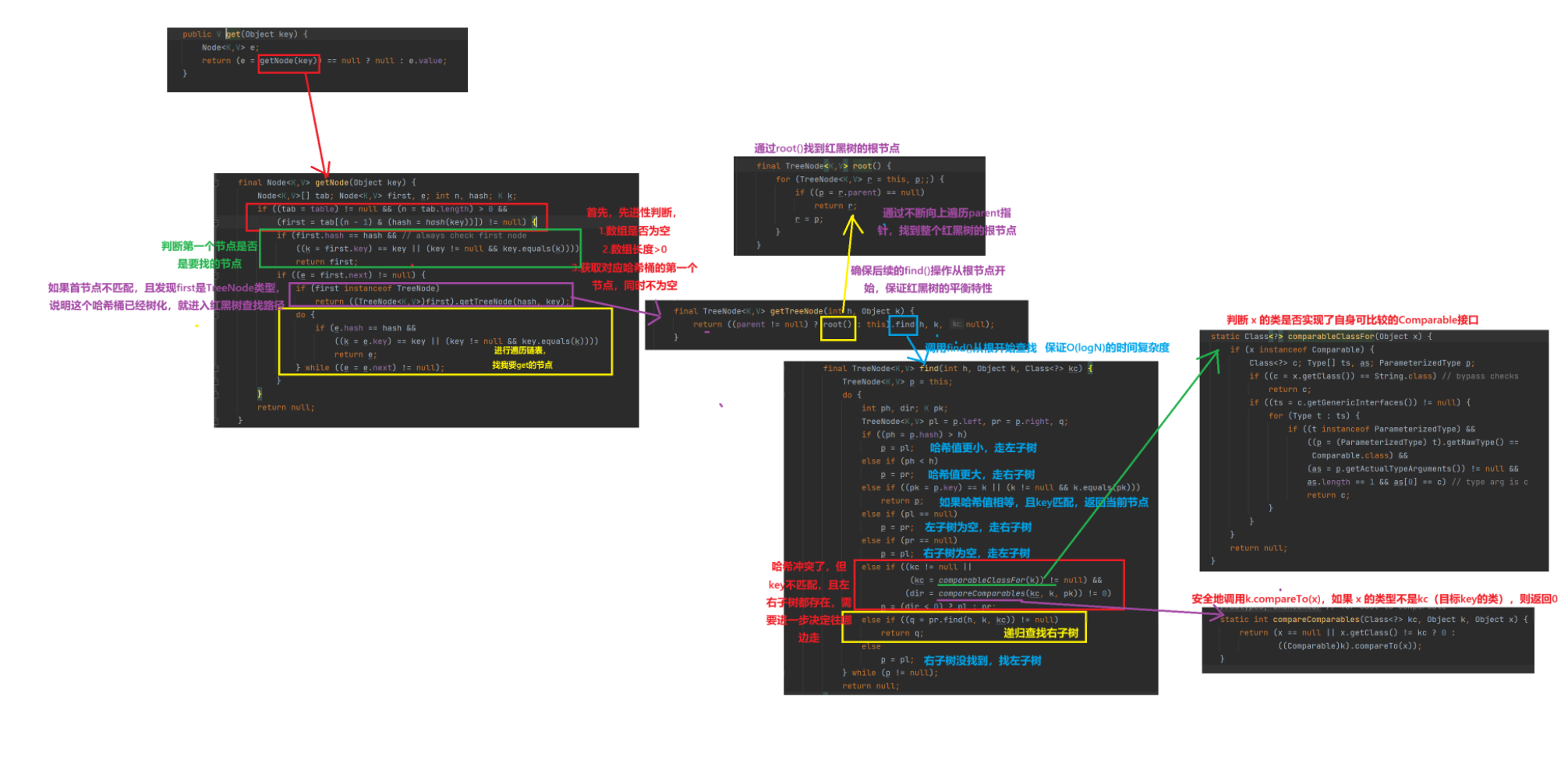
5.Java的HashMap部分源码解析
(1).初始化部分
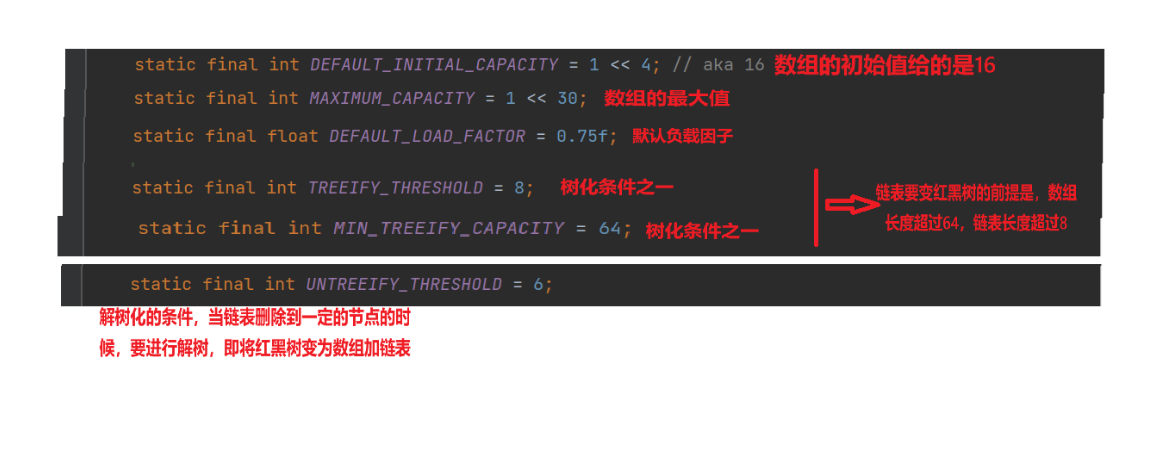
(2).构造方法

(3).put
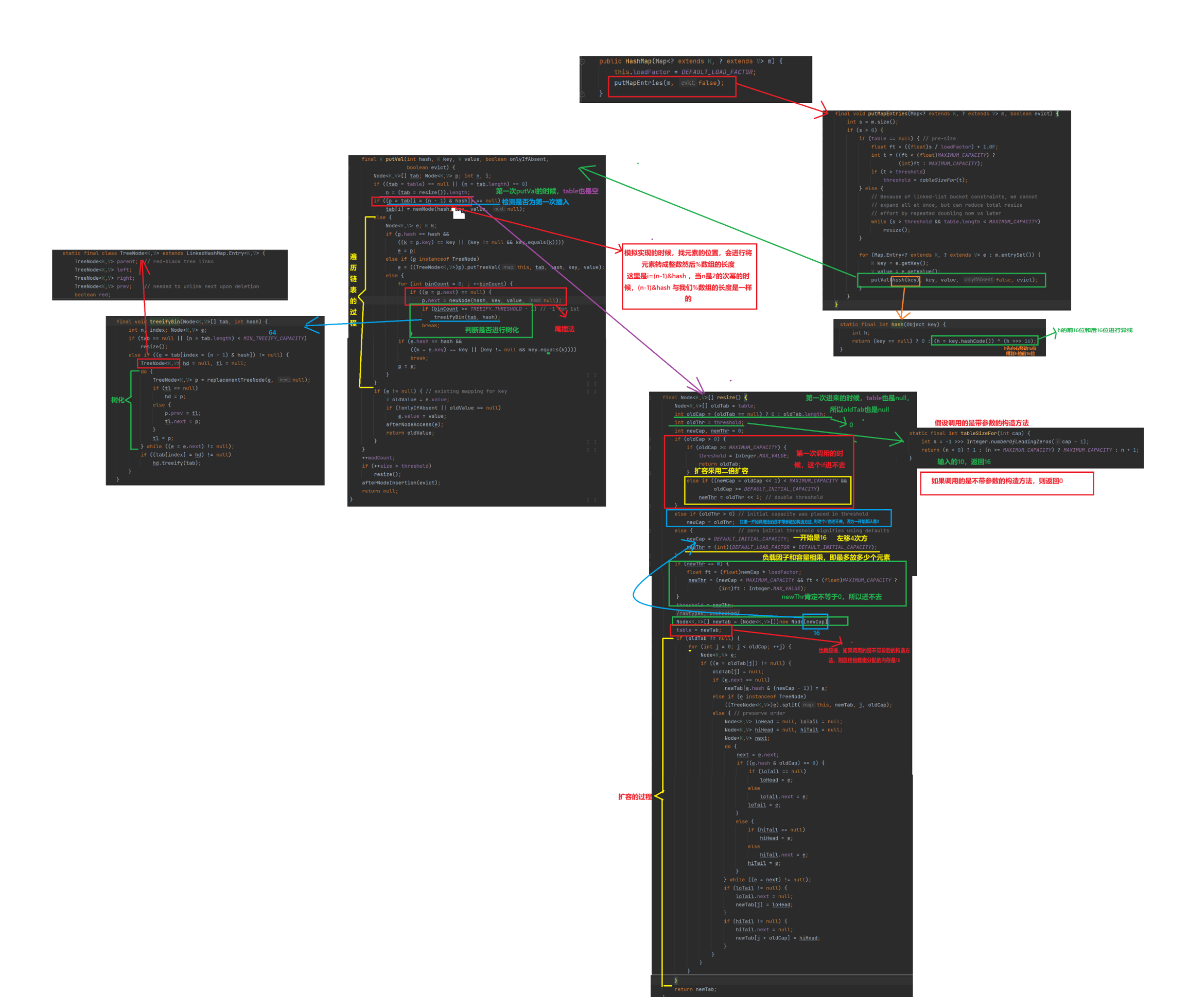
(4).get