
2026 年,计算机视觉早已不是实验室里的小众技术 ------ 它是自动驾驶汽车的 "眼睛",是医疗影像诊断的 "辅助手",是机器人交互的 "感知中枢",更是多模态大模型理解世界的核心支柱。从手机端的实时美颜到工业界的精密检测,从卫星遥感分析到穿戴设备的场景识别,视觉 AI 的应用边界正在无限拓宽。
但光鲜背后,行业始终被一个 "不可能三角" 牢牢困住:想让模型识别更准、泛化性更强,就得堆砌更大的参数量、投喂更高分辨率的图像;可参数和分辨率一上来,计算成本、推理延迟就跟着指数级暴涨。2026 年的今天,我们依然面临尴尬现实 ------ 最先进的视觉模型在数据中心里能达到 99% 的准确率,却因过高的能耗和延迟,无法落地到自动驾驶、可穿戴设备这些核心场景;而边缘设备上的轻量化模型,又不得不牺牲精度换取效率。
传统模型的 "死板" 是问题根源:***它们像一台不分重点的扫描仪,不管图像里的信息有用与否,都要逐像素平行处理,造成巨大的资源浪费。***而人类看世界的方式完全不同 ------ 我们会自然聚焦关键区域(比如看书时盯文字、过马路时看车辆),忽略无关信息,用最少的 "注意力成本" 完成感知。
2026 年,清华 LEAP 实验室最新提出的AdaptiveNN 框架,终于为这个困局带来了破局之道。它让 AI 学会了人类的 "主动视觉",一举破解 "不可能三角",相关成果已公开代码**(https://github.com/LeapLabTHU/AdaptiveNN)**,为下一代高效、灵活、可解释的计算机视觉模型指明了方向。
一、从"被动"到"主动"的范式转变
当前的计算机视觉模型遵循着一个源于数十年前的**"被动"范式**:模型一次性接收整张图像,并行处理所有像素。
这种"一视同仁"的处理方式,在面对如今高达数百万甚至数十亿像素的图像或视频时,显得效率低下。
**人类的视觉系统则完全不同。**我们不会同时处理视野中的所有信息,而是采用一种 "主动"且"选择性" 的策略:
-
**快速一瞥,**获得场景的整体理解
-
**通过眼动,**将高分辨率的中央凹依次对准少数感兴趣区域
-
整合不同注视点的信息,逐步构建对环境的感知
-
**在信息足够时,**主动结束观察
这种机制使我们能有效过滤无关信息,显著降低处理庞杂视觉数据流的复杂度。无论原始视觉环境多复杂,人类视觉的资源需求主要由**"带宽"** 和注视点总数决定,而这两者都可以根据任务需求实现最小化。
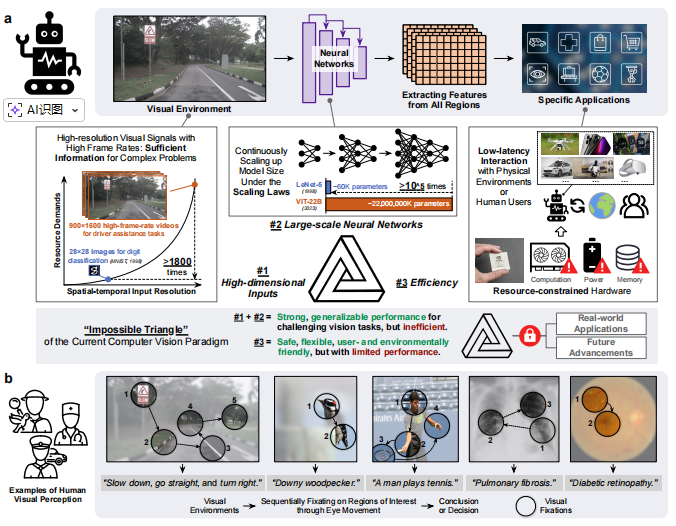
早在2015年,Yann LeCun等人就曾预言,未来的AI计算机视觉系统将通过模仿人类视觉,以智能的、任务特定的方式,序列化地、主动地决定"看哪里" 而取得重大进展。近十年后,来自清华大学自动化系智能感知与学习实验室的研究团队,将这一愿景变为了现实。
二、AdaptiveNN框架:像人一样"看"世界
研究团队提出了AdaptiveNN 框架 ,旨在驱动计算机视觉从**"被动"** 到**"主动且自适应"** 的范式转变。
AdaptiveNN 将视觉感知建模为一个由粗到细的序列决策过程:
-
**初始化:**对视觉环境进行快速"一瞥",获得粗略的全局表征。
-
**循环决策:**在每个步骤中,模型基于当前内部表征,由"视觉智能体"决定:
是否结束观察?(信息是否足够?)
如果继续,下一个应该注视哪里?
-
**信息整合:**处理选中的局部区域,提取特征,并更新动态演化的内部视觉表征。
-
**任务执行:**利用最终的表征来完成既定任务(如分类、检测等)。
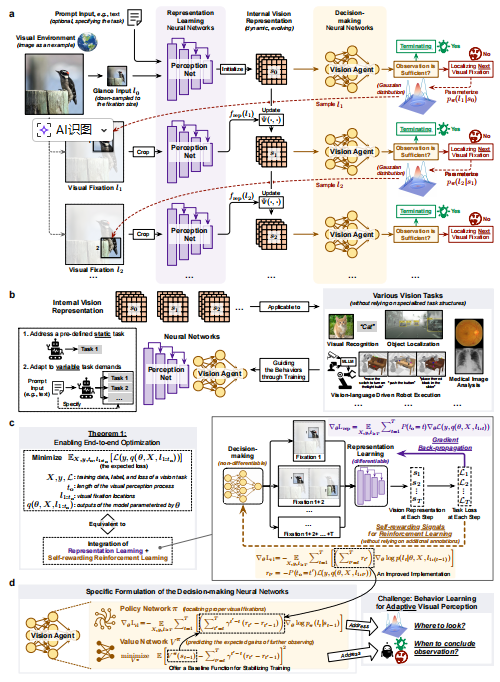
**核心优势在于:**其推理过程的资源需求独立于待感知视觉环境的大小或复杂度。模型只处理对任务至关重要的、最小必要子集的区域,从而在保持大模型高性能的同时,实现了低成本推理。
更值得一提的是,AdaptiveNN 的训练无需依赖特殊的任务结构或额外的标注 。研究团队提出了一种新颖的理论分析,将表征学习与自奖励强化学习相结合,实现了对不可微的决策过程进行端到端优化。
三、高效、灵活、可解释
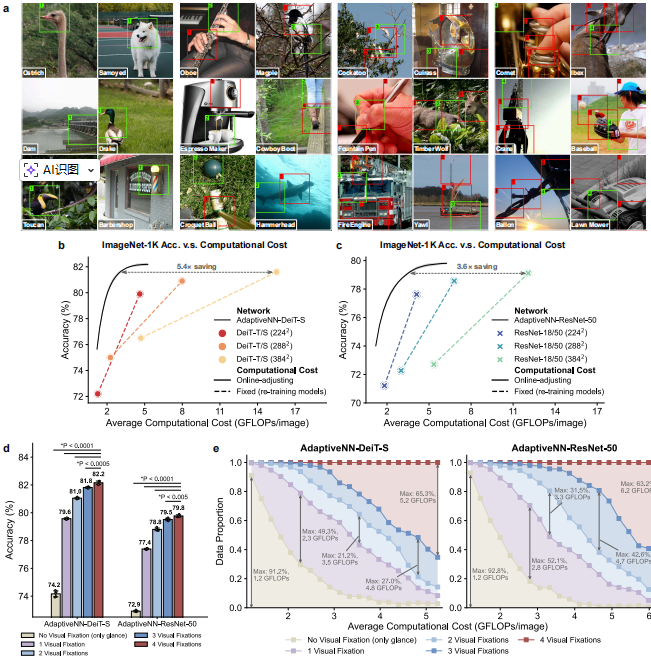
研究团队在9类不同任务、共17个基准测试上全面评估了AdaptiveNN,涵盖大规模视觉理解、细粒度识别、视觉搜索、真实驾驶/医疗场景图像处理,以及多模态大语言模型驱动的具身AI等。
效率大幅提升,最高达28倍
-
ImageNet 图像 识别任务上,AdaptiveNN 在保持同等精度的前提下,将 DeiT-S 和 ResNet-50 模型的推理成本分别降低了5.4倍 和3.6倍。
-
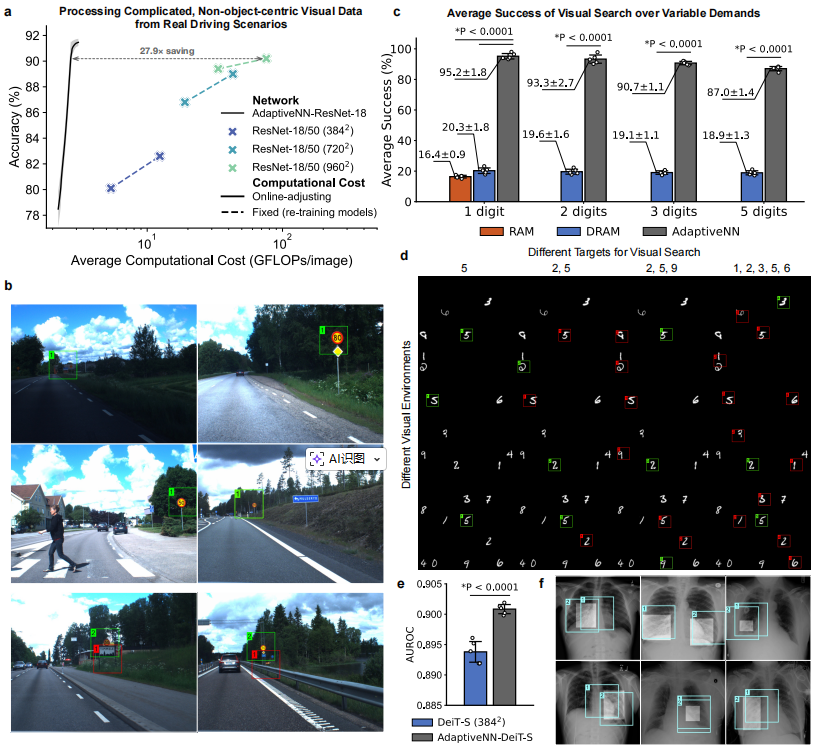
在处理真实驾驶场景(瑞典交通标志数据集)中,AdaptiveNN 实现了惊人的 27.9倍 计算成本降低,在复杂、非物体中心的道路场景中优势尤其明显。
具备类人的灵活性
-
**动态资源适应:**通过在线调整阈值,AdaptiveNN 可以在不重新训练的情况下,灵活调整其推理成本,实现效率与效果的最佳权衡。
-
多变任务适应: 在目标类别和数量可灵活变化的视觉搜索任务中,AdaptiveNN 平均成功率稳定在 ~90%,而现有方法(如RAM、DRAM)仅为 ~20%。
提供有价值的可解释性
-
**注视模式可视化:**模型的注视点模式为了解其决策过程提供了关键窗口。例如,在只使用图像级标签训练的肺炎检测任务中,AdaptiveNN 学到的注视点成功定位了肺部病灶,与人类放射科医生的判断高度一致。
-
**困难程度评估:**模型内部预测的"状态值"与人类对图像识别难易程度的主观评估强相关,表明模型能像人一样评估不同视觉环境的处理难度。
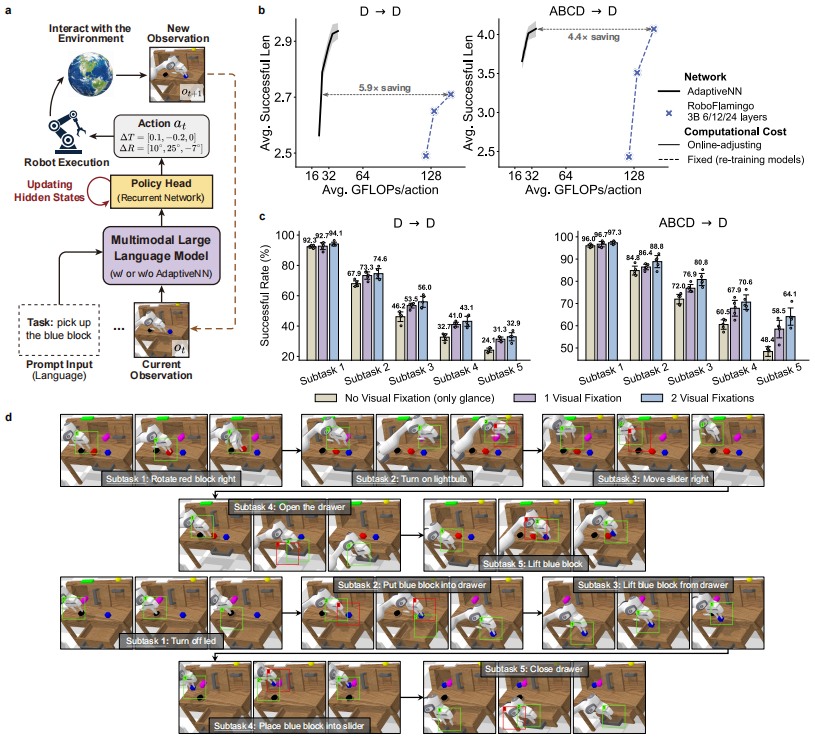
驱动具身多模态大语言模型
将 AdaptiveNN 作为感知模块嵌入到多模态大语言模型中,构建具身AI智能体。在 CALVIN 机器人操作基准测试中,基于 AdaptiveNN 的模型在保持性能的同时,将计算成本降低了 4.4-5.9倍,并能根据语言指令和视觉环境,动态决定"看哪里"。
四、与人类视觉难分伯仲
最引人注目的是,仅在大规模物体识别任务上训练的 AdaptiveNN,其视觉感知行为在许多方面与人类高度一致。
-
注视模式相似: 在 SALICON 数据集上的"零样本"测试中,AdaptiveNN 选择的注视区域与人类平均注视热图的吻合度,达到了单个人类观察者的水平。模型会被人脸、手、人体动作等吸引。
-
**难度评估一致:**模型对图像识别难度的评估,与人类的主观评分显著相关。
-
**通过"视觉图灵测试":**在双盲测试中,人类法官难以区分 AdaptiveNN 的行为与真实人类行为(正确率约50%,与随机猜测无异),而区分随机行为与人类行为则容易得多(正确率≥80%)。
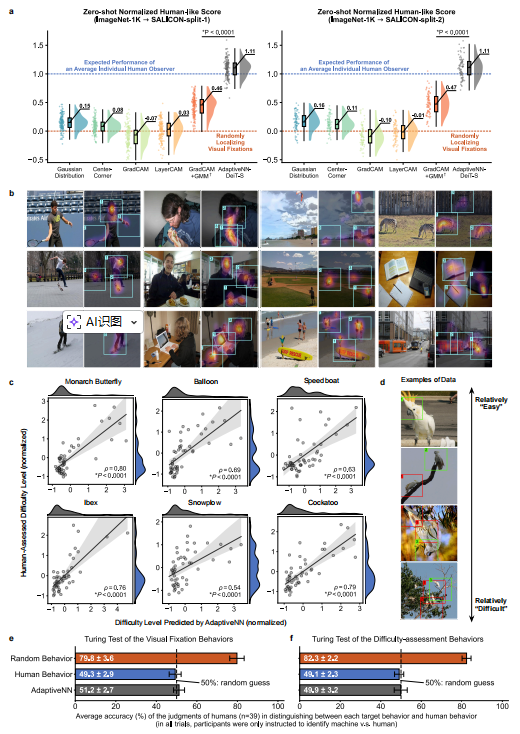
这些发现表明,许多人类的适应性视觉行为,可以通过完成常规视觉任务而习得,无需依赖关于物体、智能体、空间等先天的强归纳偏置。这为从计算视角探索"先天与后天"的认知科学经典问题提供了新工具。
五、新一代机器视觉的雏形
这项研究揭示,引入类人的自适应性 ,是迈向下一代高效、灵活、可解释机器视觉范式的一条充满希望的道路。
AdaptiveNN 不仅在工程上为突破计算机视觉的"不可能三角"提供了切实方案,其高度仿真的类人行为,也使其成为一个强大的计算工具,可用于探究人类视觉认知和行为学习过程。
该框架设计通用,与各种网络架构和任务兼容,为在机器人、可穿戴设备、移动AI、自动驾驶、医疗AI等广泛的实际场景中,部署强大而高效的视觉模型打开了新的大门。
正如论文最后所展望的,这项工作不仅有望推动更强大AI模型的发展,也期待能启发机器学习与更广泛领域之间的跨学科合作。
