作为 Java 开发者,我们享受着自动内存管理的便利,但面试和线上调优时,JVM 的垃圾回收(GC)往往是绕不开的大山。
很多人背八股文时会感到割裂:一会儿是"标记清除算法",一会儿是"三色标记",一会儿又是"CMS/G1",它们到底是什么关系?
本文将自顶向下,帮你构建一张完整的 JVM 垃圾回收知识图谱。
前置知识:核心概念综述,从理论到实践
在深入探讨具体的算法实现之前,我们需要构建一个关于 Java 垃圾回收(GC)的宏观知识图谱。我们将从判定标准 、回收策略 、落地实现 以及调优演进四个维度来拆解 GC 体系。
1. 判定标准:什么是垃圾?
GC 的首要任务是判断哪些对象是"存活"的,哪些是"垃圾"。
-
早期探索(引用计数法) :通过计算对象被引用的次数来判断。但它有一个致命缺陷------无法解决循环引用(A 引用 B,B 引用 A,两者都无外部引用)导致的内存泄漏问题,因此已被现代 JVM 抛弃。
-
现代标准(根可达性算法) :这是 Java 目前使用的核心法则。以一系列 GC Roots (如栈中引用的对象、静态变量等)为起点,沿着引用链向下搜索。凡是不可达的对象,无论它们之间是否有连接,均被视为垃圾。
2. 核心策略:垃圾回收算法
确定了垃圾之后,我们需要高效地清理它们。主流的基础算法有三种,它们各有优劣:
-
标记-清除 (Mark-Sweep):
-
特点:直接标记出垃圾并清除。
-
优点:速度快,基础简单。
-
缺点 :会产生大量内存碎片,导致后续分配大对象时可能因无法找到连续空间而触发 GC。
-
-
标记-整理 (Mark-Compact):
-
特点:清除垃圾后,将存活对象向一端移动、整理。
-
优点 :无内存碎片。
-
缺点:涉及对象的移动,效率相对较低。
-
-
复制算法 (Copying):
-
特点:将内存分为两块,每次只用一块。回收时将活对象复制到另一块,清空当前块。
-
优点 :运行高效,且无内存碎片。
-
缺点 :空间利用率低,需要占用双倍内存空间(以空间换时间)。
-
3. 管理思想:分代垃圾回收
在实际应用中,JVM 不会单一地使用某种算法,而是基于**"对象生命周期不同"这一事实,采用了分代管理**策略:
-
年轻代 (Young Gen):
-
特点:存放"朝生夕死"的对象,GC 频率极高。
-
策略 :采用 复制算法。因为存活对象少,复制成本低,效率最高。
-
-
老年代 (Old Gen):
-
特点:存放生命周期长的对象,GC 频率较低。
-
策略 :采用 标记-整理 或 标记-清除 算法。因为对象存活率高,不适合用复制算法(空间浪费且复制开销大)。
-
4. 落地执行:垃圾回收器
垃圾回收器是上述算法的具体实现者。不同的回收器适用于不同的业务场景:
-
CMS (Concurrent Mark Sweep):
-
定位 :老年代收集器,响应时间优先(低延迟)。
-
核心机制 :基于标记-清除算法。
-
亮点 :在最耗时的"并发标记"和"并发清理"阶段,允许 GC 线程与用户线程同时工作,从而极大降低了 STW(Stop The World)停顿时间。
-
-
G1 (Garbage First):
-
定位 :全年代收集器,面向大内存,追求可预测的停顿时间。
-
核心机制 :打破了物理分代,将堆划分为多个大小相等的 Region。
-
亮点 :它能根据用户设定的目标(如 STW 不超过 200ms),优先回收垃圾收益最高的 Region。这使得它在控制停顿时间的同时,保持了较高的吞吐量。
-
5. 演进与调优:GC 的自我修养
理解了回收器后,我们需要根据系统特性进行选择和调优:
-
回收器的选择:
-
标准吞吐量 :JDK 8 默认使用 Parallel GC。
-
低延迟要求 :如果系统对响应时间敏感,可切换为 CMS。
-
大内存 & 可控停顿 :如果拥有超大堆内存且需要精准控制 STW 时间,G1 是最佳选择。
-
-
JVM 内部优化:
-
元空间 (Metaspace):JDK 8 将方法区从堆内存(永久代)移到了本地内存(元空间)。这是为了适应动态类加载技术的发展,避免因永久代大小固定导致的 OOM 问题。
-
减负手段 :通过逃逸分析 和栈上分配技术,让未逃逸的对象直接在栈上分配并销毁,从而减少堆内存的分配压力和 GC 频率。
-
一、 顶层视角:它们到底是什么关系?
在深入细节前,我们需要先上帝视角看清各个概念在 JVM 体系中的层次。
-
根可达性算法 :这是宪法。它规定了"什么是垃圾,什么是活人"。所有的回收器必须遵守这个标准。
-
基础回收算法(标记清除/复制/整理) :这是战略。它是处理垃圾的宏观策略(是直接扔、还是搬家、还是整理)。
-
三色标记法 :这是战术。它专门解决**"并发"**问题。当垃圾回收线程和用户线程同时运行时,如何保证标记不乱套?靠的就是三色标记。
-
垃圾回收器(CMS/G1) :这是执行者(士兵)。它们是上述理论的具体代码实现。
核心层次图
要弄明白垃圾回收,理解他们之间的层次关系至关重要。

一句话总结:
CMS 和 G1 是两名不同的清洁工,他们都遵守根可达性(宪法)来判断垃圾。为了能在大家工作时不关门打扫(并发),他们都用到了三色标记(战术)。只不过 CMS 习惯用标记-清除(战略),而 G1 习惯用标记-整理/复制(战略)。
二、 判决标准:根可达性算法 (Reachability Analysis)
在 Java 中,我们早已抛弃了"引用计数法",而是采用根可达性算法来判断对象死活。
1. 核心逻辑
JVM 会寻找一批"绝对不能回收"的对象作为起点,称为 GC Roots。
-
从这些起点开始向下搜索,连在一起的(引用链上)就是活的。
-
断开链接的,哪怕它们之间互相引用,也是垃圾。
2. 谁是 GC Roots?(记四类即可)
-
栈中引用的对象 (比如你正在执行的方法里的
User user = ...)。 -
方法区中静态变量引用的对象 (
static修饰的)。 -
方法区中常量引用的对象 (
final修饰的)。 -
本地方法栈中引用的对象(Native 方法)。
-
被同步锁持有的对象 (
synchronized锁住的)。
三、 并发标记的核心:三色标记法 (Tri-color Marking)
正常的标记过程,应该是需要STW的,对象的引用关系是不会变化的,才能标记正确
但是这个标记过程需要消耗时间,可能导致STW的时间很长。
因此为了减少STW的时间,才出现了三色标记法,它允许并发标记,允许用户线程工作
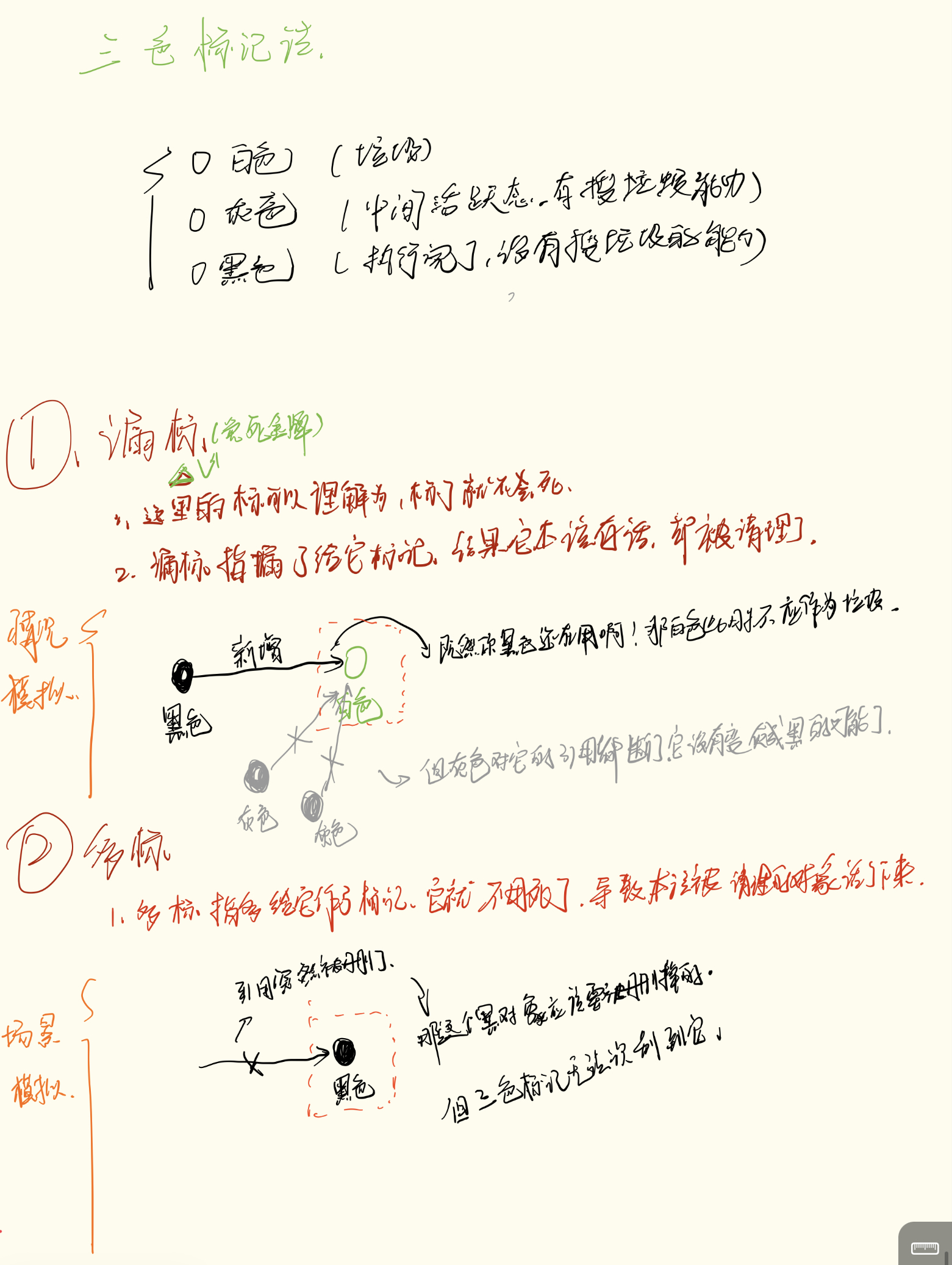
1. 三种颜色的含义
我们将对象分为三种状态:
-
⚪ 白色 :未被访问。如果扫描结束还是白色,说明是垃圾(死罪)。
-
🔘 灰色 :正在访问。自己被标记了,但引用的子对象还没检查完。(任务队列)。
-
⚫ 黑色 :访问完毕。自己和引用的子对象都检查完了。GC 以后不会再理它(免死金牌)。
2. 并发下的难题:漏标与多标
在用户线程一边跑、GC 一边标的过程中,会发生两种情况:
A. 多标(浮动垃圾):多标,这个标就相当于一个免死金牌,也就是多给他上了一个免死金牌,导致它本来应该是垃圾却没有被回收。
-
现象:对象 A 已经是黑色了,结果用户突然把 A 的引用断开了。
-
结果:A 本来该死,但因为已经是黑色,GC 这轮不杀它。
-
影响 :无害。多占点内存而已,下次 GC 再杀。
B. 漏标(对象消失 - 致命 BUG):漏标,这个标也同样是免死金牌,漏掉了这个免死金牌,导致它本不应该被回收的却被回收了。
-
现象 :本来活着的对象,被当成白色垃圾杀了。
-
成因(必须同时满足):
-
灰色断开:灰色对象断开了对白色对象的引用。
-
黑色指向:黑色对象(已免检)重新引用了这个白色对象。
-
-
结果:白色对象躲到了黑色对象身后,GC 扫描器看不见,直接把它回收了。程序崩溃。
3. 解决方案
CMS 和 G1 分别打破上述两个条件之一来解决漏标:
-
CMS (增量更新) :关注新增 。只要黑色对象指向了白色,把黑色变回灰色。下次重新扫描它。(针对漏标的条件1)
-
G1 (原始快照 SATB) :关注删除 。只要灰色对象断开了白色,把这个引用记录下来。不管它真的还是假的,这轮 GC 先当它是活的。(针对漏标的条件2)
四、 落地实现:CMS 与 G1 的巅峰对决
理解了底层的算法和三色标记法后,我们来看看 JVM 中最著名的两款垃圾回收器:CMS 和 G1。它们代表了 JVM 垃圾回收技术的两个重要里程碑。
1. CMS (Concurrent Mark Sweep) ------ 老年代的"低延迟专家"
设计目标 : CMS 是第一款真正意义上的并发收集器,它的核心目标是 响应时间优先。它致力于将 STW(Stop The World)停顿时间降到最低,非常适合对延迟敏感、希望用户感知不到卡顿的系统(如 Web 服务器)。
核心原理 : 为了实现低停顿,CMS 采用了 "标记-清除" 算法,并且创新性地实现了让垃圾回收线程与用户线程并发工作。
CMS 回收的详细过程: 整个过程分为四个阶段,其中只有两个阶段需要 STW:
-
初始标记 (Initial Mark)
[需 STW]:-
仅仅标记 GC Roots 直接关联的对象。
-
特点:速度极快,因为只查第一层引用。
-
-
并发标记 (Concurrent Mark)
[与用户线程并发]:-
从初始标记的对象出发,遍历整个对象图,标记所有可达的对象。
-
特点:这是最耗时的阶段,但它与用户线程同时运行,所以用户无感知。
-
-
重新标记 (Remark)
[需 STW]:-
目的 :由于并发标记阶段用户线程还在跑,可能会修改对象的引用关系,导致 "漏标"(即本来活着的对象被当成了垃圾,详见上文三色标记法)。
-
动作:需要再次暂停,修正这些在并发期间变动的标记记录,确保准确性。
-
-
并发清理 (Concurrent Sweep)
[与用户线程并发]:-
清理掉那些未被标记的垃圾对象。
-
特点:因为采用"标记-清除"算法,不需要移动存活对象,所以可以并发进行。
-
CMS 的弊端(阿喀琉斯之踵): 虽然 CMS 实现了低延迟,但它付出了昂贵的代价:
-
1. 内存碎片问题
-
原因 :CMS 基于 "标记-清除" 算法。它只管清除垃圾,不进行内存整理。
-
影响:长期运行后,老年代会布满像蜂窝煤一样的碎片。即使总剩余空间很大,但当需要分配一个连续的大对象时,找不到足够大的连续空间,只能被迫触发 Full GC。
-
-
2. 浮动垃圾问题
-
原因 :在 并发清理 阶段,用户线程还在运行,这期间产生的垃圾 CMS 这一轮是看不见的(无法标记),只能留到下一轮处理。这些垃圾被称为"浮动垃圾"。
-
影响:这要求 CMS 不能像其他收集器那样等老年代满了再回收,必须预留一部分空间给用户线程和浮动垃圾使用。如果预留不够,就会导致并发模式失败。
-
-
3. 退化风险 (Concurrent Mode Failure)
-
当"内存碎片过多"导致大对象分配失败,或者"浮动垃圾过多"导致老年代预留空间不足时,CMS 会宣告失败。
-
后果 :它会 退化为 Serial Old 垃圾回收器。这是一款单线程、基于"标记-整理"算法的回收器。它会强制所有用户线程暂停(长时间 STW),慢慢整理内存。这是系统卡死的噩梦。
-
2. G1 (Garbage First) ------ 全年代的"可控管家"
堆划分的革命 (Region): G1 彻底打破了物理分代的界限。
-
它不再将堆简单地分为一大块新生代和一大块老年代。
-
它将整个堆内存划分为 2000 多个大小相等的 Region(独立区域)。
-
每个 Region 的身份(Eden、Survivor、Old、Humongous)是动态分配的。
-
意义 :"分区"取代了"分代"。算法驱动设计,这种结构让回收策略变得极其灵活。
核心特点:可预测的停顿模型 G1 最大的卖点在于:用户可以指定垃圾回收的 STW 停顿时间目标 (例如:-XX:MaxGCPauseMillis=200,即每次回收尽量不超过 200ms)。
实现原理 : G1 为什么能"说到做到"?这得益于它的 Garbage First(垃圾优先) 策略:
-
G1 会在后台维护一张表,记录每个 Region 里的"垃圾有多少"以及"回收它需要多久"。
-
当进行回收时,G1 不会傻傻地回收整个老年代。它会根据你的时间目标(比如 200ms),只选择回收那些垃圾最多、回收收益最大的 Region。
-
效益最大化:回收范围缩小了(省时间),但回收掉的垃圾却很多(高效率),从而完美命中用户设定的暂停目标。
G1 回收的详细过程: G1 的回收过程与 CMS 类似,但在最后一步有本质区别:
-
初始标记 (Initial Mark)
[需 STW]:标记 GC Roots 直接关联的对象。 -
并发标记 (Concurrent Mark)
[与用户线程并发]:进行全局的可达性分析。 -
最终标记 (Final Mark)
[需 STW]:类似于 CMS 的重新标记,处理并发期间引用变动导致的漏标问题(G1 使用 SATB 算法,比 CMS 更快)。 -
混合回收 (Mixed GC)
[需 STW]:-
这是 G1 的精髓。它不再只回收年轻代或老年代。
-
计划 :它会基于暂停时间目标,制定一个回收计划,选择 所有年轻代 Region + 部分收益高的老年代 Region + 大对象 Region。
-
动作 :它采用 标记------复制算法。将这些 Region 里的存活对象复制到空的 Region 中,然后清空原 Region。
-
结果 :既完成了回收,又顺便进行了内存整理,没有内存碎片。
-
So : G1 是一款集大成者,适用于 拥有超大堆内存 、追求 高吞吐量 且需要 低延迟、可预测暂停时间 的现代系统。它用更先进的 Region 结构和算法,解决了 CMS 难以克服的碎片问题。
五、 总结与对比分析
最后,我们将这两位主角放在一起对比,助你彻底拿下面试题。
| 维度 | CMS 收集器 | G1 收集器 |
|---|---|---|
| 适用区域 | 仅老年代 (因为老年代对象很多占总的2/3) | 全堆 (新生代 + 老年代) |
| 内存结构 | 传统的物理分代 | Region 分区 (逻辑分代) |
| 回收算法 | 标记-清除 (有碎片) | 标记-复制/整理 (无碎片) |
| 并发漏标解法 | 增量更新 (重新扫描黑色对象) | SATB (保留快照,不重扫) |
| STW 控制 | 尽力而为 (不可控) | 精准控制 (用户设定目标) |
| 最大弱点 | 碎片导致 Full GC 退化 | 内存占用较高 (跨代引用表) |
| 一句话定位 | JDK 8 之前的低延迟首选 | JDK 9+ 默认的大内存管家 |
结语
记住:根可达性是宪法,垃圾回收算法是战略,三色标记是战术,而 CMS 和 G1 则是落地实现。