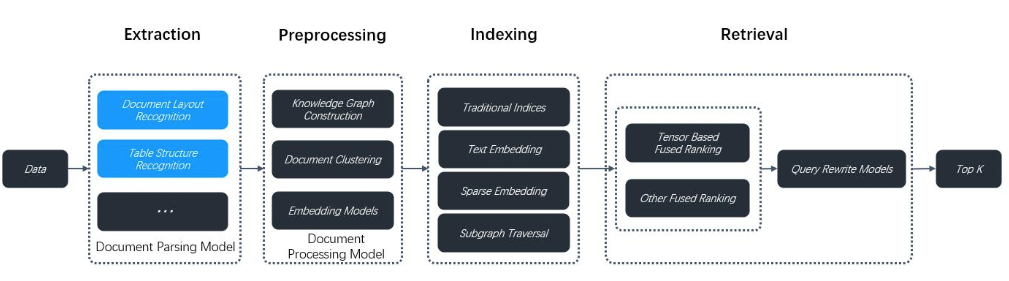
以上是从原始数据到最终返回 Top-K 结果的完整流程的信息检索或 RAG(Retrieval-Augmented Generation)系统架构图。整个流程分为四个主要阶段:Extraction(提取)、Preprocessing(预处理)、Indexing(索引构建)、Retrieval(检索)。
🔍 流程详解
1. Extraction(提取)
目标:将原始数据(如 PDF、Word、网页等)转化为结构化内容。
- 包含模块:
- Document Layout Recognition (文档布局识别)
→ 识别文本、标题、图片、表格等在页面上的位置和结构。 - Table Structure Recognition (表格结构识别)
→ 将表格内容解析为行/列结构,便于后续处理。 - 其他未列出的提取任务(用
...表示)
- Document Layout Recognition (文档布局识别)
✅ 输出:结构化的文档内容(例如:段落、标题、表格数据等),由 Document Parsing Model 完成。
2. Preprocessing(预处理)
目标:对提取出的内容进行语义增强与组织,提升后续索引和检索的质量。
- 包含模块:
- Knowledge Graph Construction (知识图谱构建)
→ 从文本中抽取实体、关系,构建图结构(如"人物-事件-地点")。 - Document Clustering (文档聚类)
→ 将相似内容的文档或段落分组,用于减少冗余或支持主题导航。 - Embedding Models (嵌入模型)
→ 使用语言模型(如 BERT、Sentence-BERT)生成文本向量表示,为后续索引做准备。
- Knowledge Graph Construction (知识图谱构建)
✅ 输出:结构化+语义增强的数据,由 Document Processing Model 处理。
3. Indexing(索引构建)
目标:将预处理后的数据建立高效可检索的索引。
- 包含模块:
- Traditional Indices (传统索引)
→ 如倒排索引(Inverted Index),支持关键词快速查找。 - Text Embedding (文本嵌入)
→ 将文本转换为稠密向量,用于语义相似度搜索。 - Sparse Embedding (稀疏嵌入)
→ 如 BM25 的向量化形式,保留关键词权重,适合短文本匹配。 - Subgraph Traversal (子图遍历)
→ 如果构建了知识图谱,则可通过图结构进行路径查询(如"谁参与了什么项目?")。
- Traditional Indices (传统索引)
✅ 输出:多种类型的索引结构,支持不同方式的检索。
4. Retrieval(检索)
目标:根据用户查询,从索引中召回最相关的 top-k 文档或片段。
- 包含模块:
- Tensor Based Fused Ranking (基于张量的融合排序)
→ 融合多个信号(如稠密向量 + 稀疏关键词 + 图结构)进行综合打分。 - Other Fused Ranking (其他融合排序方法)
→ 可能包括多模态融合、重排序模型等。 - Query Rewrite Models (查询改写模型)
→ 对原始查询进行扩展或优化(如添加同义词、补全意图),提升召回效果。
- Tensor Based Fused Ranking (基于张量的融合排序)
✅ 最终输出:Top K 个最相关的结果。
🔄 整体流程总结
Data
→ [Extraction] → 结构化内容(布局、表格等)
→ [Preprocessing] → 语义增强(知识图谱、聚类、嵌入)
→ [Indexing] → 多类型索引(传统、嵌入、图结构)
→ [Retrieval] → 融合排序 + 查询改写 → Top K 结果💡 核心思想
现代智能检索系统不再依赖单一方法,而是通过"多阶段、多模态、多策略"的协同工作,实现从原始数据到高质量结果的端到端处理。
它强调了以下几点:
| 关键点 | 说明 |
|---|---|
| ✅ 结构感知 | 提取阶段关注文档物理/逻辑结构(布局、表格),避免"纯文本切块"的问题。 |
| ✅ 语义增强 | 预处理阶段引入知识图谱、聚类、嵌入,提升上下文理解能力。 |
| ✅ 多索引融合 | 索引阶段同时支持传统关键词 + 语义向量 + 图结构,兼顾 recall 和 utilization。 |
| ✅ 智能检索 | 检索阶段使用融合排序和查询改写,提升准确率和鲁棒性。 |
🎯 实际应用场景
这种架构常见于:
- 长文档问答系统(如法律、医学文献)
- 企业知识库(如内部文档、产品手册)
- 大模型 RAG 系统(如 LlamaIndex、Weaviate、LangChain 等)
✅ 总结
这张图描绘了一个端到端的智能信息检索框架 ,通过结构化提取 → 语义预处理 → 多模态索引 → 融合检索的四步流程,解决"如何让机器既找得准、又用得好"的核心挑战。