Swin Transformer 全面解析
Swin Transformer(简称 Swin )是微软团队 2021 年提出的分层视觉 Transformer 模型 ,发表于论文《Swin Transformer: Hierarchical Vision Transformer using Shifted Windows》。它的核心创新是移位窗口自注意力机制 ,解决了原始 ViT 在高分辨率图像上计算量爆炸的问题,同时支持层级特征表示,完美适配目标检测、语义分割等密集预测任务,是目前计算机视觉领域最主流的 Transformer 骨干网络之一。
一、 核心痛点:原始 ViT 的效率瓶颈
原始 ViT 采用全局自注意力,计算复杂度为 O(N2⋅D),其中 N 是图像块数量,D 是特征维度。
- 对于 224×224 图像(16×16 分块,N=196),计算量尚可接受;
- 对于高分辨率图像(如 1024×1024,N=4096),N2 会达到 1600 万,计算量直接飙升,无法落地。
Swin 的核心目标:在保证全局建模能力的前提下,将自注意力的计算复杂度从 O(N2) 降到 O(N),实现高分辨率图像的高效处理。
二、 核心创新:移位窗口自注意力(Shifted Window Attention)
Swin 的核心思想是将全局图像划分为不重叠的局部窗口,仅在窗口内计算自注意力 ,再通过移位窗口实现跨窗口的信息交互。
我们用一个通俗例子理解:把一张猫吃鱼的高分辨率图分成 4 个小窗口(每个窗口里有猫的一部分 + 鱼的一部分),第一步只在每个小窗口内计算注意力(比如窗口 1 里的猫爪和鱼身的关联);第二步把窗口 "挪一下位置",让相邻窗口的边缘部分合并,再计算注意力(比如窗口 1 的猫头和窗口 2 的猫身的关联)------ 既保证了效率,又实现了全局信息流通。
1. 第一步:规则窗口自注意力(Regular Window Attention)
(1) 窗口划分
将特征图划分为大小为 M×M 的不重叠规则窗口,窗口数量为 G=⌈H/M⌉×⌈W/M⌉(H,W 是特征图尺寸)。
例如:特征图尺寸 56×56,窗口大小 M=7,则窗口数量 G=8×8=64。
(2) 窗口内自注意力
仅在每个窗口内计算自注意力,每个窗口的计算复杂度为 O(M2⋅D),全局总复杂度为 G⋅O(M^2⋅D)=O(HW⋅D),完美实现 O(N) 复杂度(N=HW)。
2. 第二步:移位窗口自注意力(Shifted Window Attention)
规则窗口的问题:窗口之间是孤立的,无法捕捉跨窗口的长距离依赖(比如猫的头在窗口 1,尾巴在窗口 2,规则窗口无法建模两者的关联)。
Swin 的解决方案是对特征图进行循环移位,让相邻窗口的边缘部分合并成新窗口,再计算窗口内自注意力。
(1) 移位操作
将特征图沿高度和宽度方向各移位 ⌊2M⌋ 个像素(比如 M=7,移位 3 个像素)。移位后会产生新的不重叠窗口,但会出现两种问题:
- 窗口数量增加(比如 8×8 规则窗口 → 9×9 移位窗口);
- 部分窗口尺寸变小(边缘窗口)。
(2) 优化:掩码机制(Masking Strategy)
为了避免计算量增加,Swin 采用掩码机制:
- 对移位后的特征图进行补零填充,恢复到规则窗口的尺寸;
- 给每个窗口添加掩码,标记哪些位置是 "真实相邻" 的,哪些是 "循环移位拼接" 的;
- 计算自注意力时,掩码区域的注意力分数会被设为 −∞,不参与计算。
3. 相对位置编码(Relative Position Bias)
Swin 在自注意力计算中引入了相对位置编码,而非 ViT 的绝对位置编码,更适合分层特征的尺度变化。自注意力分数的计算公式为:
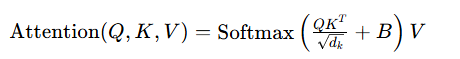
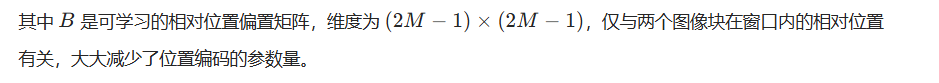
三、 Swin Transformer 完整架构
Swin 采用分层设计,和 CNN 的层级结构(Conv2d+Pooling)对齐,输出多尺度特征图,完美适配目标检测、语义分割等任务。整体架构分为 4 个阶段:
python
输入图像 → Patch Partition → Stage 1 → Stage 2 → Stage 3 → Stage 4 → 下游任务头|------------------------|-----------------------------------------------------------|----------------------|
| 模块 | 功能 | 输入输出尺寸变化 |
| Patch Partition | 图像分块:将 H×W×3 图像划分为 4×4 非重叠块,展平后通过线性层投影到 D 维 | 224×224×3 → 56×56×D |
| Swin Transformer Block | 核心计算单元:LayerNorm → 窗口自注意力 → 残差连接 → LayerNorm → MLP → 残差连接 | 尺寸不变 |
| Patch Merging | 下采样模块:将 2×2 相邻块拼接,通过线性层降维,实现特征图尺寸减半,维度翻倍 | H×W×D → 2/H×2/W×2D |
2. 分层阶段(Stage)
Swin 通过 4 个 Stage 实现分层特征提取,每个 Stage 包含多个 Swin Block + 1 个 Patch Merging(最后一个 Stage 除外):
- Stage 1:输入 56×56×D,经过多个 Swin Block,输出 56×56×D;
- Stage 2:Patch Merging 下采样到 28×28×2D,再经过 Swin Block;
- Stage 3:Patch Merging 下采样到 14×14×4D,再经过 Swin Block;
- Stage 4:Patch Merging 下采样到 7×7×8D,再经过 Swin Block。
最终输出 4 个尺度的特征图(56X56,28X28,14X14,7X7),和 ResNet 等 CNN 骨干的输出尺度完全一致,可直接替换 CNN 作为下游任务的骨干网络。
代码层面及解析
段代码核心是使用 OpenVINO 2025 框架加载 ONNX 格式的 Swin Tiny 模型,完成对蚂蚁 (ant)/ 蜜蜂 (bee) 的二分类推理,并将预测结果可视化展示。
一、整体功能总结
这段代码实现了完整的「模型加载 → 图像预处理 → 推理执行 → 结果解析 → 可视化」流程:
- 加载 OpenVINO 并编译 ONNX 格式的 Swin Tiny 模型(针对 ant/bee 二分类);
- 对输入图像执行符合 Swin 模型要求的预处理(尺寸、归一化、维度调整);
- 运行模型推理,取 Top-1 预测结果;
- 将预测类别标注在原图上并显示。
python
import cv2
import numpy as np
import openvino as ov
# 加载ONNX格式的SWIN Tiny模型
core = ov.Core()
compiled_model = core.compile_model("swin_t_ant_bee.onnx", "CPU")
# 获取输入和输出层
input_layer = compiled_model.input(0)
output_layer = compiled_model.output(0)
# 定义图像预处理函数
def preprocess_image(image_path):
# 打开图像
image = cv2.imread(image_path)
cv2.imshow("input", image)
if image is None:
raise ValueError("Image not found or unable to read")
# 调整图像大小为224x224
input_size = (224, 224)
image = cv2.resize(image, input_size)
# 转换为RGB格式
image = cv2.cvtColor(image, cv2.COLOR_BGR2RGB)
# 归一化图像
mean = [0.485, 0.456, 0.406]
std = [0.229, 0.224, 0.225]
image = np.array(image) / 255.0
image -= mean
image /= std
# 调整维度为[1, C, H, W]
image = np.transpose(image, (2, 0, 1))
image = np.expand_dims(image, axis=0)
return image
# 进行推理
def run_model(input_data):
results = compiled_model(input_data)[output_layer]
class_index = np.argmax(results) # top-1
return class_index
# 主函数
if __name__ == '__main__':
# # 加载预训练的Swin Tiny模型
from torchvision import models
model = models.swin_t(pretrained=True)
print(model)
image_path = './ant_bees/qa.png' # 替换为你的图像路径
image = cv2.imread(image_path)
# 预处理图像
input_data = preprocess_image(image_path)
# 进行推理
class_index = run_model(input_data)
lines = ['ant', 'bee']
print("Predicted class: ", lines[class_index])
cv2.putText(image, lines[class_index], (50, 50), cv2.FONT_HERSHEY_SIMPLEX, 1, (255, 0, 255), 2)
cv2.imshow("Swin@gloomyfish+OpenVINO2025", image)
cv2.waitKey(0)
cv2.destroyAllWindows()二、分模块逐行解析
1. 导入依赖模块
python
import cv2
import numpy as np
import openvino as ov
# 主函数中额外导入
from torchvision import modelscv2:OpenCV 库,负责图像读取、resize、色彩空间转换、可视化(绘图、显示);numpy:数值计算库,处理图像的数组转换、维度调整、归一化等;openvino:英特尔的深度学习推理框架,负责加载 / 编译 ONNX 模型、执行高效推理;torchvision.models:仅用于打印 Swin Tiny 的模型结构(代码中未参与实际推理,属于冗余但辅助理解的代码)。
2. 加载并编译 ONNX 模型
python
# 加载ONNX格式的SWIN Tiny模型
core = ov.Core()
compiled_model = core.compile_model("swin_t_ant_bee.onnx", "CPU")
# 获取输入和输出层
input_layer = compiled_model.input(0)
output_layer = compiled_model.output(0)这是 OpenVINO 推理的核心初始化步骤:
ov.Core():创建 OpenVINO 的核心对象,是所有操作的入口;core.compile_model():将 ONNX 模型编译为适配指定硬件的可执行模型:- 第一个参数:ONNX 模型文件路径(
swin_t_ant_bee.onnx是针对 ant/bee 二分类微调后的 Swin Tiny 模型); - 第二个参数:指定推理硬件(
CPU,也可改为GPU/MYRIAD等);
- 第一个参数:ONNX 模型文件路径(
compiled_model.input(0)/output(0):获取模型的输入 / 输出层(Swin Tiny 分类模型通常只有 1 个输入层、1 个输出层),后续推理时需按该层的要求传入数据、读取结果。
3. 图像预处理函数(核心)
python
def preprocess_image(image_path):
# 打开图像
image = cv2.imread(image_path)
cv2.imshow("input", image) # 临时显示原始输入图像
if image is None:
raise ValueError("Image not found or unable to read")
# 调整图像大小为224x224
input_size = (224, 224)
image = cv2.resize(image, input_size)
# 转换为RGB格式
image = cv2.cvtColor(image, cv2.COLOR_BGR2RGB)
# 归一化图像
mean = [0.485, 0.456, 0.406]
std = [0.229, 0.224, 0.225]
image = np.array(image) / 255.0 # 像素值从[0,255]缩放到[0,1]
image -= mean # 减均值
image /= std # 除标准差
# 调整维度为[1, C, H, W]
image = np.transpose(image, (2, 0, 1)) # [H,W,C] → [C,H,W]
image = np.expand_dims(image, axis=0) # 增加batch维度,从[C,H,W]→[1,C,H,W]
return image这组 mean = [0.485, 0.456, 0.406] 和 std = [0.229, 0.224, 0.225] 不是天生固定的,但它们是主流视觉模型(包括 Swin Transformer、ResNet、ViT 等)的「默认标准值」
什么时候需要修改这组值?
只有两种情况需要替换 mean/std,核心原则是「训练和推理时用同一组统计值」:
自定义数据集从头训练:如果你的数据集不是自然图像(比如医学 CT 图、工业缺陷检测图、卫星图),或者自然图像但分布特殊(比如全是夜景、全是红色物体),需要自己统计数据集的 mean/std:
## **计算方法:遍历数据集中所有图像,分别统计 R、G、B 三个通道的像素均值和标准差(注意:要先将像素值除以 255 转为 0-1 范围后再统计);** ## **示例:如果你的数据集统计后 R 通道均值 0.521、标准差 0.230,G 通道 0.512、0.228,B 通道 0.498、0.225,就用这组值替换原有的 mean 和 std。**使用非 ImageNet 预训练的权重:如果你的模型权重是基于其他数据集(比如 COCO、Fashion-MNIST)预训练的,需要使用该数据集对应的 mean/std(通常预训练权重的官方文档会说明)。
|---------------------|--------------------|----------------------------------------------------------------------------------------------------------------------------------------------------------|
| 步骤 | 目的 | 关键说明 |
| 读取图像 | 加载输入图片 | OpenCV 默认读取为 BGR 格式,形状为[H,W,3] |
| 调整尺寸为 224×224 | 匹配 Swin Tiny 的输入尺寸 | 预训练的 Swin Tiny 默认输入是 224×224 |
| BGR 转 RGB | 匹配模型训练时的色彩空间 | PyTorch/TorchVision 的模型训练时用 RGB 格式,而 OpenCV 读入是 BGR,必须转换 |
| 归一化(除 255→减均值→除标准差) | 消除像素值分布差异 | mean/std是 ImageNet 预训练的标准归一化参数,必须和模型训练时一致 |
| 维度调整 | 匹配模型输入格式 | Swin 模型输入要求[batch_size, channels, height, width],需完成两次转换:1. (2,0,1):把 OpenCV 的[H,W,C]转为[C,H,W];2. expand_dims:增加 batch 维度(推理时单张图 batch_size=1) |
- 推理执行函数
python
def run_model(input_data):
results = compiled_model(input_data)[output_layer]
class_index = np.argmax(results) # top-1
return class_indexcompiled_model(input_data):将预处理后的图像数据传入编译好的模型,执行推理;[output_layer]:读取输出层的结果(形状为[1, 2],对应 ant/bee 两个类别的预测概率);np.argmax(results):取概率最大的索引(Top-1 预测),索引 0 对应 ant、1 对应 bee。
- 主函数(执行流程)
python
if __name__ == '__main__':
# 【冗余代码】仅打印Swin Tiny模型结构,未参与推理
from torchvision import models
model = models.swin_t(pretrained=True)
print(model)
# 1. 定义图像路径并读取原图(用于后续可视化)
image_path = './ant_bees/qa.png' # 替换为你的图像路径
image = cv2.imread(image_path) # 读取原图(未预处理,用于绘图)
# 2. 预处理图像
input_data = preprocess_image(image_path)
# 3. 执行推理
class_index = run_model(input_data)
# 4. 类别映射(索引→标签)
lines = ['ant', 'bee']
print("Predicted class: ", lines[class_index])
# 5. 可视化结果:在原图上标注预测类别
cv2.putText(
image, # 要标注的图像(原图,非预处理后的)
lines[class_index], # 标注文本
(50, 50), # 文本左上角坐标
cv2.FONT_HERSHEY_SIMPLEX, # 字体
1, # 字体大小
(255, 0, 255), # 字体颜色(洋红)
2 # 线条粗细
)
cv2.imshow("Swin@gloomyfish+OpenVINO2025", image) # 显示标注后的图像
cv2.waitKey(0) # 等待按键(按任意键关闭窗口)
cv2.destroyAllWindows() # 销毁所有窗口主函数是代码的执行入口,核心流程:
- 冗余代码 :
models.swin_t(pretrained=True)仅加载 PyTorch 官方的 Swin Tiny 模型并打印结构,和 OpenVINO 的推理无关,可删除; - 读取原图 :
cv2.imread(image_path)读取未预处理的原图,目的是后续在原图上标注结果(预处理后的图是 224×224,原图尺寸更适合展示); - 预处理 + 推理:调用前面的函数完成核心逻辑;
- 类别映射:把索引转为易读的标签(ant/bee);
- 可视化 :用
cv2.putText标注文本,imshow显示图像,waitKey等待按键,最后销毁窗口。
三、代码中的关键注意点
- 冗余代码 :
torchvision.models.swin_t部分仅用于查看模型结构,对推理无作用,实际部署时可删除; - 图像区分 :代码中有两个 "image" 变量:
- 预处理函数内的
image:经过 resize、归一化、维度调整的图像(用于推理); - 主函数中的
image:原始尺寸的图像(用于可视化);
- 预处理函数内的
- 硬件适配 :
core.compile_model的第二个参数若改为"GPU"(需安装 OpenVINO GPU 插件),可提升推理速度; - 错误处理 :若
image_path路径错误,cv2.imread返回None,代码会抛出ValueError,保证程序不会崩溃。
四、总结
这段代码是OpenVINO 部署视觉 Transformer(Swin Tiny)的典型示例,核心关键点:
- OpenVINO 部署 ONNX 模型的核心流程:
Core() → compile_model → 输入数据 → 推理 → 解析输出; - Swin 模型的预处理必须匹配训练时的逻辑(RGB、归一化、
[B,C,H,W]维度); - 推理结果解析采用 Top-1 策略,通过索引映射到具体类别;
- 可视化需基于原图(未预处理的),保证标注位置和尺寸符合直观认知。