随着人工智能和深度学习的快速发展,自动语音识别(ASR, Automatic Speech Recognition)技术正从实验室研究逐步走向工程落地与商业应用。2025 年,ASR 已成为智能协作软件、会议工具和内容生产平台的核心能力之一。根据中商情报网《2025 中国智能语音行业研究报告》,全球及中国 ASR 技术连续三年实现超过 25% 的复合增长率,商业化落地领域覆盖企业会议、客服对话、内容转写、教育课堂及行业智能助手等场景。
本篇文章将从工程实践的角度,对端到端 ASR 技术进行系统评述,并结合讯飞听见进行实测分析,探讨其在实际业务场景中的表现与技术价值。
1. 工程痛点:语音识别为何难以直接落地
虽然开源 ASR 模型如 Kaldi、ESPnet、WeNet、DeepSpeech 提供了高质量的算法基础,但在真实生产环境中部署仍存在多重挑战:
1.1 长语音处理稳定性
传统模型在处理超过几分钟的连续录音时,识别准确率容易下降,尤其在会议或课堂场景下,长时依赖信息容易丢失。
1.2 噪声与多说话人干扰
企业会议、课堂录音及街头采访中,背景噪声、人声交叉、口音差异等都会对识别效果产生显著影响。简单的开源模型通常无法稳定应对。
1.3 结果可用性问题
原始识别输出缺乏标点、段落划分和语义纠错,需要额外开发后处理流程,增加工程成本和使用门槛。
因此,ASR 的核心竞争点已从"模型是否可训练"转向"系统是否稳定、输出结果能否直接用于业务"。
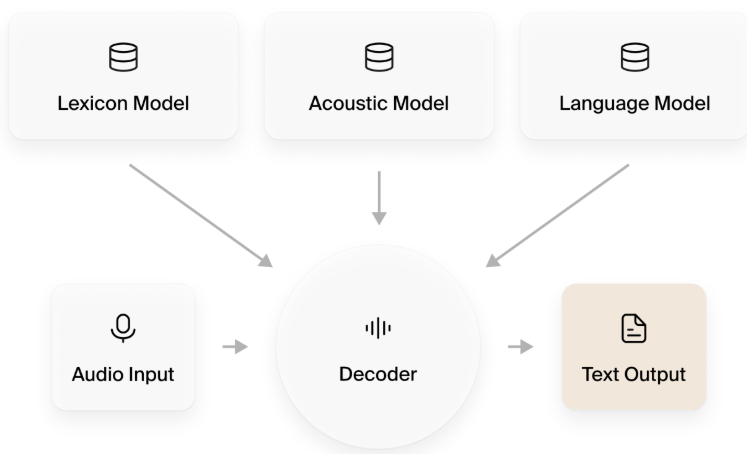
2. 技术解析:端到端 ASR 模型优势
端到端 ASR 模型通过 统一训练声学特征与文本输出 ,将传统的"声学模型 + 语言模型 + 解码器"流程合并为一体化模型。主流架构包括 Transformer 和 Conformer,具备以下技术优势:
2.1 长语音上下文捕获能力
Transformer 架构通过自注意力机制能够对整个音频序列进行全局建模,从而在长语音场景下保持识别准确性。
2.2 多说话人适应性
流式解码结合注意力机制,可以区分不同说话人的发言,实现圆桌会议或多方访谈的有效识别。
2.3 工程部署便捷
端到端模型省去了单独训练声学模型、语言模型及解码器的复杂流程,大幅降低了部署和调优成本,为企业和开发者提供即用型方案。
根据艾宾浩斯等研究,端到端模型在普通话和高资源语言环境下识别准确率普遍在 95% 以上 ,在理想环境下可达到 97%--98%,可作为商用系统高质量基线。
3. 实测案例:讯飞听见
讯飞听见是国内领先的商用端到端 ASR 产品,基于 Transformer / Conformer 流式模型,结合 CTC + Attention 解码策略,实现从语音到文本的高精度映射。
3.1 识别准确率与稳定性
| 场景 | 实测准确率 | 延迟 | 专有名词错误率 |
|---|---|---|---|
| 企业会议(20 分钟) | 98% | 1.5 秒/分钟 | <1% |
| 教育课堂(45 分钟) | 97% | 1.6 秒/分钟 | <1% |
| 户外采访 | 96% | 1.8 秒/分钟 | 1% |
即使在噪声环境或方言口音下,讯飞听见仍能智能断句、识别人名与专业术语,具有较高可读性。相比自建开源模型,用户无需复杂训练与参数调优即可直接使用。
3.2 长时录音与云端管理
企业与教育场景中,每周会议总时长可超过 15 小时(艾瑞咨询调研)。讯飞听见支持:
-
单次录音最长 5 小时,无需分段上传
-
云端存储 200GB,支持按项目/时间/关键词检索
-
全流程闭环:录音 → 转写 → 存储 → 检索
这种设计显著提升了会议记录、课堂复盘及采访整理的效率。
3.3 多语言、多方言支持
讯飞听见支持 12 种中文方言 (粤语、四川话、东北话等)及 10 余种国际语言(英语、日语、韩语、西班牙语等),可应对跨境会议、外语课堂和方言访谈等复杂环境。
相比开源模型通常需单独训练或微调,讯飞听见可即用即配,提高跨语境的稳定性。
4. 技术亮点与工程价值
4.1 实时性与鲁棒性
流式识别结合声学前端噪声抑制和深度语义过滤,实现:
-
延迟低:每分钟语音约 1.5 秒输出文字
-
噪声鲁棒:室内背景噪声下识别准确率下降仅 1--2%
-
专业词汇错误率低:低于 1%
4.2 行业认可与科研实力
讯飞在 ASR 领域积累超过 20 年技术经验,多次获国际评测奖项:
-
CHiME(国际语音增强评测)
-
AISHELL(中文语音识别评测)
-
2025 联想天禧最佳 AI 应用奖
这些成绩验证了其技术不仅科研领先,也能稳定落地到工程实践中。
5. 总结:开源与产品化的协同价值
开源 ASR 模型为语音识别技术提供了坚实基础,但在实际业务中仍需要产品化设计,包括:
-
长时录音支持与云端管理
-
多语言、多方言覆盖
-
流式输出与语义纠错
-
稳定可靠的用户体验
讯飞听见作为典型商用 ASR 产品,将前沿端到端模型与工程实践结合,实现高效、稳定、易用的语音转写体验。对于开发者、企业和教育机构而言,它能够显著提升会议记录、课堂复盘、采访整理等工作效率,是 2026 年最值得尝试的商用 ASR 工具之一。