创建AI后端项目
在上一期我们跑通了接口调用,我们就可以开始使用Java来接入阿里百炼大模型API了
环境准备
由于本项目使用的是Spring Boot 3和Spring AI开发框架,所以安装的JDK必须是17或21,不能选择其他版本
新建配置
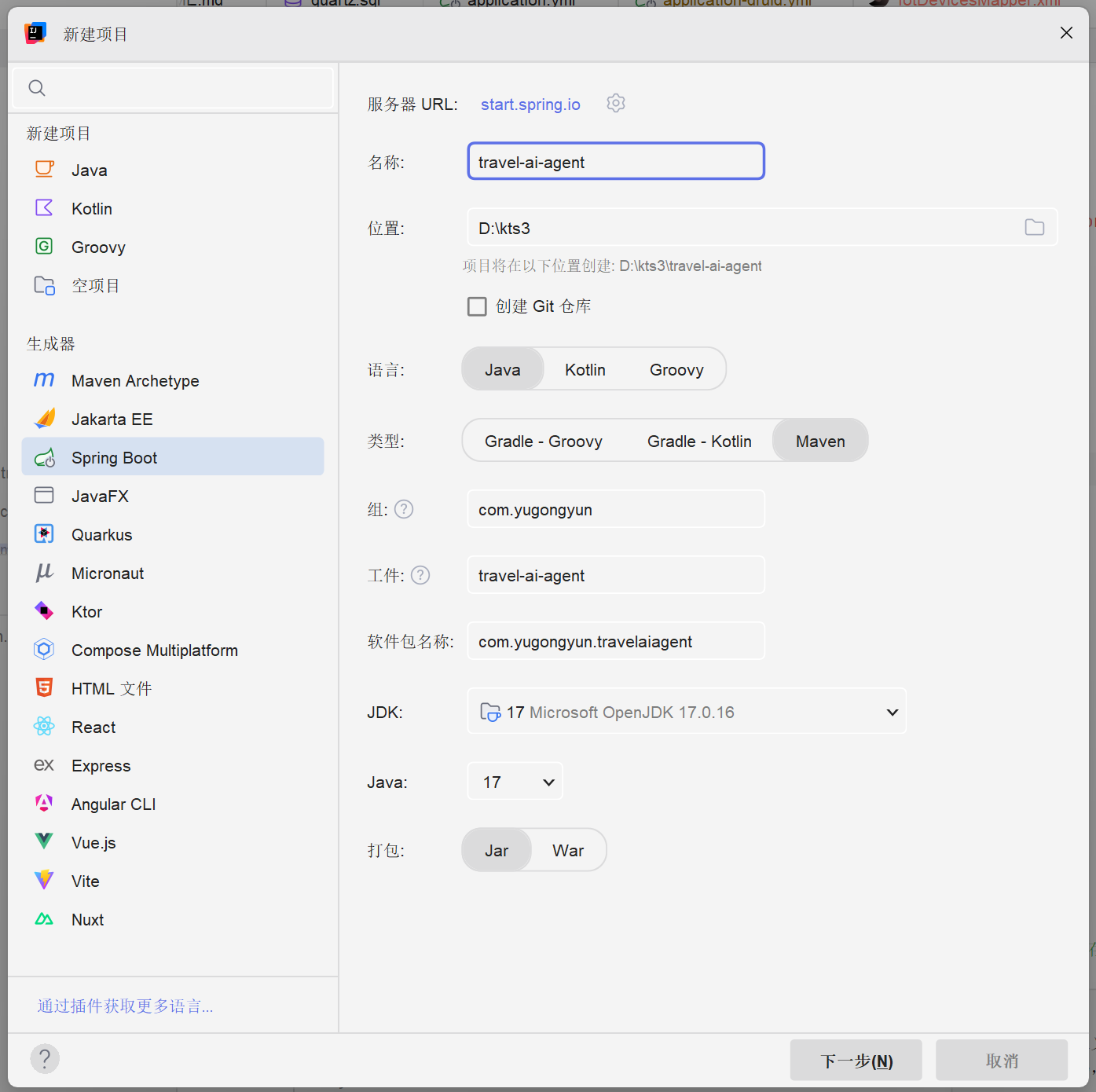
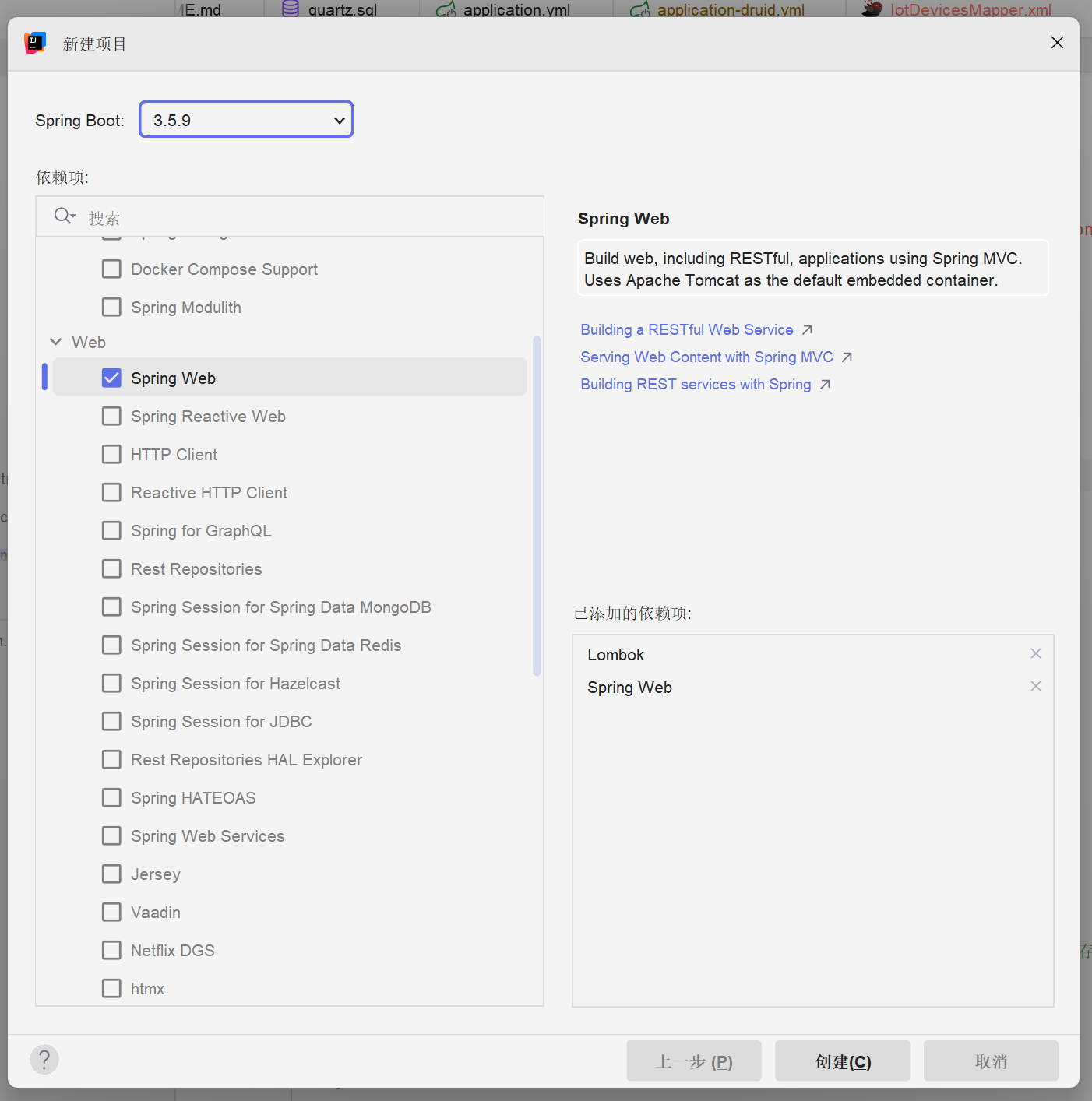
在IDEA中新建SpringBoot项目,配置如下图:
整合依赖
开发AI项目时我们通常需要使用许多开发工具和接口,所以我们来整合HHHutool工具库和Kinfe4j接口文档
引入Hutool工具库
Hutool是一个小而全的Java工具类库,通过静态方法封装,降低相关API的学习成本,提高工作效率,使Java拥有函数式语言般的优雅,让Java语言也可以"甜甜的"。
Hutool中的工具方法来自每个用户的精雕细琢,它涵盖了Java开发底层代码中的方方面面,它既是大型项目开发中解决小问题的利器,也是小型项目中的效率担当;
Hutool是项目中"util"包友好的替代,它节省了开发人员对项目中公用类和公用工具方法的封装时间,使开发专注于业务,同时可以最大限度的避免封装不完善带来的bug。
通过Maven引入Hutool
XML
<dependency>
<groupId>cn.hutool</groupId>
<artifactId>hutool-all</artifactId>
<version>5.8.38</version>
</dependency>Knife4接口文档
你想了解的 Knife4j 是目前 Java 生态中 最主流、最易用、功能最全 的 SpringBoot/SpringCloud 接口文档生成工具,是Swagger/OpenAPI 的国产增强升级版,解决了原生 Swagger 的所有痛点,是后端开发的标配组件
官方文档:https://doc.xiaominfo.com/knife4j/
在Maven的pom.xml中添加依赖:
XML
<dependency>
<groupId>com.github.xiaoymin</groupId>
<artifactId>knife4j-openapi3-jakarta-spring-boot-starter</artifactId>
<version>4.4.0</version>
</dependency>更改application.properties为application.yml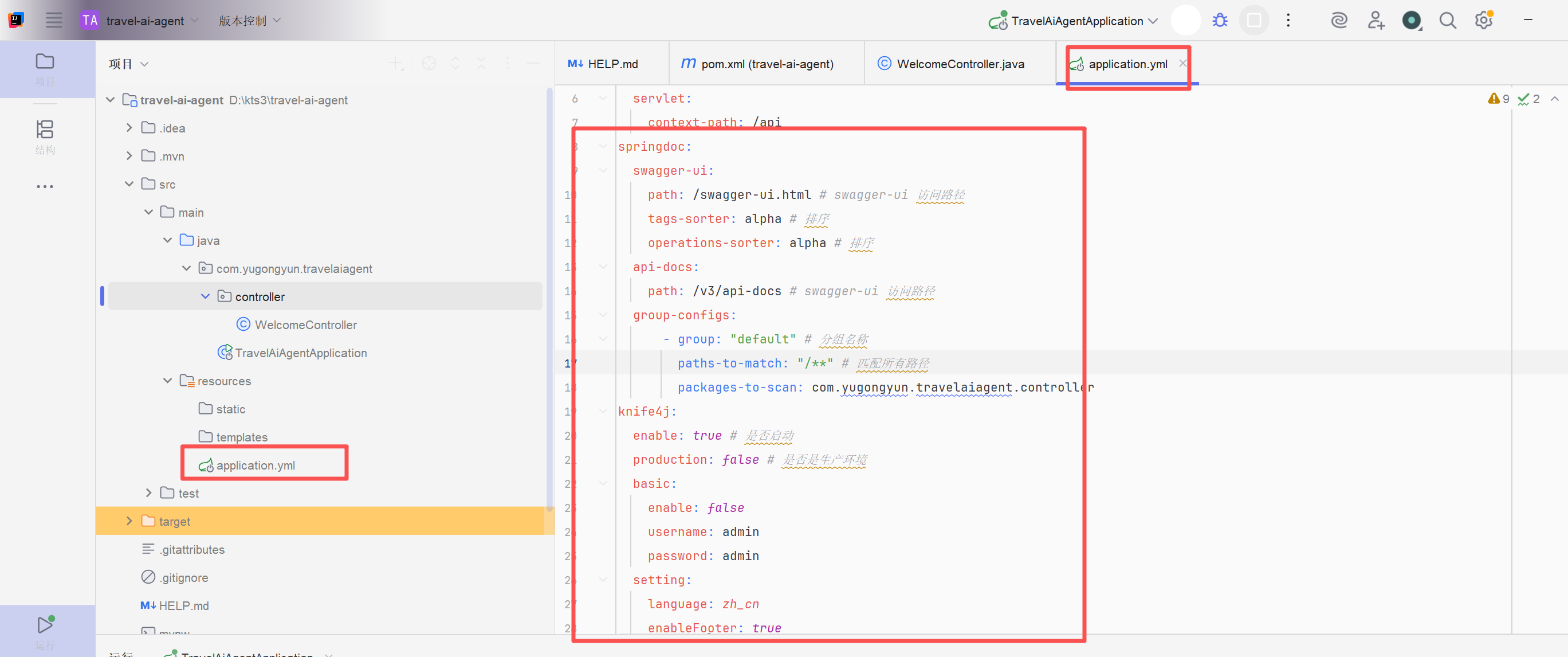
配置服务器信息和knife4j
XML
spring:
application:
name:travel-ai-agent
server:
port: 8080
servlet:
context-path: /api
springdoc:
swagger-ui:
path: /swagger-ui.html # swagger-ui 访问路径
tags-sorter: alpha # 排序
operations-sorter: alpha # 排序
api-docs:
path: /v3/api-docs # swagger-ui 访问路径
group-configs:
- group: "default" # 分组名称
paths-to-match: "/**" # 匹配所有路径
packages-to-scan: com.yugongyun.travelaiagent.controller
knife4j:
enable: true # 是否启动
production: false # 是否是生产环境
basic:
enable: false
username: admin
password: admin
setting:
language: zh_cn
enableFooter: true
enable-footer-custom: true在项目中调用AI大模型
在实际开发中,存在多种方式可以将大型人工智能模型集成到应用程序中。以下将详细介绍四种主流的接入方式,并加上对应的示例,说明如何在Java项目中实现与大型AI模型的交互。
主流接入方案:
- HTTP接入:通过模型服务商提供的REST API接口,直接发送HTTP请求来调用模型服务
- SDK接入:利用模型服务商官方提供的软件开发工具包进行集成。这是最直接,封装程度最高的方式
- Spring AI:一个基于Spring框架生态系统的AI应用开发框架,旨在简化大型语言模型在Spring应用中的集成过程
- LangChain4j:一个专为构建基于大模型语言的应用而设计的Java框架,提供了丰富的组件链来支持复杂的AI交互逻辑
开发环境选择:
HTTP实现接入
HTTP接入是通过Http协议发送主动构造第三方接口的请求,从而获得响应结果的方式,这种方式需要熟悉官方接口文档,并熟悉如何使用Java实现HTTP请求的发送和响应处理。
HTTP调用的详细说明可以参考官方文档:API请求响应参数详解与代码示例-大模型服务平台百炼-阿里云
使用Deepseek生成请求代码
可以使用Deepseek将cURL转换成接口请求
参考提示词:
帮我将以下curl代码转化为Hutool的Http请求代码curl --location "https://dashscope.aliyuncs.com/api/v1/services/aigc/text-generation/generation" \
--header "Authorization: Bearer $DASHSCOPE_API_KEY" \
--header "Content-Type: application/json" \
--data '{
"model": "qwen-plus",
"input":{
"messages":[
{
"role": "system",
"content": "You are a helpful assistant."
},
{
"role": "user",
"content": "你是谁?"
}
]
},
"parameters": {
"result_format": "message"
}
}'
由于AI生成的随机性,可能生成的结果不一样但是大部分情况都是可以正常运行
我们在项目中新建一个测试类将deepseek生成的代码放到测试类中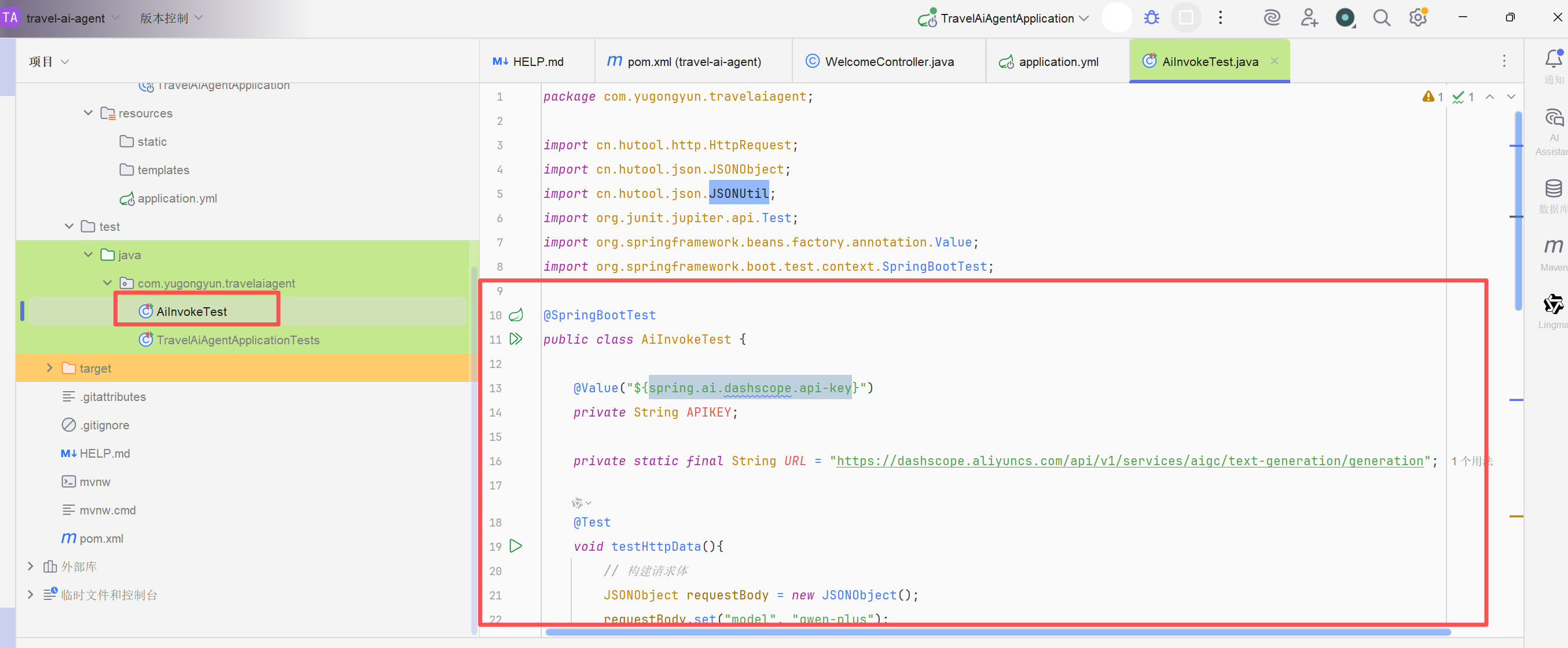
对应代码如下:
java
@SpringBootTest
public class AiInvokeTest {
@Value("${spring.ai.dashscope.api-key}")
private String APIKEY;
private static final String URL = "https://dashscope.aliyuncs.com/api/v1/services/aigc/text-generation/generation";
@Test
void testHttpData(){
// 构建请求体
JSONObject requestBody = new JSONObject();
requestBody.set("model", "qwen-plus");
JSONObject input = new JSONObject();
JSONObject systemMessage = new JSONObject();
systemMessage.set("role", "system");
systemMessage.set("content", "You are a helpful assistant.");
JSONObject userMessage = new JSONObject();
userMessage.set("role", "user");
userMessage.set("content", "你是谁?");
input.set("messages", JSONUtil.createArray().put(systemMessage).put(userMessage));
requestBody.set("input", input);
JSONObject parameters = new JSONObject();
parameters.set("result_format", "message");
requestBody.set("parameters", parameters);
// 发送请求
String response = HttpRequest.post(URL)
.header("Authorization", "Bearer " + APIKEY)
.header("Content-Type", "application/json")
.body(requestBody.toString())
.timeout(30000) // 设置超时时间30秒
.execute()
.body();
System.out.println("Response: " + response);
}
}这里的APIKEY的值提取到了配置文件中属性名为:spring.ai.dashscope.api-key
配置APIKEY避免泄露
1.配置环境分离
我们这里使用将配置存入系统变量的方式,避免将其写入代码库中:
java
spring:
ai:
dashscope:
api-key: ${DASH_SCOPE_API_KEY}然后我们在windows系统中配置环境变量DASH_SCOPE_API_KEY,值为阿里云百炼平台的API-KEY,这样就对应配置文件中的${DASH_SCOPE_API_KEY}被SpringBoot启动时读取如图所示: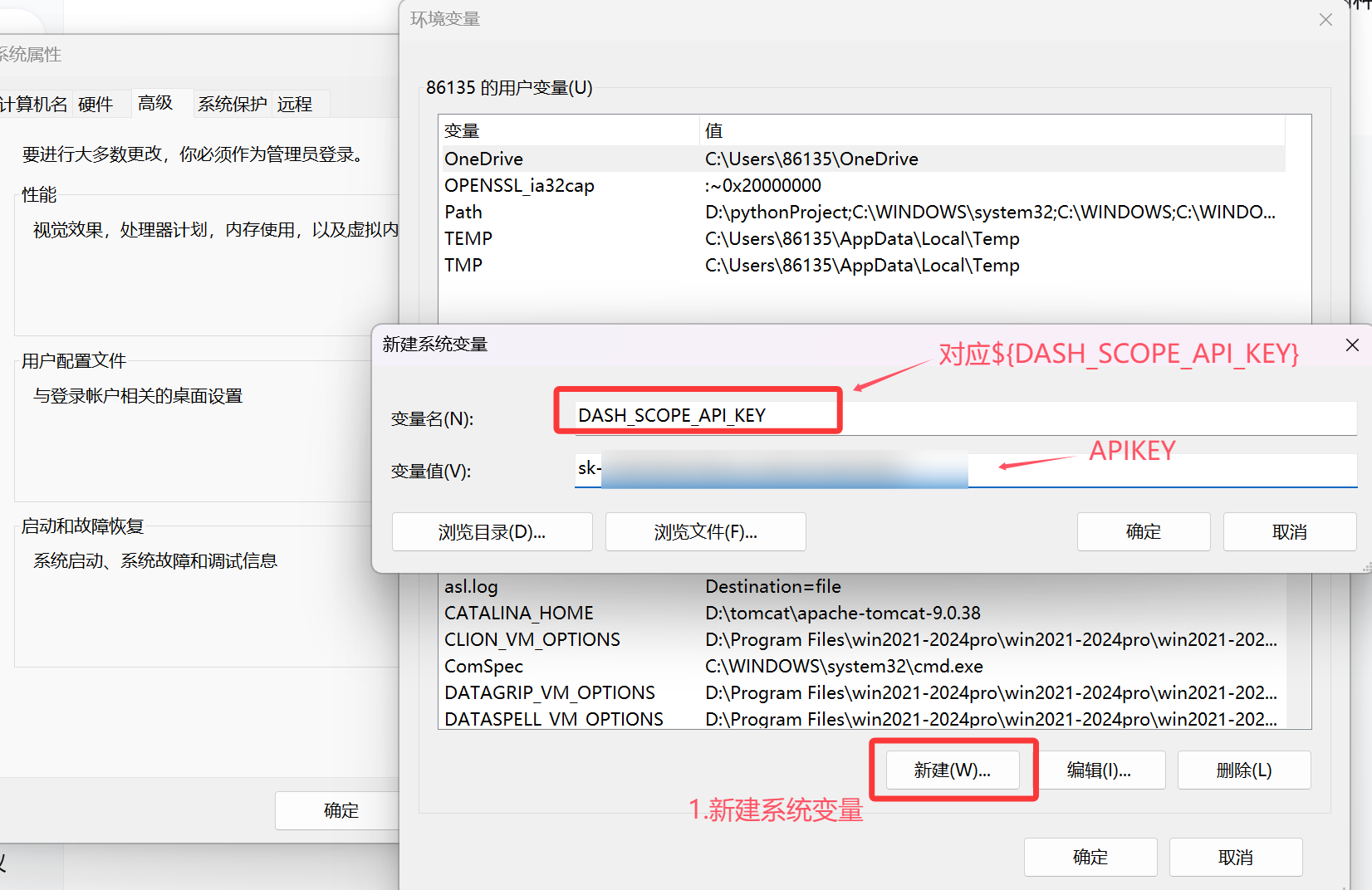
确认修改后需要重启IDEA,因为Windows环境变量在程序启动时就固定了
之后我们运行测试,输出相应结果:
2.配置文件分离
由于Linux系统和windows系统配置方式不一样,生产每个部署系统都要做一次环境变量的配置,所以我们学习一下如何通过配置文件分离实现本地配置文件密钥不上传到远程仓库
利用SpringBoot的配置文件优先级和多环境配置都可以实现
技术原理
Spring Boot的Profile是一种强大的机制,用于在不同的环境中激活不同的配置。在Spring Boot中我们可以使用@Profile注解或者spring.profile.active属性来激活特定的profile。
-
在src/java/resouress文件夹中新建一个application-dev.yml,配置文件
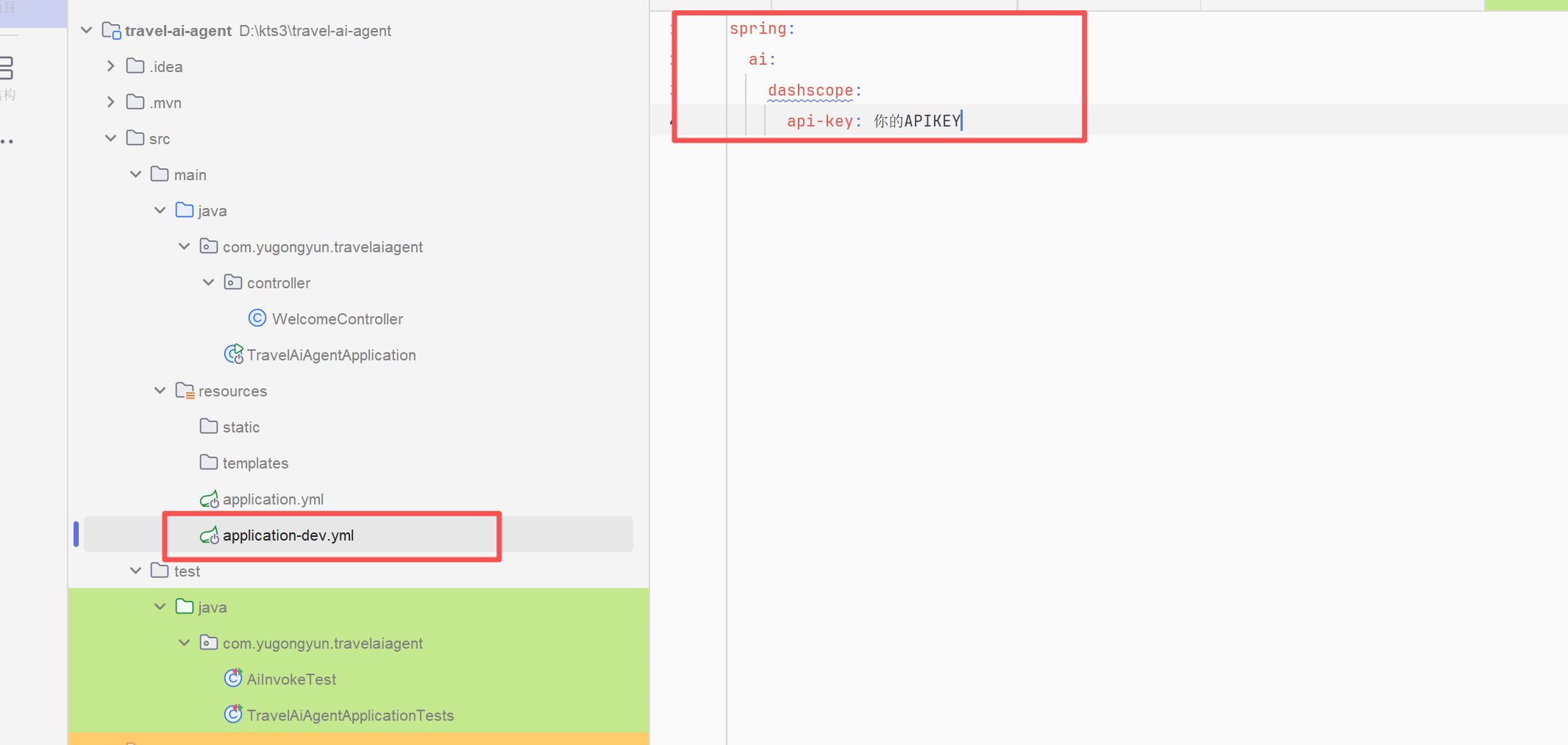
spring: ai: dashscope: api-key: 你的APIKEY -
在application.yml中新增spring.profile.active配置为dev,激活application-dev.yml配置文件
spring: ai: dashscope: api-key: ${DASH_SCOPE_API_KEY} profiles: active: dev现在我们运行看可以看到控制台显示被激活的配置是 dev

-
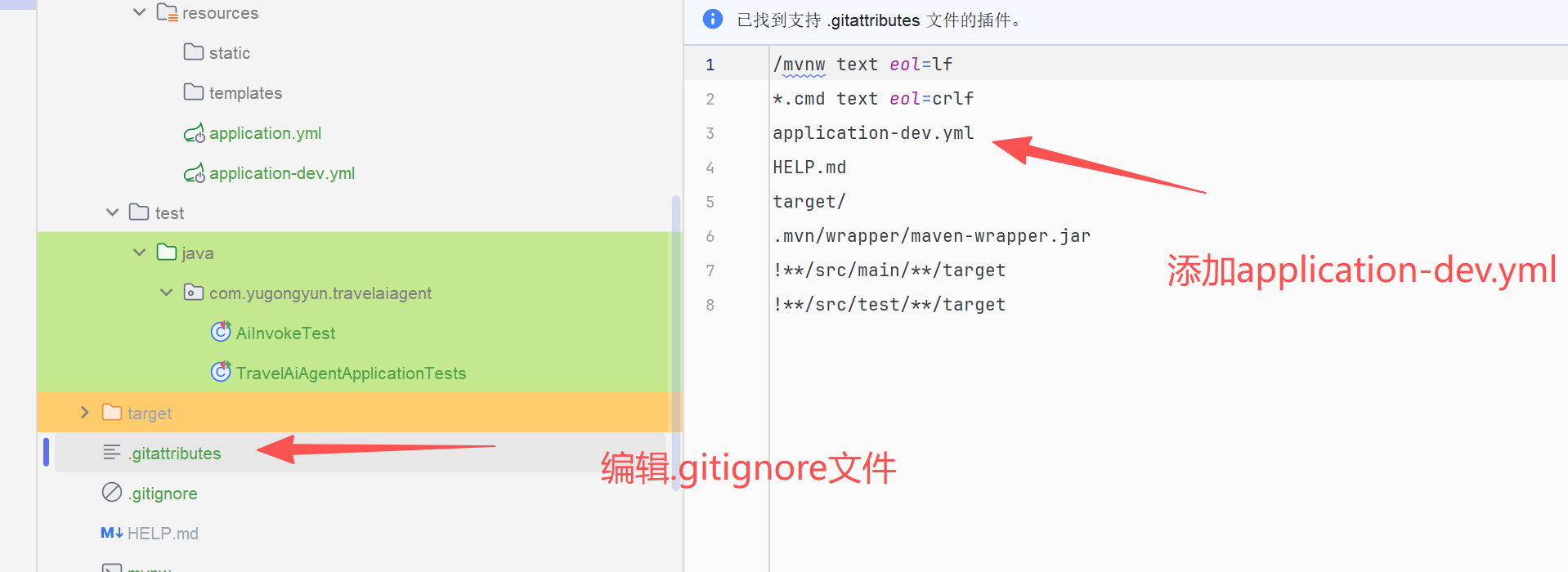
添加.gitignore规则,忽略application-dev.yml配置文件
-
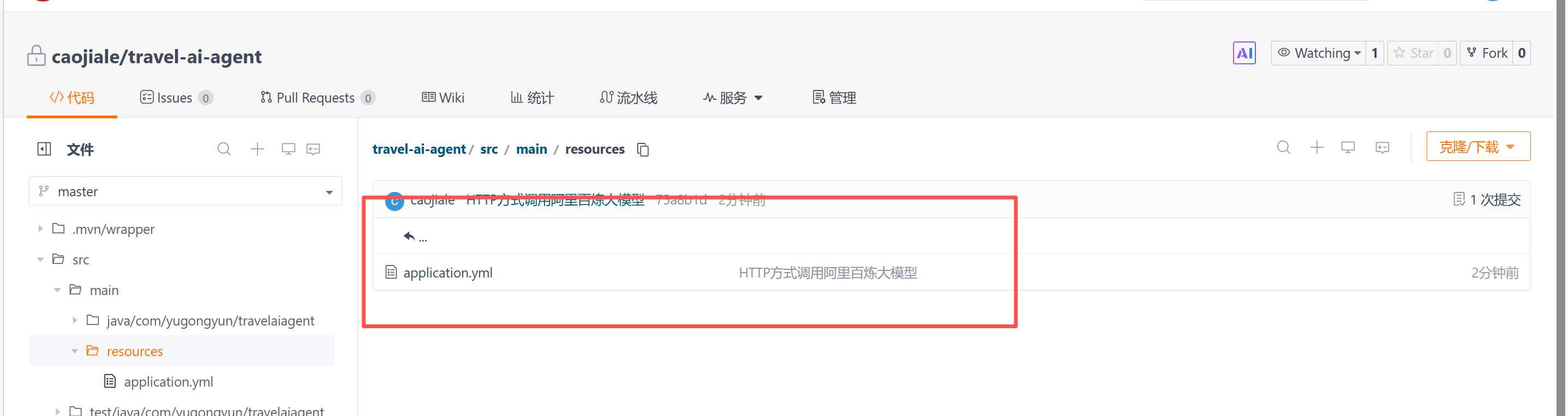
提交一个git版本,并推送到远程仓库,先复制Git远程仓库的地址然后在终端依次输入如下命令
git add git commit -m "HTTP方式调用阿里百炼大模型" git remote add origin [复制你的Gitee或GitHub远程仓库地址] git push -u origin "master"在远程仓库定位到src/resources文件夹,可以看到application-dev.yml没有被上传
SDK实现接入
SDK(软件开发工具包)是官方提供的最直接的集成方式,通常提供了完善的类型支持和错误处理机制
使用HTTP虽然可以实现接入但是请求还要自己封装,费时费力
安装DashScope Java SDK
参考官方文档:https://help.aliyun.com/zh/model-studio/first-api-call-to-qwen
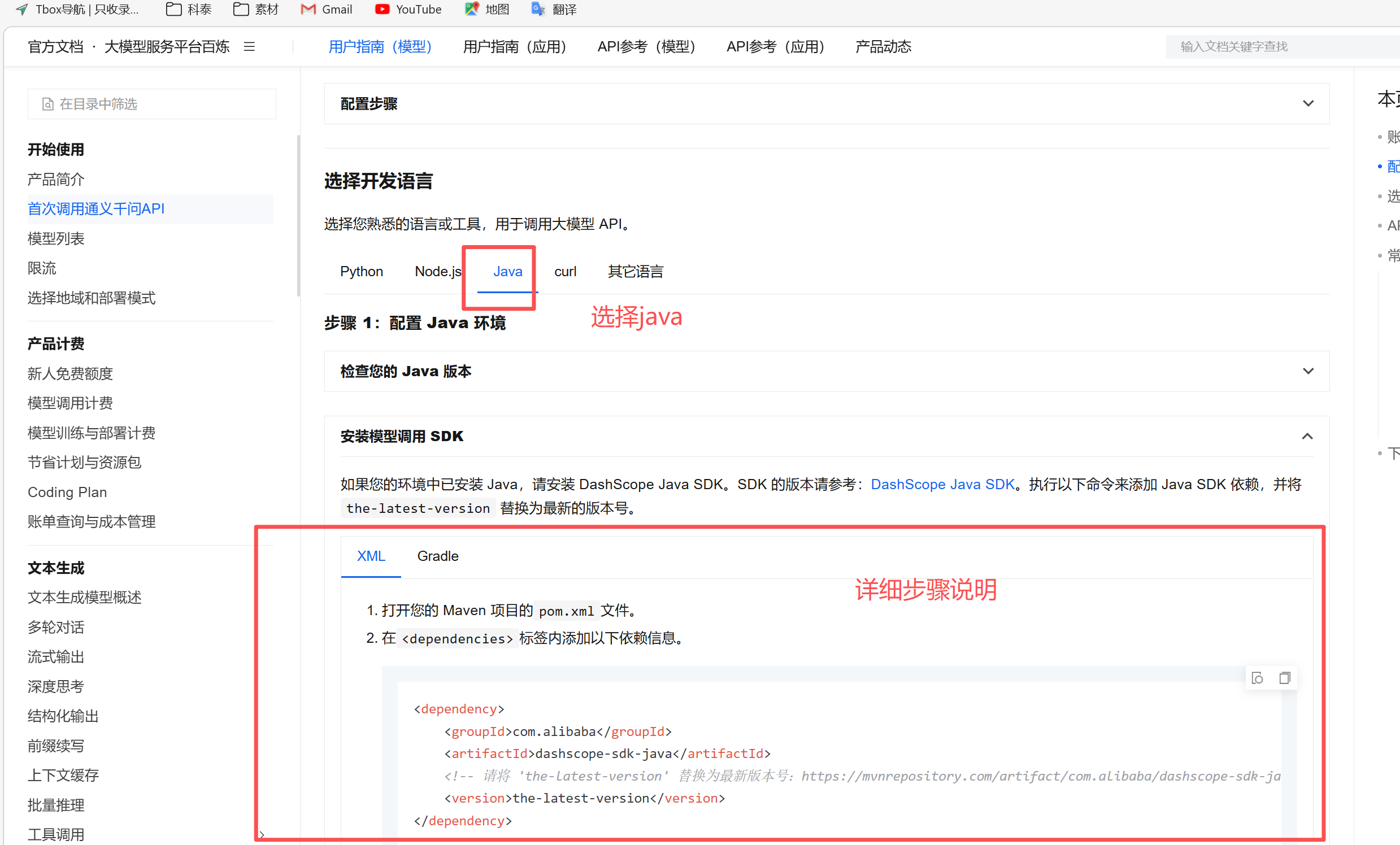
选择版本的话可以到Maven仓库查看:Maven Repository: com.alibaba >> dashscope-sdk-java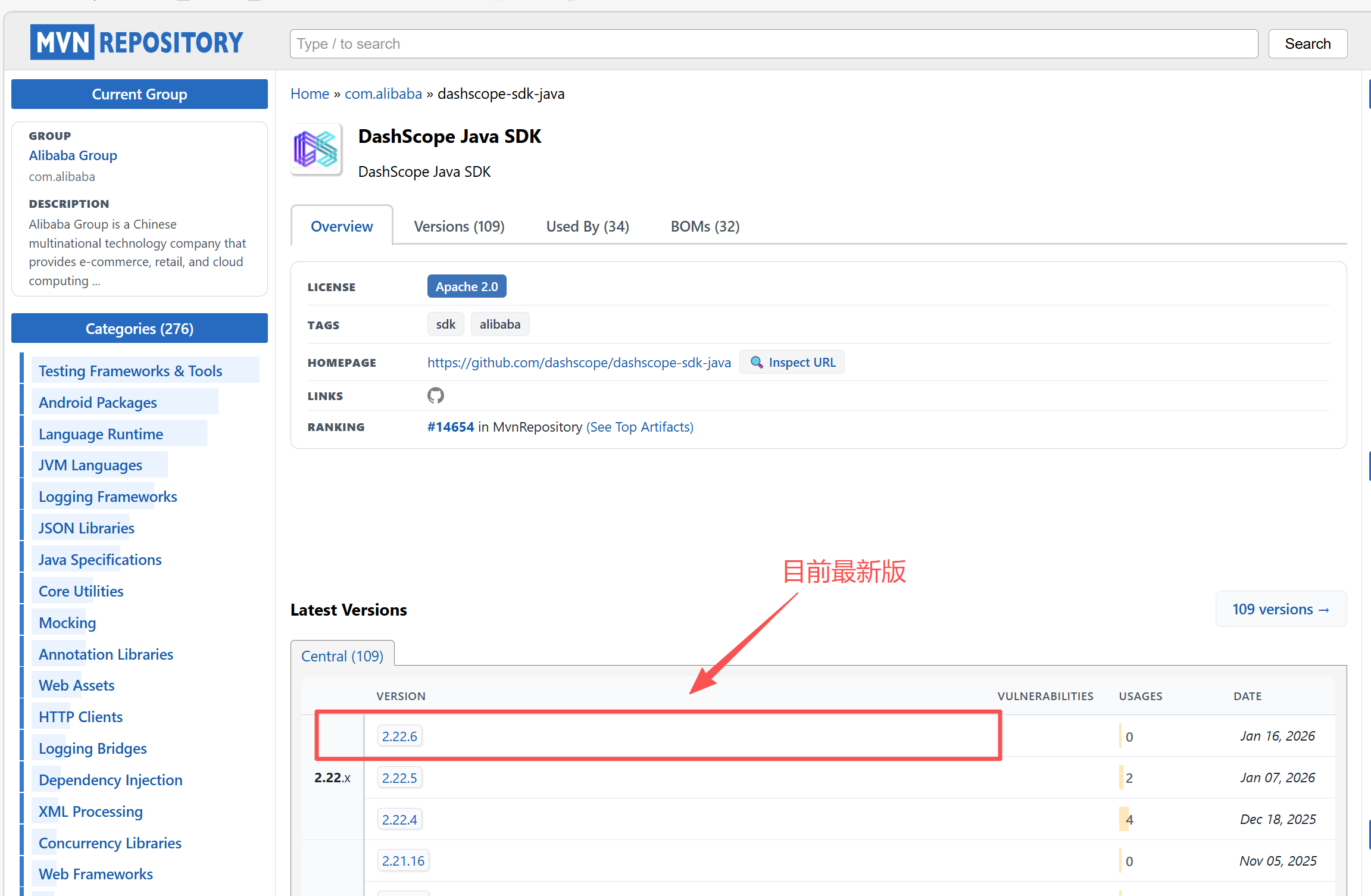
推荐不要使用最新版本,避免有BUG未修复这里我们使用2.19.5
XML
<!-- DashScope Java SDK -->
<dependency>
<groupId>com.alibaba</groupId>
<artifactId>dashscope-sdk-java</artifactId>
<version>2.19.5</version>
</dependency>参考官方文档编写接入代码
我们在刚刚的文档中复制SDK调用示例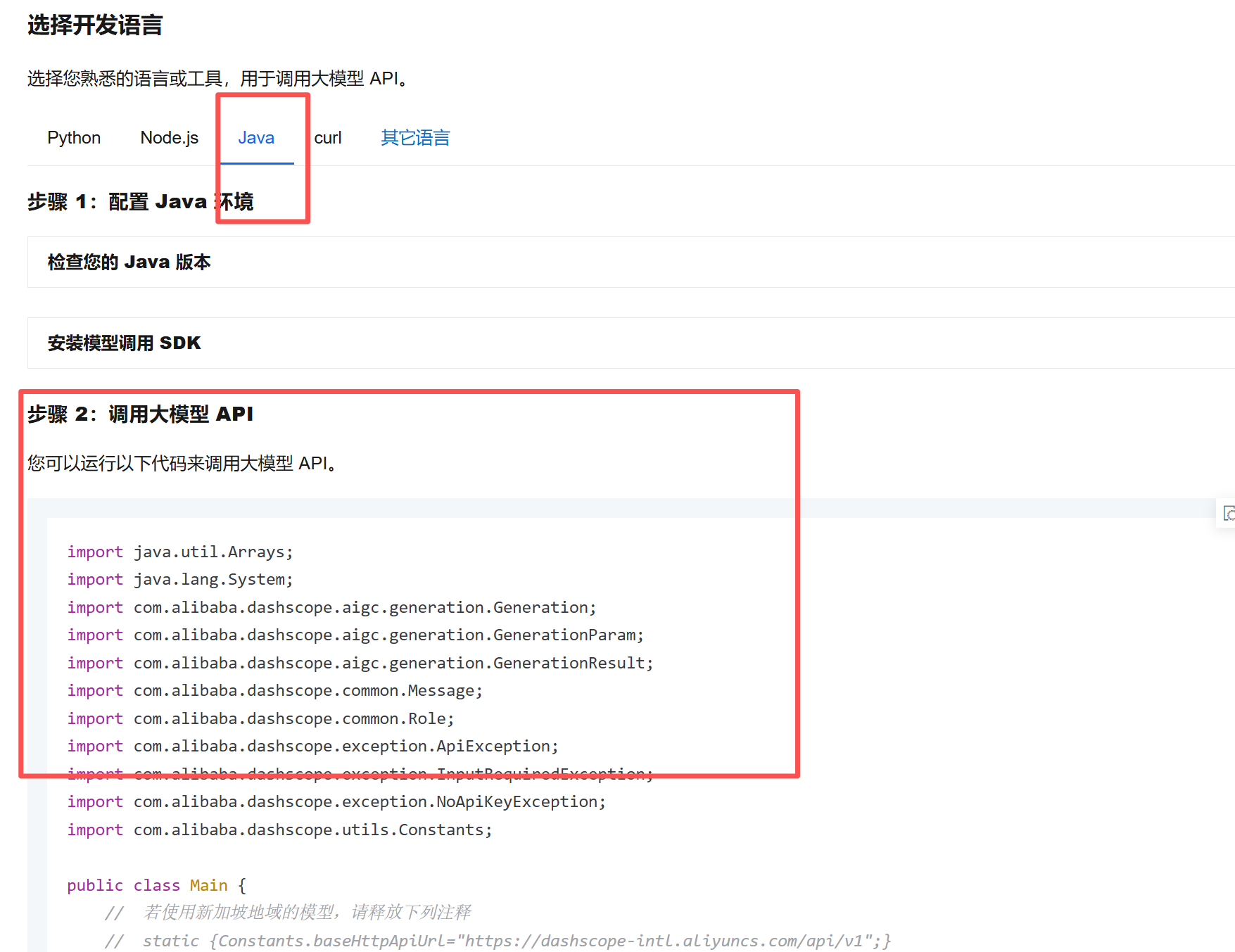
修改测试类,新增testSDKInvoke方法,将官方SDK复制过来修改
java
@Test
void testSDKInvoke() {
try {
GenerationResult result = callWithMessage("qwen-plus","你是谁");
System.out.println(result.getOutput().getChoices().get(0).getMessage().getContent());
} catch (ApiException | NoApiKeyException | InputRequiredException e) {
System.err.println("错误信息:" + e.getMessage());
System.out.println("请参考文档:https://help.aliyun.com/zh/model-studio/developer-reference/error-code");
}
System.exit(0);
}
public GenerationResult callWithMessage(String modelName, String prompt) throws ApiException, NoApiKeyException, InputRequiredException {
Generation gen = new Generation();
Message systemMsg = Message.builder()
.role(Role.SYSTEM.getValue())
.content("You are a helpful assistant.")
.build();
Message userMsg = Message.builder()
.role(Role.USER.getValue())
.content(prompt)
.build();
GenerationParam param = GenerationParam.builder()
// 这里需要使用以注入的APIKEY
.apiKey(APIKEY)
// 模型列表:https://help.aliyun.com/zh/model-studio/getting-started/models
.model(modelName)
.messages(Arrays.asList(systemMsg, userMsg))
.resultFormat(GenerationParam.ResultFormat.MESSAGE)
.build();
return gen.call(param);
}测试运行得到以下结果:
SpringAI实现接入
Spring AI 的核心是解决人工智能集成的根本挑战:将企业数据 和 API 与 AI 模型 连接起来。
Spring AI 的核心是解决人工智能集成的根本挑战:将企业数据 和 API 与 AI 模型连接起来。
Spring AI 提供以下功能,参考文档:https://spring.io/projects/spring-ai:
- 支持跨 AI 提供商的可移植 API 支持,支持同步和流式 API 选项。还可访问模型专属功能。
- 结构化输出------将AI模型输出映射到POJO。
- 支持所有主要的向量数据库提供商,如 Apache Cassandra、Azure Vector Search、Chroma、Milvus、MongoDB Atlas、Neo4j、Oracle、PostgreSQL/PGVector、PineCone、Qdrant、Redis 和 Weaviate。
- 跨向量存储提供商的可移植API,包括一种新颖的类SQL元数据过滤API。
- 工具/函数调用------允许模型请求执行客户端工具和函数,从而根据需要访问必要的实时信息。
- 可观察性------提供关于人工智能相关作的洞察。
- 用于数据工程的文档注入ETL框架。
- AI模型评估------帮助评估生成内容并防止幻觉反应的实用工具。
- ChatClient API - 用于与 AI 聊天模型通信的流畅 API,习语上类似于 WebClient 和 RestClient API。
- Advisors API - 封装反复出现的生成式人工智能模式,转换与语言模型(LLM)之间的数据转换,并提供跨多种模型和用例的可移植性。
- 支持聊天对话、记忆和检索增强生成(RAG)。
- Spring Boot 自动配置及所有 AI 模型和向量存储的启动程序------使用 start.spring.io 选择所选的模型或向量存储。
Spring AI默认没有支持所有大模型(尤其是国产的),更多是兼容OpenAI的大模型集成。因此,如果我们想要调用阿里系大模型(比如通义千问),推荐直接使用阿里自主封装的Spring AI Alibaba框架,它不仅可以直接基础阿里系大模型,用起来更方便,而且与标准的Spring AI保持兼容
修改pom.xml添加Spring AI Alibaba依赖
XML
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-test</artifactId>
<scope>test</scope>
</dependency>修改测试类:
java
@Value("${spring.ai.dashscope.api-key}")
String APIKEY;
@Resource
private ChatModel dashscopeChatModel;
@Test
void testDashScopeInvoke() {
String result = dashscopeChatModel.call("你好你是谁");
System.out.println(result);
}只需要几行代码就可以实现,1.注入ChatModel对象,通过call方法即可实现与大模型对话。测试结果如下图所示:
修改调用的大模型:
从运行结果来看,如果没有配置大模型类型,则默认使用阿里通义千问大模型,我们可以通过配置文件进行修改
例如使用Deepseek-v3.1
只需要修改application.yml增加spring.ai.dashscope.chat.options.model属性的值为deepseek-v3.1: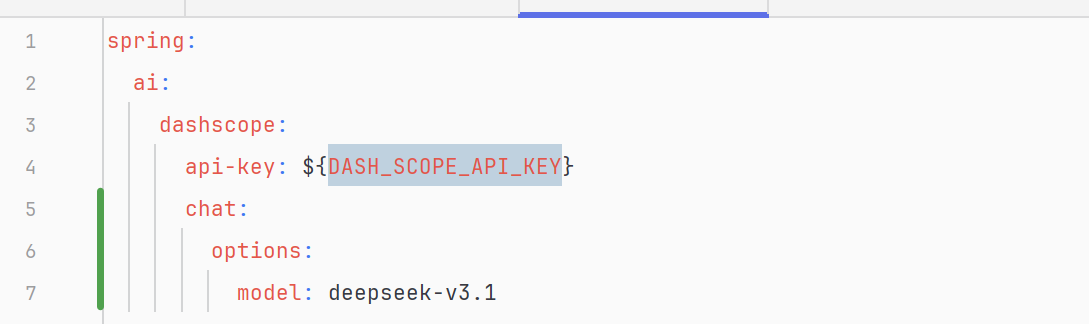
再次运行,效果图如下图所示,成功修改了大模型类型
LangChain4j实现接入:
LangChain4j 是专为 Java/Kotlin(JVM 技术栈) 打造的大语言模型 (LLM) 应用开发框架,是 Python 版 LangChain 的官方纯 Java 实现 ,无任何 Python 依赖,是 Java 开发者做 AI 大模型应用的首选框架
创建Git分支
由于LangChain4j只是测试,我们可以创建一个git分支来做测试,避免影响主分支代码,如果没有使用git此步骤可以忽略
通过idea快速创建分支,步骤如下: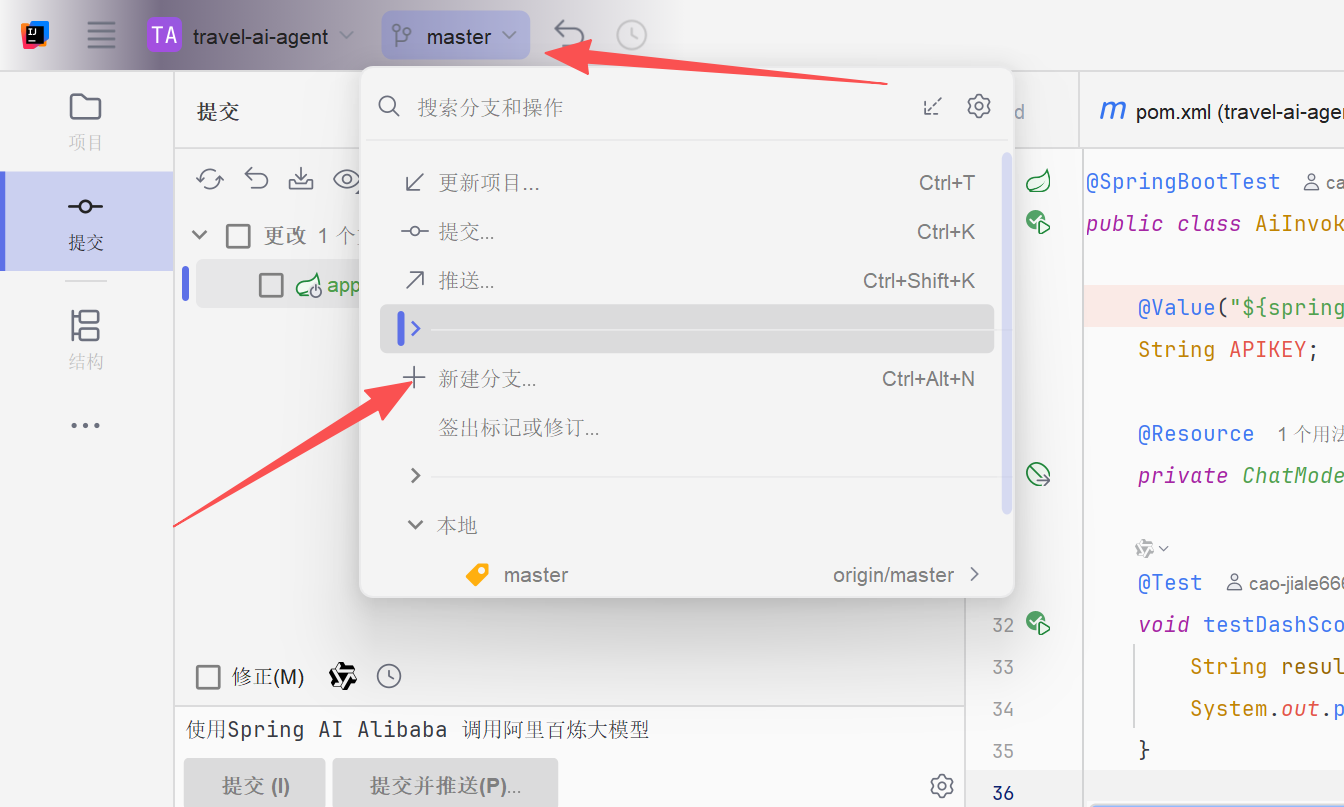
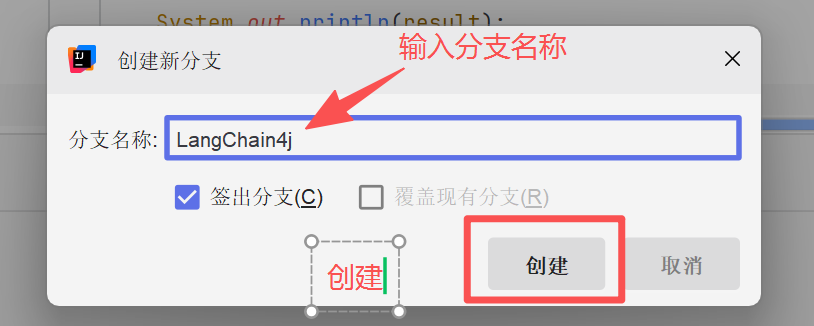
这样我们在新分支的修改就不会影响到主分支版本的内容。
导入LangChain4j依赖
LangChain官方是没有支持阿里系大模型的,只能用社区版本整合大模型包。可以在官方文档中查询支持的模型列表:
https://docs.langchain4j.info/integrations/language-models
要接入阿里云灵积模型,参考:DashScope (通义千问) | LangChain4j 中文文档
在pom文件中增加导入langchain4j的社区依赖包:
XML
<dependency>
<groupId>dev.langchain4j</groupId>
<artifactId>langchain4j-community-dashscope</artifactId>
<version>1.0.0-beta2</version>
</dependency>参考编写测试方法testLangChain4j
在测试类中增加testLangChain4j方法,创建一个ChatLanguageModel对象,和SpringAI的方法很相似。
java
@Test
void testLangChain4j(){
ChatLanguageModel model = QwenChatModel.builder()
.apiKey(APIKEY)
.modelName("deepseek-v3.1")
.build();
String result = model.chat("你好");
System.out.println(result);
}正确调用大模型获得结果,如下图所示:
测试成功我们可以在LangChain4j提交一个版本,利用IDEA的GIT管理视图可以看到版本日志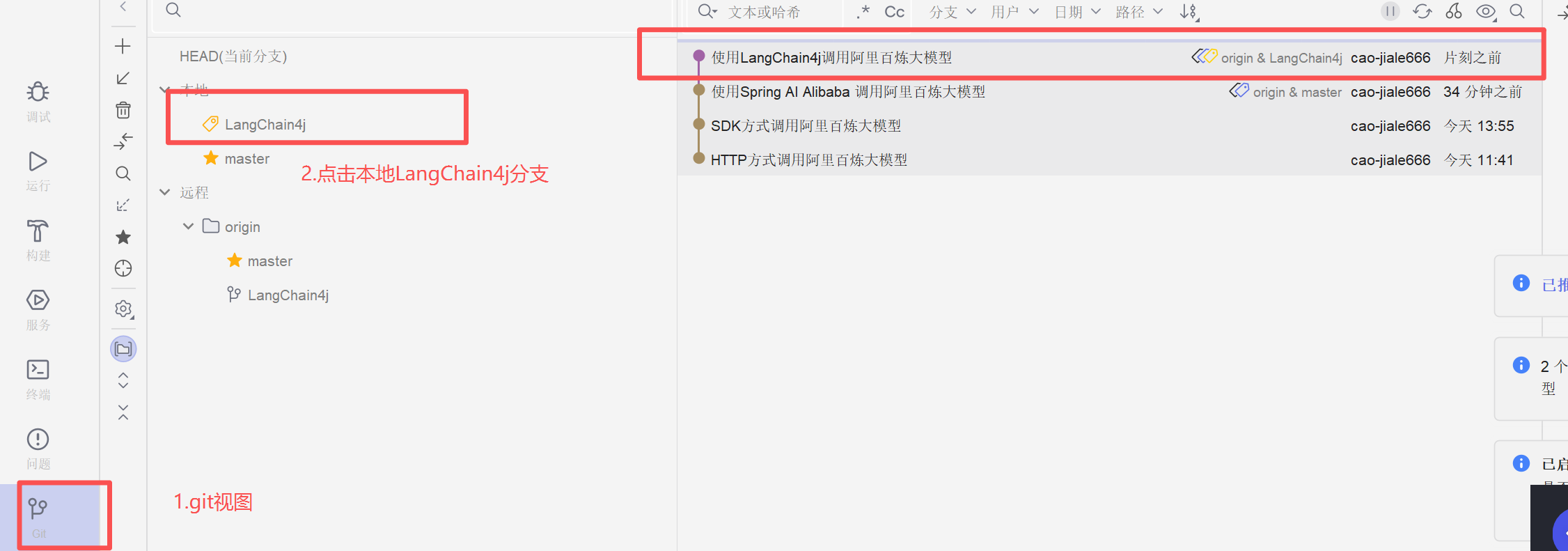
重新检出主版本(master),操作如下图所示: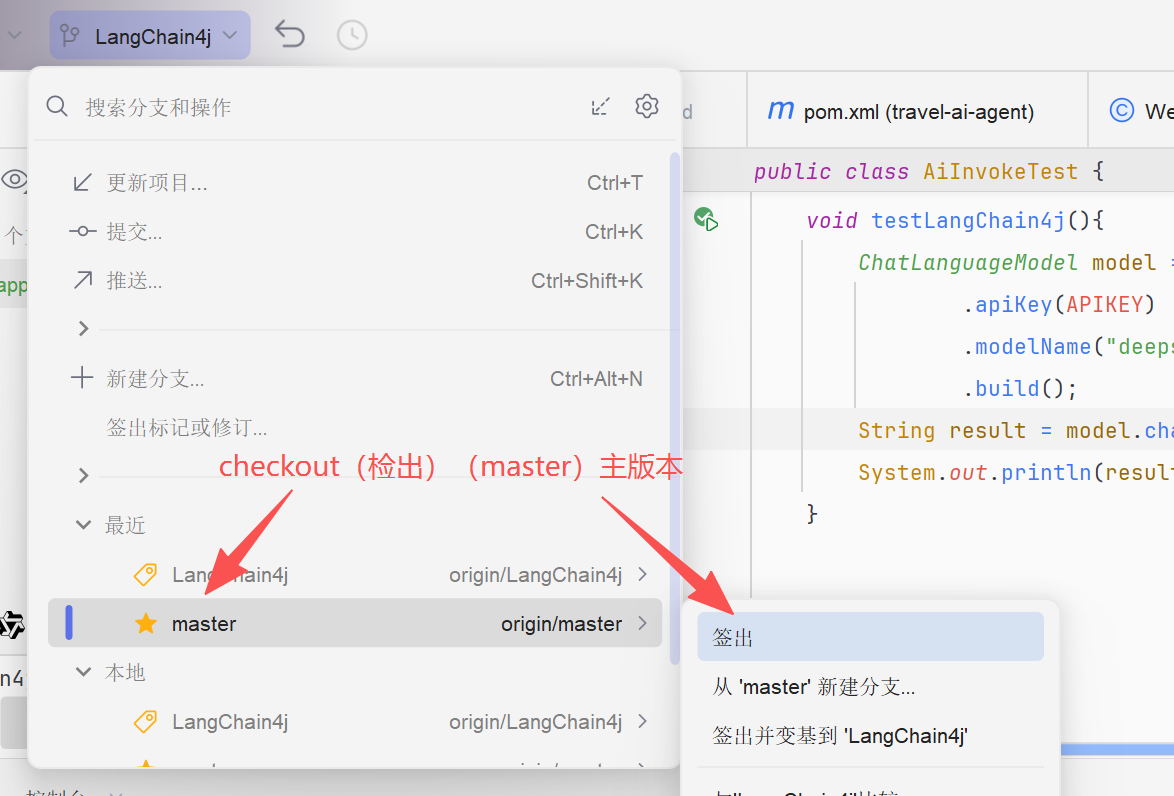
可以分析pom.xml和测试类又回到了之前的版本,这就是分支操作
推荐操作:在执行测试,修复BUG或执行危险操作时可以新建一个分支来验证,如果失败了也不会影响主分支的内容,并且切换简单
各种接入方式对比:
| 接入方式 | 核心特点 | 开发难度 | 大模型适配性 | 功能丰富度 | 核心适用场景 |
|---|---|---|---|---|---|
| HTTP 原生接入 | 纯原生请求,无依赖、链路短、性能最好,手写请求 / 解析 / 异常 | ⭐⭐⭐⭐(高) | 适配所有模型,需手动适配各厂商参数 | 仅基础问答 / 生成 | 极致轻量、嵌入式、性能优先、极简单轮调用 |
| 官方 SDK 接入 | 厂商封装的 Java 工具包,轻量,一键调用,无需处理 HTTP 细节 | ⭐(极低) | 强绑定单一厂商,切换模型需重构 | 仅基础问答 / 生成 | 快速 demo、单一模型对接、极简需求、验证功能 |
| Spring AI 接入 | Spring 官方出品,配置化开发,无缝适配 Spring 生态,低侵入 | ⭐⭐(低) | 统一适配多厂商,配置切换无代码改动 | 基础问答 + 简易上下文 + 轻量 RAG | SpringBoot 项目、常规业务、轻量 LLM 应用 |
| LangChain4j 接入 | JVM 专属 LLM 框架,声明式开发,无 Spring 强依赖,兼容所有 Java 项目 | ⭐⭐(低) | 全量适配国内外模型 + 本地模型,无感切换 | 全功能:完整 RAG / 上下文 / Agent / 工具调用 / 链式任务 | 所有 Java 项目、复杂 LLM 应用、企业级知识库、智能体、多模型兼容 |
本地部署大模型
如果我们有一台高性能显卡电脑,或者公司需要拥有自己的大模型,我们也可以在本地环境中部署和使用大模型,以获得更好的数据隐私控制,以更低的延迟以及无需网络连接的使用体验
下面我们来讲解如何在本地安装和接入AI大模型,并通过SpringAI框架进行调用
本地安装大模型
使用开源项目Ollama可以快速安装大模型,无需自己执行脚本安装,也省去了复杂的环境配置。
Ollama不仅提供了友好的命令行界面,还可以通过API调用,方便与各种应用程序集成。
官方文档:ollama/docs/api.md at main · ollama/ollama · GitHub
下载安装Ollama安装
官网下载页面(国内镜像):在 Windows 上下载 Ollama - Ollama 框架
安装过程比较简单不做赘述
挑选并下载模型
| 硬件配置 | 推荐模型规模 | 典型模型 | 显存 / 内存要求 |
|---|---|---|---|
| 低配设备(老电脑 / 轻薄本) | 1B-3.8B | Qwen2.5:1.5B、Phi3:3.8B | 4GB + 内存,无独显也能跑 |
| 主流配置(游戏本 / 中端 PC) | 7B-8B | Qwen2.5:7B、Llama3.1:8B、Mistral:7B | 8-12GB 显存,16GB + 内存 |
| 高性能配置(工作站 / 高端 GPU) | 13B-14B | Qwen2.5:14B、DeepSeek-R1:13B | 16GB + 显存,32GB + 内存 |
| 专业级配置(服务器 / 多 GPU) | 32B+ | Qwen2.5:32B、Llama3.3:70B | 24GB + 显存,64GB + 内存 |