ChatTS: Time Series LLM for Understanding and Reasoning
1、保留值的时间序列归一化
时间序列的数值特征至关重要,因为现实世界的应用通常涉及特定的数值查询(例如,询问最大 CPU 利用率),时间序列数据归一化可能导致丢失原始数据信息。
方案 :首先,我们对每个时间序列数组应用标准的最小 - 最大归一化 (0-1 缩放)。然后,对于每个时间序列 ,我们在文本中作为提示的一部分包含归一化参数 -"值缩放 "(归一化期间的缩放因子)和 "值偏移"(归一化期间应用的偏移)。
代码实现:
① 归一化:计算均值并进行中心化,计算缩放因子
② 构建元数据提示词:它会根据时间序列的统计信息 生成一段特殊的文本描述,[offset=0.1234|scaling=1.0000|length=100|max=5.5|min=-2.1|left=0.1|right=0.5]<ts><ts/>
Processing_qwen3_ts.py文件实现了:
① 实现了保留值的时间序列归一化
② 通过将自然语言和原始时间序列转化为TokenID + 归一化时间序列张量
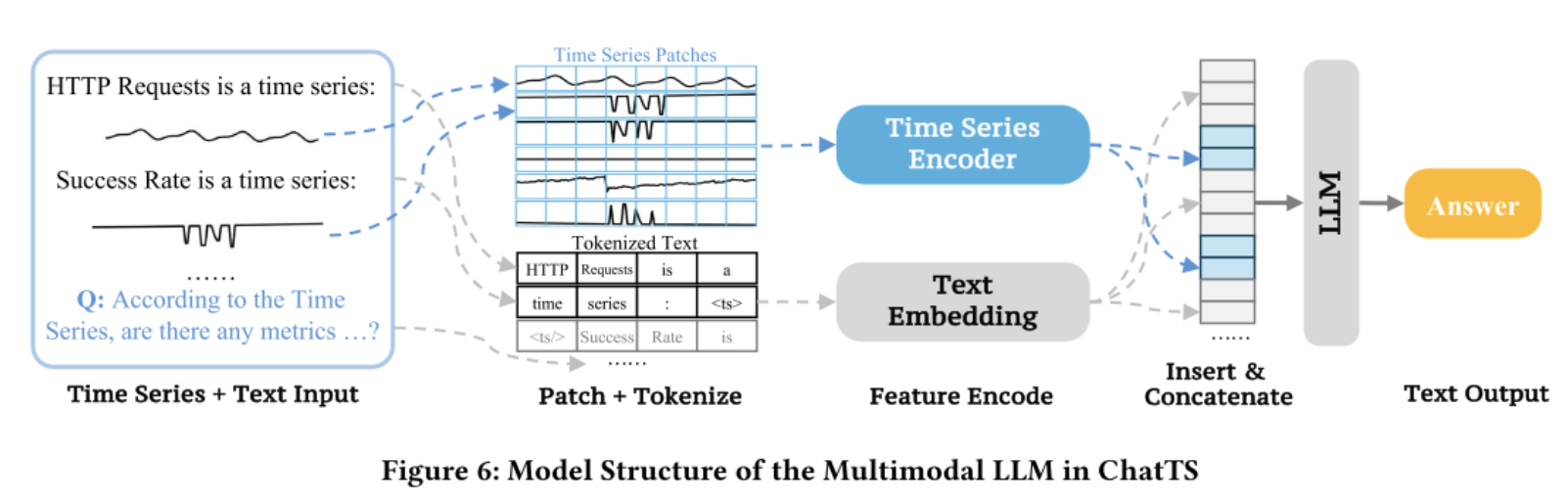
2、整体架构
该模型采用了 "Patch + Projection" 的多模态融合范式(类似 Vision Transformer 或 LLaVA 处理图像的方式):
- 基座模型 (Backbone): 使用
Qwen3Model作为大脑,负责处理上下文和生成文本。 - 编码器 (Encoder): 使用一个轻量级的
TimeSeriesEmbedding(MLP结构) 将时间序列切片(Patch)并映射到 LLM 的特征空间(Embedding Space)。 - 融合机制 (Fusion): 在输入层(Input Embedding layer)直接将文本的 Embedding 和时间序列的 Embedding 拼接在一起。