一、队列类型选择:Classic vs Quorum vs Stream
RabbitMQ 3.8+版本引入了三种队列类型,各自适用于不同的业务场景。合理选择队列类型是优化系统性能的关键。
1.1 Classic经典队列 - 传统可靠的选择
特性:
-
支持持久化(Durable)和非持久化(Transient)
-
支持自动删除(Auto delete)
-
完整的RabbitMQ功能支持
-
FIFO消息顺序
适用场景:
-
企业内部系统调用
-
消息量适中,无大规模堆积
-
需要完整RabbitMQ功能特性
声明示例:
// 持久化Classic队列
channel.queueDeclare("classic_queue", true, false, false, null);
// 非持久化Classic队列
channel.queueDeclare("classic_queue_temp", false, false, true, null);性能特点:
-
消息直接保存在内存,消费后删除
-
消息堆积时性能显著下降
-
支持懒队列模式(Lazy Mode,3.13+已不推荐)
1.2 Quorum仲裁队列 - 官方推荐的未来
核心特性:
-
基于Raft一致性协议
-
消息强制持久化
-
分布式高可靠保证
-
自动处理"毒消息"
适用场景:
-
对数据安全性要求高的业务(如订单、支付)
-
长期存在的队列
-
分布式集群环境
功能对比表:
| 特性 | Classic队列 | Quorum队列 |
|---|---|---|
| 非持久化队列 | 支持 | 不支持 |
| 独占队列 | 支持 | 不支持 |
| 消息持久化 | 可选 | 始终持久化 |
| 毒消息处理 | 无 | 自动标记删除 |
| 全局QoS | 支持 | 不支持 |
| 延迟要求 | 低延迟 | 一致性优先 |
声明示例:
Map<String, Object> quorumArgs = new HashMap<>();
quorumArgs.put("x-queue-type", "quorum");
// 可选:毒消息投递次数限制
quorumArgs.put("x-delivery-limit", 5);
channel.queueDeclare("quorum_queue", true, false, false, quorumArgs);毒消息处理机制:
// Quorum队列自动跟踪投递次数
AMQP.BasicProperties properties = new AMQP.BasicProperties.Builder()
.headers(new HashMap<String, Object>() {{
put("x-delivery-count", 3); // RabbitMQ自动维护
}})
.build();
// 当投递次数超过x-delivery-limit时,消息会被删除或转入死信队列1.3 Stream流式队列 - 大数据量场景利器
核心特性:
-
Append-only日志存储
-
消息回溯和时间旅行
-
大规模分发支持
-
高吞吐性能
适用场景:
-
日志收集与分析
-
大数据流处理
-
消息回溯需求场景
-
海量消息堆积(百万级以上)
声明示例:
Map<String, Object> streamArgs = new HashMap<>();
streamArgs.put("x-queue-type", "stream");
// 流最大大小:20GB
streamArgs.put("x-max-length-bytes", 20_000_000_000L);
// 段文件大小:100MB
streamArgs.put("x-stream-max-segment-size-bytes", 100_000_000);
// 最大年龄(毫秒)
streamArgs.put("x-max-age", "7D");
channel.queueDeclare("stream_queue", true, false, false, streamArgs);消费示例(原生API):
Map<String, Object> consumeArgs = new HashMap<>();
// 消费偏移量设置
consumeArgs.put("x-stream-offset", "first"); // 从头开始
// consumeArgs.put("x-stream-offset", "last"); // 从最新开始
// consumeArgs.put("x-stream-offset", 1000L); // 指定偏移量
// consumeArgs.put("x-stream-offset", new Date(System.currentTimeMillis() - 3600000)); // 1小时前
channel.basicConsume("stream_queue", false, consumeArgs, new DefaultConsumer(channel) {
@Override
public void handleDelivery(String consumerTag, Envelope envelope,
AMQP.BasicProperties properties, byte[] body) {
// 处理消息
long offset = (Long) properties.getHeaders().get("x-stream-offset");
System.out.println("消费偏移量: " + offset);
}
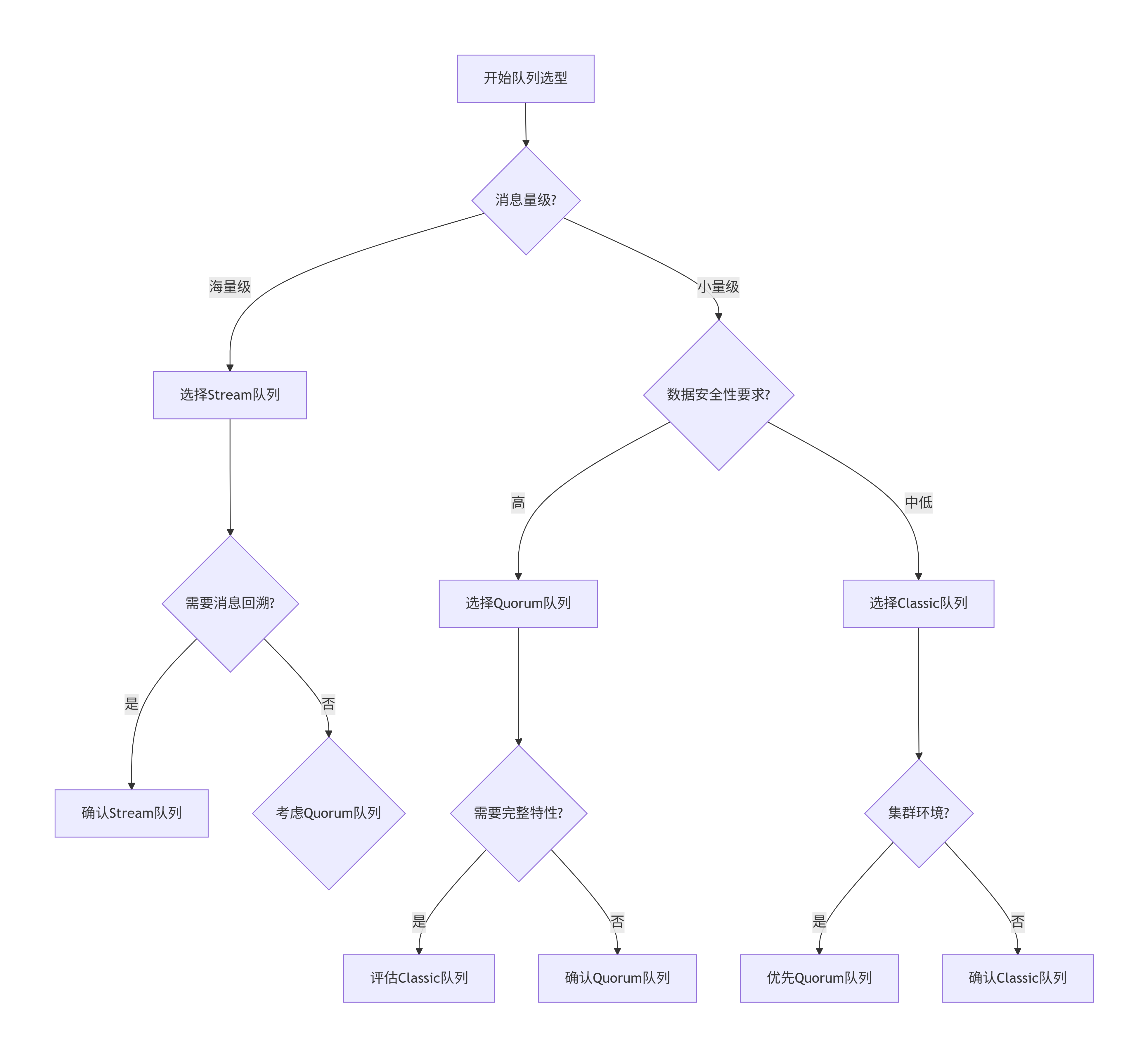
});1.4 队列选型决策树
二、死信队列(DLX)深度应用
2.1 什么是死信队列?
死信队列(Dead Letter Exchange)是RabbitMQ对异常消息的补救机制。当消息无法被正常消费时,会被路由到指定的死信交换机,进而进入死信队列。
2.2 消息成为死信的三种情况
-
消费者拒绝(basic.reject或basic.nack且requeue=false)
-
消息TTL过期
-
队列达到最大长度
2.3 死信队列配置方式
方式一:队列级别配置
// 声明死信交换机
channel.exchangeDeclare("dlx.exchange", BuiltInExchangeType.DIRECT, true);
// 声明业务队列并绑定死信
Map<String, Object> queueArgs = new HashMap<>();
queueArgs.put("x-dead-letter-exchange", "dlx.exchange");
queueArgs.put("x-dead-letter-routing-key", "order.dl");
queueArgs.put("x-message-ttl", 60000); // 消息TTL:60秒
queueArgs.put("x-max-length", 1000); // 队列最大长度
channel.queueDeclare("order.queue", true, false, false, queueArgs);
// 声明死信队列
channel.queueDeclare("dl.queue", true, false, false, null);
channel.queueBind("dl.queue", "dlx.exchange", "order.dl");方式二:策略批量配置
# 为所有以".dlx"结尾的队列配置统一死信交换机
rabbitmqctl set_policy DLX_POLICY \
"^.*\.dlx$" \
'{"dead-letter-exchange":"global.dlx"}' \
--apply-to queues
# 或通过管理界面配置2.4 死信消息标识
死信消息会在Headers中添加标识信息:
// 消费死信队列时检查标识
@RabbitListener(queues = "dl.queue")
public void handleDeadLetter(Message message, Channel channel) {
Map<String, Object> headers = message.getMessageProperties().getHeaders();
// 死信原因
String reason = (String) headers.get("x-first-death-reason");
// 原始队列
String originalQueue = (String) headers.get("x-first-death-queue");
// 原始交换机
String originalExchange = (String) headers.get("x-first-death-exchange");
System.out.println("死信原因: " + reason);
System.out.println("来自队列: " + originalQueue);
// 根据原因进行不同处理
switch (reason) {
case "expired":
handleExpiredMessage(message);
break;
case "rejected":
handleRejectedMessage(message);
break;
case "maxlen":
handleOverflowMessage(message);
break;
}
}2.5 基于死信队列实现延迟队列
RabbitMQ原生不支持延迟队列,但可通过TTL+死信队列实现:
@Configuration
public class DelayQueueConfig {
// 延迟交换机(实际是普通直连交换机)
@Bean
public DirectExchange delayExchange() {
return new DirectExchange("delay.exchange", true, false);
}
// 延迟队列 - 消息在此等待TTL过期
@Bean
public Queue delayQueue() {
Map<String, Object> args = new HashMap<>();
args.put("x-dead-letter-exchange", "process.exchange"); // 过期后转到处理交换机
args.put("x-dead-letter-routing-key", "process.key");
args.put("x-message-ttl", 10000); // 10秒延迟
return new Queue("delay.queue", true, false, false, args);
}
// 实际处理交换机
@Bean
public DirectExchange processExchange() {
return new DirectExchange("process.exchange", true, false);
}
// 实际处理队列
@Bean
public Queue processQueue() {
return new Queue("process.queue", true);
}
@Bean
public Binding delayBinding() {
return BindingBuilder.bind(delayQueue())
.to(delayExchange())
.with("delay.key");
}
@Bean
public Binding processBinding() {
return BindingBuilder.bind(processQueue())
.to(processExchange())
.with("process.key");
}
}
// 使用示例
@Service
public class OrderService {
@Autowired
private RabbitTemplate rabbitTemplate;
public void createOrderWithDelay(Order order, long delayMillis) {
// 动态设置消息TTL
MessagePostProcessor processor = message -> {
message.getMessageProperties().setExpiration(String.valueOf(delayMillis));
return message;
};
rabbitTemplate.convertAndSend("delay.exchange",
"delay.key",
order,
processor);
// 10秒后,消息会自动转到process.queue
}
}多级延迟实现:
// 多个不同TTL的延迟队列实现分级延迟
@Bean
public Queue delayQueue5s() {
Map<String, Object> args = new HashMap<>();
args.put("x-dead-letter-exchange", "process.exchange");
args.put("x-message-ttl", 5000); // 5秒
return new Queue("delay.5s.queue", true, false, false, args);
}
@Bean
public Queue delayQueue30s() {
Map<String, Object> args = new HashMap<>();
args.put("x-dead-letter-exchange", "process.exchange");
args.put("x-message-ttl", 30000); // 30秒
return new Queue("delay.30s.queue", true, false, false, args);
}
@Bean
public Queue delayQueue5m() {
Map<String, Object> args = new HashMap<>();
args.put("x-dead-letter-exchange", "process.exchange");
args.put("x-message-ttl", 300000); // 5分钟
return new Queue("delay.5m.queue", true, false, false, args);
}三、消息分片插件(Sharding Plugin)
3.1 插件作用与原理
解决的问题:
-
单个队列消费能力瓶颈
-
消费者数量有限时的性能提升
-
水平扩展消息处理能力
实现原理:
-
将一个逻辑队列拆分为多个物理分片队列
-
消息均匀分布到各个分片
-
消费者从伪队列消费,Sharding插件负责分片路由
3.2 完整使用步骤
步骤1:启用Sharding插件
# 启用插件
rabbitmq-plugins enable rabbitmq_sharding
# 重启RabbitMQ服务
service rabbitmq-server restart步骤2:配置分片策略
通过管理界面或命令行配置:
# 创建分片策略
rabbitmqctl set_policy sharding_policy \
"^sharding_" \ # 匹配以sharding_开头的交换机
'{"shards-per-node": 3}' \ # 每个节点3个分片
--apply-to exchanges # 应用于交换机步骤3:声明分片交换机
public class ShardingProducer {
private static final String EXCHANGE_NAME = "sharding_order_exchange";
public static void main(String[] args) throws Exception {
ConnectionFactory factory = new ConnectionFactory();
// ... 连接配置
try (Connection connection = factory.newConnection();
Channel channel = connection.createChannel()) {
// 声明分片交换机
Map<String, Object> exchangeArgs = new HashMap<>();
exchangeArgs.put("x-modulus-hash", "sharding"); // 分片标识
channel.exchangeDeclare(EXCHANGE_NAME,
"x-modulus-hash", // 分片交换机类型
true,
false,
exchangeArgs);
// 发送消息 - 消息会根据routing key hash到不同分片
for (int i = 0; i < 10000; i++) {
String orderId = "ORDER_" + i;
String message = "订单消息 " + i;
// routing key影响分片选择
channel.basicPublish(EXCHANGE_NAME, orderId, null, message.getBytes());
if (i % 1000 == 0) {
System.out.println("已发送 " + i + " 条消息");
}
}
}
}
}步骤4:消费分片消息
public class ShardingConsumer {
public static void main(String[] args) throws Exception {
ConnectionFactory factory = new ConnectionFactory();
// ... 连接配置
Connection connection = factory.newConnection();
Channel channel = connection.createChannel();
// 关键:声明伪队列(名称与分片交换机相同)
channel.queueDeclare("sharding_order_exchange", false, false, false, null);
// 启动多个消费者实例
for (int i = 0; i < 3; i++) {
Channel consumerChannel = connection.createChannel();
int consumerId = i + 1;
Consumer consumer = new DefaultConsumer(consumerChannel) {
@Override
public void handleDelivery(String consumerTag, Envelope envelope,
AMQP.BasicProperties properties, byte[] body) {
String message = new String(body, StandardCharsets.UTF_8);
System.out.println("消费者[" + consumerId + "] 收到消息: " + message);
try {
consumerChannel.basicAck(envelope.getDeliveryTag(), false);
} catch (IOException e) {
e.printStackTrace();
}
}
};
// 每个消费者都需要订阅伪队列
consumerChannel.basicConsume("sharding_order_exchange", false, consumer);
System.out.println("消费者[" + consumerId + "] 已启动");
}
}
}3.3 分片队列命名规则
分片插件创建的物理队列命名格式:
sharding:{exchange_name}-{node_name}-{shard_index}
例如:
-
sharding:order_exchange-rabbit@node1-0 -
sharding:order_exchange-rabbit@node1-1 -
sharding:order_exchange-rabbit@node1-2
3.4 注意事项与限制
-
消息顺序性:分片后无法保证全局消息顺序
-
分片均匀性:基于routing key的hash分布,可能不均匀
-
单独消费:避免直接消费物理分片队列
-
性能影响:分片增加路由开销,小消息场景可能降低性能
适用场景评估:
public class ShardingDecision {
public static boolean shouldUseSharding(MessageStats stats) {
// 场景1:高吞吐需求
if (stats.getPublishRate() > 10000) { // 每秒万级以上
return true;
}
// 场景2:消费延迟严重
if (stats.getConsumerUtilization() < 0.3) { // 消费者利用率低于30%
return true;
}
// 场景3:消息堆积增长
if (stats.getQueueGrowthRate() > 1000) { // 队列每小时增长千条以上
return true;
}
// 场景4:可以接受消息无序
if (!stats.isOrderSensitive()) {
return true;
}
return false;
}
}四、生产环境最佳实践
4.1 队列选型建议矩阵
| 业务场景 | 推荐队列 | 配置建议 |
|---|---|---|
| 订单/支付核心业务 | Quorum队列 | 开启Publisher Confirms,设置delivery-limit |
| 日志/监控数据 | Stream队列 | 设置合理的max-age和segment-size |
| 内部服务调用 | Classic队列 | 适度持久化,监控队列长度 |
| 延迟任务 | Classic+DLX | 多级TTL队列,死信处理 |
| 广播通知 | Classic+Fanout | 配合镜像队列保证可用性 |
4.2 监控指标
@Component
public class RabbitMQMonitor {
@Scheduled(fixedDelay = 60000) // 每分钟监控一次
public void monitorQueueHealth() {
// 关键监控指标
monitorQueueLength(); // 队列长度
monitorConsumerCount(); // 消费者数量
monitorUnackedMessages(); // 未确认消息
monitorMessageAge(); // 消息年龄
monitorDeadLetters(); // 死信数量
}
private void alertIfNeeded(QueueStats stats) {
// 预警条件
if (stats.getLength() > 10000) {
sendAlert("队列堆积告警: " + stats.getQueueName());
}
if (stats.getAvgMessageAge() > 300000) { // 5分钟
sendAlert("消息处理延迟告警");
}
if (stats.getDeadLetterCount() > 100) {
sendAlert("死信数量异常");
}
}
}4.3 故障处理预案
# rabbitmq-emergency-plan.yml
emergency_scenarios:
- scenario: "队列消息大量堆积"
actions:
- "增加消费者实例"
- "临时启用Sharding分片"
- "调整消费者prefetch数量"
- "检查消费者处理逻辑"
- scenario: "消息丢失风险"
actions:
- "切换为Quorum队列"
- "开启Publisher Confirms"
- "检查磁盘空间和IO"
- "验证备份机制"
- scenario: "消费速度过慢"
actions:
- "分析消息处理瓶颈"
- "优化消费者代码"
- "考虑Stream队列批量消费"
- "评估硬件资源"五、总结
RabbitMQ的高级功能为企业级消息处理提供了强大的工具集:
-
队列类型三剑客:
-
Classic:功能全面,适合传统场景
-
Quorum:数据可靠,面向未来
-
Stream:海量数据,高性能处理
-
-
死信队列双刃剑:
-
异常消息处理的标准方案
-
实现延迟队列的实用技巧
-
业务补偿机制的重要组成部分
-
-
分片插件水平扩展:
-
突破单队列性能瓶颈
-
无感知的消费能力扩展
-
适合高吞吐无序场景
-
演进趋势:
-
Quorum队列逐渐成为默认选择
-
Stream队列在大数据场景优势明显
-
插件生态持续丰富(Sharding、Federation等)
实践建议:
-
新项目优先考虑Quorum队列
-
核心业务必须配置死信处理
-
性能瓶颈时评估分片方案
-
建立完整的监控预警体系