原理
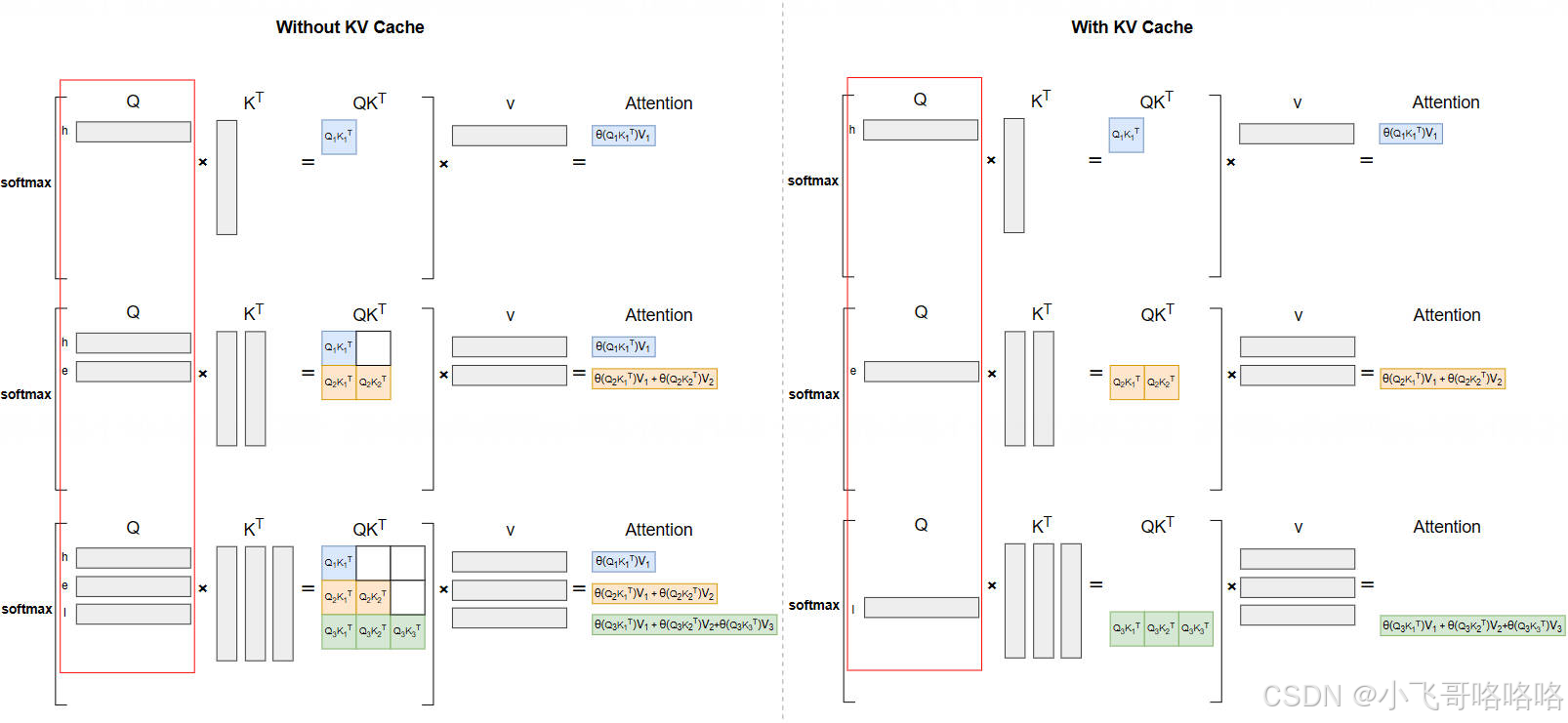
这里贴一张经典的图(ref:https://infrasys-ai.github.io/aiinfra-docs/05Infer02InferSpeedUp/01KVCache.html)
但我个人觉得这个图不能体现KV Cache减少计算的情况,因为看起来Attention的结果在前后也有优化,但实际上左边的Q也可以改成单个的,关键的是不需要重复计算K和V了。
数学推理参考https://datahonor.com/blog/2025/06/03/llm_kv_cache/
prefix Cache
直白讲,就是在KV Cache保存时,如果是相同前缀的完全相同的block,可以复用。

