深度学习面试高频问题和答复
一问一答,直击考点,背完即可上车。
1. 激活函数
Q:ReLU 相比 Sigmoid 的三大优势?
- 计算快:无 exp,前向+反向省 50% 时间。
- 缓解梯度消失:正区间导数恒 1,信号不衰减。
- 稀疏激活:负半轴输出 0,网络天然稀疏,抑制过拟合。
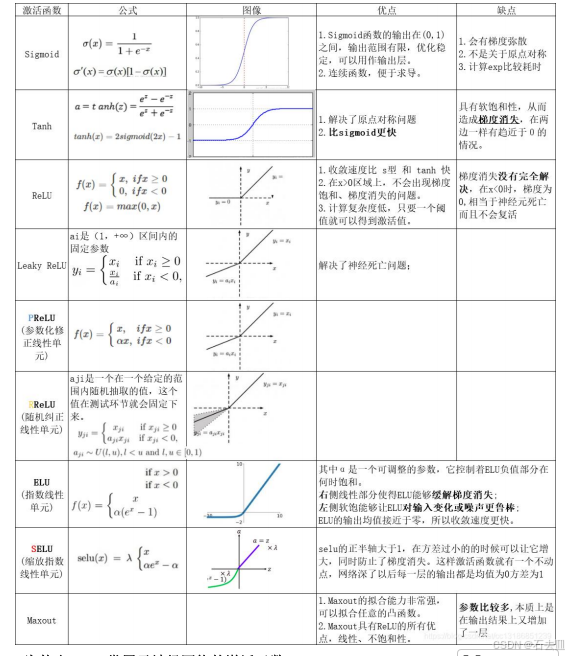
Q:Sigmoid 还能用吗?
能,仅用于二分类输出层,因其输出 0~1 可解释概率;隐藏层一律 ReLU。
2. 梯度消失/爆炸
Q:一句话定义?
前向乘小数→消失;前向乘大数→爆炸。
Q:现场快速诊断指令?
torch.nn.utils.clip_grad_norm_(model.parameters(), 5) 后 loss=NaN → 爆炸;靠近输入层梯度≈0 → 消失。
Q:三板斧解决方案?
- 换激活:ReLU/PreLU
- 加 BN:每层输出归一化
- 残差结构:跳连直接传梯度
3. 正则化
Q:L1 与 L2 区别?
L1 让权重稀疏(可做特征选择),L2 让权重平滑(泛化好)。
Q:Dropout 训练和测试差异?
训练时按概率 p 关闭神经元;测试时全部开启且权重乘以 (1-p)。
Q:BN 与 Dropout 能否共存?
可以,但 BN 自带噪声,Dropout 比例降到 0.1~0.2 即可,ResNet 官方实现直接去掉。
4. 参数初始化
Q:全零初始化会怎样?
所有神经元对称,梯度相同,只能学到同一特征 → 模型永远无法收敛。
Q:ReLU 网络用 Xavier 会怎样?
前向方差逐层减半,信号"饿死",应改用 He 初始化(方差×2)。
5. 优化器
Q:Adam vs SGD 一句话?
Adam 收敛快 ;SGD 最终精度高。
Q:面试最爱挖坑:Adam 什么时候不 work?
数据稀疏、embedding 大时 Adam 优势明显;图像分类刷榜阶段用 SGD+Momentum+余弦退火能再提 0.5%。
6. 学习率
Q:lr 过大/过小表现?
过大:loss 震荡甚至 NaN;过小:100 epoch 还下不去。
Q:现场调 lr 口诀?
"三乘三除":先 0.1 跑 3 epoch,loss 不降 → ÷3;再 3 epoch,不降 → ÷3,三次搞定。
7. Batch Size
Q:batch_size=1 能用 BN 吗?
不能 ,统计量噪声极大;换 GroupNorm 或 冻结 BN。
Q:batch_size 从 64 拉到 512,lr 怎么改?
线性缩放:新 lr = 旧 lr × (512/64) = 8×;超过 1k 后用 LARS 自适应层学习率。
8. 卷积
Q:3×3 卷积核为什么成主流?
2 个 3×3 感受野=1 个 5×5,参数量仅 18/25=72%,多一次非线性 ,表达能力更强。
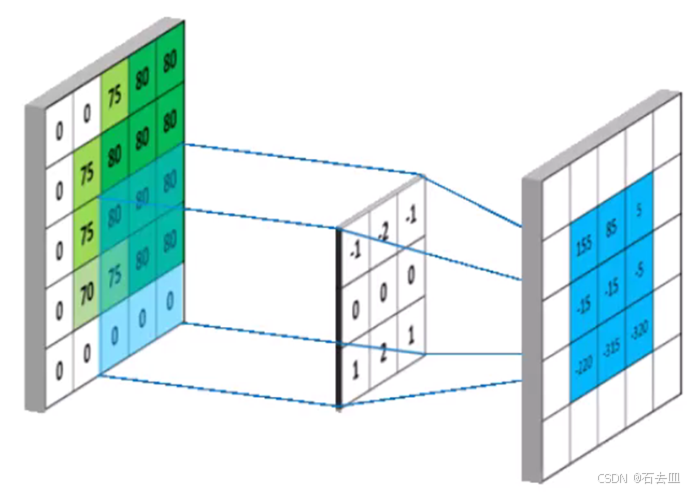
Q:1×1 卷积三大作用?
降维/升维、跨通道信息融合、加非线性(后接 ReLU)。
Q:空洞卷积 dilation=2,感受野?
3×3 实际覆盖 5×5,不增加参数的情况下扩大视野,适合语义分割。
9. 池化
Q:MaxPool 与 AveragePool 何时选?
分类网络 MaxPool 保边缘;分割网络最后一层用 AveragePool 平滑特征。
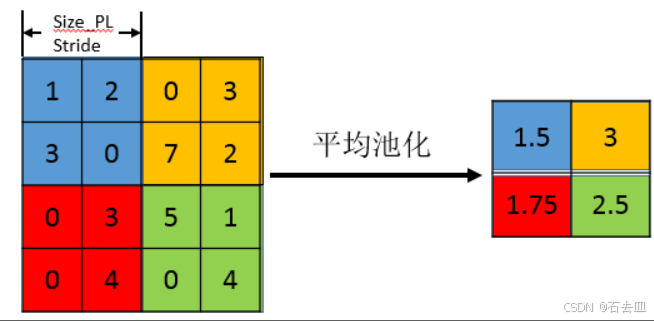
Q:Global Average Pooling 好处?
替代全连接层,参数量降为 0,防止过拟合,可接受任意输入尺寸。
10. 经典网络对比
| 模型 | 年份 | 核心创新 | 层数 | 参数量 |
|---|---|---|---|---|
| LeNet | 1998 | 首个 CNN | 7 | 60k |
| AlexNet | 2012 | ReLU+Dropout+GPU | 8 | 61M |
| VGG | 2014 | 3×3 堆叠 | 16/19 | 138M |
| Inception | 2014 | 并行多尺度 | 22 | 5M |
| ResNet | 2015 | 残差跳连 | 50/101/152 | 25M~60M |
| DenseNet | 2017 | 密集连接 | 121 | 8M |
Q:ResNet 为什么能解决"退化"?
跳连把网络拆成 多个浅层集成 ,恒等映射可学习,深层不差于浅层。
11. RNN/LSTM
Q:RNN 梯度消失根本原因?
tanh 导数<1 的连乘,时间步长 T 越大,梯度越趋 0。
Q:LSTM 如何规避?
细胞状态 Ct 的更新是"加性"而非"乘性",梯度可沿 Ct 无损回传。
Q:面试手推公式必考:
遗忘门 ft = σ(Wf·ht-1,xt+bf)
输入门 it = σ(Wi·ht-1,xt+bi)
候选状态 C̃t = tanh(Wc·ht-1,xt+bc)
细胞状态 Ct = ft∗Ct-1 + it∗C̃t
输出门 ot = σ(Wo·ht-1,xt+bo)
ht = ot∗tanh(Ct)
12. 调参万能模板(答即满分)
Q:Loss 不下降,如何系统排查?
- 数据:可视化 batch,label 对否?
- lr:÷3 再跑 3 epoch;
- 初始化:换 He/Xavier;
- 梯度:clip_norm=5;
- 正则:加 BN,降 dropout;
- 优化器:Adam → SGD;
- 最后:加数据、加模型、降学习率。
13. 微调/迁移学习
Q:小数据集(<5k)怎么微调?
冻结 backbone,只训最后一层分类器,lr=1e-3,10 epoch 搞定。
Q:大数据集(>50k)且与源域差异大?
解冻全部层,用 SGD lr=3e-5,Cosine 退火 50 epoch,可超 ImageNet 预训练。
14. 超参搜索
Q:网格搜索缺点?
指数爆炸,5 个超参各 3 档 = 243 组实验。
Q:贝叶斯优化四要素?
目标函数、搜索空间、代理模型(TPE/GP)、采集函数(EI),利用历史评估减少 60% 实验次数。
15. 面试现场"手撕"代码
Q:用 PyTorch 写残差块(ResBasicBlock)?
python
class ResBlock(nn.Module):
def __init__(self, c):
super().__init__()
self.conv = nn.Sequential(
nn.Conv2d(c, c, 3, padding=1, bias=False),
nn.BatchNorm2d(c),
nn.ReLU(inplace=True),
nn.Conv2d(c, c, 3, padding=1, bias=False),
nn.BatchNorm2d(c)
)
self.relu = nn.ReLU(inplace=True)
def forward(self, x):
return self.relu(self.conv(x) + x)注意:bias=False,因 BN 已含 bias;ReLU(inplace=True) 省显存。
16. 一句话速记 30 考点
- 激活:隐藏 ReLU,输出 Sigmoid/Softmax
- 梯度:BN+残差+He 初始化
- 正则:BN 必备,Dropout 0.1~0.5
- 优化:Adam 先降,SGD 后精
- 学习率:三乘三除,Cosine 退火
- Batch:线性缩放,1k 以上 LARS
- 卷积:3×3 堆叠,1×1 降维
- 池化:Max 保边,Global 防过拟合
- 网络:ResNet 解决退化,DenseNet 特征复用
- RNN:tanh 乘性梯度消失,LSTM 加性保存
- 微调:小数据冻层,大数据全解冻
- 搜索:网格→随机→贝叶斯