摘要
随着大语言模型(LLM)与检索增强生成(RAG)技术的普及,企业数据架构面临前所未有的挑战。尽管 PostgreSQL 通过 pgvector 等插件提供了向量存储能力,但在处理亿级规模数据、高并发检索以及复杂元数据管理的生产环境中,单一的"All-in-Postgres"架构往往暴露出性能瓶颈与运维风险。
本文深入剖析了大型科技公司(Big Tech)普遍采用的多层持久化架构(Polyglot Persistence),详细论证了以下技术栈在现代 AI 系统中的精确分工:
- 关系型数据库(PostgreSQL/MySQL)
- 向量数据库(Milvus/OpenSearch)
- 内存数据存储(Redis)
- 对象存储(S3)
报告通过对 B+ 树与 HNSW 图结构的算法差异、ACID 事务与 BASE 理论的冲突、MVCC 机制对向量索引的影响、以及纠删码(Erasure Coding)与多路复用(I/O Multiplexing)等底层原理的深度解构,揭示了这种分层架构背后的数学必然性与工程合理性。
1. 引言:从单体数据库到分层架构的演进
在生成式 AI 应用的早期原型阶段,开发者往往倾向于使用单一的数据库系统来简化开发流程。PostgreSQL 凭借其强大的扩展性和 pgvector 插件,成为了许多初创项目的首选,承载了从用户认证、会话记录到向量检索的所有功能。然而,当系统规模扩展至"大厂"级别------即拥有数千万至数十亿向量数据、每秒数万次查询(QPS)以及毫秒级延迟要求的场景时,单体架构的物理局限性开始显现 。
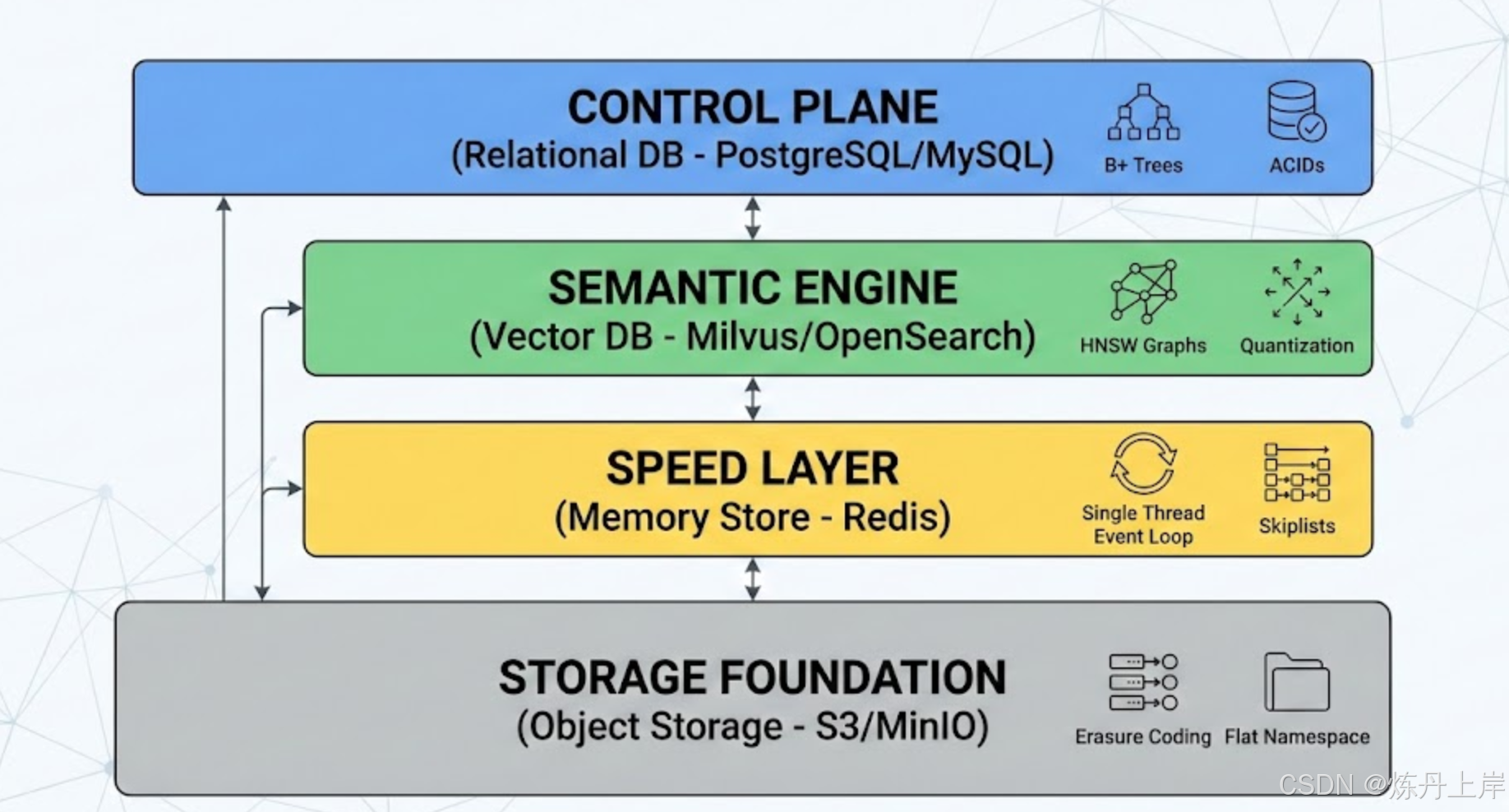
Uber、DoorDash 和 Airbnb 等科技巨头的工程实践表明,没有任何一种单一的数据结构能够同时优化强一致性的事务处理、高维度的近似最近邻搜索、极低延迟的会话状态读写以及海量非结构化数据的低成本存储 。这种内在的优化目标冲突迫使架构师将数据层解耦为四个核心组件:
- 控制平面(关系型数据库): 负责业务元数据、权限控制与核心事务状态,基于 B+ 树与 ACID 理论。
- 语义引擎(向量数据库): 负责海量向量的索引与召回,基于 HNSW 图算法与量化压缩技术。
- 极速层(内存存储): 负责语义缓存、会话管理与限流,基于单线程事件循环与跳表结构。
- 持久化基座(对象存储): 负责原始文档与索引切片的低成本存储,基于纠删码与扁平命名空间。
本报告将逐一剖析这四个层级的技术选型逻辑及其底层原理。
2. 关系型数据库(PostgreSQL/MySQL):业务元数据与状态的"真理之源"
在分层架构中,关系型数据库(RDBMS)的角色被严格限制在"控制平面"。它不再承担繁重的向量计算任务,而是专注于其最擅长的领域:结构化数据的强一致性管理与复杂关系处理。
2.1 核心职责:元数据、权限与事务状态
RDBMS 是系统的"真理之源"(Source of Truth)。在 RAG 系统中,虽然向量数据库存储了文档的语义表示,但关于文档的"业务属性"必须存储在 RDBMS 中:
- 权限控制(ACLs): 企业级 RAG 系统必须遵循严格的数据访问策略(例如,只有法律部员工能检索法律文档)。RDBMS 通过外键约束和复杂的多表关联(JOIN),能够精确定义和执行这些逻辑 。
- 事务完整性: 用户的订阅状态扣费、文档上传的元数据注册等操作,要求具备原子性(Atomicity)。如果向量写入成功但元数据记录失败,会导致"幽灵数据";反之则导致数据丢失。只有支持 ACID 的数据库能保证这种一致性 。
2.2 底层原理:B+ 树与确定性检索的数学基础
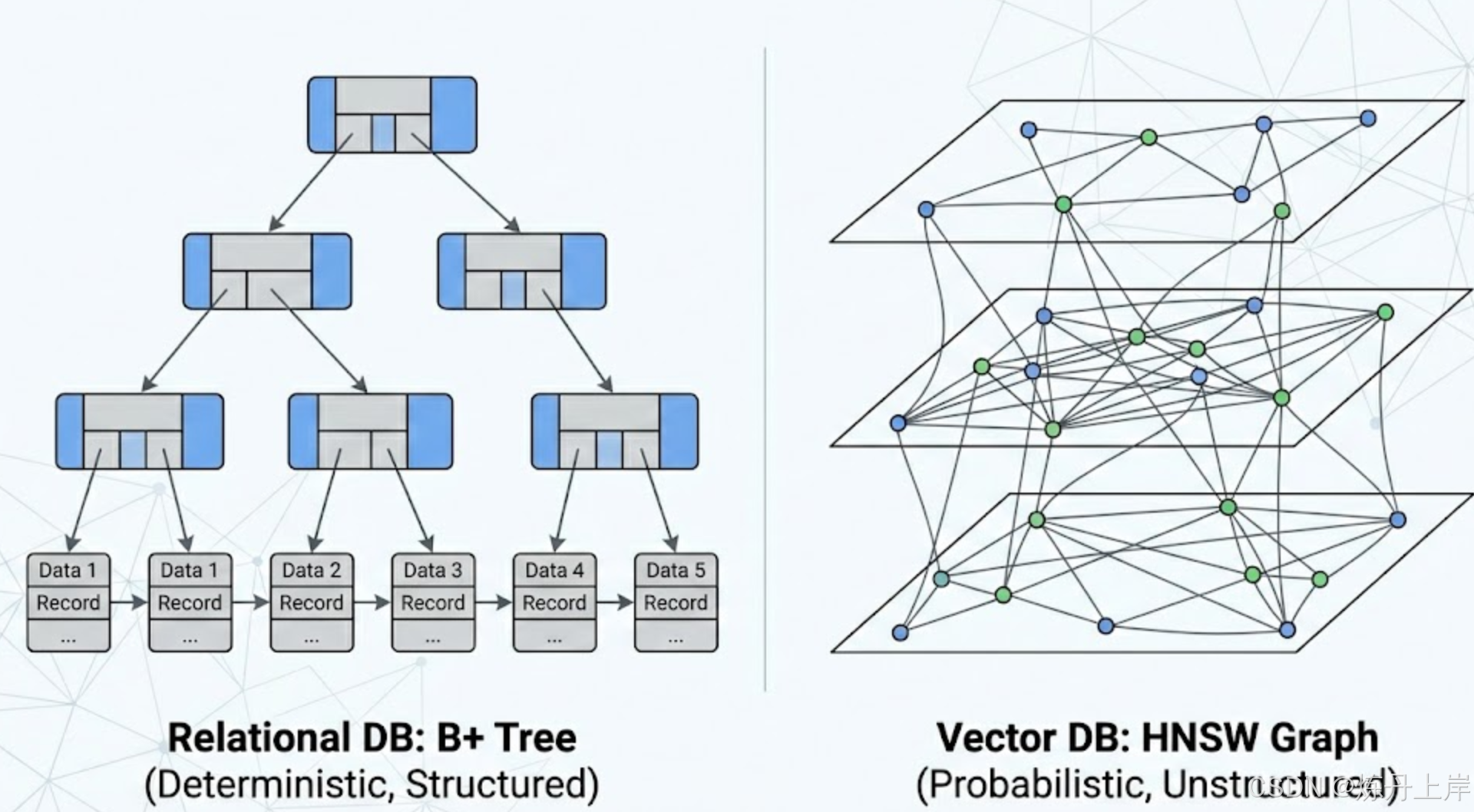
RDBMS 之所以难以被向量数据库取代,根本原因在于其核心数据结构------B+ 树(B+ Tree),它是为确定性、范围性检索而生的,与向量检索的概率性本质截然不同。
2.2.1 B+ 树的磁盘友好的设计
PostgreSQL 和 MySQL(InnoDB 引擎)均采用 B+ 树作为索引结构。
- 结构特性: B+ 树是一种多路平衡查找树。与二叉树不同,B+ 树的每个节点可以拥有大量的子节点(即高扇出,Fanout)。例如,一个 16KB 的数据页(Page)可以存储数百个指针。这意味着即使是存储亿级数据,树的高度通常也只有 3 到 4 层 。
- I/O 优化: 在数据库查询中,磁盘 I/O 是最大的性能瓶颈。B+ 树的矮胖结构保证了定位任意一条记录最多只需要 3-4 次随机磁盘读取。这对于根据 ID 快速查找用户配置或权限至关重要 。
- 范围查询优势: B+ 树的所有叶子节点通过双向链表相连。当执行
SELECT * FROM logs WHERE time BETWEEN t1 AND t2时,数据库只需找到 t1 所在的位置,然后沿着链表顺序扫描直到 t2。这种顺序 I/O 的速度远快于随机 I/O。相比之下,向量索引(如 HNSW)是基于图的,节点在内存中随机分布,无法高效处理此类范围扫描 。
2.2.2 ACID 与 MVCC 的实现机制
数据的一致性依赖于多版本并发控制(MVCC)。这是 PostgreSQL 处理高并发读写的核心机制,也是它与大多数向量数据库(通常采用最终一致性)的本质区别。
- 版本链与可见性: 在 PostgreSQL 中,每行数据都有
xmin(创建该行的事务 ID)和xmax(删除该行的事务 ID)两个隐藏字段。当执行 UPDATE 操作时,PostgreSQL 并不是直接修改原数据,而是插入一行新数据(新版本),并将旧行的xmax标记为当前事务 ID。 - 快照隔离(Snapshot Isolation): 事务启动时会获取一个数据库快照。MVCC 规则决定了事务能看到哪些版本的数据:只有那些
xmin小于当前事务 ID 且xmax未被提交或大于当前事务 ID 的行才是可见的 。 - 工程意义: 这种机制保证了"读不阻塞写,写不阻塞读"。在 RAG 系统的高并发场景下,即使用户正在更新文档的元数据,检索线程也能读取到一致的旧版本,而不会发生脏读。这是向量数据库往往无法提供的强一致性保证 。
2.3 为什么不 All-in Postgres?------深层原理剖析
尽管 pgvector 允许在 Postgres 中存储向量,但在大规模生产环境中,它面临着"真空(Vacuum)膨胀"与"资源争抢"两大死结。
2.3.1 HNSW 索引与 MVCC 的冲突
HNSW(分层可导航小世界图)是目前最高效的向量索引算法。然而,将 HNSW 嵌入到 MVCC 机制的 Postgres 中会产生严重的"写放大"问题 。
- 图结构的脆弱性: HNSW 依赖于节点之间精密的连接关系(邻居列表)来实现快速导航。在 Postgres 中,当一行数据被 UPDATE 时,实际上是"软删除"旧行并插入新行。这对于 B+ 树来说只是修改叶子节点,但对于 HNSW 图来说,意味着节点在图中的物理地址发生了变化。
- Vacuum 代价: PostgreSQL 必须通过 VACUUM 进程来清理死元组(Dead Tuples)。在 HNSW 索引中,删除一个节点不仅是释放空间,还需要"重连"该节点的所有邻居,以保持图的连通性。如果系统中存在大量更新或删除操作(例如频繁更新文档),HNSW 索引会迅速膨胀,且 VACUUM 过程会消耗巨大的 CPU 和 I/O 资源,导致索引性能急剧下降 。
- 查询规划器的盲区: Postgres 的查询规划器(Query Planner)是为标量数据设计的。它难以准确评估向量搜索的成本,经常在"先过滤后搜索"(Pre-filtering)和"先搜索后过滤"(Post-filtering)之间做出次优选择,导致查询效率低下 。
2.3.2 缓冲池(Buffer Pool)争抢
PostgreSQL 使用共享内存区域(Shared Buffers)来缓存热点数据页。
- 访问模式冲突: 向量搜索通常需要扫描大量的索引页(尤其是在 IVF 索引中),这是一种"内存密集型"操作。而事务处理通常只需要访问少量的 B+ 树页面。
- 驱逐效应: 当执行一个大规模向量查询时,大量向量索引页被加载到 Buffer Pool 中,可能会将原本用于核心业务(如用户登录、权限校验)的热点元数据页"挤出"缓存。这种"嘈杂邻居"(Noisy Neighbor)效应会导致核心业务的延迟抖动,这是企业级架构无法容忍的 。
3. 向量数据库(Milvus/OpenSearch):语义检索的专用引擎
向量数据库在架构中专门负责"模糊"的计算------即在海量的高维空间中寻找"最相似"而非"精确匹配"的数据。这种根本性的目标差异决定了其底层数据结构和架构设计与 RDBMS 完全不同。
3.1 核心职责:高维向量的近似最近邻搜索(ANN)
向量数据库的核心任务是存储 Embedding(嵌入向量)并提供毫秒级的近似最近邻(ANN)检索。
- 规模挑战: 在 Uber 或 DoorDash 这样的场景下,向量数量可达十亿级 。
- 计算挑战: 计算两个向量的相似度(如余弦相似度)需要大量的浮点数乘加运算。在十亿级数据上进行暴力搜索是不可行的,必须依赖近似算法 。
3.2 底层原理:图算法、量化与存算分离
3.2.1 HNSW:小世界导航图的数学机制
HNSW 是目前最先进的内存向量索引算法,其设计灵感来源于"六度分隔理论"。
- 跳表结构(Skip List): HNSW 构建了一个多层的图结构。顶层图非常稀疏,节点之间连接跨度大,用于快速"跳跃"到目标区域;底层图非常稠密,用于精确查找 。
- 贪婪搜索(Greedy Search): 查询从顶层的一个入口点开始,每次都向与查询向量距离最近的邻居移动。当在当前层无法找到更近的节点时,就下降到下一层继续搜索。这种机制将搜索复杂度从 降低到了 。
- 内存驻留: 为了保证图遍历的性能,HNSW 的节点关系(邻接表)通常必须完全驻留在内存中。这是向量数据库通常是"内存饥渴型"系统的主要原因 。
3.2.2 量化技术(Quantization):精度与空间的博弈
为了在有限的内存中存储十亿级向量,向量数据库广泛使用量化技术,这是 Postgres 通常缺乏深度优化的领域。
-
乘积量化(Product Quantization, PQ):
-
原理: 将一个高维向量(如 128 维)切分为 个子向量(如 8 个,每个 16 维)。
-
聚类: 对每个子空间进行 K-Means 聚类,生成 256 个质心(Codebook)。
-
压缩: 原向量的每个子向量只需存储其最近质心的 ID(1 字节)。这样,一个 128 维的 float32 向量(512 字节)就被压缩成了 8 字节,压缩比高达 64 倍 。
-
距离计算: 查询时,先计算查询向量与所有质心的距离表(Look-up Table),然后通过查表求和即可得到近似距离,极大地利用了 CPU 缓存并减少了指令数 。
-
标量量化(Scalar Quantization, SQ): Uber 的实践表明,将 float32 转换为 int8(单字节整数)可以节省 75% 的内存,同时通过 SIMD 指令集(如 AVX-512)加速计算,且召回率损失极小 。
3.2.3 存算分离与日志即数据(Log as Data)
与 Postgres 的单体架构不同,Milvus 等现代向量数据库采用了云原生的存算分离架构 。
-
组件解耦:
-
Query Nodes: 无状态的计算节点,负责在内存中加载索引段并执行搜索。可以根据 QPS 需求弹性扩容。
-
Index Nodes: 专门负责构建索引(这是一个 CPU 密集型任务)。将索引构建与查询服务物理隔离,避免了 Postgres 中"建索引卡死查询"的问题 。
-
Data Nodes: 负责数据摄入。
-
日志骨干(Log Broker): Milvus 使用 Pulsar 或 Kafka 作为系统的"骨干"。所有的数据插入和更新操作首先被写入消息队列(Log)。这保证了极高的写入吞吐量和原子性。
-
LSM 风格的持久化: 数据从 Log 流向 Data Nodes,在内存中积累后被转换成不可变的段(Segment),然后刷新到对象存储(S3)中。这种 Write-Once 的模式避免了原地更新带来的锁竞争和碎片问题,非常适合向量数据的特性 。
4. 内存数据存储(Redis):极速层的原子性与并发模型
在分层架构中,Redis 并不是简单的"缓存",而是承载了所有对延迟极其敏感(Sub-millisecond)的临时状态管理任务。
4.1 核心职责:限流、会话与语义缓存
- 分布式限流(Rate Limiting): 保护后端 LLM 和向量数据库免受恶意攻击或突发流量冲击。例如,限制每个用户每分钟只能发送 50 条消息。
- 会话状态(Session State): LLM 是无状态的,但用户对话是有状态的。Redis 存储了最近 N 轮的对话历史(Context Window),需要在每次请求时极快地读取并拼接进 Prompt 。
- 语义缓存(Semantic Caching): 将用户的自然语言查询向量化后作为 Key,将 LLM 的响应作为 Value。当新查询的向量与缓存 Key 的相似度高于阈值时,直接返回缓存结果,从而节省昂贵的 GPU 推理成本 。
4.2 底层原理:I/O 多路复用与单线程模型
Redis 之所以能作为"极速层",其核心在于完全不同于 RDBMS 的线程模型和内存数据结构。
4.2.1 Reactor 模式与 I/O 多路复用
传统数据库(如旧版 MySQL)通常采用"一连接一线程"模型,当并发连接数达到数万时,线程上下文切换(Context Switch)的开销会耗尽 CPU。
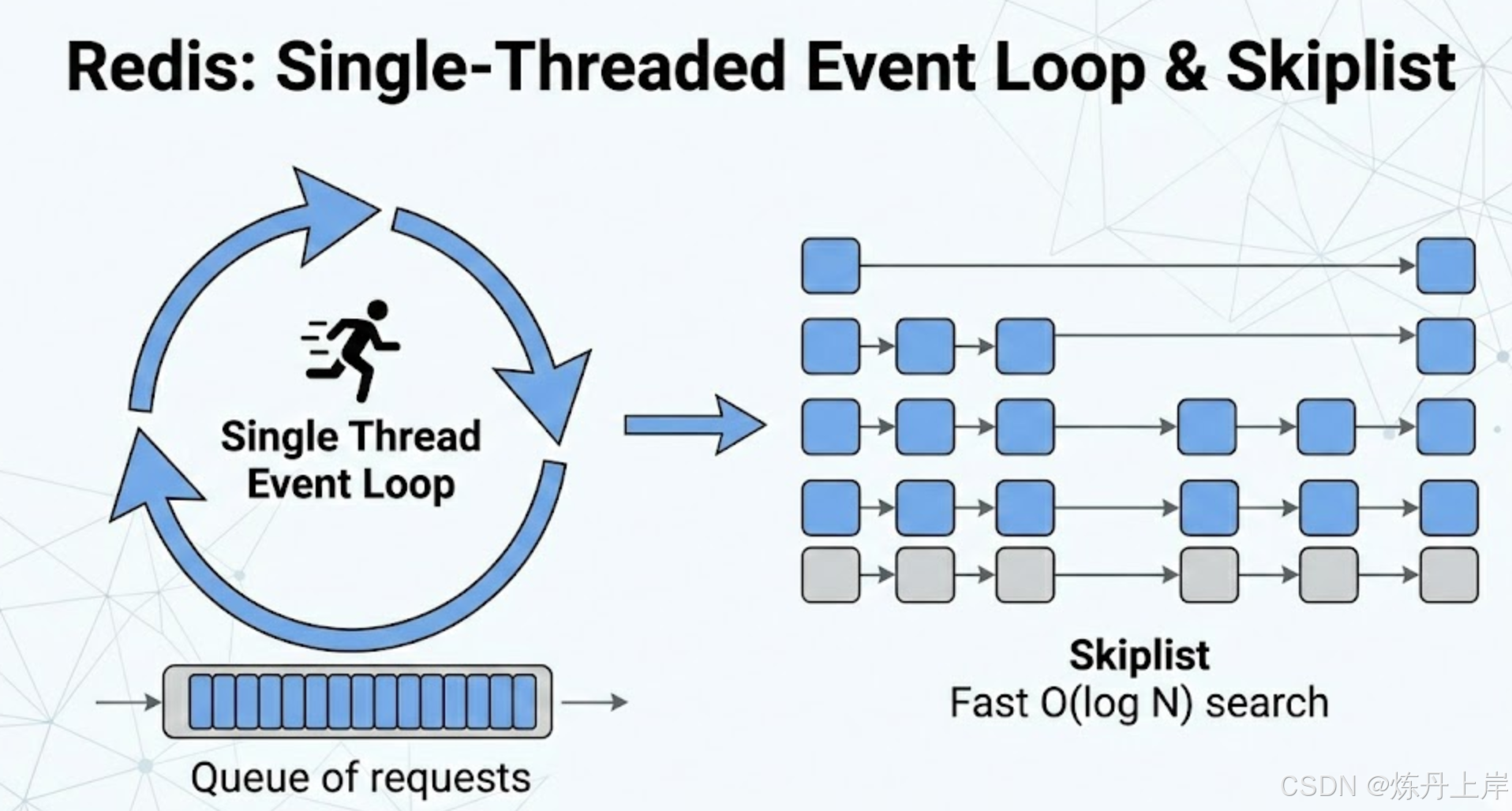
- 单线程事件循环: Redis(主要处理逻辑)运行在单线程中。它利用操作系统的 I/O 多路复用机制(Linux 上的 epoll,macOS 上的 kqueue)。
- ae.c 与 epoll: Redis 的
ae.c模块封装了事件驱动逻辑。
- Redis 调用
epoll_create创建一个监听实例。 - 所有客户端的 Socket 文件描述符(FD)都被注册到这个实例中。
- 主循环调用
epoll_wait,该系统调用会阻塞,直到至少有一个 Socket 变为可读或可写状态。操作系统内核利用红黑树高效管理这些 FD。 - 一旦有就绪事件,Redis 线程被唤醒,串行处理这些请求。由于内存操作极快(纳秒级),这种串行处理避免了锁竞争和线程切换,从而实现了每秒数十万次的操作吞吐量 。
4.2.2 ZSet 与跳表(Skiplist):滑动窗口限流的基石
Redis 的有序集合(Sorted Set / ZSet)是实现精准滑动窗口限流的关键。
- 跳表结构: ZSet 内部由一个哈希表(用于 查找成员)和一个跳表(用于 排序)组成。跳表是一种概率平衡的数据结构,通过多层索引指针链接节点,实现了类似二分查找的效率,但比平衡树更容易实现并发(虽然 Redis 是单线程)和内存紧凑 。
- 原子性与 Lua: 实现滑动窗口限流时,通常需要执行
ZADD(添加当前时间戳)、ZREMRANGEBYSCORE(移除窗口外的时间戳)和ZCARD(统计当前请求数)。通过将这些命令封装在一个 Lua 脚本中,Redis 保证了整个脚本执行的原子性------即在脚本执行期间,不会有任何其他命令插入。这彻底解决了高并发下的计数器竞态条件问题,而无需引入复杂的分布式锁 。
4.2.3 Hash 对象 vs. JSON 字符串
在存储会话元数据时,大厂倾向于使用 Redis Hash 而非 String 存储 JSON。
- ZipList/ListPack 优化: 对于小型的 Hash 对象,Redis 底层使用压缩列表(ZipList)或紧凑列表(ListPack)存储。这是一块连续的内存区域,不仅节省了指针开销,还利用了 CPU 的 L1/L2 缓存行(Cache Line),使得读取效率远高于分散的堆内存分配 。
- 部分更新: 使用 Hash 可以通过
HSET仅更新会话中的某个字段(如last_active_time),而无需像 String 那样读取整个 JSON、反序列化、修改、序列化再写回。这大大减少了网络带宽和 CPU 消耗 。
5. 对象存储(S3/MinIO):海量数据的低成本基座
在金字塔的底部,对象存储(Object Storage)承载了系统中体积最大、但访问频率相对较低的数据。
5.1 核心职责:非结构化数据与索引持久化
- 原始文档: RAG 系统摄入的 PDF、Word、图片等原始文件。
- 切片(Chunks): 经过清洗和切分后的文本块,通常以 JSON 或 Parquet 格式存储。
- 索引快照: 向量数据库(如 Milvus)会将内存中的索引定期刷写到磁盘,最终持久化到 S3。这使得计算节点可以是无状态的,因为它们随时可以从 S3 重新加载索引 。
5.2 底层原理:纠删码与扁平命名空间
对象存储之所以能做到比数据库磁盘便宜且耐用,依赖于其放弃了 POSIX 文件系统的语义,转而采用更适合分布式的设计。
5.2.1 纠删码(Erasure Coding, EC) vs. 副本复制
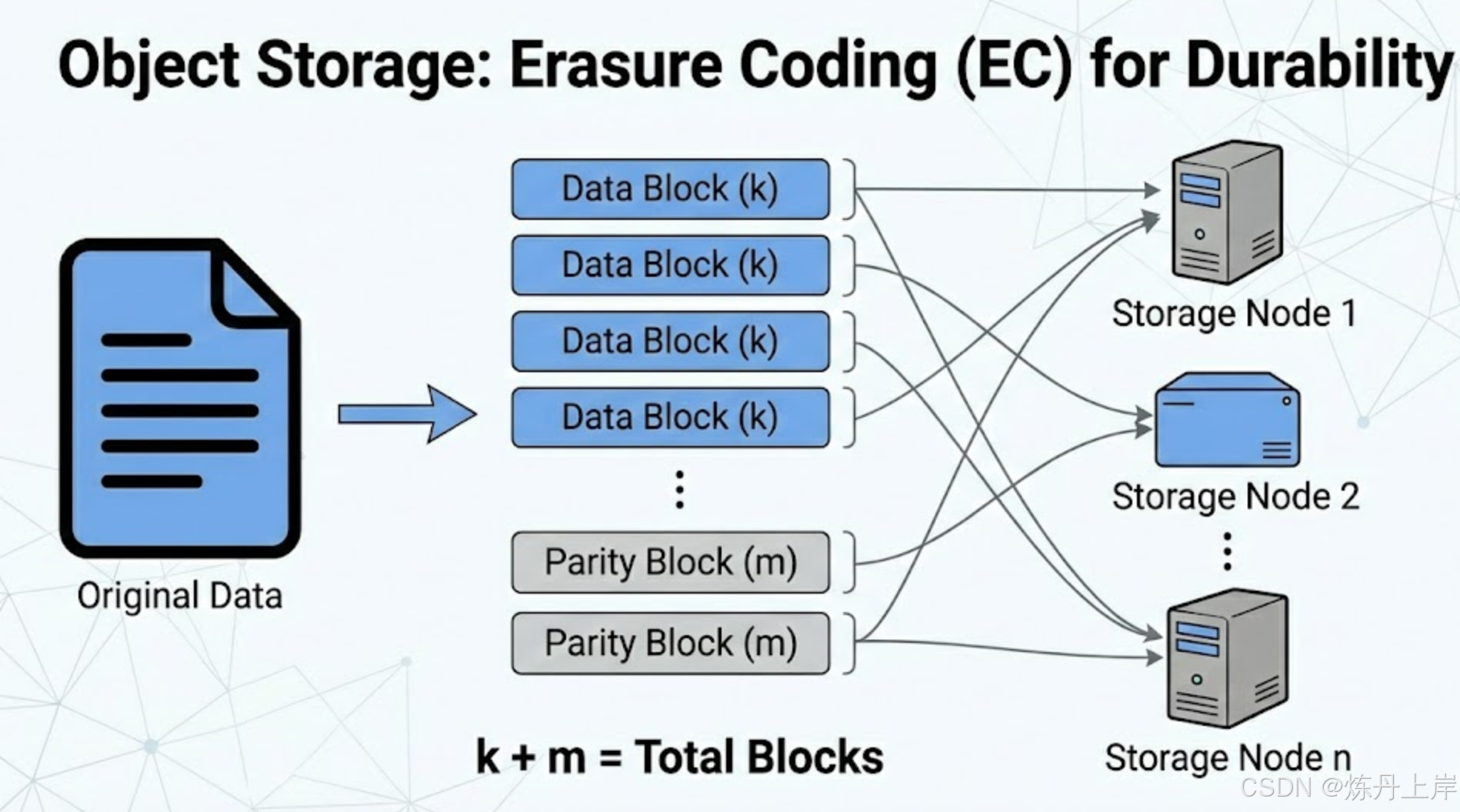
传统数据库为了可靠性通常采用 3 副本策略(Replication),即 1TB 数据占用 3TB 空间,存储利用率仅 33%。
- 数学原理: 对象存储采用纠删码(如 Reed-Solomon 算法)。它将数据切分为 个数据块,并通过矩阵运算生成 个校验块(Parity Blocks)。
- 容错能力: 只要在 个块中,任意 个块存活,就能通过线性方程组还原出原始数据 。
- 成本优势: 例如采用 10+4 配置,总共占用 1.4 倍空间,却能容忍任意 4 块磁盘同时损坏。这使得 S3 的存储成本仅为高性能 SSD 的几分之一,非常适合存储海量的 AI 训练数据和历史文档 。
5.2.2 扁平命名空间与哈希环
文件系统(Filesystem)是层级结构的(目录树),在处理数亿文件时,元数据操作(如 ls 目录)会因为锁竞争而成为瓶颈。
- 扁平结构: 对象存储没有真正的"目录",只有 Bucket 和 Key。Key
folder/file.txt只是一个字符串。 - 一致性哈希: 系统通过对 Key 进行哈希运算,将数据均匀分布在成千上万台服务器上。这种设计使得 S3 能够近乎无限地水平扩展,支持每秒数万次的并发吞吐,满足 AI 训练和 RAG 批量处理的高吞吐需求 。
6. 总结:分层架构的必然性
综上所述,大厂放弃"All-in-Postgres"而选择分层架构,并非单纯为了技术堆砌,而是基于数据物理特性和计算模式的必然选择:
| 层级 | 核心组件 | 优化目标 (Optimization Goal) | 关键数据结构/算法 | 架构必然性 (Architectural Necessity) |
|---|---|---|---|---|
| 控制平面 | PG/MySQL | 强一致性 (ACID) | B+ 树, MVCC, WAL | 只有 B+ 树能高效处理结构化元数据的范围查询与事务更新,保证业务逻辑的正确性。 |
| 语义引擎 | Milvus/ES | 高召回率 (Recall) | HNSW, 量化 (PQ), 倒排索引 | 只有图索引与量化技术能在有限内存中实现亿级向量的毫秒级检索,这是 B+ 树无法做到的。 |
| 极速层 | Redis | 低延迟 (Latency) | 跳表 (Skiplist), I/O 多路复用 | 只有单线程事件循环能消除上下文切换,实现亚毫秒级的会话读写与原子限流。 |
| 存储基座 | S3/MinIO | 低成本 & 耐用性 | 纠删码 (EC), 扁平哈希环 | 只有纠删码能以最低成本存储海量非结构化数据,并将计算与存储解耦,支持弹性伸缩。 |
这种"各司其职"的 Polyglot Persistence(多语言持久化) 架构,通过将不同形态的数据路由到最适合其数学特性的存储引擎中,解决了单体架构在扩展性、性能隔离和成本控制上的根本性矛盾,是构建企业级、高可用 AI 系统的基石。