1. 执行摘要
随着大语言模型(LLM)技术的飞速演进,数据表征的方式发生了根本性变革。嵌入向量(Embedding Vectors)的维度已从早期的 384 维 (如 BERT)、1536 维 (如 OpenAI ada-002),迅速扩展至现代"龙头"模型的 3072 维 (OpenAI text-embedding-3-large)乃至 4096 维(Mistral、Llama 等开源模型)。这种维度的爆炸式增长,直接冲击了传统关系型数据库的底层存储架构。
许多尝试在 PostgreSQL 中集成 pgvector 扩展的数据工程师,在使用默认配置索引这些高维向量时,都会遇到著名的"2000 维限制"错误:
ERROR: column cannot have more than 2000 dimensions for hnsw index
这一限制并非软件层面的随意设定,而是深深植根于 PostgreSQL 核心存储引擎的物理页结构(8KB Page Size)之中。
本报告旨在为架构师和高级工程师提供一份详尽的技术指南,深入剖析这一限制的底层物理机制,并全面揭示行业领军企业(即"龙头公司")如何通过 标量量化(Scalar Quantization) 、二进制量化(Binary Quantization) 以及 俄罗斯套娃表征学习(Matryoshka Representation Learning, MRL) 等高级策略,在不修改数据库内核的前提下,高效处理 4096 维乃至更高维度的向量检索任务。
报告将通过严谨的架构分析、数学推导及实战代码演示,证明 PostgreSQL 结合现代量化技术,依然是处理高维向量最强大且最具成本效益的解决方案之一。
2. 核心限制剖析:为什么是 2000 维?
要理解为什么 pgvector 在默认情况下无法索引超过 2000 维的向量,我们必须穿透扩展层,直视 PostgreSQL 数据库最底层的存储单元------页面(Page)。这个限制是数据库为了保证 ACID(原子性、一致性、隔离性、持久性)特性和 I/O 效率而做出的物理妥协。
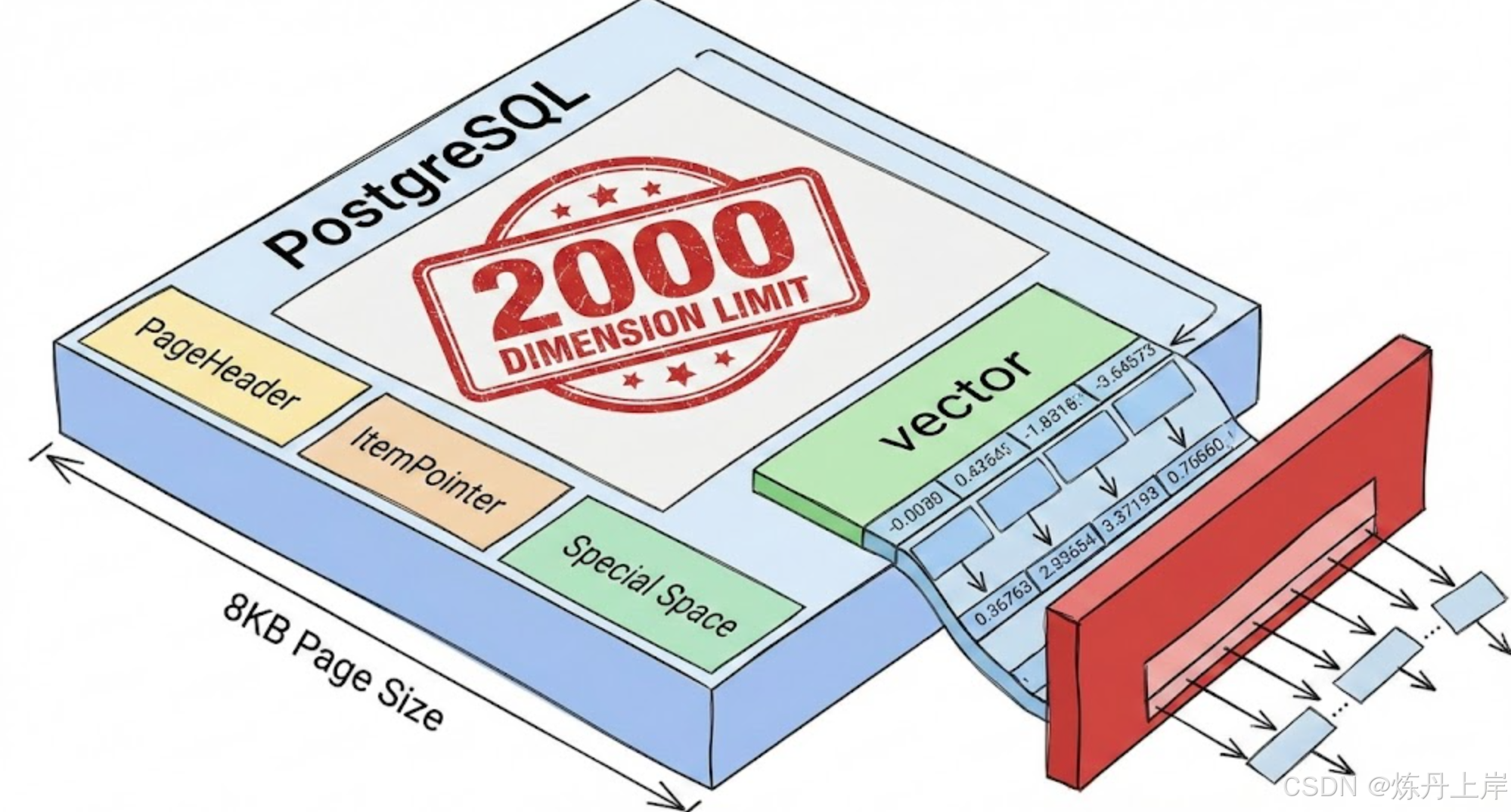
2.1 PostgreSQL 的 8KB 页面物理约束
PostgreSQL 将所有数据(表数据和索引数据)存储在固定大小的块中,这些块被称为"页面"(Page)。默认情况下,PostgreSQL 的页面大小在编译时被硬编码为 8KB (8192 Bytes)。这是一个极其关键的魔数,它决定了数据库中任何单一元组(Tuple)或索引条目的物理上限。
2.1.1 页面内部的"寸土寸金"
一个 8192 字节的页面并非全部可用于存储用户数据。它包含了一系列不可压缩的系统开销:
- 页面头(PageHeaderData): 占用约 24 字节,用于存储页面的 LSN(日志序列号)、校验和、标志位等元数据。
- 行指针(ItemPointer / Line Pointer): 每个存储在页面上的元组都需要一个对应的指针,占用 4 字节。
- 特殊空间(Special Space): 索引页面(如 HNSW 或 B-Tree)通常需要在页面末尾预留空间存储特定的索引元数据。
在除去这些固定开销后,留给存储实际数据的空间大约只有 8160 字节左右。
2.1.2 向量数据的物理体积计算
让我们从比特和字节的角度来计算一个向量的体积。标准的嵌入向量是由 单精度浮点数(Float32) 组成的数组。
- Float32 大小: 4 字节(32 bits)。
- pgvector 头部开销: 向量数据类型本身有一个极小的头部,用于记录维数等信息,约 4-8 字节。
当尝试存储一个 2000 维 的向量时:
加上 PostgreSQL 的元组头(Tuple Header,约 23 字节)和 pgvector 的头部,总大小约为:
这就已经非常接近 8192 字节的物理极限了。如果我们尝试存储 2048 维(这曾是许多模型的标准维度):
仅数据本身就已经填满了整个页面,没有任何空间留给页面头、行指针或元组头。这就是为什么 2000 维成为了一个硬性物理上限。实际上,PostgreSQL 需要保证一个页面至少能存下一条数据,一旦超过这个大小,机制就会发生变化。
2.2 TOAST 机制:存储与索引的决裂
这里存在一个常见的认知误区:用户经常发现他们可以成功地将 4096 维的向量 INSERT 到表中,但在创建索引时却报错。这是因为 存储(Storage) 和 索引(Indexing) 在处理大对象时采用了完全不同的策略。
- 表存储(Heap Storage)支持 TOAST:
当表中的一行数据超过页面大小时,PostgreSQL 会使用 TOAST (The Oversized-Attribute Storage Technique) 技术。它会自动将超长的大字段(如高维向量、长文本)压缩并切片,存储在离散的辅助表(TOAST 表)中,而在主表中只保留一个指向这些切片的指针。因此,vector 数据类型在不建立索引的情况下,理论上最高可支持 16,000 维。 - 索引存储(Index Storage)拒绝 TOAST:
HNSW(Hierarchical Navigable Small Worlds)和 IVFFlat 等向量索引算法依赖于极高频的距离计算。如果索引中的向量也被 TOAST 到辅助表中,那么每次计算距离(Distance Calculation)都需要先去辅助表读取数据、解压、重组,这将导致严重的随机 I/O,使得索引性能发生数量级的崩塌。
因此,PostgreSQL 的索引访问方法通常要求 索引条目必须完全驻留在索引页面内。由于索引条目不能被 TOAST,它们必须受限于 8KB 的物理限制。这就是为什么你可以存 4000 维的数据,却只能建 2000 维的索引。
结论: 2000 维的限制不是 pgvector 开发者的疏忽,而是 PostgreSQL 追求高性能索引查询时的物理必然。要突破这一限制,不能靠强行修改参数,而必须采用更高级的数据压缩策略。
3. 行业策略一:精度压缩革命(HalfVec 标量量化)
面对 3072 维(OpenAI text-embedding-3-large)或 4096 维(开源模型)的存储需求,业内的"龙头公司"最先采用的标准化解决方案是 标量量化(Scalar Quantization) ,具体落实为 pgvector 0.7.0 版本引入的 halfvec 数据类型。
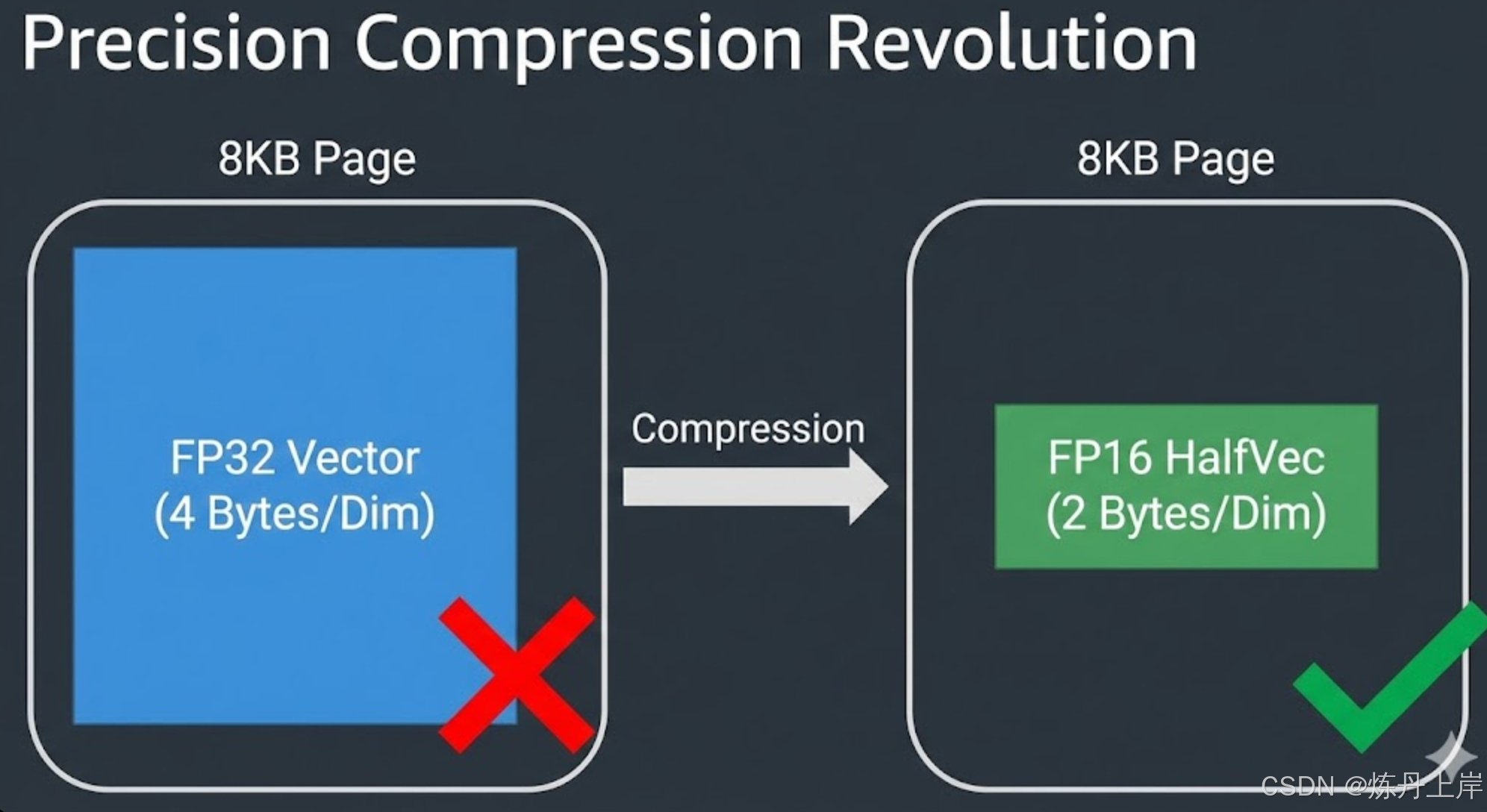
3.1 从 Float32 到 Float16
传统的 vector 类型使用 IEEE 754 单精度浮点数(FP32),每个维度占用 4 字节。而 halfvec 使用半精度浮点数(FP16),每个维度仅占用 2 字节。
3.1.1 物理空间的倍增
通过将每个维度的存储空间减半,我们直接将 8KB 页面能容纳的维度上限翻倍:
- vector (FP32):
- halfvec (FP16):
这一改变使得 PostgreSQL 能够直接索引 4000 维 的向量,完美覆盖了当前主流的高性能模型(如 3072 维的 OpenAI 模型),同时避开了复杂的 TOAST 机制。
3.2 精度与性能的权衡:为什么这是"免费的午餐"?
在许多工程领域,降低精度往往意味着妥协。但在向量搜索领域,从 FP32 降级到 FP16 几乎被视为一种"无损"优化,甚至带来了显著的性能提升。
- 信噪比理论: 深度学习模型生成的嵌入向量本质上是对语义空间的概率近似。其数值本身就包含大量的"噪声"。FP32 提供的 7-8 位有效小数精度,对于计算余弦相似度(Cosine Similarity)或欧几里得距离而言是过剩的。FP16 提供的 3-4 位精度已足以保持向量在空间中的相对排名(Ranking)不变。
- 内存带宽红利(Memory Bandwidth Bound): 向量搜索是一个典型的内存带宽受限型任务。CPU 计算距离的速度远快于从内存读取数据的速度。使用
halfvec意味着索引体积减半,同样的 RAM(PostgreSQL 的shared_buffers)可以缓存两倍数量的向量。这直接导致查询吞吐量(QPS)的显著提升,且大幅减少了磁盘 I/O。
3.3 行业实战:迁移至 HalfVec
对于正在使用 OpenAI text-embedding-3-large (3072 dims) 的企业,标准的实施路径如下:
sql
-- 1. 启用扩展
CREATE EXTENSION IF NOT EXISTS vector;
-- 2. 创建表结构:明确指定使用 halfvec 类型
-- 注意:这里定义了 3072 维,完全在 halfvec 的 4000 维限制内
CREATE TABLE enterprise_knowledge_base (
id bigserial PRIMARY KEY,
content text,
embedding halfvec(3072) -- 关键点:使用 halfvec
);
-- 3. 数据写入
-- 客户端(如 Python/Java)发送标准的 Float32 数组
-- PostgreSQL 会在写入时自动将其转换为 Float16
INSERT INTO enterprise_knowledge_base (content, embedding)
VALUES ('PostgreSQL 架构分析...', '[0.012, -0.003,...]');
-- 4. 创建 HNSW 索引
-- 关键点:必须使用对应的 halfvec 操作符类 (halfvec_l2_ops 或 halfvec_cosine_ops)
CREATE INDEX ON enterprise_knowledge_base
USING hnsw (embedding halfvec_cosine_ops)
WITH (m = 32, ef_construction = 128);业内经验: 绝大多数场景下,直接使用 halfvec 是处理 2000-4000 维向量的默认最佳实践。它不需要复杂的重排序逻辑,且能立即享受到 50% 的存储成本节约。
4. 行业策略二:超大规模的二进制量化(Binary Quantization)
当业务场景进一步扩展,遇到以下两种情况之一时,仅靠 halfvec 已不足以应对:
- 维度极高: 模型维度超过 4000(虽然罕见,但存在)。
- 数据量极大: 向量数量达到 1 亿(100M)甚至 10 亿(1B)级别。此时,即便是
halfvec索引也会消耗数百 GB 的内存,成本极高。
此时,行业龙头公司会采用更激进的 二进制量化(Binary Quantization, BQ) 策略。这种方法能将存储压缩 32 倍,支持高达 64,000 维 的索引。
4.1 极致压缩的数学原理
二进制量化的核心思想是将连续的浮点数空间坍缩为离散的比特空间。最简单的策略是基于符号的量化:
- 如果维度值 ,记录为
1。 - 如果维度值 ,记录为
0。
例如,一个 Float32 向量 [0.15, -0.23, 0.05, -0.88] 将被压缩为 4 个比特位 1010。
这种压缩看似丢失了幅值信息,但在高维空间中,向量的"方向"(即所在的象限)包含了绝大部分的语义信息。通过比较两个二进制向量的 汉明距离(Hamming Distance) (即不同比特位的数量),我们可以极快地估算出原始向量的相似度。现代 CPU 提供了硬件指令(如 POPCNT 和 XOR),能在纳秒级完成这种计算。
4.2 核心模式:重排序(Reranking / Oversampling)
由于二进制量化丢失了精度,直接使用它返回的结果可能包含较多误报(False Positives)。因此,业内采用一种标准的 "两阶段检索"(Filter-Refine) 架构:
- 阶段一(粗排): 利用极小的二进制索引(HNSW + Hamming),快速检索出 个候选者(例如,用户需要 Top 10,我们检索 Top 200)。
- 阶段二(精排/重排序): 回到主表(Heap),加载这 200 个候选者的原始全精度向量(或
halfvec),使用精确的距离公式(如 Cosine)进行计算并重新排序,最终返回 Top 10。
4.3 实战代码:构建亿级向量检索系统
在 pgvector 0.8.0+ 中,这一模式得到了原生支持。
表结构设计:
sql
CREATE TABLE massive_dataset (
id bigserial PRIMARY KEY,
-- 原始向量:存储在 Heap 中,用于重排序。使用 halfvec 节省空间。
-- 即使是 4096 维,halfvec 也只需要 8KB,刚好能由 TOAST 处理或勉强塞入
raw_embedding halfvec(4096),
-- 量化向量:用于构建索引。
-- bit(4096) 仅占用 4096 / 8 = 512 字节!远低于 8KB 限制。
binary_embedding bit(4096)
);
-- 自动量化触发器(可选,或在应用层处理)
CREATE OR REPLACE FUNCTION auto_quantize() RETURNS trigger AS $$
BEGIN
NEW.binary_embedding := binary_quantize(NEW.raw_embedding::vector);
RETURN NEW;
END;
$$ LANGUAGE plpgsql;
CREATE TRIGGER trg_quantize BEFORE INSERT ON massive_dataset
FOR EACH ROW EXECUTE FUNCTION auto_quantize();
-- 创建索引:基于二进制列,使用汉明距离
CREATE INDEX idx_binary ON massive_dataset
USING hnsw (binary_embedding bit_hamming_ops);高性能查询语句:
sql
WITH candidates AS (
-- 第一阶段:基于二进制索引的极速粗排
SELECT id, raw_embedding
FROM massive_dataset
-- 使用 <~> (汉明距离)
ORDER BY binary_embedding <~> binary_quantize($1::vector)
LIMIT 200 -- 过采样:获取比需求多 20 倍的候选者
)
-- 第二阶段:基于原始向量的精确重排
SELECT id
FROM candidates
-- 使用 <=> (余弦距离) 对 200 个结果进行精排
ORDER BY raw_embedding <=> $1::halfvec
LIMIT 10;这种架构的优势在于,索引体积只有原始向量的 1/32。对于 1 亿个 1536 维向量,全精度索引可能需要 600GB 内存,而二进制索引仅需约 20GB,完全可以放入一台普通服务器的内存中。
5. 行业策略三:俄罗斯套娃表征学习(Matryoshka Representation Learning)
除了在存储层做文章,OpenAI 等 AI 实验室在模型训练层也引入了创新,这就是 俄罗斯套娃(Matryoshka) 嵌入。这是一种从源头解决维度问题的策略。
5.1 弹性维度的魔法
传统的嵌入模型,如果直接截断后半部分维度,其语义能力会完全崩塌。但 Matryoshka 模型(如 text-embedding-3-large)在训练时被强制要求:向量的前 个维度必须也是一个有效的、高质量的嵌入。
这就好比俄罗斯套娃,最里面的小娃娃(前 256 维)是完整的,外面的中娃娃(前 1024 维)也是完整的。
OpenAI text-embedding-3-large (3072 维):
- 截断至 1024 维: 性能损失极小,可直接放入普通索引。
- 截断至 256 维: 性能优于上一代
ada-002,且索引极小。
5.2 PostgreSQL 中的自适应检索实现
利用 pgvector 的 subvector 函数,我们可以在数据库中实现这种弹性检索。
场景: 使用 3072 维模型,但为了性能只索引前 1536 维(避开 2000 维限制,且提升速度)。
sql
-- 创建函数索引:只索引前 1536 维
-- 注意:我们需要显式转换类型 ::vector(1536)
CREATE INDEX idx_matryoshka ON items
USING hnsw ( (subvector(embedding, 1, 1536)::vector(1536)) vector_cosine_ops );
-- 查询逻辑
SELECT id, content
FROM items
-- 查询时同样截断查询向量
ORDER BY subvector(embedding, 1, 1536)::vector(1536) <=> subvector($1, 1, 1536)::vector(1536)
LIMIT 10;这种方法的精髓在于灵活性。企业可以存储完整的 3072 维向量以备未来使用(或用于精排),但在高频索引路径上只使用 1024 或 1536 维,从而在 2000 维的物理限制内游刃有余。
6. 不同策略的对比与选择指南
下表总结了三种"龙头公司"处理高维向量的核心策略对比:
| 特性 | HalfVec (标量量化) | Binary Quantization (二进制量化) | Matryoshka (MRL 截断) |
|---|---|---|---|
| 最大支持维度 | 4,000 | 64,000 | 灵活 (取决于截断) |
| 存储压缩率 | 2x (50%) | 32x (96%+) | 灵活 (如 3x, 6x) |
| 精度/召回率 | 极高 (99%+) | 中 (需重排序来弥补) | 高 (模型原生支持) |
| 实现复杂度 | 低 (开箱即用) | 高 (需两阶段查询写法) | 中 (需模型支持) |
| 适用场景 | 大多数通用场景 |
Llama 3, OpenAI v3 (3072) | 亿级数据规模
或维度 > 4000 的极端场景
成本敏感型 | 需在同一模型下平衡速度与质量 |
决策树:
- 维度 < 2000? 直接使用标准
vector。 - 维度在 2000 - 4000 之间? **首选
halfvec**。这是目前最成熟、兼容性最好的方案。 - 维度 > 4000 或 数据量 > 5000 万? 考虑 二进制量化 + 重排序。
- 使用 OpenAI v3 模型且预算有限? 使用 Matryoshka 截断 (如截断到 1536 维)并结合
halfvec。
7. 运维实战:高维向量数据库的调优
在实施上述方案时,仅仅写对 SQL 是不够的。高维向量索引对数据库资源的消耗是巨大的,必须进行针对性的参数调优。
7.1 HNSW 内存陷阱
HNSW 索引构建是一个基于图的算法,需要将图结构加载到内存中。对于高维向量,如果内存不足,性能会断崖式下跌。
- 警告信号: 如果在创建索引时看到
NOTICE: hnsw graph no longer fits into maintenance_work_mem,这意味着构建过程转为了磁盘交换模式,速度可能慢 10 倍以上。 - 内存计算公式:
对于 100 万行 3072 维的 halfvec 数据,m=16:
-
VectorBytes = 6 KB
-
Graph Links = 16 * 4 = 64 bytes
-
Total per row ≈ 6.1 KB
-
Total RAM ≈ 6.1 GB
-
调优建议: 在创建索引的 Session 中,临时调大内存限制:
sql
-- 仅对当前会话生效,确保索引全内存构建
SET maintenance_work_mem = '8GB';
CREATE INDEX...;7.2 并行构建与 CPU 利用
pgvector 支持并行构建索引。对于高维数据,计算距离的 CPU 开销巨大。务必调整以下参数以跑满 CPU 核心:
sql
-- 允许索引创建使用更多核心
SET max_parallel_maintenance_workers = 16; -- 视物理核数而定
SET max_parallel_workers = 16;实测表明,在 3072 维数据上,并行度从 1 增加到 16,索引构建时间可缩短近 10-15 倍。
7.3 预热(Pre-warming)
向量索引不仅构建慢,冷启动也慢。数据库重启后,首次查询可能会因为磁盘 I/O 而非常慢。建议使用 pg_prewarm 扩展,或者在启动后运行一次全表 COUNT(*) 扫描,强制将索引页加载到 shared_buffers 中。
8. 结论
2000维最大限制,是 PostgreSQL 物理存储架构的直接体现,但这绝不意味着 PostgreSQL 不适合处理高维向量。相反,通过引入 HalfVec 和 二进制量化 等技术,PostgreSQL 已经进化为一个能够处理工业级、高维度、大规模向量负载的数据库平台。
对于使用 4000 维以上模型的"龙头公司"而言,他们并不是通过魔改 PostgreSQL 源码来突破限制,而是通过 数据类型降维(FP16/Binary)与检索流程重构(Reranking) 来绕过限制。