1、下载源码
通过以下地址下载ragflow源码
https://codeload.github.com/infiniflow/ragflow/zip/refs/heads/main
2、构建python环境
- 解压源码,通过uv下载依赖包
进入ragflow根目录,执行以下命令
bash
uv sync --python 3.12 --frozen- 清华源会报403,可以改成阿里源,打开uv.lock文件,按下图修改
bash
https://pypi.tuna.tsinghua.edu.cn/simple
全部替换
https://mirrors.aliyun.com/pypi/simple/3、修改配置文件
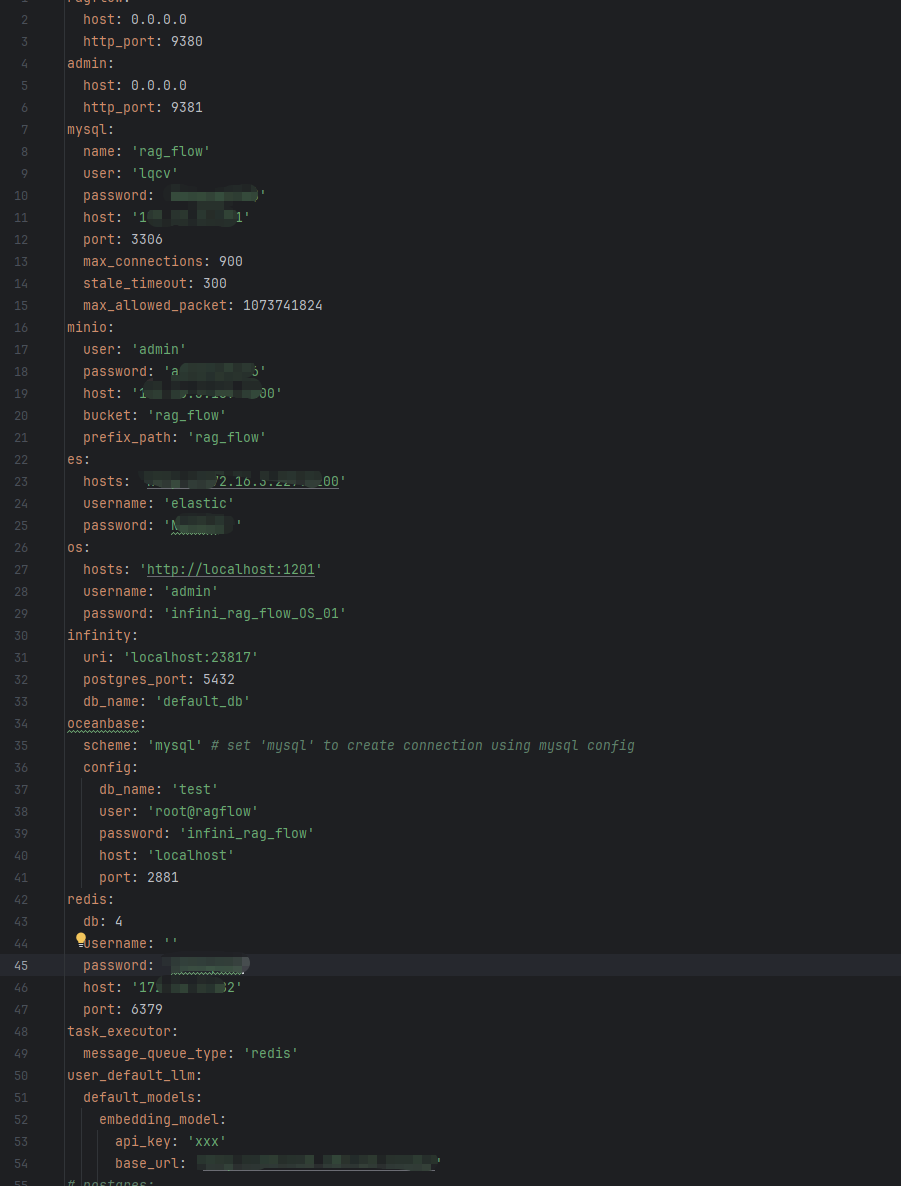
进入conf目录,打开service_conf.yaml文件,将配置改成实际依赖的环境,主要修改mysql、minio、es(必须是8以上)和redis(redis必须是5以上)
4、下载依赖项
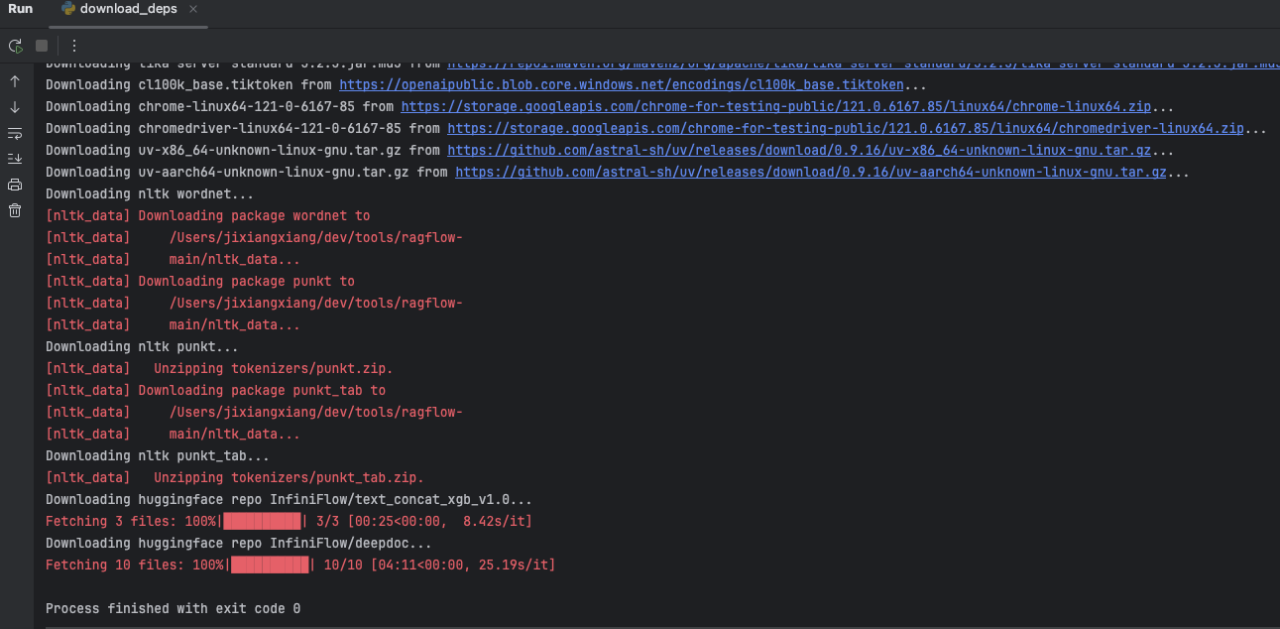
启动ragflow要先下载一些模型文件模型文件,可直接执行download_deps.py,此处需要科学上网,等待是来分钟。
5、运行API模块
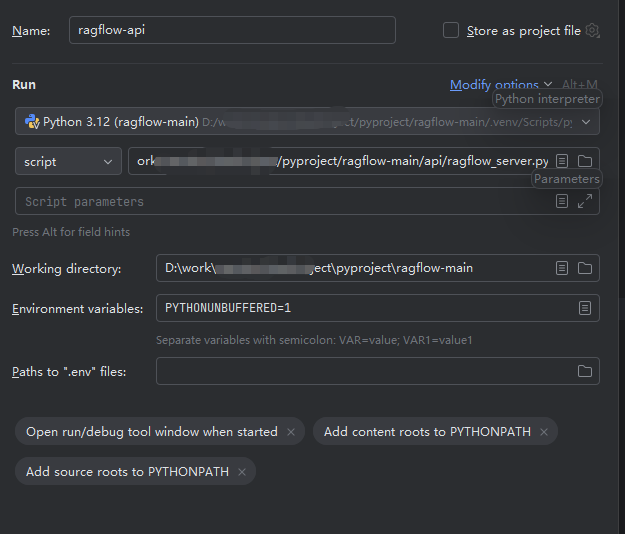
在pycharm中配置运行脚本
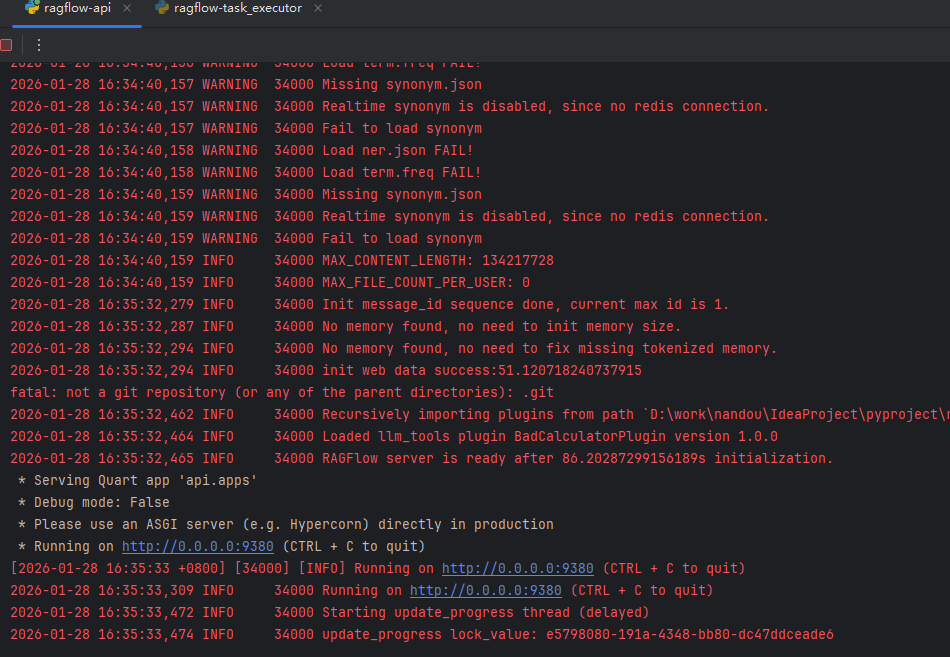
运行脚本后如下图则环境搭建完成
6 运行task-executor模块
task-executor模块是实际执行解析文档的模块,API将文档接收后推送至redis,task模块消费redis执行文档解析任务
7 api与task模块关系
下面的表格清晰展示了两者的核心区别与联系:
| 对比维度 | /api/ragflow_server.py (主服务器) |
/rag/svr/task_executor.py (任务执行器) |
它们如何联系 |
|---|---|---|---|
| 核心角色 | 系统的总控中心 与服务入口 | 后台的异步任务执行者 | 指挥与被指挥的关系。主服务器负责任务的"派发",任务执行器负责"执行"。 |
| 主要职责 | 1. 初始化并启动整个系统。 2. 提供核心的Web API服务。 3. 定期扫描并调度待处理文档,生成任务推送到队列。 | 1. 持续监听Redis任务队列 。 2. 执行具体的文档解析任务(如分块、向量化、索引等)。 | 通过 Redis消息队列 进行异步通信。主服务器是"生产者",将任务放入队列;任务执行器是"消费者",从队列取出并执行。 |
| 运行模式 | 常驻的主进程,启动所有基础服务。 | 一个或多个可水平扩展的独立后台进程。 | 构成生产者-消费者模型。两者进程独立,通过队列解耦,提高了系统的可靠性和扩展性。 |
| 关键联系 | 任务的生产者与调度者 | 任务的消费者与执行者 | 共同协作,完成从"用户上传文档"到"文档被解析并存入知识库"的完整异步处理流程。 |
🔄 它们如何协同工作?
以你上传一个PDF文件到知识库为例:
-
接收请求 :你的请求首先到达
ragflow_server.py提供的API。 -
创建记录:服务器保存文件,并在数据库创建一条"待处理"的文档记录,然后立即返回"上传成功"的响应。
-
调度任务 :
ragflow_server.py的后台线程会定期扫描数据库,发现这条新记录后,生成对应的"文档解析"任务,并将其放入 Redis 队列。 -
执行任务 :一个或多个
task_executor.py进程在后台监听队列,抢到这个任务后,开始执行复杂的解析、分块和向量化工作。 -
更新状态:执行器在处理过程中会通过数据库更新进度,完成后通知知识库更新状态。
💡 为何这样设计?
这种架构的核心优势在于解耦 和异步:
-
提升用户体验:文件上传后立刻得到响应,无需等待耗时处理。
-
提高系统可靠性:即使某个任务执行器崩溃,任务仍在队列中,可由其他执行器处理。
-
增强扩展性 :文档处理压力大时,可以单独增加
task_executor.py的实例数量来水平扩展处理能力。
总结来说,你可以把 ragflow_server.py 看作是系统的大脑和门户 ,而 task_executor.py 则是负责体力活的双手。两者通过消息队列默契配合,共同支撑起RAGFlow高效、稳定的文档处理流程。
如果你对RAGFlow的部署配置或者其他模块(如document_service.py)也感兴趣,我可以为你进一步介绍。