摘要:在未知环境中实现快速适配是机器人实现规模化现实世界自主化的关键要求,然而现有方法要么依赖穷尽式的环境探索,要么采用刚性的导航策略,均无法实现良好的跨环境泛化。本文提出 VLN-Zero------ 一款分两阶段的视觉语言导航框架,该框架利用视觉语言模型高效构建符号化场景图,并实现零样本的神经符号导航。在探索阶段,通过结构化提示词引导基于视觉语言模型的探索过程走向具备信息性和多样性的轨迹,最终生成紧凑的场景图表示。在部署阶段,神经符号规划器通过对场景图和环境观测的推理生成可执行的规划方案,同时缓存增强的执行模块通过复用先前计算的任务 - 位置轨迹,进一步加速机器人在新环境中的适配过程。通过融合快速探索、符号推理和缓存增强执行三大机制,本文提出的框架克服了现有视觉语言导航方法计算效率低下和泛化能力差的缺陷,使机器人能够在未知环境中做出鲁棒且可扩展的决策。在各类环境的实验中,VLN-Zero 的成功率相比当前最先进的零样本模型提升一倍,性能超越大多数微调基线模型,同时导航至目标位置的时间缩短一半,视觉语言模型的调用次数平均减少 55%。
沐小含持续分享前沿算法论文,欢迎关注...
一、研究背景与核心问题
1.1 机器人自主导航的行业痛点
自主智能体在全新未知环境中的快速适配是实现规模化现实世界自主化的核心需求,但现有方法存在两大致命缺陷:一是依赖穷尽式探索 ,在新环境中需要大量的交互与计算才能完成环境建模,效率极低;二是采用刚性导航策略,在一个环境中训练的策略因新环境的布局、障碍物、约束条件变化而失效,且重新微调或多轮推理的过程耗时耗力,无法满足快速部署的实际需求。
例如,在某栋写字楼训练的导航机器人,在另一栋布局不同的写字楼中几乎无法正常工作,而重新训练的流程既不经济也不实用,这成为制约机器人自主导航落地的关键瓶颈。
1.2 现有视觉语言导航(VLN)方法的局限性
视觉语言导航模型为解决环境泛化问题提供了思路,但当前 VLN 方法仍存在显著不足:
- 探索过程低效,仍依赖密集的环境交互,未实现轻量化、快速化的环境建模;
- 任务分解能力薄弱,缺乏结构化的层级任务拆解策略,导致可扩展性差;
- 训练和查询成本高昂,大量的视觉语言模型(VLM)调用使得实时性难以保证;
- 经典探索方法(如前沿探索、占用栅格建图)计算开销大,在大尺度或动态环境中可扩展性差;
- 符号规划方法虽可解释性强,但对感知噪声鲁棒性弱;深度学习策略在分布内性能优异,但跨环境泛化需要昂贵的重训练。
1.3 本文要解决的两个核心问题
针对上述痛点,论文明确提出需要解决的两个核心科学问题,也是 VLN-Zero 框架的设计出发点:
- 快速探索问题:如何让智能体在不进行穷尽式搜索的前提下,高效构建未知环境的符号化表示(如场景图)?
- 零样本部署问题:如何基于已构建的环境符号表示,在不进行微调或多轮推理的情况下,实时生成满足约束条件的导航规划?
二、VLN-Zero 框架核心贡献
为解决上述问题,论文提出VLN-Zero------ 一个分两阶段的零样本视觉语言导航框架,融合了 VLM 引导的快速探索、神经符号导航规划和缓存增强的执行机制,其三大核心创新贡献可概括为:
- VLM 引导的快速探索:设计结构化、组合式的提示词策略,引导 VLN 智能体生成探索动作,同时增量构建紧凑的符号化场景图,在时间和计算约束下完成未知环境覆盖,且规避不安全行为;
- 零样本神经符号导航:提出一种神经符号规划器,联合推理场景图、任务提示和实时视觉观测,将自由形式的自然语言指令转化为满足约束的动作序列,无需微调或多轮推理;
- 缓存增强的快速适配执行:设计轨迹级的分层缓存机制,存储已验证的任务 - 位置轨迹对,复用先前计算的规划结果,减少冗余的 VLM 调用,降低执行时间、成本和计算需求,加速实际部署。
三、问题形式化定义
VLN-Zero 的核心是利用预训练 VLM 实现无微调、无多轮推理的快速探索与环境适配,论文首先对问题进行了严格的形式化定义,明确了智能体、环境、模型、约束等核心要素的数学表达。
3.1 核心要素定义
- 自主智能体
:配备相机、惯性测量单元(IMU)等传感器,且可通过 API 调用 VLM 的机器人,能执行导航动作并感知环境;
- 用户约束
- 视觉观测
- 预训练 VLM
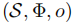 ,输出为导航动作
,输出为导航动作 - 场景图
- 任务提示
3.2 两个核心问题的形式化
问题 1:快速探索
设计针对 的提示词策略,使自主智能体在1 小时的时间限制内 ,高效探索未知环境并通过导航动作增量构建自上而下的场景图
,且该场景图需足够支撑后续的导航任务。
问题 2:部署规划
构建规划器 ,满足:
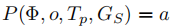
其中规划器生成的动作 需满足两个条件:① 遵守用户约束
;② 能够有效推进
中导航目标的完成。且规划器需通过对探索阶段得到的
进行推理实现环境适配,无需任何微调。
四、VLN-Zero 框架详细设计
VLN-Zero 整体分为探索阶段 和部署阶段两大核心阶段,探索阶段完成环境的快速建模和符号化场景图构建,部署阶段基于场景图实现零样本导航规划,并通过分层缓存机制加速执行,框架整体流程如图 1 所示。
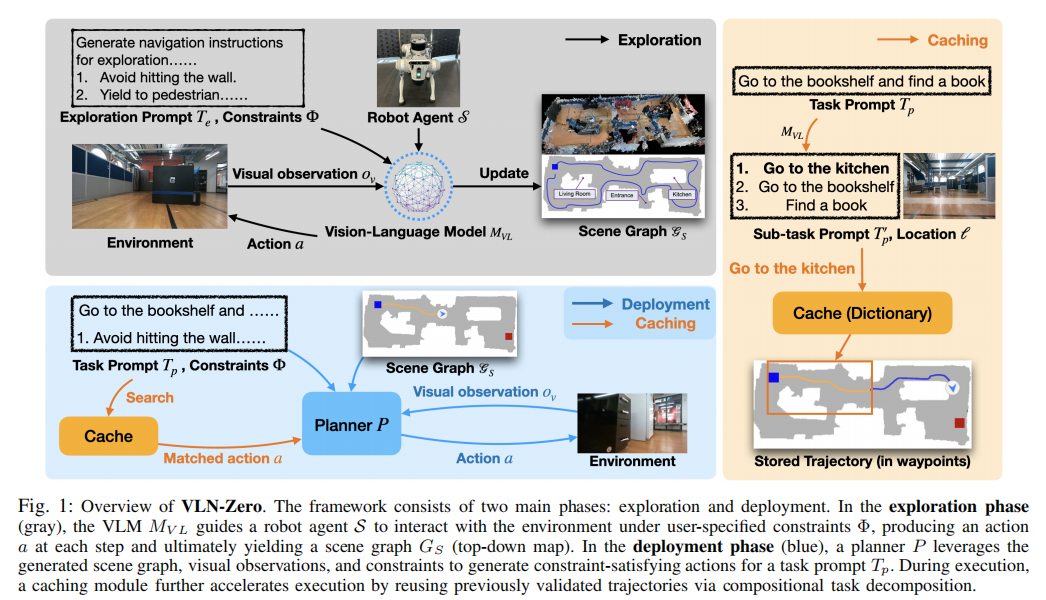
图 1 VLN-Zero 框架整体概览 该框架分为探索(灰色区域)和部署(蓝色区域)两个阶段:探索阶段通过结构化提示词引导 VLM ,让机器人在约束下与环境交互,生成动作并增量构建场景图,同时缓存模块记录轨迹;部署阶段规划器P结合缓存、场景图、视觉观测和任务提示,匹配并生成动作,复用已验证轨迹实现高效导航。
4.1 第一阶段:VLM 引导的快速探索(Rapid Exploration)
探索阶段的核心目标是:让机器人在无预训练规划器的前提下,利用 VLM 的多模态推理能力,在满足用户约束的同时,快速遍历未知环境并构建带语义标签的结构化场景图 ,为部署阶段提供基础。该阶段的设计包含提示词策略、探索流程、场景图构建与终止条件四大核心部分。
4.1.1 探索阶段的 VLM 提示词策略
论文设计了专门的探索提示词 (如图 2 所示),对 VLM 的输出进行严格约束,确保探索动作的安全性和有效性:
- 限定机器人的动作空间:仅允许前进、左转、右转、停止四种基础动作;
- 输出约束:每次仅返回单个动作,避免多动作指令的执行歧义;
- 行为约束:探索可见环境完成后或继续移动不安全时立即停止,且避免访问已探索区域;
- 输入上下文:将当前的<Scene Graph>和<Visual Observation>作为提示词上下文,让 VLM 基于已建图信息和实时视觉感知生成动作。

图 2 探索阶段引导 VLM 的提示词 提示词明确了导航指令生成要求、动作空间、核心约束,并将场景图和视觉观测作为参数化输入,VLM 最终仅返回四种动作中的一种。
4.1.2 探索阶段的算法流程
探索过程的核心逻辑通过Algorithm 1实现,为增量式的场景图构建过程,具体步骤如下:

- 初始化空的场景图
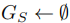 ,设置时间计数器
,设置时间计数器 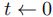 ;
; - 当
- 传感器感知环境,获取实时视觉观测
- 将 输入 VLM
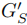 ;
; - 机器人执行动作
- 合并局部更新到全局场景图,
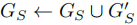 ;
; - 时间计数器自增
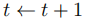 ;
;
- 传感器感知环境,获取实时视觉观测
- 达到时间限制后,返回最终的场景图
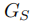 。
。
在该过程中,机器人通过 IMU 的里程计信息,将 VLM 输出的动作转化为空间位置变化,进而将第一人称视觉信息映射为自上而下的场景图,同时对环境中的物体按语义聚类(如 "客厅""厨房"),为场景图添加语义标签,提升后续导航的推理效率。
4.1.3 探索阶段的终止条件
论文并未仅依赖 1 小时的硬时间限制,还设计了场景图结构指标来判断环境是否被充分探索,当两个指标同时满足时,可提前终止探索:
- 环境外围的闭环检测:机器人已遍历可访问区域的边界,实现边界的闭环建图;
- 无大尺度未探索区域:已建图区域内不存在大面积的空白未探索区域。
该设计平衡了 "快速探索" 和 "建图完整性",既避免了穷尽式探索的低效,又保证了场景图足以支撑后续的导航任务。在实际实验中,论文设置 1 小时为硬时间限制,兼顾快速部署和场景图的完整性。
4.2 第二阶段:缓存增强的神经符号部署(Cache-Enabled Neurosymbolic Deployment)
部署阶段是 VLN-Zero 实现零样本导航的核心,基于探索阶段构建的场景图,结合神经符号规划器和分层缓存机制,将自然语言任务提示转化为可执行的导航动作,无需任何微调或重新训练。该阶段包含基于场景图的环境适配 和分层缓存的任务执行 两大核心模块,整体流程通过Algorithm 2实现。
4.2.1 基于场景图的环境适配
与传统基于策略的导航方法不同,VLN-Zero 的规划器 不依赖预训练策略,而是通过 ** 直接推理场景图
** 实现对新环境的适配,其核心设计如下:
- 规划器输入 :用户约束 ;
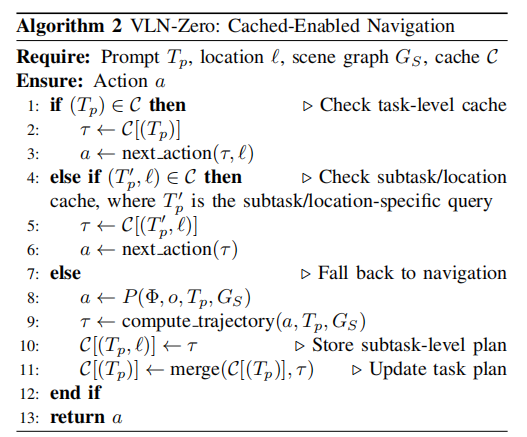
- 部署阶段提示词策略 :设计专门的部署提示词
- 定义场景图视觉元素:正方形 = 起始位置、蓝色箭头 = 当前位置与朝向、蓝色线 = 已走轨迹、灰色区域 = 可通行地面、白色区域 = 障碍物 / 墙壁;
- 导航规则:强制基于自上而下的场景图判断移动方向,结合实时视觉观测验证;
- 参数化输入:将<Constraints>、<Scene Graph>、<Visual Observation>作为上下文,保证规划器的推理依据。
- 规划器输出 :满足约束
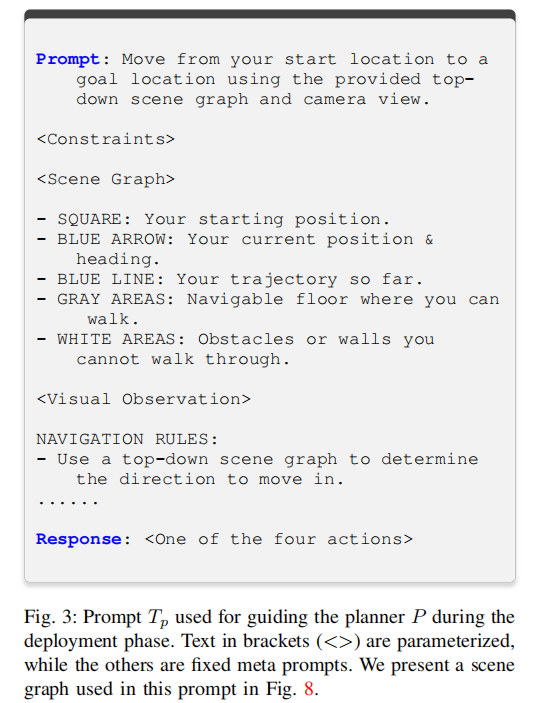
图 3 部署阶段引导规划器 P 的提示词 提示词定义了场景图各元素的含义、导航核心规则,将约束、场景图、视觉观测作为参数化输入,固定元提示词部分,保证规划器推理的一致性。
4.2.2 分层缓存的任务执行
为解决 VLM 无内置记忆、重复查询成本高的问题,论文设计了轨迹级的分层缓存机制,通过存储已验证的导航轨迹,减少 VLM 调用次数,提升实时导航效率,这是 VLN-Zero 实现高效部署的关键创新。
(1)缓存的形式化定义
缓存 被维护为一个字典结构,核心映射关系为:
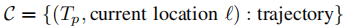
其中,键为任务提示 - 当前位置 对,值为满足约束 的可行轨迹,轨迹是场景图中一系列连续的空间点,代表环境中的相对位置变化。
(2)分层缓存的设计
为提升轨迹的复用性,缓存并非仅存储完整的任务级轨迹,而是采用多粒度的分层结构,包含三个层级的轨迹存储:
- 任务级轨迹 :对应完整的任务提示
- 子任务 / 位置级轨迹:对应任务分解后的子提示或特定位置,如 "从正门到卧室门口""从卧室门口到床";
- 可复用轨迹片段:如房间到房间、房间到物体的过渡轨迹,是导航的基础单元。
分层设计的核心优势是组合性:即使遇到从未见过的全新任务提示,规划器也可将其分解为子任务,复用缓存中的子轨迹片段,组合成新任务的可行轨迹,大幅提升泛化能力。
(3)缓存的查询与更新流程
缓存的使用逻辑通过Algorithm 2实现,核心为 "先缓存查询,再按需推理",具体步骤如下:
- 输入任务提示
- 任务级缓存查询:若
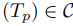 ,直接从缓存的任务轨迹
,直接从缓存的任务轨迹 - 子任务 / 位置级缓存查询 :若任务级无匹配,将
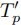 ,若
,若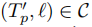 ,从子轨迹
,从子轨迹 - 兜底推理 :若上述两级均无匹配,调用规划器
- 缓存更新:将新计算的子任务 - 位置轨迹存储到缓存
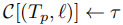 ,并将子轨迹合并到任务级轨迹
,并将子轨迹合并到任务级轨迹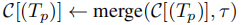 ;
; - 返回动作
(4)任务分解策略
论文中采用VLM 作为任务分解的骨干,将高维的自然语言任务提示,拆解为低维的、可执行的子任务提示,保证子任务与缓存中的轨迹片段匹配。
五、实验验证
为验证 VLN-Zero 的有效性,论文从仿真实验 和真实机器人实验两个维度展开验证,对比了零样本和微调的主流基线模型,同时单独验证了缓存机制的性能提升,实验设计遵循视觉语言导航的标准评测体系,保证结果的可信度和可复现性。
5.1 实验设置
5.1.1 仿真平台与数据集
- 仿真平台:采用 Habitat Simulator------ 目前最主流的具身智能体仿真平台,支持 3D 环境建模和多传感器模拟,基于 VLN-CE 环境构建实验场景;
- 评测数据集 :使用 R2R 和 RxR 两大经典的 "房间到房间" 导航数据集,选取Val-Unseen分割集(未见过的环境),这是零样本导航的标准评测基准,其中 R2R 含 1839 个 episode,RxR 含 1517 个 episode,每个 episode 包含起始位置、目标位置和导航指令(VLN-Zero 不依赖该指令,仅用于评测);
- VLM 模型:采用 GPT-4.1 和 GPT-5 作为基础 VLM,通过 API 调用,输入包含 RGB 相机视图、自上而下的场景图和提示词;
- 智能体感知输入 :VLN-Zero 仅需RGB 图像 和里程计(Odo) 信息,相比多数基线模型,输入模态更精简,实用性更强。
5.1.2 评测指标
采用视觉语言导航的四大标准评测指标,全面评估导航的准确性、效率和成功率:
- 导航误差(NE) :智能体最终位置与目标位置的欧氏距离,越低越好;
- Oracle 成功率(OS) :存在最优路径时的导航成功率,越高越好;
- 成功率(SR) :智能体自主导航到目标位置(3 米范围内)的概率,越高越好;
- 成功率加权路径长度(SPL) :综合考虑成功率和路径长度的指标,越高越好,计算公式为:成功时 SPL = 目标距离 / 实际路径长度,失败时 SPL=0。
5.1.3 基线模型
选取8 个零样本 VLN 模型 和10 个微调 VLN 模型作为基线,涵盖当前主流的零样本和微调方法,核心对比的代表性模型包括:
- 零样本基线:CA-Nav(约束感知)、AO-Planner(视觉可供性规划)、A²Nav(动作感知)、NavGPT-CE(LLM 推理);
- 微调基线:NaVid(视频基 VLM)、NaVILA(腿式机器人专用 VL-A)、GridMM(栅格记忆图)、DreamWalker(心智规划)。
5.2 仿真实验结果
5.2.1 跨数据集整体性能(R2R & RxR)
实验结果如表 1 所示,VLN-Zero 在零样本模型中实现全指标 SOTA,且性能比肩多数微调基线模型,核心结论如下:
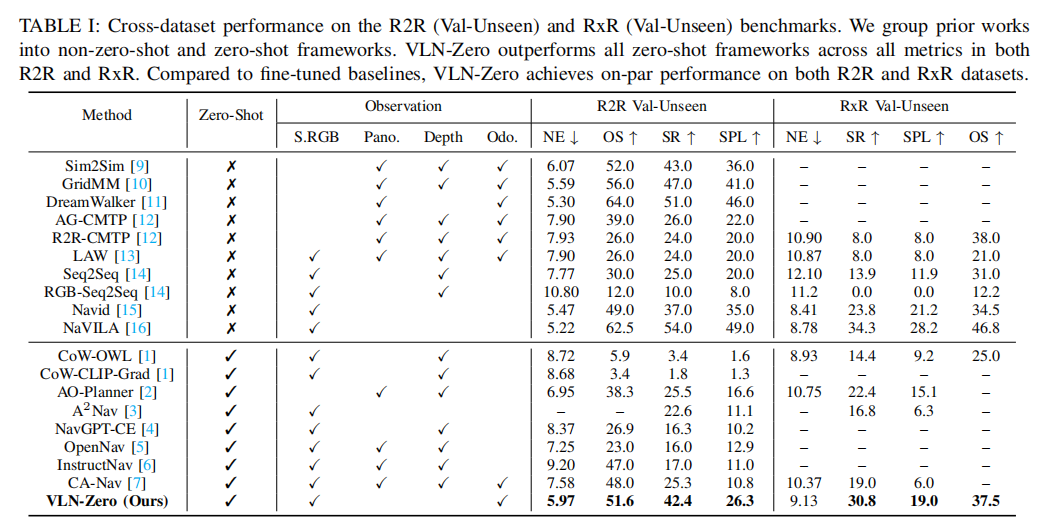
表 1 R2R 和 RxR Val-Unseen 数据集的跨数据集性能表格按 "非零样本(微调)" 和 "零样本" 分组,对比了各方法的输入模态和四大评测指标,VLN-Zero 为零样本模型,仅需 RGB+Odo 输入。
- R2R 数据集:VLN-Zero 的 SR 达到 42.4%,超过最优零样本基线 CA-Nav(25.3%)17% 以上;OS 达到 51.6%,优于 CA-Nav(48.0%);SPL 达到 26.3%,是 OpenNav(12.9%)的两倍多,且 NE 仅为 5.97,处于零样本模型的最优水平;
- RxR 数据集:VLN-Zero 的 SR 达到 30.8%,超过次优零样本基线 AO-Planner(22.4%)8.4%;OS 达到 37.5%,为所有零样本模型最优;SPL 达到 19.0%,优于 AO-Planner(15.1%)3.9%;
- 与微调模型对比:VLN-Zero 作为零样本模型,性能与多数微调模型持平(如 NaVid 的 R2R SR 为 37.0%,低于 VLN-Zero),仅略逊于少数专为特定场景优化的微调模型(如 NaVILA),但无需任何训练 / 微调,大幅降低了计算成本;
- 输入模态优势:VLN-Zero 仅需 RGB 图像和里程计,相比多数基线模型(需全景图、深度图等),感知硬件要求更低,更易在实际机器人上部署;
- 模型无关性:VLN-Zero 的性能在 GPT-4.1 和 GPT-5 上保持一致(如图 4),说明框架不依赖特定 VLM,具有良好的通用性。
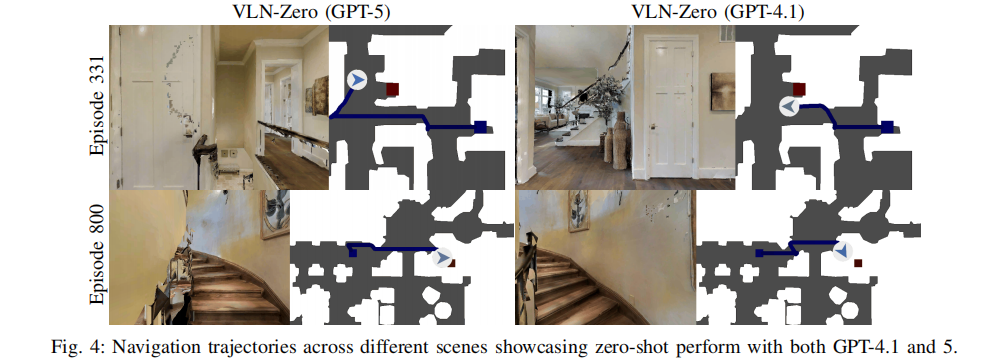
图 4 VLN-Zero 在 GPT-4.1 和 GPT-5 上的导航轨迹展示了 Episode 331 和 Episode 800 两个场景中,不同 VLM 驱动的 VLN-Zero 的导航轨迹,二者轨迹高度相似,验证了框架的模型无关性。
5.2.2 缓存机制的性能验证
为单独验证分层缓存机制的效果,论文在 R2R Val-Unseen 的同一场景中,对比了开启缓存 和关闭缓存 时的 VLN-Zero 性能,评测指标包括VLM 调用次数、每步平均时间、总执行时间、VLM 查询成本,结果如表 2 所示。

表 2 部分缓存场景下不同 Episode 的性能对比对比了 VLN-Zero 开启 / 关闭缓存时的四大性能指标,Episode 1475 和 1691 为同一场景的不同导航任务。
核心结论:
- VLM 调用次数大幅减少 :开启缓存后,Episode 1475 的 VLM 调用从 47 次降至 32 次,Episode 1691 从 84 次降至 18 次,最大减少 78.6%;
- 执行时间显著降低:每步平均时间最大减少 78.8%,总执行时间大幅缩短(如 Episode 1691 从 167.605 秒降至 35.500 秒);
- 查询成本降低:VLM API 调用成本与调用次数正相关,开启缓存后查询成本最大减少 78.4%;
- 路径更优:如图 6 所示,开启缓存的智能体轨迹(橙色)更简洁,无冗余探索,而关闭缓存的轨迹存在较多无效移动,验证了缓存对路径规划效率的提升。
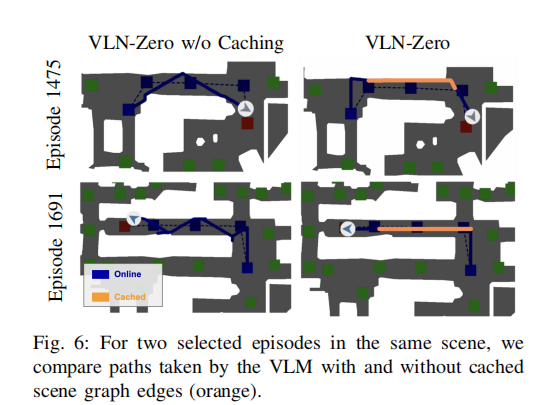
图 6 同一场景中开启 / 关闭缓存的路径对比展示了 Episode 1475 和 1691 中,VLN-Zero 开启缓存(橙色)和关闭缓存的导航路径,缓存开启后路径更简洁,无冗余探索。
5.3 真实机器人演示实验
为验证 VLN-Zero 在物理世界 的有效性,论文采用Unitree Go2 四足机器人开展真实环境导航实验,还原了探索和部署的完整流程,实验场景为包含客厅、正门、厨房的 30㎡公寓。
5.3.1 实验硬件设置
- 机器人:Unitree Go2 四足机器人,具备高机动性,适配室内非结构化环境;
- 感知模块:Intel RealSense D456 RGB-D 相机,实现像素级检测,将环境信息投影到场景图;
- 定位模块:机器人机载里程计(LIO-SAM),实现实时定位,将机器人位置映射到场景图;
- VLM 集成:将相机、里程计数据输入 VLM,通过提示词策略引导动作生成,构建场景图。
5.3.2 探索阶段实验结果
机器人在公寓中完成单轮无重复探索 ,仅用不到 10 分钟就完成了 30㎡环境的建模,探索路径长度约 30 米,成功构建了带语义标签的场景图(如图 7),包含正门、客厅、厨房的可通行区域、障碍物和地标。
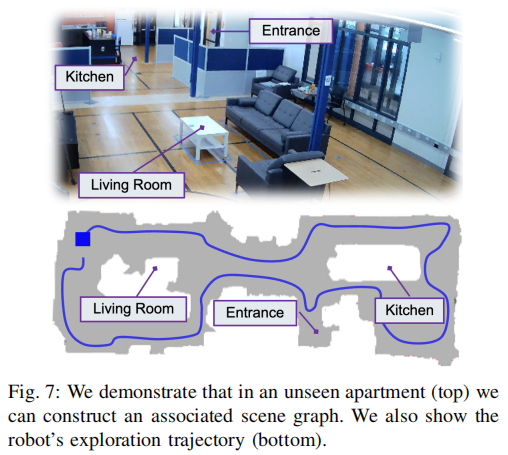
图 7 真实公寓环境与构建的场景图上半部分为真实公寓的实景,下半部分为 VLN-Zero 探索阶段构建的场景图及机器人的探索轨迹,实现了环境的精准符号化建模。
该结果验证了 VLN-Zero快速探索的实际可行性,相比传统探索方法(动辄数小时),效率提升显著,且单轮探索即可满足部署需求。
5.3.3 部署阶段实验结果
为机器人分配复合任务:"去书架找一本书,然后返回客厅的咖啡桌",规划器将该任务分解为一系列子任务,实验结果如图 5 和图 8 所示,核心结论如下:

图 5 复合任务的真实机器人执行过程上排为第三人称视角的机器人执行帧,中排为机器人第一人称相机视图,下排为场景图的增量轨迹,黄色标注的为从缓存中复用的子任务。
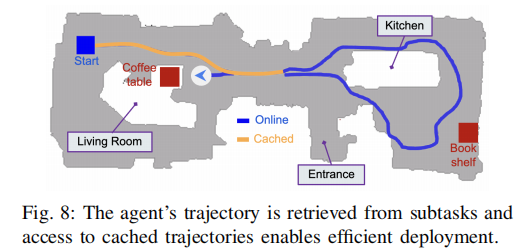
图 8 部署阶段的轨迹复用机器人的导航轨迹由缓存中的子任务轨迹组合而成,实现了厨房、客厅、正门之间的高效轨迹复用。
- 任务分解与缓存复用 :规划器将复合任务分解为 "去厨房→找书架→去客厅→停在咖啡桌旁" 等子任务,其中 "去客厅""去厨房" 的子轨迹直接从缓存中提取,无需重新推理,验证了分层缓存的组合复用能力;
- 执行效率 :机器人在约 3 分钟内完成整个复合任务,无任何重复探索和冗余动作,满足实时导航的需求;
- 安全性与准确性 :机器人全程遵守约束(避免碰撞、不触碰墙壁),精准到达目标位置,验证了 VLN-Zero 在真实环境中的约束满足能力 和导航准确性;
- 场景图的有效性 :探索阶段构建的场景图能够精准反映真实环境的拓扑结构,为部署阶段的推理提供了可靠的基础,验证了符号化场景图的实际建模价值。
六、结论与未来展望
6.1 研究结论
论文提出的 VLN-Zero 框架,通过VLM 引导的快速探索 、神经符号零样本规划 和分层缓存增强执行的有机结合,解决了传统机器人导航方法计算低效、泛化能力差的核心问题,实现了未知环境中的快速适配和零样本导航,具体结论可总结为:
- 零样本性能 SOTA:在 R2R 和 RxR 两大标准数据集上,VLN-Zero 的所有评测指标均超越现有零样本基线模型,成功率提升显著;
- 比肩微调模型:作为无微调、无多轮推理的零样本框架,VLN-Zero 的性能与多数经过大规模训练的微调模型持平,大幅降低了训练成本和部署门槛;
- 效率大幅提升:分层缓存机制使 VLM 调用次数平均减少 55% 以上,最大减少 78.6%,执行时间和查询成本同步大幅降低,满足实时导航需求;
- 硬件要求低:仅需 RGB 图像和里程计信息,相比主流方法更易在实际机器人上部署;
- 物理世界有效:在四足机器人的真实公寓实验中,VLN-Zero 实现了快速探索和高效的复合任务导航,验证了框架的实际落地价值。
6.2 未来研究方向
论文基于 VLN-Zero 的现有成果,提出了三个核心的未来研究方向,也是机器人零样本导航的前沿探索方向:
- 跨域环境适配 :将 VLN-Zero 从室内环境扩展到室外非结构化环境(如越野、园区),解决室外环境的动态性、地形复杂性和尺度更大的问题;
- 不完整场景图的推理 :针对真实部署中常见的遮挡、动态物体、信息缺失问题,研究在不完整 / 部分观测的场景图下的导航推理方法,提升框架对环境不确定性的鲁棒性;
- 动态环境的实时更新 :现有 VLN-Zero 的场景图为静态建图,未来将研究场景图的实时动态更新机制,适配行人、移动物体等动态环境要素,实现动态环境中的自主导航。
七、论文核心亮点总结
VLN-Zero 作为机器人零样本视觉语言导航的前沿框架,其核心价值不仅在于实现了性能的突破,更在于为解决 "未知环境快速适配" 这一核心问题提供了全新的技术思路,其核心亮点可概括为:
- 符号化与端到端的融合:将符号化的场景图建模与端到端的 VLM 推理结合,既保留了符号规划的可解释性和泛化能力,又利用了 VLM 的多模态推理能力,弥补了纯符号和纯数据驱动方法的缺陷;
- 提示词工程的精细化设计:为探索和部署阶段设计专用的结构化提示词,严格约束 VLM 的输出,将大模型的开放式推理转化为机器人的可执行动作,实现了大模型与机器人的有效交互;
- 分层缓存的记忆机制:为无内置记忆的 VLM 设计了轨迹级的分层缓存,通过多粒度的轨迹存储和组合复用,解决了大模型重复查询的效率问题,为大模型驱动的机器人系统提供了通用的记忆设计思路;
- 端到端的零样本流程:从环境探索到任务执行,全程无需微调、无需多轮推理,实现了真正的端到端零样本导航,大幅降低了机器人导航的部署成本,为规模化落地奠定了基础。
VLN-Zero 的提出,推动了视觉语言模型与机器人自主导航的深度融合,为未来通用自主机器人的研发提供了重要的技术参考,也为解决智能体的环境泛化问题开辟了新的研究方向。