目录
[二、RAGflow 介绍](#二、RAGflow 介绍)
[2.1 RAGflow 是什么](#2.1 RAGflow 是什么)
[2.2 RAGflow 核心特点与优势](#2.2 RAGflow 核心特点与优势)
[2.2.1 RAGflow 核心特点](#2.2.1 RAGflow 核心特点)
[2.2.2 RAGflow 优势](#2.2.2 RAGflow 优势)
[2.3 RAGflow 应用场景](#2.3 RAGflow 应用场景)
[2.4 RAGflow 与其他同类产品对比](#2.4 RAGflow 与其他同类产品对比)
[2.4.1 MaxKB](#2.4.1 MaxKB)
[2.4.2 Dify](#2.4.2 Dify)
[2.4.3 FastGPT](#2.4.3 FastGPT)
[2.4.4 RagFlow](#2.4.4 RagFlow)
[2.4.5 Anything-LLM](#2.4.5 Anything-LLM)
[三、RAGflow 搭建与使用](#三、RAGflow 搭建与使用)
[3.1 环境准备](#3.1 环境准备)
[3.1.1 服务器配置](#3.1.1 服务器配置)
[3.1.2 docker环境](#3.1.2 docker环境)
[3.1.3 修改max_map_count](#3.1.3 修改max_map_count)
[3.2 基于docker部署RAGFlow操作过程](#3.2 基于docker部署RAGFlow操作过程)
[3.2.1 获取RAGFlow安装包](#3.2.1 获取RAGFlow安装包)
[3.2.2 修改配置文件](#3.2.2 修改配置文件)
[3.2.3 启动服务](#3.2.3 启动服务)
[3.2.4 web页面访问](#3.2.4 web页面访问)
[3.3 RAGFlow基本使用](#3.3 RAGFlow基本使用)
[3.3.1 添加Embedding模型](#3.3.1 添加Embedding模型)
[3.3.2 创建Dataset](#3.3.2 创建Dataset)
[3.3.3 验证并使用](#3.3.3 验证并使用)
一、前言
在AI大模型发展热火朝天的2025年,各个厂商的大模型都在飞速的抢占市场。在企业使用大模型进行实际业务落地过程中,尽管大模型带来了很多业务场景价值的延伸,以及日常工作提效,但是在私有化大模型落地过程中,大模型使用中仍然存在一些问题,比如联网检索时回答的问题发散,不够精准,大模型幻觉问题,给出的检索结果与企业自身实际期望的结果存在差距等,这些问题都可以通过专业的RAG知识库来辅助解决,本文将介绍一款开源RAG的RAGflow使用。
二、RAGflow 介绍
2.1 RAGflow 是什么
RAGFlow是一个基于深度文档理解的开源RAG(检索增强生成)引擎。简单来说,它能够"读懂"你的各种文档,并基于这些文档内容进行智能问答,就像拥有了一个对你所有资料都了如指掌的智能助手。官方地址:https://ragflow.io/

2.2 RAGflow 核心特点与优势
2.2.1 RAGflow 核心特点
RAGFlow的核心特点可以概括为:具备深度文档理解能力的开源RAG引擎,它通过先进的文件解析、可控的处理流程和灵活的部署方式,旨在生成有据可查、幻觉最小化的可靠答案。其核心特点归纳如下:
-
深度文档理解
- 核心优势。不仅解析文本,还能高保真处理复杂表格、图片、扫描件、合并单元格等非结构化数据,确保关键信息不丢失
-
可控可解释的处理流程
-
基于模板的文本切片:提供十多种预设模板,可按场景选择。
-
过程可视化与手动调整:支持可视化调整文本切割点,对解析结果进行干预,从源头提升质量。
-
-
答案可靠,降低幻觉
-
答案提供引用溯源:生成的每个答案都会附带引用来源的原文快照,支持点击定位,确保答案有据可依
-
先进的检索技术:结合多路召回(混合搜索)和融合重排序技术,提升信息检索的相关性
-
-
强大的集成与扩展性
-
兼容各类数据源:支持Word、PDF、PPT、Excel、HTML等十多种文件格式
-
开放的模型支持:可自由配置多种大语言模型和向量模型
-
便捷的API与企业集成:提供兼容OpenAI的API,可轻松集成到钉钉、企业微信等业务系统中
-
-
灵活的部署方式
-
开源本地部署:可通过Docker在自有服务器上部署,保障数据私密性。
-
云平台一键部署:支持在阿里云等平台通过计算巢一键部署,简化运维。
-
2.2.2 RAGflow 优势
解决企业级知识库管理难题
- 试想一下:你是一家咨询公司的项目经理,手头有几百份行业报告、合同文档和技术资料。每次需要查找特定信息时,都要花费大量时间翻阅文档。有了RAGFlow,你只需要问"2025年新能源汽车市场份额是多少?",系统就会自动从相关报告中提取准确信息并给出答案。
提升客服工作效率
- 许多企业都面临客服重复回答同样问题的困扰。通过RAGFlow,你可以将产品手册、FAQ文档、政策文件等上传到系统中,构建一个智能客服助手。当用户询问"退换货流程是什么?"时,系统会基于你的政策文档给出准确、一致的回答。
学习资料个性化
- 对于学生或研究人员,RAGFlow可以将教材、论文、笔记等资料转化为个性化的学习助手。你可以问"机器学习中的过拟合现象是什么?",系统会从你上传的资料中找到相关内容进行解答。
卓越的复杂文档解析能力
- 这是RAGFlow的核心壁垒。它能高保真地解析和处理扫描件、PDF、PPT中的复杂表格、图表、合并单元格等,确保知识提取完整,从源头减少信息损失。相比之下,很多其他工具在处理此类文档时,表格信息容易错乱。
答案高度可溯源,可信赖
- 生成答案时,不仅提供引用来源,还会自动生成原文快照,并在原文中高亮定位。这相当于为每个答案都配备了"定位器"和"证据链",极大地增强了答案的可信度,便于核查。
灵活可控的知识处理流程
- 提供文本切片模板和可视化编辑功能,允许你干预和调整文档解析与切割过程,确保关键信息被正确处理,实现了从"黑盒"到"白盒"的管控。
开放集成与数据安全
-
开源与开放生态:可自由集成任何主流的LLM和向量模型。
-
数据完全私有化:支持本地或私有云部署,数据不出内网,满足高合规性要求。
-
便捷集成:提供标准API,可快速与企业内部系统(如OA、IM)对接。
2.3 RAGflow 应用场景
RAGFlow凭借其深度文档理解和答案可溯源的核心优势,在实际应用中已落地于多个对数据安全、格式复杂性和答案准确性要求高的领域。下面列举一些常用的应用场景。
-
企业内部知识管理与问答
-
统一企业知识库、部门职责查询、技术文档查询
- 整合散落在各部门(如钉钉、飞书)的文档、流程文件,通过智能问答提升效率
-
-
智能客服与产品支持
-
比如搭建企业自建的售前售后咨询、产品助手等
- 快速从复杂的产品手册、技术规范中提取精准信息,生成可靠回答,提升服务质量
-
-
政务与公共服务
-
政策咨询、办事指南解读
- 精准解析政府公文、法规,在确保数据本地化安全的前提下,提供权威、可溯源的解答
-
-
专业研究与分析
-
文献调研、医药研发、金融分析
- 处理行业特有的图纸、标准、表格数据,构建行业专属知识库
-
-
内容创作与生成
-
AI撰稿、报告生成
- 基于企业多源数据(如过往报告、市场情报)自动生成内容初稿或分析报告,提高创作效率与准确性
-
从上述场景可以看出,RAGFlow尤其适合以下三类需求:
-
文档复杂:需要处理大量扫描件、PDF、带复杂表格和图表文档的场景。
-
要求精准:金融、法律、政务、研发等领域,要求答案必须精准、有据可查。
-
注重安全:要求数据完全私有化、本地化部署,不出内部网络。
2.4 RAGflow 与其他同类产品对比
下面列举了目前市面上其他的一些主流的RAG类型的产品
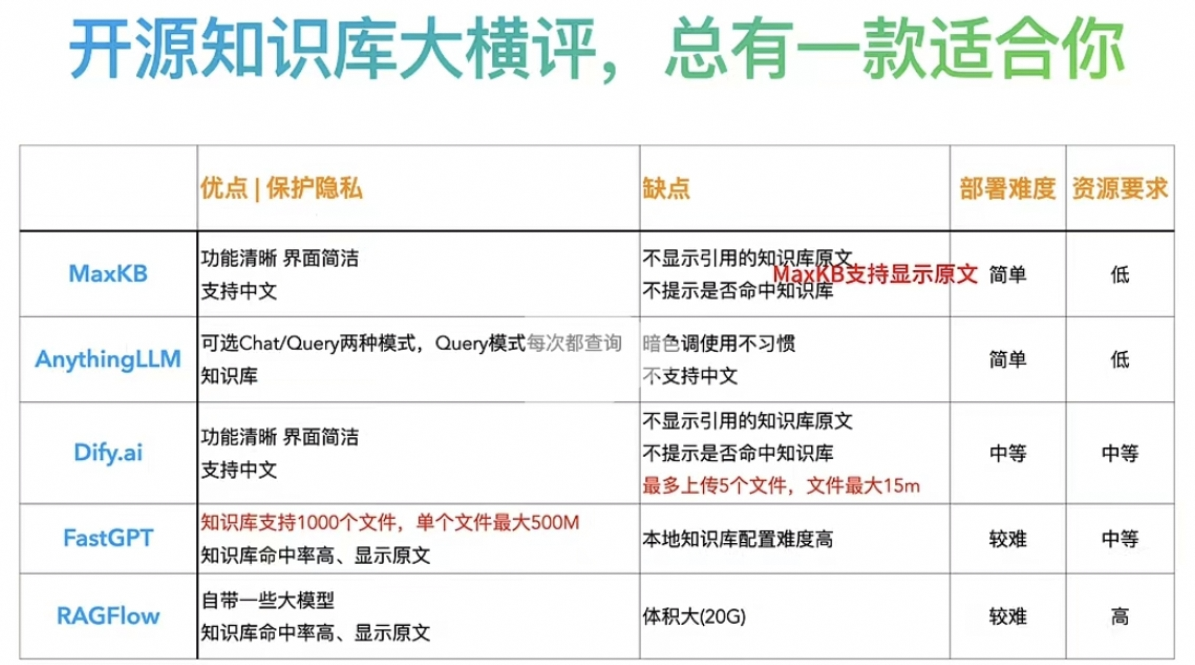
2.4.1 MaxKB
MaxKB = Max Knowledge Base,是一款基于 LLM 大语言模型的开源知识库问答系统,旨在成为企业的最强大脑。它能够帮助企业高效地管理知识,并提供智能问答功能。想象一下,你有一个虚拟助手,可以回答各种关于公司内部知识的问题,无论是政策、流程,还是技术文档,MaxKB 都能快速准确地给出答案:比如公司内网如何访问、如何提交视觉设计需求等等,官方网址:https://maxkb.cn/
2.4.2 Dify
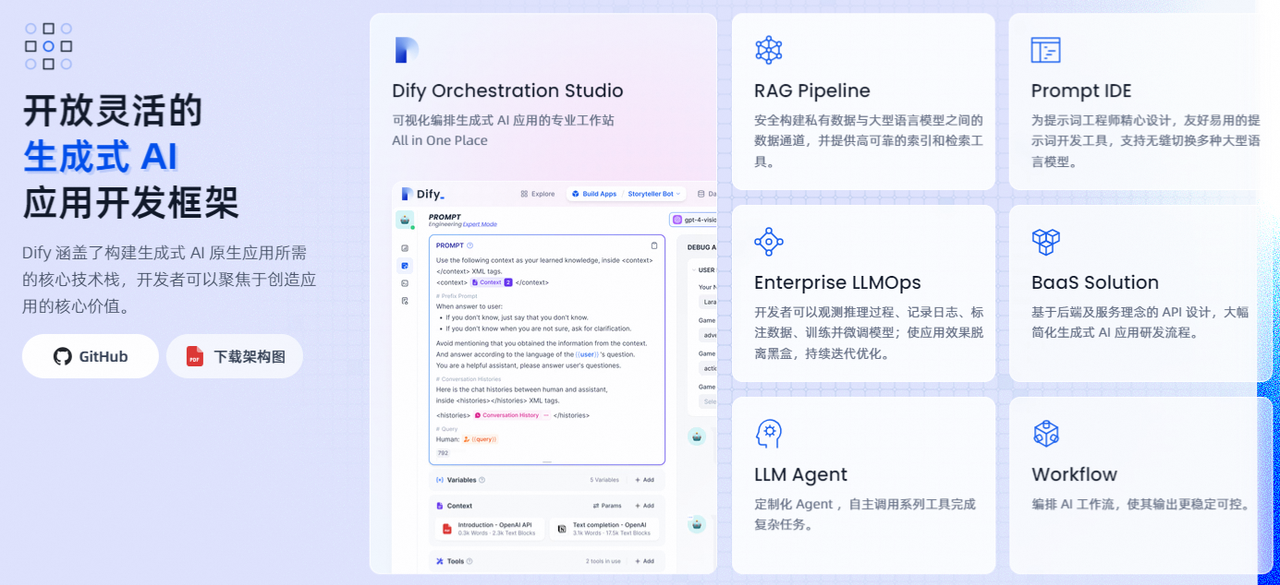
Dify 是一款开源的大语言模型(LLM) 应用开发平台。它融合了后端即服务(Backend as Service)和 LLMOps 的理念,使开发者可以快速搭建生产级的生成式 AI 应用。即使你是非技术人员,也能参与到 AI 应用的定义和数据运营过程中。官网:https://dify.ai/zh
由于 Dify 内置了构建 LLM 应用所需的关键技术栈,包括对数百个模型的支持、直观的 Prompt 编排界面、高质量的 RAG 引擎、稳健的 Agent 框架、灵活的流程编排,并同时提供了一套易用的界面和 API。这为开发者节省了许多重复造轮子的时间,使其可以专注在创新和业务需求上
2.4.3 FastGPT
FastGPT是一个功能强大的平台,专注于知识库训练和自动化工作流程的编排。它提供了一个简单易用的可视化界面,支持自动数据预处理和基于Flow模块的工作流编排。FastGPT支持创建RAG系统,提供自动化工作流程等功能,使得构建和使用RAG系统变得简单,无需编写复杂代码。
2.4.4 RagFlow
RAGFlow 是一款基于深度文档理解构建的开源 RAG(Retrieval-Augmented Generation)引擎。RAGFlow 可以为各种规模的企业及个人提供一套精简的 RAG 工作流程,结合大语言模型(LLM)针对用户各类不同的复杂格式数据提供可靠的问答以及有理有据的引用。
2.4.5 Anything-LLM
AnythingLLM是一个全栈应用程序,您可以使用现成的商业大语言模型或流行的开源大语言模型,再结合向量数据库解决方案构建一个私有ChatGPT,不再受制于人:您可以本地运行,也可以远程托管,并能够与您提供的任何文档智能聊天。
AnythingLLM将您的文档划分为称为workspaces (工作区)的对象。工作区的功能类似于线程,同时增加了文档的容器化,。工作区可以共享文档,但工作区之间的内容不会互相干扰或污染,因此您可以保持每个工作区的上下文清晰。
三、RAGflow 搭建与使用
接下来演示如何部署RAGflow 和使用。
3.1 环境准备
为了后面能够正常运行RAGflow ,在开始部署RAGflow ,需要做如下几个准备。
3.1.1 服务器配置
你的服务器需要满足下面的条件
-
CPU >= 4 核
-
RAM >= 16 GB
-
Disk >= 50 GB
-
Docker >= 24.0.0 & Docker Compose >= v2.26.1
3.1.2 docker环境
提前安装好docker和Docker Compose 环境
3.1.3 修改max_map_count
确保 vm.max_map_count 不小于 262144,如需确认 vm.max_map_count 的大小:
bash
$ sysctl vm.max_map_count如果 vm.max_map_count 的值小于 262144,可以进行重置:
bash
# 这里我们设为 262144:
$ sudo sysctl -w vm.max_map_count=262144你的改动会在下次系统重启时被重置。如果希望做永久改动,还需要在 /etc/sysctl.conf 文件里把 vm.max_map_count 的值再相应更新一遍:
bash
vm.max_map_count=2621443.2 基于docker部署RAGFlow操作过程
参考下面的流程完成基于docker部署RAGFlow的操作过程
3.2.1 获取RAGFlow安装包
下载RAGFlow项目,这里通过git获取安装的包,进入到你的服务器目录,执行下面的git命令将安装包代码拉下来
bash
git clone https://github.com/infiniflow/ragflow.git
3.2.2 修改配置文件
解压安装包,进入到安装包主目录下的docker目录中,编辑docker-compose.yml的镜像源为国内地址:
bash
# 替换原镜像配置为:
RAGFLOW_IMAGE=swr.cn-north-4.myhuaweicloud.com/infiniflow/ragflow:v0.17.0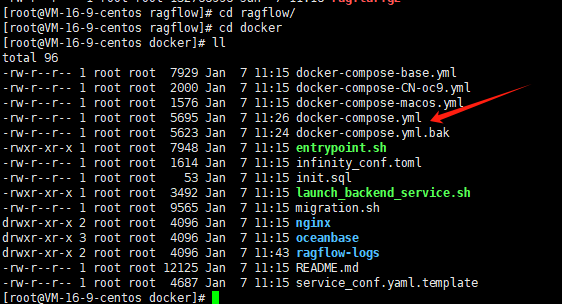
修改的位置如下:

3.2.3 启动服务
配置文件修改完成之后,以上是最小化的配置文件修改,如果在实际生产环境配置,需要适当再做一些其他的配置参数调整,然后依次执行下面的命令进行服务启动,使用docker-compose命令启动服务容器
bash
cd docker
docker-compose -f docker-compose.yml up -d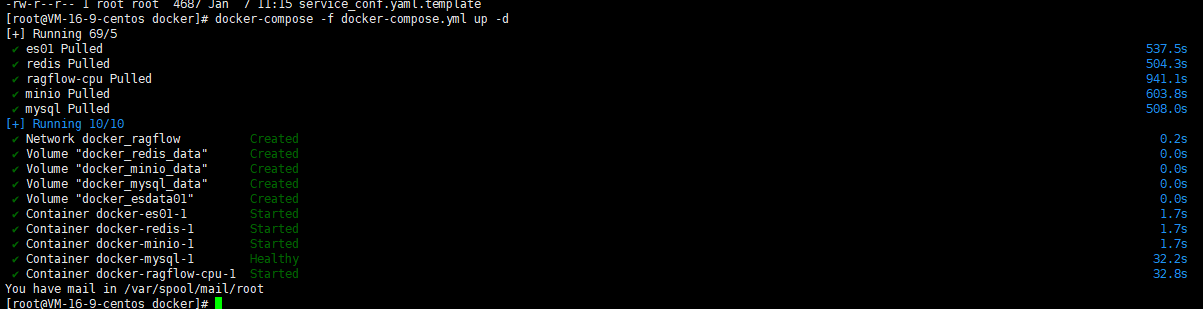
初次拉取镜像的时候由于镜像比较大,这个过程会比较长,需耐心等待一会,等5个容器全部启动成功后,通过docker ps命令检查一下

3.2.4 web页面访问
默认情况下RAGFlow提供了一个web控制台可以访问,地址,IP:8080,如果服务全部正常启动,浏览器访问效果如下
3.3 RAGFlow基本使用
3.3.1 添加Embedding模型
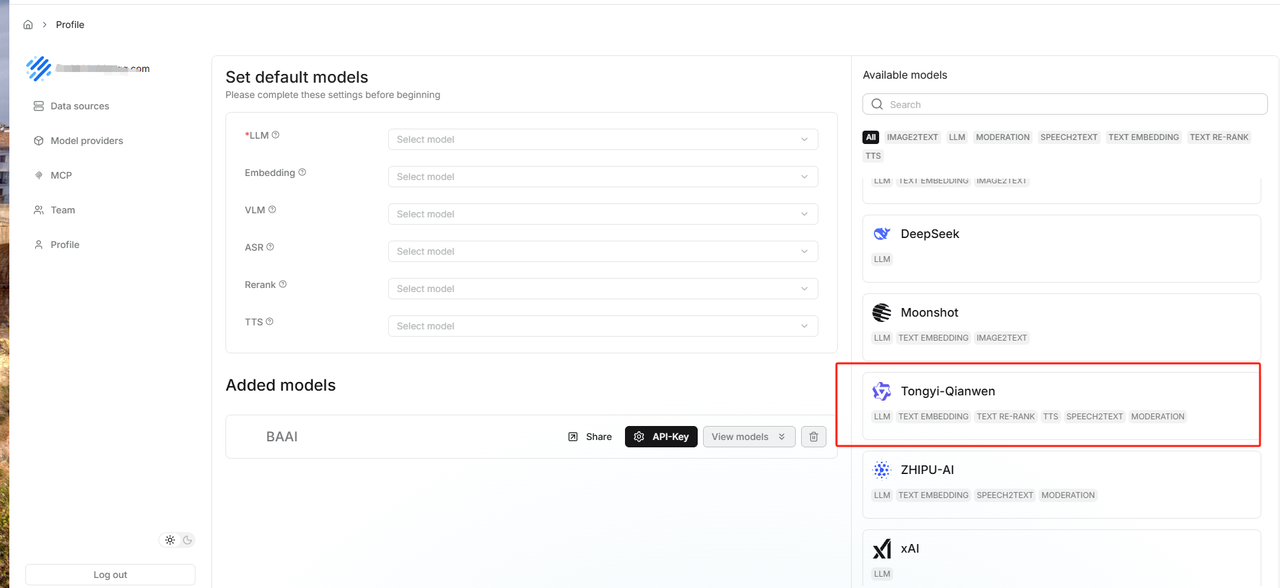
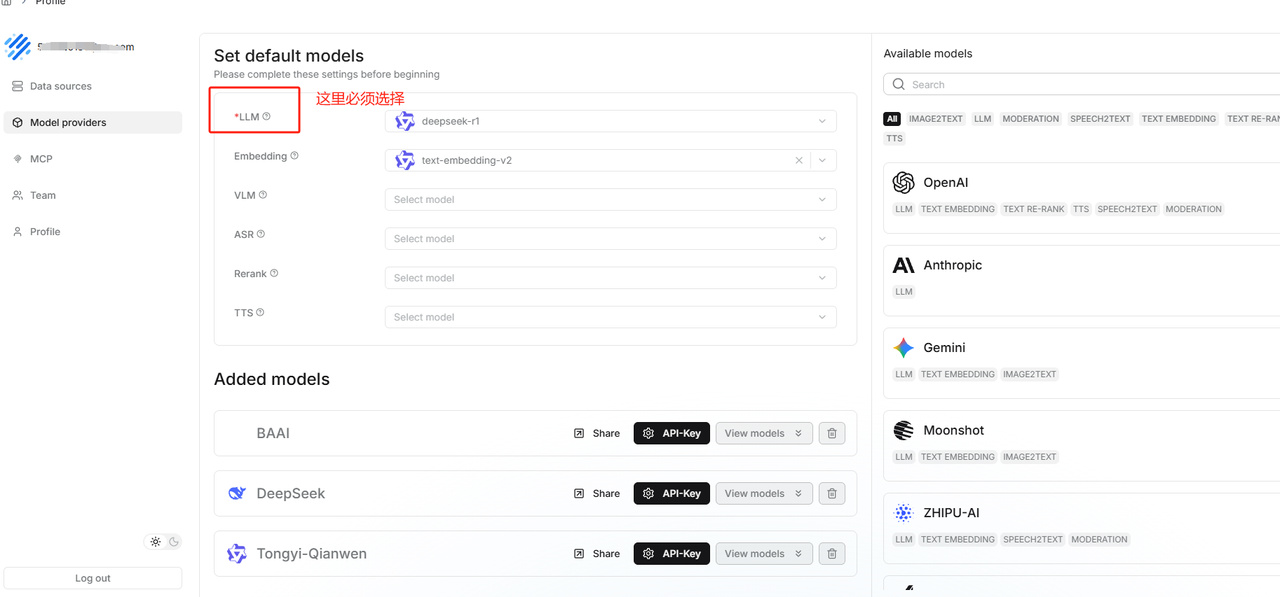
填写你的apikey,然后点击保存
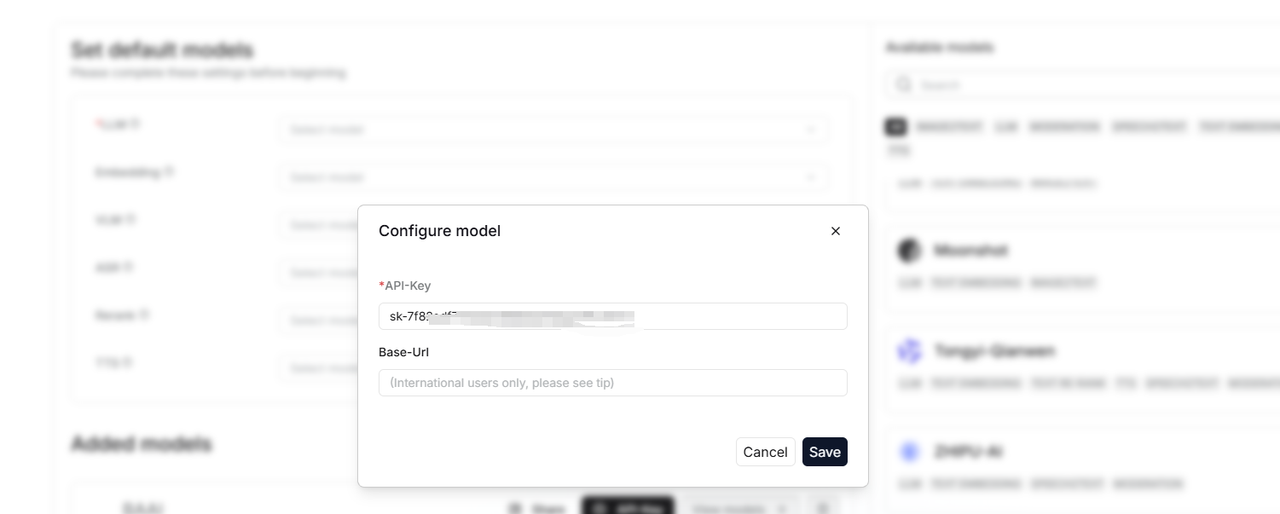
然后再在这个页面就能看到自己添加的大模型了
3.3.2 创建Dataset
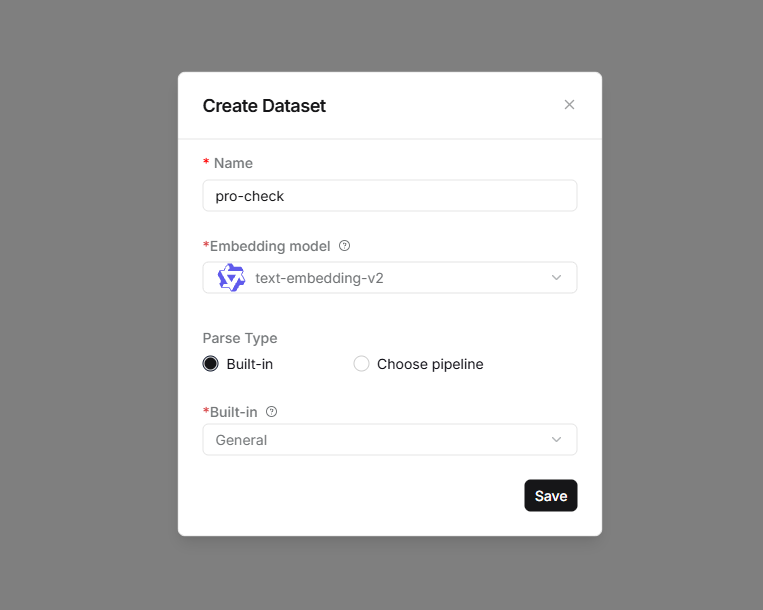
点击创建Dataset

填写下面表单中的必要信息
本地上传一个文件,我这里使用的是一个PDF文档
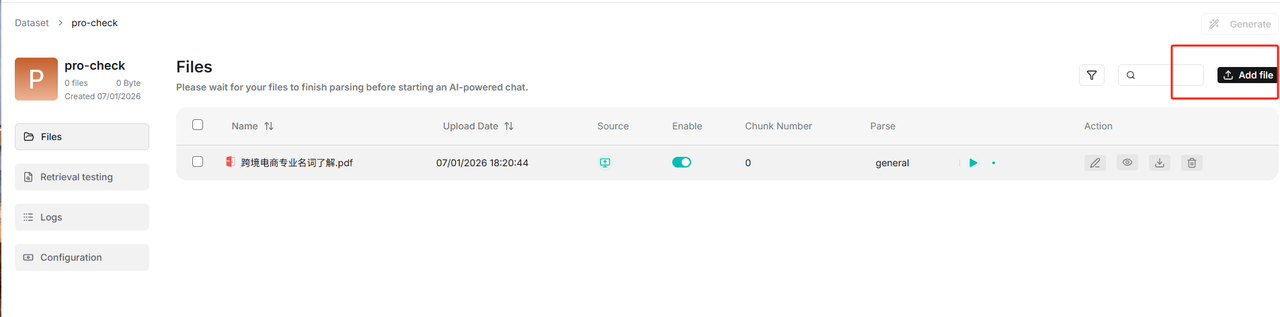
等到文档切分完成,可以点击进去查看切分的片段

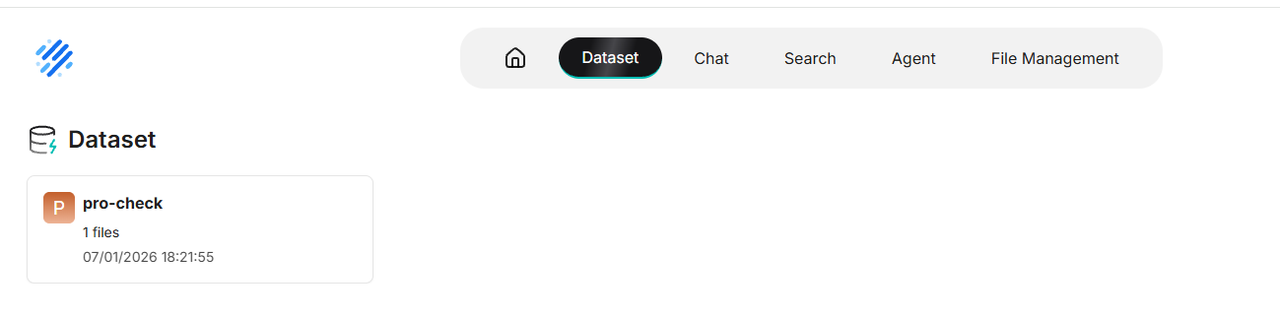
最后在Dataset主页就能看到上面创建的这个知识库了
3.3.3 验证并使用
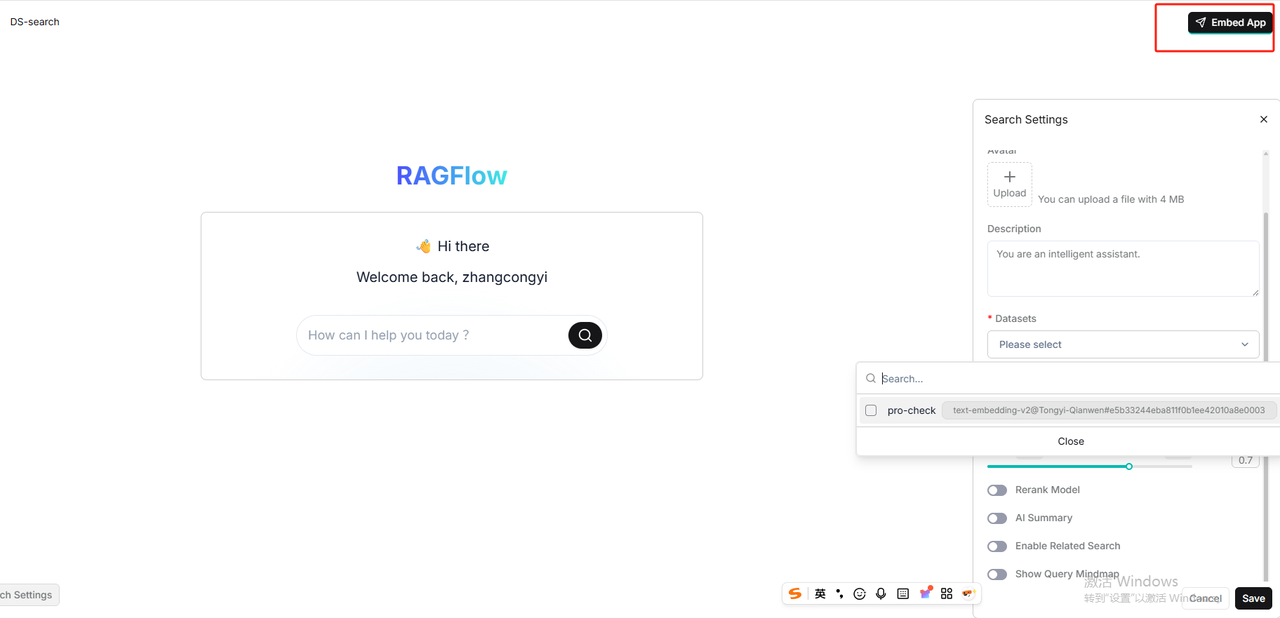
为了验证自己创建的这个知识库是否好用,可以点击创建一个Search应用,然后像下面这张图,选择自己创建的知识库,注意在右侧的选项中可以配置多项内容,比如模型,是否需要AI帮你总结等
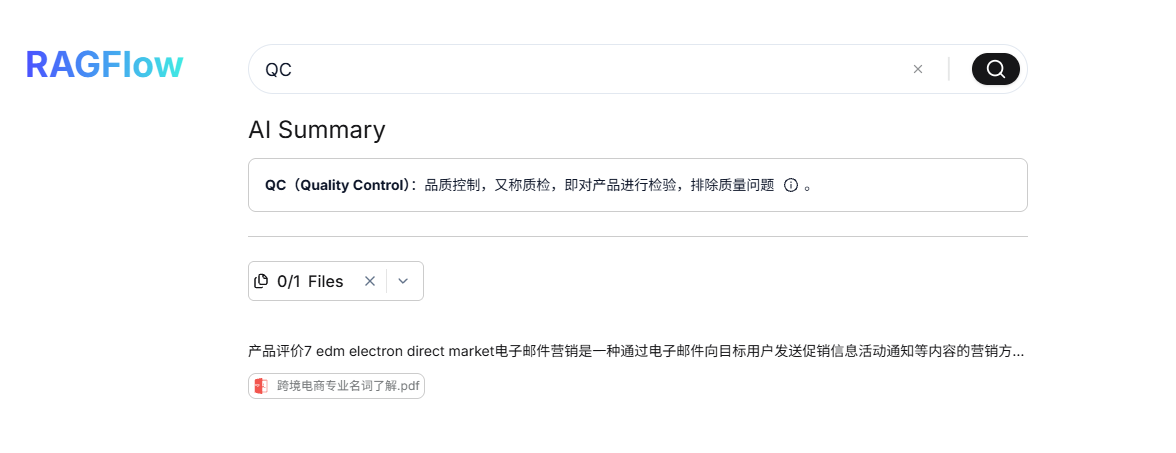
最后,在输入框中输入一个知识文档中的关键词或问题,如下效果
四、写在文末
上面简单演示了下RAGFlow的功能使用,当然还提供了更丰富的功能,有兴趣的同学可以继续研究操作,整体来说,作为私有化的知识库,RAGFlow的功能还是很丰富而且很强大的。本篇到此结束,感谢观看!