文章目录
- 摘要
- Abstract
- [一、《Learning Transferable Visual Models From Natural Language Supervision》](#一、《Learning Transferable Visual Models From Natural Language Supervision》)
-
- [1. 摘要](#1. 摘要)
- [2. CLIP完整流程](#2. CLIP完整流程)
- [3. 方法](#3. 方法)
-
- [3.1 自然语言监督](#3.1 自然语言监督)
- [3.2 创建足够大的数据集](#3.2 创建足够大的数据集)
- [3.3 选择一种高效的预训练方法](#3.3 选择一种高效的预训练方法)
- [3.4 模型的选择和缩放](#3.4 模型的选择和缩放)
- [3.5 训练](#3.5 训练)
- [4. 实验部分](#4. 实验部分)
- [二、《ColPali: Efficient Document Retrieval with Vision Language Models 》](#二、《ColPali: Efficient Document Retrieval with Vision Language Models 》)
-
- [1. 摘要](#1. 摘要)
- [2. 介绍](#2. 介绍)
- [3. 问题制定及相关工作问题设置](#3. 问题制定及相关工作问题设置)
-
- [3.1 文本检索方法](#3.1 文本检索方法)
-
- [3.1.1 在文本空间中进行文本检索](#3.1.1 在文本空间中进行文本检索)
- [3.1.2 神经检索器。](#3.1.2 神经检索器。)
- [3.1.3 后期交互的多向量检索](#3.1.3 后期交互的多向量检索)
- [3.1.4 检索评价](#3.1.4 检索评价)
- [3.2 融合视觉特征](#3.2 融合视觉特征)
- [4. ViDoRe基准](#4. ViDoRe基准)
-
- [4.1 ViDoRe基准的设计](#4.1 ViDoRe基准的设计)
- [4.2 评估当前系统的非结构化](#4.2 评估当前系统的非结构化)
- [5. 基于后期交互的视觉检索](#5. 基于后期交互的视觉检索)
-
- [5.1 架构](#5.1 架构)
- 总结
摘要
本周主要精读两篇文献。《Learning Transferable Visual Models From Natural Language Supervision》主要讲述CLIP模型,该模型通过对比学习进行预训练,完成后可以进行零样本迁移,并且模型表现良好。同时考虑到输入数据为图文对,有的文本存在多重含义,因此具体化提示词,增加匹配准确性。
《ColPali: Efficient Document Retrieval with Vision Language Models 》主要介绍Colpali模型和ViDoRe基准。Colpali模型直接读取视觉信息多向量化,并根据得到向量与查询向量后期交互进行文本检索。ViDoRe基准则为新的同时考虑文本与视觉特征的文本检索的评估方法。
Abstract
This week, I focused on reading two papers intensively.《Learning Transferable Visual Models From Natural Language Supervision》 mainly introduces the CLIP model. The model is pre-trained via contrastive learning and enables strong zero-shot transfer performance after pre-training. Considering that the input data consists of image-text pairs and some texts have multiple meanings, prompt engineering is used to make prompts more specific and improve matching accuracy.
《ColPali: Efficient Document Retrieval with Vision Language Models》 mainly presents the ColPali model and the ViDoRe benchmark. The ColPali model directly encodes visual information into embeddings, and performs document retrieval by computing the similarity between the resulting embeddings and query embeddings. The ViDoRe benchmark is a new evaluation approach for document retrieval that considers both textual and visual features.
一、《Learning Transferable Visual Models From Natural Language Supervision》
《Learning Transferable Visual Models From Natural Language Supervision》------利用自然语言的监督信号学习一个可迁移的视觉模型
可迁移:进行下游任务的时候不需要再次训练模型
1. 摘要
- 传统视觉模型严格限制物体类别,当出现一个新的类别时模型需要重新训练
- CLIP用4亿图文对做完预训练后,可以零样本完成很多视觉任务,在不少基准测试上表现相当不错
2. CLIP完整流程
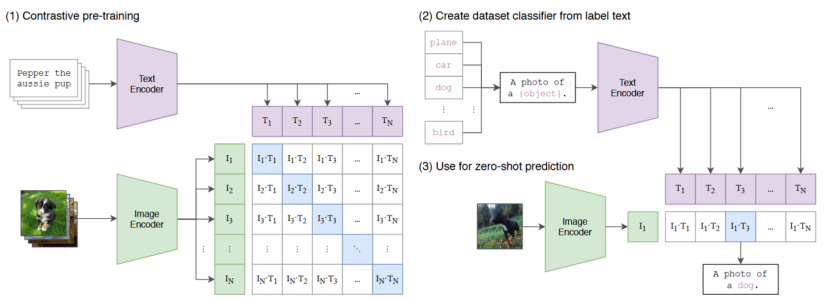
(1)对比预训练(Contrastive pre-training)
目的:让模型学会将图像和文本映射到同一个向量空间,并让匹配的图文对在该空间中靠近,不匹配的远离。
输入:一批(batch)图文对,例如图中左边是一个文本"Pepper the aussie pup"(一只澳洲牧羊犬的名字),对应的图像是该小狗的照片。
说明:文字编码器和图片编码器将文本和图片转换为特征向量,N×N的矩阵为计算所有图像与所有文本之间的余弦相似度。
训练目标:让矩阵对角线上的元素的相似度尽可能高,而非对角线元素(负样本对)的相似度尽可能低。
(2)从标签文本构造数据集分类器(Create dataset classifier from label text)
目的:将下游任务的类别标签转化为模型可以理解的文本描述,从而为后续的零样本分类做准备。
过程说明:对于每个类别,我们构造一个提示模板(prompt template),例如 :"A photo of a {object}."(一张{物体}的照片)。
将这些文本输入到训练好的 Text Encoder 中,得到每个类别对应的文本特征向量 ,这些向量就构成了一个"分类器",每个向量代表该类别的语义嵌入。
补充:
提示工程解决"分布偏移"问题
在零样本分类时,如果我们直接把单个标签(如"猫")输入给文本编码器,模型在预训练时从未见过孤立、无上下文的单词。这造成了分布偏移:训练和测试时的输入格式不一致。
提示工程的核心作用:消除这种分布偏移。通过将标签放入一个通用的句子模板中(如"A photo of a {label}"),让测试时的输入格式更接近训练时看到的自然语言。
(3)用于零样本预测(Use for zero-shot prediction)
目的:对一张未见过的图像进行分类,无需任何针对该数据集的训练。
过程说明:输入一张新的图像(例如图中下方的小狗照片),通过 Image Encoder 得到图像特征向量,计算该图像特征与(2)中所有"分类器"的点积,得到相似度分数。最后,选择相似度最高的类别作为预测结果。图中示例显示,与"A photo of a dog."的相似度最高,因此模型正确地将图片分类为"狗"。
3. 方法
3.1 自然语言监督
**定义:**用日常语言作为学习信号,使模型理解视觉内容,而不是使用人工标注的固定类别标签。
**优势:**不仅能够学习表征,还能将该表征与语言建立关联
"表征与语言建立关联"的具体解释:
监督信号从"离散标签"变成了"连续语言"
传统监督学习:给一张图片,人工打上一个标签,比如"猫"。模型学到的是"猫"这个抽象的、离散的符号。它不知道猫和"宠物"、"毛茸茸"、"会喵喵叫"这些概念有什么联系。
自然语言监督:给一张图片,配上一句描述,比如"一只橘猫躺在沙发上晒太阳"。模型学到的不仅是"猫"这个符号,还理解了图像内容与语言描述中所有词汇的对应关系(猫、橘色、躺着、沙发、太阳)。语言本身的丰富性和结构性,为模型提供了更强大的监督信号。
3.2 创建足够大的数据集
"现有数据集未能充分反映这种可能性"的原因:核心的是现有数据集的任务形式过于简单,无法衡量模型从丰富语言中学到的开放世界知识。
"任务形式过于简单"说明:数据集过于精确,不符合日常人类丰富表达方式。因此无法体现出模型在理解复杂语义、进行开放知识迁移方面的能力。
例如:给了一张"躺在沙发上沐浴阳光的橘猫"照片。数据集测试只需要知道图片中有猫,而CLIP可以获取到"沙发","阳光","橘猫"等信息,答案过于简单,未能发现CLIP真正的能力。
3.3 选择一种高效的预训练方法
最终选择的预训练方法以"训练效率"为依据。
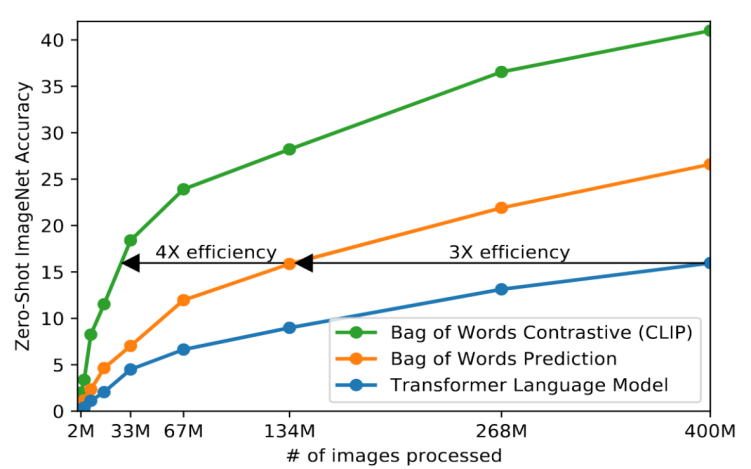
图表表示数据量/模型对视觉-语言的理解的精确度,图片中展示三种文本编码器
①BOW:简单的文本编码(词袋)。把一段文字看作一个"词的集合"(bag),不考虑词序,只关心每个词出现的次数。
②CLIP:BOW+对比学习
③Transformer语言模型
结论:Transformer语言模型的学习速度比预测文本的词袋( BOW )编码的基线慢3倍。将CLIP的预测目标替换为对比目标,又进一步提高了4x的效率。
CLIP 与 Transformer语言模型 都尝试预测每张图像所对应文本的确切词语,但实际很难办到,同时图像对比表征学习方面的研究发现:对比目标可以比等效的预测目标学习到更优的表征。因此探索训练系统预测哪条文本整体上与哪张图像配对。
CLIP核心实现的伪代码
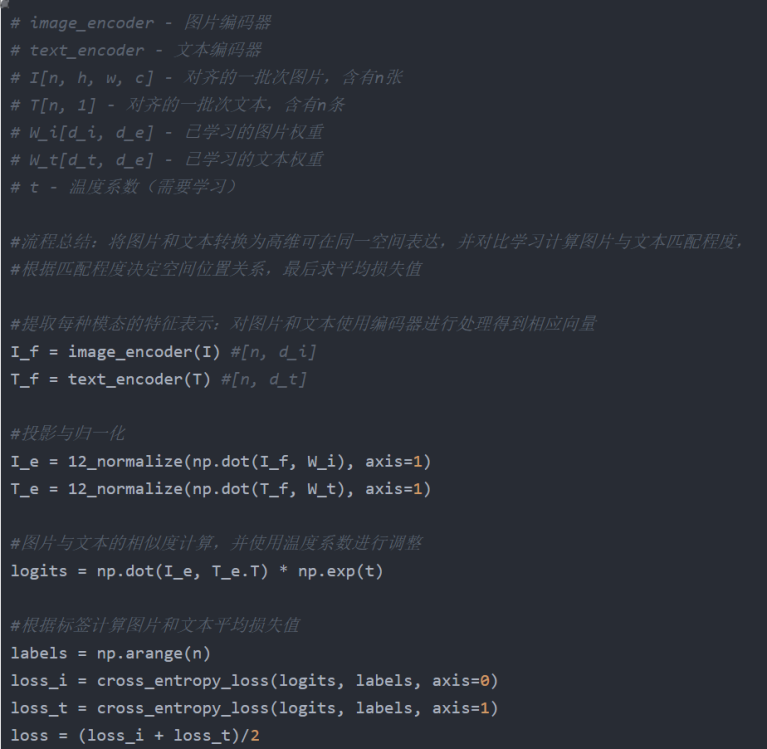
说明:
1,训练过程中仅使用从调整大小后的图像中随机裁剪方形区域作为数据增强。
2,使用线性投影将每个编码器的表示映射到多模态嵌入空间(投影与归一化部分):数值计算同线性回归,但是线性回归目的是获取具体预测值,而线性投影本质上是一个"维度变换"操作,目的是对齐模态------让图像向量和文本向量在同一个空间里可以比较。
3,控制softmax中logits范围的温度参数 τ 在训练过程中以对数参数化的乘法标量形式直接优化,从而避免将其作为超参数,且确保值为整数。
3.4 模型的选择和缩放
图片Encoder,考虑两种架构:
1,ResNet-50作为基础结构
使用方式:引入了ResNetD的改进(He等人,2019)以及抗锯齿的rect-2模糊池化方法(Zhang,2019)。此外,将原始的全局平均池化层替换为注意力池化机制。
补充:
ResNetD相对于ResNet-50有什么改进
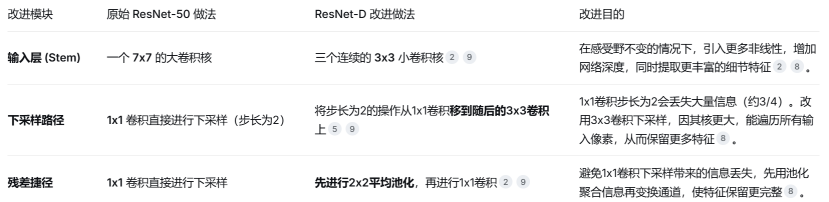
说明:
输入层改进目的:
①增加非线性,提升特征抽象能力
7×7卷积只有一次卷积操作,只有一次非线性变换。
三个3x3卷积:包含了三次卷积,有多阶段的非线性变换,可以提取出更高质量的低级特征(如边缘、纹理组合)。
非线性变换:指的是激活函数,而不是卷积本身。卷积是线性变换。
②保持感受野,同时增加网络深度:
感受野:一个像素点,对应到输入图像上映射的区域大小
网络的深度增加,参数数量却更少(三个3x3的参数总量是 3x3x3=27,小于一个7x7的49),计算效率更高,表达能力却更强。
③信息保留更细腻:
7x7卷积一步到位地降采样,可能会丢失一些精细的边缘信息。
三个3x3卷积是逐步降采样,让信息过渡更平滑,丢失更少。
(2)"抗锯齿的rect-2模糊池化方法"
- 池化(Pooling) :"信息压缩"或"降采样/下采样"的方法。核心作用是降低特征图的空间尺寸,同时保留最重要的信息。
- 目的:池化后特征图的尺寸减少计算量也减少,同时包含信息变多,后面的层能看到更大的原始图像区域,并在一定程度上防止过拟合。
- 抗锯齿的rect-2模糊池化方法为模糊图片锯齿边缘让图片边缘更柔和。主要做法:在池化之前,先对特征图应用一个2x2的模糊滤波器。模糊可以预先滤除图像中的高频噪声和细节,使得后续的池化过程不容易因为"错过"某些像素而产生信息失真(即混叠现象,表现为锯齿),从而让最终的特征图边缘更柔和、更准确。
【将原始的全局平均池化层替换为注意力池化机制。该注意力池化通过单层"Transformer风格"的多头QKV注意力实现,其中查询向量由图像的全局平均池化表示进行条件化。】
用交叉注意力机制改进全局池化的方法:先用全局平均池化得到一个初始的全局描述,再用它作为查询,与特征图的每个位置进行交互,计算出更精准的加权特征,从而得到更高质量的图像整体表示。
- 交叉注意力:用整体特征(一个向量)去和每个位置交互,获取每个位置的重要性
- 目的:让模型在聚合图像特征时能更智能地聚焦于重要区域。
- 全局平均池化:卷积后得到的特征图,形状为 H, W, C(高度、宽度、通道数)。对所有空间位置(H*W)求均值,共C个通道,最终得到一个长度为 C 的向量,这个向量被当作整张图像的全局特征表示。
- 注意力池化机制:让模型学习每个空间位置的重要性(权重),然后对特征进行加权求和,不再简单求均值。(权重通过学习获取)
- "查询向量由图像的全局平均池化表示进行条件化":快速扫描图片有整体印象(全局平均池化),在已有印象基础上判别区域重要性,最后根据重要性重新整合信息。

文本Encoder:Transformer结构
研究发现,在模型的宽度、深度和分辨率三个维度上同时分配额外的计算资源,其效果优于仅在单一维度上增加计算量。对于文本编码器,仅在宽度上进行扩展,使其与ResNet宽度的增幅成比例,而不改变深度。
注:
- 深度:指的是网络的层数(有多少个Transformer Block)。
- 宽度:指的是每一层的特征维度。
- 原因:
1,容量匹配:如果图像特征维度很大,而文本特征维度太小,文本可能没有足够的表达能力去"匹配"图像中的丰富信息。让两者按比例增宽,有助于保持多模态对齐的质量。虽然深度对计算量影响级是线性,宽度为平方级,但是增加深度无法解决信息量不匹配问题。
3.5 训练
【结合解耦的权重衰减正则化,该正则化仅应用于非增益或偏置的权重上;学习率采用余弦退火调度。】
在训练过程中,采用了 AdamW 优化器(实现了解耦的权重衰减),并且只对模型的权重参数(如卷积层权重)施加权重衰减,而批归一化层的增益/偏置等参数则不受正则化影响。同时,学习率按照余弦退火策略动态调整,从初始值平滑下降到预设的最小值。
1,解耦的权重衰减正则化
权重衰减(Weight Decay) :一种正则化技术,目的是防止模型过拟合。
对比权重衰减的两种做法:
传统做法(如 SGD + L2 正则化):在计算梯度时,同时考虑损失函数的梯度和权重衰减项,两者耦合在一起(下图括号部分内容)。
解耦的权重衰减(如 AdamW):将权重衰减从梯度更新步骤中分离出来。具体来说,在使用 Adam 等自适应优化器时,梯度计算时不包含权重衰减项,而是在参数更新完成后,直接对参数执行权重衰减(即参数乘以一个小于 1 的系数或减去一个固定比例)。这样做的好处是避免了自适应学习率对权重衰减的影响,使正则化更加稳定和有效。
2,"仅应用于非增益或偏置的权重上":
增益 和 偏置:通常指批归一化层中的缩放参数 γ和平移参数 β。也就是说,只有模型的真正"权重"(如卷积核、全连接层的权重矩阵)才受到权重衰减的约束,而归一化层的参数和偏置项保持不变,如果对它们也进行衰减,可能会限制模型的表达能力,甚至导致训练不稳定。
3,余弦退火调度
- 学习率调度:训练过程中动态调整学习率的方法。
- 余弦退火:一种学习率调度策略,使学习率按照余弦函数的形状从初始值逐渐下降到最小值,这有助于模型在初期快速探索,后期精细收敛。
- 为什么使用余弦退火?
与分段常数衰减相比,余弦退火没有陡峭的下降,变化更平滑,往往能带来更好的收敛效果。此外,在某些变体(如 SGDR)中,余弦退火还可以结合"热重启",进一步提升性能。
4. 实验部分
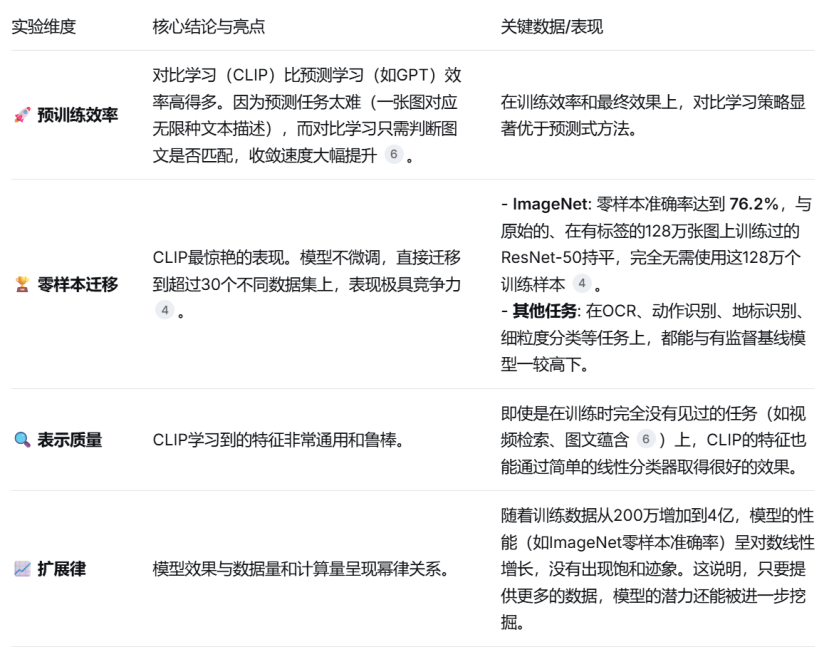
提示工程至关重要
在零样本分类时,将类别标签放入特定的提示模板(如"A photo of a {label}")比直接使用标签名效果要好得多。对于某些特殊任务(如卫星图像识别),使用"A satellite photo of a {label}"等定制化提示,能显著提升性能。
解释:
1,在零样本分类时,如果我们直接把单个标签(如"猫")输入给文本编码器,模型在预训练时从未见过孤立、无上下文的单词。这造成了分布偏移:训练和测试时的输入格式不一致。
提示工程的核心作用:消除这种分布偏移。通过将标签放入一个通用的句子模板中(如"A photo of a {label}"),让测试时的输入格式更接近训练时看到的自然语言。
2,提示工程提供更精准的语义定位,同时让多义词消歧。
提供更精准的语义定位
- 当使用"A satellite photo of a {label}"这样的定制化提示时:对于定制提示:"satellite photo"这几个词激活了模型对俯视视角、卫星图像特征的预期。模型会去关注图像的纹理、颜色分布是否符合卫星图的特点,而不是去期待看到车轮、车窗等细节。
- 效果:模型在特征空间中的搜索范围被收窄了,它更清楚地知道"该找什么",从而更容易匹配到正确的视觉特征。
让多义词消歧
- 以"crane"为例:可以指"起重机",也可以指"鹤"。如果你用"A photo of a crane, a bird"和"A photo of a crane, a machine"这样的提示,模型就能根据上下文准确锁定目标。
效果:通过上下文,模型能够把注意力引导到正确的语义维度上,排除其他无关维度的干扰。
二、《ColPali: Efficient Document Retrieval with Vision Language Models 》
1. 摘要
传统的文档搜索需要先做OCR把图片变成文字,然后处理文本,建立索引,最后搜索。ColPali新模型直接看文档图片,从文档页面的图像中产生高质量的多向量嵌入
,输出的是文字层面的理解。通过生成精细的图像特征和高效的匹配技术,实现了更准确、更快速、更简单的文档检索。
多向量嵌入:模型看完一页文档后,不是只给它打一个标签(比如"这是一张财务报表"),而是生成很多个特征向量,根据内容语义和视觉布局自动生成。
说明: 一个向量可能对应整个表格,即使表格在物理上是一个连续的区域;另一个向量可能对应一个句子,即使这个句子跨了两行。
核心机制:后期交互匹配

2. 介绍
文献检索是将用户查询与给定语料库中的相关文档进行匹配。然而,在实际中,有效的文献检索的主要性能瓶颈是来自先前的数据摄取管道。我们通常发现优化摄入管道比优化文本嵌入模型在视觉丰富的文档检索上有更好的性能。
优化摄入管道不仅仅是将数据变得更像自然语言,它是对文档进入检索系统前所有预处理步骤的改进,目的是让最终生成的向量能更完整、准确地表达原始文档的内容。
传统文本检索标引一个 PDF 预处理如下:
① 用 OCR 或解析器提取文字;
② 用布局检测模型切分段落、标题;
③ 设计合理的分块策略,把语义相关的句子组合在一起;
④ 高级做法还会把图表等视觉元素用自然语言描述出来,方便后续的文本嵌入模型处理。
对于图表、复杂排版这类视觉丰富的文档,把精力花在优化这些预处理步骤上,往往比单纯改进文本嵌入模型本身更能提升检索效果。
(本文指的嵌入模型:将图像分割成Patches并进行embedding处理的模型。)
贡献1:文献检索系统不应该仅仅根据文本嵌入模型的能力来评估,还应该考虑待检索文档的上下文和视觉元素。为此,创建并公开发布了ViDoRe,这是一个全面的基准,用于评估页面级文档检索系统,其覆盖的领域、可视元素和语言非常广泛。
贡献2:提出了一种基于视觉语言模型的新概念和模型架构,可以高效地从文档的视觉特征中索引文档,从而允许后续的快速查询匹配和后期的交互机制。
3. 问题制定及相关工作问题设置
一个检索系统对来自语料库D的文档d与查询q的相关性进行评分。计算语料库中每个文档的相似度得分s( q , d)∈R,创建一个排名,我们可以用来提取最相关的文档。
在这项工作中,我们专注于页面级检索:给定一个查询,被系统检索到的是正确的文档页面。单个页面的文档术语:原子检索元素。
由于我们专注于具有潜在大语料库规模的实际工业检索应用( RAG ,搜索引擎),因此对评分系统施加了延迟约束。 当前大多数检索系统可以分解为:
( 1 )离线索引阶段,即建立文档索引;
( 2 )在线查询阶段,即查询与索引中的文档相匹配,其中低延迟对用户体验至关重要。在这些工业限制下,我们确定了一个有效的文献检索系统应该表现出的三个主要特性:
( R1 )强大的检索性能,用标准的检索指标来衡量;
( R2 )快速在线查询,通过平均延迟来衡量;
( R3 )高吞吐率语料库索引,即给定时间框架内可嵌入的页面数量。
注:
"延迟约束"中的"延迟"指的是系统的响应时间,"约束"指的是一个强制性的上限。延迟约束就是为了确保系统在处理海量数据和大量并发请求时,依然能在几百毫秒内返回结果
3.1 文本检索方法
3.1.1 在文本空间中进行文本检索
基于词频的统计方法如TF - IDF 、BM25等由于其简单高效仍被广泛使用。
基于微调的大语言模型的神经嵌入模型在各种文本嵌入任务上表现出了最先进的性能。该嵌入模型可以更好地理解文本特征因此展现出良好的性能。
3.1.2 神经检索器。
在双编码器模型中,文档被独立地离线映射到稠密的向量空间。查询在线嵌入,并通过快速余弦距离计算与文档匹配。
一个速度较慢,但性能稍好的交叉编码系统将查询和文档连接起来作为一个单一的输入序列,并迭代地将属性匹配分数分配给每个可能的组合。这使得查询词和文档词之间能够进行充分的注意力计算,但以牺牲计算效率为代价,因为| D |编码的传递必须在线完成。
(双编码器的替代方案是交叉编码器)
说明:
(1)双编码器: 是一种将查询和文档分开处理的架构。核心思想:训练两个编码器(通常是两个结构相同或类似的神经网络),一个负责把查询变成向量,一个负责把文档变成向量。有时候这两个编码器是共享参数的。

(2)稠密向量
稀疏向量(Sparse Vector):语料库长度的向量中,文档里出现了哪个词,那个位置就是1,其余都是0。这个向量绝大多数位置是0,所以叫"稀疏"。
稠密向量:神经网络生成的向量里的每一个数都不是0,而是充满各种小数的实数。这个向量虽然维度远小于稀疏向量,但每个维度都包含了经过神经网络压缩后的、抽象的语义信息,所以叫"稠密"。
(3)为什么映射到稠密的向量空间?
①解决"语义鸿沟":稀疏向量只能做字面匹配。搜"苹果",它找不到关于"iPhone"的文档,因为字面不同。稠密向量通过训练,可以把语义相近的词在空间上拉近。在这个空间里,"苹果"和"iPhone"的向量距离很近。
②捕捉深层特征:稠密向量的每一个维度对应神经网络学习到的某种潜在语义特征(比如某个维度可能负责检测文本是否在讨论"科技",另一个维度负责检测是否在讨论"水果")。
③效率的提升:虽然维度少了,但信息密度高了,计算也更高效。
(4)查询在线嵌入是否是在有网络的情况下匹配文档与输入词的嵌入向量?
在线(Online):指"实时发生"、"在用户等待的过程中",而不是"连上互联网"

(5)交叉编码器系统是什么?
核心思想:它是把查询和文档直接拼在一起当成一句话,然后一次性输入给一个大的语言模型。
为什么更慢?
因为对于每一对(查询, 文档),它都需要让模型重新计算一遍。如果用户搜了一个查询,要比较1万个文档,它就要依次输入模型1万次。这是巨大的计算量。
在双编码器中,1万个文档只需要算一次(离线算好了),查询算一次,然后做1万次快速余弦距离就行。
为什么性能更好?
通过Transformer的注意力机制,模型可以精确地计算查询里的某个词和文档里的某个词有多匹配。比如多义词含义的判定。
3.1.3 后期交互的多向量检索
每个文档词元被预先计算嵌入并索引。运行时可以计算单个查询词元嵌入的相似度。利用单个查询词元和文档词元之间的丰富交互,同时利用双编码器带来的离线计算和快速查询匹配优势。
3.1.4 检索评价
在实际环境中,没有一个基准来评估文献检索系统;以端到端的方式,跨越多个文档类型和主题,并通过评估文本和视觉文档特征的使用。
3.2 融合视觉特征
对比视觉语言模型。
通过对比损失对齐视觉和文本编码器,并利用细粒度的后期交互机制增强跨模态匹配。
细粒度的后期交互机制:每个文本 token 与每个图像 patch 计算相似度,然后聚合得到最终匹配分数,从而捕捉更精细的空间位置关系。
视觉丰富的文档理解。
为了超越文本,一些以文档为中心的模型将文本标记与视觉或文档布局特征联合编码。大型语言转换模型( LLMs )与视觉转换模型( ViTs ) 相结合,创建了VLMs ,将经过对比训练的ViT模型的图像块向量作为输入嵌入到LLM中,并与文本标记嵌入进行串联。
4. ViDoRe基准
ViDoRe是一个使用视觉特征进行文献检索的综合基准。
4.1 ViDoRe基准的设计
旨在综合评估检索系统在页面级别匹配相关文档的能力。
通过学术任务、实践任务、评估指标三位一体的架构,实现对页面级文档检索能力的全面判别
学术任务:对比colpali与其他优秀模型对于同一数据集的表现
实际任务:将模型放入新的,实际的任务中看表现情况
评估指标:把检索结果的好坏转化成一个具体的数字,方便直接比较。
数据集组成:
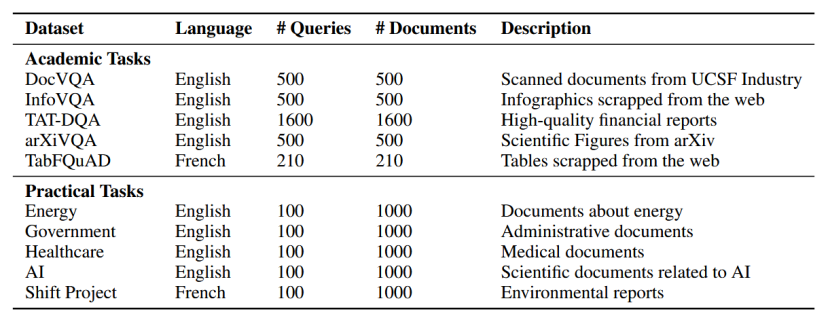
4.2 评估当前系统的非结构化
Unstructured:在最高分辨率设置下,将PDF文档解析成高质量的文本块。
Unstructured的工作流程:
①布局检测:利用深度学习视觉模型识别标题、文档结构。
②OCR识别:对非原生(扫描版)PDF提取文字。
③表格重建:用专门方法检测和重构表格。
④分块策略:利用检测到的文档结构(如按标题)在拼接文本时保留章节边界。
三种核心配置:
配置一:纯文本
做法:只保留文本元素,将图形、图像、表格视为噪声并过滤掉。
配置二:Unstructured + OCR
做法:对表格、图表和图像运行OCR,提取其中的文字,然后由Unstructured处理并独立分块。
配置三:Unstructured + 描述
做法:将视觉元素输入强大的专有视觉语言模型,生成高度详细的文本描述,再将描述文本纳入检索。
主要发现
1,性能最佳:将Unstructured解析器与视觉信息结合(无论是通过OCR还是描述生成)取得了最好的检索效果。
2,对比VLM表现滞后:单纯的对比视觉语言模型(如Jina CLIP等)在文档检索任务上表现不佳。
3,延迟问题:
(1)索引延迟(R2):PDF解析管道非常耗时,尤其是在加入OCR或描述生成策略时。
(2)查询延迟(R3):所有评估系统的在线查询速度都很好,因为查询编码和余弦相似度匹配很快。
5. 基于后期交互的视觉检索
5.1 架构
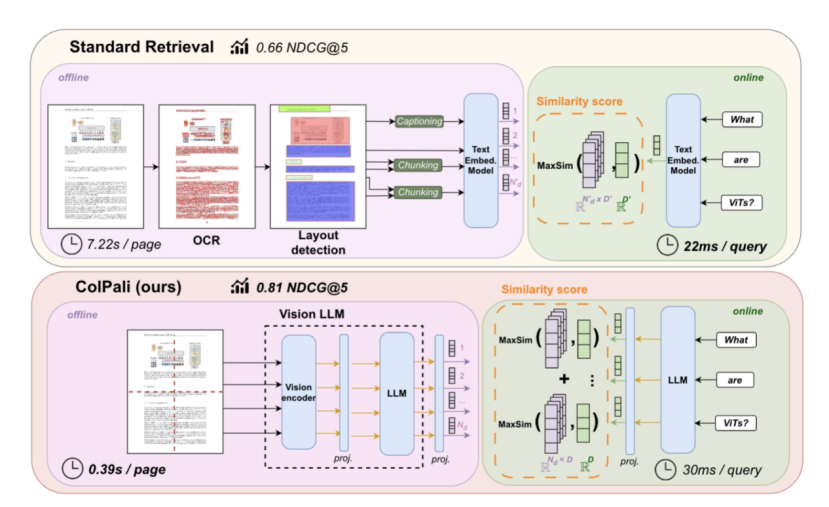

实际上,ColPali的真实工作方式是:
1,把PDF页当成一张完整图片输入Vision LLM
2,Vision LLM把图片分成N×N个patch(比如16×16)
3,每个patch生成一个向量 → 得到256个向量
4,这些向量通过训练,自动学会关注不同的语义内容(标题、表格、图表等)
总结
CLIP开创了视觉语言预训练与零样本迁移的范式;ColPali则开创了直接利用视觉信息进行端到端文档检索的新方法:
1,CLIP 模型
核心理念:通过对比学习,在海量图文对数据上预训练,打通视觉与语言模态。
核心突破:实现了强大的零样本迁移能力,无需下游任务数据即可进行分类。
实用技巧:通过提示词工程(具体化文本描述)来消除歧义,进一步提升匹配准确性。
2, ColPali 模型
核心理念:革新文档检索方式,直接利用视觉语言模型读取文档的视觉信息,绕过传统的OCR或布局解析流程。
技术创新:采用多向量化表示文档和查询,并通过后期交互机制在最后阶段进行细粒度匹配,兼顾了效率与精度。
配套基准:提出了ViDoRe基准,专门用于评估模型在考虑文本与视觉特征(如复杂排版、图表)的文档检索任务上的表现。