文章目录
概要
参考论文:Expensive Multi-Objective Bayesian Optimization Based on Diffusion Models
项目地址:https://github.com/ilog-ecnu/CDM-PSL

在现代工程的前沿,寻找"最优解 "往往是一场代价高昂的赌博。想象一下:为了提升火箭喷射器的燃烧效率,或者是缩短一款新药的临床试验周期,工程师和科学家们必须在无数种参数组合中进行筛选 。------每一次物理实验或高精度模拟都意味着数十万美金的投入或长达数周的等待。这种挑战在学界被称为"昂贵多目标优化问题(EMOPs)"。
EMOPs 是指需要同时优化多个(通常是冲突的)目标 ,且由于时间成本、资金消耗等原因,每个目标的函数评估极其昂贵或耗时的问题。这类问题常见于天线结构设计、金融云服务及临床药物试验等领域。
为了破解这一困境,多目标贝叶斯优化(MOBO)成为了主流方案。它通过构建代理模型来减少实验次数。但当样本量极度匮乏时,传统的模型往往难以捕捉到复杂的设计空间全貌。
BO 的核心是建立一个概率代理模型 (通常是高斯过程)来表示黑盒函数,并结合采集函数 (Acquisition Functions)来寻找全局最优解。通过这种方式,可以在减少实际函数评估次数的同时,有效地探索和开发决策空间。
MOBO 是贝叶斯优化与多目标优化的融合 。一种被广泛采用的 MOBO 方法是随机标量化 技术,它能将多目标优化问题有效转化为多个单目标优化问题。另一种值得关注的策略是使用复杂的采集函数 ,如超体积改进(EHVI)(Couckuyt、Deschrijver 和 Dhaene,2014)和预测熵搜索(PESMO)(Hoffman 和 Ghahramani,2015;Hernández-Lobato 等,2016)。其中,基于帕累托集学习(PSL)的方法(如 Li 等,2022)通过机器学习技术建模帕累托集,展现出了良好的性能。
现有帕累托集学习(PSL)算法在面对昂贵场景时存在哪些主要挑战?
在样本数量有限的情况下,现有 PSL 算法难以有效建模帕累托解的复杂分布,表现出明显的不稳定性。这会导致生成的解集与真实的帕累托集(PS)之间存在显著偏差。
基于上述问题,这篇文章提出了一种面向昂贵 MOBO 的新型复合扩散模型帕累托集学习算法(CDM-PSL),该算法通过扩散模型渐进式学习高质量帕累托最优解的内在分布。主要贡献如下:
- 提出了一种基于复合扩散模型 的帕累托集学习方法,用于昂贵的 MOBO,包含无条件和条件样本生成。
设计了引导采样过程,以提升扩散模型生成解的质量,从而得到条件扩散模型。 - 引入了一种基于信息熵的引导策略来平衡 EMOPs 中不同目标的重要性。该方法确保在优化过程中所有目标都能得到合理权衡。
方法概述
扩散模型相关概念可以参考文章:万字长文详细解读扩散模型(diffusion model)从原理剖析、公式推导、Unet架构到代码实现
多目标优化问题参考文章:稀土掘金---贝叶斯优化在多目标优化中的应用
下面通过一个简单的示例来展示贝叶斯优化在多目标优化中的应用。考虑一个简单的二目标优化问题,其中的目标函数为:

完整代码如下:
python
import numpy as np
import matplotlib.pyplot as plt
from pymoo.algorithms.moo.nsga2 import NSGA2
from pymoo.core.problem import Problem
from pymoo.optimize import minimize
from pymoo.visualization.scatter import Scatter
# 定义多目标优化问题
class MyProblem(Problem):
def __init__(self):
# 定义变量维度、范围,目标数量(2个),优化方向(最小化)
super().__init__(n_var=2,
xl=np.array([-5, -5]), # 变量下界
xu=np.array([5, 5]), # 变量上界
n_obj=2, # 目标数量
n_constr=0) # 约束数量
def _evaluate(self, x, out, *args, **kwargs):
# 计算两个目标函数值
f1 = (x[:, 0] - 1) ** 2 + (x[:, 1] - 1) ** 2
f2 = (x[:, 0] + 1) ** 2 + (x[:, 1] + 1) ** 2
out["F"] = np.column_stack([f1, f2])
# 初始化算法(NSGA-II,多目标优化经典算法)
algorithm = NSGA2(pop_size=50)
# 执行多目标优化
problem = MyProblem()
res = minimize(problem,
algorithm,
("n_gen", 100), # 迭代次数
seed=0,
verbose=False)
# 提取帕累托最优解和对应的目标值
pareto_solutions = res.X # 帕累托最优解的变量值
pareto_f1 = res.F[:, 0] # 对应f1的目标值
pareto_f2 = res.F[:, 1] # 对应f2的目标值
# 绘制决策空间的帕累托最优解
# 第一步:生成网格数据用于绘制目标函数的等高线
x1 = np.linspace(-5, 5, 100)
x2 = np.linspace(-5, 5, 100)
X1, X2 = np.meshgrid(x1, x2)
F1 = (X1 - 1)**2 + (X2 - 1)**2 # f1的网格值
F2 = (X1 + 1)**2 + (X2 + 1)**2 # f2的网格值
# 第二步:绘制等高线和帕累托最优解
plt.figure(figsize=(12, 5))
# 子图1:决策空间(x1-x2)+ f1的等高线 + 帕累托解
plt.subplot(1, 2, 1)
contour = plt.contourf(X1, X2, F1, levels=20, cmap='viridis', alpha=0.7)
plt.scatter(pareto_solutions[:, 0], pareto_solutions[:, 1],
color='red', s=30, label='Pareto Optimal Solutions')
plt.xlabel('x1')
plt.ylabel('x2')
plt.title('Decision Space (f1 contour)')
plt.colorbar(contour, label='f1 value')
plt.legend()
# 子图2:目标空间(f1-f2)的帕累托前沿
plt.subplot(1, 2, 2)
plt.scatter(pareto_f1, pareto_f2, color='blue', s=30)
plt.xlabel('f1 = (x1-1)² + (x2-1)²')
plt.ylabel('f2 = (x1+1)² + (x2+1)²')
plt.title('Pareto Front in Objective Space')
plt.grid(True, alpha=0.3)
plt.tight_layout()
plt.show()
# 输出帕累托最优解的部分结果(前5个)
print("前5个帕累托最优解(x1, x2):")
print(pareto_solutions[:5])
print("\n对应的f1值:", pareto_f1[:5])
print("对应的f2值:", pareto_f2[:5])运行后结果图:
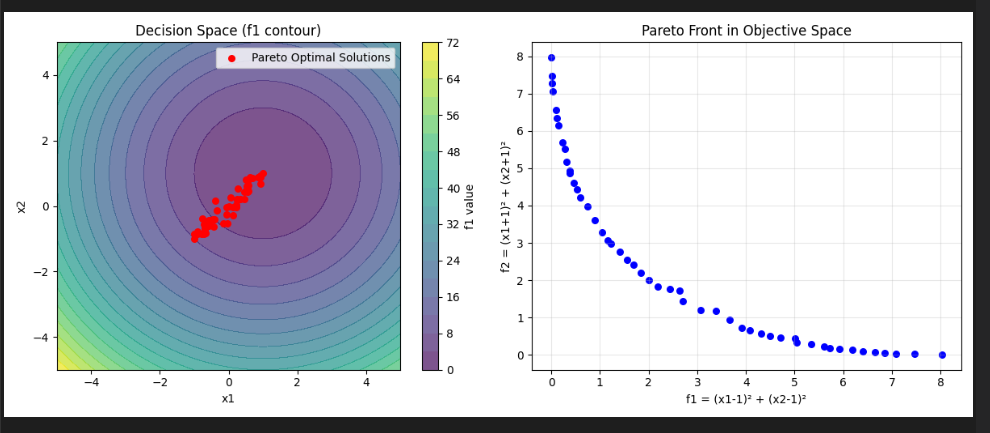
终端输出:
python
前5个帕累托最优解(x1, x2):
[[-1.00132945 -1.00460277]
[ 0.99326607 1.00027422]
[-1.00132945 -0.86145658]
[-0.02396149 -0.52843746]
[ 0.34245238 0.21870549]]
对应的f1值: [8.02375185e+00 4.54210689e-05 7.47034015e+00 3.38461818e+00
1.04278999e+00]
对应的f2值: [2.29529659e-05 7.97420655e+00 1.91960480e-02 1.17502241e+00
3.28742146e+00]
Process finished with exit code 0下面解释这篇文章中的方法:提出了一种面向 EMOP 的复合扩散模型帕累托集学习方法,记为 CDM-PSL(算法 1 和图 1)。CDM-PSL 包含三个核心组件:数据提取、扩散模型训练和条件生成。
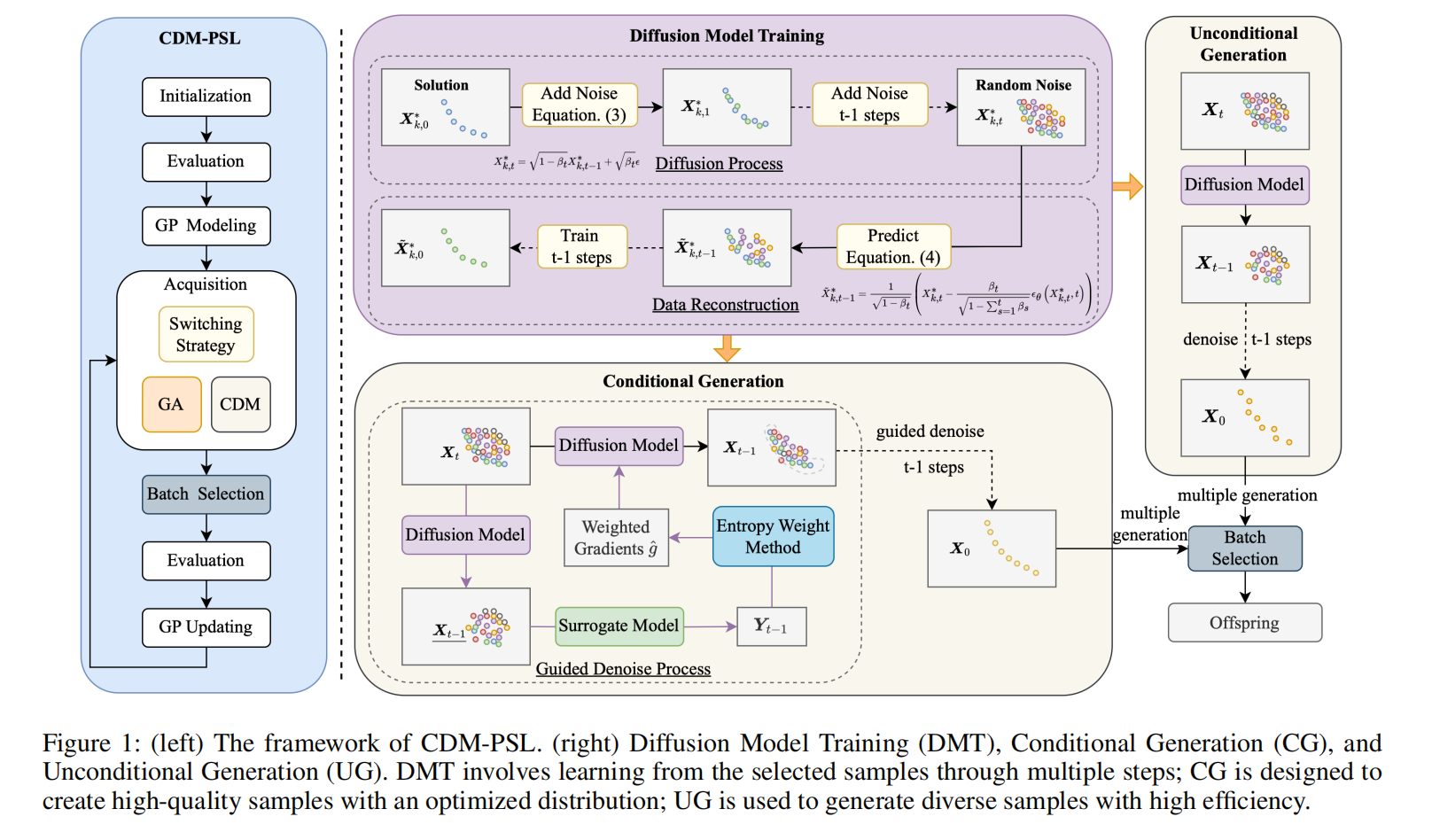

data extraction
为帕累托集学习准备训练数据(算法 2),引入移位密度估计(SDE)作为适应度函数,其数学表达式为:
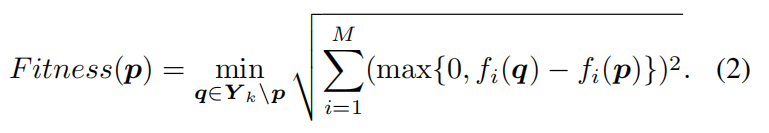
在此公式中, p p p 和 q q q 是当前解集 Y k {Y}{k} Yk 中的解, f i ( p ) {f}{i}\left( p\right) fi(p) 表示解 p p p 的第 i i i 个目标值。SDE 方法基于收敛性和多样性 特征评估样本质量。从 X k {X}{k} Xk 中,我们选择 T T T 个 ( T = ⌊ ∣ X k ∣ 3 ⌋ ) \left( {T = \lfloor \frac{\left| {X}{k}\right| }{3}\rfloor }\right) (T=⌊3∣Xk∣⌋) 具有优异 SDE 值的候选解作为帕累托最优样本。

SDE引用文章地址:Shift-Based Density Estimation for Pareto-Based
Algorithms in Many-Objective Optimization
- 计算逻辑:
对于当前解 p p p ,遍历集合中除 p p p 以外的所有解 q q q 。------ 计算 p p p 和 q q q 在每个目标 i i i 上的差值 f i ( q ) − f i ( p ) {f}{i}\left( q\right) - {f}{i}\left( p\right) fi(q)−fi(p) 。-------- 位移操作(Shift):只保留 q q q 比 p p p 差(即目标值更大,假设为最小化问题)的部分。如果 f i ( q ) > f i ( p ) {f}{i}\left( q\right) > {f}{i}\left( p\right) fi(q)>fi(p) ,
则保留差值;如果 f i ( q ) ≤ f i ( p ) {f}{i}\left( q\right) \leq {f}{i}\left( p\right) fi(q)≤fi(p) (即 q q q 在该目标上优于或等于 p p p ),则差值置为 0。-------- 计算这些保留差值的欧几里得距离。--------- F i t n e s s ( p ) {Fitness}\left( p\right) Fitness(p) 等于 p p p 到所有其他 q q q 的位移距离中的最小值。- 筛选标准:选取 F i t n e s s {Fitness} Fitness 值最大的 T T T 个解作为Pareto最优样本。
。被支配解 :如果存在一个 q q q 在所有目标上都优于 p p p ,那么所有 max { 0 , . . . } \max \{ 0,...\} max{0,...} 项均为0,导致 F i t n e s s ( p ) = 0 {Fi}{tness}\left( p\right) = 0 Fitness(p)=0 。这类解会被淘汰。
。拥挤解 :如果 p p p 附近有其他解(即使是比它稍差的解),计算出的距离会很小,导致 F i t n e s s ( p ) {Fitness}\left( p\right) Fitness(p) 较低。
。稀疏非支配解 :如果 p p p 是非支配的,且在目标空间中周围比较"空旷"(即离它最近的劣解也很远),则其 F i t n e s s ( p ) {Fi}{tness}\left( p\right) Fitness(p) 较大,更容易被选中。
扩散模型训练
扩散过程
给定样本集 X k ∗ {X}{k}^{ * } Xk∗ 和特定的扩散步数 t t t ,扩散过程通过 t t t 步向 X k ∗ {X}{k}^{ * } Xk∗ 中逐步引入高斯噪声
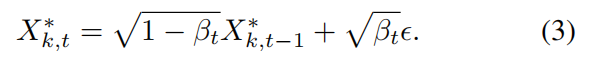
其中 X k , t ∗ {X}{k,t}^{ * } Xk,t∗ 表示第 t t t 步的数据, β t ∈ 1 e − 5 , 5 e − 2 {\beta }{t} \in \left\lbrack {{1e} - 5,{5e} - 2}\right\rbrack βt∈1e−5,5e−2 表示第 t t t 步的噪声水平。用于帕累托集学习的扩散模型训练过程是一个马尔可夫链。与直接帕累托集学习相比,这种逐步逼近的方法能更有效地捕捉最优样本的分布特征。
噪声预测
噪声预测阶段涉及重构经历了扩散过程的样本 X k , t ∗ {X}{k,t}^{ * } Xk,t∗ ,以恢复其原始状态 X k ∗ {X}{k}^{ * } Xk∗ 。这种重构通过一个模型 M \mathcal{M} M 实现,该模型预测每一步添加的噪声,从而逆转扩散过程。该过程遵循以下方程:
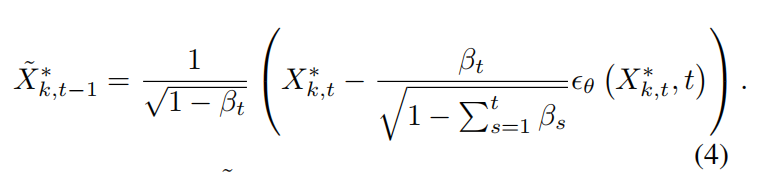
其中 X ~ k , t − 1 ∗ {\widetilde{X}}{k,t - 1}^{ * } X k,t−1∗ 表示重构后的数据, ϵ θ {\epsilon }{\theta } ϵθ 表示模型 M \mathcal{M} M 在第 t t t 步的参数。
模型 M \mathcal{M} M 的损失函数定义为:
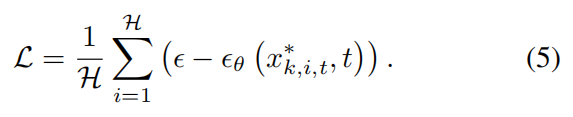
该方程考虑了最优样本的总数 H \mathcal{H} H ,其中每个 x k , i , t ∗ {x}{k,i,t}^{ * } xk,i,t∗ 来自 X k , t ∗ {X}{k,t}^{ * } Xk,t∗ , ϵ θ ( X k , t ∗ , t ) {\epsilon }{\theta }\left( {{X}{k,t}^{ * },t}\right) ϵθ(Xk,t∗,t) 表示预测的噪声。训练模型 M \mathcal{M} M 的目标是最小化该损失 L \mathcal{L} L ,从而提高噪声预测的准确性。
条件生成
条件生成(CG)模块包含两个组件:引导去噪过程 和加权梯度 。CDM-PSL 的 CG 模块根据当前估计的目标值,在每一步去噪时自适应调整不同目标的权重。 这与使用预定义超参数或人为经验确定的平均权重形成了鲜明对比。
引导去噪过程
给定步数 t t t 和样本 x t {x}_{t} xt ,引导去噪过程可实现为:
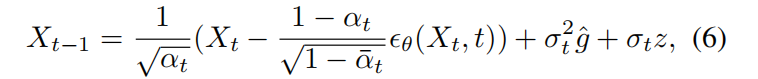
其中 α t {\alpha }{t} αt 表示 1 − β t 1 - {\beta }{t} 1−βt , ϵ θ ( X t , t ) {\epsilon }{\theta }\left( {{X}{t},t}\right) ϵθ(Xt,t) 是训练好的扩散模型预测的噪声, σ t {\sigma }_{t} σt 是第 t t t 步的标准差, g ^ \widehat{g} g 表示用于引导去噪过程的加权梯度。
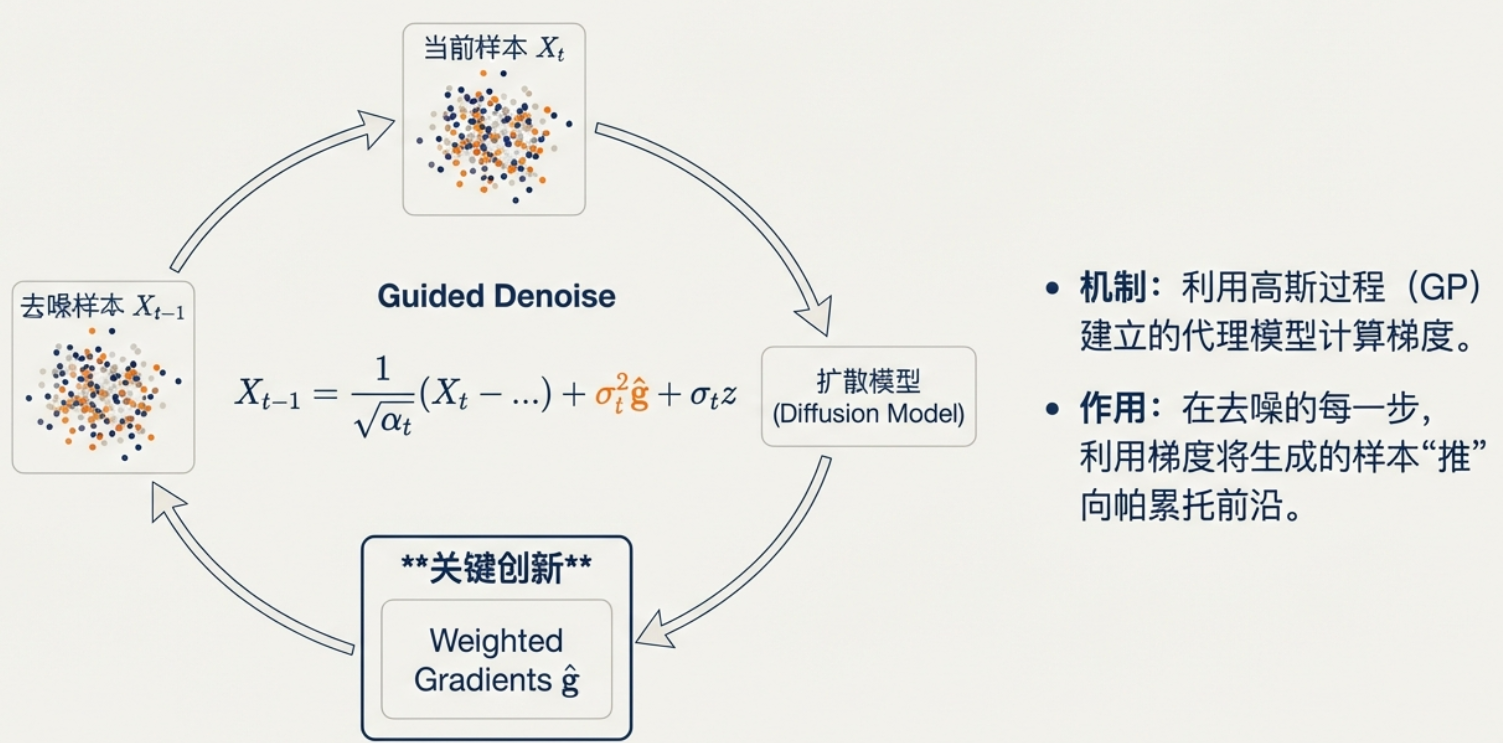
为了在样本生成过程中获取用于引导的梯度信息,为每个目标建立独立的高斯过程(GP)模型(Balandat等,2020)。这些模型用于计算所有生成样本的目标值,从而得到每个目标的梯度,为条件生成提供支持。
为了在生成过程中引导样本向更优的区域移动,需要计算目标函数的梯度。由于无法直接对昂贵的黑盒函数求导,算法利用已有的评估数据(X,Y),为每一个目标 fi 训练一个独立的GP代理模型。 GP模型是可微的,因此可以直接输入x对预测值的梯度。
加权梯度
采用加权梯度是解决 EMOPs 的关键,它需要为每个目标确定合适的权重。因此,采用了一种基于信息熵的
加权方法 ,以推导出这些加权梯度 g ^ \widehat{g} g 。
不能简单地认为所有目标同等重要,或者使用固定权重,因为目标的取值范围和分布形态都在不断变化。 ---- 为解决此问题,引入基于信息熵的自适应加权方法,如果某个目标的数据分布差异大,信息丰富,应该给予更大的权重。----- 自动识别哪些目标在当前迭代中提供了更丰富的区分信息,并赋予其更高的权重,从而合成一个更有效的综合梯度,这使得扩散模型在生成样本时,能够沿着更有潜力的方法进行"受控去噪",从而显著提升算法的收敛性能。
为了获得基于信息熵的权重,首先需要对目标值进行归一化 。设 y i j {y}{ij} yij 表示第 i i i 个个体的第 j j j 个目标值。归一化后的目标值 y ^ i j {\widehat{y}}{ij} y ij 通过最大 - 最小归一化计算得到。在此之后,对每个目标 j j j ( j = 1 , 2 , ... , M j = 1,2,\ldots ,M j=1,2,...,M ),计算概率矩阵 P i j {P}_{ij} Pij (公式 7),其中 k = 1 , 2 , ... , N k = 1,2,\ldots ,N k=1,2,...,N , N N N 表示种群中的个体数量。
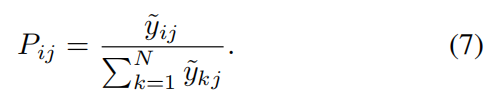
随后,对每个目标 j ( j = 1 , 2 , ... , M ) j\left( {j = 1,2,\ldots ,M}\right) j(j=1,2,...,M) ,计算其信息熵 E j {E}_{j} Ej 。计算方式如公式 8 所示:
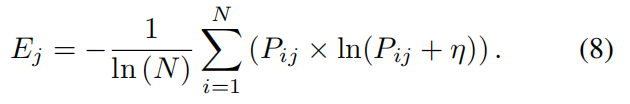
如果某个目标的所有Pij都差不多(分布均匀),熵值会很高;如果数据差异大,熵值会较低。
其中 i = 1 , 2 , ... , N i = 1,2,\ldots ,N i=1,2,...,N , j = 1 , 2 , ... , M j = 1,2,\ldots ,M j=1,2,...,M 。 N N N 表示样本总数, M M M 表示目标数量。为避免 ln ( 0 ) \ln \left( 0\right) ln(0) 的出现,引入了一个小的正数 η \eta η 。
信息熵的计算基于香农熵 ,表达式为 H ( X ) = − ∑ ( P ( x ) × log ( P ( x ) ) ) H\left( X\right) = - \sum \left( {P\left( x\right) \times \log \left( {P\left( x\right) }\right) }\right) H(X)=−∑(P(x)×log(P(x))) 。此外,系数 1 ln ( N ) \frac{1}{\ln \left( N\right) } ln(N)1 用于将信息熵的值限制在 0 , 1 \left\lbrack {0,1}\right\rbrack 0,1 范围内。
最后,对每个目标 j ( j = 1 , 2 , ... , M ) j\left( {j = 1,2,\ldots ,M}\right) j(j=1,2,...,M) ,计算其权重 W j {W}_{j} Wj (公式 9),其中 k = 1 , 2 , ... , M k = 1,2,\ldots ,M k=1,2,...,M , M M M 表示目标总数。
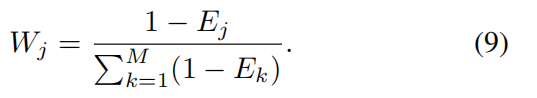
包含更多信息(熵值较低)的目标将被分配更大的权重。
利用计算得到的权重 W W W ,我们可以推导出基于信息熵的加权梯度 (EWG) g ^ \widehat{g} g :
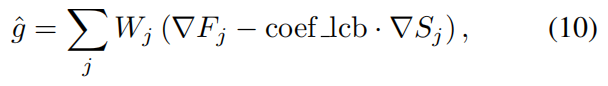
其中 W j {W}{j} Wj 是第 j j j 个目标基于熵的权重; ∇ F j \nabla {F}{j} ∇Fj 是第 j j j 个目标代理模型(高斯过程)均值的梯度; ∇ S j \nabla {S}{j} ∇Sj 是第 j j j 个目标代理模型标准差的梯度; coef_lcb \operatorname{coef\ lcb} coef_lcb 是一个系数(默认设置为 0.1),用于在 LCB(下界置信区间)策略中平衡均值和标准差。
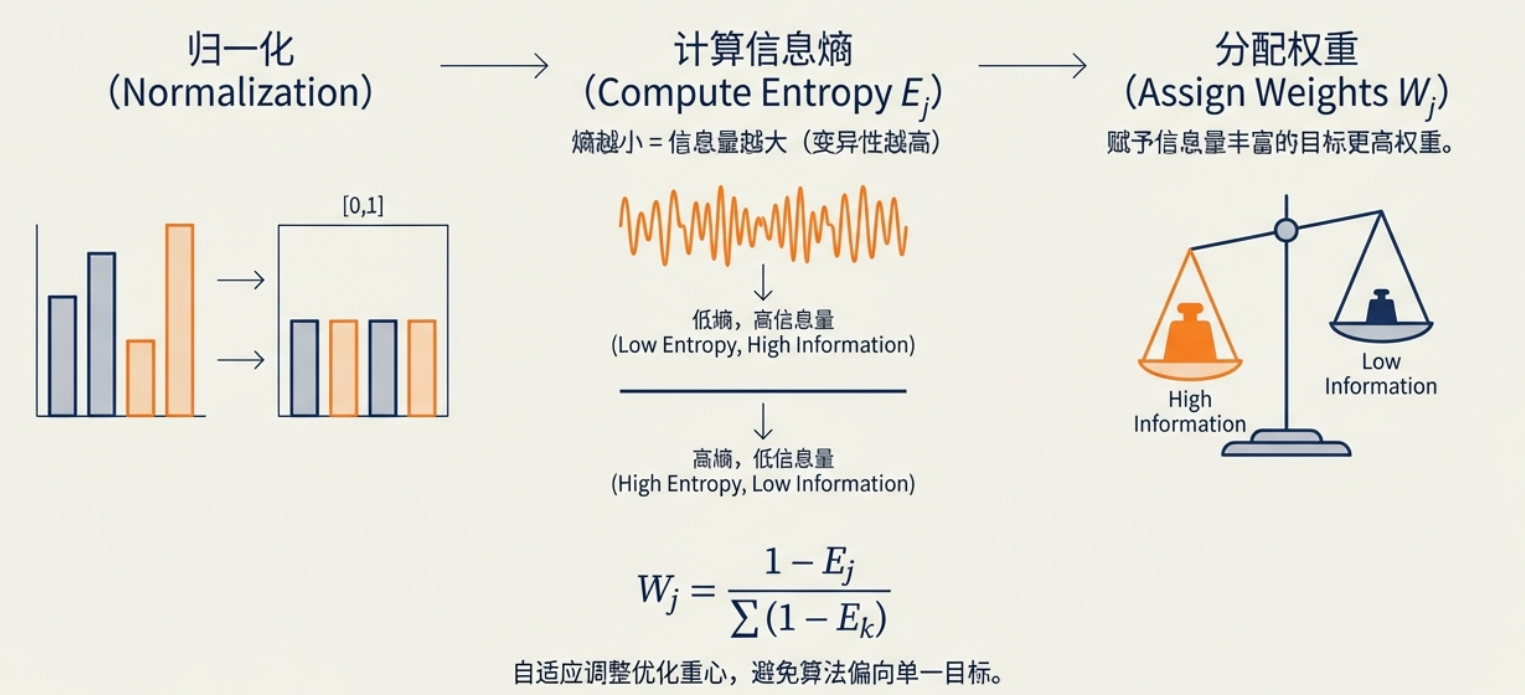
这种基于信息熵的自适应加权方法,根据目标的信息熵分配权重。该方法减少了为不同目标值分配权重时的主观性,并确保算法更关注信息丰富的目标,从而在 EMOPs 上取得更好的性能。
选择策略
批量选择
在得到 CDM-PSL 采样的解之后,采用了 PSL-MOBO (Li 等,2022) 中的批量选择策略 来选择一小部分解
X k B = { x b ∣ b = 1 , ... , B } {X}{k}^{B} = \{ {x}{b}|b = 1,\ldots ,B\} XkB={xb∣b=1,...,B} 。该策略使用超体积(HV)指标(Zitzler 和 Thiele,1999)作为选择准则,定义如下:
真实的目标函数评估代价极高,扩散模型可以生成大量候选解,但只挑选少量的解进行真实评估。
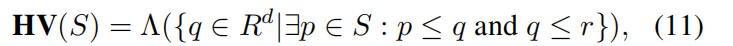
其中 S S S 表示解集, r r r 是参考向量, Λ ( ⋅ ) \Lambda \left( \cdot \right) Λ(⋅) 表示勒贝格测度。
HV是衡量多目标解集质量的常用指标,表示解集S在目标空间中支配的区域体积,算法计算候选解对当前Pareto前沿的HV贡献,选择哪些能最大化HV增量的解进入评估批次。
算子选择
在每次迭代结束时,设计了一种基于 HV 指标增长率的算子切换策略 。在算法 1 中,Flag_CDM 是一个标志位,用于指示当前是否使用 CDM 生成后代。经过一个迭代窗口 (例如,3 次评估轮次) 后,如果 HV 指标的增长率低于预设阈值(默认设置为 5%),我们就将后代生成算子切换为另一种算子(例如,从 CDM-PSL 切换到
遗传算法(GA))。这是为了防止算法陷入当前算子特有的局部最优。
扩散模型虽然在学习分布方面很强,但在优化后期可能会陷入特定算子的局部最优。设计了一种动态机制,在"扩散模型生成"和"传统进化算法生成"之间进行切换。
实验部分
测试实例与基线
在 9 个基准问题 (2 目标和 3 目标的 ZDT1-3(Zitzler、Deb 和 Thiele,2000)和 DTLZ2-7(Deb 等,2005))和 7 个真实世界问题(Tanabe 和 Ishibuchi,2020)上进行了实验。此外,我们将 CDM-PSL 与 9 种主流的经典算法进行了比较,包括 NSGA-II(Deb 等,2002)、MOEA/D-EGO(Zhang 等,2008)、TSEMO(Bradford、Schweidtmann 和 Lapkin,2018)、USEMO-EI(Bekiaris-Liberis 等,2020)、DGEMO(Konakovic Lukovic、Tantar 和 Matusik,2020)、PSL-MOBO(Li 等,2022)、qNParEGO(Knowles,2006)、qEHVI(Daulton、Balandat 和 Bakshy,2021)和 qNEHVI(Daulton、Balandat 和 Bakshy,2021)。
参数设置
为了公平比较,所有对比算法的种群大小 N 均初始化为 100。贝叶斯优化算法在 20 个批次上执行,每个批次的大小为 5,所有算法均如此。每种方法都随机运行 10 次。对于 CDM-PSL,超参数 η 设置为 25,CG 的数量 N1 设置为 10,无条件生成的数量 N2 设置为 100,批次大小 m 设置为 1024,学习率 γ 设置为 0.001,训练过程包含 400 个 epoch。其他方法的配置与原始论文保持一致。
评估指标
采用公式 1 中的超体积(HV)指标来评估所获得解的质量。HV 值越高,表示解的性能越好。
在附录 C.1 和 C.2 中提供了对扩散模型和熵加权方法优势的详细分析。更多细节,包括对数 HV 差异、数值结果、运行时间、参数敏感性分析以及额外的实验和讨论,都在附录 C.3 至 C.12 中展示。
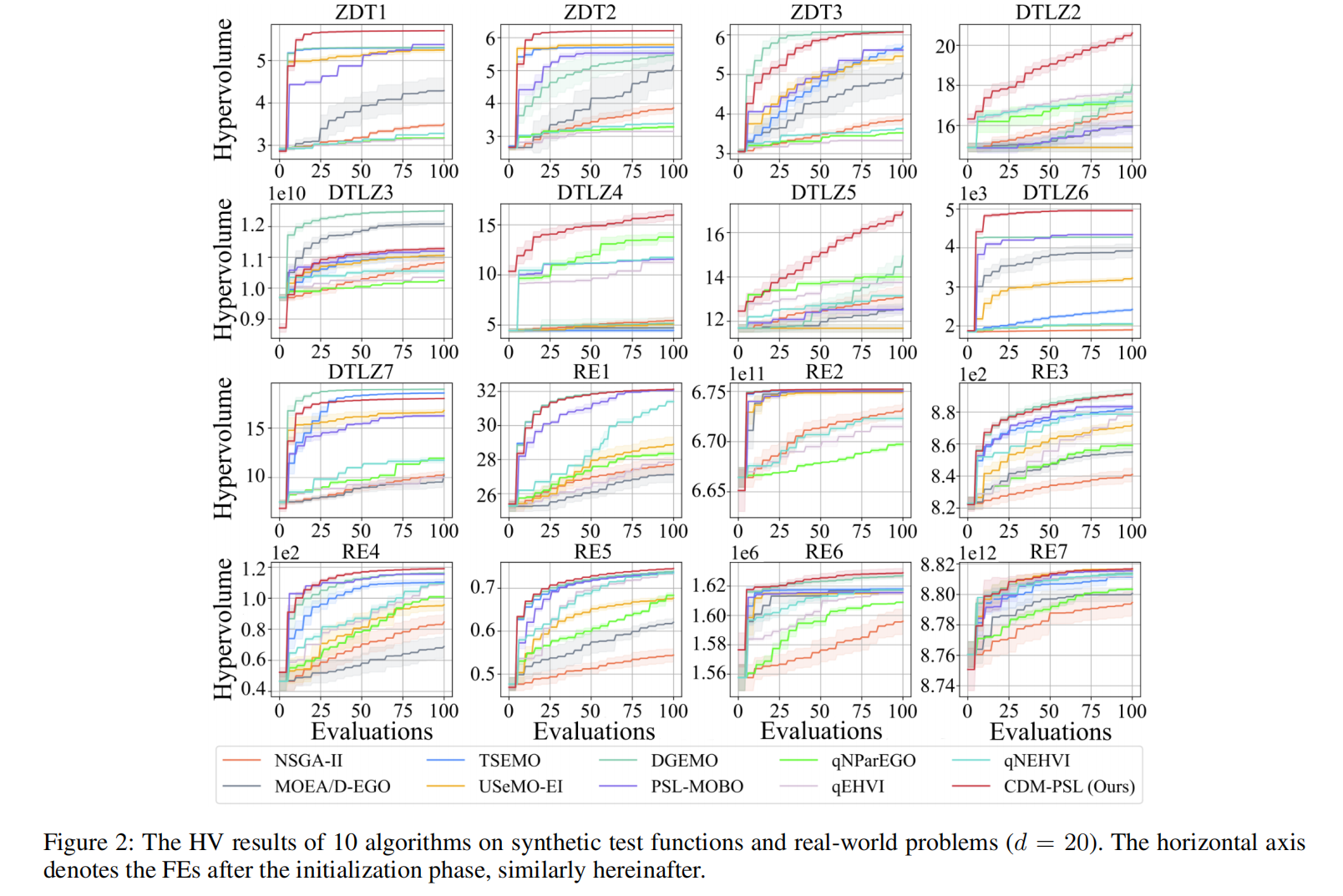
图 2 展示了 HV 指标随函数评估次数(FE)变化的对比。CDM-PSL 在所有合成基准问题上都表现出卓越的性能,在收敛速度和最终值方面均优于其他算法。此外,CDM-PSL 在真实世界问题上也表现出理想的性能。这些发现充分证明了所提出的 CDM-PSL 的有效性和优越性。
消融实验
如图 3 所示,CDM-PSL w/o Weight(使用普通梯度而非熵加权梯度(EWG)引导采样过程)在所有六个测试问题上的收敛性能均不如 CDM-PSL,并且在 ZDT3、DTLZ3 和 DTLZ6 上取得了更差的最终值。这表明 EWG 能够更准确地衡量目标的重要性,从而为采样过程提供更有效的引导。
- CDM-PSL w/o Condition(省略了条件生成组件)同样如此。在所有测试问题上,CDM-PSL 始终且显著地优于 CDM-PSL w/o Condition。这清楚地验证了 CDM-PSL 中条件生成组件的关键作用和有效性。
- CDM-PSL w/o Switch(CDM-PSL 的一个变体,没有切换策略)在 ZDT3 和 DTLZ3 上的消融实验结果表明,该策略的引入有利于提高收敛速度。
- CDM-PSL w/o DM(使用 GA 替代基于扩散模型的帕累托集学习模型作为生成算子,利用模拟二进制交叉(SBX)生成新解)的性能明显不如默认的 CDM-PSL。这种性能上的差距充分证明了基于扩散模型的帕累托集学习的有效性。
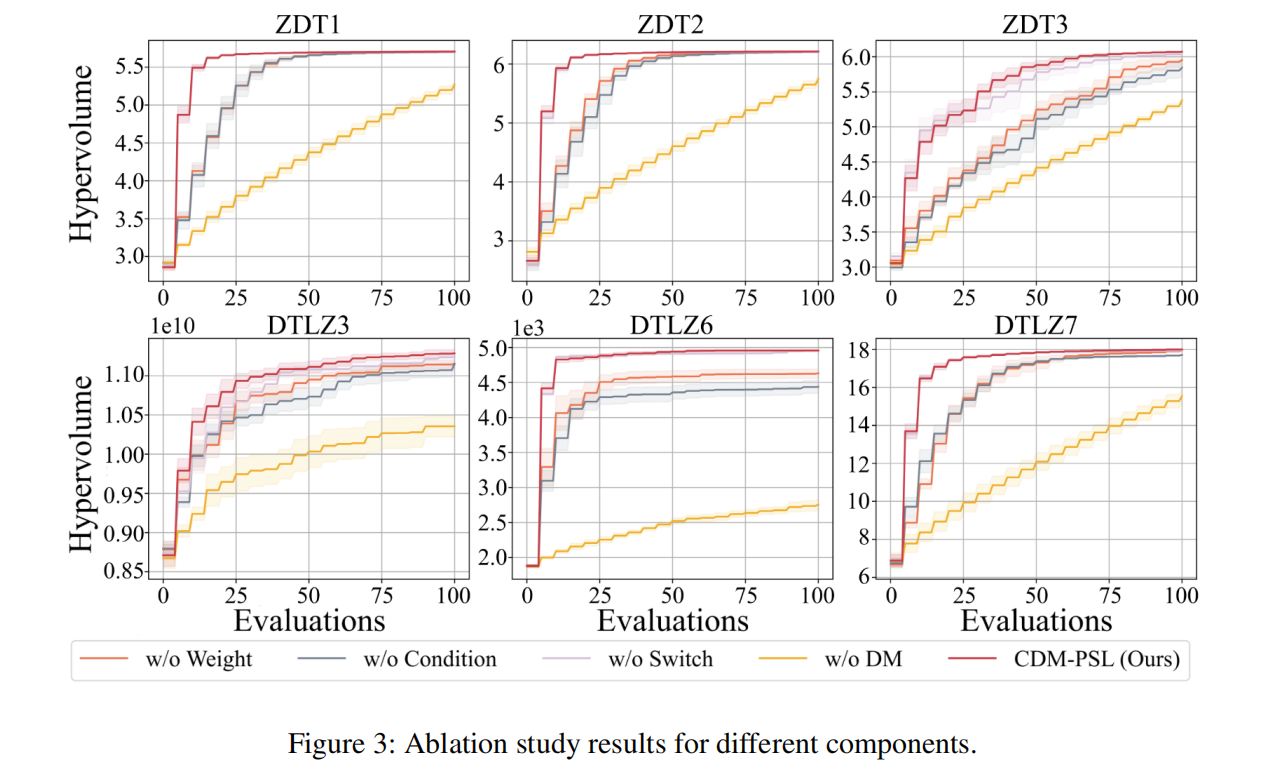
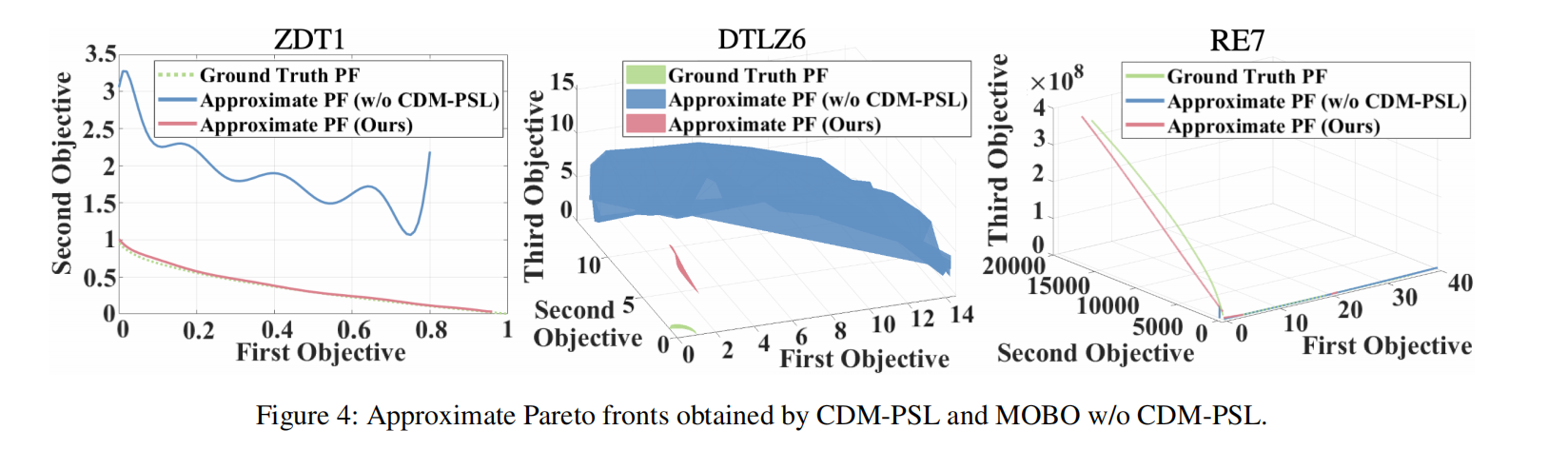
图 4 展示了 CDM-PSL 和不使用 CDM-PSL 的 MOBO 算法基于后验均值得到的解。显然,CDM-PSL 在合成基准问题和真实世界问题上都超越了不使用 CDM-PSL 的 MOBO 算法。例如,在给定有限函数评估次数的情况下,不使用 CDM-PSL 的 MOBO 算法难以逼近真实的 PF,而 CDM-PSL 则能有效捕获真实 PF 的几乎所有特征。在 ZDT1 上,CDM-PSL 可以在有限的函数评估次数内更快地逼近真实 PF。在 3 目标 DTLZ6 问题上,CDM-PSL 也能在有限的函数评估次数内更快地逼近真实 PF。此外,我们的方法在复杂问题上展现出了良好的开发能力,例如火箭喷射器设计(RE7)(Vaidyanathan 等,2003),其特点是具有复杂的 PF,帕累托最优解分布在多个区域。更多 PF 的结果请见附录 C.9。
代码解读
项目结构:
python
cdm_psl/
├── evolution/ │ ├── dom.py # Pareto 支配关系
│ ├── norm.py # 归一化工具
│ └── utils.py # 进化辅助函数
├── learning/ # 神经网络模块
│ ├── model.py # 神经网络架构
│ ├── model_init.py # 模型初始化
│ ├── model_update.py # 训练过程
│ ├── prediction.py # 推理逻辑
│ └── utils.py # 学习工具
├── mobo/ # MOBO 框架核心
│ ├── algorithms.py # 算法配置
│ ├── acquisition.py # 采集函数
│ ├── mobo.py # 基框架类
│ ├── selection.py # 选择策略
│ ├── surrogate_model/ # GP 实现
│ └── solver/ # 各种优化求解器
├── data_enhancement.py # 数据增强技术
├── diffusion.py # 核心扩散模型
├── problem.py # 基准问题定义
├── run_d20.py # 主执行脚本
├── lhs.py # 拉丁超立方采样
└── utils.py # 通用工具快速开始:
python
cd CDM-PSL/cdm_psl
pip install -r requirements.txt主要依赖项:
- PyTorch 2.0.1+cu118:支持 CUDA 的深度学习框架
- GPyTorch 1.11:用于代理建模的高斯过程模型
- PyMOO 0.6.0.1:多目标优化基准问题
- JAX/NumPyro:高效数值计算
- DEAP/Scikit-learn:进化计算和机器学习工具
执行提供的示例脚本,在 DTLZ2 基准问题上运行 CDM-PSL。这是验证安装并查看算法实际运行效果的最简单方法
python
bash example_dtlz2.sh问题:DTLZ2(3 目标测试问题)------- 通过拉丁超立方采样(LHS)获取 100 个样本。20 次迭代,每次迭代 5 个样本。200 次函数评估(昂贵优化场景)
主执行脚本:run_d20.py
run_d20.py 中的核心算法循环实现了以下关键步骤:
- 数据初始化:使用拉丁超立方采样(LHS)生成初始种群
- 模型训练:初始化 Pareto-Net 支配分类器并拟合高斯过程代理模型
- 自适应切换:监测超体积(Hypervolume)改进,根据收敛模式在扩散模型和 SBX 交叉之间动态切换
- 后代生成:使用选定的算子生成新的候选解
- 评估:在实际昂贵问题上评估候选解
- 模型更新:用新数据点更新代理模型
该算法使用自适应切换机制(run_d20.py 第 162-166 行),监测最近 3 次迭代的超体积改进。如果改进低于 5%,它会从扩散算子切换到进化算子以跳出局部最优。这种混合方法有效地平衡了探索和开发。
CDM-PSL 通过 problem.py 模块支持多个基准问题套件。你可以使用 --prob 参数指定不同的问题来运行算法。
| 问题套件 | 示例 | 维度 | 目标数 | 描述 |
|---|---|---|---|---|
| ZDT 系列 | zdt1, zdt2, zdt3 | 20 | 2 | 具有不同帕累托前沿特性的经典双目标测试问题 |
| DTLZ 系列 | dtlz2, dtlz3, dtlz4, dtlz5, dtlz6, dtlz7 | 20 | 3 | 具有 3 个目标的可扩展测试问题,包含多种前沿形状和约束 |
| RE 系列 | re1, re2, re3, re4, re5, re6, re7 | 4 | 2-3 | 真实世界的工程设计优化问题(梁、压力容器、减速器等) |
在不同的基准问题上运行实验,修改命令行参数:
python
python3 run_d20.py --prob zdt1
# 运行 DTLZ4 问题(3 目标)
python3 run_d20.py --prob dtlz4
# 运行 RE3 工程问题(3 目标)
python3 run_d20.py --prob re3关键配置参数:
| 参数 | 默认值 | 描述 |
|---|---|---|
| n_run | 5 | 独立运行次数,用于统计可靠性 |
| n_init | 100 | 由 LHS 生成的初始样本数量 |
| n_iter | 20 | 优化迭代次数 |
| n_sample | 5 | 批量大小(每次迭代的新候选数) |
| n_steps | 1000 | 扩散模型训练的学习步数 |
| n_pref_update | 10 | 每个更新步采样的偏好数 |
| coef_lcb | 0.1 | 下置信界系数 |
| n_candidate | 1000 | 近似帕累托前沿上的候选数 |
| device | "cuda" | 计算设备 |