摘要
本次学习了深度强化学习中应对稀疏奖励与无明确奖励信号的核心方法。首先详细了解了奖励塑造的基本概念,分析了在稀疏奖励环境下通过引入基于领域知识的额外奖励以引导智能体学习的机制,并特别探讨了基于好奇心的奖励塑造方法。进一步,深入讨论了在完全缺乏奖励信号的情况下如何通过模仿学习与逆强化学习进行策略学习,重点剖析了逆强化学习通过专家示范反推奖励函数、并迭代优化智能体策略的工作原理,同时揭示了其与生成对抗网络在框架上的深刻相似性,为理解和应用复杂环境下的强化学习提供了关键思路。
Abstract
This study covers core methods in deep reinforcement learning for handling sparse rewards and absent reward signals. It analyzes reward shaping, including curiosity-based approaches, which use additional rewards to guide learning. It also examines imitation learning and inverse reinforcement learning, which infers reward functions from expert demonstrations to optimize policies, highlighting its structural similarity to Generative Adversarial Networks.
一.奖励塑造(Reward Shaping)
1.奖励塑造概念
到目前为止,我们所了解到的是将actor拿去与环境互动得到奖励,然后将这些奖励进行整理得到分数A。有了分数A就可以去让actor知道哪些行为可以做,哪些不行。
但是在强化学习中就怕遇到一种情况,也就是奖励大部分情况下都是0,只有极低的概率会得到巨大的奖励。其中大部分情况下奖励为0是表示无论actor行为如何其对应的奖励以及分数A都是0。
在这种情况下就很难去训练actor,对于这种稀疏奖励(Sparse Reward)就会让我们联想到下围棋的情形正好对应。因为在下棋过程中每下一枚棋,并不会得到积极或消极的奖励,只有这盘棋局结束时赢了才会得到积极奖励,输了才会得到消极奖励。更为具体的例子就如机器手臂拧螺丝,只有正好拧进去才会有积极奖励,否则由于机器手臂挥舞的随机性只要未拧进去其奖励都为0。
对于上面的情况,我们可以通过提供额外的奖励来引导agent学习来解决。也就是在我们正真要agent去最大化的奖励以外,再定义一些额外的奖励,然后通过这些额外的奖励来帮助agent学习,这一方式就被叫做奖励塑造。
2.奖励塑造的运用
就以VizDoom为例,在这个游戏中被敌人杀掉就扣分,杀掉敌人就加分。但是只凭着这些奖励机制来训练agent,是很难将其训练好的。所以这时就要引入奖励塑造的一些概念。如增加以下机制:

当在游戏过程中有扣血,这就会得到负的奖励,目的是让机器更早知道扣血与死亡之间是有关联的;如果损失弹药就得到负的奖励;得到医疗包或弹药补给包就加分;总是呆在原地就要扣分,为了避免前期agent为了得到高的奖励从而一直呆在原地,并且告诉机器如果移动就会增加很小的分数;只是要求机器移动是不够的,现在看看第一个有趣的奖励机制,若每次agent都活着其都会被扣分,这是因为若活着没有扣分或者是一个正面的事情对于agent而言其学到的可能就在躲在边缘观察,所以这是为了强迫agent去学着战斗。
通过观察上面的奖励塑造,我们可以发现其是需要领域知识的,是需要凭借人类对于现有环境的理解强加上去。
3.基于好奇心的奖励塑造
在奖励塑造中有一个特别有趣且知名的做法就是基于好奇心的奖励塑造。所谓给机器加上好奇心就是让机器去探索新的事物,所以在原来的reward之外,再加上一个如果机器在活动中见到新的事物就会加分的reward(新的东西必须是有意义的)。
就如让机器玩马里奥,在这个游戏过程中是没有任何的其他奖励的,只是告诉机器只有不断看到新的东西,也就是这个条件可以让机器学会通过马里奥中的一些关卡。
二.无奖励信号
1.expert
在强化学习的最后要了解的是若在训练actor过程中reward都没有该如何处理。对于reward其往往只是在一些比较人为的环境中如游戏中较为容易被定义出来。但是在真实环境中定义reward是可能非常困难的,就如用强化学习来训练智驾,那对于礼让行人、闯红灯等行为又该如何定义reward呢,这个标准很难确定。
对于这个情况,是否可以像前面奖励塑造一样人为想象,答案是可以但是不是很好。就如下面三条对于机器人的指令:

机器人为了遵守上面三条指令,最后通过机器学习后就可能演变成将人类监禁起来,这样人类以及机器人不会受到伤害,保证了安全,但是这就违背了设定这三条指令以及设立机器人的初心了。
对此在没有reward的情况下让机器与环境互动的一个方法就叫做模仿学习(Imitation Learning) 。在这个方法中,假设actor仍可以跟环境互动,但是从环境中得不到reward,对此没有reward,有另外一个东西expert。Expert通常是指人类,通过将人类与环境的互动记录下来成为其的示范(就如让机械手臂摆放盘子前可以先拉着机械手臂示范一次),将这些示范称为。所以我们就可以通过这些示范以及与环境的互动进行学习。
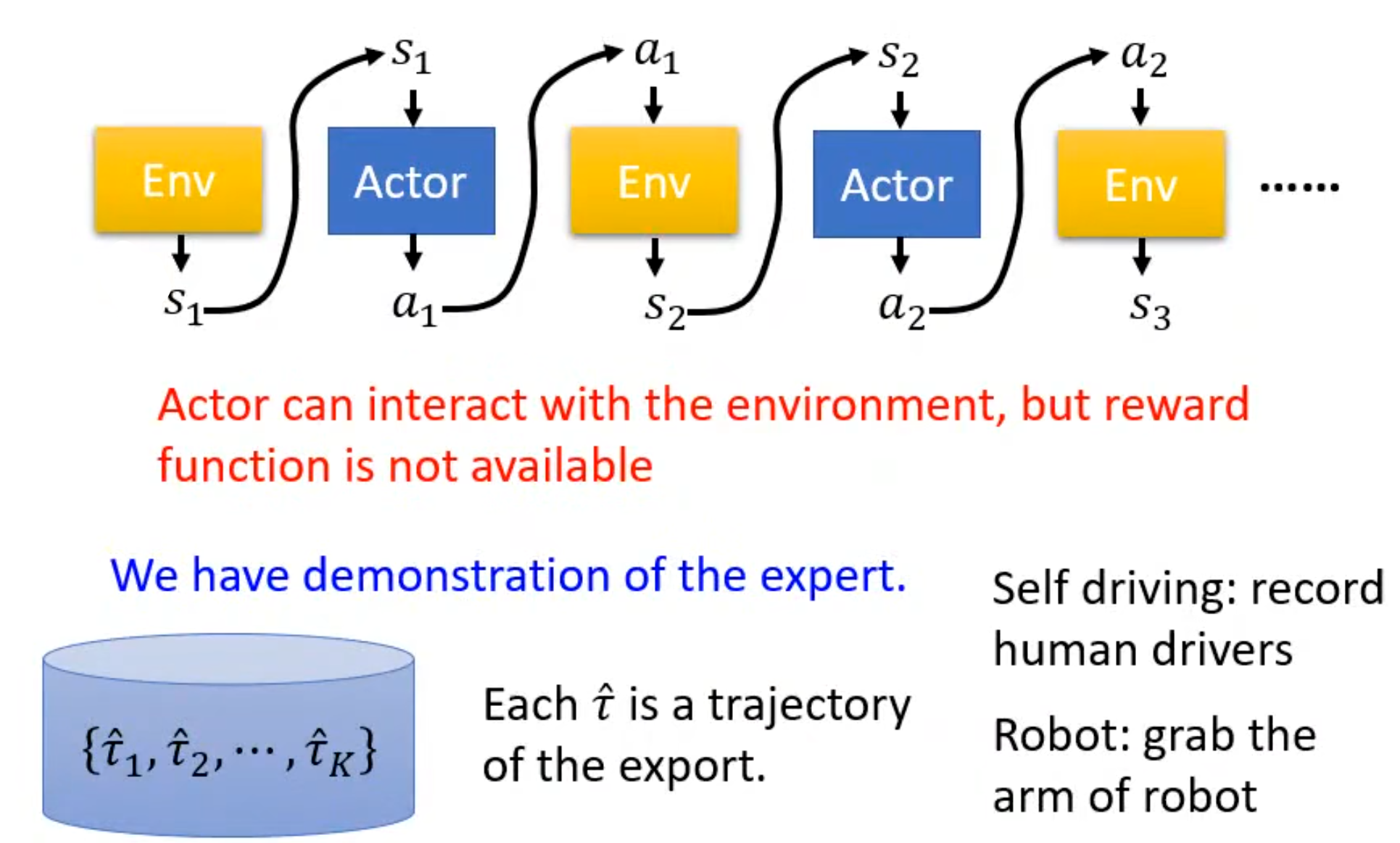
了解到这里就会发现这与前面学习的监督学习类似,就如训练自动驾驶,有人类的驾驶记录就会采取对应的行动如刹车或前进,这种行为称为行为克隆(Behavior Cloning)。但是仅仅是让机器去复制人类行为,会导致出现人类与机器可能观察到的s会是不一样的。就如开车过弯,机器通过人类示例学习到的是可以轻松通过,但是它从没有看过失败的案例,这样就会导致机器开车要撞墙时应该如何处理。
还有个问题就是对于每一个行为并不需要都要去模仿,因为有些行为是个人的习惯,机器单纯模仿情况下是区分不开的。
2.逆强化学习(Inverse Reinforcement Learning)
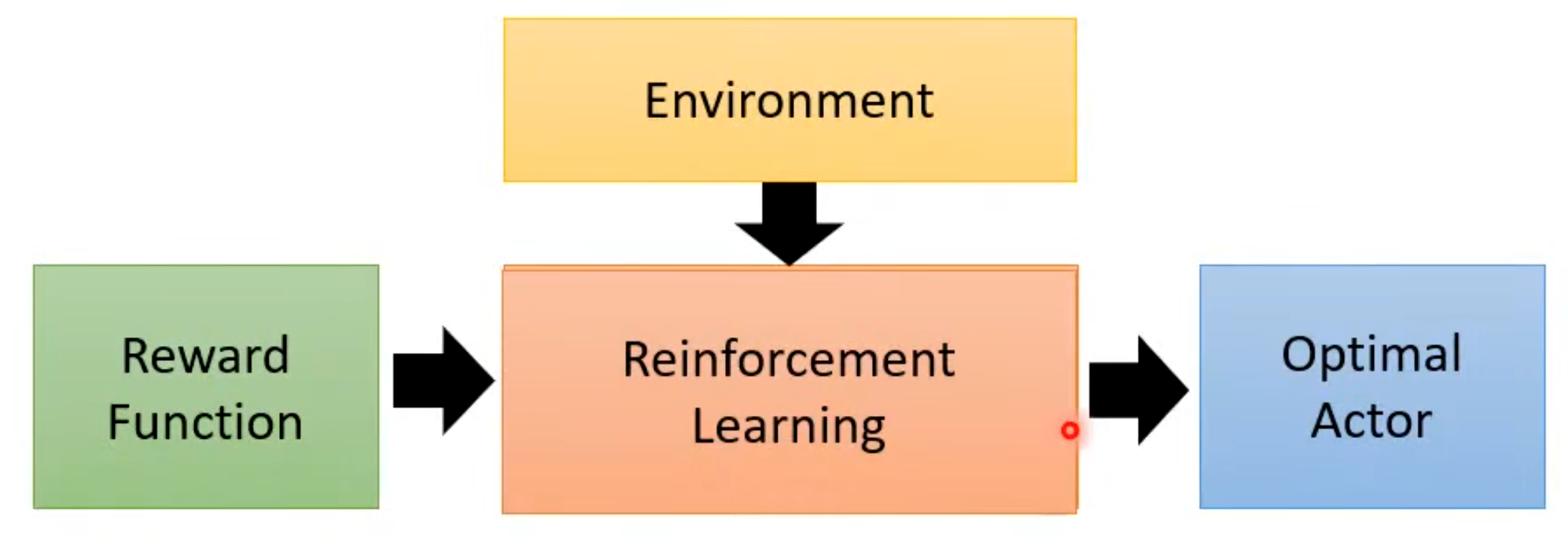
为解决这个问题,我们可以了解另外应该技术逆强化学习。在原来的强化学习中是在有奖励与环境的条件下通过强化学习便得到了actor。
但是现在是没有reward,而是有专家的示范和环境,同时将强化学习改为逆强化学习。其与原来相反,是通过expert以及环境去反推reward。得到奖励后再通过普通的强化学习得到我们想要的actor。
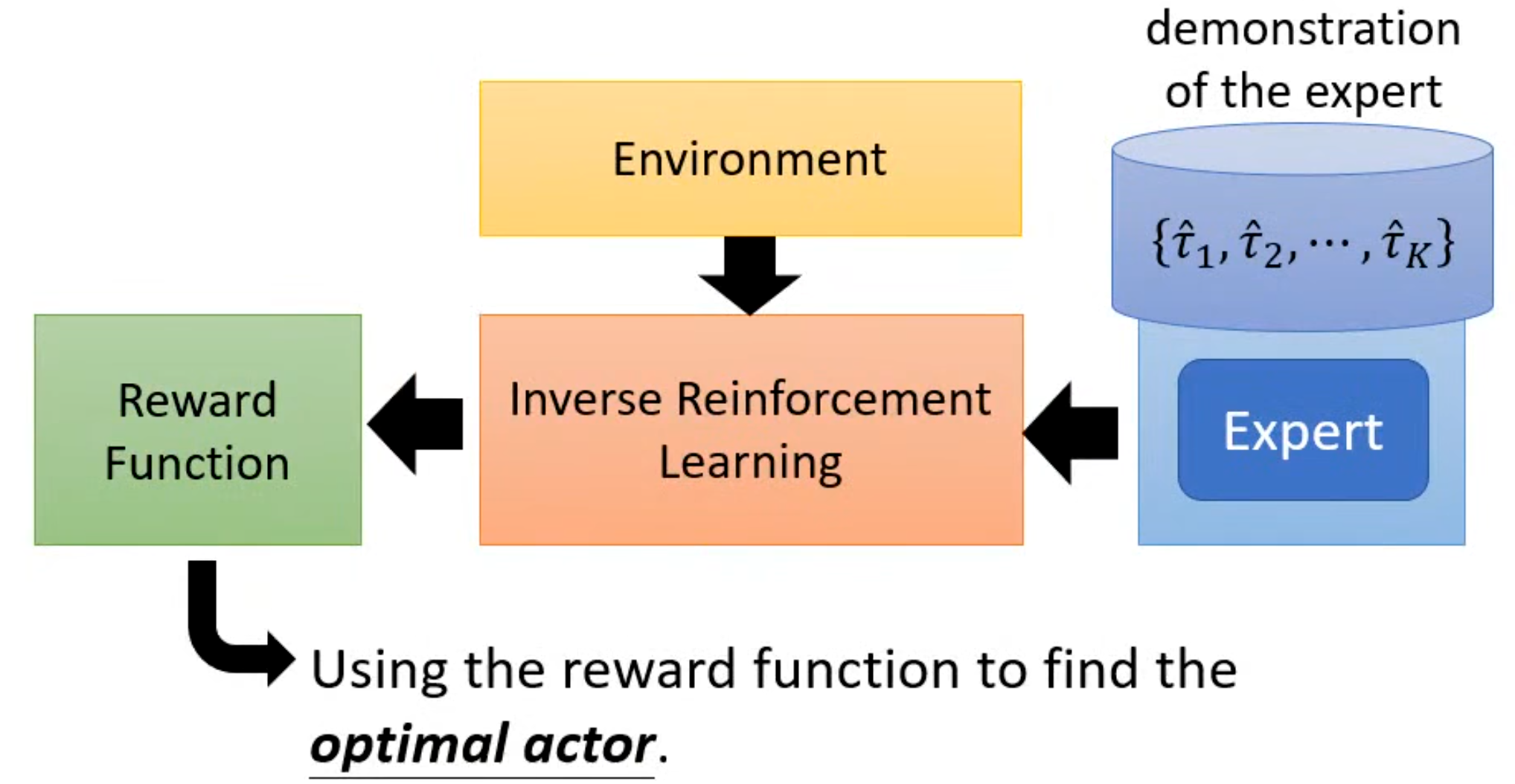
其中逆强化学习的基本原则是老师的行为是最好的(最好并不意味着单纯模仿)。其基本理念是先初始化一个actor,然后在每次迭代中先让actor与环境互动并收集actor自己的规矩信息;然后再定义一个奖励函数,使得老师的行为奖励必须要高于学生行为奖励;接着去更新actor的参数使得其可以最大化得到的奖励。最终就可以得到奖励函数。
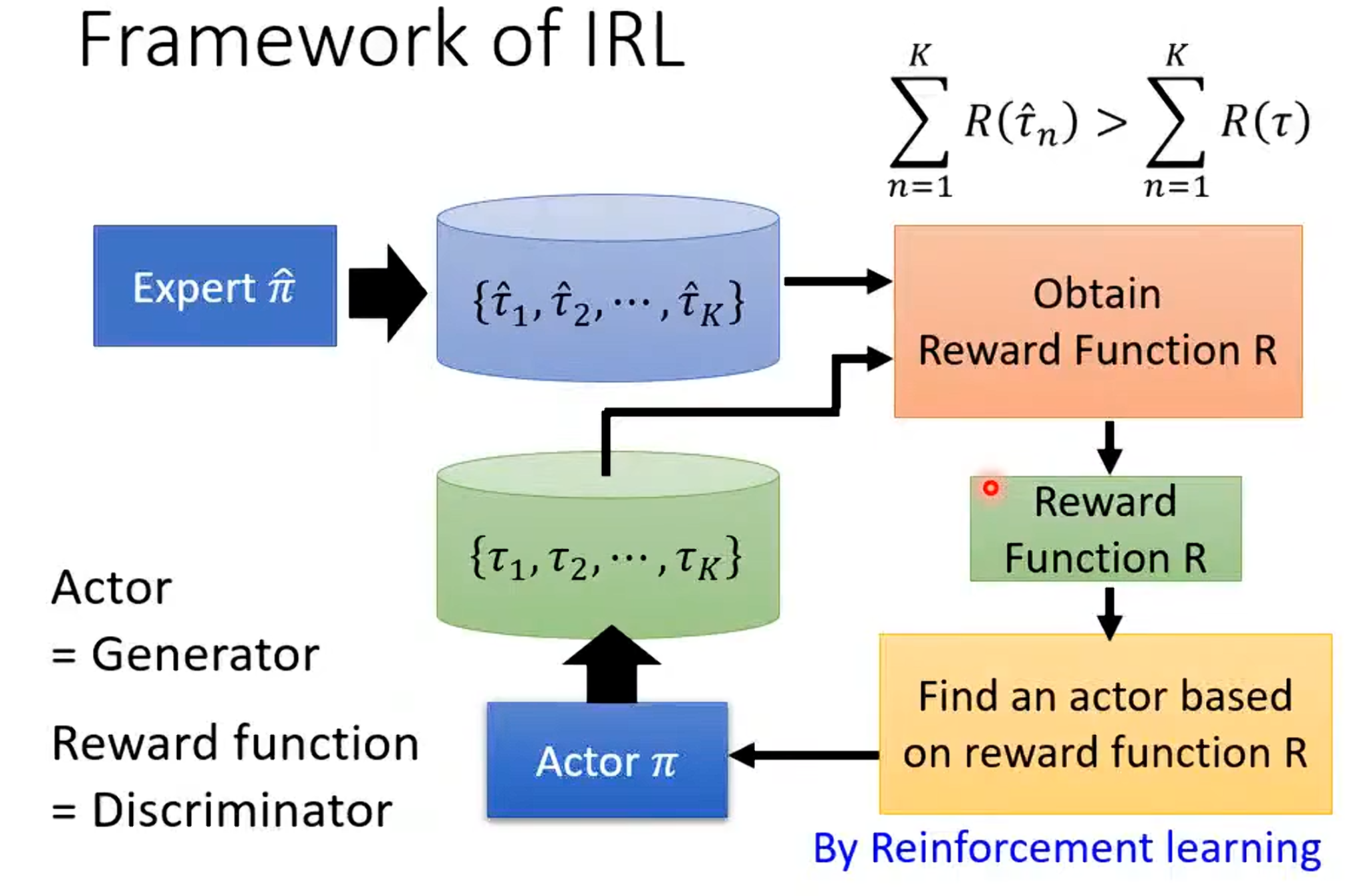
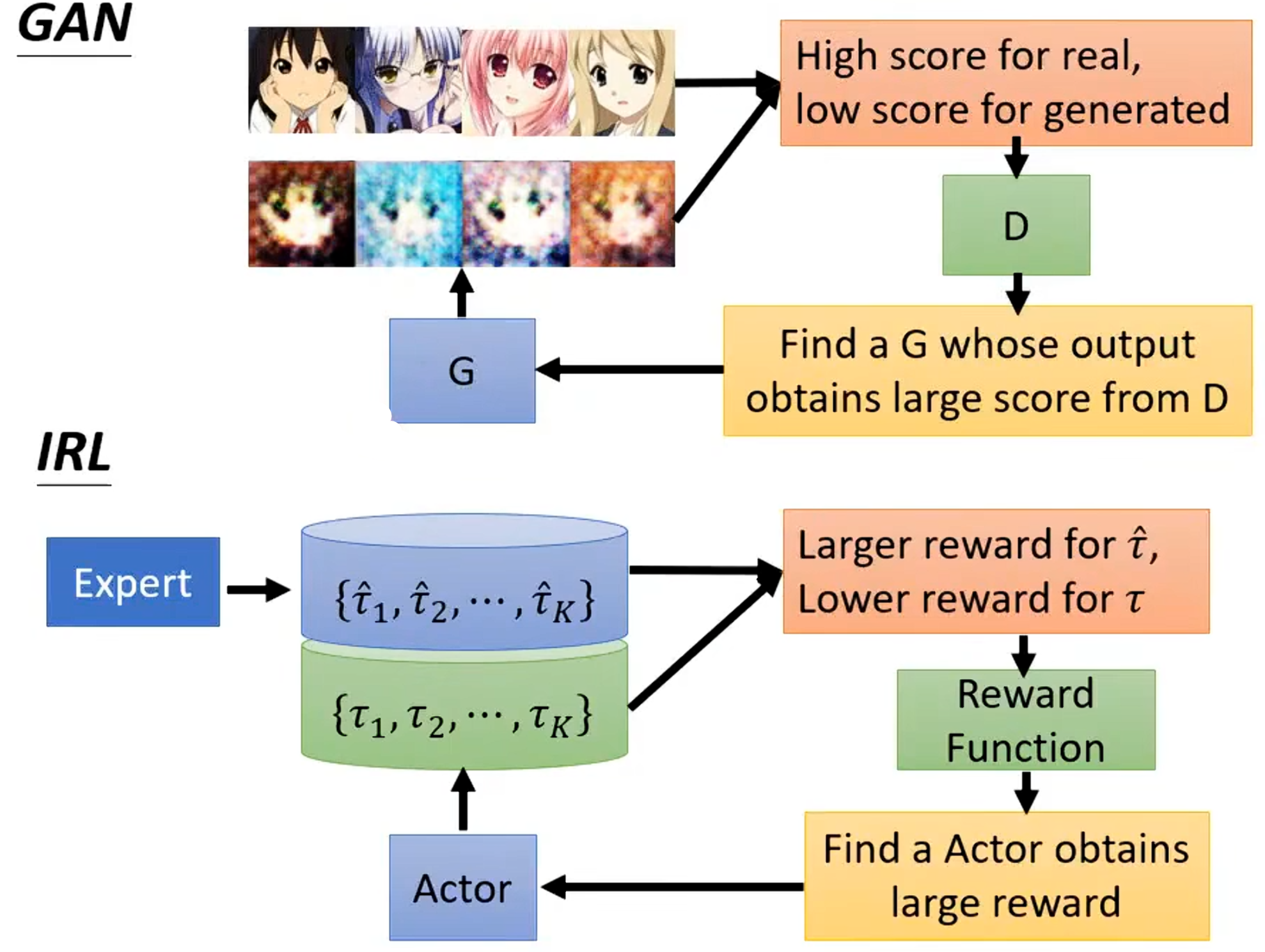
到这里可以发现这与之前学习的生成对抗网络非常相似,可以将actor看作是生成器,奖励函数可以看作是鉴别器。在生成对抗网络中生成器生成较差的图片,其中鉴别器要给真实的图片高分,给生成器生成的图片低分,接着生成器不断更新想方设法去骗过鉴别器,同时鉴别器也会不断更新自己。两者对比如下:
总结
本次课程重点探讨了深度强化学习中两类关键问题:稀疏奖励与无奖励信号下的学习策略。奖励塑造作为一种引入先验知识以缓解稀疏奖励问题的有效技术,通过设计合理的额外奖励引导智能体探索与学习,其中基于好奇心的机制进一步推动了其在未知环境中的自主探索能力。而在缺乏明确奖励信号的场景下,模仿学习与逆强化学习提供了可行的解决方案,尤其是逆强化学习,通过类比生成对抗网络的对抗训练框架,从专家行为中反推出隐含的奖励函数,进而训练出适应复杂任务的智能体。这些方法不仅拓宽了强化学习的应用边界,也体现了其与其他机器学习范式(如生成对抗网络)的深刻交叉与融合,为未来在更真实、更复杂环境中部署强化学习系统奠定了重要的方法论基础。