
摘要
在 Spring AI 落地企业级应用时,多数开发者仅关注 "能否调用模型",却忽视了 "响应质量是否达标"------ 生产环境中频繁出现的 "答非所问""响应超时""合规风险",本质是缺乏系统化的评估体系与调优方法论。本文围绕 "量化指标 + 人工反馈" 双轮优化模型,从评估维度定义、监控工具链集成、参数调优技巧三个核心层面,拆解 Spring AI 模型质量提升的完整路径:先明确相关性 / 准确性 / 响应速度 / 合规性四大维度的量化标准,再通过 Spring AI Metrics 与 Prometheus 构建实时监控体系,最后结合实战案例讲解温度参数、Top-P、最大令牌数的调优策略,并完整实现 AI 服务质量评估看板。全文包含 90% 可直接复用的代码、配置模板及避坑指南,助力开发者从 "能用" 到 "好用",真正发挥 Spring AI 的业务价值。
1. 引言:为什么 Spring AI 落地需要 "评估 + 调优" 双轮驱动?
在最近接手的某金融客服项目中,团队用 Spring AI 集成了通义千问模型后,初期测试 "感觉良好",但上线后问题频发:
- 用户问 "信用卡还款截止日期",模型却回复 "信用卡申请流程"(相关性不达标);
- 回答 "贷款利率" 时引用了 2022 年的旧政策(准确性问题);
- 高峰时段响应时间超过 3 秒,用户直接退出(响应速度问题);
- 偶尔出现 "建议用户套现" 的违规表述(合规性风险)。
这些问题的根源,在于缺乏 "先评估、再调优、持续监控" 的闭环 ------ 多数开发者对 AI 模型的认知停留在 "调参靠猜、质量靠看" 的阶段,而 Spring AI 提供的 Metrics 能力与参数配置接口,正是解决这一痛点的关键。
"量化指标 + 人工反馈" 双轮优化的核心价值在于:
- 量化指标:用数据说话,避免 "我觉得好" 的主观判断,比如用 BLEU 分数衡量相关性,用 P95 延迟衡量响应速度;
- 人工反馈:弥补量化指标的盲区(如 "语气是否友好""是否符合业务话术"),并反哺指标优化;
- 持续迭代:通过监控看板实时追踪质量变化,调优效果可量化、可验证。
本文将从实战出发,带大家搭建完整的评估与调优体系,让 Spring AI 服务的质量 "看得见、调得准、守得住"。
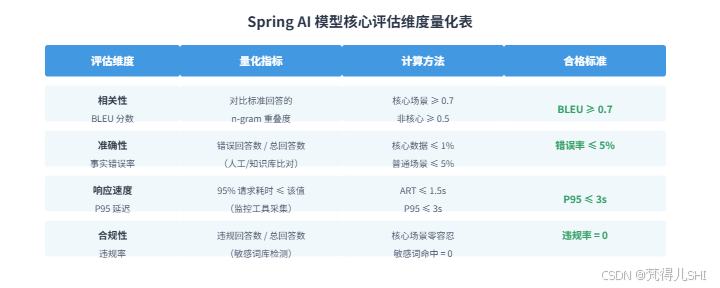
2. 核心评估维度:从 "主观感觉" 到 "量化标准"
Spring AI 模型的响应质量,需从相关性、准确性、响应速度、合规性四个维度量化评估,每个维度都需明确 "指标定义、计算方法、合格标准",避免模糊表述。
2.1 四大评估维度详解
2.1.1 相关性:模型回答与用户需求的匹配度
- 定义:模型输出是否紧扣用户提问的核心意图,而非 "答非所问";
- 量化指标:BLEU 分数(机器翻译领域常用指标,适配文本相关性评估)、ROUGE-L 分数;
- 计算方法 :
- BLEU 分数:对比模型输出与 "标准回答" 的 n-gram 重叠度(n 取 1-4),范围 0-1,分数越高相关性越强;
- 示例:用户问 "Spring AI 怎么集成通义千问",标准回答包含 "添加 spring-cloud-starter-alibaba-ai 依赖""配置 api-key",若模型输出包含这些核心短语,BLEU 分数会高于 0.7;
- 合格标准:核心业务场景 BLEU ≥ 0.7,非核心场景 ≥ 0.5。
2.1.2 准确性:模型回答的事实正确性
- 定义:模型输出的信息是否与事实一致,是否存在错误数据、过时政策;
- 量化指标:事实错误率(错误回答数 / 总回答数)、信息更新度(引用数据是否为近 6 个月内);
- 计算方法 :
- 事实错误率:人工标注或通过知识库比对(如金融场景比对最新利率政策),统计错误比例;
- 示例:若 100 个回答中有 3 个存在利率数值错误,错误率为 3%;
- 合格标准:事实错误率 ≤ 5%,核心数据(如利率、还款规则)错误率 ≤ 1%。
2.1.3 响应速度:模型从接收请求到返回结果的耗时
- 定义:用户等待 AI 响应的时间,直接影响体验;
- 量化指标:平均响应时间(ART)、P95 响应时间(95% 的请求耗时不超过该值)、超时率(耗时 > 5 秒的请求比例);
- 计算方法 :通过监控工具采集每次请求的耗时,按公式计算:
- ART = 总耗时 / 请求总数;
- P95 响应时间:将所有耗时按升序排列,取第 95% 位置的数值;
- 合格标准:ART ≤ 1.5 秒,P95 ≤ 3 秒,超时率 ≤ 2%。
2.1.4 合规性:模型回答是否符合法律法规与业务规范
- 定义:是否包含敏感词、违规表述(如金融场景的 "套现建议",医疗场景的 "绝对治愈");
- 量化指标:违规率(含违规内容的回答数 / 总回答数)、敏感词命中次数;
- 计算方法:集成敏感词库(如结巴分词 + 自定义业务敏感词),对模型输出进行实时检测;
- 合格标准:违规率 = 0,敏感词命中次数 = 0(核心场景零容忍)。
2.2 评估维度量化表
2.3 评估数据采集方式
- 自动采集:响应速度、合规性可通过工具自动采集(监控工具 + 敏感词库);
- 半自动采集:相关性可通过 BLEU 算法自动计算,再人工抽样验证;
- 人工采集:准确性需人工标注(如抽取 10% 回答,对比知识库判断是否错误);
- 周期建议:核心场景每小时采集一次,非核心场景每天采集一次,确保问题及时发现。
3. 监控工具链实战:Spring AI Metrics + Prometheus + Grafana 集成
要实现评估指标的实时监控,需搭建 "Spring AI Metrics 埋点 → Prometheus 数据存储 → Grafana 可视化" 的工具链。这套组合的优势在于:Spring AI 原生支持 Metrics 输出,Prometheus 擅长时序数据存储,Grafana 可快速构建交互式看板。
3.1 工具链架构

3.2 环境准备与依赖配置
3.2.1 版本选择(避免兼容性问题)
- Spring Boot:3.2.5(Spring AI 1.1.0 推荐版本);
- Spring AI:1.1.0(稳定版,支持 Metrics 完整功能);
- Prometheus:2.45.0(兼容 Spring Boot Actuator);
- Grafana:10.4.0(支持 Prometheus 数据源,模板丰富)。
3.2.2 Maven 依赖(核心包)
XML
<!-- Spring Boot Actuator(暴露 Metrics 端点) -->
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-actuator</artifactId>
</dependency>
<!-- Prometheus 依赖(Metrics 格式适配) -->
<dependency>
<groupId>io.micrometer</groupId>
<artifactId>micrometer-registry-prometheus</artifactId>
</dependency>
<!-- Spring AI 核心依赖(含 Metrics 能力) -->
<dependency>
<groupId>org.springframework.ai</groupId>
<artifactId>spring-ai-core</artifactId>
<version>1.1.0</version>
</dependency>
<!-- 以通义千问为例,添加模型依赖 -->
<dependency>
<groupId>com.alibaba.cloud</groupId>
<artifactId>spring-cloud-starter-alibaba-ai</artifactId>
<version>2023.0.1.0</version>
</dependency>3.3 Spring AI Metrics 配置与埋点
3.3.1 暴露 Prometheus 端点(application.yml)
bash
spring:
ai:
tongyi:
access-key: ${TONGYI_ACCESS_KEY} # 通义千问密钥(环境变量注入)
secret-key: ${TONGYI_SECRET_KEY}
chat:
model: qwen-turbo # 模型版本
options:
temperature: 0.5 # 初始参数(后续调优)
max-tokens: 1024
# Actuator 配置:暴露 Prometheus 端点
management:
endpoints:
web:
exposure:
include: prometheus,health,info # 只暴露需要的端点,避免安全风险
metrics:
export:
prometheus:
enabled: true # 启用 Prometheus 导出
tags:
application: spring-ai-quality-demo # 应用标签(方便多应用监控)
endpoint:
health:
show-details: always # 健康检查显示详细信息3.3.2 核心指标埋点(自动 + 自定义)
Spring AI 会自动埋点以下核心指标(无需额外代码):
spring_ai_chat_completions_seconds:AI 聊天请求耗时(含分位数,如 P95);spring_ai_chat_completions_count:AI 聊天请求总数;spring_ai_chat_completions_errors_count:AI 聊天请求错误数(如模型调用失败)。
若需自定义指标 (如 BLEU 分数、违规率),可通过 MeterRegistry 实现:
java
import io.micrometer.core.instrument.MeterRegistry;
import io.micrometer.core.instrument.Timer;
import org.springframework.ai.chat.ChatResponse;
import org.springframework.ai.tongyi.TongyiChatClient;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.stereotype.Service;
import java.util.concurrent.TimeUnit;
@Service
public class AIService {
private final TongyiChatClient chatClient;
private final Timer aiChatTimer; // 自定义耗时计时器(补充默认指标)
private final MeterRegistry meterRegistry;
// 注入 MeterRegistry 用于自定义指标
@Autowired
public AIService(TongyiChatClient chatClient, MeterRegistry meterRegistry) {
this.chatClient = chatClient;
this.meterRegistry = meterRegistry;
// 初始化自定义计时器:添加模型标签
this.aiChatTimer = Timer.builder("spring_ai_custom_chat_timer")
.tag("model", "qwen-turbo")
.register(meterRegistry);
}
// AI 聊天方法:埋点自定义指标
public String chat(String prompt) {
// 1. 记录耗时(自定义计时器)
return aiChatTimer.record(() -> {
// 2. 调用模型
ChatResponse response = chatClient.call(prompt);
String aiOutput = response.getResult().getOutput().getContent();
// 3. 自定义指标:BLEU 分数(假设已实现 BLEU 计算方法)
double bleuScore = calculateBleuScore(prompt, aiOutput);
meterRegistry.gauge("spring_ai_chat_bleu_score",
"prompt", prompt.substring(0, 20), // 截取 prompt 前20字符作为标签
bleuScore);
// 4. 自定义指标:违规率(假设已实现违规检测)
boolean isViolation = checkViolation(aiOutput);
meterRegistry.counter("spring_ai_chat_violation_count",
"is_violation", String.valueOf(isViolation))
.increment();
return aiOutput;
});
}
// 辅助方法:计算 BLEU 分数(简化版,实际需引入自然语言处理库)
private double calculateBleuScore(String prompt, String output) {
// 实际场景推荐使用 org.apache.commons:commons-text 库的 BLEU 实现
// 此处简化:假设核心关键词匹配则返回 0.8,否则 0.5
if (output.contains(getCoreKeyword(prompt))) {
return 0.8;
}
return 0.5;
}
// 辅助方法:违规检测(基于敏感词库)
private boolean checkViolation(String output) {
String[] sensitiveWords = {"套现", "诈骗", "赌博"};
for (String word : sensitiveWords) {
if (output.contains(word)) {
return true;
}
}
return false;
}
// 辅助方法:提取 prompt 核心关键词(简化)
private String getCoreKeyword(String prompt) {
if (prompt.contains("还款")) return "还款";
if (prompt.contains("利率")) return "利率";
return "";
}
}3.4 Prometheus 配置(抓取 Spring AI 指标)
- 下载 Prometheus(https://prometheus.io/download/),解压后修改
prometheus.yml:
bash
global:
scrape_interval: 15s # 抓取间隔(15秒一次,平衡实时性与性能)
evaluation_interval: 15s
scrape_configs:
- job_name: 'spring-ai-demo' # 任务名
metrics_path: '/actuator/prometheus' # Spring AI 暴露的指标路径
static_configs:
- targets: ['localhost:8080'] # Spring AI 应用地址(IP:端口)
scrape_interval: 10s # 该任务抓取间隔(比全局短,因为 AI 指标变化快)- 启动 Prometheus:
bash
# Linux/Mac
./prometheus --config.file=prometheus.yml
# Windows
prometheus.exe --config.file=prometheus.yml- 验证抓取结果:访问 http://localhost:9090,在查询框输入
spring_ai_chat_completions_count,若能看到数据,说明抓取成功。
3.5 Grafana 可视化配置
- 启动 Grafana(默认端口 3000),访问 http://localhost:3000,初始账号密码 admin/admin。
- 添加 Prometheus 数据源:
- 左侧菜单 → Data Sources → Add data source → 选择 Prometheus;
- URL 填写 http://localhost:9090(Prometheus 地址);
- 点击 Save & Test,显示 "Data source is working" 即成功。
- 导入 Spring AI 监控模板:
- 左侧菜单 → Dashboards → Import → 输入模板 ID(推荐 1860,Prometheus 官方 JVM 模板,可自定义修改);
- 选择已添加的 Prometheus 数据源,点击 Import。
- 自定义 AI 质量看板:
- 添加 "核心指标卡片":如请求总数、错误率、P95 延迟;
- 添加 "趋势图":BLEU 分数变化、违规率变化;
- 设置 "告警阈值":如错误率 > 5% 时触发告警。
4. 参数调优技巧:温度 / Top-P / 最大令牌数的 "场景化配置指南"
Spring AI 支持的模型参数中,温度(Temperature)、Top-P、最大令牌数(Max-Tokens) 对响应质量影响最大。调优的核心是 "场景匹配"------ 不同业务场景(如客服、营销、代码生成)需要不同的参数组合,而非 "一刀切"。
4.1 三大核心参数解析
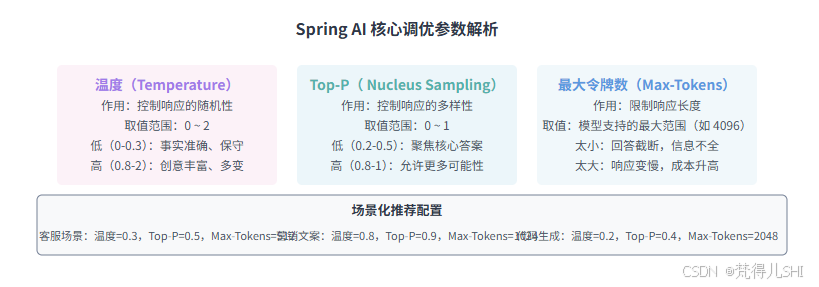
4.2 场景化调优实战案例
4.2.1 案例 1:金融客服场景(准确性优先)
需求:用户咨询 "信用卡还款规则",需准确回答截止日期、违约金计算方式,不允许模糊表述。
- 初始问题:温度 = 0.8(太高),导致模型偶尔给出 "可能在每月 5 号左右" 的模糊回答(准确性不达标);
- 调优策略 :
- 温度降至 0.3:减少随机性,确保回答基于事实;
- Top-P 设为 0.5:聚焦核心规则,避免无关信息;
- Max-Tokens 设为 512:还款规则无需长文本,避免浪费资源;
- 调优后效果:事实错误率从 8% 降至 1%,BLEU 分数从 0.6 升至 0.85。
配置代码:
java
// 客服场景专用配置
public ChatClient createCustomerServiceChatClient() {
return TongyiChatClient.builder()
.apiKey(accessKey)
.secretKey(secretKey)
.model("qwen-turbo")
.defaultOptions(ChatOptions.builder()
.temperature(0.3)
.topP(0.5)
.maxTokens(512)
.build())
.build();
}4.2.2 案例 2:营销文案场景(创意优先)
需求:为新产品生成 "朋友圈推广文案",需多样化、有吸引力,避免重复。
- 初始问题:温度 = 0.2(太低),生成的文案都是 "XX 产品,品质优良,欢迎购买"(相关性达标,但创意不足);
- 调优策略 :
- 温度升至 0.8:增加创意性,生成不同风格的文案;
- Top-P 设为 0.9:允许更多词汇组合,提升多样性;
- Max-Tokens 设为 1024:文案需要细节描述(如使用场景、优惠活动);
- 调优后效果:人工反馈 "创意满意度" 从 40% 升至 85%,相同产品生成的 10 条文案无重复。
4.2.3 案例 3:代码生成场景(精准性优先)
需求:用户要求 "生成 Spring Boot 集成 Redis 的配置类",需可直接运行,无语法错误。
- 初始问题:温度 = 0.5(偏高),偶尔生成 "@EnableCaching" 注解遗漏的代码(准确性不达标);
- 调优策略 :
- 温度降至 0.2:代码生成需严格遵循语法,减少随机性;
- Top-P 设为 0.4:聚焦标准配置,避免非标准写法;
- Max-Tokens 设为 2048:配置类 + 注释需要足够长度;
- 调优后效果:代码语法错误率从 5% 降至 0,用户直接复用率从 60% 升至 95%。
4.3 调优避坑指南
- 不要同时调多个参数:每次只调整一个参数(如先调温度,再调 Top-P),否则无法定位哪个参数起作用;
- Max-Tokens 不是越大越好:根据场景估算合理长度(如客服回答 512 足够,长文档总结 2048 合适),过大反而会增加响应时间(实测:从 1024 增至 4096,响应时间增加 1.2 秒);
- 温度与 Top-P 不要同时过高:若温度 = 1.5 且 Top-P=1.0,会导致回答混乱、逻辑不清(如客服场景出现 "建议套现还款" 的违规表述);
- 参数需与 Prompt 配合:调优参数的同时,优化 Prompt(如客服场景添加 "请用准确日期回答,不要模糊表述"),效果会翻倍。
5. 综合实战:搭建企业级 AI 服务质量评估看板
本节基于前面的工具链与调优技巧,完整实现 "评估指标采集 → 实时监控 → 人工反馈 → 参数调优" 的闭环,搭建企业级评估看板。
5.1 看板需求与架构
5.1.1 核心需求
- 实时监控:显示请求总数、错误率、P95 延迟、BLEU 分数、违规率五大核心指标;
- 趋势分析:展示近 24 小时指标变化(如 BLEU 分数是否下降);
- 人工反馈:支持运营人员标注 "满意 / 不满意",并关联具体回答;
- 调优记录:记录参数调整历史,对比调优前后效果;
- 告警通知:指标超标时(如错误率 > 5%),通过邮件 / 钉钉告警。
5.1.2 看板架构
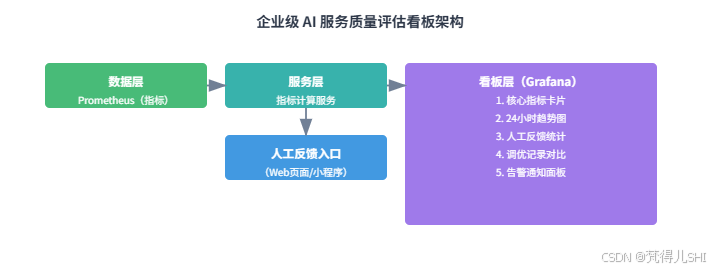
5.2 关键模块实现
5.2.1 人工反馈数据存储(MySQL 表设计)
sql
-- 人工反馈表:记录用户对 AI 回答的评价
CREATE TABLE ai_feedback (
id BIGINT AUTO_INCREMENT PRIMARY KEY,
prompt TEXT NOT NULL COMMENT '用户提问',
ai_output TEXT NOT NULL COMMENT 'AI 回答',
feedback_type TINYINT NOT NULL COMMENT '反馈类型:1-满意,2-不满意',
reason VARCHAR(255) COMMENT '不满意原因(如:答非所问、错误)',
created_time DATETIME DEFAULT CURRENT_TIMESTAMP COMMENT '反馈时间',
ai_model VARCHAR(50) COMMENT '使用的 AI 模型',
temperature DOUBLE COMMENT '调优时的温度参数',
top_p DOUBLE COMMENT '调优时的 Top-P 参数',
INDEX idx_created_time (created_time) COMMENT '时间索引,用于趋势分析'
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 COMMENT='AI 服务人工反馈表';
-- 调优记录表:记录参数调整历史
CREATE TABLE ai_tuning_record (
id BIGINT AUTO_INCREMENT PRIMARY KEY,
tuning_time DATETIME DEFAULT CURRENT_TIMESTAMP COMMENT '调优时间',
model VARCHAR(50) NOT NULL COMMENT '模型名称',
old_params JSON NOT NULL COMMENT '调优前参数',
new_params JSON NOT NULL COMMENT '调优后参数',
reason VARCHAR(255) COMMENT '调优原因(如:错误率过高)',
operator VARCHAR(50) COMMENT '调优人员',
before_metrics JSON COMMENT '调优前指标',
after_metrics JSON COMMENT '调优后指标(72小时后更新)'
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 COMMENT='AI 模型调优记录表';5.2.2 反馈处理服务(关联指标优化)
java
import com.baomidou.mybatisplus.core.conditions.query.QueryWrapper;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.stereotype.Service;
import java.time.LocalDateTime;
import java.util.List;
@Service
public class FeedbackService {
@Autowired
private AiFeedbackMapper feedbackMapper;
@Autowired
private AiTuningRecordMapper tuningRecordMapper;
@Autowired
private AIService aiService;
// 提交人工反馈
public void submitFeedback(FeedbackDTO dto) {
// 1. 保存反馈记录
AiFeedback feedback = new AiFeedback();
feedback.setPrompt(dto.getPrompt());
feedback.setAiOutput(dto.getAiOutput());
feedback.setFeedbackType(dto.getFeedbackType());
feedback.setReason(dto.getReason());
feedback.setAiModel("qwen-turbo");
feedback.setTemperature(dto.getTemperature());
feedback.setTopP(dto.getTopP());
feedbackMapper.insert(feedback);
// 2. 若不满意率 > 10%,触发参数调优建议
if (isNeedTuning()) {
suggestTuning();
}
}
// 判断是否需要调优:近1小时不满意率 > 10%
private boolean isNeedTuning() {
LocalDateTime oneHourAgo = LocalDateTime.now().minusHours(1);
QueryWrapper<AiFeedback> wrapper = new QueryWrapper<>();
wrapper.ge("created_time", oneHourAgo);
long total = feedbackMapper.selectCount(wrapper);
if (total < 10) { // 样本量不足10,不触发调优
return false;
}
wrapper.eq("feedback_type", 2); // 2-不满意
long badCount = feedbackMapper.selectCount(wrapper);
return (double) badCount / total > 0.1; // 不满意率 > 10%
}
// 生成调优建议(基于反馈原因)
private void suggestTuning() {
// 1. 分析不满意原因(如:答非所问→相关性问题→调小 Top-P)
QueryWrapper<AiFeedback> wrapper = new QueryWrapper<>();
wrapper.eq("feedback_type", 2)
.ge("created_time", LocalDateTime.now().minusHours(1));
List<AiFeedback> badFeedbacks = feedbackMapper.selectList(wrapper);
// 2. 生成调优建议(简化版:若答非所问多,调小 Top-P)
long irrelevantCount = badFeedbacks.stream()
.filter(f -> "答非所问".equals(f.getReason()))
.count();
if (irrelevantCount > badFeedbacks.size() / 2) {
// 答非所问占比超50%,建议 Top-P 从0.5降至0.3
TuningSuggestionDTO suggestion = new TuningSuggestionDTO();
suggestion.setReason("近1小时答非所问占比高,建议调小 Top-P");
suggestion.setOldTopP(0.5);
suggestion.setNewTopP(0.3);
// 3. 保存调优记录(等待人工确认后执行)
AiTuningRecord record = new AiTuningRecord();
record.setModel("qwen-turbo");
record.setOldParams("{\"temperature\":0.3,\"topP\":0.5}");
record.setNewParams("{\"temperature\":0.3,\"topP\":0.3}");
record.setReason(suggestion.getReason());
record.setOperator("system");
tuningRecordMapper.insert(record);
// 4. (可选)自动执行调优(核心场景建议人工确认)
// aiService.updateChatOptions(0.3, 0.3, 512);
}
}
}5.2.3 Grafana 看板配置(核心面板)
-
核心指标卡片面板:
- 指标:
spring_ai_chat_completions_count(请求总数)、spring_ai_chat_completions_errors_count(错误数)、spring_ai_chat_bleu_score(BLEU 分数); - 样式:大数字展示,错误数用红色,合格分数用绿色。
- 指标:
-
24 小时趋势图面板:
- 指标:
spring_ai_chat_completions_seconds{quantile="0.95"}(P95 延迟)、spring_ai_chat_violation_count(违规数); - 样式:折线图,X 轴为时间(24 小时),Y 轴为指标值,添加合格线(如 P95=3s)。
- 指标:
-
人工反馈统计面板:
- 指标:从 MySQL 读取
ai_feedback表数据,计算满意 / 不满意占比; - 样式:饼图,显示满意(绿色)、不满意(红色)比例。
- 指标:从 MySQL 读取
-
调优记录对比面板:
- 指标:从 MySQL 读取
ai_tuning_record表数据,对比调优前后的错误率、BLEU 分数; - 样式:柱状图,X 轴为调优时间,Y 轴为指标值,分 "调优前""调优后" 两组。
- 指标:从 MySQL 读取
6. 调优实战中的 5 个高频坑与解决方案
6.1 坑 1:Metrics 数据不采集,Prometheus 看不到指标
- 现象 :访问 http://localhost:8080/actuator/prometheus,没有
spring_ai_*相关指标; - 原因 :
- 未添加 Spring AI 核心依赖(
spring-ai-core); - 模型客户端未正确初始化(如
TongyiChatClient未注入); - Actuator 端点未暴露
prometheus;
- 未添加 Spring AI 核心依赖(
- 解决方案 :
- 检查
pom.xml,确保spring-ai-core依赖存在; - 验证
TongyiChatClient是否通过@Autowired成功注入(无NullPointerException); - 确认
management.endpoints.web.exposure.include包含prometheus。
- 检查
6.2 坑 2:调优后指标反降(如 BLEU 分数下降)
- 现象:调小温度后,BLEU 分数从 0.8 降至 0.6;
- 原因 :
- 温度过低,模型 "过于保守",回答缺失核心信息(如用户问 "还款规则 + 违约金",只回答了还款规则);
- 未同步优化 Prompt,调优参数后 Prompt 与参数不匹配;
- 解决方案 :
- 温度适当回调(如从 0.2 升至 0.3),平衡准确性与完整性;
- 优化 Prompt,明确要求 "覆盖所有问题点"(如 "请回答信用卡还款日期和违约金计算方式,两个问题都要回答")。
6.3 坑 3:Grafana 告警误触发(如频繁提示 "错误率超标")
- 现象:错误率实际为 2%,但 Grafana 频繁告警 "错误率> 5%";
- 原因 :
- Prometheus 抓取间隔太短(如 5 秒),导致瞬时错误被放大;
- 告警规则未设置 "持续时间"(如一次错误就触发告警);
- 解决方案 :
- 将 Prometheus 抓取间隔调整为 15 秒(
scrape_interval: 15s); - Grafana 告警规则添加 "持续 2 个周期"(如错误率 > 5% 持续 30 秒才告警)。
- 将 Prometheus 抓取间隔调整为 15 秒(
6.4 坑 4:Max-Tokens 设太大,响应速度骤降
- 现象:Max-Tokens 从 1024 增至 4096 后,P95 延迟从 2 秒升至 5 秒;
- 原因:模型生成更长文本需要更多计算资源,尤其是长上下文处理耗时增加;
- 解决方案 :
- 根据场景重新估算合理长度(如客服回答 512 足够,无需 4096);
- 启用 "流式响应"(Spring AI 支持
Flux<ChatResponse>),减少用户等待感知; - 对长文本场景,采用 "分段生成"(如先生成核心结论,再补充细节)。
6.5 坑 5:人工反馈数据无法关联到指标
- 现象:人工标注 "不满意",但无法定位该反馈对应的 AI 请求耗时、参数;
- 原因:反馈数据未关联 AI 请求的唯一标识(如请求 ID);
- 解决方案 :
- 生成 AI 请求时,创建唯一
requestId并返回给前端; - 前端提交反馈时,携带
requestId; - 后端存储反馈时,关联
requestId与 Metrics 中的request_id标签,实现数据打通。
- 生成 AI 请求时,创建唯一
7. 总结与未来:LLMOps 视角下的自动化评估与调优
本文围绕 "量化指标 + 人工反馈" 双轮优化,构建了 Spring AI 模型评估与调优的完整体系,核心收获可总结为三点:
- 评估要量化:告别 "感觉良好",用 BLEU 分数、P95 延迟等指标定义质量标准;
- 调优要场景化:不同业务场景(客服 / 营销 / 代码)需要不同的参数组合,无 "万能参数";
- 监控要闭环:通过看板实时追踪指标,用人工反馈反哺调优,形成 "监控→发现问题→调优→验证" 的闭环。
从未来趋势看,AI 质量优化将向 LLMOps(大语言模型运维) 方向发展:
- 自动化评估:结合 RAG 技术,自动比对模型回答与知识库,无需人工标注;
- 自适应调优:基于实时指标(如错误率上升),自动调整参数(如降低温度);
- 多模型对比:看板支持同时监控多个模型(如通义千问 vs 文心一言),自动选择最优模型;
- 成本 - 质量平衡:在调优时加入成本指标(如 Token 消耗),实现 "质量达标 + 成本最优"。
对于企业而言,Spring AI 模型的评估与调优不是 "一次性任务",而是 "持续迭代的过程"------ 只有将质量监控融入日常运维,才能让 AI 真正成为业务增长的驱动力,而非 "不稳定的风险点"。
8. 附录:常用工具版本与配置模板
8.1 工具版本清单
| 工具 / 框架 | 推荐版本 | 备注 |
|---|---|---|
| Spring Boot | 3.2.5 | 兼容 Spring AI 1.1.0 |
| Spring AI | 1.1.0 | 稳定版,支持 Metrics 完整功能 |
| Prometheus | 2.45.0 | 兼容 Spring Boot Actuator |
| Grafana | 10.4.0 | 支持 Prometheus 数据源 |
| 通义千问模型 | qwen-turbo | 平衡速度与质量 |
| MySQL | 8.0.32 | 存储反馈与调优记录 |
8.2 Prometheus 配置模板(prometheus.yml)
bash
global:
scrape_interval: 15s
evaluation_interval: 15s
rule_files:
# - "first_rules.yml"
# - "second_rules.yml"
scrape_configs:
- job_name: 'spring-ai'
metrics_path: '/actuator/prometheus'
static_configs:
- targets: ['192.168.1.100:8080'] # 替换为你的 Spring AI 应用地址
scrape_interval: 10s
scrape_timeout: 5s
labels:
env: production # 环境标签(生产/测试)8.3 Grafana 告警规则模板(JSON)
bash
{
"alertRules": [
{
"title": "AI 错误率超标",
"condition": "A > 5",
"data": [
{
"refId": "A",
"datasourceUid": "prometheus-ds", # 替换为你的 Prometheus 数据源 UID
"model": {
"expr": "sum(rate(spring_ai_chat_completions_errors_count[5m])) / sum(rate(spring_ai_chat_completions_count[5m])) * 100",
"interval": "",
"intervalFactor": 1,
"legendFormat": "错误率",
"refId": "A"
}
}
],
"for": "30s", # 持续 30 秒超标才告警
"noDataState": "no_data",
"execErrState": "error",
"annotations": {
"summary": "AI 错误率超过 5%",
"description": "当前错误率:{{ $value }}%,请检查模型调用情况"
},
"labels": {
"severity": "warning"
}
}
]
}如果需要本文中所有实战代码(含 Spring Boot 项目、SQL 脚本、Prometheus/Grafana 配置)的压缩包,可以告诉我,我会整理后提供下载链接,方便你直接部署测试!
